FT-Transformer: Tabular Data를 위한 Transformer 정리
1. 논문 정보
- Title: Revisiting Deep Learning Models for Tabular Data
- Conference: NeurIPS 2021
- Authors: Yury Gorishniy et al.
- 주요 모델: FT-Transformer (Feature Tokenizer + Transformer)
한 줄 요약
Tabular data에서 각 feature를 token으로 취급해 self-attention으로 feature 간 관계를 학습하는 Transformer 기반 모델을 제안한 논문.
2. 이 논문을 찾아보게 된 계기
이 논문을 찾아보게 된 직접적인 계기는 TOSS 대회를 진행하면서 tabular 데이터 문제를 다뤘던 경험 때문이다.
대회에서는 XGBoost, LightGBM 같은 트리 기반 모델이 강력한 성능을 보였지만, 개인적으로는 트리 모델을 제외한 딥러닝 기반 접근을 고민해보고 싶었다.
Tabular 데이터에 사용할 수 있는 딥러닝 모델들을 찾아보던 중,
Transformer의 attention 메커니즘을 feature 단위로 적용한 FT-Transformer를 접하게 되었고,
“attention이 정말 feature 간 연관성을 잘 뽑아낼 수 있을까?”라는 궁금증에서 이 논문을 읽게 되었다.
3. 처음 읽고 든 인상
Transformer 구조 자체는 익숙했지만,
처음에는 “왜 굳이 feature를 token처럼 다뤄야 하는가?”가 직관적으로 와닿지 않았다.
논문을 다시 읽으며 이해한 핵심은,
이 모델이 row 단위의 표현 학습이 아니라 feature 간 관계(feature interaction)를 직접 학습하려는 시도라는 점이었다.
이 관점을 이해하고 나서야 전체 구조가 자연스럽게 보이기 시작했다.
4. 전체 구조 및 아키텍처 요약
FT-Transformer의 전체 흐름은 다음과 같다.
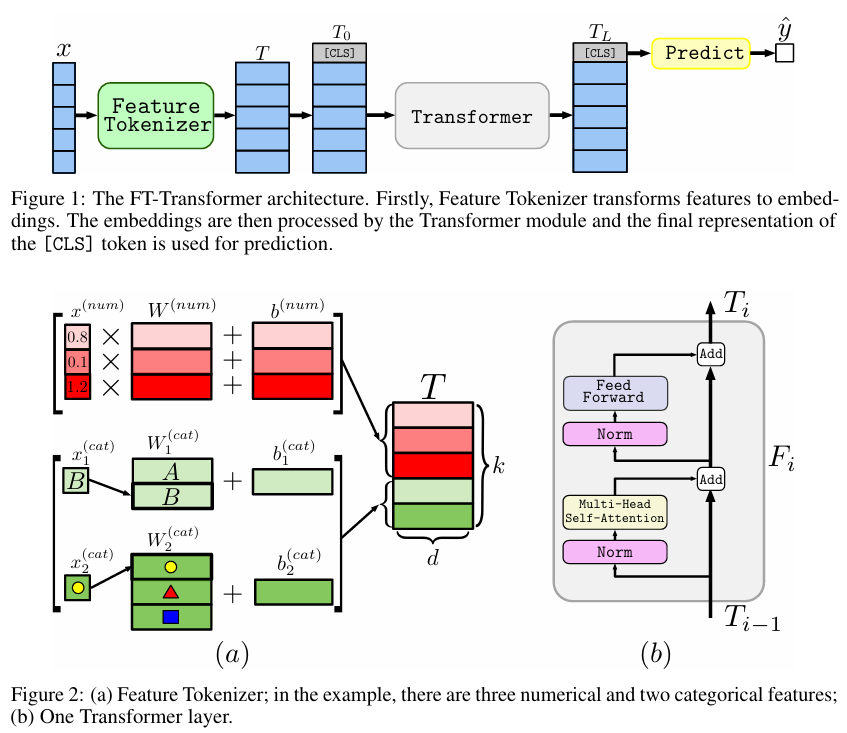



이 모델의 핵심 설계는 다음 한 문장으로 요약할 수 있다.
각 feature(column)를 하나의 token으로 보고,
self-attention으로 feature 간 관계를 학습한다.
NLP에서 단어(token) 간 관계를 학습하던 attention을
tabular data에서는 feature 간 관계 학습에 사용한다는 발상이다.
5. Feature Tokenizer 정리
Feature Tokenizer는 FT-Transformer에서 가장 중요한 구성 요소다.
Numerical Feature
- 각 numerical feature마다 학습 가능한 weight vector를 가짐
- scalar 값에 대해 선형 변환을 수행해 d차원 embedding으로 변환
- feature별 bias 또한 함께 학습
Categorical Feature
- 일반적인 embedding lookup 방식 사용
- numerical feature와 동일한 차원의 token으로 변환
이 과정을 통해 모든 feature는 동일한 embedding space의 token이 되고,
Transformer encoder의 입력으로 사용될 수 있다.
