A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal and Aman Chadha Department of Computer Science And Engineering, Indian Institute of Technology Patna Stanford University, Amazon AI, [Submitted on 5 Feb 2024 (v1), last revised 16 Mar 2025 (this version, v2)]
초록
프롬프트 엔지니어링은 LLM, VLM의 성능 확장을 위한 핵심 기법.
모델 파라미터 변경 없이 프롬프트(자연어 지시문/학습 벡터)로 원하는 행동 유도.
질의응답, 상식 추론 등 다양한 분야에서 성공 -> 하지만 체계적 정리 부족.
본 논문: 프롬프트 방법론, 응용, 관련된 모델, 그리고 사용된 데이터셋, 장단점 분석.
1 서론
프롬프트 엔지니어링은 재학습/파인튜닝 없이 다양한 과업 적응 가능.
기존 패러다임과 달리, 프롬프트만으로 출력 미세조정 가능.
제로샷, 퓨샷 -> CoC 등으로 발전.
LLM/VLM 연구 많지만, 응용 중심의 체계적 리뷰 부족.
본 논문: 29개 기법을 응용별 분류, 최신 연구 성과, 한계, 비교 제시.
2 프롬프트 엔지니어링
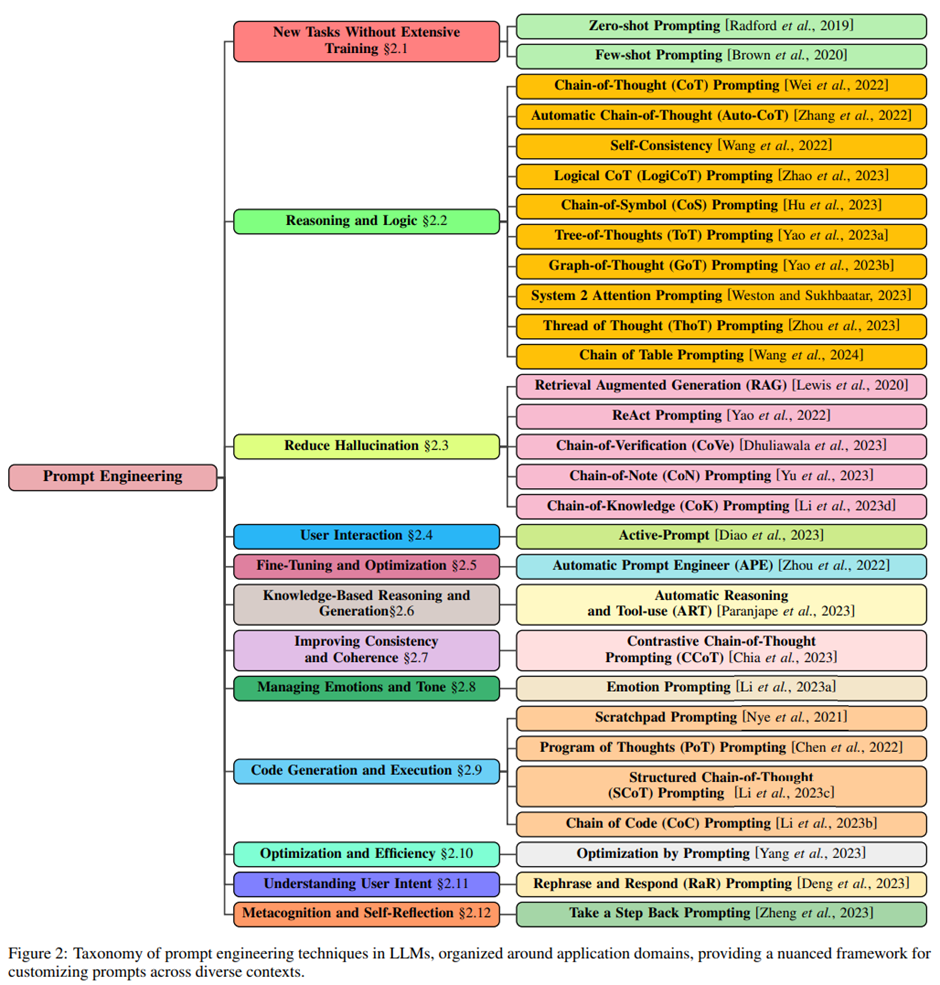
프롬프트 엔지니어링 기법들을 응용 영역에 따라 정리하고, 제로샷 프롬프트부터 최신 발전에 이르기까지 프롬프트 기법들의 진화를 간결히 개관
2.1 새로운 과업을 광범위한 훈련 없이 수행하기 (New Tasks Without Extensive Training)
Zero-Shot Prompting: 훈련 데이터 없이 프롬프트만으로 수행 ([Radford 2019]).
