SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS Xuezhi Wang Jason Wei Dale Schuurmans Quoc Le Ed H. Chi Sharan Narang Aakanksha Chowdhery Denny Zhou Google Research, Brain Team xuezhiw@google.com, dennyzhou@google.com, Published as a conference paper at ICLR 2023
1 서론
대규모 언어 모델(LLM)은 최근 다양한 NLP 과제에서 뛰어난 성과를 보이고 있지만, 여전히 복잡한 추론(reasoning) 과제에서는 한계를 드러냄. 이전 연구(Wei et al., 2022)는 모델이 단순히 답만 내놓는 대신 중간 추론 단계(Chain of Thought, CoT)를 생성하도록 프롬프트를 설계하면 추론 능력이 크게 향상된다는 사실을 보여줌.
예를 들어 “주차장에 차가 3대 있고 2대가 더 들어오면?”이라는 문제에 대해, 모델이 바로 “5”라고 대답하기보다 “3대 있고 2대가 더 왔으니 3+2=5”라고 생각의 과정을 서술하게 하면 정확도가 올라감.
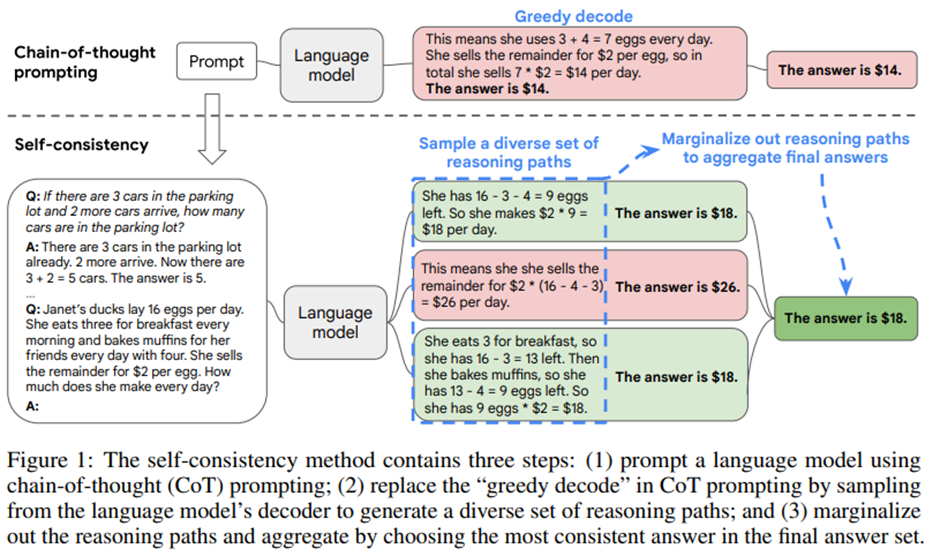
그러나 CoT는 탐욕적(greedy) 디코딩으로 하나의 추론 경로만을 생성. 때문에 모델이 잘못된 방향으로 사고를 시작하면 전체 결과가 틀려버림. -> 저자들은 Self-Consistency(자기 일관성) 라는 새로운 디코딩 전략을 제안.
이 방법은 “하나의 사고 흐름”이 아닌 “여러 개의 가능한 사고 흐름”을 샘플링하여, 가장 일관된 답을 다수결 방식으로 선택. 인간이 여러 사고 경로를 검토한 후 결론의 일관성으로 확신을 높이는 과정과 유사함.
2 방법론(SELF-CONSISTENCY OVER DIVERSE REASONING PATHS)
Self-Consistency는 다양한 reasoning path(추론 경로)를 샘플링하고, 그 결과를 marginalization(주변화)하여 최종 답을 고르는 것임.
-
먼저 프롬프트와 예시(CoT exemplar)를 주어 모델을 여러 번 샘플링. 각 샘플은 서로 다른 reasoning path r_i 와 최종 답 a_i를 포함함.
-
모든 샘플에서 추출된 답들을 모은 후, 가장 자주 등장하는 답(majority vote)을 최종 답으로 선택.
-
가중 평균 형태로 각 경로의 확률을 고려할 수도 있음.
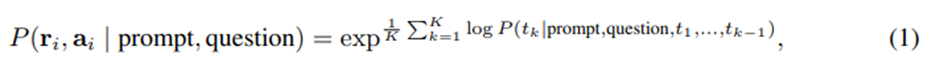
그러나 저자들은 단순한 다수결이 이미 매우 강력하다는 점을 발견.
