1. 논문 정보
- 제목: Qianfan-VL: Domain-Enhanced Universal Vision-Language Models
- 저자: Daxiang Dong 외 다수 (Baidu AI Cloud / Qianfan 팀)
- 제출: 2025년 9월 (arXiv preprint)
- 분야: Vision-Language Models, Multimodal AI, Domain-Specialized Pre-training
- 목표: 일반 멀티모달 능력과 도메인 특화 능력을 함께 갖춘 범용 비전-언어 모델 시리즈를 제안
2. 한 줄 요약
Qianfan-VL은 3B ~ 70B 매개변수 규모의 비전-언어 모델 시리즈로,
단계적(Progressive) 훈련과 정밀 데이터 합성 전략을 통해
일반 멀티모달 능력과 문서/OCR/추론 같은 분야적 전문 능력을 동시에 확보한 범용 모델이다.
3. 전체 아키텍처 개요
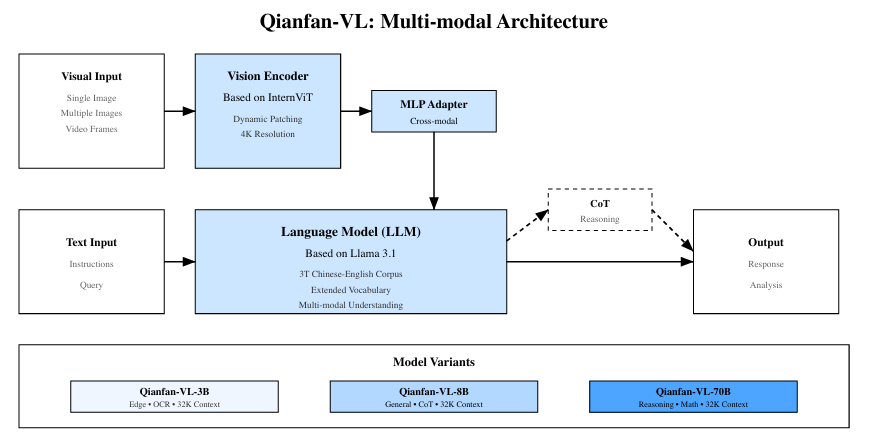
Qianfan-VL은 modular한 설계를 바탕으로, 세 가지 주요 컴포넌트로 구성된다:
3.1 Vision Encoder
-
InternViT 기반의 비전 인코더를 채택.
-
Dynamic Tiling 지원으로 최대 4K 해상도 이미지 처리 가능.
- 이미지 전체를 작은 타일로 분할해 개별 처리하고 전역 맥락을 통합해 고해상도 입력을 효율적으로 다룸.

- 이미지 전체를 작은 타일로 분할해 개별 처리하고 전역 맥락을 통합해 고해상도 입력을 효율적으로 다룸.
3.2 Language Backbone
-
모델 크기에 따라:
- 3B 모델: Qwen2.5-3B 기반
- 8B/70B 모델: Llama 3.1 기반
-
다국어 처리를 위해 확장된 어휘/멀티링구얼 사전 훈련 포함
이 LLM들은 멀티모달 지식을 언어 생성/추론에 활용할 수 있도록 설계됨.
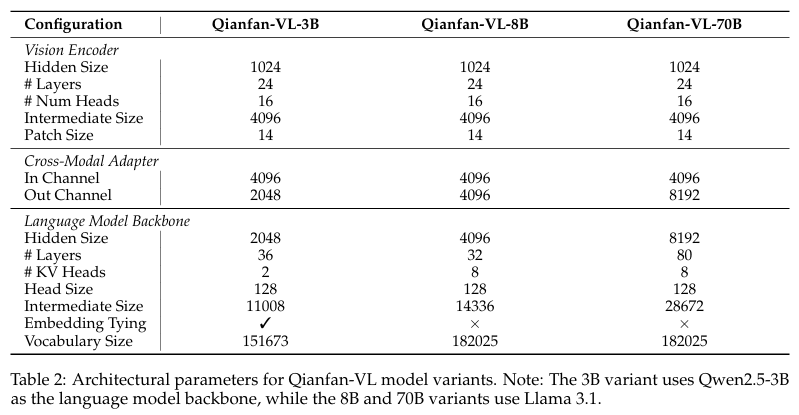
3.3 Cross-modal Adapter
- 2-레이어 MLP 어댑터를 사용해 비전 표현을 LLM 임베딩 공간으로 매핑.
- 시각 특성과 텍스트 정보를 적절히 정렬하는 역할을 수행
이 어댑터는 LLM과 Vision Encoder 간 정보를 잇는 핵심 인터페이스임.
