개요
그래프란 노드와 노드 사이에 연결된 간선의 정보를 가지고 있는 자료구조를 의미한다. 예를 들어 여러 개의 도시가 연결되어 있다 와 같은 내용은 그래프 알고리즘을 일 수도 있다. 이러한 그래프 알고리즘의 유형으로는 dfs/bfs 최단 경로 크루스칼 알고리즘 위상 정렬 알고리즘 등이 있다.
신장트리
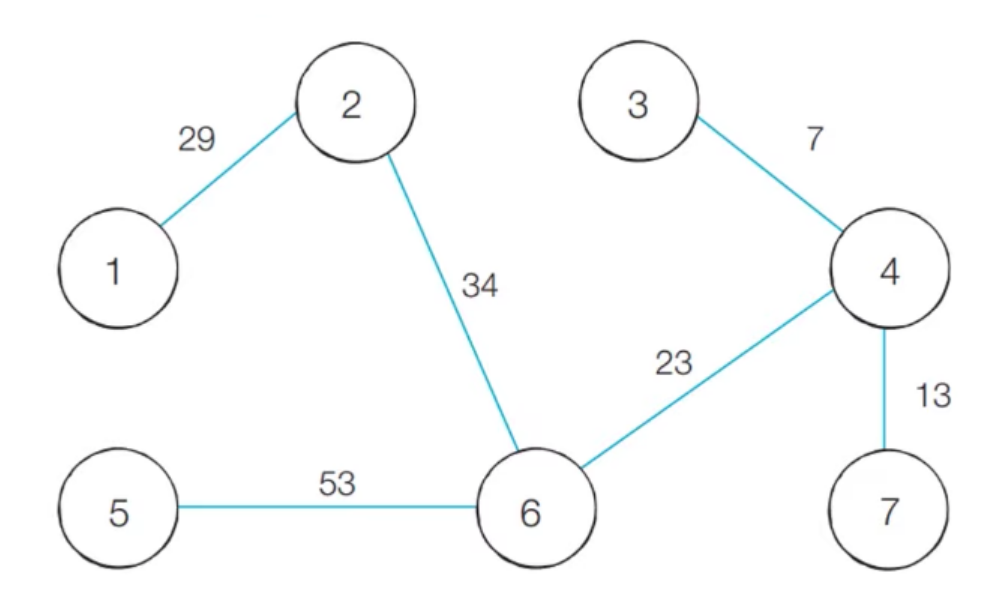
신장트리란 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다. 이때 모든 노드가 포함되어 서로 연결되면서 사이클이 존재하지 않는다는 조건은 트리의 성립 조건이기도 하다.
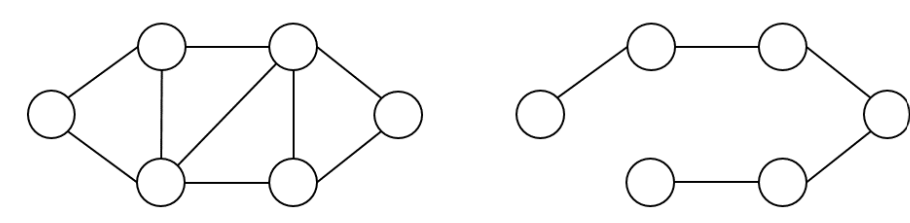
예시로 왼쪽에 있는 그래프는 사이클이 존재하여 신장트리가 아니지만, 오른쪽에 있는 그래프는 신장트리 이다.
크루스칼 알고리즘
크루스칼 알고리즘은 가장 적은 비용으로 모든 노드를 연결할 수 있는데, 이는 그리디 알고리즘으로 분류된다. 먼저 모든 간선에 대하여 정렬을 수행한 뒤에 가장 거리가 짧은 간선부터 집합에 포함시킨다. 이때 사이클을 발생시킬 수 있는 간선의 경우, 집합에 포함시키지 않는다. 구체적인 알고리즘 순서는 아래와 같다.