자기 일관성은 최종 답이 고정된 답 집합에 속하는 문제에만 적용할 수 있음. 원칙적으로는 여러 생성 간의 일관성을 평가할 수 있는 좋은 지표(예: 두 답이 일치하는지 혹은 모순되는지 여부)를 정의할 수 있으면 이 접근법은 열린 텍스트 생성 문제에도 확장될 수 있음.
3 실험
3.1 실험 설정
과제와 데이터셋
산술 추론: GSM8K, SVAMP, AQUA-RAT, AddSub, MultiArith, ASDiv
상식 추론: CommonsenseQA, StrategyQA, AI2 Reasoning Challenge
기호적 추론: Last Letter Concatenation, Coinflip
언어 모델과 프롬프트: UL2, GPT-3, LaMDA-137B, PaLM-540B
모든 실험 few-shot 설정, 추가 학습이나 파인튜닝 없음.
공정한 비교를 위해 Wei et al.(2022)에서 사용된 동일한 프롬프트를 사용. 산술 추론 과제에서는 동일한 8개의 수작업 예시를 사용, 각 상식 추론 과제에서는 훈련 데이터셋에서 무작위로 선택된 4~7개의 예시를 사용, 수작업으로 작성한 chain-of-thought 프롬프트를 사용.
샘플링 방식: temperature T, top-k, nucleus sampling 등
3.2 주요 결과
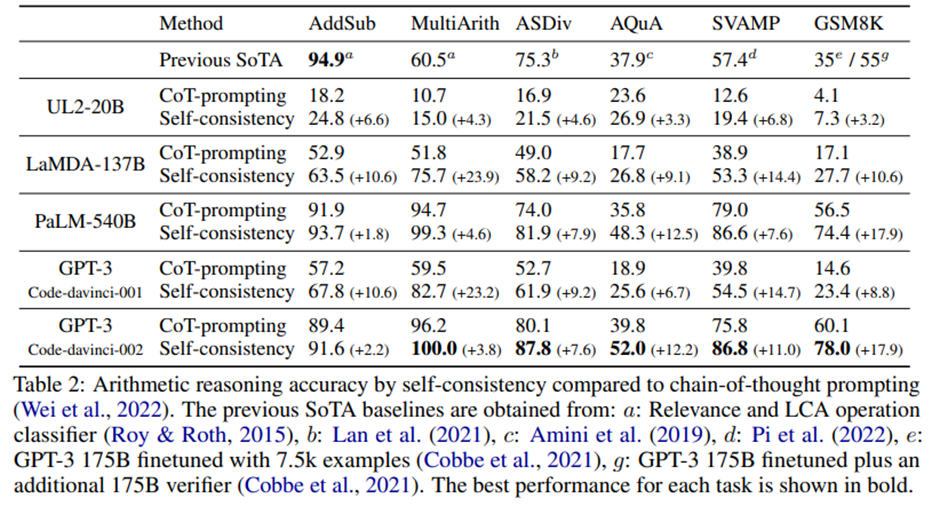
산술 추론 결과.
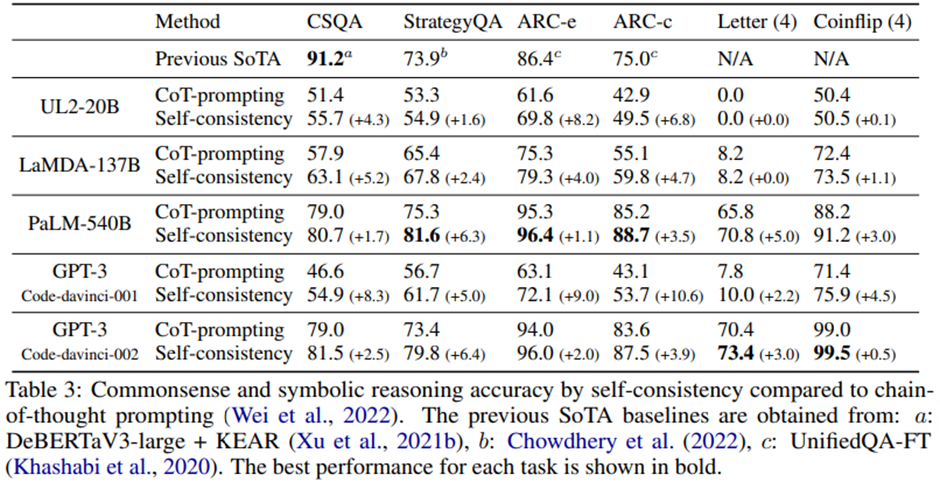
상식 및 기호적 추론 결과. 6개 과제 중 5개에서 SoTA.
