Beyond Believability: Accurate Human Behavior Simulation with Fine-Tuned LLMs Yuxuan Lu, Jing Huang , Yan Han , Sisong Bei , Yaochen Xie, Dakuo Wang , Zheshen Wang, Qi He Amazon.com, Inc., Northeastern University, 26 Mar 2025
1 서론
LLM은 그럴 듯한 응답을 하지만, 실제로 LLM이 얼마나 실제 인간처럼 행동하는지에 대해서는 연구된 바가 부족함. Action-level에서 인간 행동의 process-centric 시뮬레이션을 평가할 수 있는 정량적인 이해가 부족함.
연구 목표: 과정 중심적이고 행위 수준의 행동 시뮬레이션 과제에서 최신 LLM의 정확성에 대한 최초의 체계적인 평가를 제공
방법: 온라인 쇼핑 플랫폼에서 수집된 대규모 실제 데이터셋 활용(3,526명의 사용자로부터 31,865개의 사용자 세션, 230,965개의 사용자 행동이 포함)
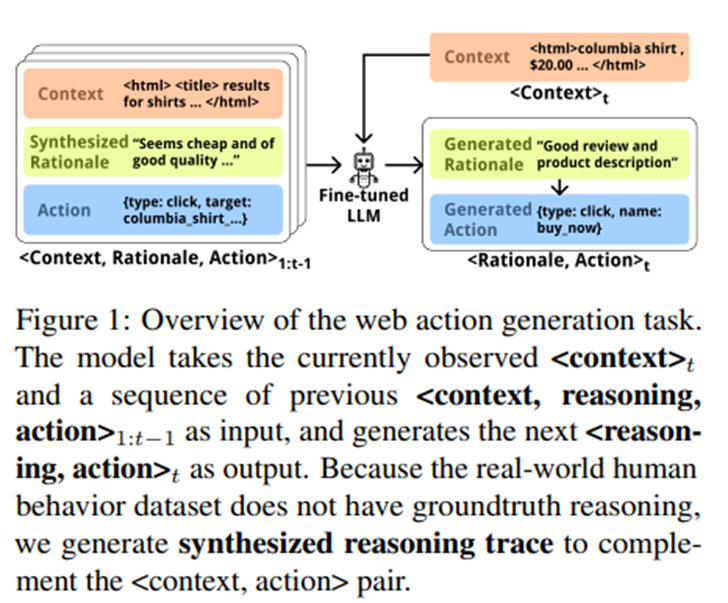
오픈소스 LLM을 파인튜닝해서 행동 시뮬레이션 과제에서의 정확성을 향상시킴.
논문의 기여: 1) 온라인 쇼핑 맥락의 실제 데이터를 이용하여, 최신 LLM이 인간의 웹 행동을 시뮬레이션하는 데 있어 최초의 정량적이고 과정 중심적인 평가를 제공, 2) 합성된 추론 흔적을 포함하여 LLM을 파인튜닝하는 것이 행동 생성 정확성을 유의미하게 향상시킨다는 것을 실증적으로 보여줌
2 관련 연구
LLM 기반 시뮬레이션은 해석 가능한 인간 행동을 모델링할 수 있음. -> 그러나 단계별 행동의 정확성은 간과함
CoT와 프롬프팅 전략을 기반으로 많은 연구들은 인간 행동 시뮬레이션에 추론 메커니즘을 도입함 -> 추론이 파인튜닝 설정에서 성능을 향상시킬 수 있는가?
3 방법
-
과제 정의
온라인 쇼핑 세션을 사용자 행동의 연속으로 정의 (검색으로 시작, 구매/종료로 끝남).
맥락: 단순화된 HTML 형식을 사용해 웹페이지의 구조화된 표현 채택 -> 핵심 구조 요소를 보존하면서 스크립트나 스타일 정보와 같은 불필요한 세부사항은 걸러냄 -
합성된 추론 흔적
행동 데이터셋에는 실제 추론 흔적이 없기 때문에, LLM을 이용해 행동의 이유를 합성.
예: 별점 4 이상 필터 클릭 → 편안한 옷을 찾고 싶어서, 평점 높은 옷을 찾고 싶어서.
이를 통해 모델은 행동뿐 아니라 행동의 이유(인간의 추론)까지 학습. -
모델 아키텍처
모델 입력: 과거 맥락(context), 과거 행동과 추론(사용자가 한 것과 그 이유).
모델 출력: 다음 행동 + 그 행동에 대한 추론.
손실 함수는 행동과 추론 토큰에 대해서만 학습(맥락 토큰에 대한 손실은 마스킹).
