논문의 핵심 문제 설정
기존 Multimodal LLM(MLLM)은 이미지 전체를 한 번 인코딩한 뒤 그 토큰을 LLM에 넣어 추론합니다:
이 구조는 다음 한계를 가집니다:
- 고해상도 이미지가 다운샘플링됨
- 세부 객체를 찾는 능동적 탐색이 없음
- 정보가 부족해도 재탐색 불가
- “어디를 봐야 하는지” 결정 불가
논문은 이를 다음처럼 재정의합니다:
멀티모달 추론 = 언어 추론 + 능동적 시각 검색
이 검색 메커니즘이 V*이며, 이를 통합한 전체 구조가 SEAL입니다.
SEAL 아키텍처 (Show, SEArch, and TelL)
입력은 질문 와 이미지 입니다.
- VQA LLM이 low-resolution vision token으로 초기 답을 시도
- 정보가 부족하면 LLM이 검색 대상 설명을 생성
- 각 에 대해 V*가 위치를 탐색
- 해당 bounding box 영역을 원본 고해상도 이미지에서 crop
- crop된 영역을 다시 Vision Encoder에 통과시켜 고해상도 visual token 추출
- 다음 항목을 Visual Working Memory(VWM)에 저장
- VQA LLM이 VWM을 추가 입력으로 받아 재추론
- 최종 답 생성
전체 흐름:
이는 단일 패스가 아닌 iterative reasoning loop입니다.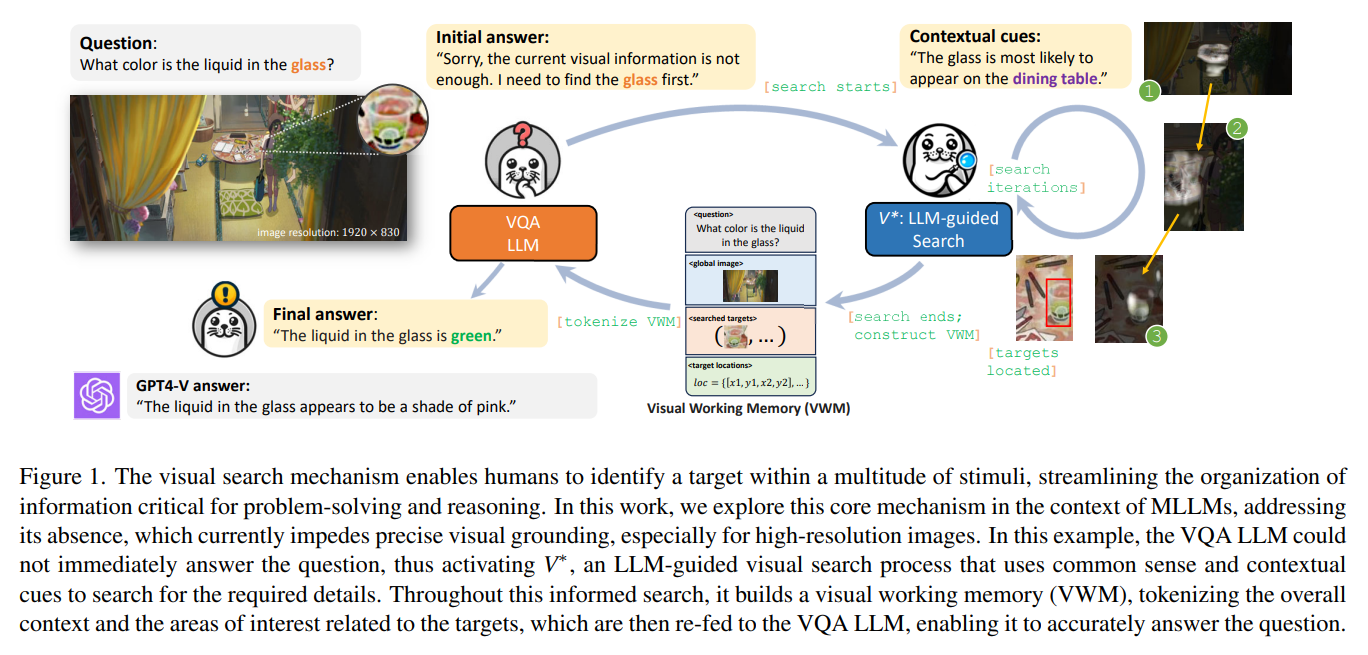
VQA LLM의 구성과 역할
SEAL의 LLM은 vision encoder와 연결된 multimodal VQA LLM입니다.
최종 입력 구성은 다음과 같습니다:
즉,
LLM 내부에서는 cross-attention을 통해:
- 텍스트 ↔ 전역 이미지
- 텍스트 ↔ 고해상도 patch
- patch ↔ patch
간 상호작용이 발생합니다.
