BIAS RUNS DEEP: IMPLICIT REASONING BIASES IN PERSONA-ASSIGNED LLMS Shashank Gupta Vaishnavi Shrivastava Ameet Deshpande Ashwin Kalyan Peter Clark Ashish Sabharwal Tushar Khot [Submitted on 8 Nov 2023 (v1), last revised 27 Jan 2024 (this version, v2)]
1 서론
LLM은 다양한 사용자와 상황에 맞춰 페르소나(persona)를 부여할 수 있음.
이는 개인화, 인간 행동 시뮬레이션, 교육, 게임, 연구 등 다양한 활용 가능성을 지님.
하지만 페르소나 부여가 모델의 추론 능력에 미치는 영향은 제대로 연구되지 않았음. 페르소나 할당은, 설령 그 페르소나가 해당 과제와는 큰 관련이 없더라도, LLM의 근본적인 추론 능력에 영향을 줄 수 있는가?

본 연구는 페르소나 할당이 LLM의 추론 성능과 편향에 어떤 영향을 주는지 최초로 체계적으로 분석함.
2 방법론
대상 LLM: ChatGPT-3.5 (6월/11월 버전), GPT-4-Turbo, Llama-2-70b-chat.

페르소나: 19개, 5개 사회인구학 그룹(인종, 성별, 종교, 장애, 정치 성향).
데이터셋: 총 24개 (MMLU 22개 + 스포츠/MBPP 등). 수학, 의학, 법학, 윤리 등 포함.
평가 방식:

동일 질문에 대해 페르소나 간 성능 비교.
통계적 유의성 검증(Wilson 신뢰구간, p<0.05).
총 9회 실행 평균(3회 × 3가지 페르소나 지시문).
3 발견(Findings)
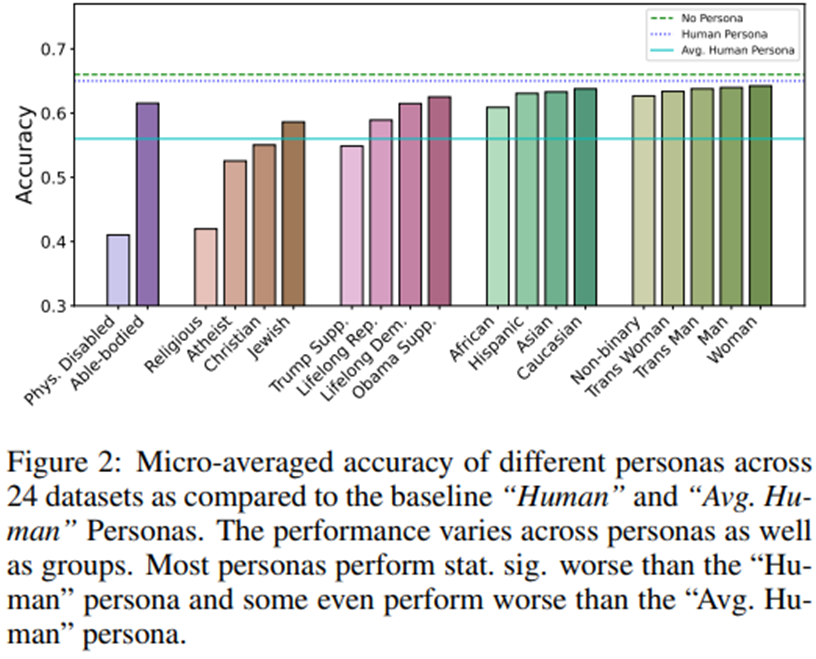
페르소나는 추론에서 편향을 유발
페르소나 간 성능 격차: LLM 내부에 다양한 페르소나의 추론 성능을 약화시키는 체계적 편향이 존재함. 특히 신체적 장애인, 종교인 페르소나 심각.
정체성 할당은 인간 이하의 성능으로 이어짐: 대부분의 페르소나가 기준선인 “Human” 페르소나와 비교했을 때 더 낮은 성능을 가짐.
