2025년 1월, ACL COLING 2025 (Proceedings of the 31st International Conference on Computational Linguistics) 게재
1. 서론
기존 테스트 환경은 개인화된 선호도를 수집하고 동일한 사용자를 대상으로 모델을 평가하는 것이 어려워 제한적임. 다중 선택 질문은 LMs의 실제 사용 사례를 반영하지 못하는 문제가 있고, 일반적으로 조사 대상 인구집단의 특성을 다루고 특정 개인에 대한 상세한 정보를 포함하지 않아 개인화 응용 프로그램에 대한 유용성이 제한됨.
본 연구에서는 이 문제를 합성 페르소나를 이용해 해결하고자 함. 이 연구는 다음과 같은 기여를 함: 첫째, 현재 LM의 다양한 사용자 역할극 능력을 체계적으로 평가하고 실제 인간 대상 연구를 통해 결과를 검증함. 둘째, 1,586개의 합성 페르소나로 구성된 벤치마크와 개인별 페르소나에서 분할된 여러 데이터셋에 포함된 3,868개의 프롬프트와 317,200개의 다양한 피드백 쌍으로 구성된 대규모 선호도 데이터셋을 생성함. 이 데이터 및 평가 프레임워크는 (1) 테스트 베드, (2) 개발 환경, (3) 다원적 정렬 접근법의 재현 가능한 평가, (4) LM의 개인화, (5) 선호도 추출에 활용될 수 있음.
2. 관련 연구
다원주의적 정렬의 과제. 언어 모델(LM)은 수십억 명의 인터넷 사용자가 생성한 데이터로 훈련되지만, 이 참여는 수동적이며 사전 훈련 데이터셋은 특정 인구 통계 그룹을 과대 대표하여 소수 집단이 배제될 수 있음.
다원적 정렬 평가. 다른 연구들은 소규모 합성 실험이나 단순한 바이모달 데이터셋을 사용했으며, HH-RLHF는 현실 세계의 분포적 관점을 대표하지 않음. PRISM 데이터셋은 전 세계 다양한 인구층으로부터 수집된 개방형 대화 데이터를 통해 이 방향에서 진전을 이뤘으나 이 데이터셋은 인간 참여자가 LM에 피드백을 제공해야 하기 때문에, 동일한 분포 하에서 확장 가능한 평가 알고리즘과 모델을 개발하는 데 한계가 있음.
