[논문] AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems [arxiv]
Junjie Zhang ACM WWW 24
📝 Key Point
-
AgentCF 제안 : 사용자와 아이템을 모두 에이전트로 설정하여, LLM 기반 에이전트 간의 상호작용을 통해 사용자-아이템 관계를 모델링하는 새로운 협업 필터링 접근법을 제안하였다.
-
Collaborative 학습 : 사용자 및 아이템 에이전트를 함께 최적화하여 자율적인 상호작용을 수행하고, 이 과정에서 선호 정보를 서로 전파함으로써 협업 필터링의 개념을 암묵적으로 모델링하였다.
-
인간 유사 행동 : 시뮬레이션된 에이전트가 다양한 상호작용(사용자-아이템, 사용자-사용자, 아이템-아이템 등)에서 인간과 유사한 행동을 보이며, 효과성을 입증하였다.
Abstract
-
배경
- LLM 기반 에이전트를 신뢰할 수 있는 인간 대리자로 활용하는 연구가 증가하고 있다.
- 기존 연구는 주로 인간 대화 시뮬레이션에 집중하고 있다.
- 사용자 선호를 암시적으로 나타내는 비언어적 행동(예: 클릭)은 충분히 탐구되지 않았다.
-
문제점
- 언어 모델링과 행동 모델링 간의 간극이 존재한다.
- LLM이 사용자-아이템 관계를 이해하지 못한다.
-
제안
- AgentCF : 추천 시스템에서 사용자-아이템 상호작용을 시뮬레이션하기 위한 방법이다.
- 사용자와 아이템을 모두 에이전트로 간주한다.
- 두 종류의 에이전트를 함께 최적화하는 Collaborative 학습 접근 방식을 개발하였다.
-
방법론
- 각 시간 단계에서 사용자와 아이템 에이전트가 자율적으로 상호작용하도록 유도한다.
- 에이전트의 결정과 실제 상호작용 기록 간의 차이를 바탕으로 Collaborative하게 조정한다.
-
결과
- 최적화된 에이전트는 다음 상호작용에서 다른 에이전트에게 자신의 선호를 전파한다.
- 다양한 상호작용 행동(사용자-아이템, 사용자-사용자, 아이템-아이템, 집단 상호작용)을 나타낸다.
- 이러한 에이전트는 실제 개인과 유사한 개인화된 행동을 보여주며, 차세대 사용자 행동 시뮬레이션 발전에 기여할 수 있다.
Figure
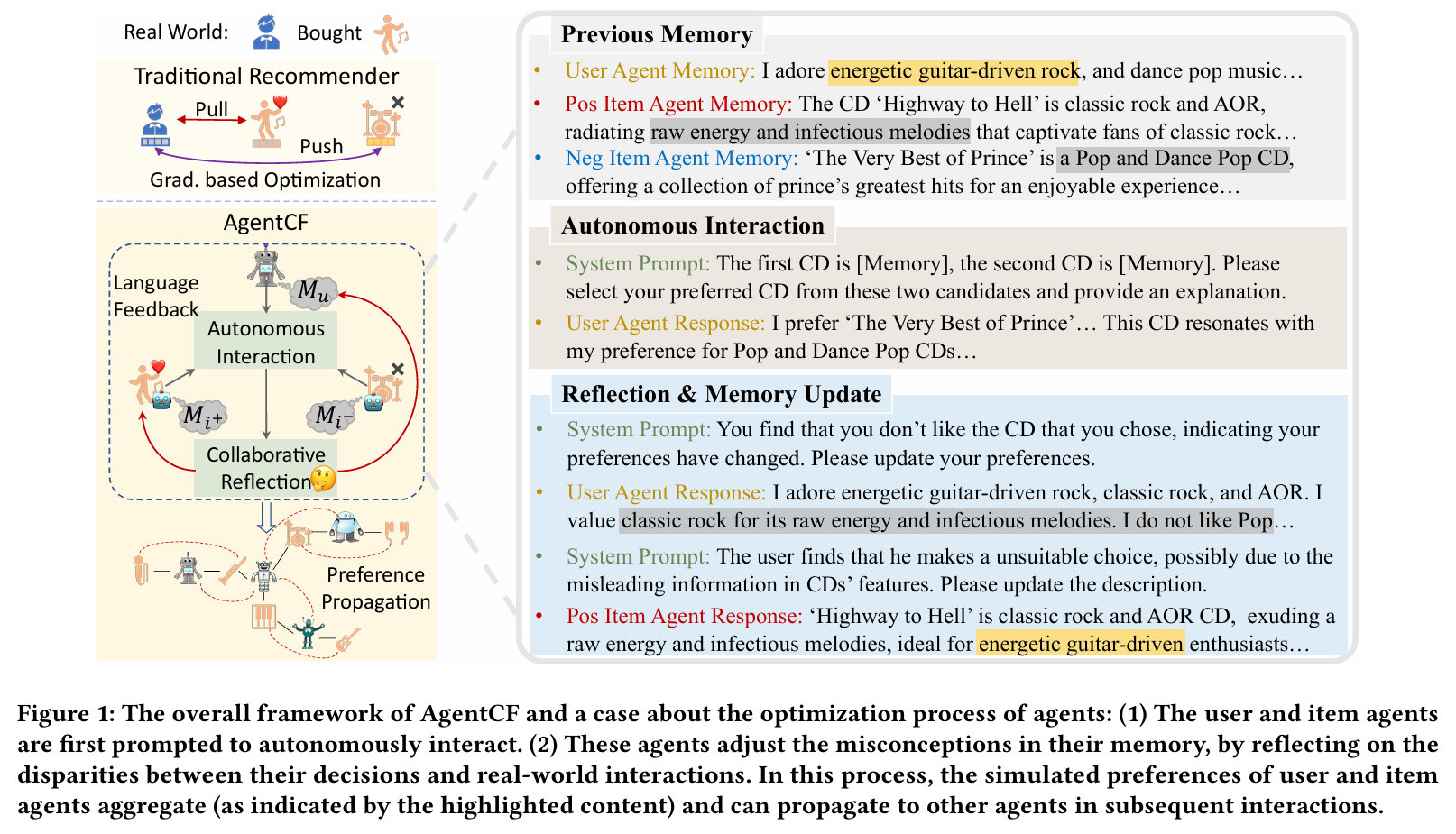
(1) 사용자와 아이템 에이전트가 자율적으로 상호작용하도록 프롬프팅된다.
(2) 에이전트는 자신의 결정과 실제 상호작용 간의 차이를 반영하여 기억 속의 오개념를 조정한다. 이 과정에서 사용자와 아이템 에이전트의 시뮬레이션된 선호가 집계되며, 이후 상호작용에서 다른 에이전트에게 전파될 수 있다.
1. Introduction
-
배경
- LLM의 발전으로 LLM 기반 에이전트가 자율적 상호작용 및 의사결정에서 인상적인 능력을 보여준다.
- 에이전트의 수를 늘리면 개인 및 집단 수준에서 인간과 유사한 행동이 나타날 수 있다.