- 간선 데이터를 비용에 따라 오름차순으로 정렬한다.
- 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인한다.
- 사이클을 발생시키지 않는 경우 최소 신장 트리에 포함시킨다.
- 사이클이 발생하는 경우 최소 신장 트리에 포함시키지 않는다.
- 모든 간선에 대하여
2번 과정을 반복한다.
과정 예시
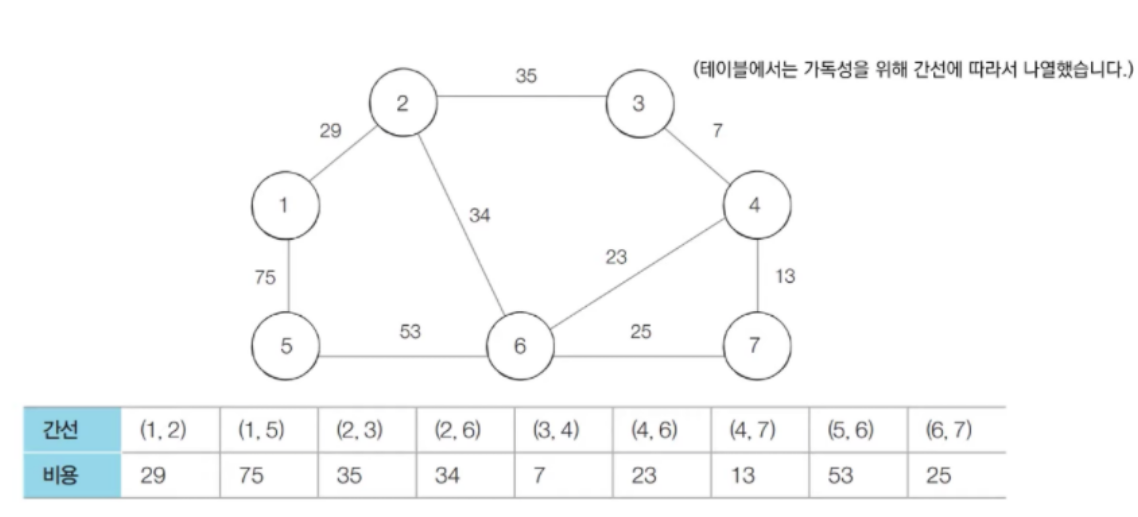
- 간선 정보를 리스트에 담은 후, 간선의 크기를 오름차순으로 정렬한다. (그림에서는 X)
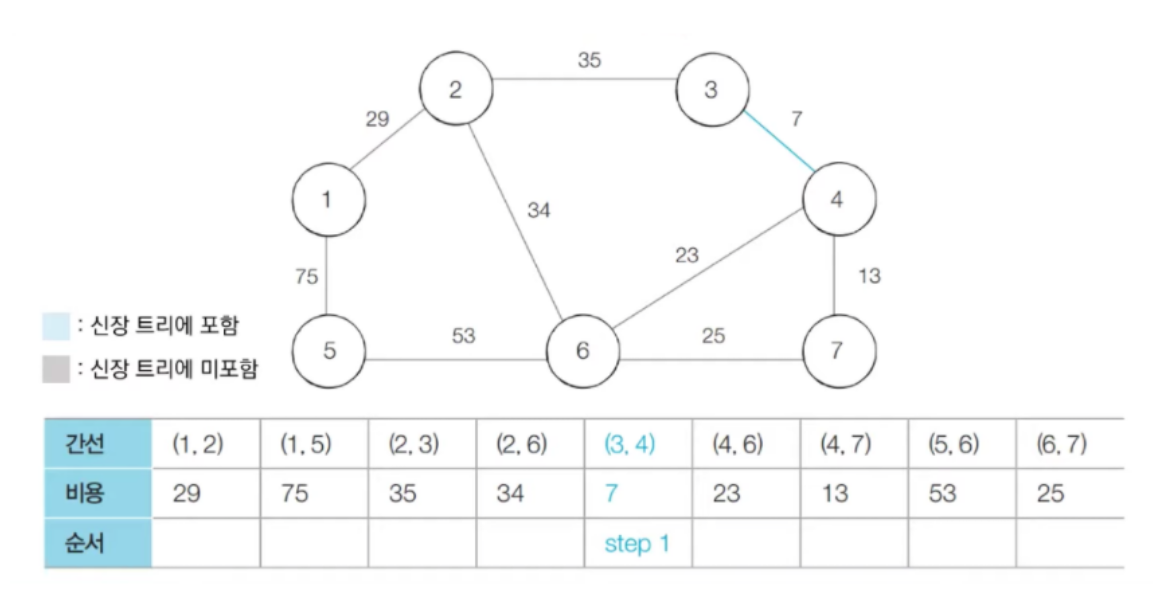
- 가장 짧은 간선을 선택하고 집합에 포함시킨다. 즉, 노드 (3, 4)를 합집합을 통하여 동일한 집합에 속하도록 만든다.