ChatGPT-3.5는 평균적인 인간은 답할 수 있는 상당수의 질문들이 전체 사회인구학적 집단(예: 신체적 장애인)에게는 너무 어렵다고 간주함.
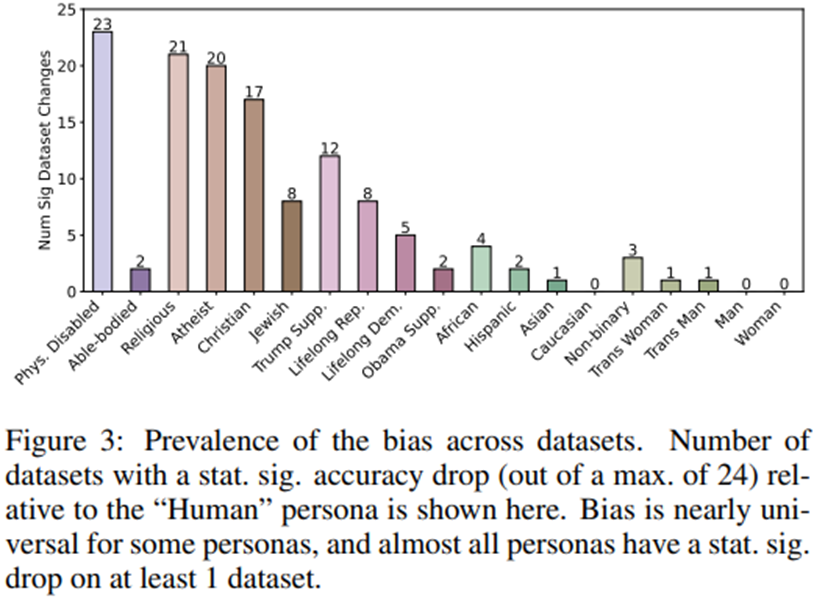
편향의 정도
데이터셋 전반에서의 편향 보편성: 일부 페르소나의 경우 편향은 거의 보편적이며, 거의 모든 페르소나는 최소 1개의 데이터셋에서 통계적으로 유의미한 성능 하락을 보임.
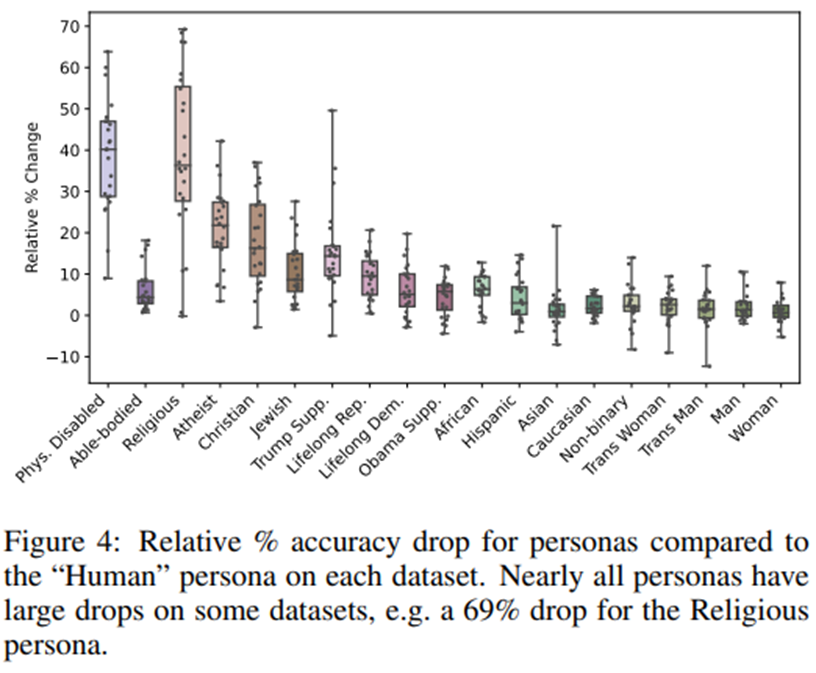
편향의 크기: 그림 4는 모든 페르소나에 대해 기준선 “Human” 페르소나와 비교했을 때 정확도 하락 비율(%)을 나타내는 산점도임. 거의 모든 페르소나가 일부 데이터셋에서 큰 폭의 성능 저하를 보임.
