[논문 리뷰] Why do tree-based models still outperform deep learning on typical tabular data?
논문 리뷰
1. 논문 정보
- 제목: Why do tree-based models still outperform deep learning on typical tabular data?
- 학회: NeurIPS 2022 (Datasets and Benchmarks Track)
- 한 줄 요약:
딥러닝이 표 데이터에서 고전하는 이유는 너무 매끄러운 함수만 찾으려는 성질(Smoothing bias)과 데이터의 축을 무시하는 회전 불변성(Rotation invariance) 때문이다.
2. 이 논문을 읽게 된 계기
최근 딥러닝이 이미지나 언어 모델에서는 압도적인데, 왜 내가 맡은 금융 데이터나 일반적인 표(Tabular) 데이터 프로젝트에서는 여전히 XGBoost나 Random Forest가 더 잘 나올까? 하는 의문이 항상 있었다.
여러 모델(TabNet, ResNet 등)을 돌려봐도 결국 트리 모델로 돌아가게 되는 현상을 보며, 이게 단순히 "내가 튜닝을 못해서"인지 아니면 구조적인 한계가 있는 건지 명확한 답을 얻고 싶었다. 이 논문은 그 질문에 대해 20,000시간 이상의 실험으로 답을 내려준다는 점에서 필독 리스트였다.
3. 처음 읽고 든 인상
처음에는 "단순히 트리 모델이 더 좋다는 걸 보여주는 또 다른 벤치마크 논문인가?" 싶었다.
하지만 데이터를 강제로 회전(Rotation)시키거나 타겟을 부드럽게(Smoothing) 만드는 등의 변환 실험을 통해, 모델의 '본능(Inductive Bias)'을 파헤치는 과정을 보면서 관점이 완전히 바뀌었다. 단순히 성능 수치를 나열하는 게 아니라, "딥러닝은 이래서 안 되는 거야"라고 논리적으로 조목조목 따지는 느낌을 받았다.
4. 전체 구조 및 아키텍처 요약
논문은 단순한 비교를 넘어 '왜?'라는 질문에 답하기 위해 다음과 같은 흐름으로 진행된다.
- 표준 벤치마크 구축: 45개의 다양한 데이터셋을 수집하고 전처리 규칙을 통일한다.
- 압도적인 HPO: 공정한 비교를 위해 각 모델당 20,000시간 이상의 하이퍼파라미터 튜닝을 거친다.
- 성능 격차 확인: 모든 튜닝 예산에서 트리 모델이 딥러닝을 앞선다는 사실을 먼저 박고 시작한다.
- 원인 분석 실험:
- 타겟 함수를 뭉개보기 (Smoothing).
- 무의미한 특성 넣어보기 (Uninformative features).
- 데이터 축을 돌려보기 (Rotation).
5. 주요 구성 요소 상세 설명
논문에서 지목한 딥러닝의 3대 패배 원인은 다음과 같다.
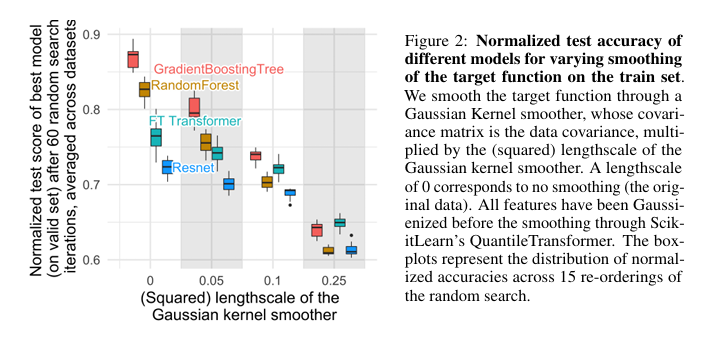
(1) Neural networks are biased to overly smooth solutions
신경망은 기본적으로 부드러운 함수(Smooth function)를 배우려 한다. 하지만 실제 Tabular 데이터의 타겟 값은 계단식처럼 뚝뚝 끊기거나 불규칙한 경우가 많다.
- 결과: 타겟을 인위적으로 부드럽게 만들수록 트리 모델 성능은 급락하지만, 신경망은 별 타격이 없었다. 즉, 신경망은 원래부터 Tabular 데이터의 거친 패턴을 못 잡고 있었다는 뜻이다.