6. 핵심 아이디어 (내가 이해한 방식)
이 논문의 핵심 주장은 다음과 같이 정리할 수 있다.
Tabular data에서 중요한 것은 개별 feature의 값보다
feature 간 상호작용이며,
self-attention은 이를 학습하기에 적합한 메커니즘이다.
기존 MLP 기반 모델은 모든 feature를 단순히 concat한 뒤 처리하기 때문에,
복잡한 feature 관계를 학습하는 데 구조적인 제약이 있었다.
FT-Transformer는 이러한 feature interaction을
attention 구조로 명시적으로 모델링하려는 접근이라고 이해했다.
7. Transformer 설계 선택에 대한 정리
-
Encoder-only 구조
- 순서 개념이 없기 때문에 positional encoding을 사용하지 않음
-
[CLS] token 사용
- 모든 feature 정보를 집약한 row-level representation 생성
-
Pre-Norm Transformer
- 학습 안정성을 고려한 설계 선택
NLP용 Transformer를 그대로 가져온 것이 아니라,
tabular data 특성에 맞게 불필요한 요소를 제거한 구조라는 점이 인상적이었다.
8. 논문을 통해 얻은 깨달음
이 논문을 통해 가장 크게 느낀 점은 다음이다.
Transformer의 attention은
feature 간 연관성을 사람이 직접 설계하지 않아도,
데이터로부터 관계를 학습할 수 있는 구조라는 점이다.
MLP 역시 충분히 깊고 크다면 복잡한 관계를 표현할 수 있지만,
attention은 “서로를 참조한다”는 구조를 모델 차원에서 명확히 가진다는 차이가 있다.
9. MLP vs Attention에 대한 개인적인 궁금증
논문을 읽으며 자연스럽게 다음과 같은 질문이 들었다.
MLP와 attention 중,
어떤 구조가 feature 간 관계를 더 잘 뽑아내고
실제 성능으로도 이어질 수 있을까?
MLP는 표현력은 강하지만 관계 학습을 구조적으로 강제하지 않는다.
반면 attention은 설계 단계에서부터 feature 간 상호작용을 전제로 한다.
이 논문은 attention이 항상 MLP보다 낫다고 주장하지는 않지만,
적어도 tabular data에서 관계 학습을 유도하는 하나의 효과적인 방식임을 보여준다.
10. FT-Transformer가 ResNet보다 나았던 이유
논문에서는 FT-Transformer와 ResNet의 차이를 더 명확히 이해하기 위해
흥미로운 synthetic experiment를 수행한다.
아이디어는 단순하다.
타겟 함수의 성격을 점점 바꿔가며, 어떤 모델이 어디서 무너지는지를 관찰하는 것이다.
저자들은 두 가지 종류의 타겟 함수를 만든다.
하나는 여러 개의 결정트리로 구성된 함수로, GBDT가 잘 맞추는 형태이고,
다른 하나는 MLP로 구성된 함수로, 딥러닝 모델이 잘 맞추는 형태다.
그리고 이 두 함수를 비율로 섞어가며 데이터의 성격을 점진적으로 변화시킨다.
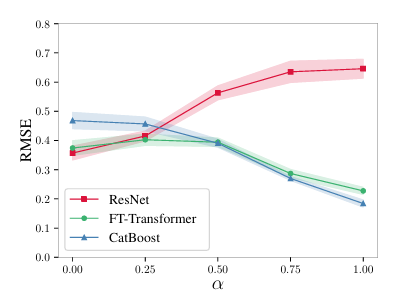
실험 결과, 딥러닝 친화적인 타겟에서는 ResNet과 FT-Transformer가 비슷한 성능을 보였지만,
타겟이 점점 트리 친화적인 형태로 변할수록 ResNet의 성능은 급격히 하락했다.
반면 FT-Transformer는 이러한 변화에도 비교적 안정적인 성능을 유지했다.
이 실험은 FT-Transformer가 단순히 ResNet의 변형이 아니라,
트리 모델이 잘 푸는 유형의 함수에도 상대적으로 강한 구조임을 보여준다.
이는 attention이 feature 간 조건적 관계를 표현하는 데
구조적인 이점을 가진다는 점과 연결된다고 이해했다.
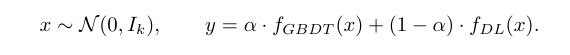
11. Ablation Study: FT-Transformer 설계 선택에 대한 검증
논문에서는 FT-Transformer의 설계가 단순한 선택이 아니라 실제 성능에 영향을 미치는지 확인하기 위해
ablation study를 수행한다.
