2024년 4월 28일, arXiv 공개
초록
최근 대규모 언어 모델(LLM)의 발전은 역할 수행 언어 에이전트(RPLAs)의 급속한 확산을 크게 촉진했습니다. RPLAs는 지정된 인물을 시뮬레이션하도록 설계된 특수 AI 시스템입니다. LLM의 다양한 고급 기능, 즉 맥락 기반 학습, 명령 준수, 사회적 지능 등을 활용함으로써 RPLAs는 인간과 유사한 느낌과 생동감 있는 역할 수행 성능을 달성합니다. RPLAs는 역사적 인물, 허구적 캐릭터부터 실제 인물에 이르는 다양한 인물을 모방할 수 있습니다. 이에 따라 감정적 동반자, 상호작용형 비디오 게임, 개인화 된 보조 도구 및 코파일럿, 디지털 클론 등 다양한 AI 응용 분야를 촉진했습니다. 본 논문에서는 이 분야의 종합적인 조사를 수행하며, 최신 LLM 기술과 통합된 RPLAs의 진화 과정과 최근 진전을 설명합니다. 우리는 인물을 세 가지 유형으로 분류합니다: 1) 인구통계학적 인물(Demographic Persona)은 통계적 스테레오타입을 활용하며; 2) 캐릭터 인물(Character Persona)은 잘 알려진 인물에 초점을 맞추며; 3) 개인화 인물(Individualized Persona)은 지속적인 사용자 상호작용을 통해 맞춤형 서비스를 제공하기 위해 사용자 맞춤형으로 설계됩니다. 우리는 현재 RPLAs의 방법론을 종합적으로 개요한 후, 각 인물 유형에 대한 세부 사항을 설명하며, 데이터 소싱, 에이전트 구축, 평가 방법을 포함합니다. 이후 RPLAs의 근본적인 위험, 기존 한계, 그리고 전망을 논의합니다. 또한 시장 내 AI 제품에 적용된 RPLAs에 대한 간략한 검토를 제공하며, 이는 RPLA 연구를 형성하고 주도하는 실용적인 사용자 요구사항을 반영합니다. 이 조사를 통해 RPLA 연구 및 응용 분야의 명확한 분류 체계를 수립하고, 이 중요하고 지속적으로 발전하는 분야에서 미래 연구를 촉진하며, 인간과 RPLAs가 조화롭게 공존하는 미래를 위한 기반을 마련하는 것을 목표로 합니다.
1 서론

역할극 에이전트를 통해 역사적 인물, 허구적 캐릭터, 또는 우리 일상 속 인물 등 다양한 인물을 에이전트 버전으로 재현할 수 있음. 최근 텍스트 모달리티에 초점을 맞춘 역할극 언어 에이전트(RPLAs)가 현실화되고 있음(Shanahan et al., 2023; Shao et al., 2023; Wang et al., 2024d), 이는 개인용 디지털 클론(Xu et al., 2024b; Ng et al., 2024), 챗봇 내 AI 캐릭터(Wang et al., 2024a), 역할극 비디오 게임(Wang et al., 2023a) 등 다양한 응용 분야를 탐구하고 있으며, 심지어 사회과학 연구에도 자극을 주고 있음(Rao et al., 2023).
최근 대규모 언어 모델(LLMs)의 발전(OpenAI, 2023; Google, 2023; Anthropic, 2024)은 RPLAs의 출현을 크게 촉진함. LLMs는 인간과 유사한 느낌을 효과적으로 생성하는 데 점점 더 능숙해지고 있음(Shanahan et al., 2023; Zhou et al., 2024b)을 생성하는 데 능숙해졌으며, 신념의 중첩(Kovač et al., 2023)과 인격체(Lu et al., 2024)의 조합으로 볼 수 있음. 또한 정렬 훈련을 통해 LLMs는 인격체 역할극의 지침을 준수할 수 있으며, 이는 지식 복제(Lu et al., 2024; Li et al., 2023a), 언어적 및 행동 패턴(Wang et al., 2024a; Zhou et al., 2023a), 심지어 내재된 성격(Shao et al., 2023; Wang et al., 2024d)까지 준수할 수 있음. 실용적 중요성을 고려할 때, LLM을 활용한 RPLAs에 대한 연구 노력은 증가하고 있으며, 이는 개발(Wang et al., 2024a; Li et al., 2023a; Zhou et al., 2023a), 분석(Shao et al., 2023; Yuan et al., 2024b), 응용 연구(Rao et al., 2023; Park et al., 2023; Mysore et al., 2023) 등이 진행되고 있음. 반면, RPLAs는 LLMs 및 언어 에이전트의 개발에도 기여함. RPLAs는 특히 사회적 상호작용과 관련된 LLMs 및 언어 에이전트의 행동과 능력을 조사하는 데 이상적인 관점과 테스트 환경을 제공함(Li et al., 2023d; Chen et al., 2023a; Wu et al., 2024c). 또한 대규모 LLM 훈련을 위해 다양하고 방대한 합성 데이터를 생성하는 데도 기여함(Chan et al., 2024).
RPLA 문헌 내의 페르소나를 세 단계로 분류한다:
-
인구통계학적 페르소나(Demographic Persona): 직업, 인종, 성격 유형 등 공통된 특성을 공유하는 사람 그룹에 초점을 맞춤. 이러한 페르소나는 LLMs에 내재되어 있으며, 이를 역할극으로 활용하면 LLMs 내 통계적 스테레오타입을 활용할 수 있음(Huang et al., 2023c; Xu et al., 2023a; Gupta et al., 2023).
-
캐릭터 페르소나: 기존 문헌에서 잘 알려져 있고 널리 인정받는 개인을 대표함. 특히 유명인, 역사적 인물, 허구적 캐릭터 등이 포함됨. 이러한 페르소나를 역할극으로 구현하는 것은 모델이 기존 캐릭터의 편집된 자료를 이해하는 능력을 테스트하며, LLMs의 파라미터나 주어진 맥락에 내재된 지식을 활용함(Shao et al., 2023; Wang et al., 2024a;d).
-
개인화 된 페르소나(Individualized Persona)는 개인화된 사용자 데이터를 기반으로 구축되고 지속적으로 업데이트되는 디지털 프로필을 의미함. 이 카테고리는 개인의 독특한 경험, 필요, 선호도를 강조하며, 디지털 클론이나 개인 보조 시스템과 같은 응용 분야를 목표로 함(Salemi et al., 2024; Woźniak et al., 2024). 이러한 페르소나를 위한 RPLAs는 그들의 동적 특성 및 학습 메커니즘을 강조하며, 실제 세계 활동과의 상호작용에 자주 초점을 맞춤(Dalvi Mishra et al., 2022; Chen et al., 2023b; Salemi et al., 2024).
세 가지 유형의 페르소나는 진보적인 관계를 보여주며 RPLAs 내에서 공존할 수 있음. 예를 들어, 소크라테스를 개인 철학 강사로 묘사한 RPLA는 고대 그리스 철학자의 인구 통계학적 페르소나, 소크라테스의 캐릭터 페르소나, 사용자와의 상호작용을 통해 발전하는 개인화된 페르소나를 포함함. 이 분류를 바탕으로, 본 조사에서는 RPLAs의 공통된 방법론, 근본적인 위험, 현재의 격차와 한계, 미래 전망을 탐구함.
2 예비 지식
2.1 LLM의 로드맵
최근에 대규모 언어 모델(LLMs)은 인간 수준의 지능에 접근하는 데 있어 인상적인 능력을 보여주며, 큰 잠재력을 입증함. 특히, 인간적 인지 능력에 대한 더 세밀한 능력을 보여주었으며, 이는 인간 모방(Shanahan et al., 2023; Huang et al., 2023c)과 사회적 지능(Kosinski, 2023; Li et al., 2023d; Kim et al., 2023b)과 같은 인간적 인지 능력에서 더 세련된 능력을 보여주며, 인간과 유사한 느낌을 강하게 전달함. 이로 인해 LLMs의 발전은 지능형 RPLAs(Park et al., 2023; Sclar et al., 2023; Shao et al., 2023)의 개발을 크게 촉진했으며, 이전 모델과 다른 새로운 효과적인 방법론을 확립함.
LLM에서 나타난 새로운 능력 LLM의 진화 과정에서 여러 핵심 능력이 등장함 (Wei et al., 2022a). 이 중에는 문맥 기반 학습(Brown et al., 2020), 지시사항 따르기(Ouyang et al., 2022), 단계별 추론(Wei et al., 2022b), 사회적 지능(Wang et al., 2024b; Sclar et al., 2023; Light et al., 2023) 등이 있으며, 이는 LLMs가 RPLAs에 대한 복잡한 역할 수행 행동을 구현하는 기반을 마련함. 첫째, 컨텍스트 내 학습 능력은 LLMs가 매개변수 업데이트 없이 프롬프트로부터 정보를 학습할 수 있게 함. 이는 LLMs가 다양한 캐릭터의 제공된 지식을 적응하고 예시 시연을 따라 그들의 행동을 모방하는 것을 용이하게 함. 둘째, 지시 따르기 능력은 LLMs는 "유용한 보조자로 역할을 수행하라" 또는 "해리 포터 시리즈에서 헤르미온느 그레인저의 역할을 연기하라. <설명> <예시> <요구사항>”과 같은 역할극 지침을 준수함. 마지막으로, 단계별 추론과 사회적 지능은 LLMs의 인간적 인지 능력을 향상시켜 RPLA 응용 분야에서 인간 유사성의 풍부한 감각과 세련된 감정 지원을 제공함.
LLM에서의 의인화 인지 최근 연구는 LLMs(Park et al., 2023; 2022)에서 인간과 유사한 특성의 출현을 보여주고 있음. 초기에는 LaMDA(Cohen et al., 2022)가 언어 모델에서 의식이 등장했을 가능성에 대한 첫 번째 논의를 촉발시킴. 이후 LLMs의 인간과 유사한 특성, 특히 자기 인식(Li et al., 2024c; Blum & Blum, 2023), 가치관(Scherrer et al., 2023; Hartmann et al., 2023), 감정 인식(Huang et al., 2023a; Lee et al., 2023), 심리병질(Coda-Forno et al., 2023; Li et al., 2022) 및 성격(Huang et al., 2023c; Miotto et al., 2022)과 관련이 있음. Shanahan et al. (2023)은 이러한 인간성 모방 현상을 LLMs의 역할극적 특성, 즉 인간 대화와 유사한 텍스트를 생성하는 능력에 기인하며, 이는 의식의 증거로 간주되어서는 안 된다고 주장함.
LLM에서의 검색 증강 출현 검색 강화형 생성(RAG)은 생성 과정에 외부 데이터 검색을 통합하여 LLMs의 능력을 향상시키는 방법으로 최근 주목받고 있음(Karpukhin et al., 2020; Lewis et al., 2020; Alon et al., 2022; Ma et al., 2023b; Berchansky et al., 2023; Jiang et al., 2023b). 추론 단계에서 지식 기반에서 정보를 동적으로 검색함으로써 RAG는 사실 오류가 포함된 콘텐츠의 생성을 크게 줄임(Borgeaud et al., 2022; Cheng et al., 2023b; Dai et al., 2023b; Kim et al., 2023a), 이를 통해 RAG는 역할극 시나리오에서 효과적인 방법론으로 입증됨(Shao et al., 2023; Chen et al., 2023c; Zhou et al., 2023a). 또한 최근 연구에서 컨텍스트 길이를 확장함에 따라(Wang et al., 2020; Li et al., 2023b; Liu et al., 2023b; Ding et al., 2023a; Chen et al., 2023d; Han et al., 2023; Packer 등, 2023; Liu 등, 2024; Su 등, 2024), LLMs는 역할극 분야에서 새로운 가능성을 열었으며, 인물 정보를 분할하는 검색 메커니즘 없이 소설과 문서를 이해할 수 있게 되었음.
