1. 배경 및 문제 정의
로봇 학습 분야의 오랜 숙제는 일반화(Generalization)입니다. 기존의 로봇 제어 모델들은 특정 환경과 사물에 국한된 데이터를 학습하여, 훈련 데이터에 없는 새로운 사물이나 명령어를 접했을 때 대응 능력이 현저히 떨어졌습니다.
- 기존 방법론: 주로 ImageNet과 같은 시각 데이터로 인코더를 사전 학습(Pre-training)하거나, 로봇의 작업 궤적(Trajectory) 데이터만을 사용하여 행동 복제(Behavior Cloning)를 수행했습니다.
- 한계점: 로봇 데이터는 인터넷 규모의 텍스트나 이미지 데이터에 비해 그 양이 압도적으로 부족합니다. 따라서 기존 모델은 "바나나를 집어라"는 수행할 수 있어도, "가장 건강한 간식을 집어라"와 같은 고수준의 추론이나 "공룡 인형 옆에 놓아라"와 같은 상징적 이해가 불필요한 상황에서는 작동하지 않았습니다.
- 핵심 문제: 인터넷의 방대한 지식(Web-scale knowledge)을 어떻게 로봇의 저수준 제어(Low-level control) 시스템에 직접 주입하여 추상적 사고와 물리적 행동을 결합할 것인가가 본 연구의 핵심 과제입니다.
2. 제안 방법 (Method)
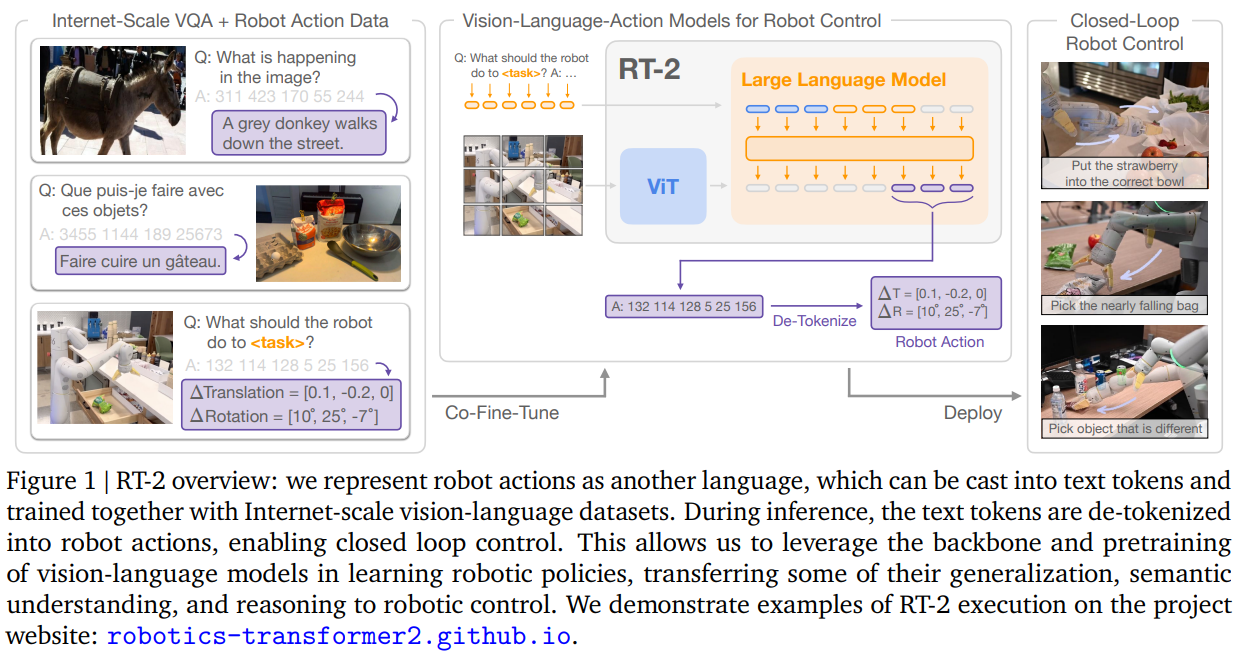
RT-2는 시각-언어 모델(VLM)을 시각-언어-행동 모델(VLA, Vision-Language-Action)로 확장하는 단순하면서도 강력한 아키텍처를 제안합니다.
데이터 표현 및 토큰화 (Action as Text)
RT-2의 핵심은 로봇의 동작을 별도의 수치 벡터가 아닌 텍스트 토큰으로 취급하는 것입니다. 이를 통해, 인터넷의 방대한 언어 지식과 로봇의 물리적 행동을 동일한 형식으로 통합하여, 별도의 구조 변경 없이도 고차원적인 추론 능력을 제어 시스템에 직접 전이시킬 수 있습니다. 즉, 이미지와 텍스트와 행동을 하나의 임베딩 차원 공간에 둘 수 있게 됩니다.