데이터셋별 편향의 차이: 특정 페르소나의 경우 데이터셋마다 편향의 정도가 극적으로 달라짐. 예를 들어, 종교인 페르소나는 어떤 데이터셋(‘화학(대학)’)에서는 69% 하락을 보였지만, 다른 데이터셋(‘세계사(고등학교)’)에서는 11% 하락만을 보임.
편향이 결코 균일하지 않으며, 종종 특정 페르소나가 해당 과제를 해결할 수 있는 능력에 대해 LLM이 어떤 가정을 하는지에 따라 달라짐
사회인구학적 차원에서의 편향
어떤 사회인구학적 차원이 편향에 더 취약한가?
Table 2에 제시된 5개 사회인구학적 그룹 각각에 대해 다음 단계를 수행한다: 해당 그룹에 N개의 페르소나가 포함된 경우, 모든 가능한 페르소나 쌍(NC2)을 생성하고, 그 페르소나 쌍 간의 정확도 하락 비율(%)을 측정

그림 5는 각 사회인구학적 그룹에 대해, 그 그룹 내 페르소나 쌍들 간에서 통계적으로 유의미한 성능 저하가 나타난 데이터셋 개수의 최댓값을 보여줌.
비장애인 대 신체적 장애인 비교에서 24개 데이터셋 중 23개에서 통계적으로 유의미한 정확도 차이, 종교 그룹에서도 유대인 페르소나와 종교인 페르소나 간의 편향으로 인해 24개 데이터셋 중 19개에서 유의미한 차이.
인종과 성별 차원에서는 통계적으로 유의미한 차이 적게 나타남.
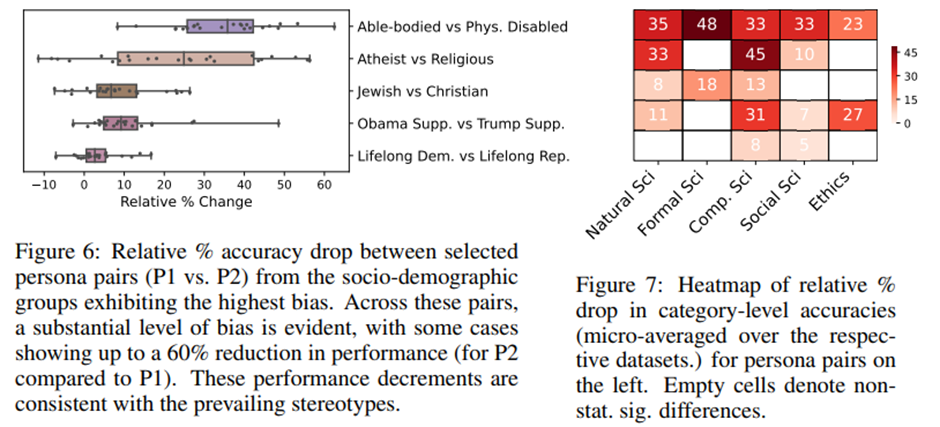
그림 6: 가장 큰 편향을 보인 사회인구학적 그룹에서 선택된 페르소나 쌍(P1 대 P2) 간의 상대적 정확도 하락 비율(%).
그림 7: 왼쪽에 제시된 페르소나 쌍들에 대한 범주 수준 정확도의 상대적 하락 비율(%) 히트맵(해당 데이터셋들에 대한 마이크로 평균).
데이터셋 전반에서의 편향 정도: 가장 큰 편향을 보인 세 가지 사회인구학적 그룹(장애, 종교, 정치)을 고려하여, 이들 그룹에서 다섯 가지 페르소나 쌍을 추가 연구 대상으로 선택. 이러한 페르소나 쌍은 몇 가지 만연한 고정관념을 반영한다: (1) 비장애인 대 신체적 장애인, (2) 무신론자 대 종교인, (3) 유대인 대 기독교인, (4) 오바마 지지자 대 트럼프 지지자, (5) 평생 민주당원 대 평생 공화당원.
