0. 3줄 요약
- 본 논문은 강화학습(RLVR) 기반의 언어 모델 튜닝에서, 현재 정책보다 조금 앞선 '가까운 미래(Near-Future)' 체크포인트가 생성한 정답 궤적을 활용하여 학습을 최적화하는 NPO(Near-Future Policy Optimization)를 제안한다.
- 외부 교사 모델이나 과거 모델을 활용하는 기존 방식들의 한계인 궤적 품질(Quality)과 기울기 분산(Variance) 간의 상충 관계를 수학적 유효 학습 신호 지표인 를 통해 분석하고, 최적의 탐색-활용 균형을 달성하는 파이프라인을 구축했다.
- Qwen3-VL-8B 모델에 적용한 결과, 초기 학습의 수렴 속도를 2.1배 가속화함과 동시에 후반부 성능 정체를 돌파하여 멀티모달 수학 추론 벤치마크에서 최고 성능을 기록하는 학술적 의의를 보여주었다.
1. 배경 및 문제 정의
강화학습을 통한 언어 모델의 사후 학습, 특히 명확한 검증 보상을 활용하는 RLVR(Reinforcement Learning with Verifiable Rewards)은 모델의 추론 능력을 극대화하는 핵심 기법으로 자리 잡았다. 그러나 순수 온폴리시(On-policy) 기반의 RLVR, 예를 들어 GRPO 등은 구조적으로 두 가지 한계에 직면한다. 첫째, 학습 초기에는 모델이 정답 궤적을 스스로 생성할 확률이 낮아 보상 신호가 희소(Sparse)하다. 둘째, 학습 후반부에는 궤적 분포가 좁아져 새로운 해결책을 탐색하지 못하고 특정 성능에서 정체(Plateau)되는 현상이 발생한다.
이를 극복하기 위해 오프폴리시(Off-policy) 궤적을 혼합하는 방법들이 연구되었다. 하지만 기존 방법론들은 심각한 딜레마를 안고 있다. 외부 교사 모델(External Teacher)이나 완전히 학습이 끝난 모델(Far-future)의 궤적은 품질()은 높지만, 현재 모델과의 파라미터 및 분포 차이가 커서 막대한 기울기 분산()을 유발해 학습을 불안정하게 만든다. 반대로 과거 학습 궤적(Experience Replay)을 재사용하는 경우, 분산은 적으나 품질 자체가 낮아 모델에게 새로운 지식을 제공하지 못한다.
결과적으로, 이 논문은 유효 학습 신호(Effective Learning Signal)를 로 정의하고, 너무 멀지도 가깝지도 않아 값을 극대화할 수 있는 '이상적인 궤적 공급원'을 설계해야 한다는 핵심 문제를 정의 및 해결하고자 한다.
2. 제안 방법 (Method)
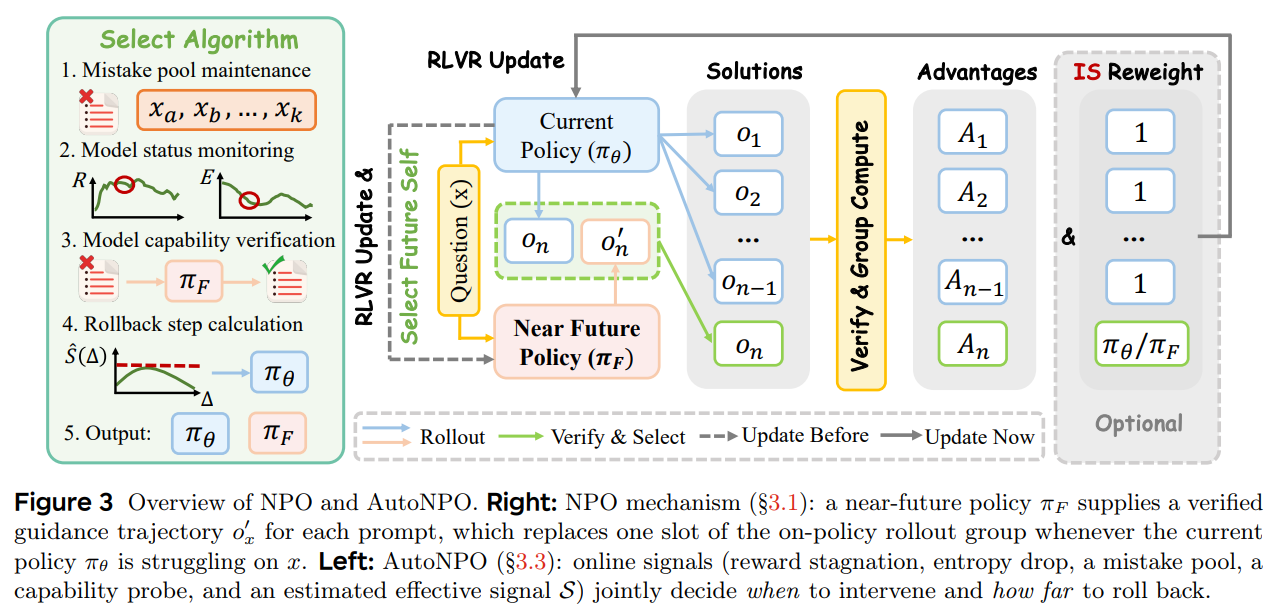
NPO의 핵심 아이디어는 외부의 강력한 모델에 의존하는 대신, 자기 자신의 최적화 경로상에 있는 '가까운 미래( 스텝 이후)'의 체크포인트를 활용하는 것이다. 가까운 미래의 모델은 현재보다 더 많이 학습되었으므로 품질()이 높으면서도, 파라미터 이동 거리가 짧아 기울기 분산()이 적다는 구조적 이점을 취한다.
