Large Language Models can Accurately Predict Searcher Preferences Paul Thomas Microsoft Adelaide, Australia pathom@microsoft.com Seth Spielman Microsoft Boulder, USA sethspielman@microsoft.com Nick Craswell Microsoft Seattle, USA nickcr@microsoft.com Bhaskar Mitra Microsoft Research Montreal, Canada bhaskar.mitra@microsoft.com SIGIR '24: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval Published: 11 July 2024
1. 관련성 라벨링(Labelling Relevance)
관련성 레이블(결과가 검색자의 필요에 부합하는지를 나타내는 주석)은 정보 검색 시스템을 평가하는 데 필수적.
골드 레이블은 자신의 쿼리 주제를 직접 개발한 relevance assessor로부터 비롯되지만, 제3자 평가자는 골드 레이블과 불일치하는 결과를 냄. 이런 편향은 라벨을 추가로 수집해도 해결되지 않음.
고품질 라벨을 얻기 위한 표준 절차.
Real searchers에 대한 이해를 쌓기 위한 인터뷰, 사용자 연구, 직접적인 선호 피드백, 클릭 같은 암묵적 피드백 수집 -> 관련성 라벨 분석해서 라벨러들이 검색자의 의도를 체계적으로 잘못 이해하는 패턴 찾음 -> 가이드라인이나 예시를 통해 라벨러 교육해서 오류 최소화
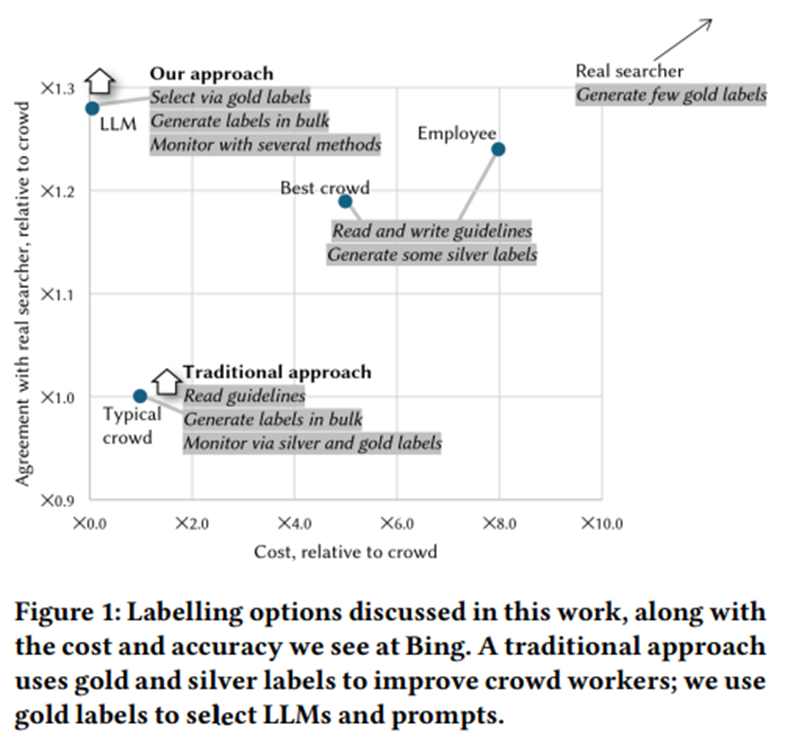
제안: 실제 검색자 선호와 일치하는 매우 고품질의 라벨을 얻기 위한 새로운 방법. 실제 검색자들이 제공한 소수의 고품질 피드백을 이용해 피드백과 가장 잘 일치하는 LLM 프롬프트 선택. -> 이 LLM으로 대규모 레이블 생성.
2. LLM을 활용한 관련성 라벨링(Labelling Relevance with an LLM)
TREC-Robust 2004 [50]의 쿼리, 문서, 레이블을 사용하여 실험 수행.
2.1 Machinery and data
TREC-Robust는 250개의 주제(topic)를 포함하고, 각 주제는 하나의 표준 쿼리(canonical query)를 가짐. 본 논문에서는 쿼리와 주제 동일하게 취급. 쿼리는 TREC의 ‘title’ 필드에서 가져왔고, 일부 프롬프트에서는 ‘description’과 ‘narrative’ 필드도 포함.
