1. 논문 정보
- 제목: MMAD: Multi-modal Movie Audio Description
- 저자: Xiaojun Ye, Junhao Chen, Xiang Li, Haidong Xin, Chao Li, Sheng Zhou, Jiajun Bu
- 학회: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)
- 분야: Multimodal Learning, Video Understanding, Accessibility/Audio Description
- 문제 정의: 영화 영상에서 시각 장애인을 위한 Audio Description (AD)을 자동 생성하는 문제
2. 한 줄 요약
MMAD는 영화 영상의 핵심 장면과 맥락을 포착하기 위해 영상, 음향, 자막, 캐릭터 정보를 결합한 멀티모달 파이프라인을 구성하고, LLaMA2 기반 언어 모델을 이용해 풍부하고 맥락적인 Movie Audio Description을 자동 생성하는 모델이다.
3. 연구 동기
기존의 자동 Audio Description 생성 방법들은 다음과 같은 한계가 있다:
- 수동 작업에 크게 의존하여 비용이 높고 확장성이 떨어짐
- 이미지/비디오 단일 모달만을 사용하여 문맥적으로 풍부한 설명을 충분히 생성하지 못함
- 캐릭터 중심의 플롯 묘사나 배경음 정보 등 맥락을 포괄하는 설명이 부족함
MMAD는 이러한 문제를 해결하기 위해 멀티모달 정보(영상 + 음향 + 자막 + 캐릭터)를 통합하는 구조를 제안한다.
4. 전체 아키텍처 및 핵심 구성
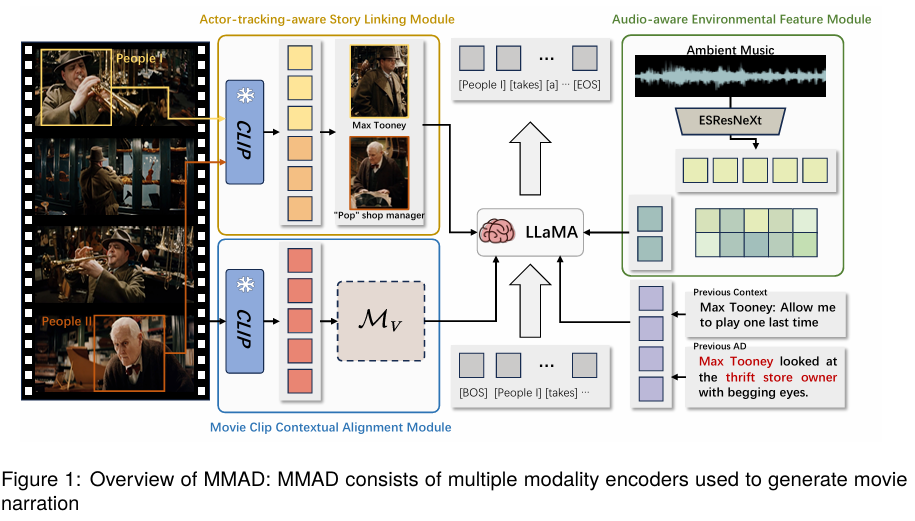
MMAD의 파이프라인은 크게 세 가지 모듈로 이루어진다
4.1. Audio-aware Feature Enhancing Module
- 영상에서 음향(ambient audio) 특징을 추출하여 배경장면의 분위기·환경을 설명에 추가
- 음향은 비주얼만으로는 파악하기 어려운 장면 정보를 제공하여 AD의 풍부함을 증가
- Ambient Audio Encoder + Modality Alignment Module로 구성
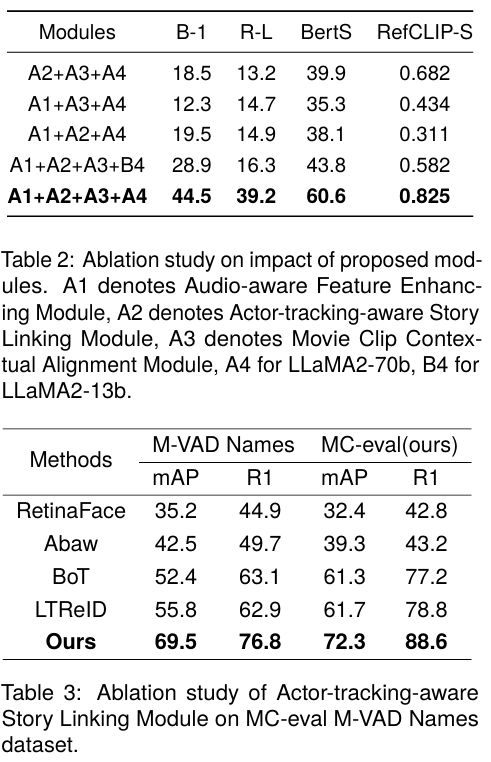
4.2. Actor-tracking-aware Story Linking Module
- 영화 장면에서 활성 캐릭터를 트래킹하고
- 대명사(he/she) 대신 실제 캐릭터 이름을 서술하도록 설계함
- 캐릭터 프로필/이미지와 영화 프레임을 매칭하여 스토리 연결성과 사람 중심 묘사를 강화
이 모듈은 기존 AD가 놓치기 쉬운 캐릭터 중심 맥락을 촘촘하게 설명에 담는 역할을 한다.
