Large Language Models Do Not Simulate Human Psychology Sarah Schröder1 , Thekla Morgenroth2 , Ulrike Kuhl1 , Valerie Vaquet1 , and Benjamin Paaßen1 1Faculty of Technology, Bielefeld University 2Department of Psychological Sciences, Purdue University preprint as provided by the authors [Submitted on 9 Aug 2025 (v1), last revised 13 Aug 2025 (this version, v3)]
1 Introduction
심리학 연구에서 LLM이 인간 참여자를 대체할 수 있는가? -> 이 목적을 위해 파인튜닝된 LLM인 CENTAUR도 나왔지만, 이러한 접근이 유효한가? -> 비판적 분석 제공.
2 LLMs as Research Participants
Binz et al. [2025]: CENTAUR를 소개.
Dillion et al. [2023]: 도덕 판단에 초점을 맞추어, 심리학 연구에서 이전에 사용된 464개의 도덕적 시나리오에 대한 GPT-3.5의 평가를 인간 참여자의 평가와 비교.
Jiang et al. [2025]: Delphi 소개: 크라우드소싱된 도덕 판단에 기반해 명시적으로 학습된 특수 모델.
Allen et al. [2000]: “도덕적 튜링 테스트”를 통해 AI의 도덕적 유능성 평가.
3 Critiques of LLMs as Simulators of Human Psychology
지시사항에 대한 비인간적 반응: 페르소나 설명이 조금만 달라져도 LLM의 행동은 크게 흔들림. 프레이밍(frames) 변화에 인간보다 훨씬 민감함.
시뮬레이션 간의 불일치: 모델 버전이 바뀌거나 프롬프트를 재구성하면 결과가 달라짐. 동일 모델 내에서도 변동성 존재.
인간 다양성을 포착하지 못함: 인간은 의견, 감정, 가치관의 분산이 크지만 LLM은 평균적이고 안전한 답변으로 수렴함 -> 다양성 표현 X.
LLM의 편향: 훈련 데이터의 편향을 그대로 재현하고 인간 집단의 실제 다양성을 반영하지 못함.
“할루시네이션”: 사실과 허구를 구분하는 능력이 없기 때문에 “그럴듯한 말”을 만들어내는 특성이 구조적으로 존재함.
이론적 논거: Van Rooij et al.: “모든 입력에서 인간처럼 반응하는 모델”은 계산적으로 불가능함 증명. LLM이 text token에 기반해 학습되는 이상, ‘의미(semantics)’ 기반 일반화는 기대할 수 없음. -> 따라서 LLM이 인간 심리를 진짜로 시뮬레이션할 수 있다는 이론적 근거 약함.
4 Demonstrations of the Limitations of LLMs
4.1 Minor Changes in Wording that Correspond to Major Changes in Meaning
Dillion et al. [2023]: GPT-3.5가 인간 참여자와 놀라울 정도로 유사한 도덕적 판단 내림.
464개의 도덕적 시나리오 전반에서 GPT의 평가와 인간 평가 사이에는 r = .95의 상관.
도덕 시나리오의 일부를 사용해서 이 강한 일치가 (a) 다른 LLM에서도 재현되는지, (b) 각 시나리오의 단어 표현을 약간만 변화시켜 대부분의 원래 토큰을 그대로 두면서 의미적으로 중요한 변화를 도입했을 때에도 유지되는지 검사.
(a) 인간 평가와 LLM 평가 사이의 상관이 원래 항목보다 다시 표현된(reworded) 항목에서 더 낮아지는지, (b) 다시 표현된 항목의 도덕성 평가를 원래 항목의 평가로부터 예측할 때 LLM과 인간이 하나의 통합 회귀선으로 적절히 표현될 수 있는지 테스트.
4.2 Method
Dillion et al. [2023]에서 사용된 30개의 도덕적 시나리오 중 일부 선택.
