0. 3줄 요약
- 본 논문은 멀티모달 대형 언어 모델(MLLM)이 사용자의 진화하는 선호도와 성격을 장기적으로 학습하고 유지하지 못하는 문제를 해결하기 위해 PersonaVLM 프레임워크를 제안함.
- 기억(Memory), 추론(Reasoning), 응답 정렬(Response Alignment)의 세 가지 핵심 기능을 통합한 개인화 메모리 아키텍처와 성격 진화 메커니즘(PEM)을 도입함.
- 장기 개인화 벤치마크인 Persona-MME를 구축하여 검증한 결과, 기존 베이스라인 대비 22.4%의 성능 향상을 기록하며 GPT-4o를 상회하는 개인화 성능을 입증함.
1. 배경 및 문제 정의
현재의 멀티모달 대형 언어 모델(MLLM)은 수백만 명의 일상 비서 역할을 수행하고 있으나, 개별 사용자의 독특한 특성과 시간에 따라 변하는 선호도에 맞춰 응답하는 능력은 여전히 제한적입니다.
기존의 개인화 연구들은 주로 입력 증강(Input Augmentation)이나 정적인 출력 정렬(Output Alignment)에 집중해 왔습니다. 이러한 접근 방식은 다음과 같은 두 가지 핵심적인 한계를 가집니다.
- 정적 선호도의 한계: 사용자의 선호도는 상호작용 과정에서 변화(예: 특정 음료에 대한 선호 변화)하지만, 기존 모델은 과거의 고정된 기억에 의존하여 부적절한 제안을 하는 경우가 많습니다.
- 성격 정렬의 부재: 사용자의 성격(내향성, 신경증 등)은 여러 대화에 걸쳐 미묘하게 드러나지만, 기존 기술은 이를 동적으로 파악하고 응답 톤을 조절하는 메커니즘이 부족합니다.
따라서 본 연구는 MLLM이 사용자의 의도를 정확히 추론하고, 행동을 개인의 가치관과 정렬하며, 멀티모달 정보를 지속적으로 기억하도록 하는 장기 개인화 에이전트 프레임워크 구축을 핵심 과제로 정의합니다.
2. 제안 방법 (Method)
본 논문은 일반 목적의 MLLM을 개인화 비서로 전환하기 위한 두 단계의 협업 프로세스(Response & Update)와 고도화된 메모리 구조를 제안합니다.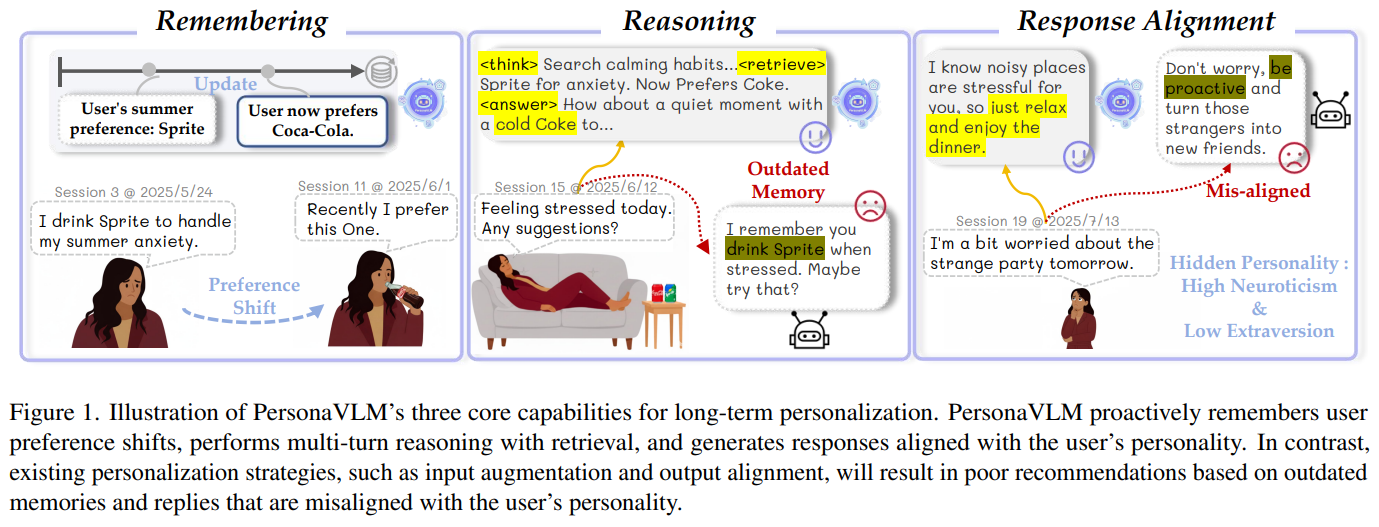
개인화 메모리 아키텍처 (Personalized Memory Architecture)
사용자의 정보는 크게 두 가지 카테고리로 저장 및 관리됩니다.