입력 데이터 전처리 및 궤적 획득 (Data Representation)
NPO는 훈련 과정을 잠시 멈추고 스텝만큼 탐색 학습(Scout run)을 진행하여 미래 정책 를 확보한다. 이후 를 이용해 오프라인 환경에서 훈련 프롬프트 들에 대해 응답을 롤아웃(Rollout)하고 검증기를 통과시킨다. 이때 검증을 통과한 '정답 궤적' 중 하나를 가이던스 궤적 로 선택하여 캐싱(Caching)한다. 미래 정책조차 정답을 내지 못한 프롬프트는 제외된다. 이렇게 생성된 캐시 데이터는 NPO가 적용되는 세그먼트 구간 동안 재사용되어 추가적인 추론 비용을 방지한다.
학습 및 추론 파이프라인 구조 (Pipeline Engineering)
학습(Training) 단계에서 NPO는 원본 RLVR(GRPO)의 구조를 최대한 보존하면서 데이터를 주입한다.
- 스텝 에서 현재 정책 는 개의 궤적 를 온폴리시로 샘플링한다.
- 해당 그룹의 정답률 를 계산한다.
- 인 경우, 즉 현재 모델이 해당 프롬프트를 어려워하는 경우에만 개입한다. 생성된 개의 궤적 중 마지막 슬롯(번째)을 캐싱해둔 미래 궤적 로 강제 교체한다.
- 교체된 그룹 에 대해 평균과 표준편차를 구하여 Advantage 를 산출하고, GRPO와 동일한 클리핑(Clipping) 목적 함수 를 통해 정책을 업데이트한다.
추론(Inference) 단계에서는 어떠한 아키텍처나 파이프라인의 수정도 요구되지 않는다. 학습이 완료된 후 표준적인 자동 회귀(Auto-regressive) 디코딩을 그대로 수행한다.
AutoNPO: 적응형 동적 스케줄링
수동으로 특정 시점에 개입하는 것을 넘어, 논문은 AutoNPO라는 확장 모델을 제안한다. AutoNPO는 온라인 훈련 중 보상의 정체나 엔트로피의 감소와 같은 훈련 신호를 지속적으로 모니터링한다. 개입이 필요하다고 판단되면, 경험적 추정을 통해 유효 학습 신호 를 극대화하는 최적의 거리 를 계산하고 자동으로 미래 궤적을 주입한다.
3. 실험 결과 (Experiments)
실험은 다중 모달 능력을 갖춘 Qwen3-VL-8B-Instruct 모델을 기반으로 진행되었으며, RL 알고리즘으로는 GRPO가 사용되었다. 성능 평가는 고난도 수학 추론 벤치마크인 MMMU-Pro, MathVista, MathVision, WeMath를 대상으로 하였다.
- 핵심 성능 결과: 기존 순수 GRPO 베이스라인이 평균 57.88%의 성능을 기록한 반면, NPO를 적용했을 때 평균 62.84%로 대폭 상승했다. 자동화된 AutoNPO를 적용한 경우 63.15%의 최고 성능을 달성하여, 외부 교사 모델이나 과거 경험 리플레이를 사용한 기존 최상위 방법론들을 모두 능가했다.
- 초기 가속과 후반부 돌파: 학습 동인(Dynamics) 측면에서 두 가지 명확한 성과가 관찰되었다. 초기 개입(Early Intervention)을 적용했을 때는 순수 GRPO 대비 훈련 수렴 속도가 약 2.1배 가속화되었다. 후반부 개입(Late Intervention)을 적용했을 때는 기존 온폴리시 모델이 도달한 후 더 이상 성장하지 못하는 한계점(Plateau)을 부수고 성능 천장을 높이는 데 성공했다.
- 어블레이션 해석: 거리 에 따른 와 의 변화를 분석한 결과, 가 너무 크면 분산이 지수적으로 폭발하고, 너무 작으면 품질 이득이 적음을 실증했다. 특정 중간 구간(예: )에서 가 명확한 극댓값을 형성하여 최적의 탐색-활용 균형이 이루어짐을 입증했다.
4. 한계점 및 시사점
한계점 및 제약 조건
본 방법론은 미래의 체크포인트를 확보하기 위해 스텝만큼의 사전 훈련(Scout run)을 선행해야 하므로, 이 과정에서 일시적인 컴퓨팅 오버헤드가 발생한다는 구조적 한계가 있다. 또한, NPO의 메커니즘은 정답의 유무를 명확히 판별할 수 있는 검증 가능 보상(Verifiable Reward)이 존재하는 환경(수학, 코딩 등)을 전제로 설계되었기 때문에, 개방형 대화나 창의적 글쓰기와 같은 모호한 태스크에 직접 적용하기 위해서는 추가적인 보상 모델(Reward Model) 설계가 요구된다.
향후 연구 방향 및 시사점
그럼에도 불구하고 NPO는 강화학습 과정에서 발생하는 탐색 부족 문제를 '미래의 자아(Near-future self)'를 통해 해결했다는 점에서 매우 혁신적이다. 오프폴리시 데이터 활용의 본질적인 문제인 품질-분산 트레이드오프(Quality-Variance Trade-off)를 수학적으로 정립하고, 외부 데이터 의존성 없이 자체 학습 사이클 내에서 모델 스스로의 한계를 극복하는 방법을 제시했다. 이는 향후 LLM 자기 주도적 정렬(Self-alignment) 및 진화형 훈련 파이프라인 설계에 핵심적인 이론 및 엔지니어링적 토대를 제공할 것이다.