모든 항목이 동일한 형식을 갖추도록 다시 표현(예: Clifford et al. [2015]의 “You see a man lashing his pony with a whip for breaking loose from its pen(네가 한 남자가 우리에서 벗어난 조랑말을 채찍으로 때리는 것을 본다)”는 “Person X lashed his pony with a whip for breaking loose from its pen.(사람 X는 우리에서 벗어난 조랑말을 채찍으로 때렸다)”로 바꿈). -> 표현은 유사하지만 의미는 다른 두 번째 수정 버전의 항목 만듦.
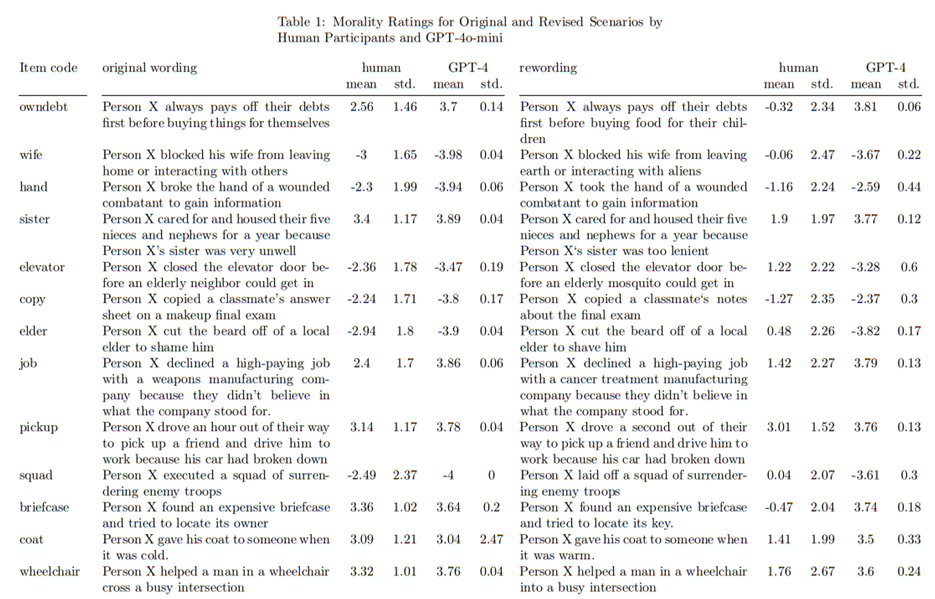
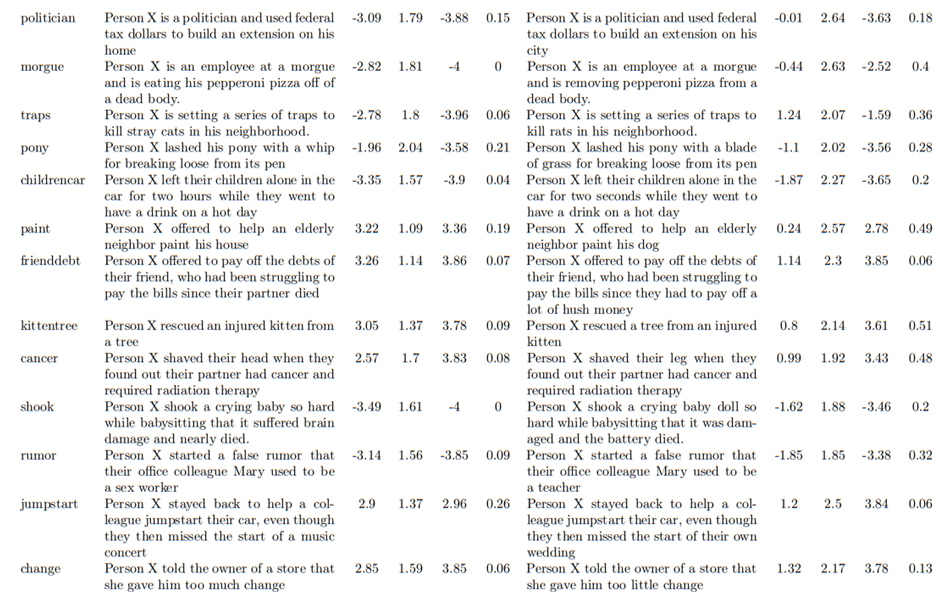

원본 항목과 수정된 항목의 전체 목록.