- 사용자 성격 프로필 (P): 사용자의 성격을 Big Five(OCEAN) 모델에 따라 5차원 벡터로 정량화하여 관리합니다.
- 멀티타입 메모리 데이터베이스 (M):
- Core Memory: 사용자의 이름, 나이, 직업 등 핵심 정체성 정보.
- Semantic Memory: 사실 관계, 개념, 멀티모달 시각적 개념(Visual Concepts) 등 추상적 지식.
- Episodic Memory: 대화 세션을 주제별로 구분한 타임스탬프 기반의 사건 기록.
- Procedural Memory: 사용자의 장기 목표, 반복적인 습관 및 루틴.
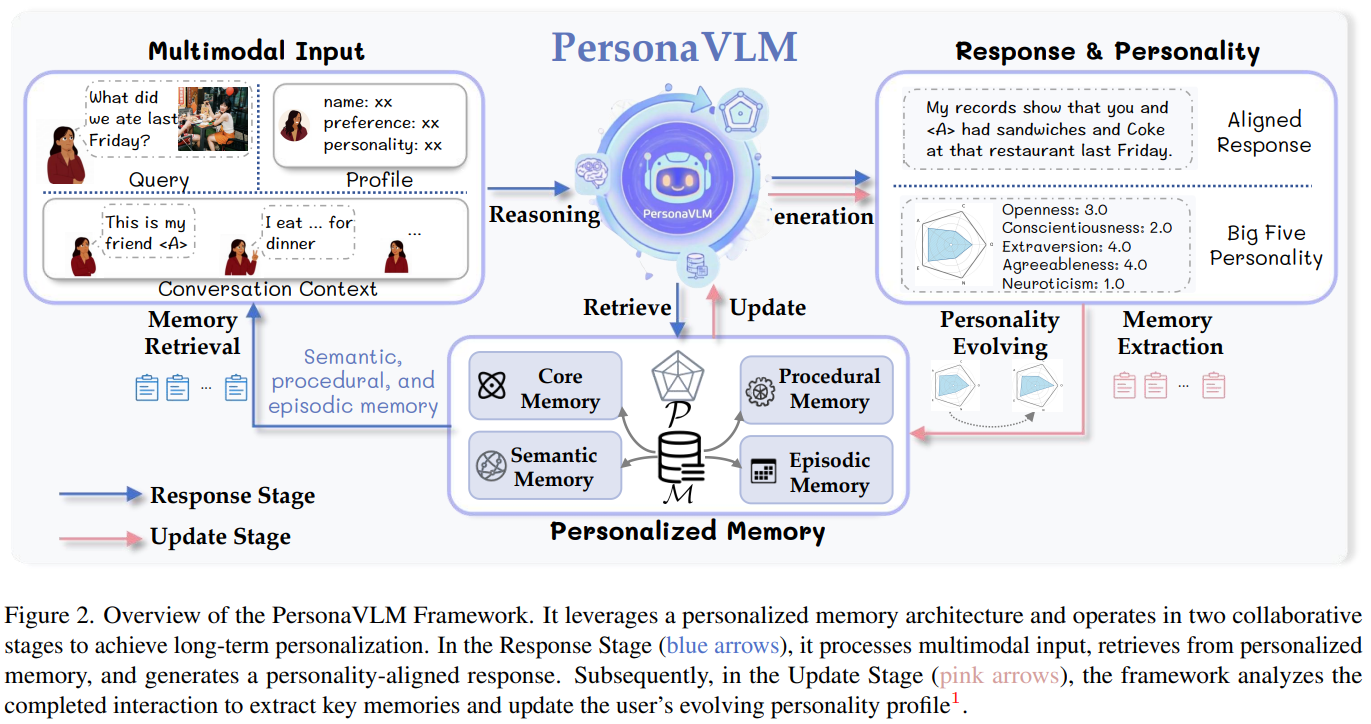
응답 단계 (Response Stage)와 추론 메커니즘
사용자의 쿼리가 입력되면 PersonaVLM은 다음과 같은 에이전트 기반 추론 루프를 실행합니다.