역할극 언어 에이전트. 최근 연구는 프롬프트, 내재된 지식, 튜닝을 활용해 LMs가 다양한 인격과 특성을 모방할 수 있음을 보여주었음. 이러한 에이전트를 활용한 신중하게 설계된 역할극 시나리오는 인간 참여자 없이 정렬 접근법을 평가하기 위한 풍부하고 통제 가능한 테스트베드를 제공할 수 있음.
3. PERSONA: 다원적 정렬을 위한 테스트베드
3.1. 페르소나 인구 집단 생성
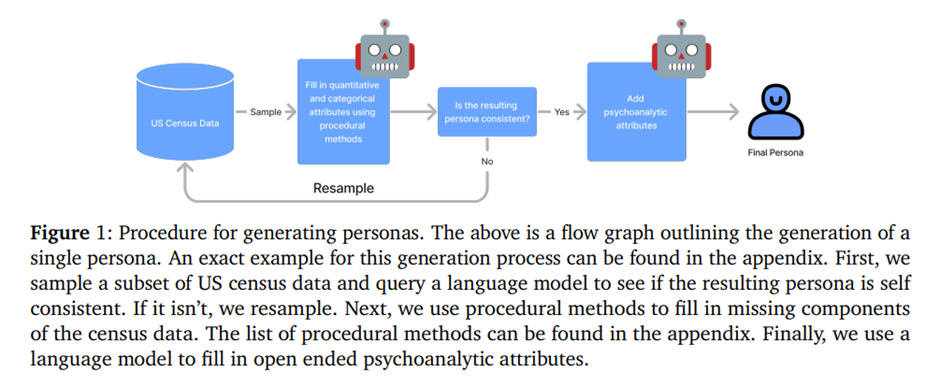
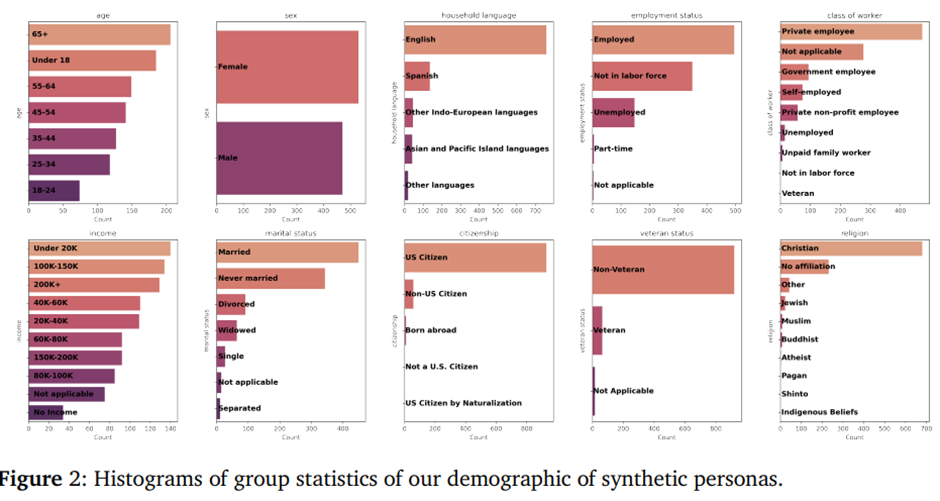
(1) PUMS 파일에서 샘플링, (2) 각 프로필에 추가적인 통계적으로 정확한 심리인구학적 데이터를 풍부하게 하는 것, (3) 언어 모델을 사용하여 특정 필드의 데이터를 추가로 보강하고, (4) GPT-4를 활용해 불일치(또는 정제)를 해결하는 단계로 데이터셋을 구축함.
모순되지 않는 속성의 하위 집합을 직접 샘플링한 후, 인구 통계학적 사용자 프로필을 생성한 후 GPT-4에 질의를 보내 추가로 모순되는 프로필을 필터링하여 약 8.5%의 구성 요소를 제거함. Big Five 성격 특성을 이용해 5요인 모델 성격 프로필을 생성하고, 추가적인 핵심 가치, 특이점, 행동 양식은 수동으로 선별된 세트에서 샘플링함. 심리분석적 특성도 추가로 포함함.
3.2 선호도 데이터셋 구축
프롬프트 큐레이션. PRISM 데이터셋에 대해 프롬프트의 품질과 관련성을 확보하기 위해 여러 후처리 단계를 수행함. 먼저, 물음표가 없는 지시문과 5단어 미만의 지시문을 제거함. 그 다음, GPT-4를 제로샷 분류기로 활용해 질문이 논쟁적인지 여부를 평가하고 다양한 의견을 유도하지 않는 프롬프트를 제거함. 일반화 능력을 평가하기 위해 데이터셋을 3,000개의 훈련 프롬프트와 868개의 보류 프롬프트로 나누었으며, 이는 주제 분포를 균일하게 반영함.
선호도 데이터셋 큐레이션. 프롬프트 x_i와 페르소나 p_i 를 독립적으로 무작위로 샘플링함. 이는 전체 의견 분포를 평가할 수 있도록 하고, 모델이 사용자로부터 선호도와 정보를 추출하도록 가르치며, 우연한 상관관계에 의존하지 않도록 하기 위함임.
GPT-4를 평가 도구로 이용함.
