1. 배경 및 문제 정의
컴퓨터 비전(CV)과 자연어 처리(NLP) 분야는 소규모의 특정 작업 맞춤형 데이터셋에서 벗어나, 방대한 범용 데이터셋으로 사전 학습된 대규모 모델(Large General Models) 패러다임으로 전환하며 눈부신 발전을 이루었습니다. 이러한 모델들은 풍부한 데이터를 흡수하여 새로운 작업 환경에서도 제로샷(Zero-shot) 일반화 성능을 보여줍니다.
로보틱스 분야 역시 이러한 범용 모델의 도입이 절실하지만, 실제 환경의 로봇 데이터를 수집하는 것은 막대한 엔지니어링 비용과 인간의 시연이 요구되는 병목 현상을 겪고 있습니다.
기존의 로봇 제어 방법론은 주로 두 가지 한계를 지니고 있었습니다.
첫째, BC-Z와 같은 모델은 다중 작업(Multi-task)을 수행할 수 있으나, 연속적인 동작 공간(Continuous action space)을 사용하여 복잡하고 다중 모달(Multi-modal)적인 동작 분포를 포착하는 데 한계가 있으며, 새로운 환경에 대한 일반화 성능이 상대적으로 낮습니다.
둘째, Gato와 같은 트랜스포머 기반의 범용 에이전트가 존재하나, 실제 물리적 로봇 환경에서의 다중 작업보다는 시뮬레이션이나 특정 작업(예: 블록 쌓기)에 편중되어 있어 미지의 실제 환경에 대한 범용성이 입증되지 않았습니다. 또한, 모델의 크기로 인해 폐루프 제어(Closed-loop control)에 필수적인 실시간 추론 속도를 달성하기 어렵다는 치명적인 문제가 있습니다.