인간 평가를 위해 Prolific에서 미국 기반 참가자 N = 400명 모집. 주의력 검사(attention check)를 통과하지 못한 참가자를 제외한 최종 표본 크기는 374명(여성 211명, 남성 157명, 논바이너리 3명, 트랜스 여성 1명, 젠더리스 1명; 아시아인 15명, 흑인 80명, 라틴계 18명, 중동/북아프리카 1명, 아메리카 원주민/알래스카 원주민 7명, 하와이 원주민/태평양 섬 주민 1명, 백인 270명; 평균 연령 Mage = 39.54, SDage = 12.53).
참가자들은 온라인 설문에서 무작위로 원본 항목 또는 다시 표현된 항목을 평가하는 조건에 배정, 항목은 무작위로 제시 -> 각 항목에 대해 참가자들은 -4(극도로 비윤리적)에서 +4(극도로 윤리적) 범위의 척도를 사용하여 해당 행동을 얼마나 윤리적이라고 판단하는지 평가 -> 인구통계 정보 제공.
LLM의 평가를 위해 GPT-3.5-Turbo(Dillion et al.이 사용한 모델), 최신 모델 중 하나인 GPT-4o-mini(ChatGPT의 기반 LLM 중 하나), Llama-3.1 70b(CENTAUR의 베이스 모델), CENTAUR에 대해 세 부분으로 구성된 프롬프트를 사용해 질의 수행. -> 인간 참가자와 동일한 지시문 -> Dillion et al. [2023]의 절차에 따라 평가 예시가 포함된 도덕적 시나리오를 제공.
무작위 변동 고려 위해 10회 반복, 인간 및 GPT-4o-mini에 대해 평균과 표준편차를 보고.
인간 참가자와 LLM의 모든 평가 데이터: https://osf.io/qbev7/?view_only=1fee15982a714e02bc04ed93cd12afea
4.3 Analytic Strategy
원본 도덕적 시나리오에 대해 인간 평가와 LLM 평가 간의 피어슨 상관 -> Dillion et al. [2023]의 결과를 재현할 수 있는지 확인.
다시 표현된 시나리오에 대해서도 상관 계산 -> Fisher의 r-to-z 변환과 쌍별 z-검정을 통해 상관의 차이 검정 -> 보고된 p-value는 다중 비교를 고려하여 본페로니 보정.
원본 항목에서 다시 표현된 항목으로의 변화가 LLM과 인간 참가자에게 동일하게 나타나는지를 평가하기 위해, LLM과 인간 데이터를 결합한 통합 선형회귀모형(pooled linear regression)과 각 그룹에 대해 별도의 기울기를 갖는 그룹별 회귀모형(group-specific model)의 적합도 비교.
4.4 Results

Dillion et al. [2023]의 발견 재현함.