- 이러한 관찰은 LLM 기반 에이전트를 활용하여 인간의 사회적 행동을 시뮬레이션할 수 있는 가능성을 강조한다.
-
문제 인식
- 기존 연구는 주로 LLM의 의미적 지식을 활용하여 인간 대화 시뮬레이션에 집중하고 있다.
- 그러나 실제 인간 행동은 사용자-아이템 상호작용과 같은 비언어적 측면을 포함하며, 이는 사용자 선호를 반영하고 개인화된 사용자 모델링에 기여할 수 있다.
- 상호작용 기록을 자연어 텍스트로 변환하여 LLM을 유도하는 방법은 이러한 상호작용의 기본 행동 패턴을 포착하는 데 한계가 있다.
-
연구의 초점
- 추천 시스템을 연구 대상으로 삼아 LLM 기반 에이전트로 사용자-아이템 상호작용을 시뮬레이션하는 방법을 고려한다.
- 기존 연구는 사용자 측 행동을 특성화하는 데 중점을 두고, 아이템 측 모델링의 영향을 간과하고 있다.
-
제안된 접근법
- 협업 필터링 아이디어에서 영감을 받아 사용자와 아이템을 모두 에이전트로 간주하고, 두 에이전트를 함께 최적화하는 방법을 개발한다.
- 사용자와 아이템 에이전트를 자율적으로 상호작용하게 유도하고, 상호작용 기록에 기반하여 collaborative한 반영 메커니즘을 설계한다.
-
방법의 장점
- 사용자-아이템 상호작용을 자율적 상호작용으로 모델링하여 단순한 텍스트화 과정을 피한다.
- 사용자와 아이템 에이전트를 상호 최적화하여 two-sided 관계를 포착한다.
-
연구 기여
- 사용자와 아이템을 에이전트로 고려하여 추천 시스템을 위한 사용자-아이템 상호작용 시뮬레이션 접근법을 개발한다.
- 사용자 및 아이템 에이전트를 collaborative하게 최적화하고, 메모리의 상호 업데이트를 달성하는 반영 메커니즘을 설계한다.
- 실제 데이터셋에 대한 광범위한 실험을 통해 개인화된 상호작용 시뮬레이션의 효과성을 입증한다.
2. Methodology
AgentCF는 에이전트 기반 협업 필터링 접근법이다. 이 접근법은 사용자 에이전트와 아이템 에이전트가 추천 시스템에서 사용자-아이템 상호작용으로부터 collaborative하게 학습할 수 있도록 한다.
2.1 Preliminaries
Traditional Recommendation Setting
- 추천 시스템에는 사용자 집합 , 아이템 집합 , 그리고 이들의 상호작용 기록 집합 가 존재한다.
- 추천을 수행하기 위해, 사용자 가 아이템 에 대한 선호 정도를 포착하는 선호 함수 가 구축된다.
- 상호작용한 아이템(positive item, )은 사용자와 상호작용하지 않은 아이템(negative item, )보다 높은 점수를 받는다.
- 예를 들어, BPR은 두 후보 아이템에 대한 선호도를 비교하는 개인화된 pairwise 순위 모델을 구축하고, NCF는 신경망을 사용하여 사용자-아이템 상호작용 관계를 적합시킨다.
- 선호 함수 의 학습은 머신러닝에서 표준적인 gradient 기반 함수 적합 문제로 변환될 수 있다.
Our Task Setting
- 본 연구는 위의 전통적인 추천 설정을 따르며, LLM 기반 에이전트를 추천 시스템에 통합한다.
- 이전 연구와는 달리, 아이템 에이전트도 포함되어 제안한 접근법에서 중요한 역할을 한다.
- 사용자 에이전트 는 해당 실제 사용자의 선호를 포착하고, 아이템 에이전트 는 해당 아이템의 특성과 잠재적 수용자의 선호를 반영한다.
- 사용자-아이템 상호작용은 사용자와 아이템 에이전트 간의 자율적 상호작용을 통해 시뮬레이션된다.
- 본 연구에서는 후보 목록 에 대해 사용자 LLM 에이전트 를 기반으로 하는 순위 작업을 고려한다.
Overview of AgentCF
- 에이전트를 구현하기 위해 메모리 메커니즘(i.e. 과거 상태, 행동 및 맥락 저장)과 반영 메커니즘(i.e. 에이전트의 상태나 인식 수정)을 사용한다.
- 추천 작업은 사용자와 아이템 간의 two-sided 상호작용 관계를 모델링해야 하므로, 아이템 에이전트는 실제 상호작용 시나리오를 시뮬레이션하는 데 중요하다.
- 본 접근법은 LLM을 추천 시스템에 적응시키는 두 가지 기술적 기여를 포함한다.
- Collaborative 메모리 기반 최적화 : LLM에 사용자의 과거 상호작용을 단순히 제공하는 대신, simulated 사용자와 아이템 에이전트를 상호작용을 통해 정제한다. 각 시간 단계에서 이들 에이전트는 자율적으로 상호작용하고, 결정과 실제 상호작용 기록 간의 차이를 collaborative하게 반영한다.
- 암묵적 선호 전파 : 이전 연구와는 달리, 본 접근법은 사용자 및 아이템 에이전트의 메모리에 각 상호작용 기록을 업데이트한다. 이는 아이템 메모리가 이 아이템과 상호작용한 사용자에게 주입될 수 있게 한다. 새로운 상호작용이 발생할 때, 이후 사용자는 이전 수용자의 선호를 알게 된다. 이 과정은 사용자 측에도 적용 가능하다. 본 접근법은 사용자-아이템 상호작용에서 선호를 전파하여 협업 필터링 아이디어를 모델링한다.
2.2 Collaborative Agent Optimization
2.2.1 Memory Design
- LLM 기반 에이전트를 추천 시스템에 맞게 특화하기 위해, 사용자와 아이템 에이전트 모두에 메모리 모듈을 장착한다.
User Memory
- 사용자 에이전트는 사용자 선호를 반영하는 다양한 정보를 저장하는 메모리 모듈을 갖춘다.
- 사용자 선호는 동적으로 변화하므로, 각 사용자 에이전트 는 단기 메모리 와 장기 메모리 를 갖는다.
- 단기 메모리는 최근 업데이트된 선호를 설명하는 자연어 텍스트이다.
- 장기 메모리는 사용자의 선호 변화를 기록하는 역사적 선호 텍스트의 집합이다.
Item Memory
- 아이템 에이전트는 자신의 특성과 수용자의 선호를 기록하는 조정 가능한 메모리 모듈을 갖춘다.
- 각 아이템 에이전트 는 통합 메모리 모듈 만을 갖는다. 아이템 정보는 시간에 따라 비교적 안정적이기 때문이다.
- 아이템 메모리는 아이템의 정체성 정보(e.g. 제목, 카테고리)로 초기화되며, 사용자 선호에 따라 지속적으로 업데이트된다.
