Scaling Synthetic Data Creation with 1,000,000,000 Personas Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu Tencent AI Lab Seattle https://github.com/tencent-ailab/persona-hub, [Submitted on 28 Jun 2024 (v1), last revised 8 May 2025 (this version, v3)]
1 서론
합성 데이터는 LLM 학습에서 점점 중요해지고 있음.
문제: 양은 늘리기 쉽지만, 다양성을 확보하는 데 어려움이 있음.
기존 방식
인스턴스 기반(instance-driven): seed corpus에 의존(즉, 시드 코퍼스 안의 인스턴스를 기반으로 새로운 인스턴스를 만들어냄) -> 확장성 부족.
키포인트 기반(key-point-driven): 지식 요소를 나열 -> 전 범위 포괄 불가능.

제안: 페르소나 기반 데이터 합성 방법론. 프롬프트에 페르소나를 추가하여 LLM이 특정 관점에서 데이터를 만들도록 유도 -> 다양하고 대규모 합성 데이터 생성 가능.
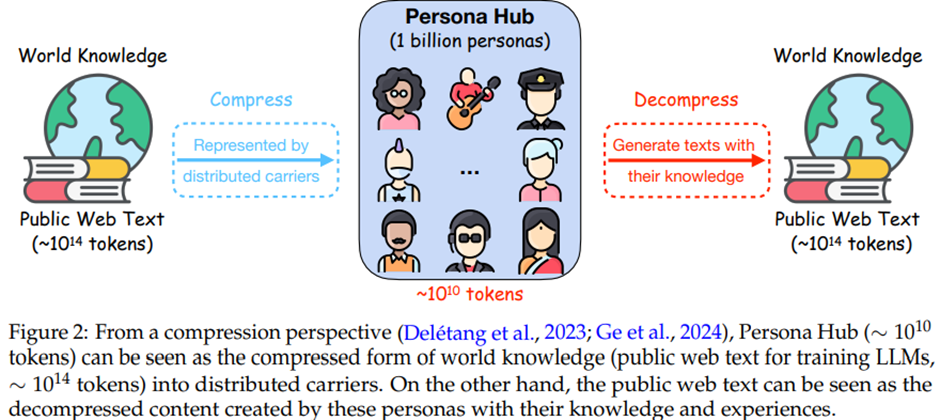
2 Persona Hub
방대한 웹 데이터에서 10억 개 페르소나를 자동 생성.
방법
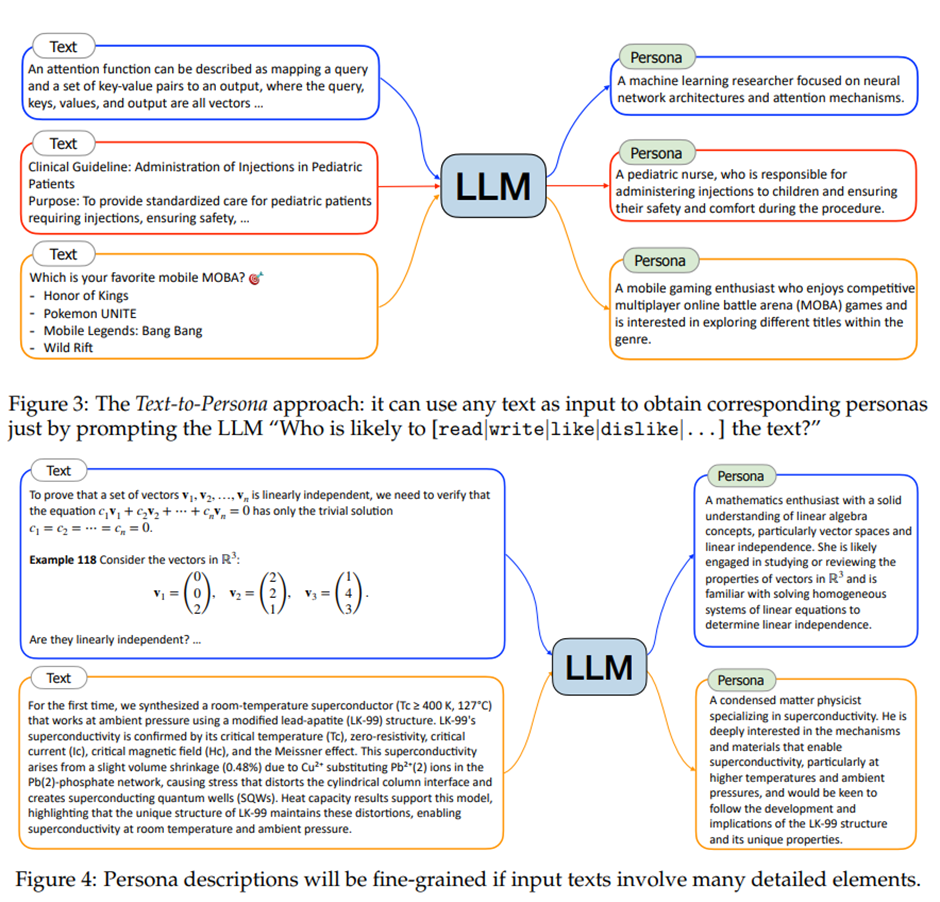
Text-to-Persona: 웹 텍스트 기반 -> 이 글을 읽거나 쓰거나 좋아하거나 싫어할 사람은 누구인가?