공식 라벨은 TREC-Robust의 qrel 파일에서 가져옴. 골드 레이블임.
원본 qrels 파일에는 “매우 관련 있음(highly relevant)” 1031건, “관련 있음(relevant)” 16381건, “관련 없음(not relevant)” 293998건의 라벨 포함됨. 초기 실험에서는 각 클래스에서 1000개의 샘플을 계층적 무작위 표본추출(stratified random sampling) 방식으로 선택하여 총 3000개의 쿼리–문서 쌍 사용. 이후 실험에서는 Robust 2004에서 랭크 1~100 범위에 해당하는 모든 문서 중 실제 평가가 이루어진 문서 사용.
LLM은 내부 버전의 GPT-4, temperature은 0, top p=1, frequency penalty=0.5, presence penalty=0, stopwords 없음. 초반 테스트에서 프롬프트를 사용하지 않은 경우, 모델은 TREC 문서나 qrels를 무작위 수준(chance level) 이상의 정확도로 재현하지 못함.
2.2 Prompting
프롬프트 템플릿 변형 고려함.

프롬프트 전체 구조. 이탤릭체는 주제 및 문서에 따라 달라지는 자리표시자(placeholder), 회색 음영 부분은 일부 변형 프롬프트에서만 포함된 선택적 요소. 프롬프트는 네 부분으로 구성됨.
- 지시문과 역할(Instructions, role)
작업 지시문은 TREC 평가자에게 주어진 지침을 기반으로 함. 지침의 라벨 일관성 내용은 삭제, “you are a search engine quality rater…”라는 구문으로 TREC의 일부 텍스트를 대체하여 사용. ‘search quality rater’ 문구를 포함하여 평가 기준 함축적으로 전달.
- 컨텍스트, 설명, 내러티브(context, description, narrative)
라벨링할 쿼리-문서 쌍 제공. 모든 프롬프트에 쿼리는 포함되며, 일부 변형에서는 TREC의 ‘description’과 ‘narrative’ 필드까지 포함.
쿼리만으로는 정보 요구를 충분히 표현하지 못하지만, TREC 주제에는 ‘description’이 쿼리의 의미를 보충하고, ‘narrative’가 어떤 문서를 관련 문서로 볼지에 대한 기준을 제시함.
- 추가 지시문, 측면, 다중 평가자(Further instructions, aspects, multiple judges)
Cot, step by step에 기반해 “검색자의 의도와 문서를 단계적으로 고려하라(split this problem into steps)”는 식으로 과제를 재진술. 일부 프롬프트 변형에서는 ‘토픽 적합성(topicality)’과 ‘신뢰도(trust)’의 두 측면에 대한 점수도 함께 요청했으며, 일부에서는 여러 명의 인간 평가자를 시뮬레이션하도록 요구.
일부 프롬프트에서는 모델에게 5명의 가상 평가자를 시뮬레이션하게 하여 각각의 점수를 생성하도록 함. -> 이전 연구에서 다중 생성된 라벨을 평균해 사용하는 방식이 유용했기 때문.
- 출력(Output)
JSON 형식의 예시를 포함해 구문 오류 방지하도록.
프롬프트는 제로샷. TREC 문서가 길기 때문에 하나의 완전한 예시를 포함하기 어려움.
3. 라벨 평가(Evaluating the Labels)
라벨 평가는 타당성으로 함. 새로 생성된 라벨이 골드 라벨과 얼마나 일치하는가. 개별 라벨 자체를 비교하거나 문서 간 선호를 비교. 라벨은 일반적으로 쿼리 수준이나 시스템 수준으로 집계되어(query-level, system-level) 사용되므로, LLM이 생성한 라벨을 이용해 이러한 집계 수준에서도 기존과 유사한 결론에 도달할 수 있는지도 중요.
3.1 Document labels
문서 레벨의 기계 라벨링 과정을 평가하는 가장 단순한 방법: 그것이 인간 라벨러가 부여했을 레이블과 같은 레이블을 만들어내는가?
기계와 인간 레이블 간의 차이는 혼동행렬(confusion matrix)로 요약. 레이블은 서열척도(ordinal scale)이지만 두 수준에 점수 0과 1을 할당하면 인간과 기계 레이블 간의 평균 차이도 추가로 계산 가능.