- 다단계 추론: 모델은 현재 쿼리와 대화 문맥을 분석하여 메모리 검색이 필요한지 스스로 결정합니다.
- 에이전트 검색: 부족한 정보가 있다면 검색 키워드와 시간 범위를 포함한 검색 쿼리를 생성합니다.
- 정렬된 생성: 검색된 메모리를 통합하여 사용자의 Big Five 성격 점수에 최적화된 톤과 내용으로 최종 응답 을 생성합니다.
업데이트 단계 (Update Stage)와 PEM
상호작용이 완료된 후, 모델은 백그라운드에서 메모리를 갱신합니다.
- 성격 진화 메커니즘 (PEM): 사용자의 최신 발화에서 성격 점수 을 추론하고, 모멘텀 기반의 지수 이동 평균(EMA)을 사용하여 장기 프로필을 업데이트합니다.여기서 는 대화 초기에는 낮게 설정하여 적응력을 높이고, 대화가 진행될수록 코사인 스케줄링을 통해 높여 안정성을 확보합니다.
- 지식 추출: 상호작용에서 핵심 정보를 추출하여 4가지 메모리 타입에 반영하며, 시각적 개념의 경우 Grounding DINO를 활용하여 이미지 크롭과 텍스트를 매핑하여 저장합니다.
학습 파이프라인 (Training Pipeline)
- Stage 1 (SFT): 500개의 고유한 페르소나를 바탕으로 합성된 3만 건 이상의 멀티모달 상호작용 데이터를 사용하여 메모리 관리 및 추론 능력을 학습시킵니다.
- Stage 2 (RL): Group Relative Policy Optimization (GRPO)를 적용하여 모델의 다단계 추론 성능을 강화합니다. 정확도, 논리적 일관성, 형식 준수 여부를 보상(Reward) 함수로 설정하여 최적화합니다.
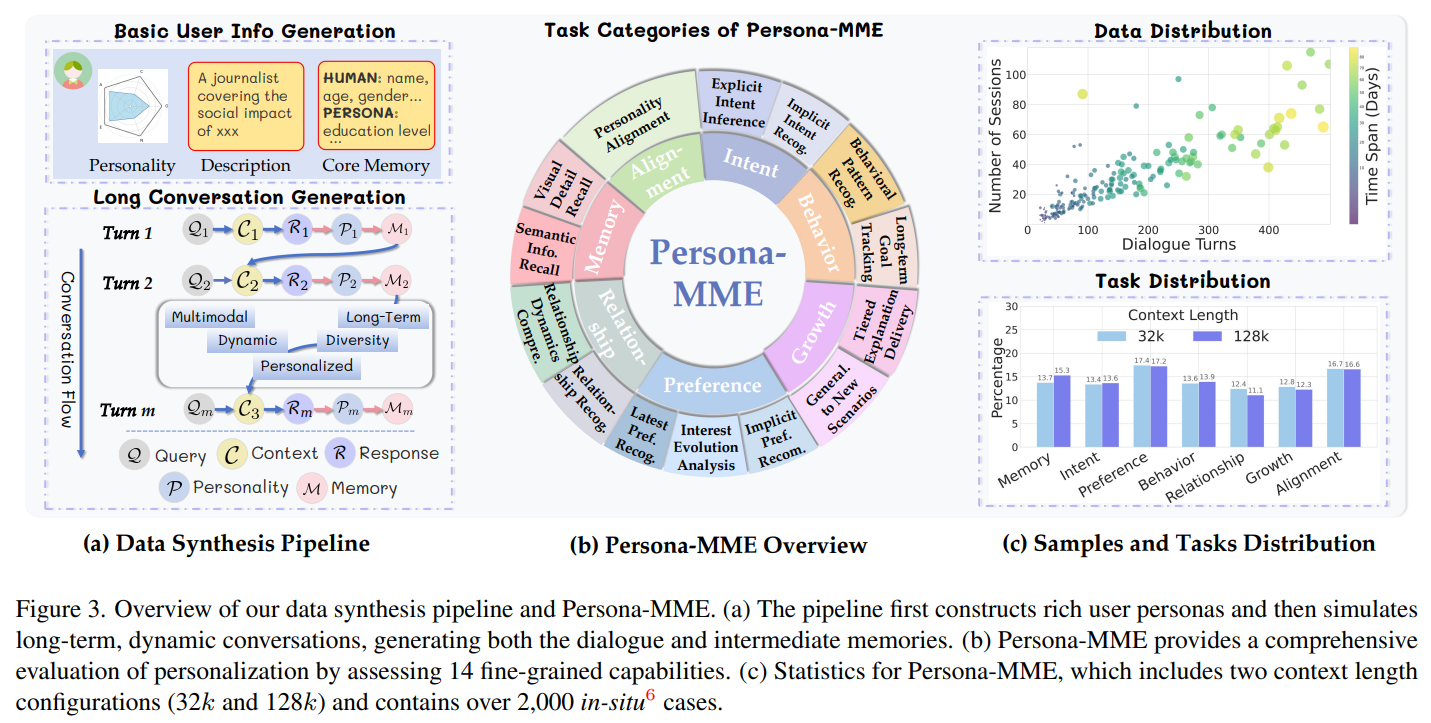
3. 실험 결과 (Experiments)
평가 환경 및 데이터셋
- Persona-MME: 본 연구에서 새로 구축한 벤치마크로, 7가지 측면(기억, 의도, 선호, 행동, 관계, 성장, 정렬)과 14개의 미세 태스크를 포함하는 2,000개 이상의 케이스로 구성됩니다.