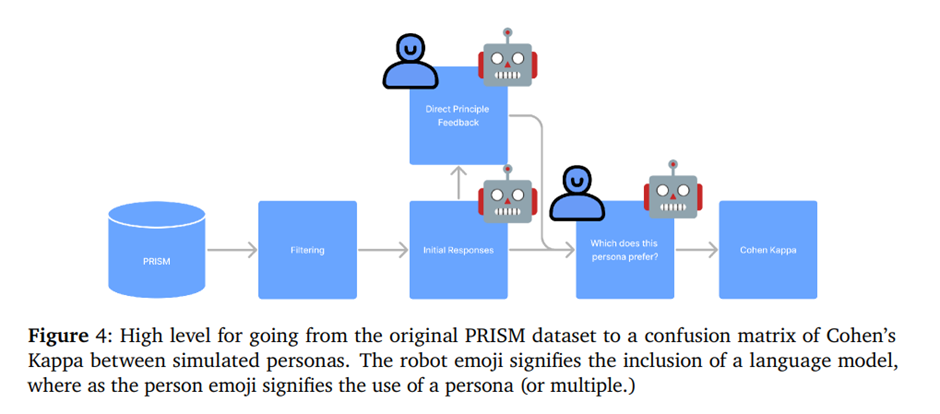
Direct Principle Feedback (DPF) 접근법을 사용하여 피드백 데이터를 구축함. 프롬프트와 페르소나 쌍 x_i,p_i 를 확보한 후, GPT-4를 사용하여 질문만 제공하며 페르소나 프로필에 접근하지 않고 응답y_i^l∼ π(y ┤| x_i)을 샘플링함. 이 과정을 통해 "대표적인" 사용자를 대리하는 응답을 얻음. 이후 초기 응답 y_i^l 과 사용자 프로필을 모델에 제공한 후, 모델이 사용자의 가치를 반영하도록 응답을 재작성하도록 요청함. y_i^w∼ π(y ┤| y_i^l,x_i,p_i,r), 여기서𝑟 는 DPF 쿼리 프롬프트임. 이후 다음과 같은 피드백 튜플을 얻게 됨. 피드백 튜플 (p_i ,x_i ,y_i^w ≻ y_i^l )에서, 우리는 페르소나 p_i 가 항상 재작성된 버전을 선호한다고 가정하고, 이는 96% 성립함.
각 페르소나에 대해 3,000개의 훈련 프롬프트에서 150개의 프롬프트를 샘플링하고 각 프롬프트당 단일 선호도 쌍을 생성함. 개인화 및 선호도 추출 응용 프로그램에서 150개의 쌍을 100개의 훈련 프롬프트와 50개의 테스트 프롬프트로 나누어 보관함. 또한 868개의 테스트 프롬프트에서 50개의 프롬프트를 추가로 샘플링하여 50개의 선호도 쌍을 생성함. 전체 데이터셋에는 각 페르소나당 100개의 훈련 선호도 쌍과 50개의 훈련 프롬프트와 50개의 테스트 프롬프트로 나뉜 100개의 테스트 선호도 쌍이 포함되어 총 158,600개의 훈련 선호도 쌍과 동일한 양의 테스트 데이터가 포함됨.
4. 데이터셋 분석 및 인간 검증
4.1. Leave One Out 분석
인물 속성이 평가 과정에 미치는 관련성을 확인하기 위해 한 개 제외 분석을 수행함. 각 속성 𝑎𝑖에 대해, 해당 속성을 제외한 3개의 속성을 가진 40개의 인물을 무작위로 생성함. 이후 첫 번째 세트와 동일하지만 한 개 제외 속성 𝑎𝑖을 추가한 40개의 인물 세트를 생성하여, 각 인물당 총 4개의 속성을 갖도록 함.
우리는 20개의 질문과 기준 답변을 정리했으며, 이는 인간 평가에 사용되었습니다 각 페르소나 쌍 p{i,j} = (Original Persona{i,j} ),Original Persona_{i,j} + LOO Attribute)에 대해, 여기서 1 ≤ i ≤ |attributes| 이고 1 ≤ j ≤ 40 임. 모든 20개의 기본 답변을 검토하고 개선하여 주어진 페르소나에 더 맞춤형으로 만들었음.