평균절대오차(MAE)를 사용하여 정확도 보고, 0은 두 출처가 항상 레이블에 동의함을, 1은 최대한으로 다름을 의미. 이전 연구와 비교하기 위해 이전 연구와 같이 부분적으로 관련 있음과 매우 관련 있음을 합치는 이진화된 레이블에 대해 𝜅를 보고.
3.2 Document preference
문서 레벨 MAE를 최소화하면 쿼리 전반에 걸쳐 보정(calibrated)된 점수를 얻을 수 있고, 디버깅과 개발을 위해 해석 가능해짐. 랭킹은 보정된 점수 대신 문서 간의 선호(preferences)를 사용할 수 있으며, 이는 많은 learning-to-rank 알고리즘에서도 충분. 중요한 것은 임의의 두 문서 사이의 상대적 순서이고, pairwise accuracy 또는 AUC(인간의 선호가 주어진 임의의 두 문서에 대해 모델의 선호가 동일할 확률)로 측정(0-1).
두 점수 체계가 스케일과 위치에서 다를 수 있음. -> pairwise accuracy는 이것에 강건함.
3.3 Query ordering
특정 고정된 검색 엔진을 기준으로 사람에 의해 생성된 레이블에 따라 어떤 지표(예: RBP 또는 MAP)로 결과 리스트(SERP)를 순서화하고; 동일한 결과 리스트를 동일한 지표로 모델이 생성한 레이블에 따라 순서화한 뒤; 두 순서가 얼마나 유사한지 물음.
쿼리를 최저 점수에서 최고 점수 순으로 정렬한 뒤 순위 편향 중복도(rank-biased overlap, RBO)[52]로 상관 측정.
해석 용이성을 위해 이 최소값을 사용하여 RBO 점수를 0에서 1 범위로 정규화.
𝜙 = 0.9 -> 이는 실험자가 평균적으로 처음 10개의 쿼리를 본다는 가정에 대응.
3.4 System ordering
쿼리:문서 점수의 주된 용도는 물론 전체 시스템의 점수를 계산하는 것.
문서 점수를 쿼리 점수로 누적하고, 다음에 쿼리 점수를 시스템 점수로 누적 -> 동일한 쿼리를 실행한 시스템들에 대해 RBO 보고 -> 최소 RBO 점수를 계산하여 정규화
실험자는 상위 세 개 또는 네 개 시스템을 심각하게 검토할 수 있으므로, 𝜙 = 0.7로 설정.
3.5 Ground-truth preferences between results
기계 레이블을 인간 레이블과의 일치로 평가하는 것은 유용하지만 레이블의 타당성(validity), 즉 레이블(또는 레이블에서 파생된 지표)이 어떤 진정한 검색자 경험을 반영하는지 여부에 대해서는 말해주지 않음.
3.6 Other criteria
비용, 시간, 신뢰성, 확장성, 유연성, 디버깅의 용이성 등.
4 결과 (RESULTS)
프롬프트를 실행한 후, 우리는 레이블을 [0, 2] 범위의 점수로 변환. TREC 가이드라인을 따르기 위해, 측면(aspects)을 프롬프트로 요청했더라도 최종 평가는 전체 레이블만 고려. 모델이 파싱 불가능한 출력물을 생성한 경우 해당 결과는 전부 제외.
TREC-Robust 토픽 650까지는 이전 TREC 에디션에서 가져온 것이며 이들은 이진 관련성 판단(“관련 있음” 또는 “관련 없음”; 1 또는 0)만을 가짐. 651–700번 토픽은 해당 트랙을 위해 개발되었고 세 수준 판단(“매우 관련 있음”을 추가하여 2)을 가짐.
레이블 품질 평가: 각 문서에 대해 모델의 레이블을 TREC 평가자의 레이블과 비교, 그 결과로 얻어지는 전체 쿼리 및 시스템 랭킹을 비교.
4.1 점수 비교
모델이 생성한 점수를 TREC 평가자의 점수와 비교.