로봇의 행동 는 다음과 같이 8차원의 이산화된 상태로 정의됩니다.
각 연속적인 값은 256개의 빈(bin)으로 균등 이산화됩니다. 모델은 이 숫자들을 일반적인 텍스트 토큰(예: PaLI-X의 경우 숫자 1~256에 해당하는 토큰)으로 처리합니다. 결과적으로 모델은 "질문: 로봇이 무엇을 해야 하나요? 답변: 1 128 91..."과 같은 형태의 멀티모달 문장을 생성하게 됩니다.
네트워크 구조의 엔지니어링 디테일
본 연구는 PaLI-X와 PaLM-E라는 거대 모델을 백본으로 사용합니다.
- 비전 인코더: ViT-22B 등을 사용하여 입력 이미지를 고차원 패치 토큰으로 변환합니다.
- 언어-행동 디코더: 텍스트 명령과 비전 토큰을 입력받아 다음 토큰(행동 토큰)을 예측하는 Transformer 구조입니다. 최대 55B(550억 개) 파라미터 규모를 가집니다.
학습 및 추론 파이프라인
- Co-Fine-tuning (학습): 로봇 데이터만 학습할 경우 발생하는 "파괴적 망각(Catastrophic Forgetting)"을 방지하기 위해, 원본 웹 데이터(VQA, 캡셔닝 등)와 로봇 궤적 데이터를 혼합하여 파인튜닝합니다.
(*파괴적 망각: 모델이 새로운 정보를 학습할 때, 기존에 배워두었던 지식을 순식간에 잊어버리는 현상, =가중치 덮어쓰기)
(**VQA: 이미지의 시각적 정보와 자연어 질문을 결합하여, 사진 속 상황이나 사물에 대해 AI가 답변하는 기술) - Output Constraint (추론): 추론 시 모델이 엉뚱한 텍스트를 내뱉지 않도록, 로봇 제어 모드에서는 행동 토큰 범위 내에서만 샘플링되도록 디코딩 과정을 제한합니다.
- Real-Time Inference: 55B 규모의 모델을 실시간 제어(1~5Hz)하기 위해, 멀티 TPU 클라우드 서비스 기반의 추론 파이프라인을 구축하여 네트워크를 통해 로봇에 명령을 전달합니다.
3. 실험 결과 (Experiments)
실험은 7자유도 로봇 팔을 이용해 6,000회 이상의 테스트를 거쳤으며, 기존 모델(RT-1, VC-1 등)과 비교되었습니다.
주요 성능 지표
- 일반화 성능 (Unseen Scenarios): 훈련 데이터에 없던 새로운 물체, 배경, 환경에서의 성공률이 기존 모델(RT-1) 대비 약 3배(32% -> 62%) 높게 나타났습니다.
- 창발적 능력 (Emergent Capabilities): * 상징 이해: "X 표시 옆으로 이동해라"와 같은 명령 수행 가능.
- 추론 및 연산: "2+1의 결과값에 해당하는 숫자로 물체를 옮겨라"와 같은 산술 추론 가능.
- 언어 이해: 스페인어나 독일어 등 다국어 명령 수행 가능.
어블레이션 스터디 (Ablation Study)
모델의 크기가 커질수록(), 그리고 단순히 파인튜닝하는 것보다 웹 데이터와 함께 Co-fine-tuning했을 때 일반화 능력이 극대화됨을 확인했습니다. 이는 거대 모델의 "세상에 대한 지식"이 로봇의 제어 능력으로 전이(Transfer)되었음을 시사합니다.
4. 한계점 및 시사점
기술적 한계
- 새로운 물리적 기술의 부재: RT-2는 웹 지식을 통해 "어떤 물체를 집을지"는 더 잘 판단하지만, 로봇 데이터에 없던 "수건 접기"나 "닦기" 같은 새로운 물리적 동작 자체를 창조하지는 못합니다.
- 연산 비용: 55B 파라미터 모델을 실시간으로 돌리기 위해서는 막대한 컴퓨팅 자원이 필요하며, 이는 온디바이스(On-device) 제어의 제약 요소가 됩니다.
연구의 시사점
RT-2는 로봇 학습을 더 이상 폐쇄적인 데이터셋의 문제가 아니라, 거대 언어 모델의 발전과 직접적으로 동기화되는 분야로 확장시켰습니다. 특히 Chain-of-Thought(사고의 사슬) 기법을 로봇에 적용하여, "배가 고프다"는 사용자 명령에 "에너지바를 집는다"는 계획을 세우고 행동으로 옮기는 단일 모델 기반의 인공지능 가능성을 보여주었습니다. 이는 미래의 범용 서비스 로봇 구현을 위한 중요한 이정표가 될 것입니다.