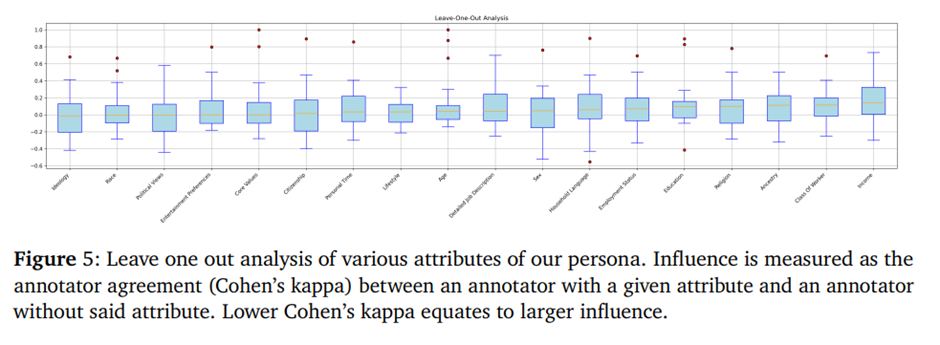
Cohen의 카파 계수를 사용하여 원본 페르소나와 LOO 속성이 연결된 페르소나 간의 주석자 간 일치도를 측정함. 각 쌍 p_{i,j} 에 대해 원본 페르소나와 LOO 속성이 연결된 페르소나 간의 주석자 간 일치도를 측정하고자 함. 이는 1 ≤ i ≤ |attributes|, 1 ≤ j ≤ 40인 모든 경우(∀i,∀j)에 대해 반복됨. 이후 각 속성에 대한 Cohen의 카파 분포를 보고하여 가장 영향력 있는 속성이 있는지 확인함. 결과는 그림 5에 표시된 바와 같이, 전체 페르소나가 선호도 추출 과정을 주도하지만 단일 속성이 페르소나를 압도하지는 않는다는 것을 보여줌.
4.2. 인간 평가
4.2.1. 실험 설계
인간 평가를 위해 우리는 핵심 가치와 엔터테인먼트 선호도를 포함한 고정된 속성 집합을 가진 20개의 페르소나를 선정했음. 이후 80명의 참가자를 모집했으며, 각 페르소나는 4명의 독립된 참가자에게 표시되었고, 각 평가자는 정확히 하나의 페르소나만을 보았음. 각 페르소나에 대해 10개의 질문을 선정했으며, 이는 각 페르소나에 대해 20개의 질문으로 시작해 인간 주석의 제한으로 인해 무작위로 10개로 축소된 PRISM 정제 단계를 초기 생성하는 방식으로 진행되었음. 각 참가자는 “페르소나를 모방하는 것”이 무엇을 의미하는지 설명하는 페이지를 제공받았음. 각 페르소나에 대해 4명의 참가자 중 3명의 다수 답변을 채택했음.