2.2.2 Autonomous Interactions for Contrastive Item Selection
- 목적 : 초기화된 에이전트를 최적화하고 실제 사용자-아이템 상호작용을 시뮬레이션하기 위해, 시뮬레이션된 에이전트와 실제 개인 간의 행동 일치를 탐색한다.
- 행동 일치 탐색 : 에이전트가 실제 상호작용 기록과 일치하는 결정을 내릴 수 있는지를 시험한다.
- 아이템 선택 : 사용자 에이전트는 긍정적 아이템 와 부정적 아이템 의 대조 쌍에서 선택을 수행한다.
- 편향 도입 : 선택 난이도를 높이기 위해 인기 편향과 위치 편향을 도입하며, 인기 있는 부정적 아이템을 샘플링하고 이를 선택 목록에서 긍정적 아이템 앞에 배치한다.
- 선택 및 설명 : 사용자 에이전트 는 후보 목록에서 아이템 를 선택하고, 이 선택에 대한 설명 을 제공한다. 이 과정에서 사용자 메모리에서의 선호와 후보 아이템의 특성을 collaborative하게 고려한다.
2.2.3 Collaborative Reflection and Memory Update
- 목적 : 에이전트의 결정과 실제 상호작용 데이터를 비교하여 피드백 신호를 생성하고, 이를 통해 사용자 및 아이템 에이전트를 collaborative하게 최적화한다.
- gradient 기반 학습 없음 : LLM은 고정되어 있으므로 명시적인 gradient 기반 학습 과정이 없다. 대신 사용자 및 아이템 에이전트의 메모리를 업데이트한다.
- Collaborative Reflection : 에이전트의 잘못된 선택에 대해 Collaborative Reflection 메커니즘을 통해 메모리와 행동을 수정한다. 사용자 에이전트는 올바른 선택을 했을 때 그 정확성을 알리고 관련 상호작용 정보를 메모리에 저장한다.
- 메모리 업데이트 : 잘못된 선택의 경우, 사용자 에이전트와 아이템 에이전트가 자신의 선호와 특성을 조정할 수 있도록 반영 과정을 수행한다. 이는 사용자-아이템 관계의 collaborative한 학습을 강조한다.
2.2.4 Connection with Classical Recommendation Models
- 추천 시스템의 모델 : BPR, NCF와 같은 다양한 추천 모델이 존재한다. 이들 모델은 사용자 선호와 아이템 특성을 나타내는 파라미터를 설정하고, 이를 사용자-아이템 상호작용 기록에 맞추어 최적화한다.
- 최적화 과정 모방 : 본 접근법은 전통적인 추천 모델의 최적화 과정을 모방한다. 사용자 및 아이템 메모리는 언어 기반 파라미터(i.e. 임베딩)로 간주되며, Item Selection 과정과 Collaborative Reflection 과정은 추천 모델의 forward preference evaluation(선호 점수 추정)과 backward parameter update(gradient 업데이트) 단계에 해당한다.
- 협업 필터링 아이디어 : Collaborative Reflection은 사용자 및 아이템 에이전트가 상호작용하고 선호 정보를 집계하여 후속 상호작용에 전파하는 역할을 하며, 이를 통해 협업 필터링 아이디어를 포함한다.
2.3 Agent Interaction Inference
- 메모리 기반 최적화 이후, 제안한 접근법은 개인화된 사용자 에이전트와 선호를 인식하는 아이템 에이전트를 시뮬레이션할 수 있다.
- 이러한 시뮬레이션된 에이전트를 활용하여 잠재적인 사용자-아이템 상호작용을 추론하는 방법과 후보 목록 에 대한 순위 작업을 제시한다.
Basic Prompting Strategy
- 사용자와 아이템 에이전트가 서로의 관계를 모델링하기 위해 collaborative하게 최적화되었기 때문에, 에이전트의 시뮬레이션된 사용자 선호와 후보 아이템 특성을 기본적인 프롬프트 형태로 LLM에 직접 프롬프팅한다.
- 이 과정은 LLM이 collaborative recommender로 작동할 수 있게 한다.
- 여기서 는 사용자 에이전트 의 단기 메모리, 는 후보 아이템 에이전트의 메모리, 은 후보의 수, 는 순위 결과를 나타낸다.
Advanced Prompting Strategies
- 단기 메모리는 사용자 에이전트의 현재 선호를 설명하지만, 장기 메모리에서 후보에 대한 전문화된 선호를 검색하면 더 개인화된 추론을 가능하게 한다.
- 상호작용 기록이 희소하고 선호 전파가 제한적일 때, 사용자 역사적 상호작용을 프롬프트에 통합하여 LLM이 순차 추천자로 작동할 수 있도록 한다.
- 이러한 두 가지 개선 전략은 다음과 같이 표현할 수 있다:
- 여기서 는 후보 아이템의 메모리를 쿼리로 사용하여 사용자 에이전트 의 장기 메모리에서 검색된 전문화된 선호를 나타내고, 는 아이템 와의 역사적 상호작용에 대한 메모리이다.
에이전트를 통한 상호작용 향상
- 최적화된 사용자 에이전트와 아이템 에이전트를 기반으로, 논문의 방법은 실제 관찰된 다양한 상호작용 행동을 더 잘 시뮬레이션할 수 있다. 예를 들어, 사용자-아이템 상호작용, 사용자의 사회적 행동, 심지어 추천 시스템 내의 집단 행동을 포함한다.
- 아이템을 에이전트로 활성화함으로써 아이템 간의 더 새롭고 매력적인 상호작용을 창출할 가능성이 있다.
- 예를 들어, 아이템 간 에이전트 상호작용은 수집된 사용자 선호를 새로운 아이템에 자발적으로 전파하여 아이템 콜드 스타트 시나리오에서 유용할 수 있다.
3. Experiments
3.1 Experimental Setup
3.1.1 Datasets
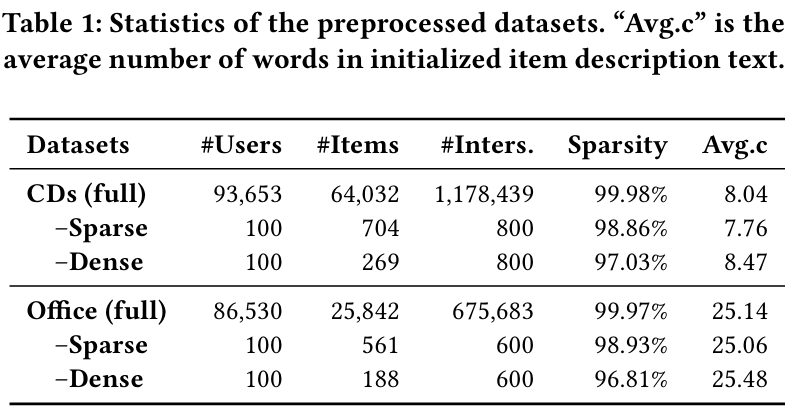
- 실험은 Amazon 리뷰 데이터셋의 텍스트 집합인 "CDs and Vinyl"과 "Office Products"로 진행된다.