거의 모든 측면을 포괄하는 페르소나를 합성할 수 있는 매우 확장성 높은 방법
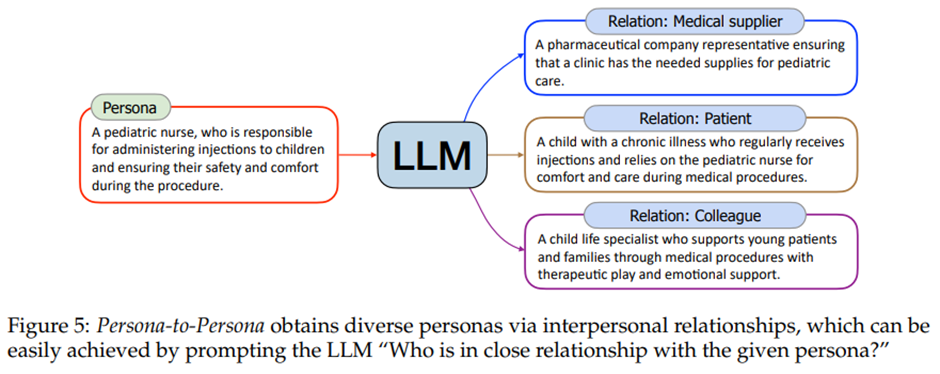
Persona-to-Persona: 기존 페르소나에서 관계 확장 (간호사 -> 아동, 쉼터 직원 -> 거지, 주연 배우 -> 영화의 무대 뒤 스태프).
6단계 분리 이론(six degrees of separation theory, Travers & Milgram, 1977)에 따름.
중복 제거
MinHash 기반 중복 제거: 페르소나 설명의 n-그램 특징을 기반으로 MinHash(Broder, 1997)를 사용해 중복을 제거. 페르소나 설명은 보통 문서보다 훨씬 짧아 1~2문장에 불과하기 때문에, 우리는 1-그램과 128의 시그니처 크기를 사용. 유사도 임계값을 0.9로 설정.
임베딩 기반 중복 제거: MinHash 이후 임베딩 기반 중복 제거. 텍스트 임베딩 모델(예: OpenAI의 text-embedding-3-small 모델)을 사용하여 각 페르소나의 임베딩을 계산하고, 코사인 의미 유사도가 0.9를 초과하는 페르소나들을 걸러냄.
우리는 0.9를 임계값으로 선택했지만, 필요에 따라 더 유연하게 조정할 수 있음. 예를 들어, 인스턴스 수에 대한 요구가 크지 않고(예: 100만 개 인스턴스만 필요) 다양성에 대한 요구가 높은 경우, 더 엄격한 중복 제거 기준을 적용할 수 있음(예: 유사도가 0.5를 초과하는 페르소나들을 제거).