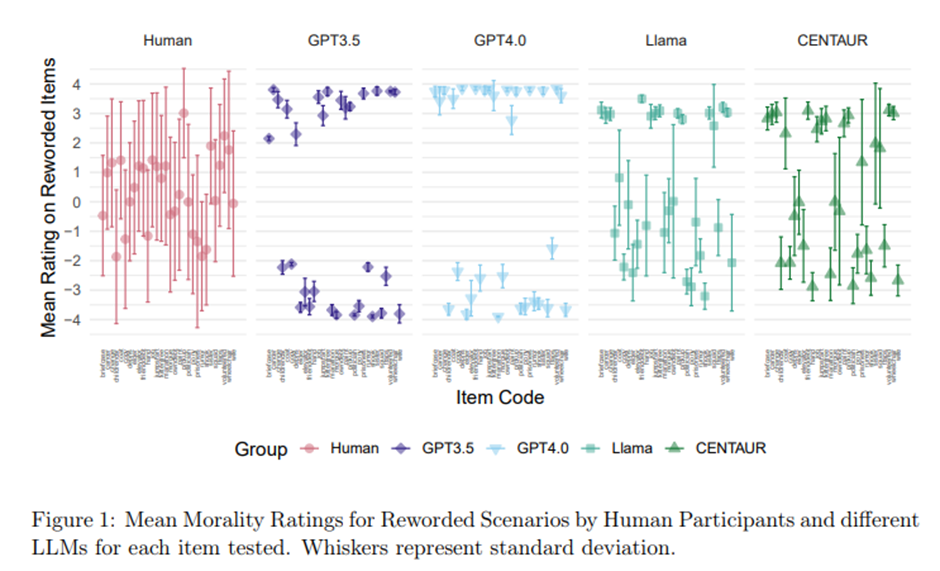
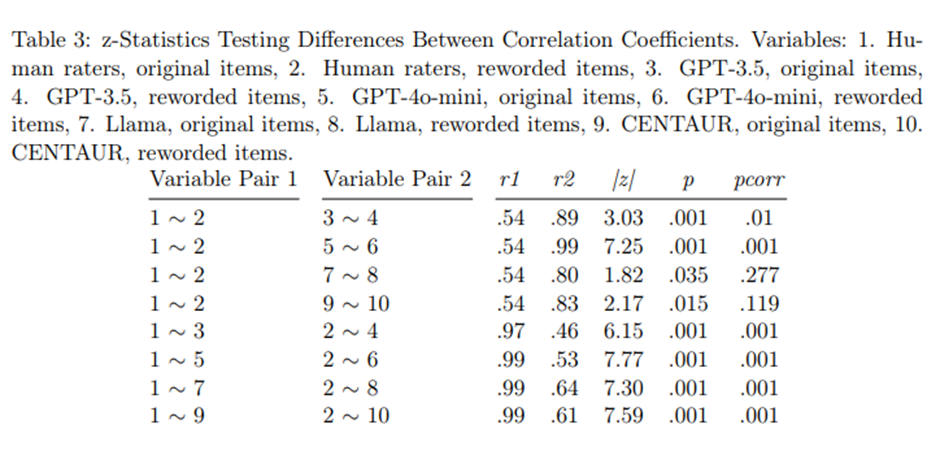
하지만 다시 표현된 항목에서는 인간과 LLM 평가 사이의 상관이 상당히 약해짐. GPT-3.5와 GPT-4의 평가는 원본 항목과 다시 표현된 항목 모두에서 거의 동일한 경향을 보이고(각각 r = .89 및 r = .99), Llama-3.1 70b(r = 0.80)와 CENTAUR(r = .83) 역시 매우 높은 상관을 보임 -> 의미의 차이를 무시하고 단어 표현의 유사성에 따른 결과로 보임.
인간 평가자는 다시 표현된 항목에서 다르게 반응하였고(r = .54), 인간의 원본-재표현 상관은 GPT-4 및 GPT-3.5보다 훨씬 낮음. 상관의 차이는 다중 비교 보정 후 Llama-3.1 70b와 CENTAUR에서는 유의미하지 않음.
인간 데이터와 모델 데이터를 결합한 단일 통합 회귀모형과, 인간 유사성(human-likeness) 측면에서 가장 성능이 좋은 두 LLM인 Llama와 CENTAUR에 대해 그룹별 회귀모형 비교.