- 데이터의 희소성이 협업 필터링 추천자에 미치는 영향을 고려하여, 각 데이터셋에서 두 개의 하위 집합(하나는 밀집, 하나는 희소)을 무작위로 샘플링한다. 각 하위 집합은 100명의 사용자를 포함하며, 다양한 상호작용 시나리오를 탐색한다.
- 추가 분석 실험에는 밀집 데이터셋을 사용하여 에이전트 간의 상호작용을 더 잘 나타낸다.
3.1.2 Evaluation Metrics
- 성능 평가를 위해 NDCG@K를 사용하며, 여기서 K는 1, 5, 10으로 설정된다.
- 기존 연구를 따르며, 평가를 위해 마지막 아이템을 실제 아이템으로 간주하는 leave-one-out 전략을 사용한다.
- 모델을 랭커로 활용하여 9개의 무작위 샘플 아이템과 함께 타겟 아이템을 순위 매긴다.
- 모든 테스트 인스턴스에 대해 3회 반복하여 평균 결과를 보고한다.
3.1.3 Baseline Models
- BPR : 행렬 분해를 활용하여 사용자와 아이템의 표현을 학습하고 BPR 손실을 최적화한다.
- SASRec : 변환기 인코더를 활용하여 사용자 과거 상호작용의 순차적 패턴을 캡처한다.
- Pop : 후보를 인기도에 따라 순위 매기며, 이는 상호작용 수로 측정된다.
- BM25 : 사용자 과거 상호작용과의 텍스트 유사성에 따라 후보를 순위 매긴다.
- LLMRank : ChatGPT를 제로샷 랭커로 사용하여 사용자 순차 상호작용 이력을 조건으로 고려한다.
3.2 Overall Performance
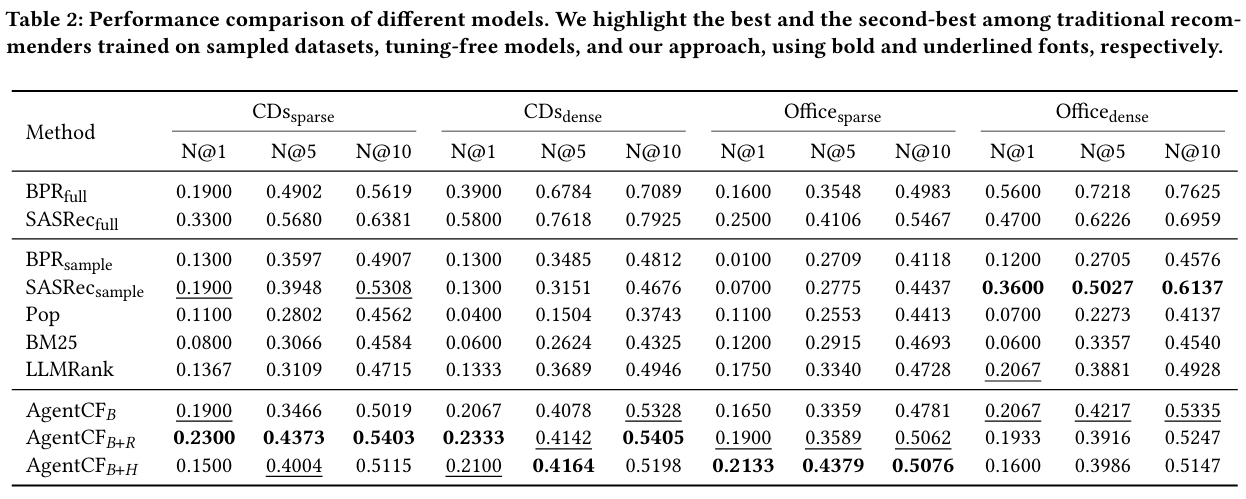
- 제안한 방법은 대부분의 시나리오에서 다른 기준 모델을 능가하여 개인화된 에이전트를 시뮬레이션하는 collaborative 학습의 효과를 강조한다.
- 샘플링된 데이터셋에서 전통적인 추천 모델과 비교하여 우수하거나 유사한 성능을 보이며, 전체 데이터셋에서 훈련된 모델과 비슷한 성능을 기록하였다.
- Pop, BM25, LLMRank와 같은 튜닝 없는 기존 방법들은 만족스럽지 않은 성능을 나타내며, LLM의 일반 지식이 사용자 선호를 포착하는 데 한계를 보인다.
3.3 Further Model Analyses
3.3.1 Ablation Study
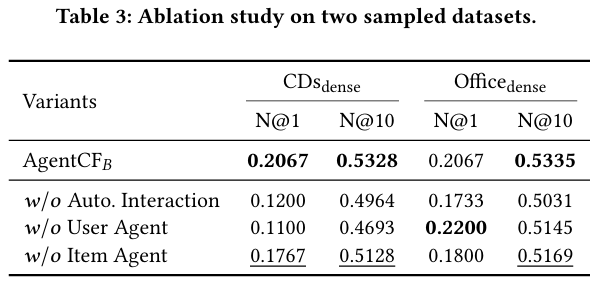
- 제안된 협업 필터링 접근법의 각 구성 요소의 효과를 검증하기 위한 절제 연구를 수행하였다.
- 𝑤/𝑜 Autonomous Interaction : 실제 사용자 상호작용 기록을 제공하여 에이전트의 반응을 관찰함으로써 시뮬레이션된 에이전트와 실제 사용자 간의 불일치를 확인하였다.
- 𝑤/𝑜 User Agent : 사용자 에이전트 최적화를 제거하고 단순히 과거 상호작용으로 사용자 표현을 나타내어 성능 저하를 확인하였다.
- 𝑤/𝑜 Item Agent : 아이템 에이전트 최적화를 제거하여 성능 저하를 확인하고, 사용자와 아이템 간의 상호작용 관계를 캡처하는 데 있어 아이템 에이전트의 중요성을 강조한다.
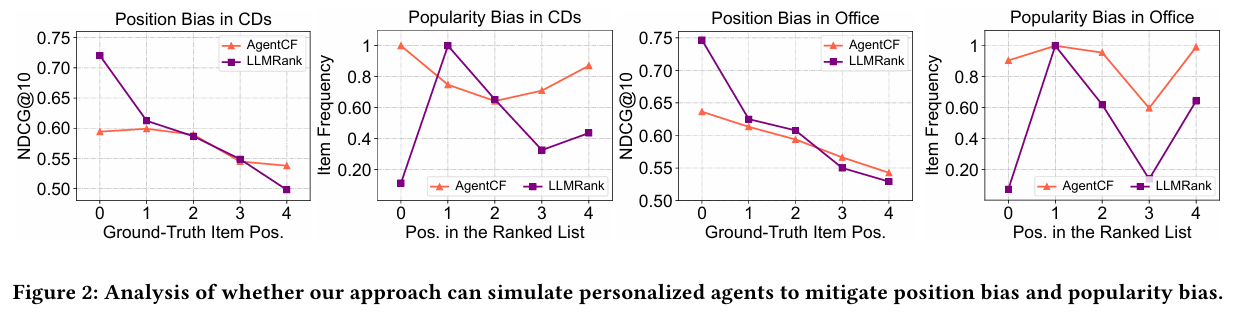
3.3.2 Performance Comparison w.r.t. Position Bias and Popularity Bias
- 개인화된 에이전트를 시뮬레이션하는 능력을 평가하기 위해 위치 및 인기 편향의 영향을 조사하였다.
