[논문 리뷰] T2G-FORMER: Organizing Tabular Features into Relation Graphs Promotes Heterogeneous Feature Interaction
논문 리뷰
1. 논문 정보
-
제목: T2G-FORMER: Organizing Tabular Features into Relation Graphs Promotes Heterogeneous Feature Interaction
-
학회: AAAI 2023
-
한 줄 요약:
테이블 데이터를 그냥 attention으로 섞지 말고, feature 간 관계를 그래프로 먼저 조직한 뒤 Transformer로 상호작용하자는 접근
2. 이 논문을 읽게 된 계기
최근에 tabular data 프로젝트를 하면서 또 한 번 느낀 건,
“왜 딥러닝은 테이블 데이터에서 트리 모델을 못 이길까?”라는 오래된 질문이었다.
FT-Transformer, TabNet, DANet 같은 모델들을 보면서도 계속 걸리는 지점이 있었다.
- 모든 feature를 attention으로 다 섞는 게 과연 맞나?
- height, weight, HIV-Ab 같은 feature가 동등하게 상호작용하는 게 자연스러운가?
- 사람은 분명 “관련 있는 것끼리만 같이 본다”
DANet은 grouping으로 한 단계 나아갔지만,
그룹 내부에서는 여전히 무차별적으로 섞인다는 느낌이 강했다.
이 논문은 제목부터가 딱 그 지점을 찌른다.
“heterogeneous feature interaction을 그래프로 정리해보자”
3. 처음 읽고 든 인상
첫 인상은 솔직히 좀 복잡했다.
- “Graph Estimator?”
- “Static topology + adaptive weight?”
- “Transformer + Graph?”
처음에는 Transformer에 GNN을 억지로 붙인 느낌도 들었다.
그런데 Fig.1의 의료 데이터 예시를 다시 보면서 관점이 바뀌었다.
- 완전 연결 attention → 너무 시끄럽다
- grouping → 덜 시끄럽지만 여전히 거칠다
- graph → “어떤 feature 쌍이 의미 있는지”를 명시적으로 관리
재독하면서 이 논문은 성능보다 inductive bias를 설계하는 논문이라는 느낌이 강해졌다.
4. 전체 구조 및 아키텍처 요약
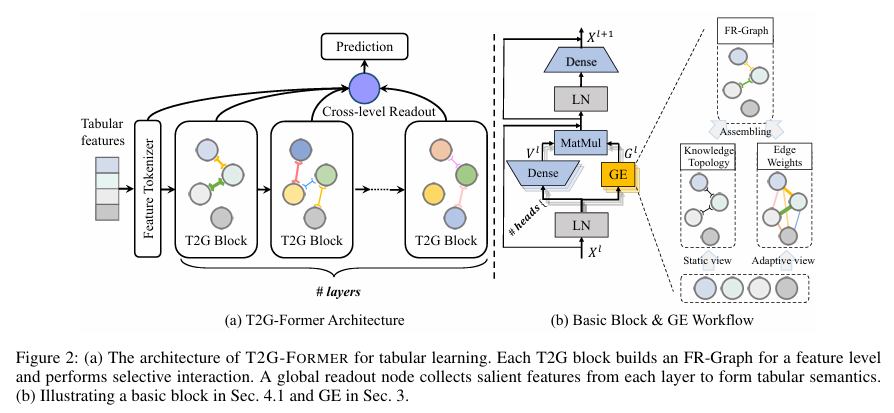