Llama, Qwen, Mistral 등 오픈소스 LLM을 파인튜닝.
훈련 시 세션 전체(context, action, reasoning)를 입력으로 연결.
4. 실험
데이터셋 구축: 온라인 쇼핑 시나리오에서 3,526명의 사용자로부터 31,865개의 세션이 포함되며, 총 230,965개의 사용자 행동으로 구성, 최종 결과에는 4,432건의 구매 행동과 27,433건의 세션 종료 행동.
Claude-3.5-Sonnet을 사용해 각 행동에 대한 맥락 기반 합성 추론을 생성.
평가와 메트릭
평가 데이터셋: 훈련에 사용되지 않은 데이터셋의 일부를 테스트 세트로 사용, 테스트 세트 내 사용자 세션이 파인튜닝 중 모델에 노출되지 않도록 함. 각 세션에서 두 번째 행동과 그 이후의 모든 행동을 사용, 첫 번째 행동은 선행 맥락이 없으므로 제외.
각 테스트 케이스에서, 모델은 동일한 세션 내에서의 과거 맥락, 모든 이전 행동, 추론 흔적을 제공받고, 다음 추론과 해당 행동을 모두 예측하는 과제를 수행.
총 932개의 테스트 케이스.
Baseline method
일반 목적 사전학습: 프롬프트 기반 Claude, Llama, Mistral
추론: DeepSeek-R1.
평가 메트릭(Evaluation Metrics)
최종 결과 예측: 구매 vs 종료를 F1 score로 평가.
행동 생성 정확도: 예측 행동이 유형, 대상(예: 검색창 또는 제품 링크), 속성(적용 가능한 경우, 예: 검색 키워드)까지 정답과 정확히 일치할 때만 정답 처리.
실험 설정(Experimental Setup)
비교: 동일 데이터셋으로 파인튜닝된 모델.
파인튜닝된 모델(Fine-Tuned Models): Llama 3.2, Qwen 2.5, Mistral의 다양한 버전.
베이스라인 모델(Baseline Models): Claude, Llama, Mistral, DeepSeek-R1의 다양한 버전.
(하이퍼파라미터 정리)
학습률: 2e-5
배치 크기: GPU당(per-device) = 1, 전체(global) = 64 (→ 64개의 GPU * 1 = 64)
학습 에포크: 1
스케쥴러: cosine scheduler (adaptive learning rate 조정)
컨텍스트 길이: 40k 토큰
패딩/트렁케이션: 모든 시퀀스를 40k에 맞춰 padding 또는 truncate
GPU 환경: NVIDIA H200 GPU, 64개 사용 (8노드 × 8GPU), GPU당 메모리 140GB.
평가 결과 및 분석
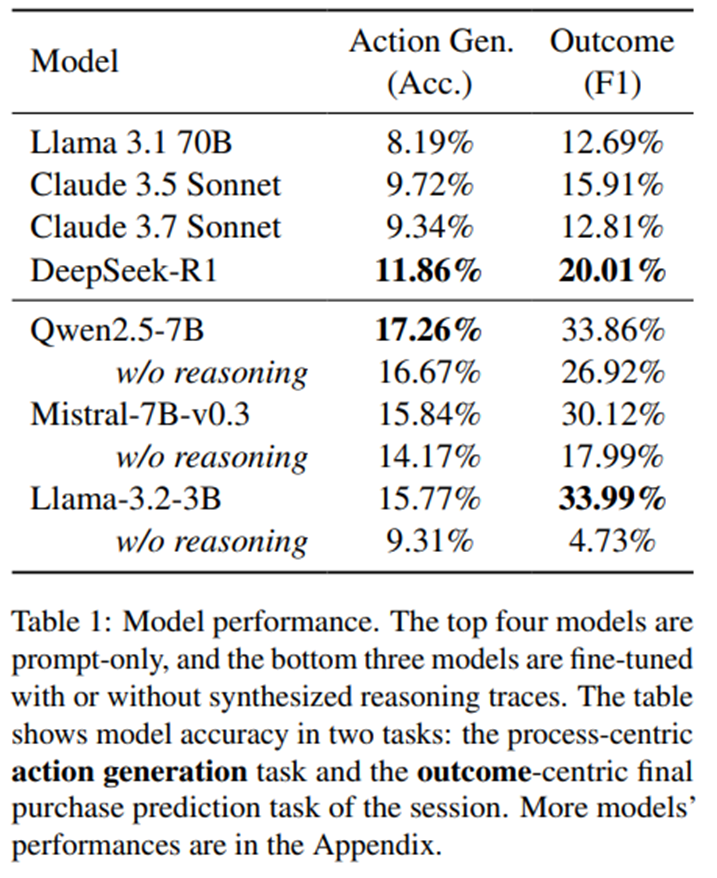
우리는 쇼핑 시나리오에서 인간 행동을 시뮬레이션하는 프롬프트 기반 LLM들의 성능을 평가함. 프롬프트 기반 LLM 은 인간 행동을 “그럴듯하게” 보이게는 하지만, 정확도는 매우 낮음.