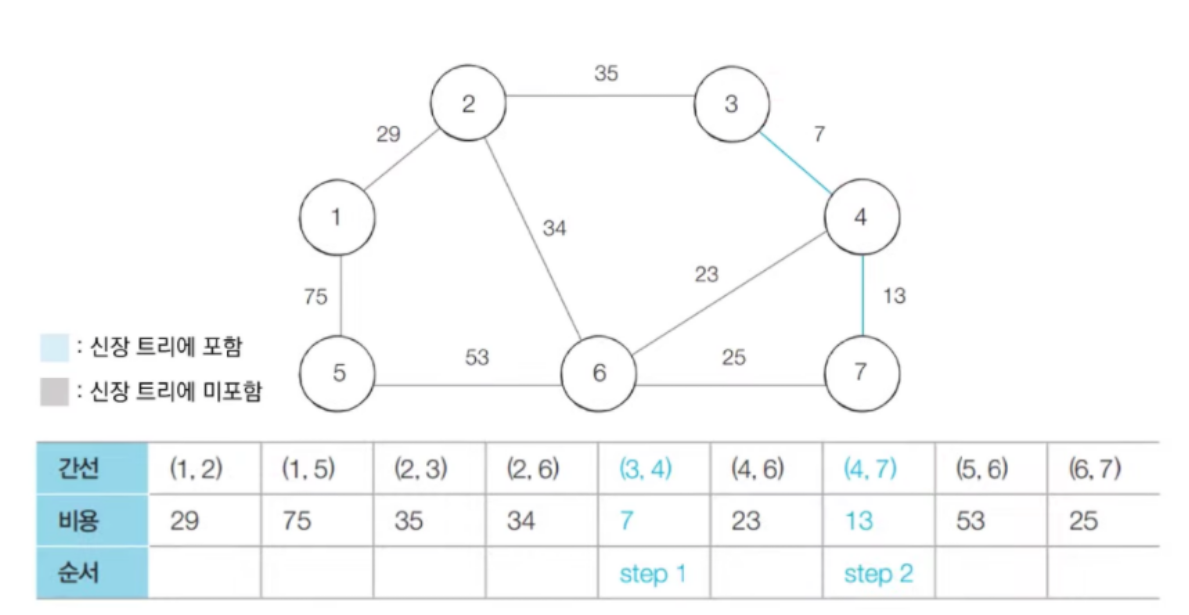
- 다음으로 짧은 간선인 (4, 7) 을 선택한다. 그리고 노드 4, 7에 대하여 union 연산을 수행한다.