4. 훈련 전략
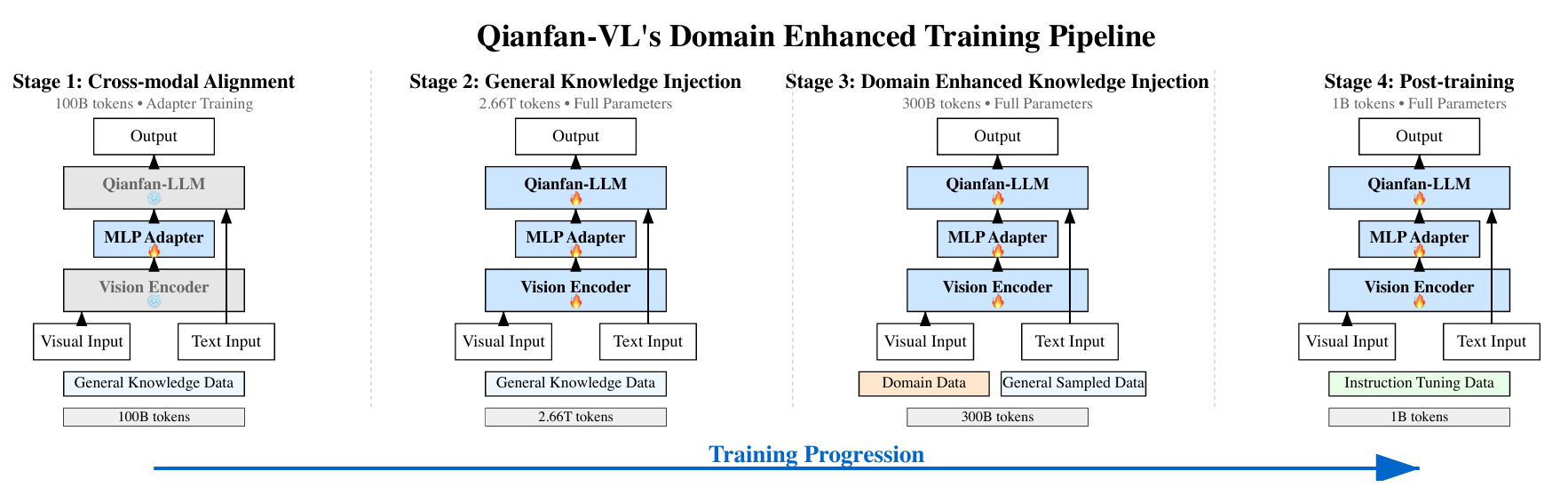
Qianfan-VL의 주요 혁신은 4단계의 Progressive Pre-training에 있다.
• Stage 1: Cross-modal Alignment
시각과 언어 간의 기본 연결을 확립
- 초기에는 어댑터만 학습하고 backbone은 고정 → 안정적인 cross-modal mapping 학습
- 약 100B 토큰 수준의 학습으로 기본 정렬 구축
• Stage 2: General Knowledge Injection
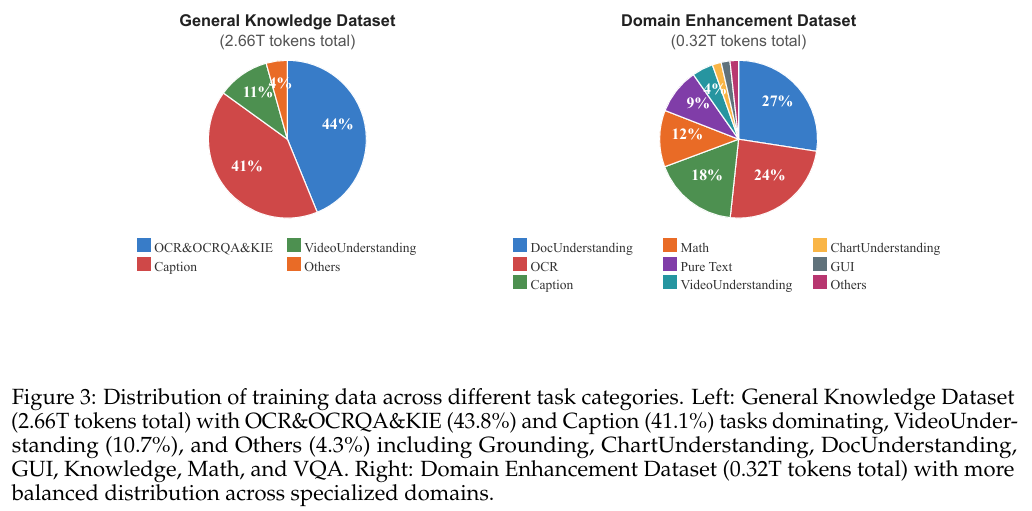
광범위한 멀티모달 데이터를 활용해 일반적 이해 능력을 확장.