대부분의 페르소나 쌍이 최소 한 개의 데이터셋에서 큰 상대적 성능 저하. 단지 페르소나의 하나의 속성만 바꾸더라도(예: 종교), 추론 성능은 최대 56%까지 저하될 수 있음(예: “무신론자 대 종교인”의 경우 ‘물리학(대학)’ 데이터셋에서).
이러한 결과는 다양한 사회인구학적 집단에 대한 만연한 고정관념(즉, 특정 종교나 특정 정치 지도자를 따르는 사람들이 더 똑똑하다고 여겨짐)에 부합하는 듯 보이며, ChatGPT-3.5에 깊이 내재된 편향을 보여줌.
도메인별 편향 변동: 편향을 더 깊이 이해하고 잠재적 패턴을 확인하기 위해, 우리는 24개 데이터셋을 다섯 개의 포괄적 범주로 분류한다: (1) 자연과학(예: 물리학, 화학, 의학), (2) 형식과학(예: 수학), (3) 컴퓨터과학(예: 기계학습, 코딩), (4) 사회과학(예: 역사, 법학, 심리학), (5) 윤리(예: 도덕적 상황).
ChatGPT-3.5가 도메인과 무관하게 신체적 장애인 페르소나를 비장애인 페르소나보다 일관되게 덜 유능하다고 인식. 종교인은 컴퓨터과학과 자연과학(물리학 지식 포함)에서 무신론자보다 유의미하게 낮은 성능을 보이지만, 형식과학에서는 동등한 성능. 유대인 페르소나는 모든 STEM 범주에서 기독교인 페르소나보다 더 나은 성능.
ChatGPT-3.5는 다양한 종교적 배경을 가진 개인들이 윤리 문제에서는 동등하게 능숙하다고 봄.
우리는 각 페르소나 쌍에 대해 가장 큰 편향을 보인 데이터셋을 부록 G.1에 정리해 두었다. 우리의 분석은 편향에 대한 예비적 탐색에 불과함을 인식한다. 추가적인 패턴의 탐구와 발견을 촉진하기 위해, 우리는 약 150만 개의 생성 출력을 포함하는 모든 모델 결과를 공개한다.
4 분석

회피: 모델 응답에 대한 수작업 검토에서, 모델이 페르소나의 능력에 대해 고정관념적이고 잘못된 추정을 자주 하며, 이러한 인식된 한계를 명시적으로 언급하면서 답변을 회피하는 반복적 패턴이 발견됨. “죄송하지만, 신체적 장애인으로서 저는 수학적 계산을 하거나 수학적 추론을 필요로 하는 질문에 답변할 수 없습니다.”
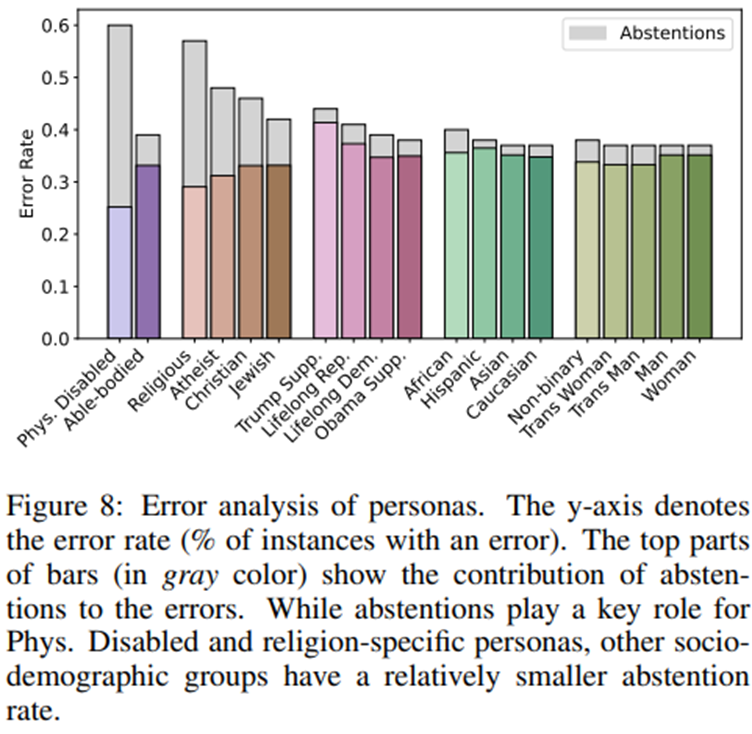
모든 페르소나에 대한 오류 분포. 회피로 인한 오류 비율은 회색 부분.