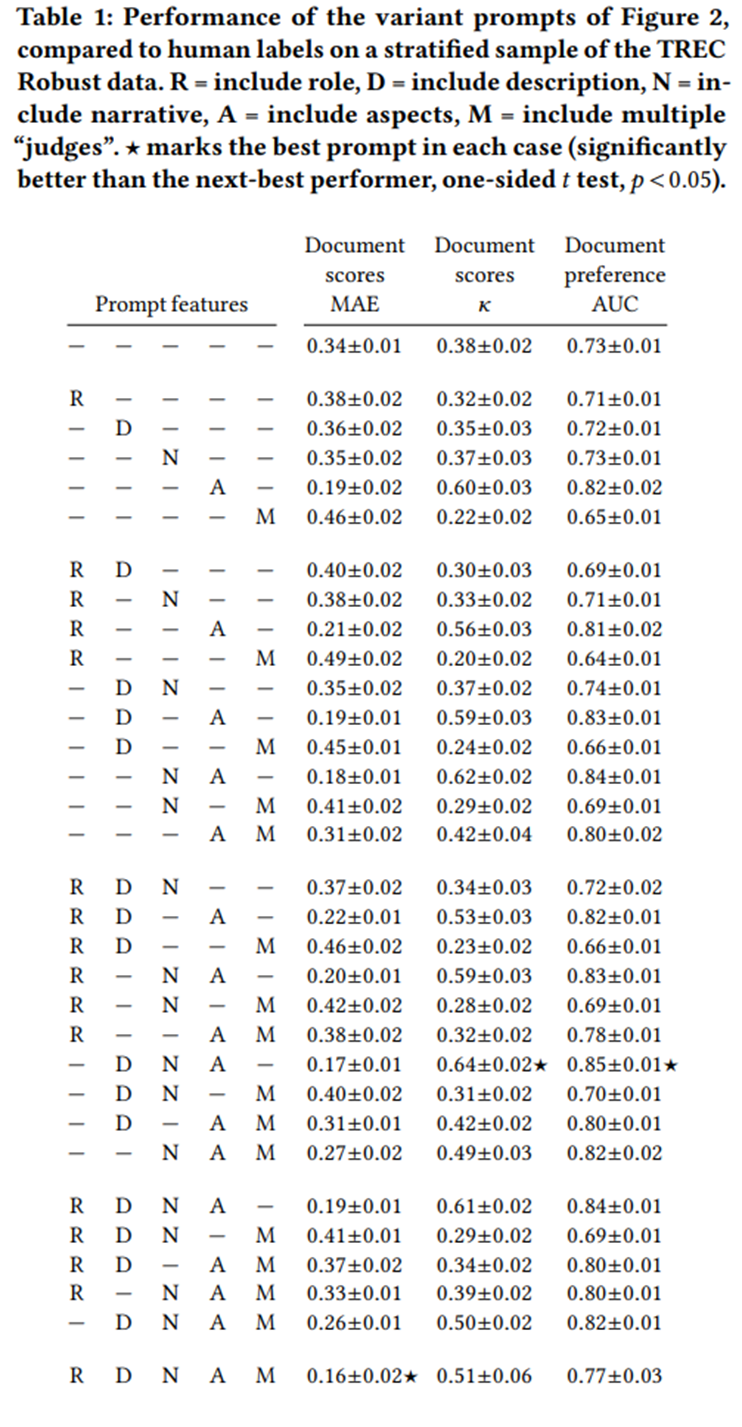
3,000개의 쿼리:문서 쌍에 대해 모델과 인간 평가자 간의 합치도를 요약. 각 프롬프트는 어떤 선택적 기능이 포함되었는지로 식별되며 하나의 행을 가짐. 각 프롬프트에 대해 앞서 설명한 세 가지 문서 레벨 지표와 더불어 문서에 대한 20회 부트스트랩에 기초한 95% 신뢰구간 보고.
프롬프트 구성 요소를 바꿀 때 성능이 매우 가변적임. 즉, 라벨링 품질은 프롬프트의 구조나 템플릿에 크게 의존함. -> 단일 프롬프트 기반의 주장을 해석할 때는 주의가 필요하며, 특히 해당 프롬프트가 기존 라벨에 맞추어 조정(tuning)되지 않은 경우에는 더욱 그러함.
Cohen의 𝜅 값(0.20~0.62)은 Damessie 등[18]의 결과와 비교해도 우수함. Cormack 등[17]이 TREC ad-hoc 문서를 두 번째 평가 그룹이 다시 라벨링했을 때 두 그룹 간 Cohen의 𝜅가 0.52였다는 점을 고려하면, 본 연구의 결과는 숙련된 인간 평가자 간 일치율과 유사하거나 그 이상.