- OCR, VQA, 캡션 생성 등 다양한 영역 결합
- 2.66T tokens급 대규모 데이터로 학습
• Stage 3: Domain Enhancement
특정 분야(예: OCR/문서/수학추론 등)에 특화된 전문 능력 강화.
- 전문 데이터 혼합 비율을 조절해 일반화와 특화의 균형 유지
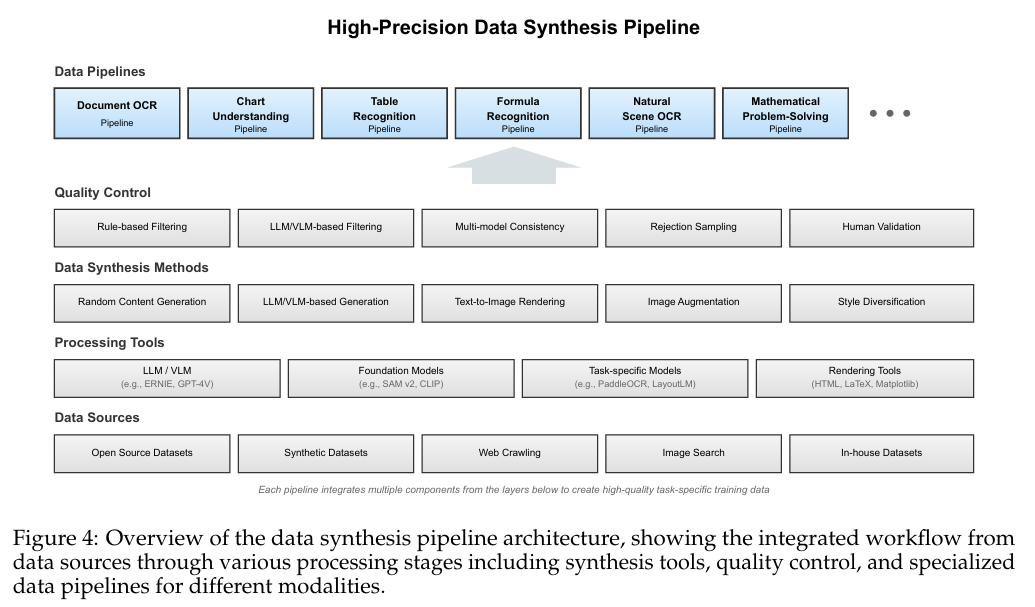

• Stage 4: Instruction Tuning
실사용을 위한 응답 조정 및 명령 추종 능력 강화.
- 복잡한 지시/조건학습 샘플 기반 fine-tuning
5. 주요 기여
Qianfan-VL의 핵심 기여는 다음과 같이 정리할 수 있다.
5.1 도메인 특화 능력 강화 전략
기존 범용 VLM은 일반적 시각-텍스트 이해 능력이 뛰어나지만,
특정 분야(예: OCR, 문서 이해, 복잡 추론)에서는 한계가 있었다.
Qianfan-VL은 multi-stage progressive training + high-precision synthetic data 전략으로
도메인별 능력을 크게 향상시킴.
5.2 모듈식 아키텍처
Vision Encoder, Cross-modal Adapter, LLM을 모듈화해
다양한 모델 규모(3B/8B/70B)에 적용 가능하다는 점도 주요 기여임.
즉 유연성과 확장성이 뛰어나다.
5.3 기업용/현실 세계 적용 최적화
OCR, 문서 이해, 수학·논리 추론 등 산업에서 자주 필요한 태스크 성능을 크게 개선함.
이는 학술 성능뿐 아니라 응용성 관점에서도 의미 있는 발전이다.