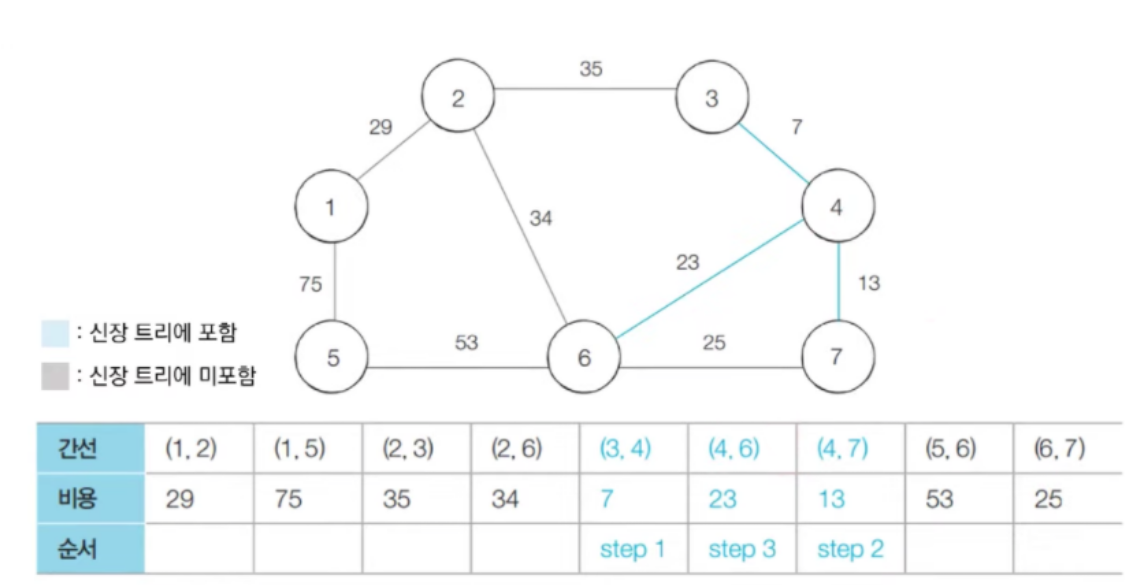
- 다음으로 가장 짧은 간선인 (4, 6) 을 선택한다. 사이클이 발생하지 않으므로 동일하게 합집합 연산을 수행한다.
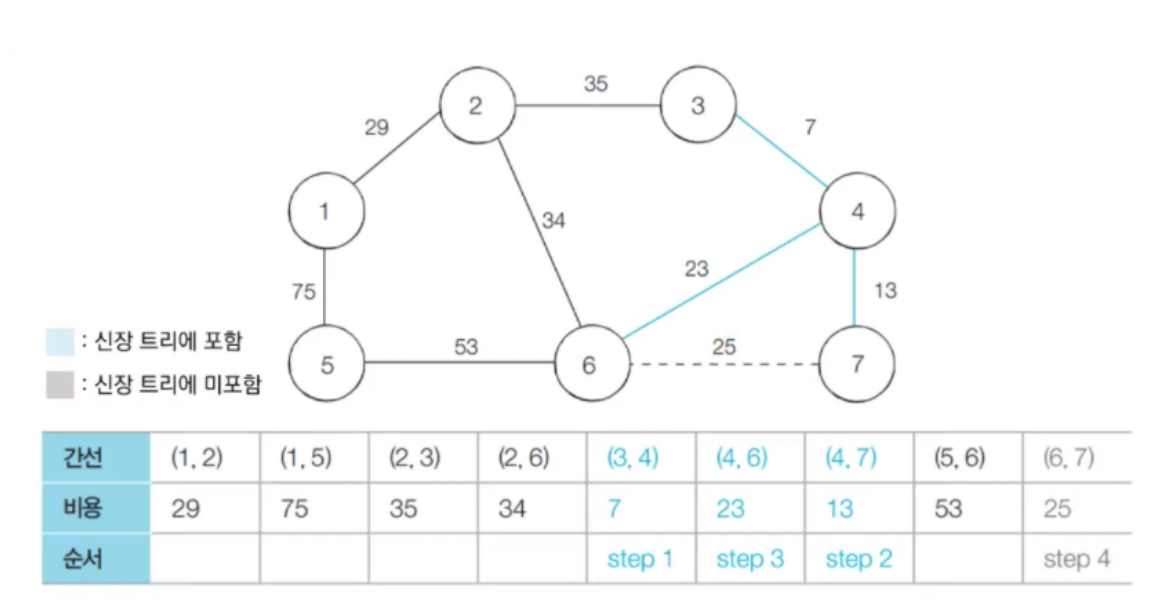