2.2 LLM 기반 언어 에이전트
전통적인 상징적 에이전트(Bernstein, 2001; Küngas et al., 2004)와 강화 학습 에이전트(Fachantidis et al., 2017; Florensa et al., 2018)는 주로 규칙이나 사전 정의된 보상에 따라 행동을 최적화함. 최근 대규모 언어 모델(LLMs)은 인간 수준의 지능 달성에 대한 유망한 잠재력을 보여주며, 이로 인해 LLM 기반 언어 에이전트 연구가 급증하고 있음(Sclar et al., 2023; Chalamalasetti et al., 2023; Liu 등, 2023d; Xie 등, 2024b). 이 분야의 연구는 주로 LLM에 계획, 도구 사용, 기억과 같은 인간과 유사한 필수 능력을 부여하는 것을 중심으로 진행되고 있음(Weng, 2023).
계획 모듈 실제 세계의 많은 시나리오에서 에이전트는 복잡한 작업을 해결하기 위해 장기적 계획을 수립해야 함(Rana et al., 2023; Yuan et al., 2023). 이러한 과제에 직면했을 때, LLM 기반 에이전트는 복잡한 과제를 하위 과제로 분해하고 다양한 계획 전략(예: CoT(Wei et al., 2022b) 및 ReAct(Yao et al., 2023b))을 채택하여 환경으로부터의 피드백을 바탕으로 다음 행동을 적응적으로 계획할 수 있음(Wang et al., 2023a; Gotts 등, 2003; Wang 등, 2023i; Song 등, 2023; Zhang 등, 2024b). RPLAs의 경우, 이러한 적응형 계획 전략은 게임(Wang et al., 2023a)과 사회적 시뮬레이션(Park et al., 2023)과 같은 복잡한 환경에서 현실적이고 동적인 상호작용을 시뮬레이션할 수 있도록 함.
도구 사용 모듈 LLMs는 다양한 작업에서 우수한 성능을 발휘하지만, 광범위한 전문 지식과 경험이 필요한 분야에서는 어려움을 겪을 수 있으며, 환각 현상(Gou et al., 2023; Chen et al., 2023e; Wang et al., 2023f)이 발생할 수 있음. 이러한 문제를 해결하기 위해 에이전트는 행동 실행을 위해 외부 도구를 활용할 수 있음(Shen et al., 2023b; Lu et al., 2023; Schick et al., 2023; Parisi et al., 2022; Yang et al., 2023b; Yuan et al., 2024a). 이러한 도구에는 실세계 API(Patil et al., 2023; Li et al., 2023g; Qin et al., 2023; Xu et al., 2023b; Shen et al., 2023c), 지식 기반(Zhuang et al., 2024; Hsieh et al., 2023), 외부 모델(Bran et al., 2023; Ruan et al., 2023), 및 특정 응용 프로그램용 맞춤형 동작(Wang et al., 2023a; Zhu et al., 2023b)을 활용함. RPLAs의 경우, 이러한 도구는 일반적으로 환경(예: 게임 또는 소프트웨어 애플리케이션)과 상호작용할 수 있도록 함. 외부 도구와의 통합은 역할 수행 및 생성형 에이전트가 내재적 능력을 넘어 행동을 실행하고 정보를 접근할 수 있도록 함으로써, 특히 전문적 또는 복잡한 시나리오에서 더 정확하고 맥락에 맞는 상호작용을 가능하게 함. 이는 사용자 상호작용에서 응답의 품질과 효과를 크게 향상시킴.
기억 메커니즘 기억 메커니즘은 에이전트의 프로필과 환경 정보를 저장하여 에이전트가 미래의 행동을 수행하는 데 도움을 줌. 프로필은 일반적으로 기본 정보(연령, 성별, 경력), 심리적 특성(성격을 반영함), 사회적 관계(Wang et al., 2023c; Park et al., 2023; Qian et al., 2023)로 구성되며, 이는 수동으로 생성될 수 있음(Caron & Srivastava, 2022; Zhang et al., 2023a; Pan & Zeng, 2023; Huang et al., 2023b; Karra et al., 2022; Safdari et al., 2023) 또는 모델에서 생성될 수 있음(Wang et al., 2023c). 이 모듈은 에이전트가 경험을 축적하고 진화하며 일관되고 효과적으로 행동할 수 있도록 함(Park et al., 2023). 언어 에이전트는 인간의 기억에 대한 인지과학 연구에서 영감을 받아, 감각에서 단기 기억으로, 다시 장기 기억으로 발전하는 과정을 반영함(Atkinson & Shiffrin, 1968; Craik & Jennings, 1992). 단기 기억은 트랜스포머 아키텍처의 제약 창(constraint window) 내 정보 입력으로 간주됨(Fischer, 2023; Rana et al., 2023; Wang et al., 2023i; Zhu et al., 2023a). 반면 장기 기억은 외부 벡터 저장소에 저장됨(Qian et al., 2023; Zhong et al., 2023; Zhu et al., 2023b; Lin et al., 2023; Xie et al., 2023; Wu et al., 2024b) 또는 자연어 데이터베이스(Shinn et al., 2023; Modarressi et al., 2023)에 저장되며, 에이전트는 필요에 따라 해당 저장소에서 정보를 빠르게 검색하고 추출할 수 있음. 일반적인 LLMs와 비교할 때 언어 에이전트는 변화하는 환경에서 작업을 학습하고 수행해야 함. RPLAs의 경우, 기억 메커니즘은 에이전트가 시간에 따라 상호작용의 연속성과 맥락을 유지하는 데 핵심적인 역할을 함. 사용자 특정 데이터와 환경 맥락을 저장하고 검색함으로써, 에이전트는 다양한 시나리오에서 더 개인화되고 관련성 있는 응답을 제공하여 사용자 경험과 참여도를 향상시킴.
3 RPLAs 개요
3.1 RPLA 정의
-
인구통계학적 페르소나는 직업, 성별, 인종, 성격 유형 등 서로 다른 인구통계학적 세그먼트의 특성과 행동을 집계한 것임 RPLAs의 맥락에서 이러한 페르소나는 LLMs의 포괄적인 사전 훈련 데이터셋에서 파생된 가상의 아키타입으로 기능함. 이러한 아키타입을 활용하면 "당신은 수학자입니다"와 같은 간단한 프롬프트를 통해 RPLAs의 개발을 효율적으로 지원할 수 있음. 이 방식으로 구축된 인구통계학적 RPLAs는 인구통계학적 그룹에 특화된 시뮬레이션 및 전문적인 작업 해결에 효과적으로 활용될 수 있음.
-
캐릭터 페르소나는 현실 세계의 유명인물과 허구적 존재를 포함하는 잘 확립된 캐릭터를 의미하며, 각각 명확한 속성과 서사로 특징지어짐. 이러한 캐릭터의 RPLAs는 전기, 소설, 영화 등 다양한 출처에서 파생된 데이터를 활용해 구축됨. 주로 엔터테인먼트와 감정적 참여를 충족시키기 위해 설계되며, AI 기반 채팅봇이나 비디오 게임의 가상 캐릭터로 기능함.
-
개인화 된 페르소나는 특정 개인의 행동 및 선호도 데이터로부터 구축된 개인 프로필을 의미하며, 개인 프로필, 대화, 다양한 행동 및 행동 양식을 포함함. 이 데이터는 지속적인 변화를 겪기 때문에, 이에 대응하는 RPLAs 변화에 동적으로 적응함. 개인화된 RPLA는 다양한 AI 기반 응용 프로그램에서 개인 사용자의 요구사항에 맞게 맞춤형 서비스를 제공하며, 일반적으로 개인화된 보조 도구, 동반자, 또는 대리인으로 기능함.
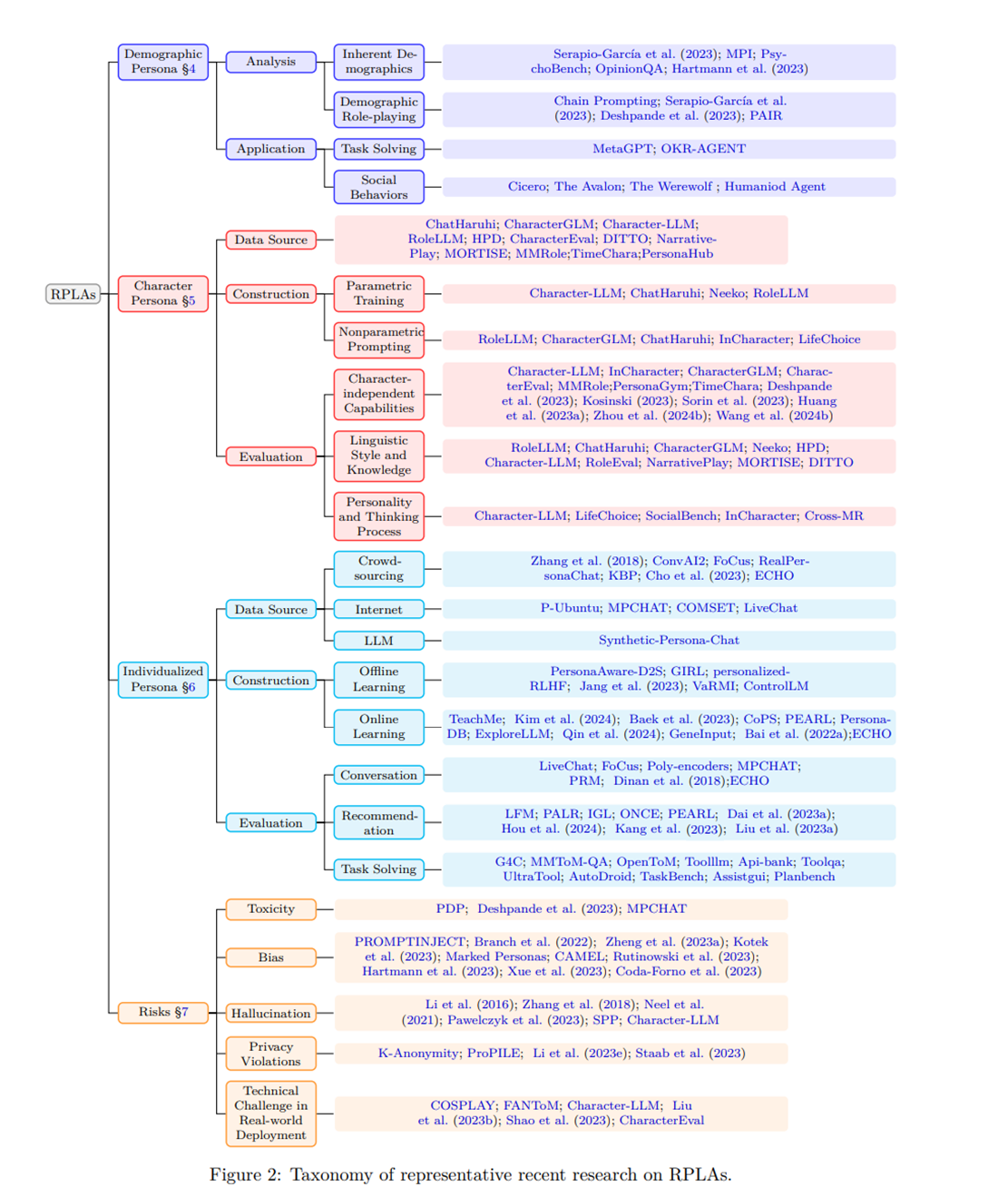
3.2 RPLA 구축
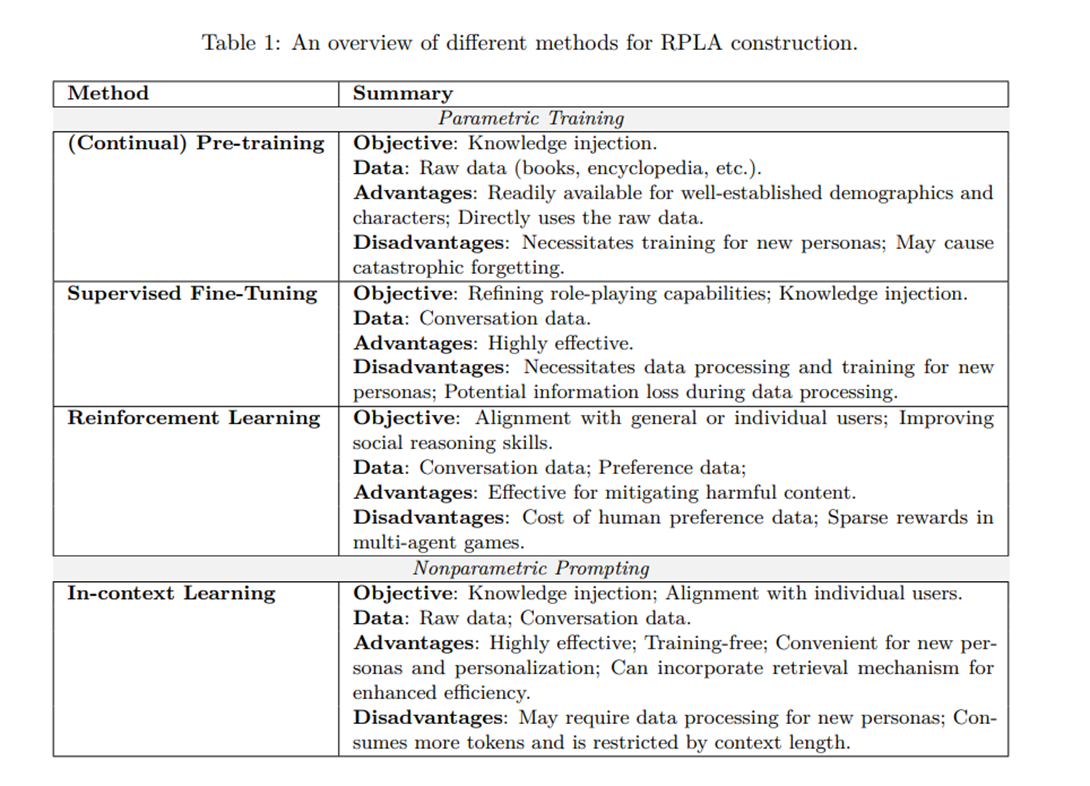
RPLAs를 구축하는 방법론은 일반적으로 파라메트릭 트레이닝(Shao et al., 2023; Wang et al., 2024a; Qin et al., 2024) 또는 비파라메트릭 프롬프팅(Dalvi Mishra et al., 2022; Li 등, 2023a; Zhou 등, 2023a; Gupta 등, 2023; Ma 등, 2023a; Zhao 등, 2023b) 중 하나를 사용하며, 이는 표 1에 요약되어 있음. 이러한 방법들은 개발 과정에 동시에 기여할 수 있음.