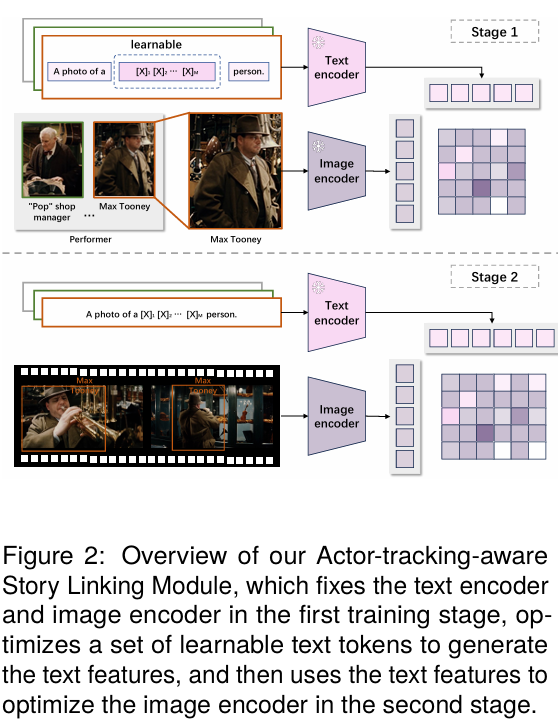
4.3. Subtitled Movie Clip Contextual Alignment Module
- 영화 내 자막 정보를 활용하여 대사/비대사 구간을 구분
- 영화 전체 맥락을 고려하여 문맥적 연속성을 AD에 반영
- WhisperX 등 음성-자막 도구를 도입하여 자막/대사 구간을 정확히 분리하고 contextual description 생성
이 모듈 덕분에 단순 프레임 묘사뿐 아니라 영화 플롯 전체를 이해하는 설명 생성이 가능해진다.

4.4. LLaMA2 기반 통합 생성
- 세 모듈을 통해 얻은 영상/음향/자막/캐릭터 특징은 LLaMA2 기반 언어 모델 입력으로 매핑됨
- 이는 잠재적으로 multimodal prompt 형식으로 구성되어 모델이 자연스럽고 플롯 일관성이 있는 설명을 생성하게 함
5. 주요 기여
(1) 멀티모달 통합 파이프라인
MMAD는 영상뿐 아니라 음향과 자막, 캐릭터 정체성 추적 정보를 통합하여 영화 AD를 생성하는 구조를 제안한다.
(2) 캐릭터 중심 설명 강화
Actor-tracking-aware 모듈 덕분에,
단순 객체·장면 묘사뿐 아니라 플롯상의 등장인물 중심 서술이 가능하다.
(3) 문맥적 일관성 유지
Dialogue segment와 non-dialogue segment를 분리해 context alignment를 구현함으로써
단편적 설명이 아니라 영화 전체 플롯의 연속성을 살리는 설명을 만든다.