- LLMRank는 인기와 위치 편향에 영향을 받는 반면, 제안된 접근법은 개인화된 선호에 기반하여 더 안정적인 성능을 보여준다.
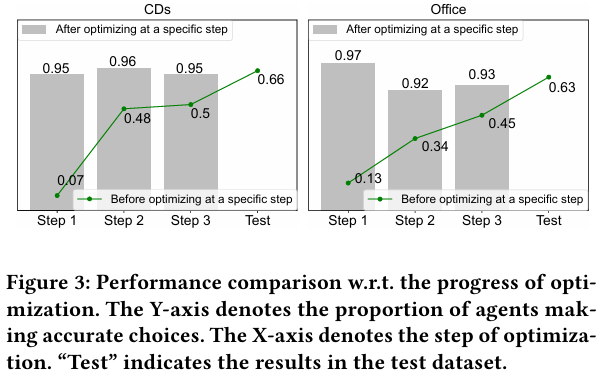
3.3.3 Effectiveness of Collaborative Reflection
- 최적화 과정에서 에이전트와 실제 사용자 간의 정렬 변화를 평가하여 Collaborative Reflection의 효과를 확인하였다.
- 지속적인 최적화가 사용자 에이전트의 선호를 실제 사용자와 일치시키는 데 기여함을 보여준다.
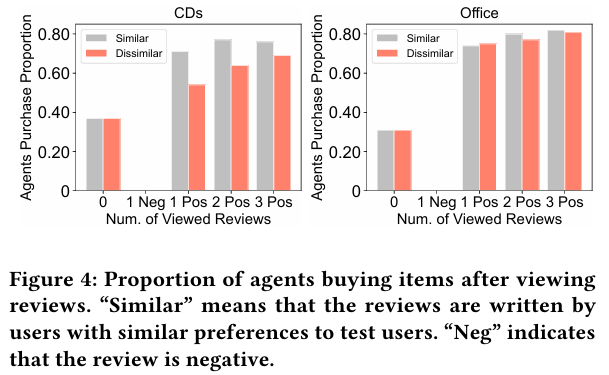
3.4 Simulations on Other Types of Interactions
3.4.1 User-user Interaction Simulation
- 사용자 에이전트가 다른 사용자와 유사한 사회적 행동을 나타내는지 확인하기 위해 사용자 간 상호작용을 시뮬레이션하였다.
- 사용자가 긍정적 리뷰를 접했을 때 구매 의향이 증가하고 부정적 리뷰를 접했을 때 구매를 자제하는 경향을 보인다.
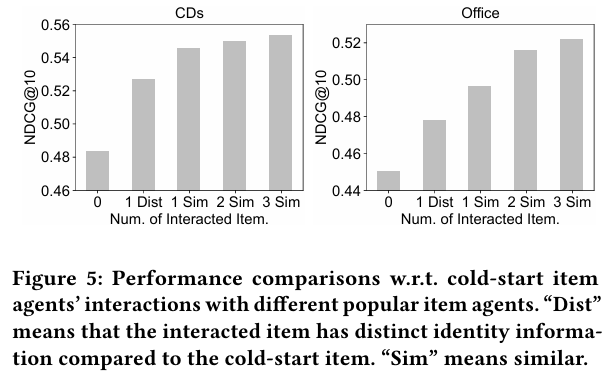
3.4.2 Item-item Interaction Simulation
- 콜드 스타트 문제를 완화하기 위해 새로운 아이템 에이전트와 인기 아이템 에이전트 간의 자율 상호작용을 탐색하였다.
- 새로운 아이템 에이전트가 사용자 선호를 추정하고 메모리를 조정하여 추천 성능을 향상시키는 과정을 보여준다.
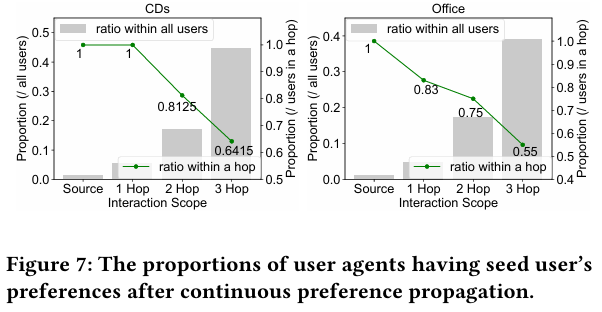
3.4.3 Process of Preference Propagation
- collaborative 최적화를 통해 선호 전파 과정을 자세히 설명한다.
- 사용자와 아이템 에이전트가 상호작용하여 서로의 선호를 전파하는 과정을 보여준다.

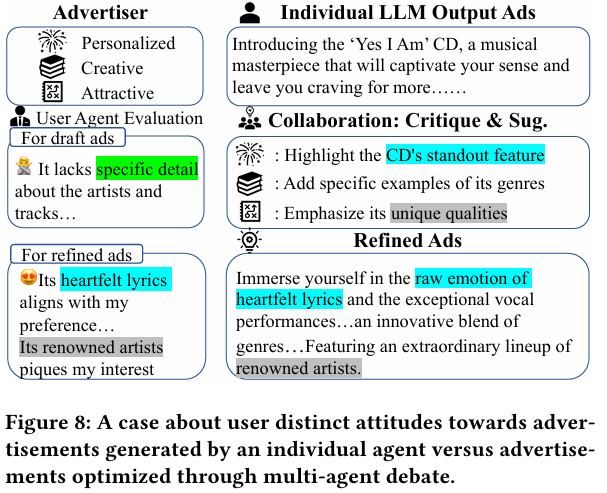
3.4.4 Collaborative Advertisements Creation
- 여러 LLM 간 협력이 광고 생성 결과를 개선할 수 있음을 탐구하였다.
- 다양한 광고 전문성을 가진 에이전트가 협력하여 더 매력적인 광고를 생성하는 과정이 나타난다.
5. Conclusion and Future Work
본 논문에서는 추천 시스템에서 사용자-아이템 상호작용을 시뮬레이션하기 위한 에이전트 기반 협업 필터링 접근법인 AgentCF를 제안하였다.
-
에이전트 : 사용자뿐만 아니라 아이템도 에이전트로 설정하여 LLM 기반 에이전트 간의 상호작용을 통해 two-sided 관계를 모델링한다.
-
collaborative 학습 접근법 : 사용자 및 아이템 에이전트를 함께 최적화하여 자율적인 상호작용을 수행하고, 그들의 결정과 실제 상호작용 기록 간의 불일치를 반영한다.