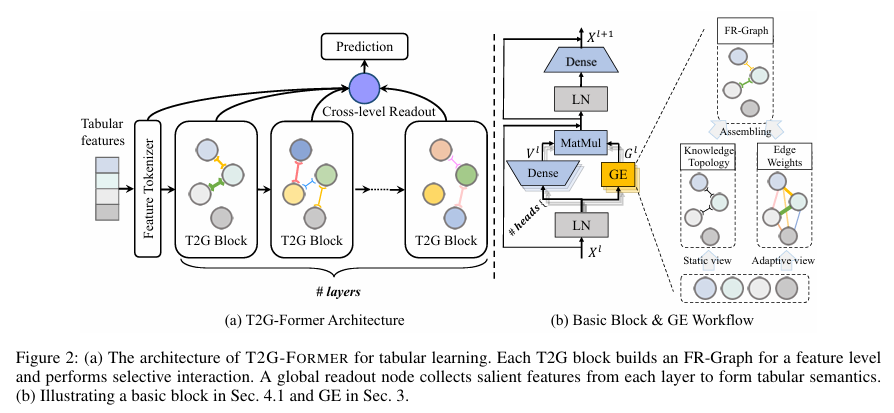
전체 파이프라인은 생각보다 명확하다.
- 각 column(feature)을 하나의 노드로 본다
- Graph Estimator(GE)가
- feature 간 관계 그래프(FR-Graph)를 만든다
- 이 그래프를 이용해서
- Transformer block 안에서 선별적 feature interaction을 수행한다
- 이 과정을 여러 layer에서 반복한다
- 각 layer의 중요한 feature를
- Cross-level Readout이 모아서 최종 예측에 사용한다
즉,
테이블 → feature graph → graph-guided transformer → 여러 level 의미를 모아서 예측
5. 주요 구성 요소 상세 설명
Head / Tail / Relation
- Head (H): 관계의 출발점이 되는 노드
- Tail (T): 관계의 도착점이 되는 노드
- Relation (R): Head와 Tail을 연결하는 관계/edge
예시 (지식 그래프)
| Head (H) | Relation (R) | Tail (T) |
|---|---|---|
| Paris | isCapitalOf | France |
| Einstein | bornIn | Ulm |
| Apple | foundedBy | Steve Jobs |
💡 핵심 포인트:
- Head 중심 관점 → tail과 relation을 보고 head를 예측
- Tail 중심 관점 → head와 relation을 보고 tail을 예측
- Relation은 단순 라벨이 아니라, 두 노드가 상호작용하는 방식을 정의
(1) Graph Estimator (GE)
이 논문의 핵심.
GE는 feature 관계를 두 가지 관점에서 만든다.
- Adaptive edge weight (데이터 기반)
- 특정 샘플에서 “이 두 feature가 지금 상황에서 얼마나 관련 있나?”

- 특정 샘플에서 “이 두 feature가 지금 상황에서 얼마나 관련 있나?”
- Static topology (전역적 지식)
- 데이터 전체를 봤을 때 “이 feature 쌍은 원래 의미 있는 관계인가?”


- 데이터 전체를 봤을 때 “이 feature 쌍은 원래 의미 있는 관계인가?”
이 둘을 곱해서 최종 그래프를 만든다.
👉 내 이해로는
- adaptive weight = 상황별 중요도 (feature 간의 관계성)
- static topology = “아무 때나 섞지 마라”는 규칙 (feature 간의 관계성에 적용할 필터)
이 조합이 꽤 설득력 있었다.
(2) FR-Graph 기반 feature interaction

Transformer의 attention과 가장 다른 점은 이거다.
- 모든 feature 쌍이 attention 대상이 아니다
- 그래프에 edge가 있는 경우에만 상호작용한다
- self-loop(자기 자신과의 interaction)는 아예 제거
자기 정보는 shortcut으로 유지하고, interaction은 오로지 “다른 feature와의 관계”에만 집중한다는 설계가 인상 깊었다.
(3) Cross-level Readout