이 논문은 "다양한 로봇 작업 데이터를 흡수할 수 있는 고용량 아키텍처를 설계하면서도, 실제 로봇 제어에 필수적인 실시간 추론(Real-time inference)이 가능한 단일 범용 트랜스포머 모델을 구축할 수 있는가?"라는 핵심 문제를 정의하고, 이를 해결하기 위한 Robotics Transformer 1 (RT-1)을 제안합니다.
2. 제안 방법 (Method)
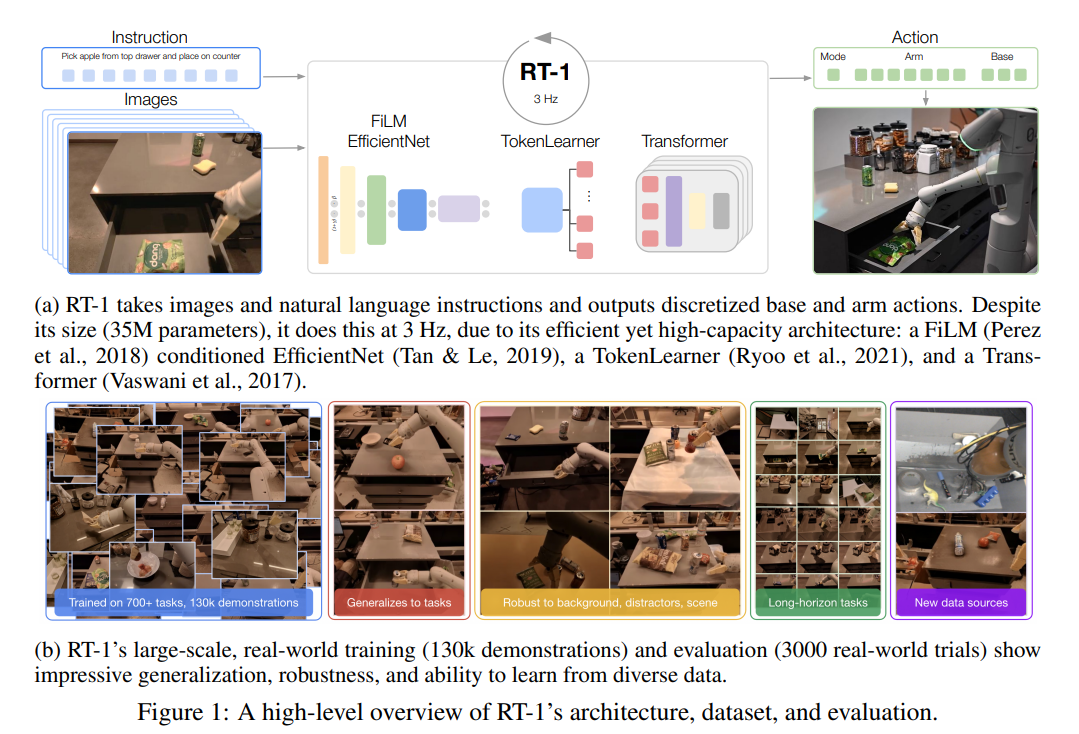
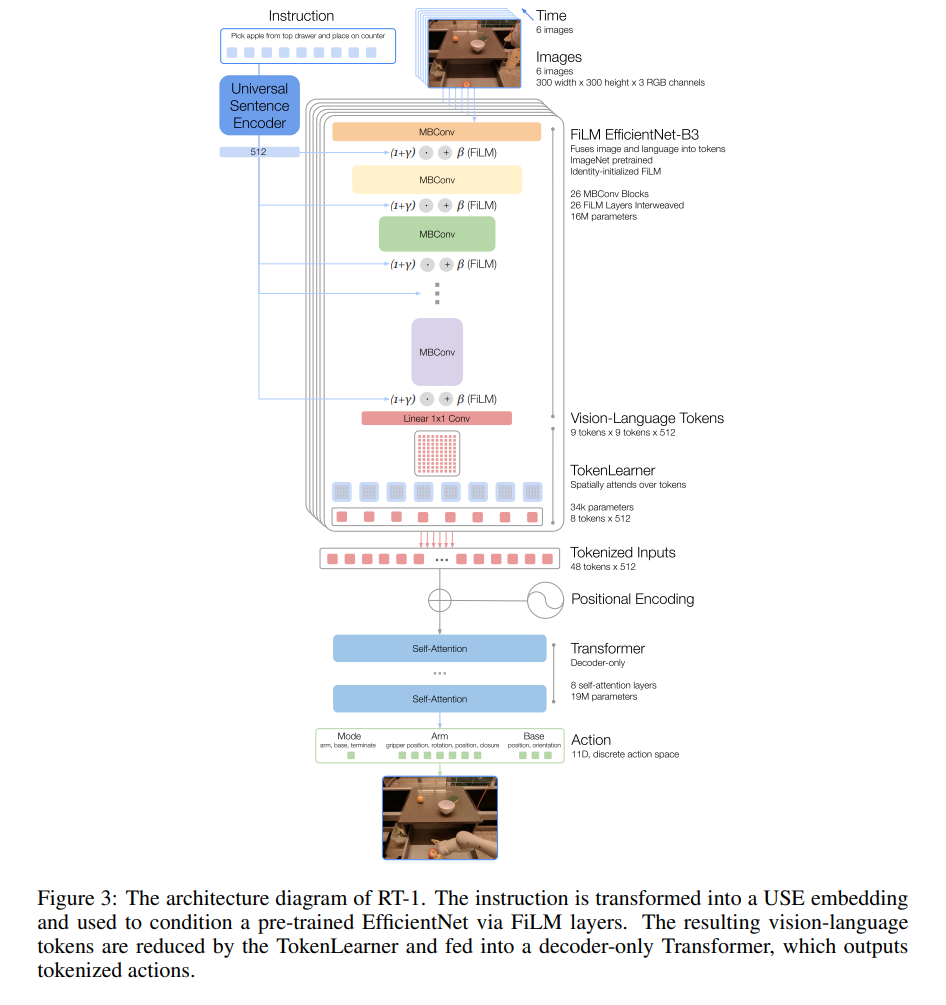
RT-1의 핵심 아이디어는 로봇 제어를 일련의 시퀀스 모델링(Sequence modeling) 문제로 취급하는 것입니다. 시각적 관측과 자연어 지시를 입력받아, 로봇의 행동을 이산화된 토큰(Discretized action tokens)으로 변환하여 트랜스포머가 다음 행동을 예측하도록 합니다. 특히 연산량을 극도로 압축하여 고성능을 유지하면서도 제어 주파수를 맞추는 파이프라인 설계가 돋보입니다.
데이터 표현 및 전처리 방식
모델은 특정 시점 에서 자연어 명령어 와 최근 6프레임의 이미지 시퀀스 를 입력으로 받습니다.