-
선호 전파 : 이 과정에서 사용자와 아이템 에이전트는 서로의 선호를 조정하고, 후속 상호작용에서 이 정보를 다른 에이전트에게 전파하여 협업 필터링 아이디어를 암묵적으로 모델링한다.
-
인간 유사 행동 : 시뮬레이션된 사용자 및 아이템 에이전트는 다양한 유형의 상호작용(사용자-아이템, 사용자-사용자, 아이템-아이템, 집단 상호작용)에서 인간과 유사한 행동을 보이며, AgentCF의 효과성을 입증한다.
향후 연구 방향
-
다양한 실제 시나리오 탐색 : 향후 연구에서는 더 많은 유형의 실제 시나리오와 그에 따른 상호작용을 탐구할 예정이다.
-
비인간 에이전트의 자율성 : AgentCF는 LLM 기반 에이전트를 통해 인간뿐만 아니라 비인간 객체도 시뮬레이션할 수 있는 작은 단계로, 비인간 객체에 자율성을 부여하고 모든 것을 연결하는 지능형 에이전트 생태계를 형성할 가능성을 지니고 있다. 이러한 주제는 향후 연구에서 다룰 것이다
Related Work
LLM-powered Agents
최근 LLM 기반 에이전트는 추론 및 계획 능력 덕분에 AGI 개발의 잠재력을 보여주고 있다. memory와 reflection 모듈을 갖춘 에이전트들은 과거 경험을 저장하고 미래 행동에 대한 더 나은 결정을 내릴 수 있다.
Memory 모듈
Memory 모듈은 에이전트가 이전의 대화 내용이나 사용자와의 상호작용에서 얻은 정보를 저장하고 활용할 수 있도록 한다. 이를 통해 에이전트는 사용자의 선호, 과거 질문 및 답변, 대화의 맥락 등을 기억하여 보다 일관되고 개인화된 응답을 제공할 수 있다. Memory는 에이전트가 장기적인 대화 맥락을 유지하고, 사용자와의 관계를 발전시키는 데 중요한 역할을 한다.
Reflection 모듈
Reflection(반성) 모듈은 에이전트가 자신의 행동이나 응답을 평가하고, 이를 바탕으로 학습할 수 있도록 돕는다. 이 모듈은 에이전트가 과거의 상호작용에서 얻은 피드백을 분석하고, 어떤 응답이 효과적이었는지, 어떤 부분에서 개선이 필요한지를 반영한다. Reflection은 에이전트가 지속적으로 발전하고, 사용자와의 상호작용에서 더 나은 성과를 낼 수 있도록 하는 데 기여한다.
일상적인 상호작용을 시뮬레이션하기 위해 에이전트를 활용하는 여러 연구가 제안되었으며, 여기에는 작은 마을의 일상, 토론, 심지어 게임 플레이가 포함된다. 이러한 연구들은 LLM 기반 에이전트가 사용자-아이템 상호작용을 시뮬레이션하는 응용 가능성을 탐구하도록 영감을 준다.
1. 작은 마을의 일상
Generative Agents: Interactive Simulacra of Human Behavior (2023)
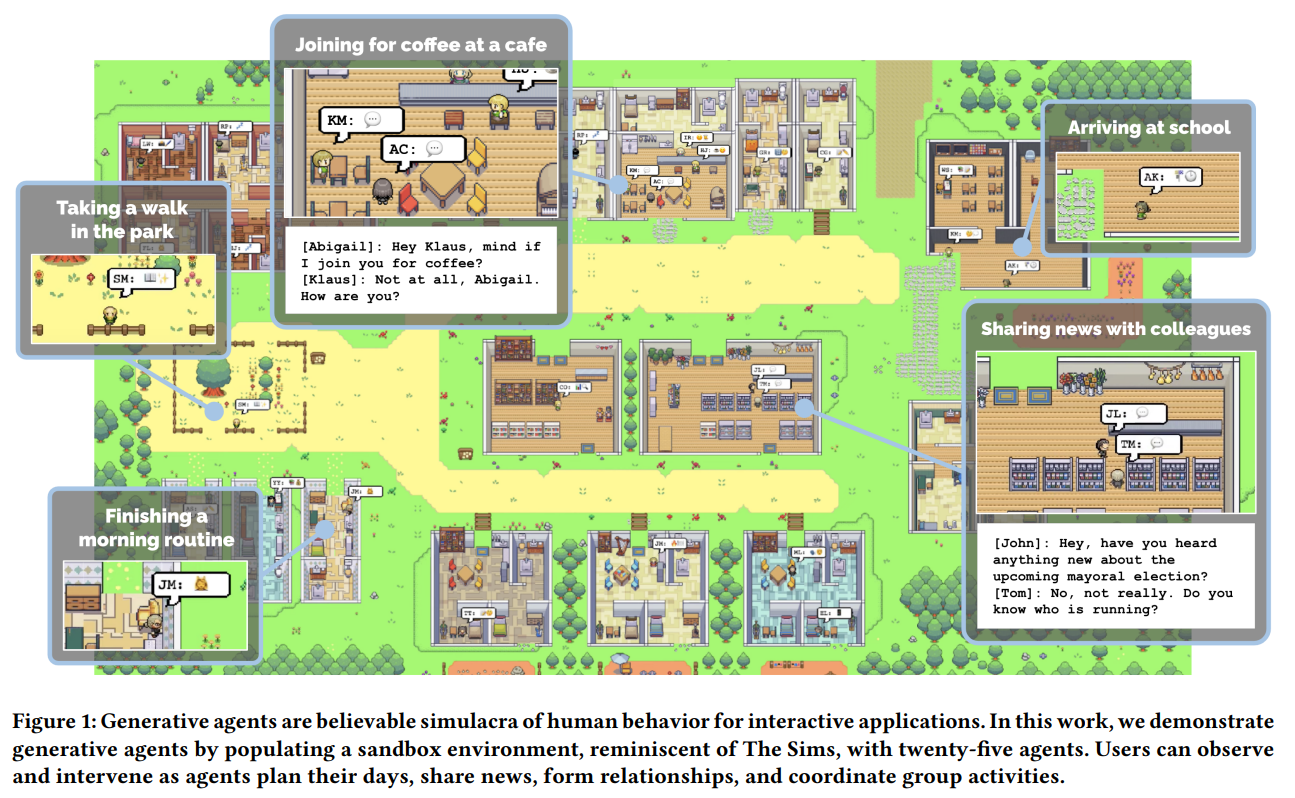
Generative Agents는 신뢰할 수 있는 인간 행동을 시뮬레이션하는 계산 소프트웨어 에이전트로, 이들은 일상적인 활동(예: 아침식사 준비, 출근 등)을 수행하고, 예술 활동을 하며, 의견을 형성하고 대화를 시작하는 등 인간과 유사한 행동을 한다.
Generative Agents에 LLM을 활용하는데, 자연어를 사용하여 에이전트의 경험에 대한 기록을 저장한다. 그리고 시간이 지남에 따라 이러한 기억을 더 높은 수준의 reflection으로 합성하고, 이를 동적으로 검색하여 행동을 계획한다. 이들은 The Sims에서 영감을 받은 인터랙티브 샌드박스 환경에 배치되어, 사용자가 자연어로 25명의 에이전트가 있는 소도시와 상호작용할 수 있게 한다.