LLM은 두 가지 기능을 수행합니다:
- Answer generation
- Search query generation
즉 reasoning module이자 search planner 역할을 합니다.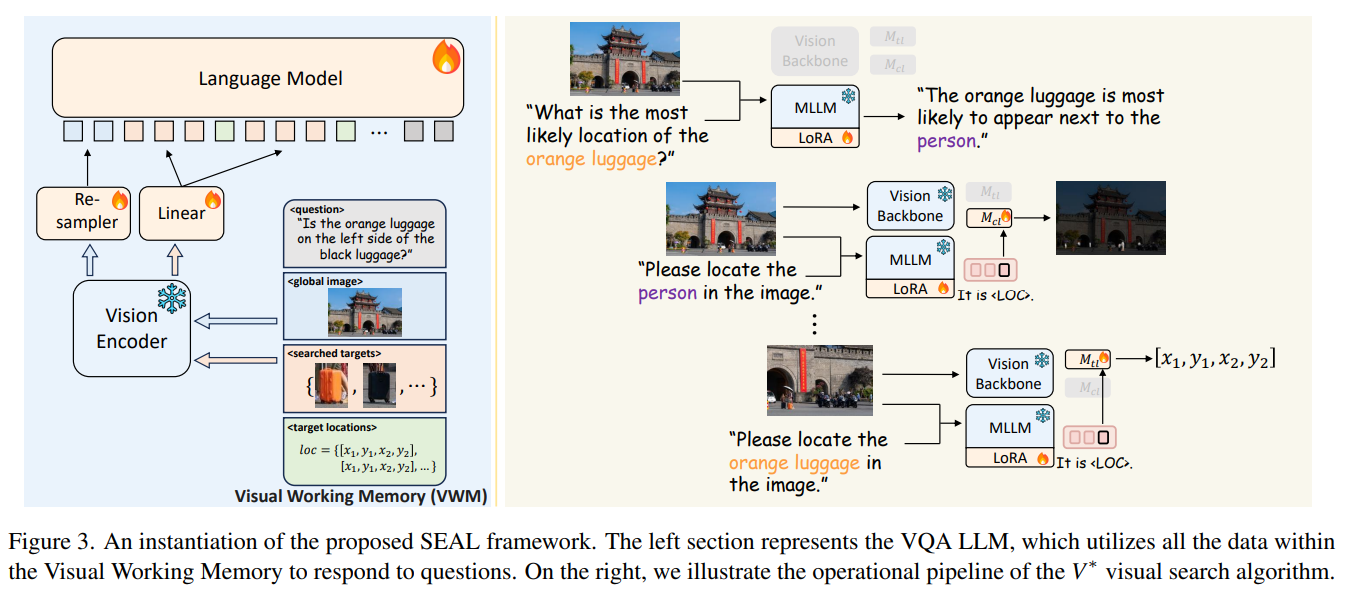
V* 알고리즘의 핵심 원리
V*는 시각 검색을 A*-like heuristic 탐색 문제로 정의합니다.
각 탐색 노드 에 대해:
- : 탐색 비용
- : search cue 기반 heuristic
Localization decoder는 다음을 예측합니다:
Heuristic 정의:
종료 조건:
또는 최대 depth 도달.
언어 임베딩이 decoder 내부에서 시각 feature와 결합되어 탐색 방향을 결정합니다.

Localization Decoder 구조
Localization decoder는 language-conditioned region predictor입니다.
입력:
- Image feature map
- Text embedding
- 질문 context embedding
구조:
이후 FFN을 통해 box regression 및 confidence prediction 수행.
출력:
Heatmap은 intermediate feature에서 생성되며 supervision을 받아 학습됩니다.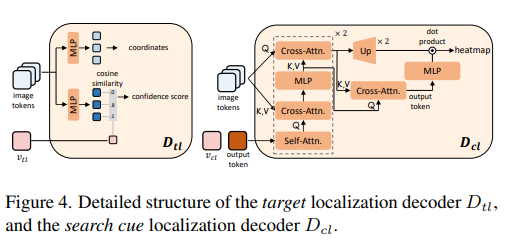
Loss 함수
전체 손실:
- Bounding box regression loss
- Confidence loss
- Heatmap supervision loss
Grounding/REC 계열 데이터셋 기반으로 학습됩니다.
Visual Working Memory 구성 과정
VWM은 단순 이미지 저장이 아니라, 다음 과정을 거쳐 구성됩니다.
-
Target text 저장
-
Bounding box 저장
-
고해상도 patch 추출:
-
Vision Encoder 재통과:
-
LLM 차원으로 projection:
-
Confidence score 저장:
최종 VWM 항목:
최종 LLM 재추론 입력
이를 통해 전역 정보와 국소 고해상도 정보를 동시에 활용한 정밀 추론이 가능합니다.
V*Bench
고해상도 세부 객체 기반 질문 평가용 벤치마크.
특징:
- fine-grained grounding 질문
- 작은 객체 및 텍스트 객체 포함
- 단순 VQA로 해결 어려움
SEAL + V*는 기존 MLLM 대비 높은 성능을 보입니다.
Ablation 결과
- VWM 제거 → 성능 크게 감소
- cue heatmap 제거 → 탐색 비효율
- context cue 제거 → localization 정확도 감소
- recursive depth 감소 → 성능 하락
Heuristic 기반 guided search와 고해상도 memory 저장이 핵심 기여 요소입니다.
계산 비용과 한계
- 반복적 patch 재인코딩으로 latency 증가
- localization 모델 성능 의존
- occlusion에 취약
- video/long document 확장 미검증
- search 단계는 fully differentiable하지 않음
- LLM과 search 모듈은 완전 end-to-end joint training 구조는 아님
한 문장 요약
이 논문은 멀티모달 LLM을
“이미지를 한 번 보고 답하는 모델”에서
“언어가 탐색을 지시하고, localization decoder가 영역을 찾고, 고해상도 재인코딩 결과를 VWM에 저장한 뒤 재추론하는 모델”로 전환시켰다는 점이 핵심입니다.
프롬프트 모음