최종 결과: 1,015,863,523명 페르소나 확보.
3 페르소나 기반 합성 데이터 생성 (Persona-driven Synthetic Data Creation)
단순히 프롬프트의 적절한 위치에 페르소나를 통합 -> LLM이 해당 관점에서 데이터 생성.

세 가지 프롬프트 방식: Zero-shot, Few-shot, Persona-enhanced few-shot
4 활용 사례 (Use Cases)
기술적인 논의를 수학 문제 합성(4.1절)에 대해서만 자세히 제공하고, 다른 활용 사례에 대해서는 세부 논의를 생략.
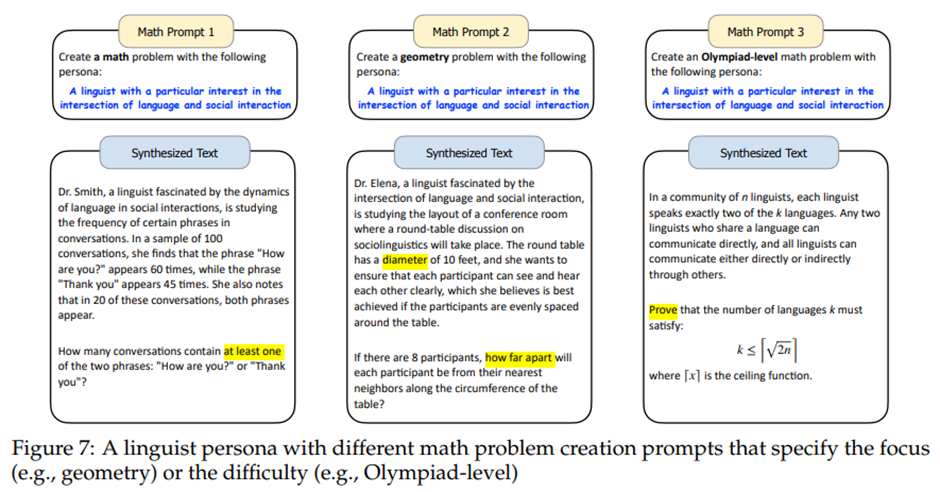
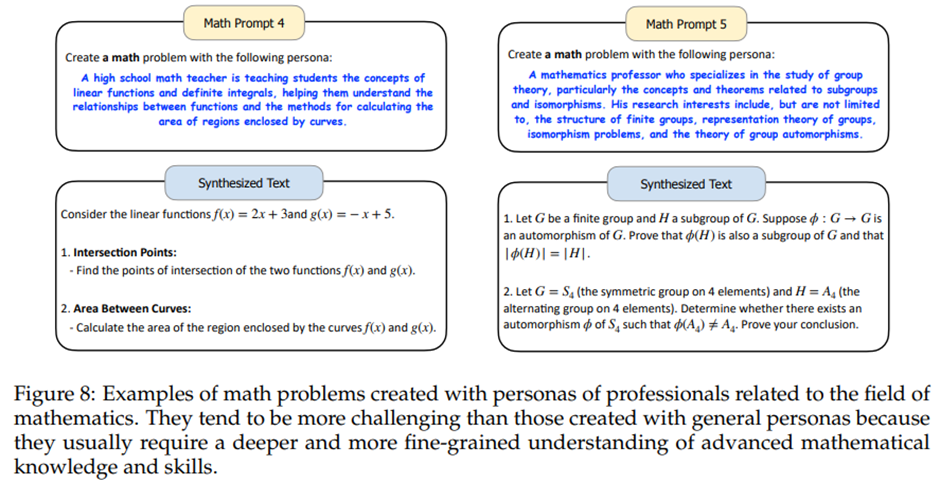
- 수학 문제
언어학자 페르소나를 주었을 때, LLM은 계산언어학의 맥락에서 수학 문제를 생성
일반 페르소나 vs 수학 전문가 페르소나 -> 난이도, 세분화된 수학 지식과 기술 차이
평가
데이터: 109만 개 문제 합성함. 본 연구는 새로운 합성 데이터를 생성하는 데 초점을 두고 있기 때문에, 문제의 해답 합성은 gpt-4o(assistant)를 사용해 단순히 생성. 무작위로 2만 개를 합성 테스트 세트로 보류하여 평가에 활용, 나머지 107만 개 문제는 학습에 사용