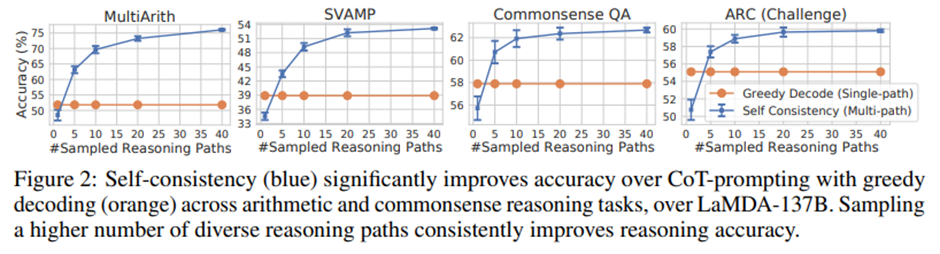
샘플링된 추론 경로 수의 효과를 보여주기 위해, 그림 2에 샘플링 경로 수(1, 5, 10, 20, 40)에 따른 정확도(10회 실행에 대한 평균 및 표준편차)를 그림. 더 많은 수(예: 40)의 추론 경로를 샘플링할수록 일관되게 더 나은 성능으로 이어짐.

두 가지 과제에서 몇 가지 예시 질문을 사용. 자기 일관성이 탐욕적 디코딩에 비해 더 풍부한 추론 경로 집합을 생성함을 보여줌.
3.3 CoT가 성능을 해칠 때의 보정 효과
일부 NLP 과제에서는 CoT가 오히려 성능을 떨어뜨리는 경우가 있음(Ye & Durrett, 2022). 예: ANLI, e-SNLI, RTE 등.

이때 Self-Consistency를 적용하면 CoT의 단점을 보완하며 표준 프롬프트보다 높은 성능을 달성.
3.4 기존의 다른 접근법들과의 비교
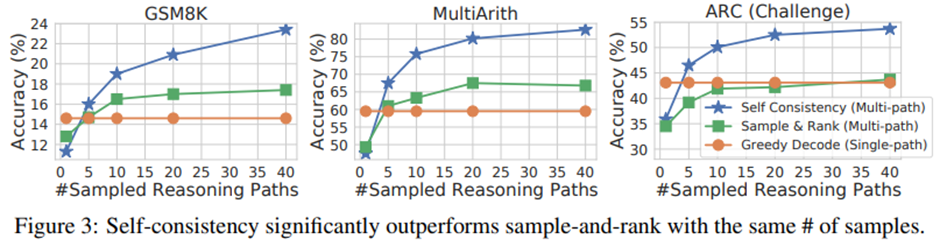
Sample-and-Rank: 다수의 시퀀스를 샘플링 후 로그 확률로 순위를 매기는 기존 기법보다 Self-Consistency가 훨씬 큰 성능 향상을 보임.
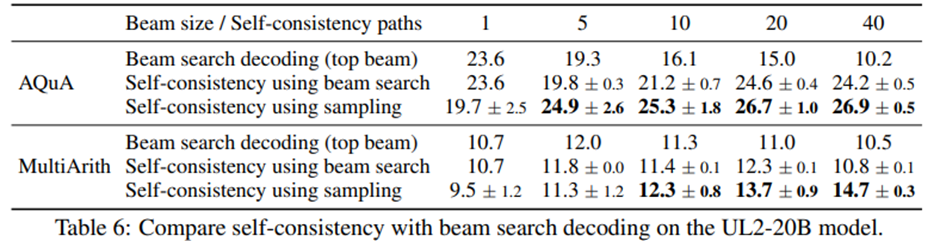
Beam Search: 동일한 빔 수에서 Self-Consistency가 더 우수함. Beam search는 출력 다양성이 부족하기 때문.

Ensemble-based Approaches: 프롬프트 순서를 섞거나 다른 프롬프트 집합을 사용하는 기존 앙상블보다 Self-Consistency가 훨씬 효율적임. 이는 하나의 모델 안에서의 자기 앙상블(self-ensemble)로 작동하기 때문.