1. 자연어 임베딩: 명령어 는 Universal Sentence Encoder (USE)를 통해 텍스트 임베딩으로 변환됩니다.
2. 시각 및 언어의 초기 결합 (Early Fusion): 각 해상도의 이미지는 ImageNet으로 사전 학습된 EfficientNet-B3를 통과합니다. 이때, USE 임베딩을 FiLM (Feature-wise Linear Modulation) 레이어에 주입하여 EfficientNet의 중간 특징 맵(Feature map)을 조정합니다. 즉, 이미지에서 명령어와 관련된 특징만을 초기 단계에서부터 선택적으로 추출합니다. 사전 학습 가중치 훼손을 막기 위해 FiLM 레이어는 항등 함수(Identity)로 초기화됩니다.
3. 토큰 압축 (TokenLearner): EfficientNet의 출력인 특징 맵은 81개의 시각-언어 토큰으로 평탄화(Flatten)됩니다. 이후 TokenLearner 모듈을 통해 정보량이 높은 요소만 소프트 선택(Soft-select)되어 프레임당 단 8개의 토큰으로 압축됩니다. 최종적으로 6프레임에 대한 총 48개의 토큰 시퀀스가 생성됩니다.
모델 세부 구조 및 행동 공간의 이산화
압축된 48개의 토큰은 19M 파라미터 크기의 디코더 전용 트랜스포머(Decoder-only Transformer)에 입력됩니다.
로봇의 행동 는 팔 제어 7차원(x, y, z, roll, pitch, yaw, 그리퍼 개폐), 베이스 이동 3차원(x, y, yaw), 모드 전환 1차원(팔, 베이스, 종료) 등 총 11차원으로 구성됩니다. RT-1은 연속적인 제어 값을 사용하는 대신, 각 차원의 목표값을 256개의 균등한 구간(Bins)으로 이산화(Discretization)합니다. 트랜스포머는 각 차원마다 256개의 클래스에 대한 범주형 분포(Categorical distribution)를 출력합니다.
학습(Training) 및 추론(Inference) 알고리즘 흐름
- 학습 단계: 성공적인 데모 데이터셋 을 바탕으로 행동 복제(Behavioral Cloning)를 수행합니다. 트랜스포머 구조의 특성을 살려 인과적 마스킹(Causal masking)을 적용하고, 모델의 목적 함수는 다음과 같이 예측 행동 분포와 실제 행동 간의 범주형 교차 엔트로피 손실(Categorical cross-entropy loss)을 최소화하는 방향으로 최적화됩니다.
- 추론 단계: 실제 로봇은 이상의 속도(즉, 이하의 지연)로 행동을 산출해야 합니다. RT-1은 TokenLearner를 통한 차원 축소와 더불어, 매 타임스텝마다 전체 시퀀스를 재계산하지 않고 이전 프레임의 연산된 토큰을 캐싱하여 재사용하는 윈도우 오버래핑(Window overlapping) 기법을 통해 추론 속도를 대폭 단축시킵니다.
이러한 접근은 Gato의 패치 기반 토큰화 및 후기 결합(Late fusion) 방식 대비 연산 효율성과 작업 집중도를 극대화하며, 기존 BC-Z의 연속형 행동 회귀 대비 이산화된 행동 분포를 통해 불확실성이 높은 실제 환경에서 복잡한 다중 모달성을 안정적으로 학습할 수 있는 기술적 차별성을 갖습니다.
3. 실험 결과 (Experiments)
실험 환경 및 비교 대상
실험은 13대의 실제 모바일 매니퓰레이터를 활용해 17개월간 수집된 13만 개의 에피소드(700개 이상의 작업 명령어 포함) 데이터셋을 바탕으로 진행되었습니다. 학습 환경을 모사한 사무실 주방과, 시각적 요소 및 구조가 완전히 새로운 2개의 실제 주방 환경에서 약 3,000회의 평가가 이루어졌습니다. 비교 대상(Baseline)으로는 로봇 제어 속도에 맞춰 파라미터 크기를 조정한 Gato(37M)와 BC-Z, 그리고 파라미터를 늘린 BC-Z XL 모델이 사용되었습니다.
핵심 성능 및 정량/정성 평가
RT-1은 모든 평가 지표에서 기존 방법론을 압도했습니다.