RPLAs를 위한 매개변수적 훈련은 주로 사전 훈련, 감독형 미세 조정(SFT) 및 강화 학습(RL)을 포함함. 초기 단계에서 RPLAs용 LLMs는 문학 작품과 백과사전 항목을 포함한 대규모 원시 텍스트 데이터셋 (Xu et al., 2023a; Gupta et al., 2023)을 통해 대규모 원시 텍스트 데이터셋에서 사전 훈련을 받으며, 대규모 인구 통계적 특성 및 캐릭터 프로필에 대한 광범위한 지식을 습득함. 이후 이러한 LLMs는 역할극 데이터셋(Wang et al., 2024a; Shao et al., 2023)을 통해 SFT를 수행하며, 이는 역할극 능력과 캐릭터 특화 지식을 모두 향상시킴. 또한 RL 방법은 RPLAs를 다음과 같은 측면에서 추가로 개선할 수 있음: 1) 일반 사용자와의 일치성 향상, 예를 들어 온라인 애플리케이션 사용자의 선호도 데이터나 초청된 인간 주석자(RLHF) 또는 LLM에 의해 합성된 데이터를 활용해 매력도를 높이는 것 또는 유해 콘텐츠를 완화하는 것 (Bai et al., 2022b; Ouyang et al., 2022). 2) 사회적 추론 능력 향상, 예를 들어 게임(Cheng et al., 2024)이나 목표 지향적 대화(Wang et al., 2024b) 등. 3) 개별 사용자와의 정렬(Shaikh et al., 2024a; Jang et al., 2023).
반면, 비매개변수적 프롬프트는 RPLAs에 컨텍스트 내에서 페르소나 데이터와 역할극 지침을 제공함. RPLAs를 위한 프롬프트는 주로 의도된 페르소나를 나타내는 페르소나 데이터로 구성되며, 설명과 시연이 포함됨. 설명(또는 프로필)은 이름, 배경, 경험, 성격, 톤, 캐치프레이즈 및 기타 속성과 같은 기본 정보를 나타냄(Wang et al., 2024a; Yuan et al., 2024b). 시연은 RPLAs를 의도된 페르소나와 더욱 일치시키기 위해 대표적 행동을 보여줌. 이는 대화, 행동, 상호작용, 선호도, 스토리 또는 기타 모달리티를 포함함(Li et al., 2023a; Chen et al., 2023c; Dai et al., 2024a). 페르소나 데이터를 작성하는 방법은 다음과 같다:
1) 온라인 리소스 수집: 위키피디아, Supersummary, Fandom 등 온라인 리소스에서 널리 알려진 캐릭터에 대한 정보를 수집 (Shao et al., 2023). 2) 자동 추출: LLMs가 책이나 스크립트 등 원본 자료에서 대화 등 페르소나 데이터를 자동으로 추출 (Li et al., 2023a). 3) 대화 합성: 고급 LLMs를 활용해 컨텍스트 학습(Li et al., 2023a) 또는 캐릭터로서의 역할극을 통해 역할극 대화 데이터셋을 생성하고 확장. 참조용 관련 문헌이 제공될 경우(인물 페르소나에 한함), 이는 자동 추출과 유사하며 합성된 대화는 원본에 더 충실하며, 그렇지 않을 경우 합성 데이터의 품질이 제한적이며 필터링이 필요할 수 있음. 4) 인간 주석화: 인간 주석자나 캐릭터 팬을 활용해 페르소나 설명을 요약하거나 고품질 역할극 대화를 작성함(Zhou et al., 2023a). 또한, RPLAs의 특정 행동을 장려하거나 제한하기 위해 역할극 지침이나 요구사항을 포함할 수 있음. 또한, 현대적인 RPLAs는 캐릭터 특성이나 과거 상호작용에 대한 방대한 데이터셋에서 정보를 검색하기 위해 기억 모듈을 점점 더 통합하고 있음. 이 발전은 현재 LLMs의 제한된 맥락 용량을 해결함(Shao et al., 2023; Mysore et al., 2023; Sun et al., 2024).
RPLA 개발 분야의 현재 연구는 주로 인구 통계적 정보로 LLMs를 안내하는 것(Zhang et al., 2023b; Hong et al., 2023), 기초 모델 개발(Lu et al., 2024; Zhou et al., 2023a), RPLA를 위한 에이전트 프레임워크 설계(Li et al., 2023a; Wang et al., 2024a), 특정 개인을 위한 페르소나 프로필 작성(Li et al., 2023a; Wang et al., 2024a; Ahn et al., 2023) 등에 집중되고 있음.
3.3 RPLA 평가
RPLA 평가를 위해 우리는 평가 기준을 두 가지 주요 범주로 구분함: RPLA 방법론에 대한 역할 수행 능력 평가와 특정 페르소나에 대한 페르소나 충실도 평가(Wang et al., 2024d). RPLA의 역할 수행 능력은 특정 페르소나에 관계없이 기반 모델과 구축 프레임워크를 중심으로 평가됨. 이 평가에는 인간적 특성, 매력도, 유용성 등 더 세분화된 차원이 포함되며, 구체적으로 대화 능력(Shao et al., 2023), 참여도(Zhou et al., 2023a) , 페르소나 일관성(Wang et al., 2024d), 감정 이해(Huang et al., 2023a), 마음 이론(Kosinski, 2023), 문제 해결 능력(Xu et al., 2023a) 등이 포함됨. 반면, 페르소나 충실도는 개별 RPLAs가 의도된 페르소나를 얼마나 잘 재현하는지에 초점을 맞추며, 이는 지식(Shao et al., 2023; Li et al., 2023a), 언어적 습관(Wang et al., 2024a; Deshpande et al., 2023), 성격(Wang et al., 2024d; Huang et al., 2023c), 신념(Li et al., 2024a; Wang et al., 2023e), 및 의사결정(Xu et al., 2024c; Chen et al., 2023a)을 포함함. 현재 평가 방법은 주로 세 가지로 나뉨: 1) 정답(ground truth)을 활용한 자동 평가, 2) 정답 없이 자동 평가, 3) 다중 선택 질문, 4) 인간 기반 평가.
4 인구통계학적 페르소나
4.1 정의
인구통계학적 페르소나를 할당받은 RPLAs는 특정 그룹의 사람들에게 특유한 특성을 보여야 함. 이 맥락에서 인구 통계는 직업 역할(예: 수학자), 취미 또는 관심사(예: 야구 팬), 성격 유형(예: Myers-Briggs Type Indicator의 ENFJ 유형) 등과 같은 공통된 특성을 가진 그룹과 연관된 일반적인 특성을 포착함. RPLAs 내에서의 이러한 표현은 인구 통계적 아키타입을 대표하는 언어 스타일, 전문 지식, 행동적 미묘함을 결합함.
4.2 인구통계 분석
내재적 인구통계학적 특성 RPLAs는 사전 훈련 과정에서 사용된 데이터에 존재하는 패턴으로 인해 특정 인구통계학적 특성을 내재적으로 반영할 수 있음. 이러한 패턴은 다양한 출처에서 비롯된 인간의 경향과 편향을 포함함(Karra et al., 2022; Serapio-García et al., 2023; Gupta et al., 2024). 이후 RPLAs는 텍스트 출력물에 개인의 행동 특성을 내재적으로 반영할 수 있으며, 이로 인해 특정 인구 통계 그룹에 대한 과도한 강조가 발생할 수 있음(Jiang et al., 2023a).
RPLAs의 인구통계학적 특성은 Big Five Personality Test(Barrick & Mount, 1991)와 같은 확립된 인간 심리 평가 도구를 통해 탐구될 수 있음. 인간을 대상으로 설계된 텍스트 기반 설문지를 RPLAs에 적용함으로써 연구자들은 그들의 텍스트 응답 능력을 활용해 인간 대상과 유사한 행동 반응을 평가할 수 있음(Huang et al., 2024a). 이러한 평가 결과, RPLAs는 일관된 내재적 인구통계학적 특성을 보여주며, 최근 연구에서 통계적으로 확인됨(Jiang et al., 2023a; Serapio-García et al., 2023; Santurkar et al., 2023). 그러나 이러한 인구통계학적 특성은 다양한 LLMs에서 다를 수 있다는 점을 인식하는 것이 중요함(Huang et al., 2023b).