Few-Shot Prompting: 소수 입출력 예시 제공 -> 성능 향상, 하지만 토큰 비용, 편향 문제 ([Brown 2020]).
2.2 추론과 논리 (Reasoning and Logic)
Chain-of-Thought (CoT): 단계별 추론 촉진, PaLM 540B로 수학, 상식 추론 SOTA 달성 ([Wei 2022]).
Auto-CoT: “step-by-step” 자동 샘플링, 수동 제작 불필요 -> 정확도 소폭 향상 ([Zhang 2022]).
Self-Consistency: 다양한 추론 체인 샘플링 -> 최종 일관된 답 선택 -> 성능 대폭 향상 ([Wang 2022]).
LogiCoT: 상징 논리 적용, 잘못된 추론을 귀류법을 적용해 검증, 수정 루프 -> 오류, 환각 감소 ([Zhao 2023]).
Chain-of-Symbol (CoS): 자연어 대신 기호 사용 -> 공간 추론 향상, ChatGPT 성능 향상, Brick World 92.6%로 정확도 올림 ([Hu 2023]).
Tree-of-Thoughts (ToT): 추론을 트리 구조로 관리, 탐색 알고리즘 통합 -> CoT보다 월등히 우수 ([Yao 2023a]).
Graph-of-Thoughts (GoT): 그래프 구조로 사고 모델링 -> 비선형 추론 가능, CoT보다 성능 향상 ([Yao 2023b]).
System 2 Attention (S2A): 불필요 맥락 제거, 맥락 재생성 통해 응답 품질 향상 ([Weston 2023]).
Thread of Thought (ThoT): 긴 혼란스러운 문맥을 분할, 요약 후 종합 ([Zhou 2023]).
Chain-of-Table: 표 데이터용, SQL/DataFrame 연산 활용 -> TabFact +8.69%, WikiTQ +6.72% ([Wang 2024]).
2.3 환각(hallucination) 줄이기 (Reduce Hallucination)
RAG: 검색+생성 결합, TriviaQA 56.8%, NQ 44.5% -> 최신 지식 활용 가능 ([Lewis 2020]).
ReAct: 추론+행동 병행, Wikipedia API 활용 -> HotpotQA, Fever에서 환각 감소 ([Yao 2022]).
CoVe: 검증 질문 생성, 답변, 수정 응답 -> 오류 감소, 사실 유지 ([Dhuliawala 2023]).
CoN: 검색 문서의 신뢰성 평가, 필터링, 불확실 상황에 “모름” 대응 ([Yu 2023]).
CoK: 복잡 과업을 단계별 분해, 내외부 지식 결합 ([Li 2023d]).
2.4 사용자 인터페이스 (User Interface)
Active Prompting: 불확실성 기반 능동 학습 적용, 주석 효율화 -> Self-Consistency 능가 ([Diao 2023]).
2.5 파인튜닝과 최적화 (Fine-Tuning and Optimization)
APE: 자동 프롬프트 생성, 선택, 강화학습 기반 -> 24개 중 19개 과업에서 인간 프롬프트 능가 ([Zhou 2022]).
2.6 지식 기반 추론과 생성 (Knowledge-Based Reasoning and Generation)
ART: 외부 도구 통합, 자동화된 추론, 계산 -> BigBench, MMLU 성능 향상 ([Paranjape 2023]).
2.7 일관성과 응집력 향상 (Improving Consistency and Coherence)
CCoT: 올바른/잘못된 추론 예시 모두 제공 -> 4~16% 향상, Self-Consistency 결합 시 추가 +5% ([Chia 2023]).