이 지표를 기준으로 할 때, 최소한 이번 TREC 컬렉션과 일부 프롬프트 조합에서는 LLM이 이미 인간 평가자 수준의 품질에 도달했음.
4.2 프롬프트 구성 요소의 효과(Effect of Prompt Features)
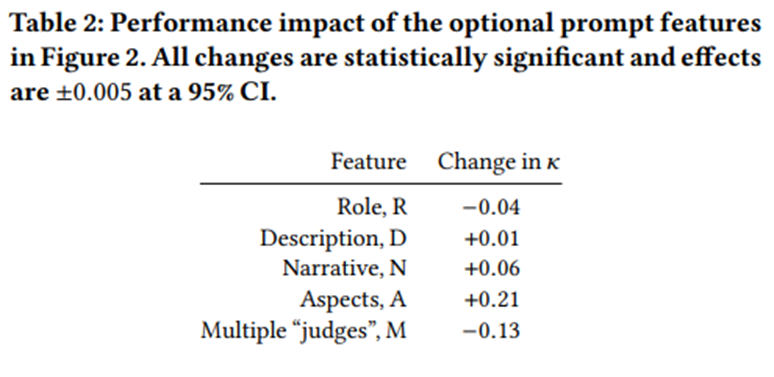
다른 요소들의 유무와 관계없이 각 프롬프트 요소가 Cohen의 𝜅에 미친 평균적 효과.
역할(role, R) 과 다중 평가자(multiple judges, M)는 모두 통계적으로 유의한 부정적 효과.
설명(description, D)을 추가하면 0.01 정도의 미미한 상승 효과.
내러티브(narrative, N)를 추가하면 0.06 정도의 향상 -> LLM이 이미 공공 데이터 기반의 충분한 배경지식을 가지고 있기 때문에, 내러티브가 쿼리 단어 외에 크게 새로운 정보를 제공하지 않았기 때문으로 해석.
측면(aspects, A)은 가장 두드러진 향상. -> 특정 측면의 내용 때문이라기보다, 라벨링을 단계적으로 수행(step-by-step) 하게 만드는 프롬프트 구조 자체가 개선 효과를 낳은 것으로 해석.
4.3 프롬프트 패러프레이징(Paraphrasing)의 효과
LLM은 단순히 프롬프트의 큰 틀(예: “측면(aspects)”을 요구하는가 여부)에만 민감한가, 아니면 문장 표현 방식의 사소한 차이에도 민감한가?
“assume that you are writing a report(보고서를 작성한다고 가정하라)”라는 문장을 “pretend you are collecting information for a report(보고서 작성을 위한 정보를 수집한다고 상상하라)” 혹은 “you are collecting reading material before writing a report(보고서 작성을 준비하기 위해 자료를 모으고 있다)”로 바꾼다면, 생성되는 라벨이 달라질까?
LLM이 겉보기에 사소한 표현상의 변화에도 매우 민감하다는 것은 지금까지의 결과는 가능한 성능 범위 중 하나에 불과하고, LLM을 대규모로 실사용하기 위해서는 훨씬 더 넓고 비구조적인 프롬프트 공간(prompt space)을 탐색해야 함을 의미.
가장 성능이 좋았던 “-DNA-” 프롬프트를 기반으로 두 개의 문구를 재작성하여 42개의 패러프레이즈 버전 생성. “Given a query and a web page ... Otherwise, mark it 0”(쿼리와 웹페이지가 주어졌을 때 … 그렇지 않다면 0으로 표시하라) 부분을 다시 쓴 버전, “Split this problem into steps: … Produce a JSON array of scores without providing any reasoning”(이 문제를 단계적으로 나누어라 … 근거 설명 없이 점수의 JSON 배열을 생성하라) 부분을 다시 쓴 버전.

패러프레이즈 일부 예시.