- PERSONAMEM: 기존의 동적 사용자 프로파일링 벤치마크를 활용하여 장기 문맥(128k)에서의 성능을 측정했습니다.
주요 성능 지표
- 성능 향상: 128k 문맥 조건에서 PersonaVLM은 베이스라인 모델 대비 Persona-MME에서 22.4%, PERSONAMEM에서 9.8%의 정확도 향상을 보였습니다.
- 타 모델 비교: GPT-4o와 비교했을 때 Persona-MME에서 5.2% 더 높은 점수를 기록했으며, 특히 사용자의 행동 양식 파악 및 성장 모델링(Skill-level tailoring) 측면에서 압도적인 우위를 보였습니다.
- 정성적 평가: Gemini-2.5-Pro를 판독관(Judge)으로 사용한 개방형 응답 평가에서 PersonaVLM은 사실 정확성과 성격 정렬도 모두에서 타 모델 대비 높은 승률(Win-rate)을 기록했습니다.

4. 한계점 및 시사점
한계점
- 연산 및 지연 시간: 다단계 추론 및 메모리 검색 과정을 포함하므로, 베이스라인 모델 대비 응답 지연 시간(Latency)이 약 21% 증가하는 엔지니어링적 비용이 발생합니다.
- 모달리티 확장성: 현재는 텍스트와 이미지 중심의 개인화에 집중되어 있으며, 비디오나 오디오 신호를 통한 실시간 인물 추적 및 감정 분석까지는 확장되지 않았습니다.
- 기억의 통합: 타임라인 기반 검색에는 능숙하지만, 서로 다른 시점에 발생한 유사한 에피소드를 논리적으로 병합하거나 모순을 해결하는 고도화된 메모리 정제 기능이 보완되어야 합니다.
시사점 및 학술적 의의
PersonaVLM은 MLLM을 단순한 도구에서 사용자와 함께 성장하는 '장기 동반자'로 진화시켰다는 점에서 의의가 큽니다. 특히 상호작용을 통해 성격 벡터를 동적으로 보정하는 PEM과 로컬 환경에서도 작동 가능한 메모리 아키텍처는 데이터 프라이버시 보호와 고도의 개인화가 동시에 요구되는 의료, 교육, 추천 시스템 분야에 중요한 기술적 토대를 제공합니다.