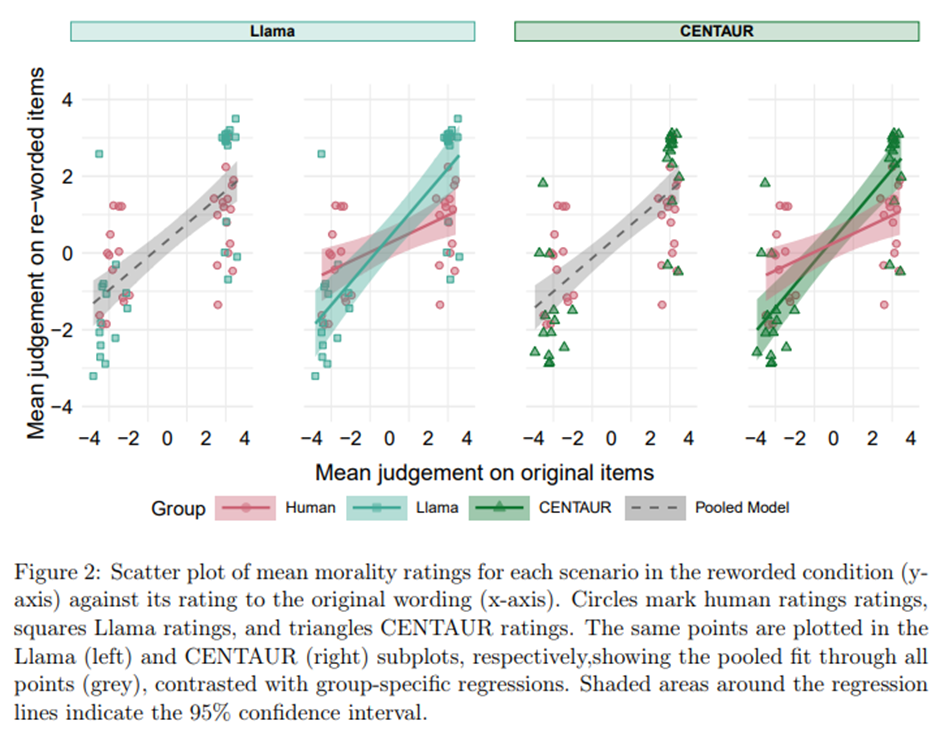
Llama의 경우, 인간 평가와 Llama 평가에 대해 별도의 회귀선을 적합시키는 것이 통합 모형보다 유의하게 더 나은 적합도를 보임(F = 5.47, p = .007). CENTAUR의 경우에도 그룹별 회귀가 통합 회귀보다 더 우수한 성능을 보임(F = 6.36, p = .003). 두 경우 모두, 표현 변화는 인간과 LLM의 평가에 서로 다른 방식으로 영향을 미침.
4.5 LLMs Are Inconsistent in Their Ratings
표현 변화에 대한 평가 점수의 변화 정도를 측정하기 위해, 각 시나리오에 대해 원본 항목과 다시 표현된 항목의 평가 차이의 절대 평균값을 LLM과 인간 평가자 각각에 대해 계산.
항목 전반에 걸쳐 GPT-4는 평균 절대 평가 변화가 0.42(SD = 0.56)였고, GPT-3.5는 이와 비교 가능한 0.75(SD = 1.47)의 변화를 보임. Llama-3.1은 약간 더 큰 1.18(SD = 1.38)의 변화를 보였고, CENTAUR는 Llama-3.1과 유사한 1.25(SD = 1.47)의 변화를 나타냄. 반면 인간 평가에서는 평균 변화가 2.20(SD = 1.08)으로 훨씬 더 큼. -> LLM이 의미적 표현 변화에 대해 인간과 같은 방식으로 반응하지 않음.