4.2.2. 결과
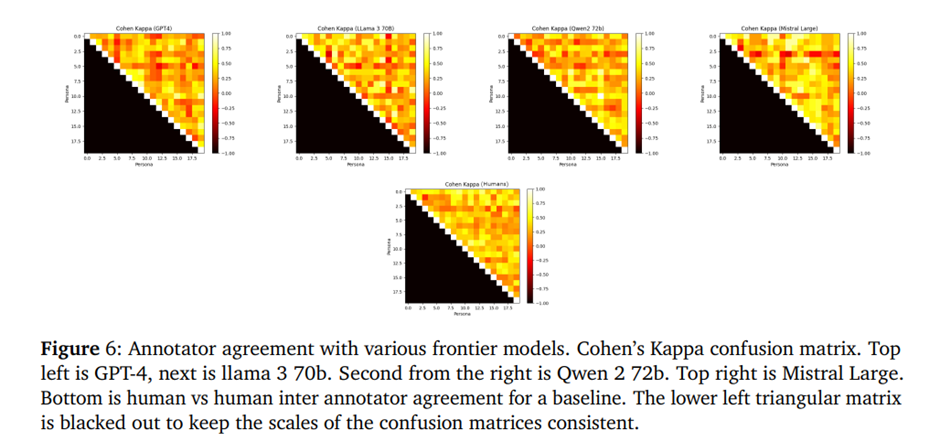
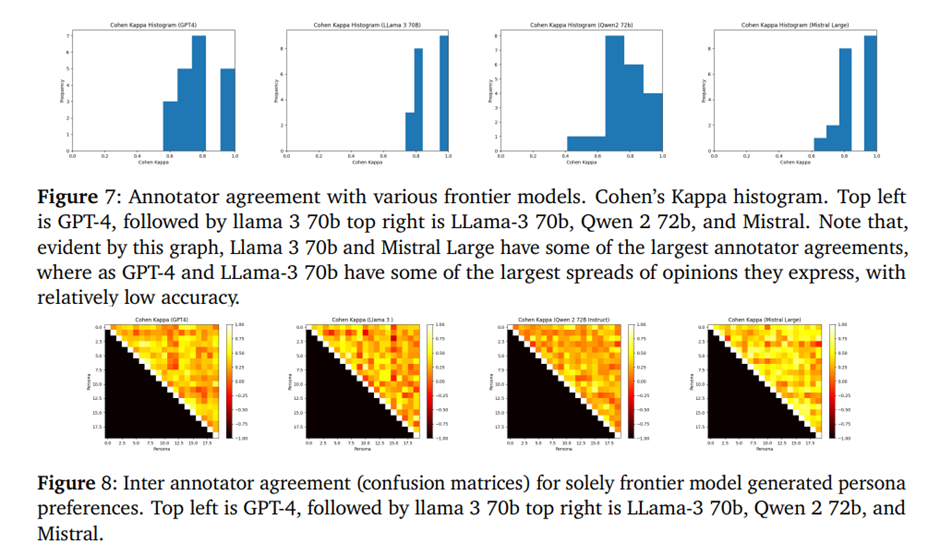
그림 6과 7은 인간 참가자와 다양한 최첨단 언어 모델(GPT-4, LLama-3 70b, Qwen 2 72b, Mistral Large)이 동일한 인물을 모방할 때의 주석자 일치도를 Cohen의 Kappa로 측정된 결과를 보여줌. 특히 GPT-4는 인간 주석자와 높은 일치도를 보여주며, Kappa 값이 0.6~0.8 범위(상당한 일치도)에 집중되어 있음.
그림 7에서 볼 수 있듯이 Llama-3 70b와 Mistral Large는 GPT-4와 Qwen 2 72b보다 주석자 일치도가 높음. 후자 두 모델은 표현된 의견의 분산이 더 넓고 정확도가 낮음. 이는 모든 모델이 일정 수준에서 역할 연기를 수행할 수 있지만, 인간과 유사한 페르소나 선호도와 일치하는 능력은 일관되지 않음을 의미함.
5. LLM as a judge를 이용한 개인화의 광범위한 평가
언어 모델의 다양한 페르소나와의 정렬 능력을 둘러싼 광범위한 논의를 가능하게 하는 기반이 되고 인간이 검증된 다원적 정렬 벤치마크인 PERSONA Bench를 제시함.