2.8 감정과 어조 관리 (Managing Emotions and Tone)
Emotion Prompting: 정서 자극 문장 11개 추가 -> BIG-Bench +115%, 참가자 평가 +10.9% ([Li 2023a]).
2.9 코드 생성과 실행 (Code Generation and Execution)
Scratchpad Prompting: 중간 토큰 생성 허용 -> MBPP-aug 46.8%, 하지만 context 512 한계 ([Nye 2021]).
Program of Thoughts (PoT) Prompting: Python 인터프리터 사용, 수학, 금융 과업에서 +12% 향상 ([Chen 2022]).
Structured Chain-of-Thought (SCoT) Prompting: 프로그램 구조(순차/분기/반복) 반영 -> ChatGPT/Codex 성능 +13.79% ([Li 2023c]).
Chain-of-Code (CoC) Prompting: 코드 기반 추론, BIG-Bench Hard 84% 정확도 (+12%) -> 대소규모 모델 모두 효과 ([Li 2023b]).
2.10 최적화와 효율성 (Optimization and Efficiency)
Optimization by Prompting (OPRO): LLM을 최적화 도구로 활용, 선형 회귀, 외판원 문제 적용 -> GSM8K +8%, Big-Bench 어려운 과업 +50% ([Yang 2023]).
2.11 사용자 의도 이해 (Understanding User Intent)
Rephrase and Respond (RaR) Prompting: 질문 재구성+응답 -> 모호성 해소, 의미적 명확성 향상 ([Deng 2023]).
2.12 메타인지와 자기 성찰 (Metacognition and Self-Reflection)
Take a Step Back Prompting: 추상화->추론 2단계, PaLM-2L 적용 -> MMLU 물리, 화학 +7%, TimeQA +27% ([Zheng 2023]).
3 결론
프롬프트 엔지니어링은 LLM의 잠재력을 확장하는 변혁적 힘.
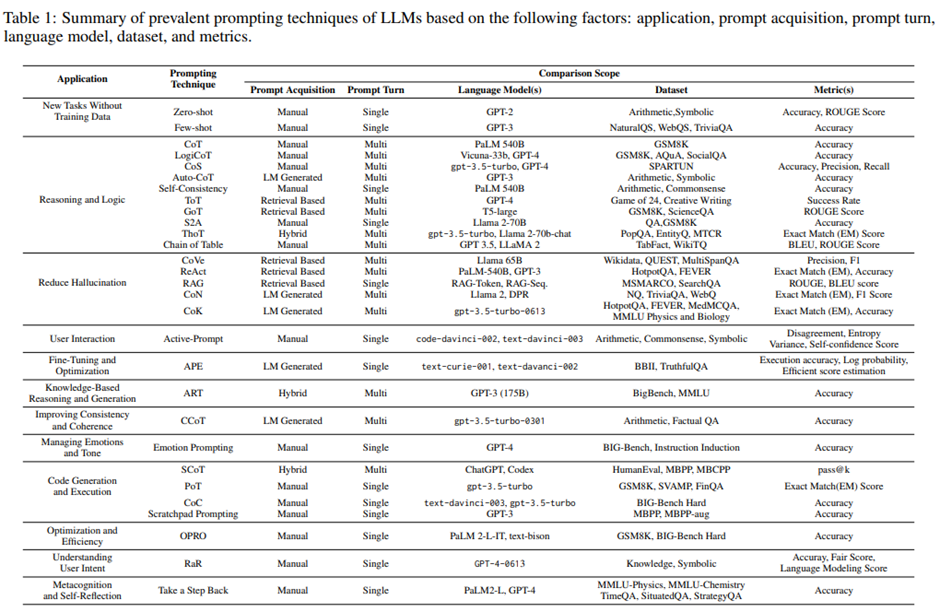
본 논문: 29개 기법을 기능별 분류, 장단점, 응용, 모델, 데이터셋 정리, 표와 다이어그램 제공.
남은 과제: 편향, 사실 오류, 해석 가능성 부족 -> 추가 연구 필요.
미래 방향: 메타러닝, 하이브리드 아키텍처 등으로 능력 강화.
윤리적 고려: 책임 있는 개발, 배포를 통해 사회적 통합 보장.