6. 실험 결과 해석
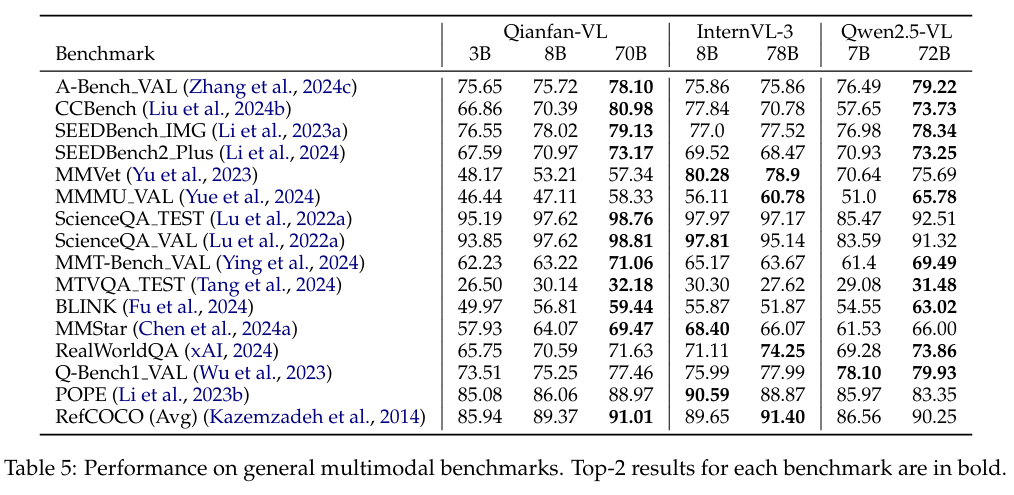

6.1 일반 멀티모달 벤치마크
Qianfan-VL은 일반적인 멀티모달 평가에서
기존 최첨단 모델과 비슷하거나 그 이상의 성능을 보여준다.
예를 들어 CCBench, SEEDBench IMG, ScienceQA, MMStar 등에서 경쟁력 있는 결과를 확보했다.
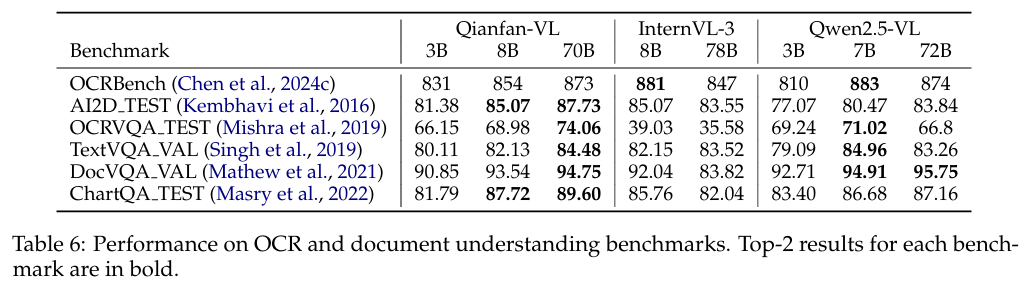
6.2 도메인 특화 평가
- OCRBench 873 및 DocVQA와 같은 문서/텍스트 중심 평가에서 SOTA 수준 성능
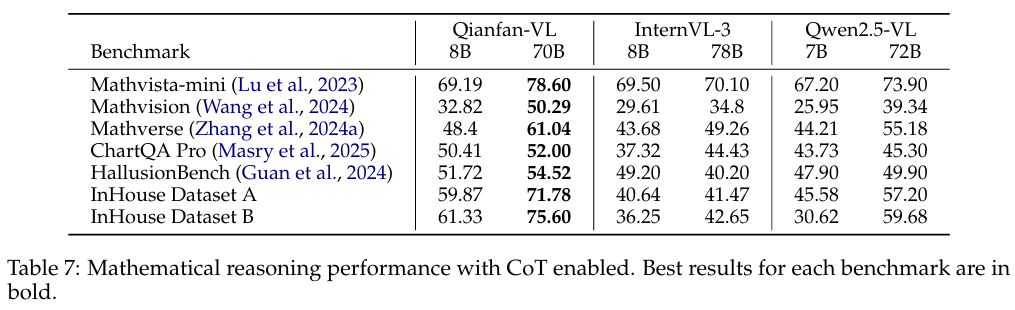
- MathVista와 같은 수학·추론 벤치마크에서도 뛰어난 결과 도출
이런 결과는 도메인 강화 전략이 실제로 효과적임을 정량적으로 보여준다.


7. 장점 및 한계
✔ 장점
- 도메인 특화와 일반화 능력을 동시에 확보한 설계
- 다양한 모델 크기로 응용 범위 확장 가능
- 대규모 인프라(대규모 클러스터)에서 효율적인 분산 학습 검증
⚠ 한계 및 과제
- 대규모 계산 자원 의존적 학습 전략 → 현실적으로 비용 부담이 높음
- 모델이 사전학습에 쓰인 합성 데이터 특성에 민감 → 실제 도메인 데이터와의 분포 차이 문제 가능
- 비교 실험에서 Qwen3-VL 계열 등 최신 공개 모델과의 평가가 제한적임
8. 한 문장 요약
Qianfan-VL은 progressive training과 high-precision synthetic data 전략을 통해 일반 멀티모달 능력과 OCR/문서/추론 같은 도메인 특화 능력을 동시에 향상시킨, 다양한 규모의 범용 비전-언어 모델 시리즈다.