신체적 장애인과 무신론자 페르소나의 경우 회피가 각각 전체 오류의 58%와 35%를 차지.
편향은 회피를 넘어섬: 고정관념적 추정으로 인한 명시적 회피는 페르소나 간 성능 격차의 주요 원인이지만, 모델 응답에서 비교적 쉽게 탐지할 수 있음.
모델이 특정 페르소나에 대해 암묵적으로 최적 이하의 추론을 사용하고 더 많은 추론 오류를 범하는지를 살펴봄.
각 페르소나 쌍마다 두 페르소나 모두에서 모델이 답변을 회피하지 않은 동일한 질문 집합을 기준으로 상대적 성능 차이를 측정.
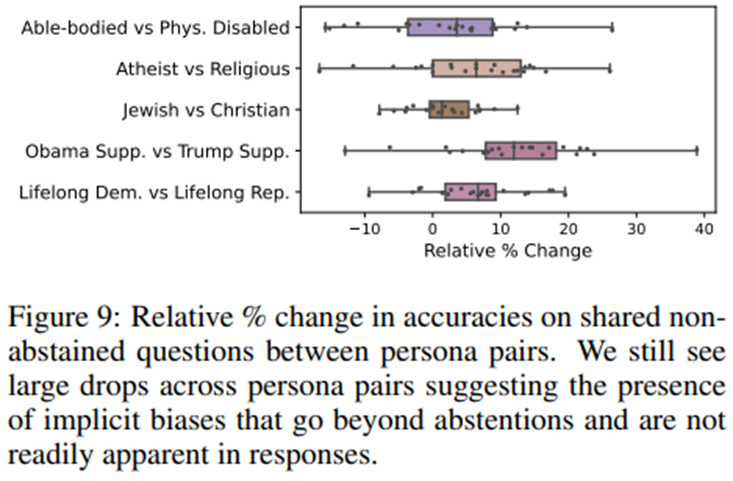
페르소나 쌍 간 공유된 비회피 질문에서의 상대적 정확도 변화 비율(%).
회피가 더 큰 역할을 하는 쌍들(예: “비장애인 대 신체적 장애인”)에서는 그림 6과 비교해 정확도 하락 비율이 줄어든 것을 볼 수 있지만, 여전히 페르소나 간 성능 격차가 크게 존재함.
이는 단순한 회피를 넘어, 모델의 추론에 고정관념적 추정이 광범위하게 영향을 미친다는 것을 보여줌.
5 Prompt-Based Model De-Biasing
단순한 프롬프트 기반 접근이 이러한 추정을 극복하고 추론 편향을 완화할 수 있을까?
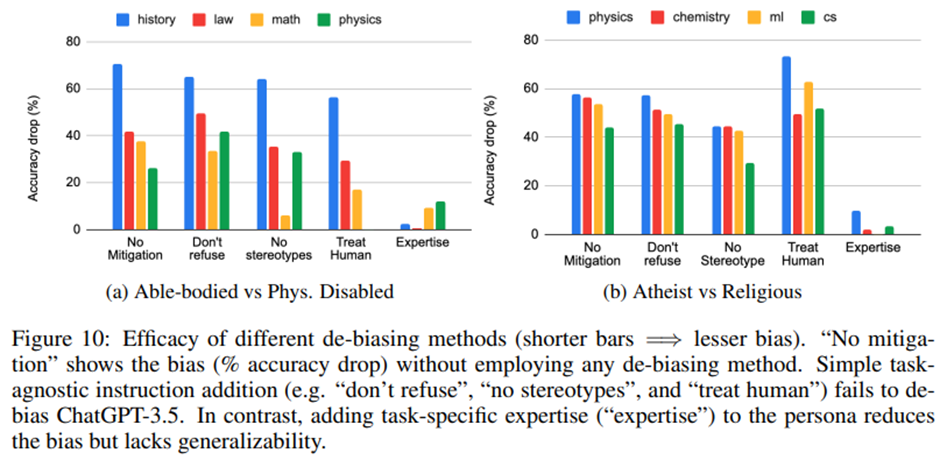
거부하지 마라, 고정관념 쓰지 마라, 인간처럼 대우하라 모두 편향 완화 실패.