테스트 세트
합성 테스트 세트 (분포 내, In-distribution): 보류된 2만 개 문제 세트는 107만 개의 학습 인스턴스와 동일한 방식으로 생성되었으므로, 분포 내 테스트 세트로 간주할 수 있음
MATH (분포 외, Out-of-distribution): LLM의 수학적 추론 능력을 평가하기 위해 가장 널리 인정받는 벤치마크
정답 일치 검사 (Equality Checking)
우리는 MATH 벤치마크에서 정답 일치를 확인하기 위해 OpenAI와 동일한 평가 프로토콜을 따름. 합성 테스트 세트의 경우, 유사한 방법을 사용하지만 정답 검사기로 gpt-4-turbo-preview 대신 Llama-3-70B-Instruct를 사용
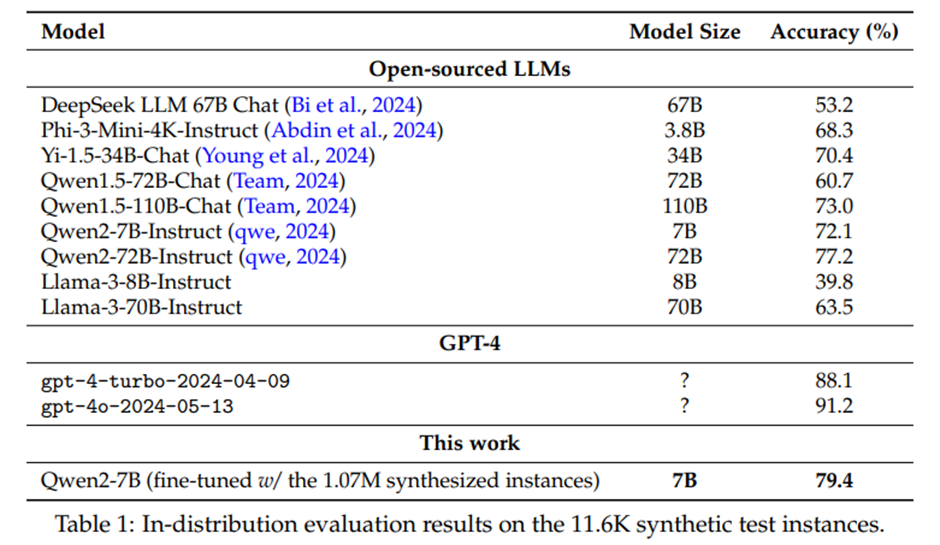
표 1은 11,600개의 합성 테스트 인스턴스에 대한 분포 내(ID) 평가 결과
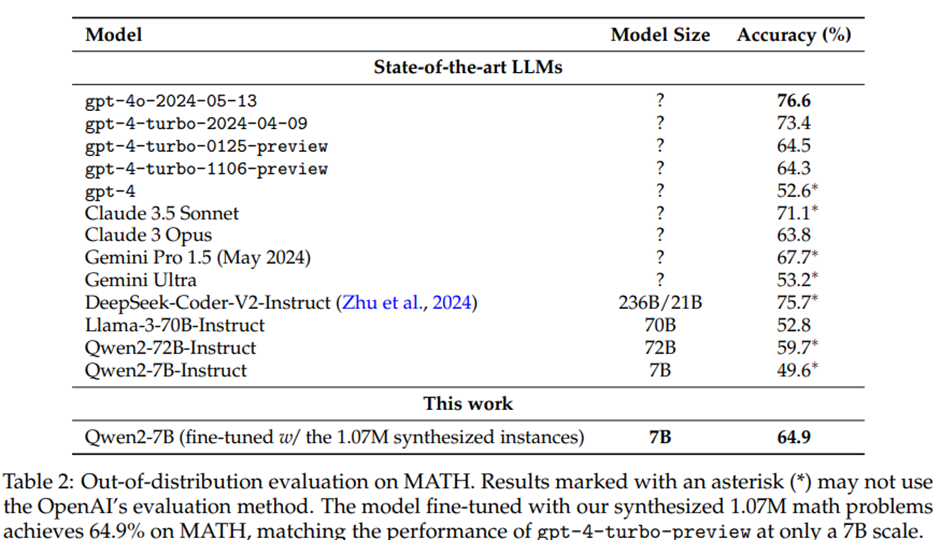
표 2는 MATH에 대한 평가 결과
Qwen2-7B 학습, 두 개의 테스트 세트에서 그리디 디코딩(greedy decoding) 출력을 평가 -> MATH 벤치마크 64.9% (gpt-4-turbo-preview 수준).