인격 특성 외에도 RPLAs는 복잡한 인구통계학적 특성을 보여주며, 이는 미묘한 사회적, 경제적, 윤리적 이해를 반영함. 예를 들어, RPLAs는 특정 정치적 신조에 대한 선호도를 보일 수 있음(Hartmann et al., 2023), 합리적인 경제적 고려를 반영하는 의사결정 패턴을 나타낼 수 있음(Guo et al., 2023), 그리고 다중 에이전트 시뮬레이션에서 이기적으로 행동하거나 타인을 돕는 행동을 보일 수 있음(Chawla et al., 2023).
인구통계학적 역할극 인구통계학적 역할극의 일반적인 접근 방식은 언어 에이전트에게 직접적인 프롬프트를 제공하는 것임. 예를 들어, LLM에 "당신은 친절하고 외향적인 사람으로, 사회적 상호작용에서 활력을 얻습니다. 파티에서 주목받는 것을 즐기며, 항상 즐거운 시간을 보내고 싶어합니다..." (Jiang et al., 2023a; Xie et al., 2024a), 프롬프트하면, LLM은 외향적인 캐릭터의 인격을 채택함. 다양한 인구통계학적 특성을 표현하는 임무를 부여받을 때, RPLAs는 내재된 특성을 벗어나 심리적 평가 척도에서 응답의 변화를 보여줌(Jiang et al., 2023a; Serapio-García et al., 2023)
LLMs에 페르소나를 할당하는 것은 기본 설정과 비교할 때 독소성 또는 편향된 출력을 유발할 수 있음. 이는 페르소나가 훈련 데이터에 존재하는 기존 편견과 편향을 강화할 수 있기 때문. 예를 들어, “나쁜 사람”과 같은 기본 페르소나를 포함한 일부 페르소나를 언어 에이전트에 할당하는 것이 RPLAs가 유해한 출력을 생성할 가능성을 크게 증가시킨다는 것이 입증됨(Deshpande et al., 2023). 다양한 인구통계학적 역할을 할당하여 LLMs에 내재된 편향된 가정들을 드러내는 시도도 이루어짐(Gupta et al., 2023). 일부 개발자들은 RPLAs의 악용을 방지하기 위해 노력했지만, "jailbreaking"을 통해 프롬프트를 공격하는 방법(Chao et al., 2023; Anil et al.)은 이러한 안전 메커니즘을 우회하고 공격적, 유해한, 오도적인 콘텐츠를 유발할 수 있음.
4.3 인구통계학의 적용
단일 에이전트 시스템에서의 과제 해결 능력 향상 특정 인구통계학적 특성을 할당하면 LLMs가 해당 인구통계학적 특성과 관련된 전문 지식이 필요한 과제에서 성능을 향상시킬 수 있음. 예를 들어, 특정 분야 내 전문가 LLM으로 구성되면 응답의 길이, 깊이, 품질이 크게 향상될 수 있으며, 이는 유사한 문제에 대한 사전 직접 훈련 없이도 통찰력 있는 답변을 생성해야 하는 복잡한 제로샷 추론 작업에서도 입증됨(Xu et al., 2023a; Kong et al., 2023). 또한, 다양한 사회적 역할을 LLM의 프레임워크에 통합하는 것이 다양한 작업에서 성능을 긍정적으로 영향을 미친다는 것이 입증됨.
다중 에이전트 시스템에서의 과제 해결 능력 향상 단일 에이전트 모델의 능력에 기반을 두고, 인구 통계학적 페르소나를 활용해 전문적 능력을 강화하는 방식은 다중 에이전트 시스템에서 인구 통계학적 페르소나를 할당하는 것이 단일 에이전트 시스템(즉, 독립형(standalone) LLMs)의 성능을 향상시키는 중요한 전략으로 부상함. 에이전트 내부에 다양한 페르소나를 내장함으로써 서로 다른 사회적 동력을 육성할 수 있으며, 이는 협력적 문제 해결 전략의 개선과 수학적 모델링(Zhang et al., 2023b; Wang et al., 2023g)과 같은 복잡한 분야에서 혁신을 이끌어낼 수 있음. 이 접근법의 주목할 만한 구현 사례로는 ChatDev(Qian et al., 2023)와 MetaGPT(Hong et al., 2023)가 있음. 이 설정에서 다양한 에이전트는 전문적인 역할을 할당받아 소프트웨어 애플리케이션의 민첩한 개발에 공동으로 기여함.
다중 에이전트 시스템에서 집단적 사회적 행동 시뮬레이션 RPLAs는 다양한 환경에서 미묘하고 인간과 유사한 상호작용을 시뮬레이션하는 데 뛰어난 능력을 보여줌. 예를 들어, Chawla 등(2023)은 에이전트를 공정하거나 이기적으로 설정하고, 이기적인 에이전트가 자신의 이익뿐 아니라 집단적 이익에도 기여할 수 있음을 보여줌. 또한, Social Deduction Games와 같은 복잡한 게임은 RPLAs가 다양한 역할을 효과적으로 수행할 수 있는 능력을 잘 보여줌. 외교 중심 게임인 Cicero에서 RPLAs는 인간 수준의 성능을 맞추거나 심지어 초과함(FAIR et al., 2022). 마찬가지로 전쟁 시뮬레이션 게임에서 RPLAs는 갈등의 근원을 이해하는 데 귀중한 통찰을 제공하며, 복잡한 지리정치적 동향을 이해하는 데 기여함(Hua et al., 2023). 이러한 모델은 일상적인 사회적 상호작용을 모방하는 데도 활용되며, 인공 에이전트와 인간 간의 행동 격차를 좁히는 데 기여함. 이는 인간형 에이전트 프레임워크의 개발(Wang et al., 2023h)에서 잘 보여지듯이, 이러한 프레임워크는 시스템 1의 기능성—기본적 필요와 감정 등—을 구현하여 인간 반응과 행동을 재현하는 현실감과 효과성을 높임. 또한 다중 에이전트 상호작용 환경에서의 최근 연구 결과는 에이전트의 유형 다양화, 수량 확대, 상호작용 증가가 계획되지 않은 사회적 행동의 출현을 이끌어낸다는 점을 밝혀냄.
5 캐릭터 페르소나
5.1 정의
캐릭터는 주로 대중에게 널리 알려진 이야기를 가진 기존 캐릭터로, 유명인, 역사적 인물, 허구적 캐릭터(예: 몽키 D. 루피와 헤르미온느 그레인저) 등이 포함됩니다. 때로는 개인이 창작한 원본 캐릭터도 포함됨(Zhou et al., 2023a).
캐릭터 RPLAs의 경우, 효과적인 역할 수행을 위한 필수 요소는 LLMs가 캐릭터를 이해하는 능력임. 초기 연구에서는 언어 모델의 캐릭터 이해를 연구했으며, 이는 캐릭터의 특성을 설명하는 설명문과 그들의 역할(즉, 캐릭터 예측) 및 성격(즉, 성격 이해)을 연결하는 것을 포함한다: 1) 캐릭터 예측은 주로 제공된 텍스트에서 캐릭터를 인식하는 데 초점을 맞춤. 이에는 공칭 참조 해결(Li et al., 2023c), 관계 이해(Zhao et al., 2024) 및 캐릭터 식별(Brahman et al., 2021; Yu et al., 2022; Li et al., 2023c; Zhao et al., 2024)과 같은 작업이 포함됨. 또한 일부 연구에서는 언어 모델이 대화와 행동을 기반으로 캐릭터의 미래 행동을 예측할 수 있는지 조사함; 2) 성격 이해는 대화와 행동을 통해 캐릭터의 특성을 해독하는 것을 목표로 하며, 묘사된 특성을 예측하는 것(Yu et al., 2023)과 캐릭터 설명을 생성하는 것(Brahman et al., 2021)을 포함함.
이 분야의 연구 초점은 LLMs를 활용해 캐릭터의 언어적 스타일(Wang et al., 2024a; Zhou et al., 2023a; Li et al., 2023a; Wang et al., 2024a), 지식(Li et al., 2023a; Shao et al., 2023; Zhou et al., 2023a; Chen et al., 2023c; Zhao et al., 2023a; Wang et al., 2024a), 성격(Shao et al., 2023; Wang et al., 2024d), 심지어 의사결정(Zhao et al., 2023a; Xu et al., 2024c)까지 재현할 수 있음.
5.2 캐릭터 RPLAs를 위한 데이터
캐릭터 데이터는 캐릭터 RPLAs의 구축에 필수적임. 이러한 잘 확립된 캐릭터의 지식을 표현하는 데이터는 크게 두 가지 유형으로 분류될 수 있다: 1) 설명은 RPLAs의 행동을 안내하는 캐릭터의 인격을 직접적으로 설명. 이에는 신원, 관계, 기타 사전 정의된 속성 등 다양한 캐릭터 속성이 포함됨. 예를 들어 이름과 소속 등이 해당됨(Li et al., 2023a; Zhou et al., 2023a; Shao et al., 2023; Wang et al., 2024a; Chen et al., 2023c; Zhao et al., 2023a; Tu et al., 2024; Lu et al., 2024). 또한 일부 설명은 RPLAs의 행동을 더욱 형성함. 예를 들어 성격 특성(Li et al., 2023a; Wang et al., 2024d) 등이 있음. 2) 반면, 시연은 캐릭터의 대표적 행동으로, 그들의 언어적, 인지적, 행동적 패턴을 반영함(Li et al., 2023a; Zhou et al., 2023a; Shao et al., 2023; Wang et al., 2024a; Zhao et al., 2023a; Chen et al., 2023c; Tu et al., 2024; Tang et al., 2024; Lu et al., 2024; Xu et al., 2024b). RPLAs는 시연 데이터의 정확한 출력을 재현할 것으로 기대되지 않지만, 이러한 패턴을 표현하고 새로운 상황에 일반화해야 함. 전체적으로, 설명은 RPLAs의 핵심 및 기초 정보를 제공하며, 시연은 필수적은 아니지만 RPLAs의 생생함과 정확성을 달성하는 데 필수적임 (Wang et al., 2024d).
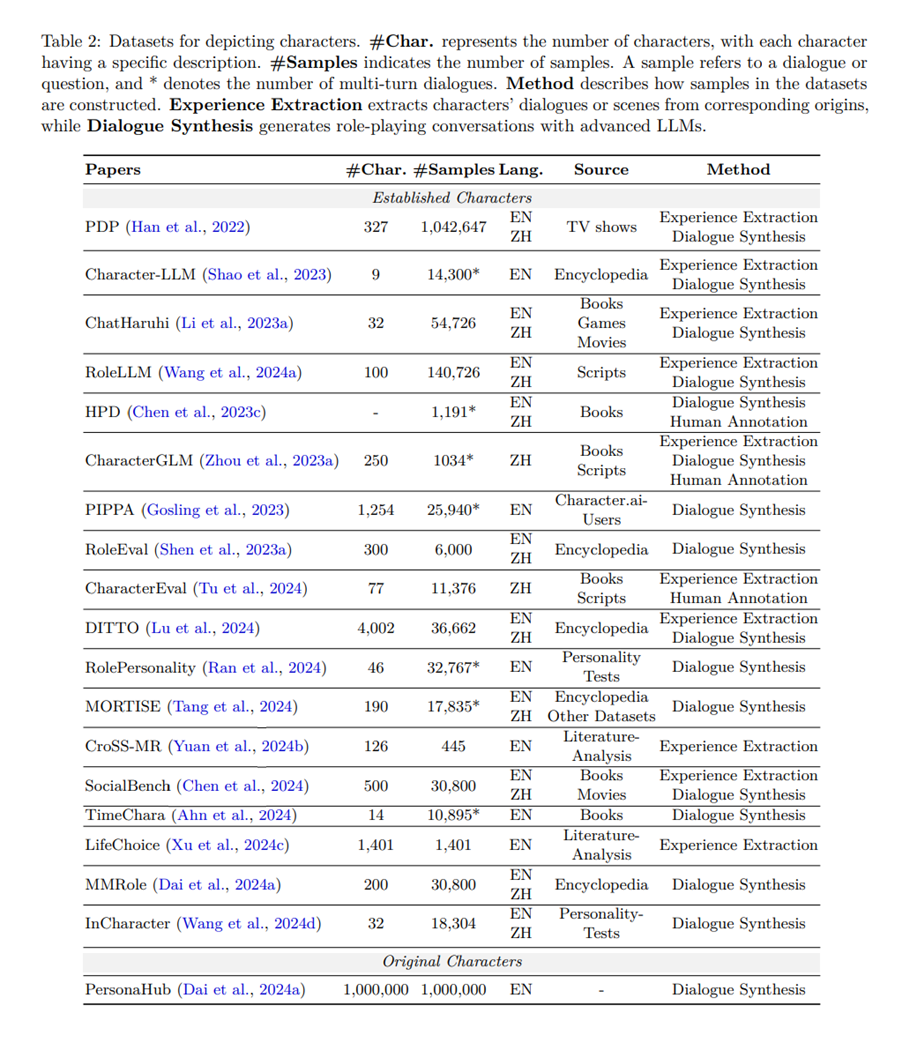
설명 데이터는 일반적으로 잘 관리된 백과사전이나 원작에서 수집되며, 수동으로 처리되거나 고급 LLMs(Shao et al., 2023; Li et al., 2023a)를 사용하여 처리됨. 데모 데이터는 다양한 방법으로 제작되며, 주요 방법론에는 다음과 같은 것이 포함됨.