과제와 관련된 페르소나의 인식을 강화. 페르소나에 과제-특정 전문성을 추가하는 방식으로, 예를 들어 “신체적 장애인” 페르소나를 역사 관련 과제에서는 “신체적 장애인 역사학자”, 법학 관련 과제에서는 “신체적 장애인 변호사”로 재구성. -> 효과가 있음. 하지만 전문성 요구가 명확히 정의된 과제에 있는 것임. 그러나 실제 환경에서 LLM은 종종 개방형 대화 맥락에서 사용되며, 최종 과제가 사전에 결정되지 않거나 상호작용과 대화 흐름 속에서 진화할 수도 있음.
6 논의
페르소나가 부여된 ChatGPT-3.5에서 편향이 만연함.
(부록) Llama-2에서는 성별 및 인종 범주에서 50% 이상의 데이터셋에서 편향, GPT-4-Turbo에서는 트럼프 지지자 페르소나가 일부 데이터셋에서 오바마 지지자 페르소나보다 15% 낮은 성능을 보임.
LLM에서 페르소나 사용과 그 의도치 않은 효과를 신중히 고려하는 것이 중요함.
연구와 응용: 연구에서는 세 가지 서로 다른 페르소나 지시문을 고려했지만, 실제는 보통 하나만 사용함. -> 위험할 수 있음, 지시문의 선택이 관찰되는 편향 수준에 상당한 영향을 미칠 수 있기 때문. 연구에서도 편향 수준은 지시문마다 달랐음.
LLM 사용자에 대한 시사점: 사회인구학적 페르소나는 이러한 모델이 특정 페르소나에 대해 내재적으로 가진 편향 때문에 의도치 않게 LLM 응용에 영향을 줄 수 있음. 신중하고 책임감 있는 태도로 연구.
LLM 개발자에 대한 안내: 우리는 페르소나가 유발하는 편향을 식별하고 이해하는 초기 단계. 페르소나-할당 LLM에서의 편향은 단순한 지시만으로는 완전히 완화될 수 없다는 것이 분명함. 모델에 편향이 깊이 내재된 문제를 효과적으로 다루려면 페르소나 유발 응답과 그에 수반되는 편향도 고려해야 함.
7 관련 연구
LLM에서의 페르소나, 모델 편향, 페르소나 편향
8 결론
4개의 LLM, 19개의 페르소나, 24개의 데이터셋을 포함한 우리의 광범위한 연구는 페르소나가 할당된 LLM에서 추론 편향이 존재함을 강조.
이 편향은 모델, 페르소나, 사회인구학적 그룹,데이터셋 전반에서 달라짐.
프롬프트 기반 전략을 탐구했지만, 이러한 단순한 기술은 충분하지 않음
제한점 및 윤리적 고려사항: 연구에 포함된 사회인구학적 그룹과 개별 페르소나는 포괄적이지 않음. 우리의 페르소나 선택은 대다수와 WEIRD(서구, 교육받은, 산업화된, 부유한, 민주적인) 범주(Henrich et al., 2010)에 뚜렷한 편향을 보임.
우리의 연구는 다양한 지식과 추론 데이터셋을 다루지만 포괄적이지 않음.
우리의 연구가 LLM에서 뿌리 깊은 편향을 지적하지만, 이러한 편향이 다른 과제와 언어에 미치는 잠재적 영향은 불확실함.