- 학습된 작업(Seen Tasks): 97%의 성공률을 기록하여 BC-Z(72%) 및 Gato(65%)를 크게 상회했습니다.
- 보지 못한 작업(Unseen Tasks): 학습 데이터에 없던 새로운 명령어 조합에 대해 76%의 일반화 성공률을 달성했습니다.
- 견고성(Robustness): 복잡한 방해물(Distractor)이 있는 환경에서 83%, 조명과 바닥 재질이 완전히 다른 새로운 배경(Background)에서 59%의 성공률을 보이며 강건함을 입증했습니다.
해석 중심의 어블레이션 및 심층 실험 결과
- 이종 데이터 흡수(Heterogeneous Data Absorption): RT-1은 시뮬레이션 데이터를 실제 데이터와 융합했을 때, 실제 환경 성능 하락 없이 시뮬레이션에서만 보았던 객체에 대한 성능을 23%에서 87%로 대폭 향상시켰습니다. 또한, 이질적인 형태의 Kuka 로봇 데이터를 섞어 학습시켰을 때, 대상 로봇(Everyday Robots)의 새로운 작업 성능이 22%에서 39%로 약 두 배 증가하여 다기종 데이터의 모멘텀 전이(Domain transfer)가 가능함을 입증했습니다.
- 데이터 다양성 vs 양: 어블레이션 스터디 결과, 데이터의 전체 양을 줄이는 것보다 작업의 다양성(Task diversity)을 줄일 때 일반화 성능이 훨씬 급격히 하락했습니다. 이는 대규모 로봇 학습에 있어 데이터의 절대적 수치보다 '다양성'이 모델의 범용성을 결정짓는 핵심 지표임을 시사합니다.
- 장기 계획(Long-horizon) 적용: SayCan 프레임워크에 RT-1을 조작 정책으로 통합한 결과, 새로운 주방 환경에서 최장 50단계에 이르는 복잡한 연속 지시를 안정적으로 수행했습니다(Gato 0%, BC-Z 13% 대비 RT-1 67% 성공률).
4. 한계점 및 시사점
방법의 한계
- 모방 학습의 태생적 제약: RT-1은 인간의 데모를 기반으로 학습하는 모방 학습 모델이므로, 데모 제공자의 수행 능력을 초과하는 최적화된 움직임을 스스로 창출해 내기 어렵습니다.
- 일반화의 범위: 새로운 명령어에 대한 제로샷 일반화는 기존에 보았던 개념(기술, 객체)들의 새로운 조합에 국한됩니다. 아예 한 번도 학습하지 않은 물리적 동작 메커니즘을 창조해 내는 것은 불가능합니다.
- 조작의 섬세함 한계: 모델의 행동 공간 한계로 인해, 케이블 정리나 천 등 변형 가능한 물체를 다루는 극도로 정교한(Dexterous) 조작 작업에는 아직 한계를 보입니다.
엔지니어링 및 이론적 과제
실제 환경에 배치하기 위해서는 트랜스포머의 문맥 길이(Context length) 한계를 극복해야 합니다. 짧은 관측 기록(6 프레임)만을 사용하므로 일시적 가려짐 현상이나 장기적인 상태 추적에 취약할 수 있으며, 어텐션의 연산 병목을 해결하기 위한 효율적인 메모리 아키텍처 연구가 추가로 필요합니다. 또한 양질의 다양한 로봇 데이터를 확장 가능한 방식(Scalable way)으로 수집하는 파이프라인의 구축이 필수적입니다.
이 연구가 가지는 의미
RT-1은 컴퓨터 비전이나 자연어 처리에서 입증된 '대규모 범용 모델'의 이점이 로보틱스 도메인에서도 동일하게 성립함을 실제 로봇 스케일에서 입증한 기념비적인 연구입니다. 특히, 연산량의 한계로 트랜스포머를 기피하던 실시간 로봇 제어 환경에서, TokenLearner와 이산화된 행동 분포라는 엔지니어링 설계를 통해 '높은 표현력을 지닌 흡수력 있는 모델(Absorbent model)'이 로보틱스에서도 실용화될 수 있음을 보여주었으며, 향후 다양한 기종과 환경의 데이터를 통합 학습하는 파운데이션 로봇 모델로 나아가는 명확한 방향성을 제시합니다.