평가 결과, 생성 에이전트들은 신뢰할 수 있는 개인 행동과 사회적 행동을 발휘한다. 예를 들어, 한 에이전트가 발렌타인 데이 파티를 열고 싶다는 단서로 시작해, 에이전트들이 자율적으로 초대장을 퍼뜨리고 새로운 친구를 사귀며, 파티에 함께 참석하기 위해 조율하는 모습을 보여준다.
2. 토론
Improving Factuality and Reasoning in Language Models through Multiagent Debate (2023)
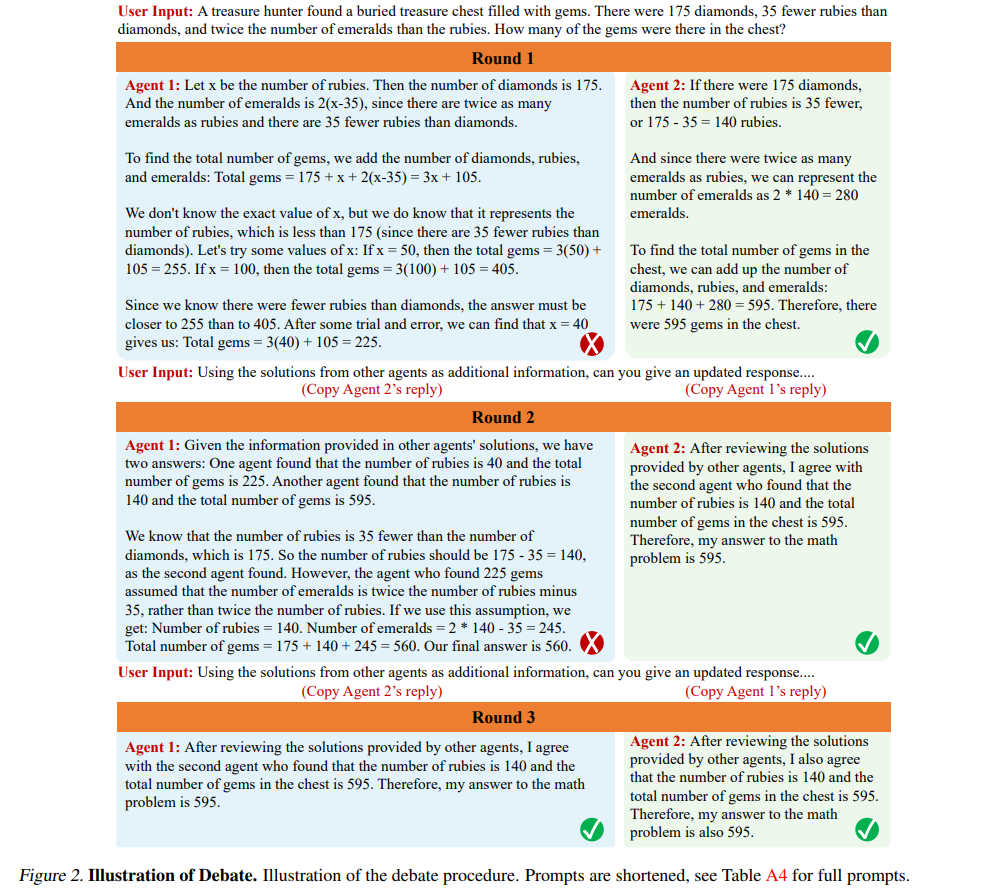
이 연구에서는 여러 언어 모델 인스턴스가 각자의 응답과 추론 과정을 제안하고 논의하여 공통의 최종 답변에 도달하는 방법을 소개한다. 연구 결과, 이 접근 방식이 수학적 및 전략적 추론 능력을 크게 향상시키며, 생성된 콘텐츠의 사실적 유효성을 개선하고, 현대 모델들이 자주 발생시키는 오류와 환각을 줄인다는 것을 보여준다.

3. 게임 플레이
Voyager: An Open-Ended Embodied Agent with Large Language Models (2023)
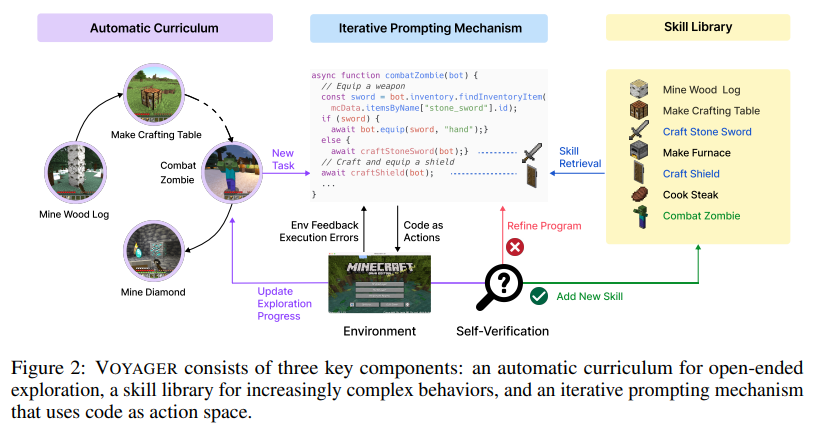
이 논문에서는 최초로 LLM 기반으로 구현된 Lifelong Learning Agent(지속적인 학습 능력을 갖춘 에이전트)인 Voyager를 소개한다. Voyager는 Minecraft 세계를 지속적으로 탐험하며, 다양한 기술을 습득하고 새로운 발견을 하며, 인간의 개입 없이 작동한다. Voyager는 GPT-4와 블랙박스 쿼리를 통해 상호작용하며, 모델 파라미터의 미세 조정 없이 작업을 수행한다.
Blackbox Query
블랙박스 모델 : 내부 작동 방식이나 파라미터에 대한 접근 없이, 입력을 주면 출력만 얻는 시스템을 말한다.
쿼리 방식 : Voyager는 GPT-4에 특정 질문이나 요청(쿼리)을 보내고, 그에 대한 응답을 받아 이를 활용합니다. 이 과정에서 GPT-4의 내부 동작이나 구조는 고려하지 않으며, 모델이 제공하는 정보나 답변을 그대로 사용한다.
Language Model for Recommendation
추천을 위해 언어 모델을 활용하려는 여러 시도가 있었다. 구체적으로, 언어 모델이 사용자 과거 상호작용을 바탕으로 사용자 선호를 추론하도록 유도하는 연구가 있었다. 그러나 LLM의 보편적인 지식과 도메인 특정 사용자 행동 패턴 간의 간극 때문에 개인화된 추천을 제공하는 데 한계가 있을 수 있다.
이를 해결하기 위해 여러 연구는 LLM의 지식을 통합하여 추천 모델을 향상시키는 방법을 제안하고 있다. 일부 연구는 추천 데이터를 기반으로 LLM을 미세 조정하여 추천에 특화시키기도 하지만, 이는 시간이 많이 소요될 수 있다.