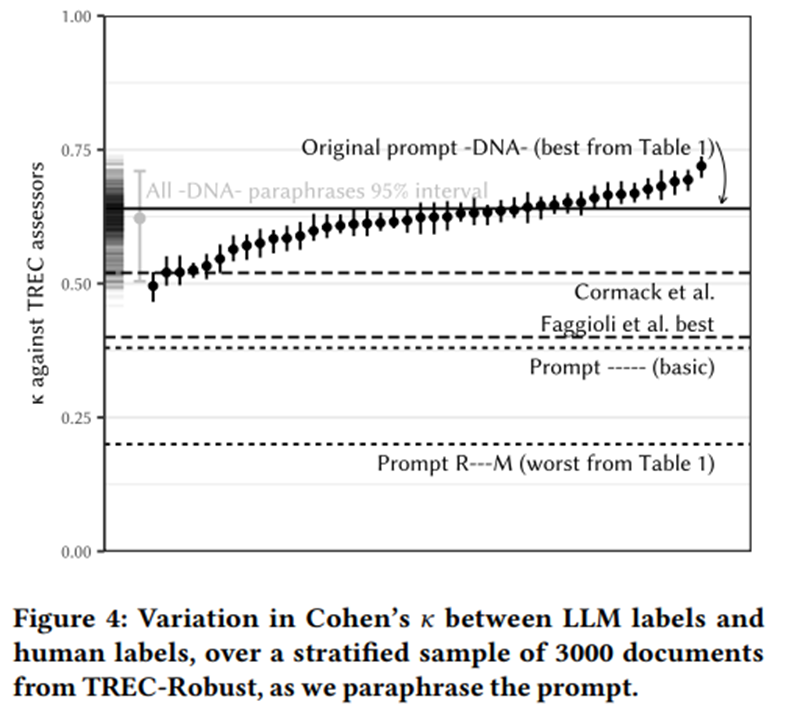
생성된 42개의 프롬프트가 만든 라벨의 품질 분포. Cohen의 𝜅로 측정, TREC 평가자의 라벨을 기준으로 3,000개의 문서 층화 표본을 대상으로 함. 각 프롬프트 패러프레이즈는 하나의 검은 선으로 표현되며, 이는 20회 부트스트랩(bootstrap)을 통한 평균 𝜅와 95% 신뢰구간 보여줌.
𝜅 값은 0.50(보통 수준의 일치, moderate agreement) 에서 0.72(상당한 수준의 일치, substantial agreement) 사이로 넓게 분포. 이 중 상한선은 앞서 인용된 인간 평가자 간 일치율(예: [1, 12, 17, 21, 26])보다 높은 수준. 모든 부트스트랩과 모든 패러프레이즈를 통합했을 때의 경험적 95% 신뢰구간(empirical 95% CI) 은 0.50–0.71(그림 왼쪽 가장자리).
프롬프트 길이(prompt length)나 문서 길이(document length)가 성능에 일관되거나 실질적인 영향을 미치는 패턴은 발견되지 않음.
시사점: 어떤 프롬프트의 성능도 가능한 성능 분포 중 단 하나의 표본(sample)에 불과함(문장의 일부 단어를 조금만 바꿔도 전반적인 설계를 바꾸지 않고도 성능이 뚜렷하게 달라질 수 있음). 전체적인 프롬프트 설계 구조를 고정한 뒤, 그 안에서 다양한 문장 재구성(rephrasing)과 대안적 표현을 탐색하는 것이 바람직함.
4.4 문서 선택의 영향 (Effect of Document Selection)
총 1,000회 반복(iterations) 동안, 3,000개의 TREC 및 LLM 레이블을 무작위로 나누어 두 세트(각 1,500개 문서, train/test)로 분리. -> 프롬프트(표 1 기준)를 평가한 경우, 1,000회 중 모든 경우에서 첫 번째 데이터셋에서 최고 성능을 보인 프롬프트는 두 번째 데이터셋에서도 기본 프롬프트(“-----”)보다 항상 우수.
기본 프롬프트에서 출발해 기능(feature)을 추가하거나 문장을 패러프레이즈한 여러 변형을 생성한 뒤, 가장 좋은 변형으로 전환하는 것은 안전한 선택임. 특정 문서 집합에서 최고 성능을 보인 변형을 선택하더라도, 보지 못한(new) 문서들에서 그 성능이 기본 프롬프트보다 나빠질 가능성은 거의 없음.
4.5 쿼리 난이도와 실행(run) 효율성 (Query Difficulty and Run Effectiveness)
어떤 지표 하에서 쿼리나 실행의 순위(ordering) 가 얼마나 일관되게 유지되는지 평가. 라벨링 체계를 바꿨을 때도 “어떤 쿼리가 어려운가?”, “어떤 실행(run)이 최상인가?”에 대한 판단이 동일하게 유지되는지 확인.