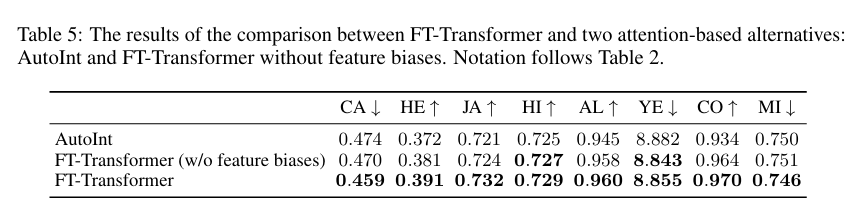
먼저, 가장 유사한 모델인 AutoInt와 비교한다.
AutoInt 역시 모든 feature를 embedding으로 변환한 뒤 self-attention을 적용하지만,
feature bias를 사용하지 않고, vanilla Transformer와는 다른 backbone을 사용하며,
[CLS] token을 통한 집계 방식도 사용하지 않는다.
실험 결과, FT-Transformer는 AutoInt보다 전반적으로 더 나은 성능을 보였고,
Feature Tokenizer에서 feature bias를 제거한 경우에도 성능이 눈에 띄게 감소했다.
이는 단순히 attention을 사용하는 것만으로는 충분하지 않고,
feature bias와 vanilla Transformer backbone 같은 세부 설계가
tabular 데이터 성능에 중요한 역할을 한다는 점을 시사한다.
이 결과를 통해 FT-Transformer는
“attention 기반 모델”이라기보다는,
tabular 데이터에 맞게 정제된 Transformer 구조로 이해하는 것이 더 적절하다고 느꼈다.
12. Attention 기반 Feature Importance 추출
부가적으로, 논문에서는 FT-Transformer의 attention map을 활용해
feature importance를 추정하는 간단한 방법도 제안한다.
FT-Transformer에서는 각 feature가 하나의 token이며,
최종 예측은 [CLS] token을 통해 이루어진다.
따라서 [CLS] token이 각 feature token을 얼마나 참고했는지를
feature importance로 해석할 수 있다.
논문에서는 한 샘플에 대해 모든 layer와 head에서의
[CLS] → feature attention을 평균내고,
이를 여러 샘플에 대해 다시 평균하는 방식을 사용한다.
이 방법은 forward pass 한 번만으로 importance를 계산할 수 있어
계산 비용이 매우 낮으며,
Integrated Gradients와 비교했을 때도
feature 중요도 순위(rank correlation) 측면에서 유사한 수준의 결과를 보였다.
다만 attention weight를 곧바로 설명으로 해석하는 데에는 한계가 있으며,
이 방법은 정확한 인과적 중요도라기보다는
저비용의 heuristic한 해석 도구로 이해하는 것이 적절하다고 느꼈다.
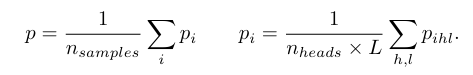
13. 프로젝트에서의 응용: 시계열 + Transformer 변형
이 논문의 아이디어를 그대로 사용하기보다는,
개인 프로젝트에서는 다음과 같은 방식으로 변형해 적용해보았다.
- 시계열 데이터를 LSTM에 입력
- LSTM의 hidden state를 임베딩 벡터로 추출
- 이 임베딩을 Transformer의 입력 token으로 사용
즉,
- 시계열 내부의 패턴은 LSTM이 요약하고
- 여러 시계열 또는 feature 간 관계는 Transformer가 attention으로 학습하도록 구성했다
FT-Transformer의 “feature를 token으로 보고 attention을 적용한다”는 관점을
시계열 임베딩에도 확장해본 시도였다.
14. 장점 정리
- Feature interaction을 수동으로 설계할 필요가 없음
- Numerical / Categorical feature를 동일한 방식으로 처리 가능
- 구조가 비교적 단순하고 일반적
- 기존 MLP나 attention 기반 tabular 모델 대비 안정적인 성능
특히 데이터 규모가 커질수록
ResNet 기반 모델보다 일관된 성능을 보이는 점이 인상적이었다.

15. 한계 및 아쉬운 점
- GBDT 계열 모델을 항상 이기지는 못함
- Feature 수가 많아질 경우 attention 계산 비용 증가
- Attention weight를 통한 해석성은 제한적
- “왜 잘 되는가”에 대한 이론적 설명은 충분하지 않음
Transformer가 tabular data의 만능 해법은 아니라는 점을
논문에서도 비교적 솔직하게 인정한다.
16. 현재 시점에서의 정리
이 논문에서 가장 인상 깊었던 부분은
Transformer 자체보다는 Feature Tokenization이라는 관점 전환이었다.
FT-Transformer는
“tabular data에서도 딥러닝을 진지하게 고려할 수 있다”는
하나의 기준점을 제시한 논문으로 느껴졌다.
다음에 다시 읽을 때는 다음을 중점적으로 볼 예정이다.
- 어떤 데이터 특성에서 FT-Transformer가 ResNet보다 유리한지
- Feature Tokenizer를 다른 구조에 응용할 수 있는지
- 실제 프로젝트에서 계산 비용 대비 이점이 있는지