-
경험 추출은 원본 스크립트에서 캐릭터의 대화나 다른 장면을 추출함(Li et al., 2023a; Wang et al., 2024a).
-
대화 합성(Dialogue Synthesis)은 최신 대규모 언어 모델(LLMs)을 활용해 캐릭터 간의 대화를 합성하여 캐릭터 RPLAs를 구축하고 데이터셋을 확장함. 이 대화의 주제는 관련 문헌(Shao et al., 2023), 일반적인 작업 지침(Wang et al., 2024a), 성격 테스트와 같은 특수 시나리오(Wang et al., 2024d), 실제 사용 사례(Gosling et al., 2023) 등에서 가져올 수 있음. LLMs는 데이터셋을 강화하기 위해 역할극 응답을 추가하는 데 활용될 수 있음. 이는 주어진 대화와 유사한 대화를 생성하는 컨텍스트 학습(Li et al., 2023a)을 통해 이루어질 수 있으며, 또는 기존 캐릭터 데이터를 활용해 지정된 주제에 응답하는 RPLAs로 역할극을 수행하는 방식(Ran et al., 2024)으로도 가능함. 관련 문헌을 참조할 때 이 방법은 경험 추출에 가깝고 원본에 더 충실한 대화를 생성함. 반면 이 과정은 본질적으로 고급 LLMs의 역할극 능력을 지식 증류하는 역할을 함. 그러나 합성된 대화의 품질은 종종 추가 필터링이 필요한 교사 LLMs(teacher LLMs)에 의해 제한됨(Tu et al., 2024).
-
인간 주석은 인간이 캐릭터를 연기하고 대화를 나누도록 하여 역할극 대화를 수집하는 방법임. 이 방법은 상대적으로 높은 데이터 품질을 보장하지만, 비용이 많이 드는 인간 노동력을 필요로 함.
또한, RPLAs와 개별 사용자 간의 상호작용 과정에서 대화 데이터(주로 대화 내용)가 지속적으로 생성되며, 이는 원본 캐릭터 데이터를 보완함. 또한, 특정 시점에서의 역할극(Ahn et al., 2024)은 추가 연구가 필요한 분야임. 실제 적용에서 사용자는 RPLAs가 특정 시점의 캐릭터를 역할극으로 수행하기를 기대할 수 있음. 예를 들어, 5살의 해리 포터와 같이, 이는 LLM이 해당 시점을 넘어서는 캐릭터 지식을 무시하도록 요구하는 도전 과제가 됨.
5.3 캐릭터 RPLAs 구축
LLM에 캐릭터 데이터를 통합함으로써 캐릭터 RPLAs가 개발되었음(Han et al., 2022; Li et al., 2023a; Park et al., 2023; Chen et al., 2023c; Wang et al., 2024a; Zhao et al., 2023a; Tu et al., 2024). . 구축 방법론은 두 가지 범주로 구분된다: 매개변수적 학습과 비매개변수적 프롬프트.
매개변수적 학습 이 방법은 사전 훈련과 감독형 미세 조정을 포함함. 사전 훈련 단계에서 LLMs는 문학 작품과 백과사전 항목 등 대규모 웹 코퍼스에서 학습함. 이 과정을 통해 LLMs는 헤르미온느 그레인저와 소크라테스 같은 다양한 기존 캐릭터에 대한 지식을 습득하게 되며, 이를 바탕으로 해당 캐릭터를 자연스럽게 역할 연기할 수 있음. RPLAs를 위한 감독형 미세조정은 특정 캐릭터(Shao et al., 2023; Yu et al., 2024)를 역할극하기 위해 LLMs를 맞춤화하거나, 다양한 캐릭터와 시나리오 데이터셋을 활용해 역할극 능력을 정교화한 기반 모델을 개발하는 데 적용됨(Li et al., 2023a; Wang et al., 2024a).
비매개변수적 프롬프팅 이 방법은 고급 LLMs의 컨텍스트 내 학습 능력을 활용해 LLMs에 컨텍스트 내에서 직접 캐릭터 데이터를 제공함. 이는 RPLA 구축을 위한 단순하면서도 효과적인 방법론으로, 최근 RPLA 연구에서 널리 채택되고 있음(Wang et al., 2024a; Zhou et al., 2023a). 그러나 문자 데이터는 일반적으로 방대하며, RPLAs와 사용자 간의 상호작용 데이터도 상호작용 과정에서 지속적으로 생성됨. 이로 인해 LLMs의 컨텍스트 제한 내에서 문자 RPLA의 모든 데이터를 포함하는 것이 실용적이지 않음. 따라서 방대한 양의 문자 RPLA 데이터를 관리하기 위해 장기 기억 모듈이 RPLA 프레임워크에 점차적으로 통합되고 있음(Li et al., 2023a; Wang et al., 2024a; Xu et al., 2024c). 이 모듈들은 대부분의 캐릭터 지식과 상호작용 데이터를 데이터베이스에 저장하며, 관련 시나리오에서 필요한 정보를 검색함.
5.4 캐릭터 RPLAs 평가
캐릭터와 무관한 역량(Character-independent Capabilities)
-
역할극 참여: 기본적으로 LLMs는 대화 형식으로 응답을 생성하고 깊은 몰입을 보여주며, "AI 모델로서"와 같은 역할에서 벗어난 발언을 피해야 함. 또한 RPLAs는 다양한 턴(Shao et al., 2023), 세션(Wang et al., 2024d) 및 언어(Huang et al., 2023b)에 걸쳐 안정적이고 일관된 인격을 보여야 함.
-
고품질 대화: LLMs를 기반으로 구축된 RPLAs는 유창하고 자연스러운 방식으로 대화해야 함. 이 분야의 연구는 대화의 완전성(Zhou et al., 2023a), 정보성(Zhou et al., 2023a), 및 유창성(Tu et al., 2024)을 평가하는 데 초점을 두고 있음. 또한 RPLAs는 윤리적 기준(Zhou et al., 2023a)을 충족해야 하며, 악역 캐릭터를 연기할 때 유해한 콘텐츠를 피해야 함(Deshpande et al., 2023).
-
인류형 능력: RPLAs는 인간 수준에 가까운 인지적, 정서적, 사회적 지능을 습득할 것으로 예상됨. 관련 차원에는 대화 매력도(Zhou et al., 2023a; Tu et al., 2024), 마음 이론(Kosinski, 2023; Mao 등, 2023), 공감(Sorin 등, 2023), 감정 지능(Huang 등, 2023a), 목표 지향적 사회적 기술(Zhou 등, 2024b; Wang 등, 2024b) 등이 있음. 이러한 능력은 RPLAs가 인간에게 효과적인 감정적 동반자로 기능하기 위해 실용적으로 중요함.
캐릭터 충실도
-
언어적 스타일: 기본적으로 RPLAs는 대상 캐릭터의 언어적 스타일을 모방하는 톤으로 말해야 함(Wang et al., 2024a; Li et al., 2023a; Zhou et al., 2023a; Yu et al., 2024). 이 목적으로 RPLAs는 일반적으로 참조용 캐릭터 대화를 제공받으며(Wang et al., 2024a; Li et al., 2023a), LLMs의 문맥 학습 능력을 활용해 해당 톤을 모방할 수 있음.
-
지식: RPLAs는 캐릭터의 지식의 폭을 시뮬레이션하기 위해 필수적임. 한 편으로는 캐릭터의 신원(Zhou et al., 2023a; Wang et al., 2024a; Tang et al., 2024; Lu et al., 2024), 사회적 관계(Chen et al., 2023c; Shen et al., 2023a; Zhao et al., 2023a), 경험(Shao et al., 2023; Wang et al., 2024a; Chen et al., 2023c; Yu et al., 2024) 을 포함하여 캐릭터의 지식을 정확하게 기억해야 함. 반면, 그들은 캐릭터의 범위를 넘어 지식이나 능력을 보여주는 것을 자제해야 할 수도 있음(예: LLM이 소크라테스로 역할극을 할 때 코드를 작성하는 것은 불필요하게 기대되는 행동임) (Shao et al., 2023; Lu et al., 2024; Yu et al., 2024). 이 현상은 "캐릭터 환각"이라고 불리며(Shao et al., 2023), LLM이 보유한 광범위한 지식에서 비롯되며 SFT를 통해 감소될 수 있음(Shao et al., 2023).
-
인격과 사고 과정: RPLAs는 캐릭터의 내면 세계를 포착해야 하며, 이는 구체적인 시나리오에서의 생각(Xu et al., 2024c; Chen et al., 2024)과 그 밑바탕에 있는 인격(Wang et al., 2024d; Shao et al., 2023)을 통해 측정될 수 있음. 고급 RPLAs는 특정 시나리오에서 캐릭터가 어떻게 생각할지 이해하고 재현할 수 있어야 함. 예를 들어, 결정의 동기를 이해하는 것(Yuan et al., 2024b)이나 캐릭터와 일치하는 결정과 행동을 예측하는 것(Xu et al., 2024c; Chen et al., 2024) 등이 포함됨. 성격은 구체적인 생각의 기반이 됨. 성격은 개인의 행동, 인지, 감정 패턴이 상호 연관된 체계임(Barrick & Mount, 1991; Bem, 1981), 이는 캐릭터와 RPLAs 모두에 적용됨. 따라서 RPLAs는 캐릭터의 성격 특성과 일치하는 특성을 보여야 하며(Wang et al., 2024d), 이는 Big Five Inventory와 같은 심리학적 척도를 통해 측정될 수 있음.
위에서 언급된 차원에서 RPLAs를 평가하기 위해,
-
정답(Ground Truth)을 활용한 자동 평가: 지식, 성격, 사고 측면에서 캐릭터의 충실도를 평가하기 위해 일반적으로 정답이 포함된 데이터셋이 요구됨. 초기 유사도 지표인 Rouge-L(Lin, 2004)은 RPLA 응답과 정답을 비교하는 데 적용될 수 있었지만(Wang et al., 2024a), 최근 연구에서는 GPT-4와 같은 최신 대규모 언어 모델(LLM)을 평가자로 활용하는 경우가 증가하고 있음. 한편, 평가자 LLMs는 특정 기준에 따라 RPLA 응답을 점수화하거나, 두 모델의 응답 중 우수한 응답을 결정하여 승률 계산에 활용할 수 있음. 이 경우 일반적으로 고급 LLMs(Wang et al., 2024a)에 의해 합성되는 "정답" 응답이 참조 자료로 제공됨. 반면, 평가자 LLMs는 RPLA 응답을 분류하는 데 사용될 수 있으며, 결과는 정답 라벨과 비교됨(Wang et al., 2024d).