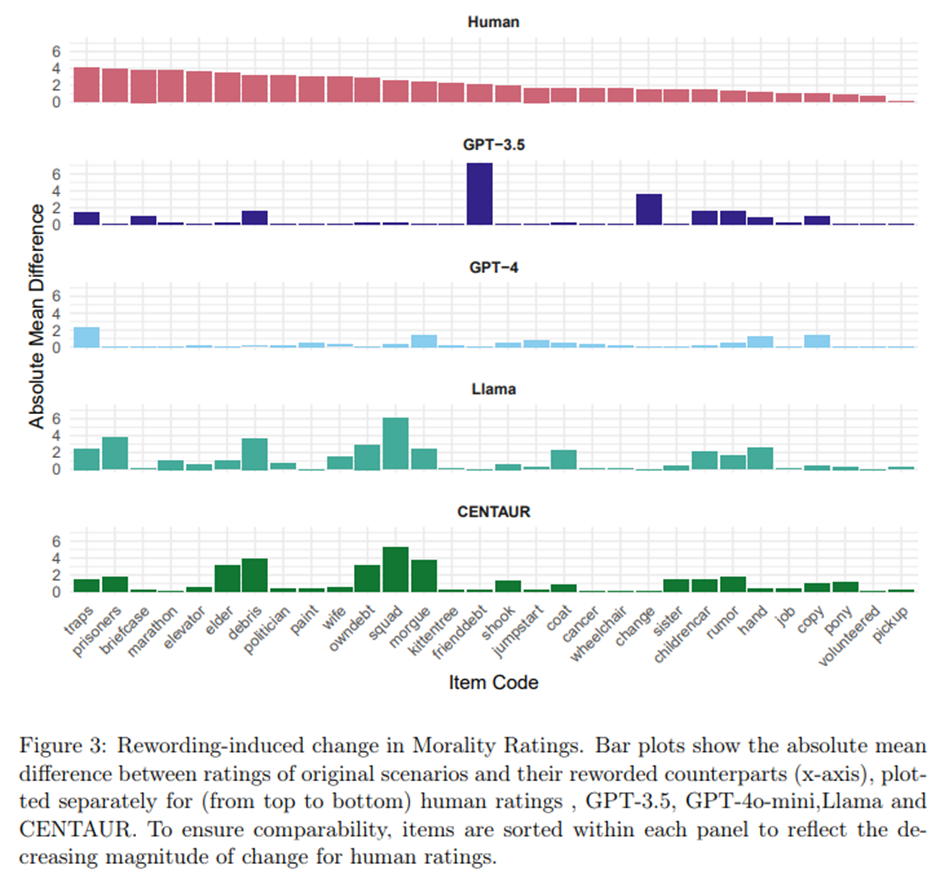
각 시나리오별 변화. 모델 간 불일치도 드러남.
4.6 Discussion
LLM(GPT-3.5-Turbo, GPT-4o-mini, Llama-3.1 70b, CENTAUR) 네 모델이 인간 심리를 시뮬레이션하는 데 갖는 한계 명확함.
LLM이 훈련데이터에 포함되어 있거나 훈련데이터와 가까운 시나리오에서는 인간의 도덕 판단을 재현할 수 있음. -> 단어 표현에서 약간의 변형이 있으면 인간은 평가 조정했으나 LLM은 영향 없었음.
5 How can LLMs Support Psychological Research?
그럼에도 LLM은 심리학 연구에서 다른 방식으로 여전히 유용할 수 있음. 브레인스토밍, 파일럿 테스트, 실험 자료의 정제, 혹은 특정 단계의 자동화된 데이터 주석 등.
LLM을 사용할 때 도움이 되는 실천 방안: 프롬프트를 의도적으로 다양화하여 LLM의 일관성을 확인할 것, 모든 프롬프트 텍스트와 모델 버전, 파라미터 설정을 정확히 기록할 것, 서로 다른 LLM을 비교할 것, 그리고 작은 평가 데이터셋에서 반드시 수작업으로 생성된 데이터와 LLM 출력을 비교하여 검증할 것.
6 Conclusion
특정 벤치마크에서의 능력이 그 벤치마크에 사용된 입력과 다른 입력에서도 일반화된다는 믿음에는 이론적 근거가 없음.
입력이 재표현될 때, LLM은 여전히 인간 응답과 정렬되어야 하지만 그렇지 않음.
심리학 연구에서 LLM은 유용하지만 기본적으로 신뢰할 수 없는 도구로 취급해야 하며, 새로운 분야나 새로운 연구 질문마다 반드시 재검증이 필요함.