- 다음으로 짧은 간선인 (6, 7) 을 선택한다. 이때 (6, 7)은 사이클을 발생시키기 때문에 집합에 포함시키지 않는다. (6의 부모노드가 6, 7의 부모노드가 6이기 때문에 사이클 발생)
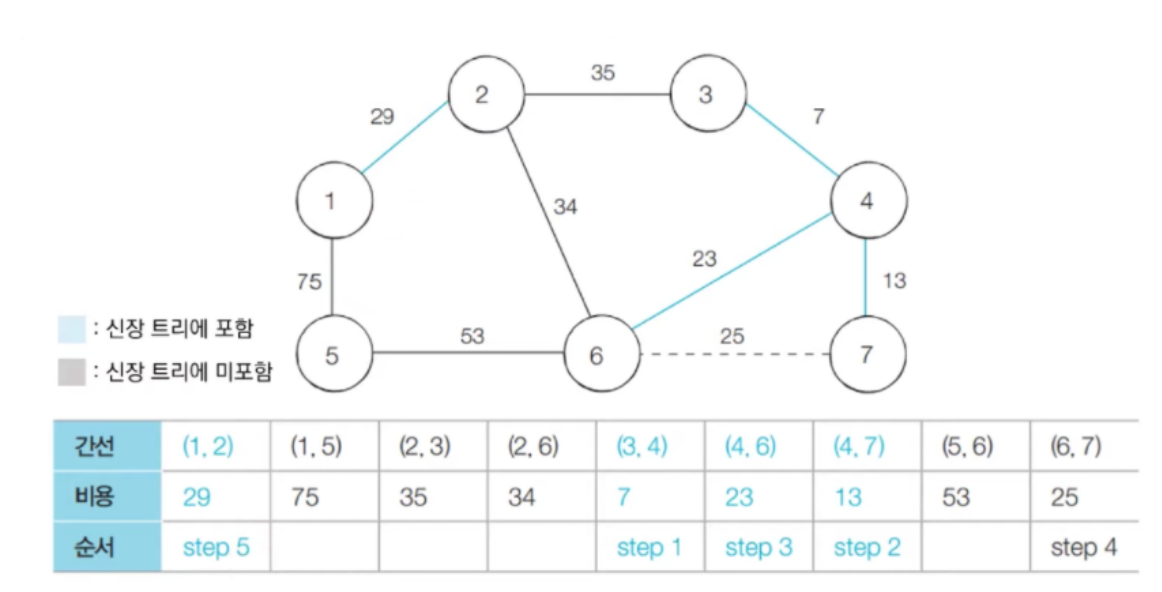
- 다음으로 짧은 간선인 (1, 2)를 선택하고 합집합 연산을 수행한다.