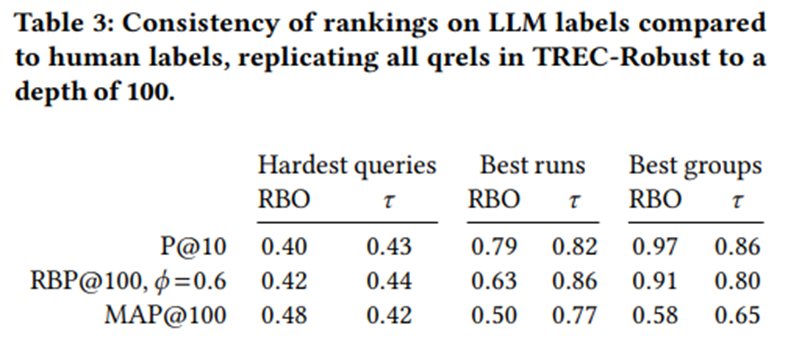
인간 라벨에서 LLM 라벨로 전환했을 때 쿼리와 실행 순위의 일관성.
TREC의 인간 라벨을 기반으로 특정 지표(예: P@10)로 쿼리별 점수를 계산하고, 동일한 지표로 LLM 라벨을 기반으로 다시 점수를 계산. 추가 라벨을 수집하여 모든 실행(run)의 상위 100개 문서까지 라벨링했으며, 단 TREC에서 라벨링되지 않은 문서는 일관성을 위해 “관련 없음(not relevant)”으로 간주. 두 개의 쿼리 순위 목록 일관성은 정규화된 RBO(rank-biased overlap)로 측정. 실험자는 평균적으로 최악의 10개 쿼리를 본다고 가정해 𝜙 = 0.9로 설정.
110개 실행(run)에 대해 반복했으며, 여기서는 상위 3~4개의 실행을 찾는 것을 목표로 하므로 𝜙 = 0.7로 설정.
각 그룹의 최고 실행(best run) 만을 고려해 비교 반복. -> 단순히 매개변수 최적화가 아닌 “어떤 접근법(또는 벤더)”이 가장 우수한지를 선택하는 시나리오.
세 가지 비교(쿼리, 실행, 그룹) 모두에서 순위 일관성은 사용한 지표(metric)에 따라 다름.
MAP 기준: 쿼리 순위가 가장 일관적, P@10 평균 기준: 실행(run) 및 그룹 순위가 더 일관적. 그룹 수준(group-level) 순위는 쿼리나 개별 실행보다 항상 더 일관적. -> 250개의 쿼리를 정렬하는 것보다 110개의 실행이나 14개의 그룹을 정렬하는 것이 덜 변동적이기 때문.
어떤 평가 지표를 사용하든 LLM 기반 레이블로부터 얻은 순위는 인간 라벨로부터 얻은 순위와 전체적으로 유사. -> 모든 지표에서 상위 3개 실행(run) 동일, 상위 5개 그룹은 P@10 기준에서 동일, 상위 3개 그룹 은 RBP@100 기준에서, 상위 4개 그룹 중 3개는 MAP@100 기준에서 일치. 가장 성능이 낮은 쿼리는 P@10과 RBP@100 기준에서 인간과 LLM 라벨 모두 동일했으며, MAP@100에서도 최하위 3개 중 2개 쿼리가 일치.
전체 문서를 사용한 110개 실행(run)에 대해, MAP@100 기준 𝜏 = 0.77, P@10 기준 𝜏 = 0.86. -> 인간 평가자 간 일치도와 비슷하거나 그에 근접한 수준.
4.6 관찰(Observations)
LLM은 TREC-Robust 환경에서 최소한 인간 수준의 라벨링 역량을 보유하고 있음. GPT-4를 사용한 경우, 생성된 라벨은 인간 라벨러 간에도 존재하는 수준의 불일치 한계 내에서 충분히 근접했으며, 가장 어려운 쿼리, 최상의 실행(run), 최적의 그룹을 안정적으로 식별할 수 있음.
5 WEB SEARCH AT BING
TREC 실험에서 확인된 라벨링을 Bing의 실제 사용에 적용.