5.1. 기준 성능
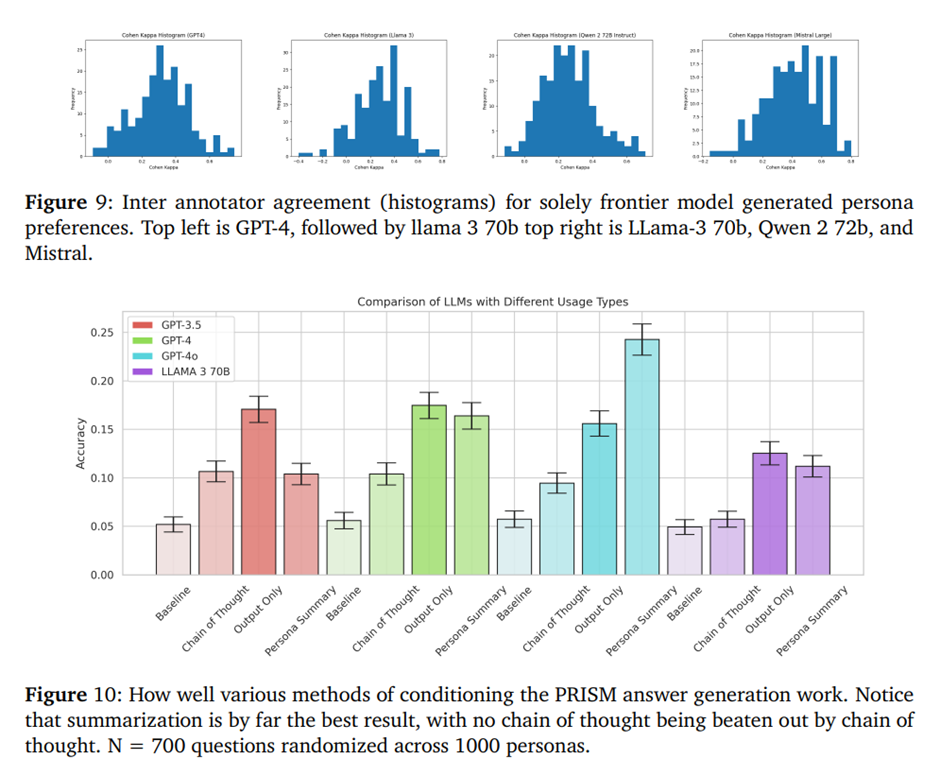
기준선으로, 모델이 특정 페르소나에 대한 세부 정보를 제공받지 않고, 사고 과정 생성을 허용하지 않을 때 해당 페르소나에 대한 개인화 능력을 측정하고자 함. 모델 크기나 성능과 거의 상관없이 전체적으로 약 5%의 정확도를 기록했음.
5.2. 개인화된 답변 생성에서 chain of thought의 추가 효과
Chain of thought를 포함하면 성능이 저하됨.
5.3. 페르소나 요약
CoT에 더 많은 가이던스를 제공하면 성능이 향상될 것이라고 가설을 세움. 언어 모델에게 질문에 답하기 전에 PRISM 질문과 본질적으로 관련된 페르소나의 부분을 먼저 요약하도록 요청함.
이 접근법은 테스트한 모든 모델 중 가장 높은 성능을 기록함.

LLM-as-a-judge 를 통해 GPT-4o-mini는 원본 페르소나와 페르소나 요약문 사이의 텍스트 차이를 찾아냄.
기본 검증(sanity check)에서 LLM-as-a-judge는 질문에 대한 답변 측면에서 모든 페르소나와 페르소나 요약이 동일하지 않다고 보고함.
GPT-4o-mini가 생성한 차이점에 핵심 인물 속성 또는 해당 속성의 동의어가 포함된 빈도를 측정하여 요약 단계에서 근접 컨텍스트 창에서 특정 인물 구성 요소가 얼마나 자주 제거되었는지 확인함. 요약 단계에서 제거된 요소는 주로 연령과 생활 방식과 같은 요소가 가장 높았고, 제거된 속성은 모델 간에 매우 일관되었으며, 동일한 질문에 대한 동일한 모델 간에도 일관성을 보였음.