6. 실험 및 평가
- 다양한 기존 AD 벤치마크 데이터셋을 실험에 활용
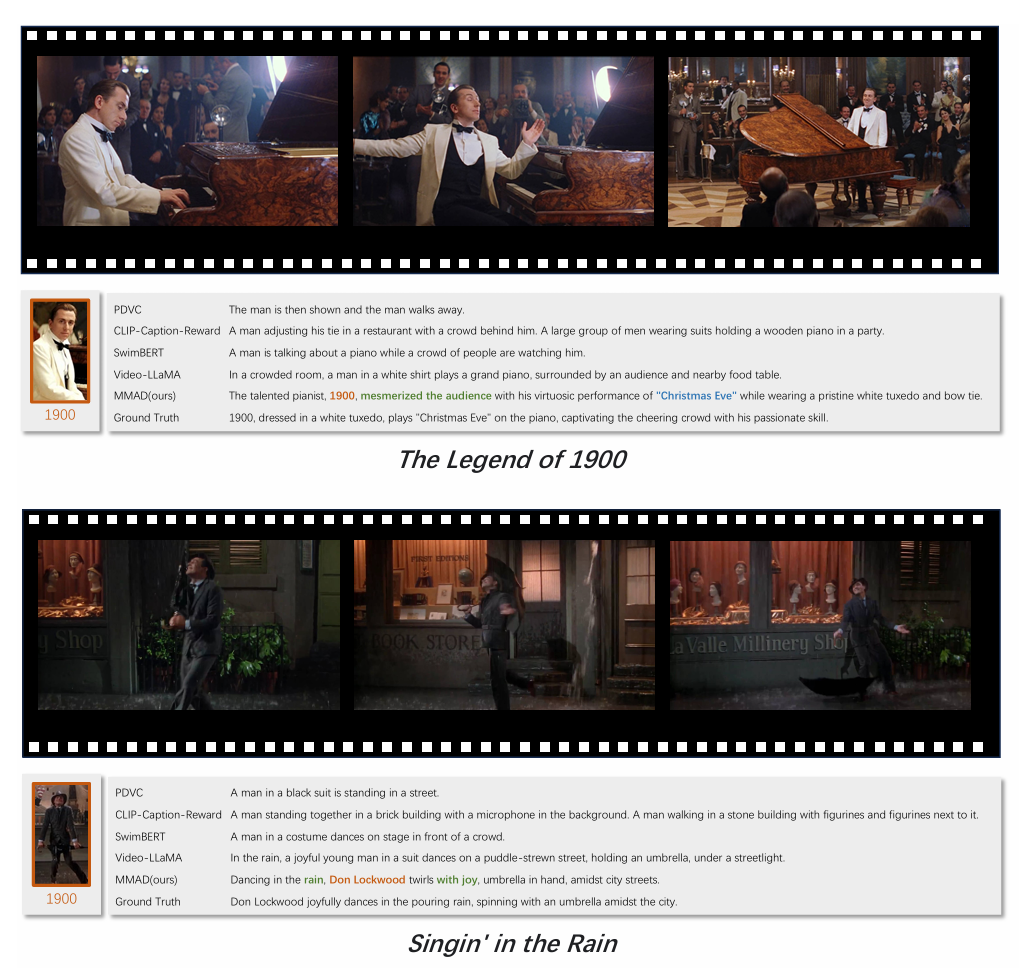
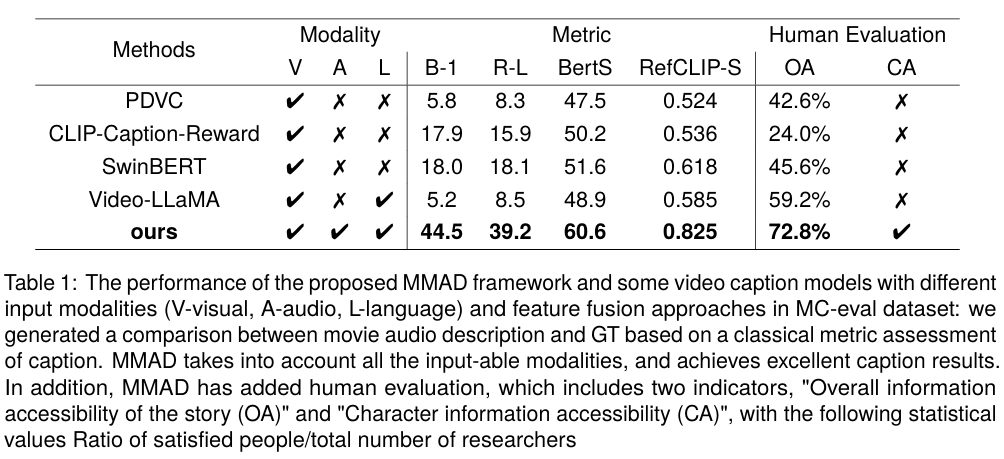
- MMAD는 기존 AD 생성 방법을 상당한 성능 차이로 능가하며 최첨단 결과를 보임
정량적/정성적 평가를 통해 MMAD가 context preservation 및 캐릭터 중심 서술 성능을 높였음을 보인다.

7. 장점 및 한계
📌 장점
- 배경음, 캐릭터, 자막 등 다양한 modal 정보를 종합적으로 활용
- 플롯·맥락을 살리는 설명 생성
- LLaMA2와 같은 LLM을 외부 생성기로 활용한 실용적 구조
⚠ 한계
- LLM 기반 생성은 prompt 설계나 텍스트 질 관리가 중요
- 자막/대사 구간 분리의 정확도에 따라 AD 품질이 변동 가능
- 대규모 영화 전체를 처리하는 데 연산 비용/메모리 부담 존재
8. 한 문장 요약
MMAD는 영화 영상, 음향, 자막, 캐릭터 트래킹을 통합하여 context-aware Movie Audio Description을 생성하는 멀티모달 파이프라인으로, 기존 자동 AD 방법 대비 플롯 일관성·캐릭터 중심 묘사 성능을 크게 향상시킨다.
