1. 문서 정보
- 제목: Learning Transferable Visual Models From Natural Language Supervision
- 저자: Alec Radford et al. (OpenAI)
- 형식: 학술 논문
- 발행: 2021 (ICML)
한 줄 요약
CLIP은 이미지와 자연어를 동일한 임베딩 공간에 정렬시키는 대규모 대비 학습을 통해, 별도의 태스크별 학습 없이도 강력한 zero-shot 비전 모델을 가능하게 한 연구이다.
2. 배경 및 동기
기존 비전 모델의 한계는 명확했다:
- 태스크별 데이터셋 필요
- 태스크별 classifier 필요
- 라벨 설계 비용 큼
- 일반화 한계 (dataset bias)
OpenAI의 문제의식은 다음과 같았다:
“자연어 자체를 supervision으로 쓰면
비전 모델을 더 범용적으로 만들 수 있지 않을까?”
즉,
- ImageNet class label ❌
- Bounding box ❌
- Task-specific head ❌
👉 인터넷에 이미 존재하는 (이미지, 텍스트) 쌍을 그대로 사용
3. 아키텍처 및 기술 구성
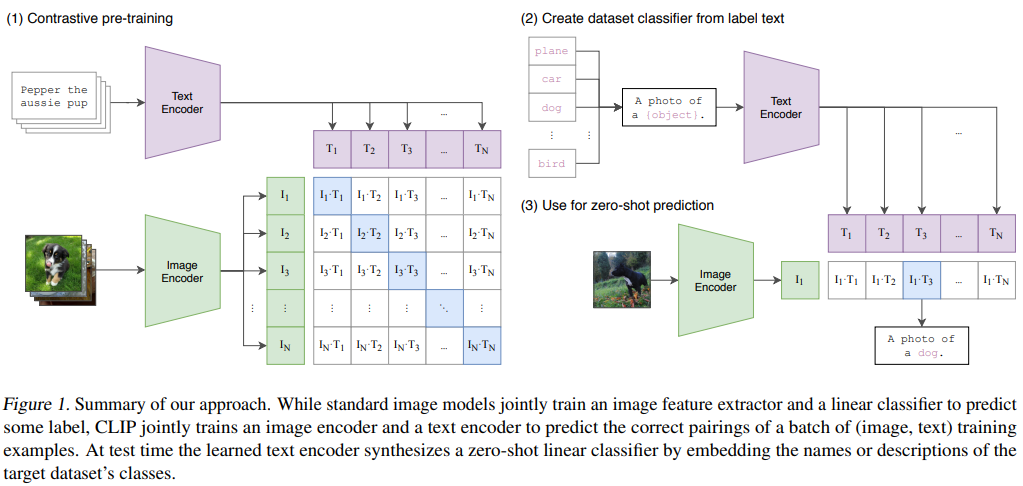
3.1 전체 구조 개요
CLIP은 Dual Encoder 구조를 사용한다.
Image → Image Encoder → Image Embedding
Text → Text Encoder → Text Embedding
↓
Cosine Similarity- Image encoder: ResNet or ViT
- Text encoder: Transformer
- Fusion layer ❌
- Cross-attention ❌
👉 이미지와 텍스트는 끝까지 섞이지 않는다
3.2 핵심 아이디어: Contrastive Learning
CLIP의 학습 목표는 단순하다:
정답 (image, text) 쌍은 가깝게,
나머지는 멀게
수식적으로는:
- batch 내 N개의 (image, text) 쌍
- N×N similarity matrix
- InfoNCE 기반 contrastive loss
👉 supervision = 자연어 그 자체
3.3 Zero-shot Classification 메커니즘
CLIP의 혁신은 학습이 아니라 “사용 방식”에 있다.
-
클래스 이름을 자연어 prompt로 변환
"a photo of a {class}" -
텍스트 임베딩 생성
-
이미지 임베딩과 similarity 계산
-
가장 가까운 텍스트 선택
📌 classifier를 학습하지 않음
오케이, 이제 요구가 정확히 이해됐어 👍
👉 “전체 구조는 그대로 두고,
그 안에 **내가 고민했던 포인트—‘인코더를 통해 이해가 가능해진다’, ‘결국 인코딩/정렬 문제다’—를 명시적으로 추가”하는 거지.*
아래는 기존 글을 최대한 건드리지 않고,
👉 자연스럽게 “추가”하면 되는 블록들이야.
(복붙해서 그대로 넣어도 되고, 톤도 맞춰놨어)
3.4 CLIP에서 “이해”는 어떻게 발생하는가? (Encoder 관점)
CLIP은 이미지와 텍스트를 단순히 매칭하는 모델처럼 보이지만,
실제로는 각 모달리티 인코더가 ‘의미를 이해할 수 있는 표현 공간’을 형성하는 데 초점이 맞춰져 있다.
여기서 중요한 점은 다음과 같다:
- CLIP은 이미지 자체를 “해석”하지 않는다
- 대신, 이미지를 의미적으로 설명 가능한 벡터로 인코딩한다
- 이 벡터는 자연어 개념들과 직접 비교 가능한 공간에 위치한다
즉, CLIP에서의 “이해”란:
이미지를 어떤 태스크에 맞게 해석하는 것이 아니라,
언어로 설명 가능한 의미 공간 안에 위치시키는 것
이다.
이 관점에서 보면 CLIP은
- 멀티모달 reasoning 모델 ❌
- 멀티모달 representation alignment 모델 ⭕
로 이해하는 것이 정확하다.