이건 개인적으로 꽤 마음에 들었다.
- 보통 Transformer는 마지막 layer만 쓴다
- 여기서는 각 layer에서 의미 있는 feature를 조금씩 모은다
“저수준 feature도 여전히 중요할 수 있다”는 전제를 깔고 있는 느낌.
트리 모델이 shallow한 feature를 잘 쓰는 이유를 딥러닝 쪽에서 흉내 내려는 시도로 보였다.
6. 핵심 아이디어 (내가 이해한 방식)
이 논문이 던지는 핵심 질문은 이거다.
“테이블 feature는 서로 다 다른데,
왜 우리는 항상 동일한 방식으로 섞으려고 할까?”
저자들의 답은:
- feature를 그래프 구조로 조직
- 의미 있는 관계만 골라서 interaction
- Transformer는 그 위에서 “계산 엔진” 역할
👉 내가 이해한 한 문장 요약:
Tabular learning에서 중요한 건 더 센 attention이 아니라,
attention을 어디에 쓰지 말아야 하는지를 아는 것
7. 기존 방법과의 비교에 대한 개인적인 생각
-
FT-Transformer
- 모든 feature를 토큰처럼 취급
- 깔끔하지만 heterogeneity에 둔감
-
DANet
- selection & abstraction은 좋음
- grouping이 너무 coarse
-
T2G-FORMER
- feature 간 관계를 “edge 단위”로 다룸
- grouping보다 훨씬 세밀함
다만 아직도 확신이 안 드는 부분은:
- static topology가
정말 “underlying knowledge”를 학습하는지
아니면 그냥 또 다른 parameter matrix인지
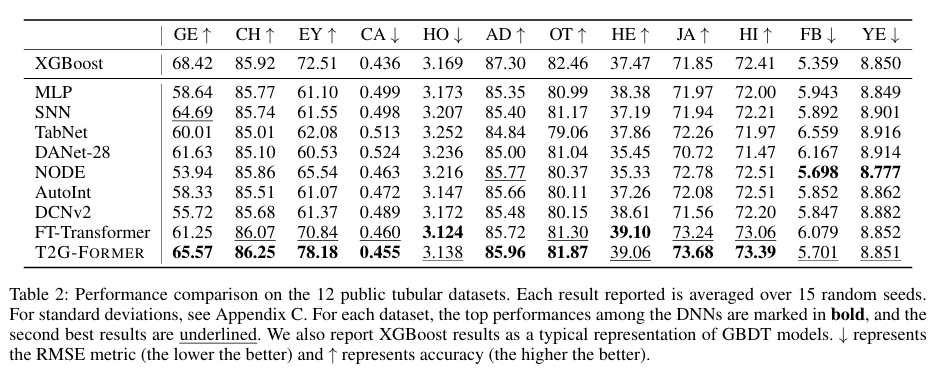
8. 실험 결과에 대한 해석
이 논문에서 인상적인 건
“GBDT를 이겼다”보다도 “GBDT와 비슷해졌다”는 점이다.
- 딥러닝 모델 중에서는 거의 항상 상위권
- 데이터셋에 따라서는 XGBoost와 근접
내 해석은 이렇다.
feature interaction을 무작위로 늘리는 대신,
구조를 주니까 딥러닝이 드디어 테이블 데이터에서 길을 찾기 시작했다
9. 추가 분석 / 설계 검증 실험
Ablation 실험들이 전반적으로 설계 의도를 잘 보여준다.
-
self-loop 제거 → 성능 소폭 개선
→ “자기 자신은 interaction 대상이 아니다”라는 가설 지지 -
GE 위치 실험
→ 첫 layer의 GE가 특히 중요
→ “원초적 feature 관계를 초기에 잡는 게 중요하다” -
group(DANet) vs graph
→ graph가 consistently 더 나음
→ grouping은 정보 손실이 크다는 걸 다시 확인
10. 해석 가능성 / 분석 관점
FR-Graph 시각화는 꽤 설득력이 있다.
- California Housing에서
income ↔ occupancy, location ↔ population 같은 관계 - readout이 특정 feature만 강하게 선택하는 것도 직관적
다만,
- 그래프가 “왜 그렇게 나왔는지”까지 설명되진 않는다
- interpretability라기보단 inspectability에 가깝다
11. 개인 프로젝트 / 실무에의 연결
이 논문을 보면서 떠오른 아이디어들:
- 도메인 지식이 있는 경우
→ static topology를 부분적으로 고정해도 재밌을 듯 - feature 수가 많은 추천/금융 데이터
→ “interaction budget” 개념으로 쓰기 좋아 보임 - 기존 FT-Transformer의 attention score를
→ graph mask로 제한하는 간단한 변형도 시도해보고 싶다
12. 장점과 한계 정리
장점
- tabular feature heterogeneity를 정면으로 다룸
- grouping보다 세밀한 inductive bias
- Transformer를 “계산 도구”로 잘 활용
한계 / 의문
- 구조가 복잡하고 구현 부담 큼
- static topology가 진짜 지식인지 학습된 편향인지 애매
- feature 수가 매우 클 때 scalability는 고민 필요
13. 현재 시점에서의 정리
이 논문에서 가장 인상 깊었던 관점은 이거다.
“interaction을 더 잘하는 것보다,
interaction을 제한하는 게 더 중요할 수 있다.”
다음에 다시 읽을 때는:
- GE의 static topology 학습 방식
- attention과 graph의 수학적 차이
- GBDT의 split 구조와의 연결점
을 더 집중해서 보고 싶다.
이어 읽고 싶은 키워드/논문:
- Graph-based tabular learning
- DANet 이후 계열
- “Why GBDT still wins on tabular data”류의 분석 논문