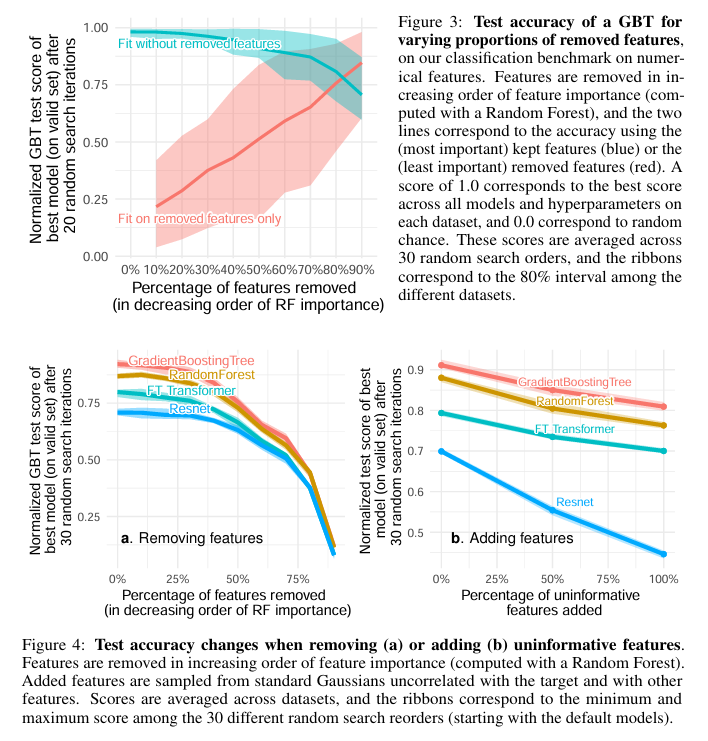
(2) Uninformative features affect more MLP-like neural networks
Tabular 데이터에는 예측에 쓸모없는 '잡음' 컬럼이 많다.
- 트리 모델: 분할(Split) 과정에서 무의미한 특성을 자동으로 걸러낸다.
- 신경망(MLP): 모든 특성을 선형 결합으로 섞어버리기 때문에 잡음이 조금만 섞여도 가중치 전체가 오염된다.
사용자께서 요청하신 내용을 바탕으로, '회전 불변성(Rotation Invariance)'의 원리와 실험적 의미를 깊이 있게 파헤친 블로그 세부 섹션을 구성해 드립니다.
(3) Data are non-invariant by rotation
신경망은 기본적으로 회전 불변성(Rotation invariance)을 가진 성질을 보입니다.
| 개념 | 의미 | 표 데이터에서의 영향 |
|---|---|---|
| 회전 불변성 | 데이터를 회전시켜도(특성끼리 선형 결합으로 섞어도) 모델이 같은 결과를 내는 성질 |
| 표 데이터의 각 열(나이, 소득 등)은 고유한 의미가 있는데, 이를 섞어버리면 개별 특성의 통계적 의미가 훼손됨
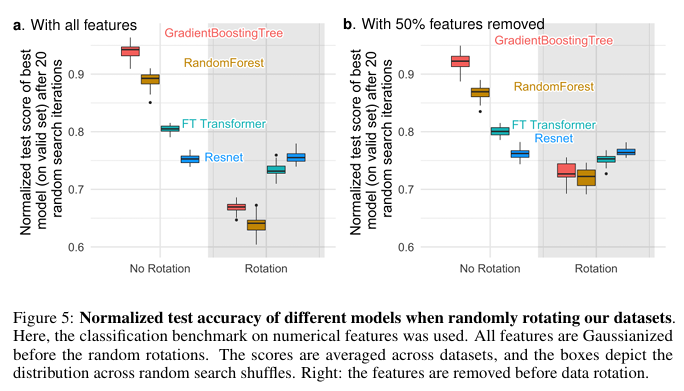
트리 모델은 특정 축(열)을 기준으로 데이터를 자르기 때문에 회전 변환에 매우 민감합니다. 그런데 데이터를 무작위로 회전시키니 딥러닝이 트리 모델을 이겨버리는 '순위 역전' 현상이 발생했습니다.
💡 왜 '회전'이 모델의 성적표를 바꿀까? (Deep Dive)
이 실험이 시사하는 바는 단순히 "트리가 회전에 약하다"는 것이 아니라, 표 데이터의 본질이 '축(Coordinate)'에 의존한다는 사실입니다.
- 신경망의 본능 (): 신경망은 입력값 에 가중치 행렬 를 곱하는 선형 결합으로 학습을 시작합니다. 만약 데이터가 회전()되어 들어오더라도 가중치 가 이를 상쇄하도록 조정될 수 있기 때문에, 신경망은 축이 돌아갔는지 아닌지를 상관하지 않고 동일한 방식으로 학습합니다.