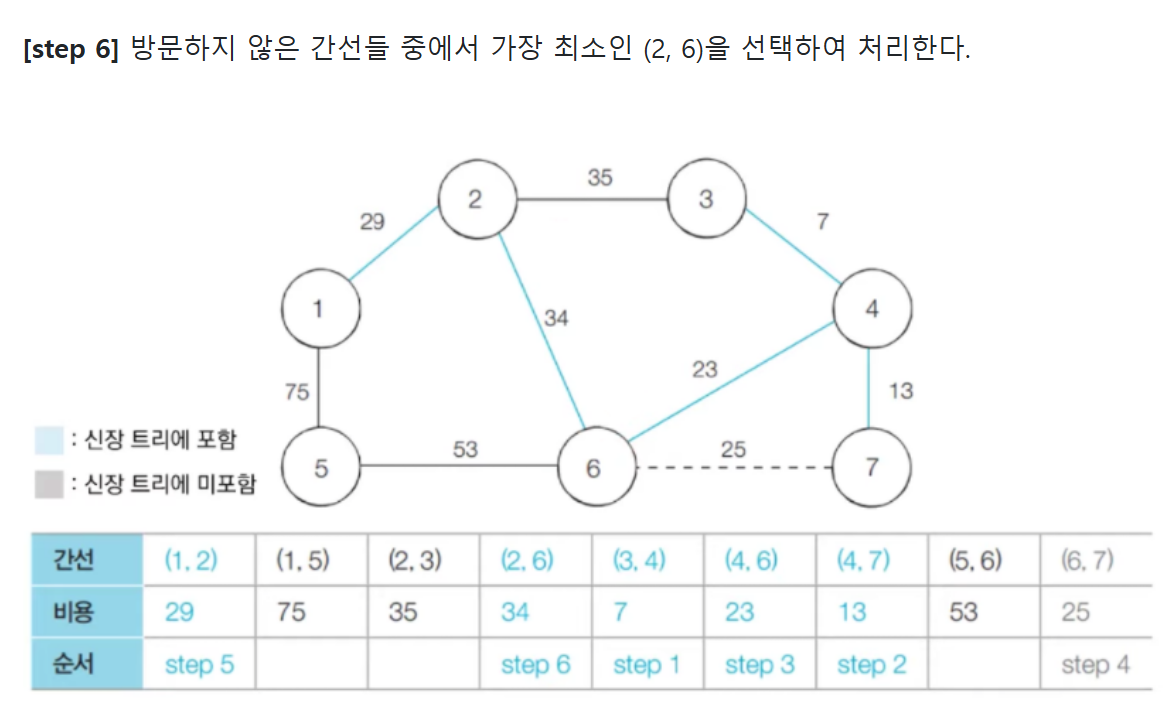
- 다음으로 짧은 간선인 (2, 6)을 선택하고 합집합 연산을 수행한다.
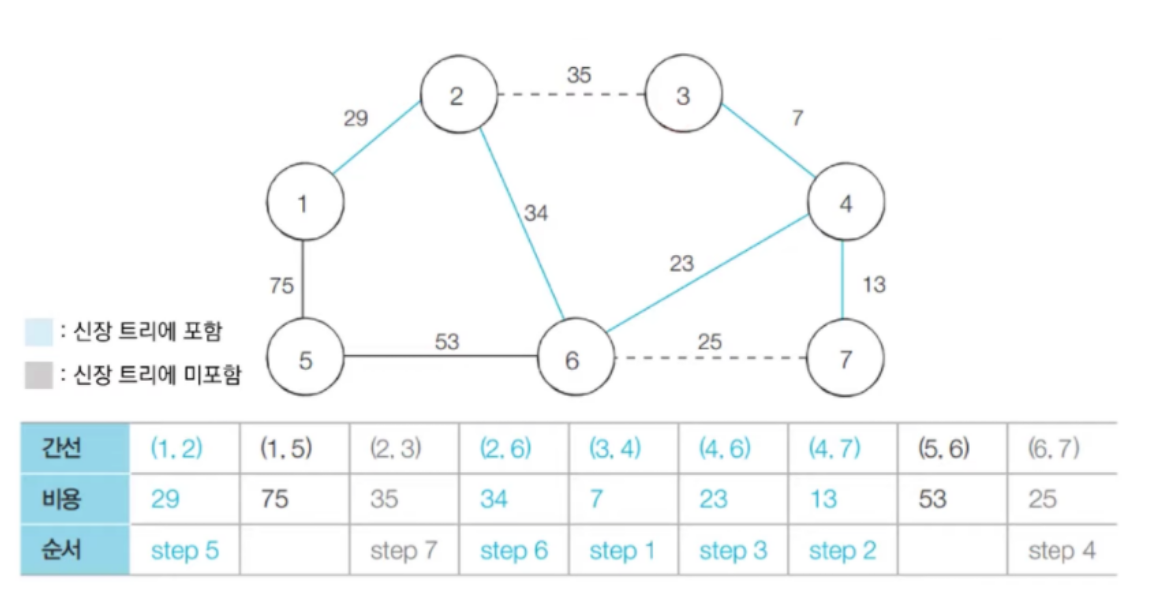
- 다음으로 짧은 간선인 (2, 3) 은 사이클을 발생시키기 때문에 집합에 포함시키지 않는다.