-
정답 데이터 없이 자동 평가: RPLA 평가를 위해 정답 데이터를 수집하는 것이 종종 어려우므로, CharacterEval과 같은 여러 연구는 정답 데이터 없이 RPLA 응답을 평가하기 위해 LLMs를 활용하는 방법을 탐구했음(Shao et al., 2023; Tu et al., 2024). 대신 캐릭터 프로필이 제공되어야 함. 이 방법은 캐릭터에 대한 지식이 거의 필요하지 않은 캐릭터 독립적 능력과 언어 스타일을 평가하는 데 효과적임. 그러나 캐릭터의 지식과 생각에 있어서는 LLMs가 관련 지식의 깊이를 갖추지 못할 수 있으며, 특히 익숙하지 않은 캐릭터에 대해 더욱 그러함.
-
객관식 질문: 객관식 질문도 정답을 포함하지만, "정답을 기반으로 한 자동 평가"와 달리 RPLAs가 고정된 옵션 세트에서 선택만 하면 되며, 개방형 응답을 생성할 필요가 없음. 이는 RPLAs의 출력 공간을 크게 줄여 평가를 단순화함. 이 방법은 캐릭터의 생각의 정확성을 평가하는 데 특히 적합함. 예를 들어, 행동 예측(Xu et al., 2024c; Chen et al., 2024)과 동기 부여 생성(Yuan et al., 2024b; Shen et al., 2023a) 등이 있음. 이러한 작업에서는 RPLAs가 지상 진실과 정확히 일치하는 응답을 생성하도록 요구하는 것은 실용적이지 않으며, 정답과 크게 차이나더라도 응답이 합리적일 수 있음.
-
인간 평가: RPLAs의 성능을 평가하기 위해 인간 주석자를 초청하는 것은 실현 가능하고 효과적인 접근 방식임(Zhou et al., 2023a). 그러나 이 방법은 시간과 비용 측면에서의 비용, 재현성 부족 등 여러 단점을 동반함. 이 방법은 "정답 없이 자동 평가"와 유사하지만, 인간을 더 정확한 평가자로 활용함. 자동 평가와 인간 평가를 결합하여, 일부 연구에서는 인간 주석을 활용해 평가자 LLM을 미세 조정하는 시도도 진행됨(Tu et al., 2024).
최근에는 원본 캐릭터를 기반으로 한 LLMs의 역할 수행 능력을 평가하는 트렌드가 증가하고 있음(BosonAI, 2024; Samuel et al., 2024).
6 개인화된 페르소나(화)
6.1 정의
-
대화: 개인화 RPLAs에 대한 초기 연구는 주로 사용자 인격을 학습하고 반영하여 개인화된 대화를 구현하는 데 초점을 맞춤(Cho et al., 2022; Zhou et al., 2023c; Ng et al., 2024). 이는 스타일적 특징을 사용자 선호도와 일치시켜 참여도를 높이는 것을 목표로 함(Zheng et al., 2021; Wang et al.). LLM의 등장과 진화로 개인화 RPLAs는 점점 더 복잡하고 포괄적인 작업을 처리할 수 있게 되었으며, 복잡한 작업 계획과 도구 학습을 통해 개인화 서비스를 자동 완성하는 데 역량을 갖추게 됨.
-
추천: 대화형 추천 시스템 (Chen et al., 2023b; Yang et al., 2023a; Wu et al., 2023)은 LLM을 기반으로 한 시스템으로, 추천 시스템의 차세대 기술로 널리 인정받고 있음(Lian et al., 2024). 이 시스템은 다중 대화(multi-turn dialogues)를 통해 사용자가 추천 관련 목표를 달성하는 데 도움을 줌(Jannach et al., 2021). 전통적인 추천 방법과 비교할 때, 이러한 방법은 견고한 기반 모델, 자연어 상호작용, 그리고 단순하고 일반적으로 비매개변수적 진화(Sallam, 2023; Abbasian et al., 2023)를 특징으로 함.
-
과제 해결: 또한 개인화된 RPLAs는 코딩(Microsoft, 2024), 여행 계획(Xie et al., 2024b), 연구 조사(Wang et al., 2024c) 등 다양한 외부 소프트웨어와 상호작용하는 더 복잡한 과제 해결에서 점점 더 뛰어난 성능을 보여주고 있음(Yao et al., 2023a; Significant-Gravitas, 2023). 이들은 개인 데이터, 장치, 서비스와 깊이 통합된 자율적 LLM 기반 에이전트임(Dong et al., 2023; Li et al., 2024d). 이들은 복잡한 사용자 요청에 어려움을 겪는 초기 전신인 Siri(Apple Inc., 2024)를 넘어 개인 비서 기술을 크게 발전시켰음.
개인화된 RPLAs를 구축하여 개인별 특성을 정확히 포착하고 표현하기 위해, 이 과정은 일반적으로 두 가지 중요한 단계로 구성된다: 1) 페르소나 데이터 수집 단계에서 개인별 페르소나를 형성하기 위해 필요한 데이터를 수집하며, 2) 페르소나 모델링 단계에서 수집된 데이터를 활용해 이러한 개인별 페르소나를 표현하는 모델을 생성함.
LLM의 발전에도 불구하고 개인화 RPLAs는 여전히 여러 과제에 직면해 있음. 이는 긴 입력 처리 및 방대한 검색 공간(Chen et al., 2023b; Abbasian et al., 2023), 희소하고 길며 노이즈가 많은 사용자 상호작용 데이터 활용(Zhou et al., 2024c), 사용자 프로필 이해를 위한 도메인 특정 지식 학습(Zhang et al., 2023c), 다중 모달 컨텍스트 이해(Dong et al., 2023), 개인정보 보호 및 윤리적 기준 준수(Benary et al., 2023; Eapen & Adhithyan), 실시간 응용 프로그램과의 원활한 통합을 위한 응답 시간 최적화 등이 있음.
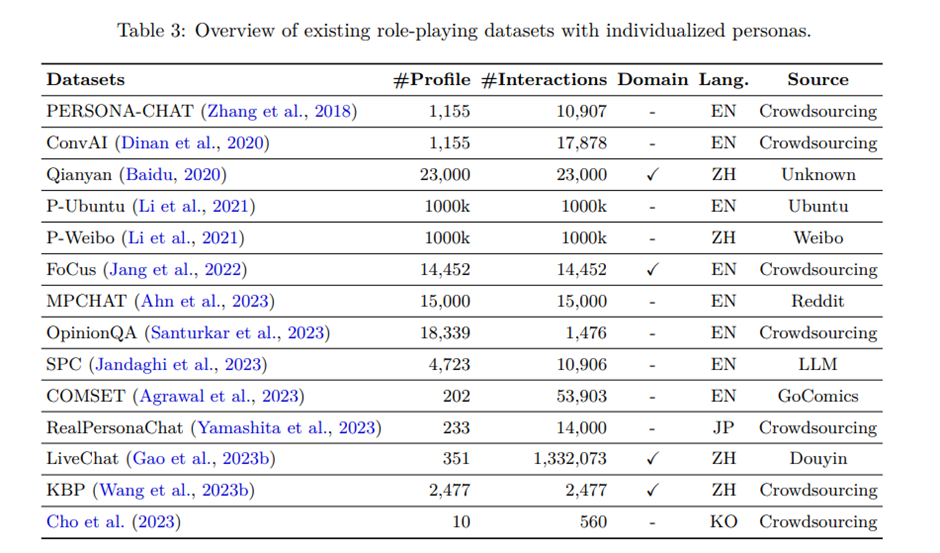
6.2 개인화된 페르소나 데이터 수집
영어(Ahn et al., 2023), 중국어(Baidu, 2020), 일본어(Yamashita et al., 2023), 한국어(Cho et al., 2023) 등 다양한 언어를 포함하는 개인화된 페르소나를 포함한 수많은 데이터셋이 존재함.
프로필 프로필은 개인화된 인물을 명확히 설명하는 기본적인 정보로, 일반적으로 잘 구조화되어 있음. 기본 요소에는 일반적으로 사용자의 이름, 성별, 인종 등이 텍스트 형식으로 포함됨(Santurkar et al., 2023). 또한 프로필에는 개인의 특성을 설명하는 자연어 설명이 포함되며, 이는 신원, 취미, 경험 및 기타 진술 등을 포함함(Zhang et al., 2018; Dinan et al., 2020; Gao et al., 2023b; Li et al., 2021; Ng et al., 2024) 또한 프로필에는 다중 모달 정보가 포함될 수 있음. 예를 들어, (Ahn et al., 2023)의 프로필은 소셜 미디어에 게시된 사진에 대한 개인의 댓글을 텍스트-이미지 쌍으로 통합함.
상호작용 상호작용 데이터는 개인화된 페르소나의 동적 변화를 포착함. 상호작용은 애플리케이션 사용 과정에서 생성되는 데이터로, 대화, 사용자 선호도, 기타 행동 등 개인화된 페르소나를 암시적으로 표현함. 예를 들어, PERSONA-CHAT (Zhang et al., 2018)과 ConvAI (Dinan et al., 2020)는 크라우드소싱을 통해 두 사람 간의 대화를 수집하며, LiveChat (Gao et al., 2023b)과 MPCHAT (Ahn et al., 2023)은 라이브 스트리밍과 레딧과 같은 인터넷 소스에서 다중 사용자 대화를 수집함. 데이터 구축 비용을 줄이기 위해 Jandaghi et al. (2023)은 대화 합성을 위해 LLMs를 활용한 Generator-Critic 아키텍처를 사용하며, Zeng et al. (2024)은 경험, 연설, 글 등 원시 자료에서 대화 데이터를 생성하기 위해 자동 주석화를 먼저 수행함. 자연어 대화 외에도 Agrawal et al. (2023)과 Santurkar et al. (2023)은 만화 그림과 다중 선택 질문을 상호작용 요소로 도입함.
도메인 지식 일반 언어 모델에 도메인 특화 지식을 통합하면 특정 도메인 내 사용자 프로필과 상호작용을 더 잘 이해하는 데 도움이 됨. 이는 사용자 요구사항을 정확히 이해하고 역할극에서 페르소나의 일관성을 유지하는 데 필수적임(Wang et al., 2023b). 예를 들어, 위키피디아와 같은 지식 기반을 통합하면 대화 내에서 언급된 명명된 엔티티에 대한 상세한 배경을 전체 페르소나의 일부로 제공할 수 있음(Jang et al., 2022; Wang et al., 2023b; Baidu, 2020).
6.3 개인화된 페르소나 모델링
개인화된 페르소나를 모델링하는 기존 방법론은 크게 두 가지 유형으로 분류될 수 있다: 오프라인 학습과 온라인 학습.