- 트리 모델의 고집 (Axis-aligned split): 트리는 "나이가 30세 이상인가?"처럼 한 번에 하나의 피처(축)만 선택해서 수직으로 자릅니다. 표 데이터는 각 컬럼이 '나이', '소득'처럼 명확한 의미(Natural Basis)를 가지므로, 이 축을 지키며 자르는 트리의 방식이 표 데이터의 구조적 편향과 완벽히 일치하는 것입니다.
- 무의미한 특성(Irrelevant features)과의 관계: 회전 불변인 알고리즘은 모든 피처가 섞인 상태에서 학습을 시작하므로, 어떤 피처가 무의미한지 찾아내는 데 훨씬 더 많은 데이터를 필요로 합니다. 반면 트리는 축별로 검토하므로 잡음 섞인 컬럼을 무시하기가 매우 쉽습니다.
🚀 핵심 통찰: "표 데이터에서 딥러닝이 이기려면?"
논문은 회전 불변성을 깨뜨리는 것이 성능 개선의 핵심이라고 말합니다. 실제로 FT-Transformer 같은 모델이 선전하는 이유는 각 특성을 개별적으로 처리하는 임베딩 층(Tokenizer)을 통해 신경망의 회전 불변 본능을 억제하고, 각 컬럼의 독립적인 의미를 보존했기 때문입니다.
결국 표 데이터 딥러닝의 과제는 "어떻게 하면 트리 모델처럼 축의 의미를 존중하면서도 신경망의 유연성을 가져올 것인가"로 귀결됩니다.
6. 핵심 아이디어 (내가 이해한 방식)
이 논문이 해결하려는 핵심 문제는 이거다.
“딥러닝의 우수한 유연성이 왜 표 데이터에서는 독이 될까?”
저자들의 답은:
- 표 데이터는 불연속적이고 거칠다.
- 각 특성은 개별적인 물리적 의미를 가진다.
- 딥러닝은 이걸 무시하고 부드럽고 둥글둥글하게만 이해하려 하니 안 되는 것이다.
👉 내가 이해한 한 문장 요약:
표 데이터 분석에서 중요한 건 모든 걸 다 학습하는 능력이 아니라, 무의미한 걸 무시하고 각 특성의 경계를 날카롭게 가르는 능력이다.
7. 기존 방법과의 비교에 대한 개인적인 생각
- FT-Transformer: 그나마 딥러닝 중 선전한 모델인데, 이 논문에 따르면 그 이유가 'Tokenizer' 단계에서 각 특성을 개별적으로 처리해 회전 불변성을 어느 정도 깨뜨렸기 때문이라고 한다.
- ResNet / MLP: 가장 기본적인 구조지만, 무의미한 특성(Uninformative features)에 너무 취약하다는 게 다시 확인됐다.
다만 의문이 드는 건:
- 데이터가 수백만 건 이상인 초대규모(Large-scale) 환경에서도 트리 모델이 압도적일까? 논문은 중간 크기(10K) 위주라 이 부분이 여전히 궁금하다.
8. 실험 결과에 대한 해석
이 논문에서 인상적인 건 성능 수치보다 "Order Reversal(순위 역전)"이다.
- 원본 데이터: 트리 > 딥러닝.
- 회전된 데이터: 딥러닝 > 트리.
내 해석은 이렇다.
트리 모델이 잘나서라기보다, 우리가 다루는 데이터가 '축(Feature)' 중심의 특성을 가지고 있기 때문에 트리가 유리한 환경이었을 뿐이다. 딥러닝이 못난 게 아니라 환경이 안 맞았던 셈이다.
9. 추가 분석 / 설계 검증 실험
Ablation 연구 성격의 변환 실험들이 핵심이다.
- Gaussianized features: 모든 특성을 가우시안 분포로 바꿔도 트리 모델의 우위는 유지됐다. 범주형 데이터 처리 능력이 패배의 유일한 이유는 아니라는 뜻이다.
- Feature removal: 무의미한 특성을 제거할수록 딥러닝 성능이 급격히 올라간다. 딥러닝을 쓸 거면 Feature Selection이 트리 모델보다 훨씬 더 치명적으로 중요하다는 걸 시사한다.
10. 개인 프로젝트 / 실무에의 연결
- 금융/거시경제 프로젝트: 지표(Feature) 하나하나의 의미가 중요한 시계열/표 데이터에서는 딥러닝보다 XGBoost 베이스라인을 훨씬 더 깊게 파야겠다고 생각했다.
- 하이브리드 전략: 딥러닝을 굳이 써야 한다면, 회전 불변성을 깨는 Embedding 설계나 특성 선택(Feature selection)에 훨씬 더 많은 공을 들여야겠다.