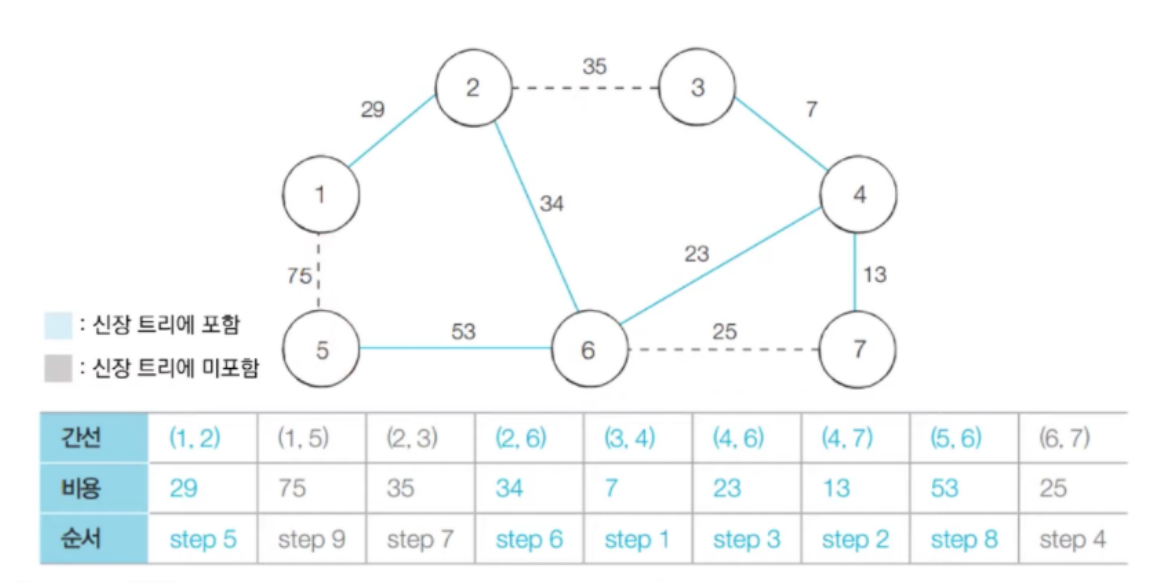
- 다음으로 짧은 간선인 노드 (5, 6) 은 집합에 포함시키고, (1, 5) 는 사이클을 발생하기 때문에 집합에 포함시키지 않는다.
- 따라서 최종결과는 다음과 같다.
크루스칼 알고리즘 소스코드
def find_parent(parent, x):
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
#노드의 개수와 간선(union 연산)의 개수 입력 받기
v, e = map(int, input().split())
parent = [0] * (v + 1) #부모 테이블 초기화
#모든 간선을 다믈 리스트와 최종 비용을 담을 변수
edges = []
result = 0
#부모 테이블 상에서, 부모를 자기 자신으로 초기화
for i in range(1, v + 1):
parent[i] = i
#union 연산을 각각 수행
for i in range(e):
a, b, cost = map(int, input().split())
#비용순으로 정렬하기 위해서 튜플의 첫 번째 원소를 비용으로 지정
edges.append((cost, a, b))
edges.sort()
for edge in edges:
cost, a, b = edge
#사이클을 발생시키지 않으면
if find_parent(parent, a) !=find_parent(parent, b):
union_parent(parent, a ,b)
result += cost
print(result)- 크루스칼 알고리즘의 시간복잡도는 간선의 개수가 E개 일때 O(ElogE) 의 시간복잡도를 가진다. 왜냐하면 이 알고리즘에서 시간이 가장 오래 걸리는 작업이 간선을 정렬하는 작업이기 때문이다.

인사이트를 얻고 정리하는 공간입니다