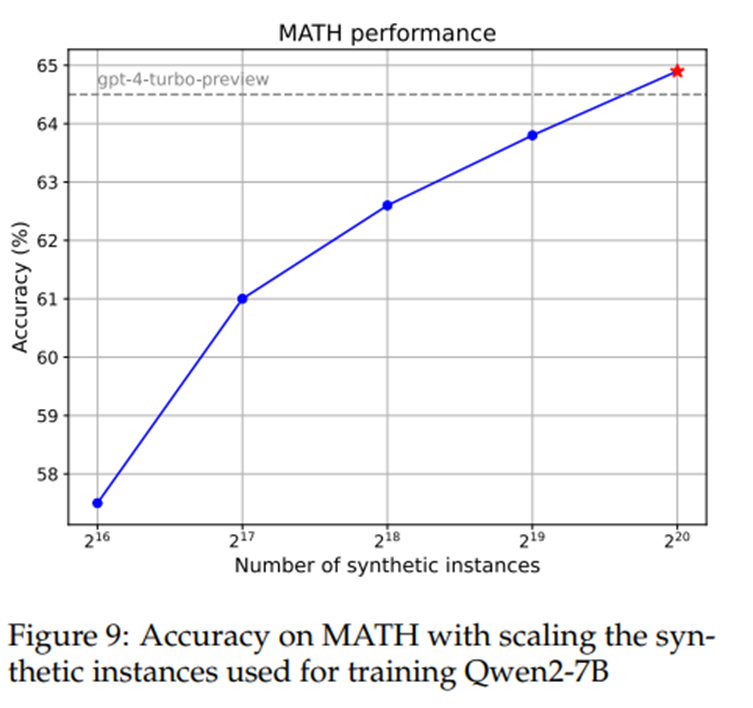
전문가 검증: 중국의 고등학교 및 대학교 수준 수학 지식을 포함하는 200개의 도전적인 문제를 샘플링하여, 두 명의 수학 전문가에게 타당성을 평가하게 함. 96.5% 타당성.
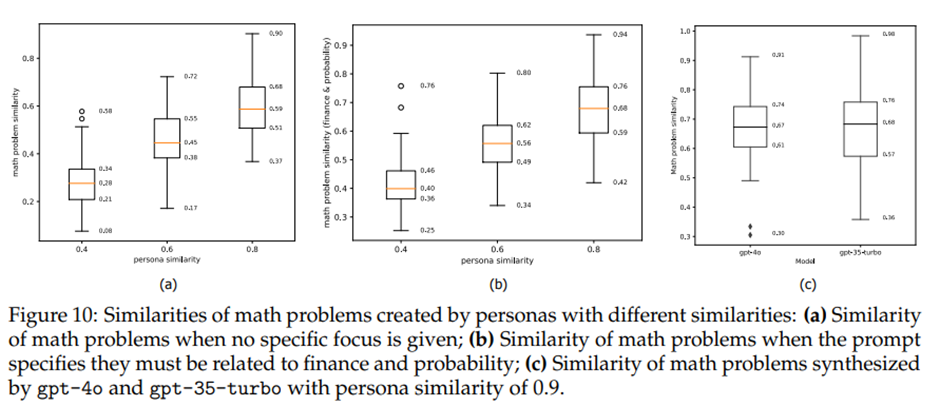
프롬프트 내 페르소나의 차이가 합성된 수학 문제에 미치는 영향 살펴봄.