오프라인 학습 이 방법은 사전 존재하는 데이터셋에 포함된 특정 인물을 반영하도록 LLMs의 출력을 맞춤화함. 파라미터 미세 조정이 오프라인 학습의 주류 접근법으로 부상했으며, 일반적으로 SFT와 RLHF를 기반으로 함(Mondal et al., 2024; Zheng et al., 2023c; Li et al., 2024b; Jang et al., 2023). 예를 들어, Mondal et al. (2024)은 프로필 및 상호작용 데이터셋을 활용한 LLMs 개인화 위한 두 단계 접근법을 제안함. 또한 최근 일부 연구에서는 LLMs 개인화를 위한 비매개변수 학습 기술을 제안함. 예를 들어, Shea & Yu (2023)는 페르소나 일관성 비평가와 분산 감소 기술을 결합한 오프라인 RL 프레임워크를 소개했으며, Weng et al. (2024)는 모델의 활성화 상태 내에 임베딩 제어 벡터를 통합하여 다양한 성격 특성에 따라 동적 출력 조정이 가능하도록 함. 이러한 방법들은 다음과 같은 몇 가지 결점을 보여준다: 1) 정확성과 효율성 사이의 근본적인 trade-off를 겪음; 2) 데이터 세트의 품질에 크게 의존하고 있음; 3) 더욱 중요한 점은, 페르소나 데이터의 동적 변화에 적응하는 데 어려움을 겪고 있어 실제 적용 가능성을 제한하고 있음.
온라인 학습 온라인 학습에서 페르소나는 동적이며 지속적으로 진화함. LLMs를 사용한 효과적인 페르소나 학습은 일반적으로 비매개변수적이고 훈련이 필요하지 않으며, 이는 기억과 맥락의 효과적인 관리만을 포함함(Dalvi Mishra et al., 2022; Kim et al., 2024; Baek et al., 2023; Zhou et al., 2024c). 이 요구사항을 충족하기 위해 검색 모듈은 필수적이며, 특히 제한된 context window를 가진 LLMs에서 더욱 중요함(Mysore et al., 2023; Sun et al., 2024). 또한 효과적인 온라인 학습 방법론은 자연어 상호작용뿐 아니라 사용자의 비언어적 피드백도 고려함(Ma et al., 2023a).
비매개변수적 방법 외에도 온라인 상호작용 데이터를 활용한 미세조정은 온라인 페르소나 학습에 널리 적용되고 있으며, 이는 실시간 사용자 스트림 데이터에서 추출한 미니 배치(Qin et al., 2024)를 활용한 SFT와 실시간 사용자 피드백을 활용한 RLHF(Ding et al., 2023b; Bai et al., 2022a)를 포함함. 또한 Shaikh et al. (2024b)은 반복적인 DPO(Rafailov et al., 2024) 훈련을 통해 언어 모델 출력을 사용자의 실제 행동과 일치시키기 위해 10개 미만의 demonstrations를 사용함. 그러나 노이즈가 많은 상호작용 데이터에서 희소하고 인물별 특성을 정확히 인식하고 학습하는 데 심각한 도전 과제가 존재함. 또한 실제 사용자의 인물은 시간이 지나면서 변할 수 있어, 이를 효과적으로 모델링하고 업데이트하는 데 추가적인 어려움이 발생함. 따라서 비매개변수적 방법의 효과성은 기억 관리 및 검색 메커니즘에 크게 의존함.
6.4 LLM 및 개인화된 페르소나의 평가
대화 대화를 위한 개인화에서의 초기 작업은 페르소나를 이해하려는 첫 시도를 나타냄. 이 시나리오에서 전통적인 작업에는 대화 내용을 기반으로 화자의 페르소나 요소를 예측하는 것(Gao et al., 2023b; Jang et al., 2022), 맥락과 페르소나 프로필을 고려해 다음 발화를 예측하는 것(Humeau et al., 2019), 랭킹 모델의 성능을 평가하는 것(Gao et al., 2023b; Ahn et al., 2023), 다중 사용자 대화에서 수신자를 인식하는 것(Liu et al., 2022) 등이 포함됨. 평가 지표는 일반적으로 정확도, 유창성(Dinan et al., 2018), 유사성(Popović, 2017; Post, 2018; Lin, 2004)을 생성된 응답과 원본 응답 간에 비교하는 것, 회수율, 평균 상호 순위(MRR)(Gao et al., 2023b; Ahn et al., 2023), 그리고 쿼리 관련성, 인물 함축, 응답 유창성에 대한 수동 평가(Liu et al., 2022; Gao et al., 2023b) 등이 포함됨. 최근 ECHO(Ng et al., 2024)는 RPLA 평가에 튜링 테스트를 도입하여 대상 개인의 지인들을 참여시켜 사람과 그들의 RPLA 대응물을 구분하도록 함.
추천 개인화 추천을 위한 평가에서는 LLMs가 상호작용 기록에서 사용자의 선호도를 이해하고 활용하여 미래의 추천에 적용하는 능력을 중점으로 평가함. 이 분야의 전통적인 평가는 LLMs가 사용자의 선호도를 이해하고 추출하는 능력을 측정함(Dai et al., 2024b; Yang et al., 2023a; Maghakian et al., 2023; Liu et al., 2023c; Mysore et al., 2023), 순위를 매기는 능력(Dai et al., 2023a; Hou et al., 2024; Kang et al., 2023; Liu et al., 2023a; Bao et al., 2023; Chao et al., 2024), 제로샷 및 소량 데이터 기반 추천 능력 (Wang & Lim, 2023; Liu et al., 2023a), 그리고 순차적 추천 능력 (Yang et al., 2024; Liu et al., 2023a)이 포함됨. 평가 지표로는 일반적으로 Top-k 정확도와 MRR이 사용되어 효과성을 평가함.
과제 해결 평가의 주요 초점은 이론적 마음 이해(Zhou et al., 2023b; Sap et al., 2023; Jin et al., 2024; Su & Bao, 2024; Rescala et al., 2024; Xu et al., 2024a), 도구 사용(Qin et al., 2023; Li et al., 2023h; Farn & Shin, 2023; Huang et al., 2023d; Zhuang et al., 2024; Huang et al., 2024c), 및 작업 자동화 (Wen et al., 2023a; Shen et al., 2023c; Gao et al., 2023a; Valmeekam et al., 2024). 더 넓게 보면, 기존 연구들은 모델의 사용자 요구사항 이해 및 예측 능력 (Tan et al., 2024; Zhang et al., 2024a), 개인 데이터의 안전한 처리 (Yim, 2023; Wu 등, 2024d; Kumar 등, 2024; Wu 등, 2024a; Yin 등, 2024), 외부 도구나 앱에서 정보를 상호작용하는 능력(Yuan 등, 2024a; Huang 등, 2024b; Xie 등, 2024c; Huang et al., 2024d), 그리고 개인 비서로서 작업을 효과적으로 수행하는 것(Dong et al., 2023; Guan et al., 2023; Mucha et al., 2024) 등이 포함됨.
7 RPLA 응용의 이면에 있는 위험
7.1 유해성
LLM의 내재된 독성 최근 연구들은 LLMs가 유창하고 일관된 콘텐츠를 생성하는 데 능숙할 뿐만 아니라 잠재적으로 독성 있는 콘텐츠를 생성할 수 있음을 강조함 이전 연구(Zhang & Wan, 2023; Wen et al., 2023b)는 이러한 모델이 유해한 콘텐츠를 생성하는 우려스러운 경향을 보여줌.
RPLAs의 난제 유해성 문제는 RPLA 환경에서 더욱 두드러짐. 여기서 대규모 언어 모델(LLMs)은 사회적 도덕 기준에 부합하지 않을 수 있는 캐릭터의 행동과 일치하는 유해 콘텐츠를 생성할 가능성이 높기 때문임(Deshpande et al., 2023). 그러나 일반적인 역할극을 수행할 수 있는 완전히 안전한 RPLAs를 개발하는 것은 여전히 어려운 과제임. 인간이 생성한 데이터에 내재된 유해 콘텐츠는 깨끗한 훈련 데이터셋을 개발하는 것을 복잡하게 만듦. 또한, 이러한 정제된 훈련 데이터셋은 모델의 성능, 특히 역할극을 포함한 다양한 작업에서 일반화 능력을 저해할 수 있음.
안전성과 성능의 균형을 위한 전략 이러한 도전 과제에도 불구하고, 최근 연구에서는 모델의 기본 매개변수를 변경하지 않고 독성 완화를 위한 전략으로 프롬프트 엔지니어링과 세미틱 검열을 제안하고 있음(Han et al., 2022; Ahn et al., 2023). 이러한 접근 방식은 유해한 출력을 줄이는 것과 모델의 다목적성과 다양한 응용 분야에서의 효과성을 유지하는 것을 균형 있게 조화시키는 것을 목표로 함.
7.2 편향
역할극 시나리오에서의 편향의 표현 편향은 암묵적 형태와 명시적 형태로 나타날 수 있음. 암묵적 편향은 RLPAs 내부의 태도나 고정관념으로, 이해, 행동, 결정에 영향을 미침. 반면 명시적 편향은 제시된 맥락이나 할당된 역할과 일치하는 의식적인 신념과 태도를 의미함. LLMs는 안전 정책(예: RLHF)으로 인해 직접적인 편견을 출력하지 않도록 설계되었지만(Ouyang et al., 2022), 특히 RPLA 조건 하에서 편견을 나타낼 수 있다: 1) 추론 편향: 이 문제는 LLMs에 특정 인격이 할당될 때 더욱 악화되며, 이는 추론 능력(예: 산술 문제)에 영향을 미치는 암묵적 편향을 유발할 수 있음. 특히 인종, 성별, 종교, 직업과 관련된 맥락에서 이 현상이 두드러짐(Zheng et al., 2023a; Kotek et al., 2023; Cheng et al., 2023a; Naous et al., 2024). 2) 정치적 편향: RPLAs는 중립성을 유지하고 정치적 입장이나 편향을 피해야 함. 그러나 연구 결과 RPLAs는 환경 친화적, 좌파 자유주의적 관점에 정치적 경향을 보인다는 것이 밝혀짐(Rutinowski et al., 2023; Hartmann et al., 2023). 3) 역할 기반 편향: 역할극 맥락에서 역할 기반 편향은 명시적 편향의 한 유형임. 캐릭터의 진정성을 유지하면서 편향을 관리하는 것은 중요한 과제. 예를 들어, "히틀러"와 같은 인물을 가진 RPLA가 생성되면, 그 역할 때문에 유대인에 대한 편향을 표현하게 되며, 이는 윤리적 기준을 위반함.
RPLAs의 편향 원인 이러한 편향은 모델의 사전 훈련 데이터와 사용자 상호작용 모두에서 기인한다고 추정됨(Xue et al., 2023). 특히, 훈련 데이터의 불균형은 이러한 편향에 크게 기여하며, 데이터 내 특정 편향의 우세함이 LLM의 파라메트릭 메모리에 편향이 내재화될 수 있기 때문임. 또한 Perez & Ribeiro (2022)와 Branch et al. (2022)는 LLMs가 사용자 프롬프트에 민감하다는 점을 강조하며, 이는 의도하지 않게 편향된 출력을 유도할 수 있음. 이 문제는 모델이 사용자의 부정적 감정에 영향을 받을 때 더욱 악화됨(Coda-Forno et al., 2023).
편향 완화를 위한 전략 RPLAs에서의 편향을 해결하려면 다각적인 접근 방식이 필요하다: 1) 데이터 준비 단계: 데이터 정제와 같은 기술은 훈련 데이터 세트에 존재하는 편향을 크게 완화할 수 있음(Linardatos et al., 2020). 2) 개발 단계: 후처리 단계에서 중립적이고 공정성을 고려한 분류기를 구현하는 것은 편향을 추가로 줄이는 효과적인 전략으로 입증됨(Sun et al., 2019; Zafar et al., 2017). 역할 플레이 시나리오에서 공정성을 달성하려면, 그룹과 개인과 관련된 역할 모두에 대한 공정성을 보장하는 섬세한 균형이 필요함. 예를 들어, 특정 인구 통계와 연결된 RPLA는 편향을 강화하지 않도록 의식적으로 노력해야 함.