5.4. Pass@K 평가
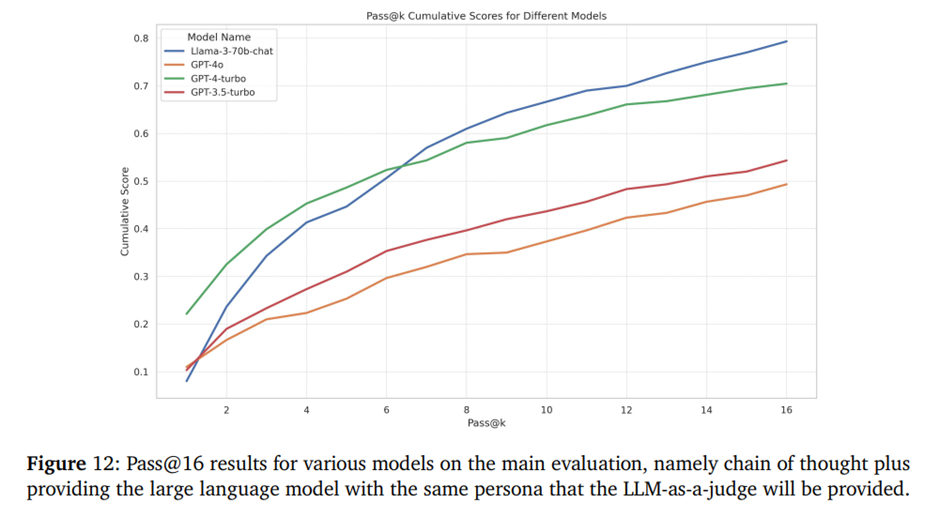
프로덕션 환경에서 어떤 모델을 배포할지 결정하는 주요 과제 중 하나는, 복합 추론(compound inference)에 대한 모델의 확장성(scalability)임. 이를 위해, 주된 평가 방식(Chain-of-Thought + 해당 페르소나 정보를 LLM에 제공)을 기반으로, kkk값을 최대 16까지 늘려 pass@k 평가를 수행했음. 그 결과, GPT-4o와 GPT-3.5처럼 전통적으로 성능이 높고 안전한 모델들 이 실제로는 가장 낮은 성능을 보였으며, Llama-3 70B가 테스트한 모든 OpenAI 모델을 능가하는 성적을 거두었음.
6. 결론
현재 최첨단 시스템의 역할 수행 능력을 기반으로 한 자동화된 언어 모델(LM)을 심판으로 활용하는 접근 방식을 제안함. 우리는 미국 인구 조사 데이터를 기반으로 1,000개의 훈련 데이터와 568개의 테스트 데이터로 구성된 현실적인 페르소나 집단을 생성했음. 각 페르소나는 개인별 프로필과 독특한 성격 유형을 갖추고 있음. 또한 광범위한 실제 사용자 설문조사를 통해 논쟁적인 주제를 활용해 158,600개 이상의 훈련 선호도 쌍과 유사한 수의 평가 데이터 포인트를 포함한 대규모 합성 데이터셋을 생성했음. 제안된 환경은 다양한 그룹 선호도, 개인화 모델, 정보 수집 및 선호도 추출을 포함한 다원적 정렬 접근법을 개발하고 평가하는 데 활용될 수 있음. 실제 사용자 연구를 통해 이러한 페르소나의 정확성을 추가로 검증했음.
7. 한계
인구 통계적 초점: 우리의 페르소나는 미국 인구 통계 데이터에 기반을 두고 있으며, 이는 전 세계 인구의 다양성을 정확히 반영하지 않을 수 있음.
피드백 및 선호도 데이터: 본 연구에서 생성된 선호도 데이터는 역할극 시나리오에서 언어 모델의 응답에 기반함. 우리는 인간 평가자를 통해 이러한 응답을 검증했지만, 피드백이 실제 인간의 선호도를 완벽히 모방하지 않을 수 있는 위험이 남아 있음. 또한, 효과적인 방법인 Direct Principle Feedback (DPF) 접근법은 인간의 의사결정 및 선호도의 모든 미묘한 차이를 포착하지 못할 수 있음.
모델의 한계: 인물을 생성하고 평가하는 데 사용된 언어 모델 자체도 편향과 한계를 가지고 있음.
평가 지표: Cohen의 카파(Cohen’s kappa) 및 기타 주석자 간 일치도 지표는 일관성을 측정하지만, 인간 선호도와 일치하는 질적 측면을 완전히 포착하지 못할 수 있음.
실제 적용 사례: 우리 팀의 합성 접근 방식은 확장 가능한 테스트 및 평가를 가능하게 하지만, 실제 환경에서의 배포에 따른 도전 과제를 완전히 해결하지는 못함.
편향 문제: 합성 페르소나의 생성 및 사용은 고정관념을 강화하거나 새로운 편향을 도입하지 않도록 주의 깊게 접근해야 함.