5.1 Experience with LLMs

정규직 직원(주로 지표 작업을 맡은 과학자와 엔지니어), 지표 문제를 위해 선발·교육되고 면밀히 감독되는 최고 수준의 크라우드 워커, 품질 관리는 받지만 교육은 최소한인 일반 크라우드 워커 풀, 그리고 LLM 모델을 비교해 경험을 요약.
LLM은 정확도 높음, 속도 빠름, 처리량 많음, 비용 저렴. -> 더 많은 결과 측정 가능, 민감도 향상.
2022년 말부터 오프라인 지표의 대부분에서 전문가 인간 라벨러와 함께 LLM을 사용함.
5.2 라벨러와 프롬프트 평가
골드 라벨은 주로 현장(in situ)에서 수집.
그라운드 말뭉치는 쿼리, 필요의 설명, 위치와 날짜 같은 메타데이터, 그리고 쿼리당 최소 두 개의 예시 결과로 구성. 결과는 실제 검색자에 의해 좋음, 보통, 나쁨 태깅. -> TREC 실험과 유사하게, 여기서 선호되는 결과와 비선호 결과의 쌍을 도출하고, 라벨링과 스코어링을 이진 분류 문제로 취급할 수 있음. 모든 쿼리와 결과 쌍에서 선호 결과의 점수가 비선호 결과보다 높아야 함. pairwise agreement를 사용해 모델과 인간 라벨러 정확도 평가.
약 250만 개의 이런 쌍으로 구성, 약 10개의 언어와 약 50개 국가 포괄.
5.3 LLM 시스템 모니터링
매주 모델이 최근에 생성한 라벨을 층화 표본으로 추출 -> 훈련된 평가자들이 다시 라벨링하고, 불일치율이나 불일치 패턴의 변화가 있는지 모니터링
변화가 감지되면 크라우드와 LLM 프로세스 모두에 전문성을 가진 지표 팀이 조사.
우리의 시스템은 Clarke 등[15]의 “수동 검증”과 “완전 자동화” 사이 어딘가에 위치함. 자동화의 규모를 가지되, 수동 검증을 통한 일부 통제와 품질 보증 유지. 불일치와 그 분석은 향후 지표와 골드 세트, 그리고 LLM 라벨러의 개발에 정보 제공.
LLM 라벨은 우리의 평가에서 중요하지만 웹 규모 검색 시스템의 한 부분일 뿐임.
6 POTENTIAL LIMITATIONS AND PITFALLS
언어 모델은 해로운 고정관념과 편향을 재생산, 증폭하는 것으로 알려져 있고[4, 5, 7, 10, 23], 관련성 라벨링에서 이러한 편향이 어느 정도인지 우리는 알지 못함. -> 검색 시스템의 기존 재현적(representational), 할당적(allocative) 피해를 심화시킬 수 있음.
더 긴 문서의 관련성을 과소평가하는 등 다른 형태의 편향 나타날 수 있음.
LLM 기반 라벨을 향해 최적화하는 것은 관련성 개선이 아니라 LLM의 특이성(idiosyncrasies)에 과적합할 위험이 있음. -> 다만 우리는 제3자 평가자보다 LLM이 그라운드 트루스에 더 가까움.
7 CONCLUDING REMARKS
크라우드 라벨을 개선하기 위해 (i) 실제 검색자로부터 통찰을 수집하고, (ii) 이를 가이드라인으로 전환하며, (iii) 신뢰할 수 있는 워커에게 이 가이드라인을 읽히고 “실버” 라벨을 생성하게 하고, (iv) 동일한 가이드라인을 크라우드 워커에게 제공.
검색자 자신으로부터 고품질의 골드 라벨을 수집하고, 이를 사용해 LLM의 프롬프트를 평가, 선정함. 모델이 생성하는 라벨은 고품질이고, 실제로 훈련된 평가자의 라벨보다도 더 유용함.
TREC과 Bing의 말뭉치처럼 과업 설명이 명확한 테스트 세트로 우리의 라벨을 부분적으로 측정함.
시간이 지남에 따라 더 미세한 구분을 담은 더 어려운 골드 세트를 구축할 필요가 있음. -> 라벨러와 프롬프트를 더 잘 구분하기 위해.
접근법을 Bing에서 생산적으로 사용해 왔으며, 더 높은 속도, 낮은 비용, 그리고 운영 중인 시스템의 실질적인 개선을 위해 활용함.