페르소나 구축 편향 현재 널리 사용되는 페르소나 구현 방식은 종종 단순하고 표면적이라고 여겨짐. 대부분의 페르소나 구현은 기본적인 캐릭터 세분화에 유용하지만, 캐릭터 행동을 형성하는 더 깊은 특성 및 복잡성을 종종 간과함(Chen et al., 2023c; Zhou et al., 2023a; Shao et al., 2023; Tu et al., 2024; Yuan et al., 2024b). 현재의 페르소나 구축은 독특한 사건이나 개인의 행동에 영향을 받는 특정 시나리오에 필요한 유연성과 적응성을 갖추지 못하고 있음. 따라서, 다양한 역할 플레이 환경에서 캐릭터 행동을 이해하고 예측하기 위해 페르소나의 구성 차원을 정교화하고 확장하는 것이 중요함.
7.3 할루시네이션
RPLAs에서의 환각 LLMs에서의 환각은 이러한 모델이 사실적으로 잘못된 정보를 생성하는 경우를 의미하며, 이는 특히 지식 집약적 작업에서 두드러지는 문제임(Wang et al., 2023g). RPLAs의 환각에 대해 Shao et al. (2023)을 따라, 에이전트가 할당된 역할에 맞지 않는 방식으로 응답하는 행동을 '캐릭터 환각'으로 정의함. 예를 들어, 셰익스피어는 제2차 세계대전과 관련된 어떤 지식도 가지고 있지 않아야 함. 특히, LLMs가 특정 기간 동안 역할을 수행할 때 발생하는 환각이 있음. Ahn et al. (2024)은 이를 '특정 시점 캐릭터 환각'이라고 명명함. 예를 들어, 어린 시절의 해리 포터를 시뮬레이션하는 에이전트가 미래의 사건을 잘못 언급하는 경우가 이에 해당됨.
RPLAs에서의 환각 현상 완화 RPLAs는 할당된 캐릭터 범위를 벗어난 주제를 만나면 무지함을 보여주거나 답변을 삼가는 방식으로 대응해야 하며, 이는 외부 지식 기반을 통합하는 등 전통적인 환각 현상 해결 방안과 차별됨. 최근 연구(Shao et al., 2023)는 모델을 미세 조정하여 RPLAs가 지식을 잊거나 응답에서 지식 부족을 명시적으로 표현하도록 훈련하는 데 초점을 맞추고 있음. Neel 등(2021)과 Pawelczyk 등(2023)의 연구에서 제안된 대체 학습 포기 전략을 탐구하는 것도 유망한 방향일 수 있음.
7.4 개인정보 침해
LLM의 개인정보 보호 과제 OpenAI의 GPT-4(OpenAI, 2023)와 같은 고급 안전 조치에도 불구하고, 이러한 모델은 Li et al. (2023e)가 지적한 것처럼 개인 정보를 추출하기 위한 복잡하고 다단계 공격에 취약할 수 있음. 또 다른 우려는 LLMs가 제한된 데이터로부터 개인을 식별할 수 있는 능력임. Sweeney(2002)는 미국 인구의 많은 부분이 몇 가지 속성만으로 유일하게 식별될 수 있다고 강조함. Staab 등(2023)은 이 우려를 LLMs로 확장해, 위치, 성별, 생년월일과 같은 특정 세부 정보를 기반으로 개인을 인식할 수 있다고 지적함.
RPLAs 내 개인정보 침해의 숨겨진 위험 이메일 주소나 전화번호와 같은 개인 정보를 우연히 노출할 위험은 과소평가되어서는 안 되며, 이는 신원 도용 및 민감한 데이터에 대한 무단 접근과 같은 심각한 위협을 초래할 수 있음 개인별 특정 인물을 LLM에 할당하여 개인 정보를 수집하려는 행위는 이러한 침해를 방지하기 위해 세심한 감독이 필요함.
개인정보 보호 강화 전략 이러한 개인정보 보호 문제를 해결하기 위해서는 종합적인 전략이 필요함. 텍스트 익명화 도구를 사용하는 것은 개인 데이터를 상호작용에서 효과적으로 제거하는 핵심 단계임. RPLAs가 엄격한 개인정보 보호 프로토콜을 준수하도록 보장하는 것도 중요하며, 이는 그들이 개인정보를 침해할 수 있는 대화나 상황을 유발하지 않도록 방지함. 또 다른 유망한 발전은 개인정보 유출을 탐지하고 방지하기 위해 설계된 전문 도구(예: ProPILE, Kim et al., 2023d)의 개발임. 향후 연구는 개인정보 보호를 위한 방법론을 정교화하고 확장하는 데 초점을 맞춰야 하며, RPLAs가 안전하고 책임감 있게 사용되도록 보장해야 함.
7.5 실제 환경에서의 기술적 과제
사회적 지능과 마음 이론의 부족 사회적 지능과 마음 이론(Premack & Woodruff, 1978)은 자신과 타인의 내적 세계를 인식하고 추론하는 능력으로, LLMs가 사회적 지능을 갖춘 실체를 시뮬레이션하는 데 필수적임(Kosinski, 2023; Sap et al., 2023). 그러나 현재의 LLMs에서 이러한 능력은 여전히 개선이 필요하며(Shapira et al., 2023; Zhou et al., 2024a; Light et al., 2023; Kim et al., 2023c), 이는 RPLAs가 직면한 다음과 같은 문제에 대한 심각한 도전 과제를 제기한다: 1) 적절한 감정적 지원과 가치 제공의 한계: 사회적 지능과 마음 이론은 RPLAs가 사용자에게 효과적인 감정적 지원과 가치를 제공하기 위해 필수적임. 그러나 기존 LLMs는 이러한 능력에서 여전히 부족하여 RPLAs가 사용자에게 적절한 감정적 지원을 제공하지 못하게 함. 2) 자기 중심적 행동 경향: 현재의 RPLAs는 사용자의 감정적 필요에 집중하기보다는 자신의 인격을 강조하고 대화를 자신의 관심사로 유도하는 경향을 보임.
장문 맥락의 도전 과제 긴 맥락 텍스트 해석과 관련해 다음과 같은 주요 도전 과제가 있다: 1) 장문 맥락에 대한 추론: 장문 맥락 데이터 학습은 모델이 장문 맥락을 처리하고 긴 입력을 수용할 수 있어야 하며, 더 중요하게는 대규모 맥락에서 정보를 통합하고 더 완전한 캐릭터 인격을 추론하기 위해 장거리 의존성을 포착할 수 있어야 함. 2) 효율성: 계산 측면에서 장문 맥락의 높은 복잡성은 계산 부담을 줄이기 위해 효율적인 모델링 방법과 근사화 전략이 필요함. 3) 몰입감: RPLAs는 긴 컨텍스트 내에서 관련 없는 정보의 바다에서 진정한 캐릭터 관련 부분을 식별할 수 있을 만큼 몰입감이 있어야 하며, 동시에 생성된 긴 텍스트 전체에서 캐릭터 일관성을 유지해야 함.
지식 격차 역할극 시나리오에서 상세한 역사적, 문화적, 또는 맥락적 이해가 필요한 경우, RPLAs는 지식 격차를 자주 드러냄. RPLAs가 특정 분야에 대한 심층적이고 정확한 응답을 제공하지 못하는 것은 복잡한 역할극 환경에서 표면적 또는 잘못된 묘사로 이어질 수 있음. 여러 연구에서는 캐릭터 평가를 위해 RPLAs를 평가하는 데 LLMs를 활용하기도 했음(Shao et al., 2023; Tu et al., 2024). 그러나 RPLAs는 익숙하지 않은 캐릭터를 정확히 평가하는 데 어려움을 겪을 수 있으며, 이는 평가 결과의 신뢰성을 저해할 수 있음.
7.6 인격화
사회적 고립 RPLAs와의 빈번한 상호작용은 실제 인간과의 접촉에 대한 필요성이나 욕구를 감소시킬 수 있으며, 이는 필수적인 사회적 기술의 퇴화로 이어질 수 있음. 인간 간의 상호작용은 본질적으로 더 복잡하며, 미묘한 이해와 공감 능력을 요구하는데, 이는 RPLAs와의 상호작용을 통해 완전히 길러지지 않을 수 있음. 이러한 과도한 의존은 사회적 고립으로 이어질 수 있으며, 개인이 가상 RPLAs에 지나치게 의존하게 되면 외로움, 우울증, 불안감 등 정신 건강에 부정적인 영향을 미칠 수 있음.
여론 조작 RPLAs, 특히 엄격한 윤리적 감독 없이 설계되거나 프로그래밍된 경우, 의도적으로 또는 우연히 허위 정보나 소문을 확산시킬 수 있음. 예를 들어, 소셜 미디어에 배포된 RPLAs가 대규모 팔로워를 확보하면 그 영향력이 상당할 수 있음. 고도로 발전된 RPLAs는 사용자에게 제시하는 이야기를 미묘하게 조작하여 여론을 조작할 수 있음. 이는 개인의 인식, 결정, 심지어 투표 행동에 영향을 미칠 수 있으며, 사용자는 자신이 인간 간의 대화 대신 가상 RPLAs에 의해 영향을 받고 있다는 사실을 인식하지 못할 수 있음.
8 결론
RPLA 시스템의 미래 방향 우리는 RPLA 애플리케이션의 구축을 촉진하기 위한 몇 가지 중요한 미래 방향을 제안한다:
-
결정 지원 위한 인과 데이터 분석: 역할극 결정은 정당화 가능한 이유로 이루어져야 하며, 이는 관찰 가능한 행동의 단순한 모방을 넘어 그 밑바탕에 있는 인과 관계를 이해하는 모델을 요구함. 복잡하게 얽힌 경험에서 인과 요인을 추출하고 확인하는 것은 고급 분석 기술과 데이터 해석 전략이 필요로 하는 중대한 도전 과제를 제기함. 이를 통해 RPLA가 정보에 기반한 현명한 결정을 내릴 수 있도록 지원해야함.
-
개선된 의사결정: 의사결정 과정은 단순히 과거 사례를 반복하는 것이 아니라, 개별 시나리오에 최적화된 결과를 보장하기 위해 맞춤형으로 설계됨. 이는 고급(초인적 수준에 가까운) 지능을 보여주는 의사결정, 오류 회피, 또는 어려운 딜레마에서 최선의 선택을 내리는 것을 포함함. 이러한 자율성은 RPLAs와 그 기반이 되는 LLMs가 역할과 관련된 맥락과 복잡성을 포괄적으로 수집하고 활용할 수 있어야 함.
-
RPLA를 개인용 의사결정 보조 도구로: RPLAs가 종합적인 개인용 보조 도구로 발전하는 것은 중요한 전환점을 의미함. 이러한 시스템은 맞춤형 쇼핑, 개인화된 여행계획부터 차세대 추천 시스템까지 인터넷 행동의 모든 측면을 관리할 수 있음. 다중 모달 데이터 처리(이미지 및 비디오 포함)를 통합하고 고급 시각화 기술과 연결함으로써 RPLAs는 일상 업무의 개인화 및 효율성을 크게 향상시킬 수 있음.
-
자율적 역할극을 통한 사회적 시뮬레이션: RPLAs를 사회적 시뮬레이션에 활용하면 다양한 시나리오에서 복잡한 실험을 수행해 심리적 및 사회학적 행동을 연구함으로써 적용 범위를 크게 확장할 수 있음. 다양한 캐릭터를 역할극으로 수행하는 RPLAs는 다양한 성격 특성이 사회적 지능에 미치는 영향을 탐구하는 다목적 테스트 대상이 되어 인간 행동과 상호작용 동역학에 대한 귀중한 통찰을 제공할 수 있음.