예: DeepSeek-R1의 행동 생성 정확도 11.86% 더 높음, 결과 예측 F1 20.01%.
파인튜닝된 모델 은 성능이 크게 향상됨.
Qwen 2.5-7B: 행동 생성 정확도 17.26% (DeepSeek-R1보다 5.4% ↑).
Llama 3.2-3B: 결과 예측 F1 33.99% (기존 대비 큰 향상).
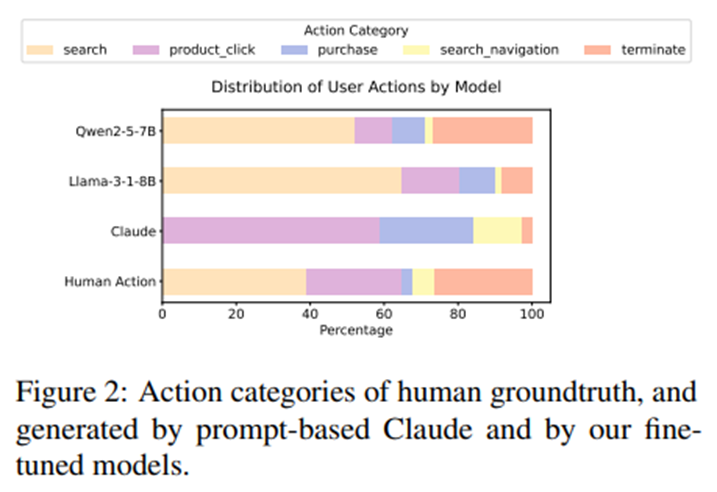
행동 분포 비교
파인튜닝된 모델은 검색, 클릭, 탐색 행동의 비율이 인간과 유사.
반면 Claude 3.5 Sonnet은 검색 1회 + 과도한 구매 비율 -> 실제 사용자와 다름.
즉, 파인튜닝은 단순히 정확도 향상뿐 아니라 행동 패턴의 현실성도 개선.
제거 연구(Ablation Study)
추론 흔적(reasoning)을 제거하고 훈련했을 때, 모델 성능이 크게 하락.
예: Qwen 2.5-7B → F1 33.86%(추론 포함) → 26.92%(추론 제거).
합성된 추론 흔적을 통합하는 것이 행동 생성과 최종 결과 모델링 모두를 향상시키며, 인간 행동 시뮬레이션을 위한 파인튜닝에서 그 가치가 큼.
논의
일반 LLM은 언어 기반 작업에서는 “그럴듯한” 결과를 내지만, 정확한 행동 예측은 불가능.
합성된 추론 흔적은 해석 가능성 향상뿐 아니라, 맥락에 맞는 인간 유사 의사결정을 유도하는 안내 메커니즘 역할을 함. 따라서 단순 프롬프트 기반 접근을 넘어서, 도메인 특화 파인튜닝 + 추론 증강 데이터가 필요함.
향후 연구 방향:
데이터셋 규모 확장(강건성↑, 일반화↑).
사용자 페르소나 통합(개인화 시뮬레이션).
강화학습(RL) 활용해 추론 생성 정제.
비전-언어 모델(VLMs) 결합해 복잡한 웹 환경의 그래픽 인터페이스 이해 강화.
7. 결론
실제 행동 데이터 + 합성된 추론 흔적을 이용한 파인튜닝은 행동 생성 정확도와 결과 예측 모두 개선.
이는 온라인 쇼핑뿐 아니라 다양한 LLM 에이전트 응용에서 정확하고 설명 가능한 인간 행동 시뮬레이션을 가능케 할 수 있음을 시사.
8. 윤리적 고려사항
인간 평가 부재: 생성된 추론이 실제로 사람의 이해와 신뢰에 도움이 되는지 검증되지 않음.
단일 과제(온라인 쇼핑)만 실험 -> 일반화 한계.
합성된 추론 흔적이 실제 인간 추론과 얼마나 맞는지는 불확실.
합성 과정에서 편향이 유입될 가능성 존재.
행동 공간을 단순화(클릭, 입력, 종료)했음 -> 스크롤, 대기, 호버 등 추가해야 더 현실적인 시뮬레이션 가능.