3.5 추가 연구
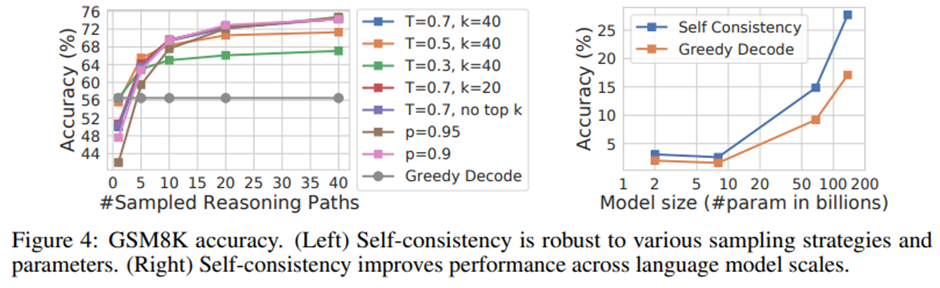
자기 일관성은 샘플링 전략과 스케일링에 강인함. 자기 일관성은 언어 모델 규모 전반에 걸쳐 성능을 향상시킴.
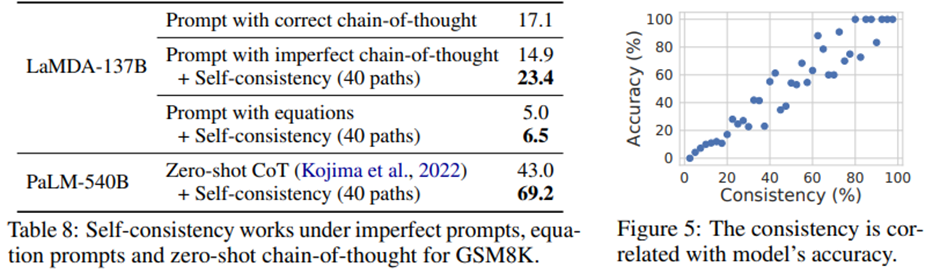
자기 일관성은 불완전한 프롬프트에 대한 강인성을 향상시킴. 일관성(최종 집계된 답변과 일치하는 디코딩의 비율)이 정확도와 매우 강하게 상관되어 있음.
자기 일관성은 비자연어적 추론 경로와 zero-shot CoT에서도 작동함.
4 관련 연구
Reasoning in LMs: 논리, 산술 추론 능력 부족을 해결하기 위한 다양한 시도들이 있었지만, Self-Consistency는 학습이나 주석 없이 폭넓게 적용 가능.
Sampling & Re-ranking: temperature, top-k, nucleus sampling 등 다양한 디코딩 전략이 있으나, Self-Consistency는 단순히 샘플링과 집계만으로 이들을 포괄함.
Reasoning Path Extraction: 기존 연구들은 추론 경로를 그래프나 RNN 기반으로 탐색했지만, Self-Consistency는 단순한 디코딩 샘플링만으로 충분.
Consistency in LMs: 기존 연구들이 문맥 일관성, 대화 일관성을 다뤘다면, 본 연구는 답변의 일관성을 중심으로 한 새로운 정의를 제시.
5 결론 및 논의
자기 일관성은 다양한 규모의 네 가지 대규모 언어 모델에서 여러 산술 및 상식 추론 과제의 정확도를 크게 향상시킴.
한계는 더 많은 계산 비용을 요구한다는 점. -> 그러나 실제로는 5개-10개의 소수의 경로만 시도해도 대부분의 성능 향상을 얻을 수 있고, 비용은 크게 늘어나지 않음.
미래 연구로 자기 일관성을 사용해서 더 나은 지도 데이터 생성하고 모델을 파인튜닝 할 수 있음.
언어 모델이 때때로 잘못되거나 비논리적인 추론 경로를 생성할 수 있음. -> 모델의 근거 생성(rationale generation)을 더 잘 정립하기 위한 추가 연구 필요.
Reproducibility Statement
UL2는 완전히 오픈소스 모델로, 모델 체크포인트가 https://github.com/google-research/google-research/tree/master/ul2 에서 제공.
GPT-3 역시 공개된 모델로, 공개 API가 https://openai.com/api/ 를 통해 제공.
비공개 모델에 대한 프롬프트는 부록 A.3에 제공(파인튜닝 x, 프롬프트만 적용함).
윤리 성명
nonsensical하거나 사실과 맞지 않는 추론 경로 생성을 주의해야 함.
실제 환경에서 언어 모델을 사용할 때는 모델의 예측을 더 잘 정립하고, 사실성(factuality)과 안전성을 향상시키기 위한 추가 연구 필요.