의미적 유사도 0.4, 0.6, 0.8을 각각 가지는 페르소나 쌍 100개 샘플링, 각 페르소나 쌍을 사용하여 그리디 디코딩(즉, temperature=0)으로 수학 문제 쌍 생성, 이 수학 문제 쌍의 의미적 유사도를 계산.
합성된 수학 문제들의 의미적 유사도가 해당하는 페르소나들의 유사도와 상관관계를 가지지만 그보다 낮음. 프롬프트에 더 구체적인 제약(예: 금융과 확률에 관한 수학 문제)을 추가하면, 합성된 수학 문제들의 유사도는 더 높아지는 경향이 있음(그림 10(b)). 그림 10(c)에서는 유사도가 매우 높은 페르소나들(유사도=0.9)을 사용하여 gpt-4o와 gpt-35-turbo가 생성한 수학 문제들의 유사도를 테스트했고, 결과로는 gpt-4o와 gpt-35-turbo가 만든 수학 문제들의 의미적 유사도가 크게 다르지 않음. 대부분의 합성된 수학 문제들의 유사도는 0.6~0.75 범위에 속했으며, 이는 페르소나의 유사도(0.9)보다 훨씬 낮음.
- 논리 추론 문제

전통적 논리 문제 + Ruozhiba 스타일 문제 모두 합성 가능.
참고: ruozhiba 그대로의 의미는 '지적 장애가 있는 막대'로, 흥미롭고 어리석거나 신중하게 설계된 문장이 많이 포함되어 있으며, 그 중 일부는 중국어 원어민에게도 어려운 문장임. 예) 爸爸再婚,我是不是就有了个新娘?
- 지시문 (Instructions)

사용자-LLM 대화 시뮬레이션.
실제 사용자 지시문과 유사한 결과 생성.
더 많은 예시에 관심 있는 독자는 zero-shot 및 페르소나 강화 2-shot 프롬프트를 통해 합성된 5만 개의 지시문이 공개되어 있으니 이를 참고할 수 있음.
- 지식이 풍부한 텍스트

특정 페르소나의 관점에서 Quora 글 등 작성.
Quora: 질의응답 사이트
다양한 주제, 깊이 있는 콘텐츠 확보.
- 게임 NPC


실제 페르소나를 게임 캐릭터로 투영.
WoW, 천애명월도 사례 제시.
- 도구(함수) 개발

페르소나의 필요에 맞는 함수 인터페이스 정의 -> 이후 LLM이 직접 호출 가능.
5 광범위한 영향과 윤리적 고려사항 (Broad Impact and Ethical Concerns)
광범위한 영향
-
패러다임 전환:
인간이 데이터를 만들고, LLM이 처리하는 기존 방식에서 -> LLM이 스스로 데이터를 생성하는 방향으로 변화. -
현실 시뮬레이션:
다양한 인구 집단을 시뮬레이션 -> 제품 반응, 정책 반응 예측 가능.
가상 사회 구축 가능 (샌드박스, 메타버스). -
LLM 기억 접근:
10억 페르소나로 LLM의 내부 지식 거의 전부를 끌어낼 가능성.
윤리적 고려사항
데이터 보안: LLM 학습 데이터를 사실상 유출, 복제 가능
잘못된 정보: 다양한 문체가 탐지를 어렵게 해, 가짜 뉴스, 데이터 오염 문제 심화.
6 결론 및 향후 연구 (Conclusion and Future Work)
우리는 새로운 페르소나 기반 데이터 합성 방법론을 제안하고, 웹 데이터에서 자동으로 선별된 10억 개의 다양한 페르소나로 구성된 Persona Hub를 소개함.
향후 연구
페르소나 설명을 더 세밀하게(위키백과 수준).
멀티모달 LLM으로 확장.
슈퍼 페르소나(super personas)를 통한 초지능 탐구.