4. Inductive Bias 관점 분석
4.1 CLIP의 철학
CLIP은 다음을 전제로 한다:
시각 개념은 언어로 표현 가능하다
따라서:
- class boundary를 구조로 강제 ❌
- 언어 공간에 정렬 ⭕
4.2 CLIP의 inductive bias는 어디에 있나?
| 요소 | 역할 |
|---|---|
| Dual encoder | 모달리티 독립성 유지 |
| Contrastive loss | 의미 정렬 강제 |
| Prompt | 클래스 정의를 언어로 위임 |
👉 Bias는 구조가 아니라 objective에 있음
4.3 “결국 인코더만 잘 만들면 이해가 되는 것 아닌가?”에 대한 CLIP의 답
CLIP 논문은 명시적으로 다음과 같은 입장을 취한다:
“이미지를 이해하기 위해
이미지 내부에 복잡한 추론 구조를 넣을 필요는 없다.”
대신 CLIP이 선택한 전략은:
- 이미지 → 의미 벡터로 인코딩
- 텍스트 → 같은 의미 공간으로 인코딩
- 두 벡터의 상대적 위치로 의미 판단
즉, CLIP에서 중요한 것은
fusion이나 cross-attention이 아니라 encoder가 만들어내는 표현의 질이다.
이 점에서 CLIP은 다음과 같은 가정을 전제로 한다:
- “이 이미지가 무엇인지 이해했다”
≒ - “이 이미지 임베딩이 어떤 언어 개념들과 가까운지 안다”
👉 이해(understanding)를 추론 과정이 아니라
표현 공간 상의 위치로 정의한 것이 CLIP의 가장 중요한 관점 전환이다.
5. 훈련 전략과 데이터
5.1 데이터 규모
- 약 4억 개의 (image, text) 쌍
- 웹에서 수집
- noisy but diverse
📌 논문의 핵심 주장:
Noisy large-scale data > clean small-scale data
5.2 학습 특성
- End-to-end contrastive training
- No task-specific fine-tuning
- Encoder는 범용 feature extractor로 작동
6. 실험 결과 및 성능
6.1 Zero-shot Image Classification
CLIP은:
- ImageNet
- CIFAR
- Oxford Pets
- Flowers102
등에서:
- ResNet을 능가하거나 근접
- fine-tuning 없이 달성
👉 패러다임 전환
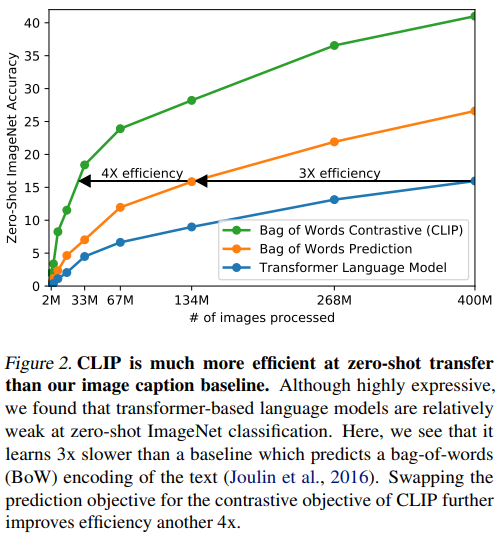
6.2 Robustness & Generalization
- Distribution shift에 강함
- Adversarial prompt에도 상대적으로 안정
- Dataset bias 감소
7. 장점 및 한계
✔ 장점
- Zero-shot / open-vocabulary
- 태스크 독립적
- 언어 기반 의미 일반화
- 멀티모달 정렬의 표준 제시
⚠ 한계
- Fine-grained localization ❌
- Spatial reasoning 약함
- Prompt 설계에 민감
- 생성 능력 없음 (discriminative only)
👉 이후 연구로 이어짐:
- BLIP
- ALIGN
- LLaVA
- GPT-4V
8. 한 문장 요약
CLIP은 이미지와 자연어를 동일한 의미 공간에 정렬함으로써, 비전 모델을 태스크별 분류기에서 범용 의미 인식기로 전환시킨 결정적 연구이다.
🔑 CLIP 논문에서 반드시 가져가야 할 인사이트
- Alignment가 Fusion보다 중요할 수 있다
- Vision–Language 문제는 “matching”에서 시작
- 언어는 최고의 supervision
- Zero-shot은 구조가 아니라 표현의 문제
🔗 ViT · CLIP · LLaVA 한 줄 연결
| 모델 | 핵심 |
|---|---|
| ViT | Vision = sequence |
| CLIP | Vision = language-aligned |
| LLaVA | Vision = instruction-conditioned |
👉 모두 “단순한 구조 + 대규모 학습”
CLIP이 이후 멀티모달 모델에 남긴 핵심 전제
CLIP 이후 등장한 LLaVA, GPT-4V 등의 모델들은
공통적으로 다음 전제를 계승한다:
“이미지는 이미 인코더 단계에서 의미적으로 정렬될 수 있으며,
이후 모델은 그 표현을 ‘어떻게 사용할지’만 학습하면 된다.”
이 관점에서 보면:
- CLIP → 의미 공간을 만든 모델
- LLaVA → 그 공간을 언어 추론에 사용하는 모델
이라고 역할이 명확히 분리된다.
즉, CLIP은
“이미지를 이해하는 모델”이라기보다
“이미지를 이해 가능한 형태로 바꿔주는 모델”
이라고 정의하는 것이 가장 정확하다.
마지막으로
CLIP을 이렇게 이해하면 정확합니다:
CLIP은 이미지와 텍스트를 동일한 의미 공간에 정렬함으로써,
이미지를 ‘해석 대상’이 아니라
‘언어적으로 이해 가능한 표현’으로 변환한 모델이다.
이로써 멀티모달 이해의 핵심이
구조가 아니라 인코딩과 정렬에 있음을 보여주었다.
그래서:
- LLaVA는 CLIP 없이는 불가능했고
- GPT-4V는 CLIP의 철학을 계승했다