최근 연구자들은 추천 시스템에 에이전트를 통합하려고 시도하며, 추천을 촉진하거나 사용자 행동 시뮬레이션에 중점을 두고 있다.
그러나 이러한 연구들은 주로 사용자 행동에 초점을 맞추고 사용자-아이템 관계 모델링을 간과하는데, 이는 추천 시스템의 핵심이다. 이러한 방법들과 달리, 본 논문은 아이템을 에이전트로 간주하고 사용자와 아이템 에이전트가 two-sided 관계를 모델링할 수 있도록 에이전트 기반 협업 필터링 접근 방식을 제안한다.
1. InteRecAgent
Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations (2023)
이 논문에서는 추천 모델과 LLM의 장점을 결합하여 다목적이고 interactive한 추천 시스템을 만드는 방법을 제안한다. InteRecAgent는 추천 모델과 LLM 간의 간극을 메우기 위해 LLM을 두뇌로, 추천 모델을 도구로 사용한다. InteRecAgent는 ID 기반 Matrix Factorization 모델과 같은 기존 추천 시스템이 LLM 통합을 통해 자연어 인터페이스를 갖춘 interactive 시스템으로 발전할 수 있게 한다.
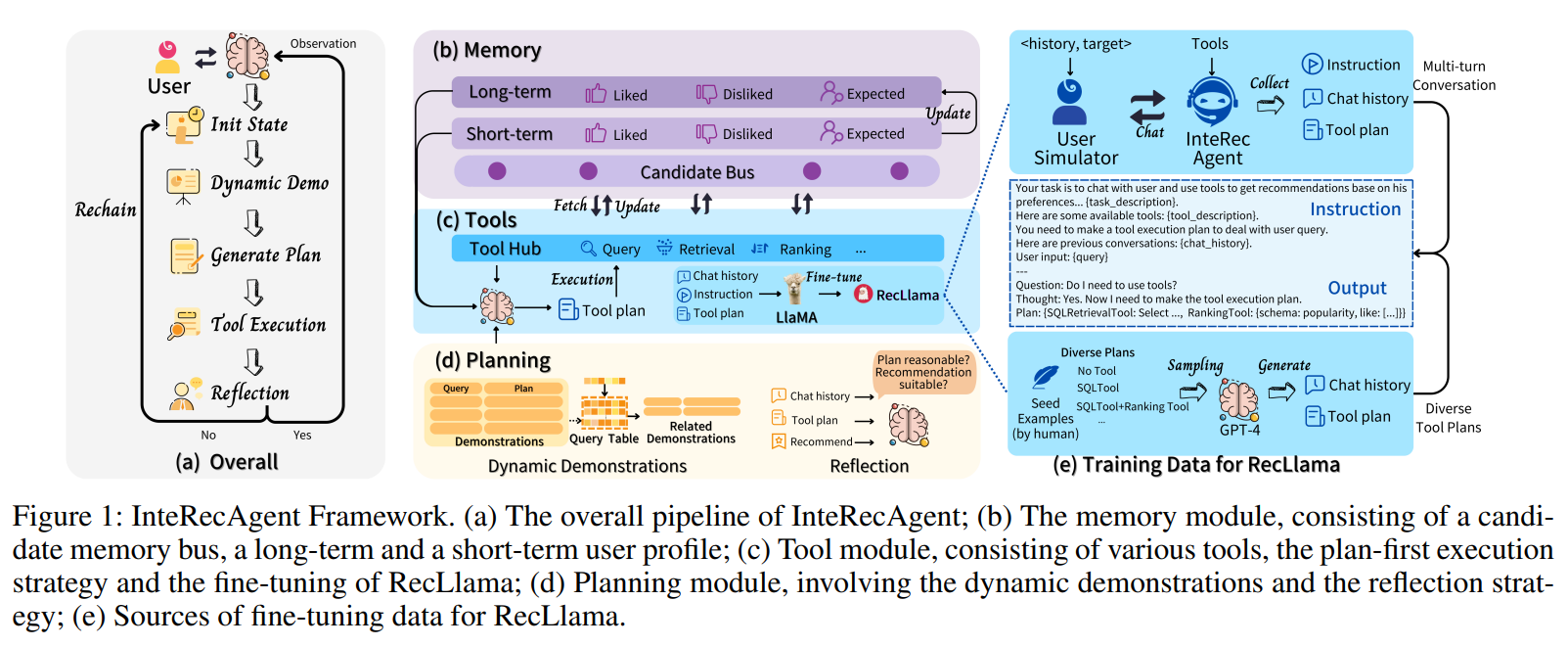
(a) InteRecAgent의 파이프라인
(b) 메모리 모듈 : 이 모듈은 후보 메모리 버스, 장기 사용자 프로필, 단기 사용자 프로필로 구성되어 있다. 이를 통해 사용자의 행동과 선호도를 저장하고 관리한다.
(c) 도구 모듈 : 추천 시스템의 실행을 지원하는 다양한 도구들로 구성되어 있으며, 계획 우선 실행 전략과 RecLlama의 fine-tuning을 포함한다.
(d) 계획 모듈 : Dynamic Demonstration(특정 작업이나 문제 해결 과정을 실시간으로 보여주는 방식)과 Reflection 전략을 포함하여, 추천 작업을 효율적으로 계획하고 조정하는 역할을 한다.
(e) RecLlama fine-tuning 데이터
2. RecSim
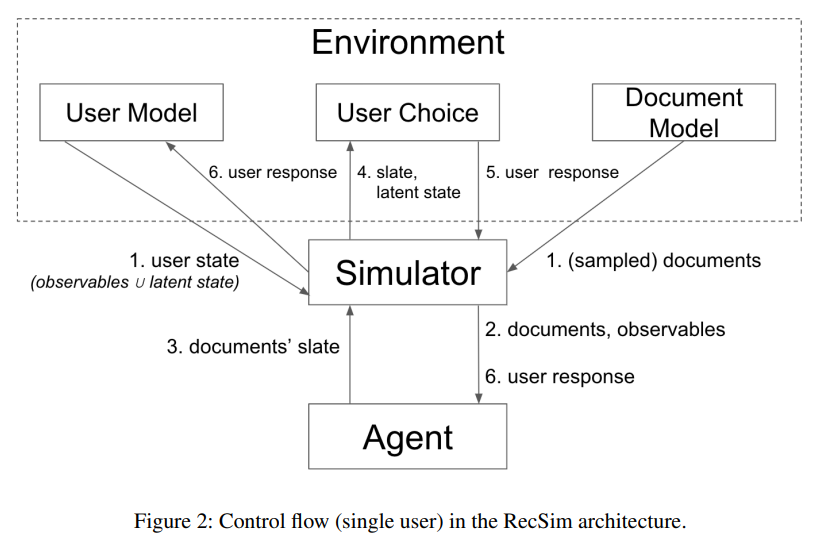
RecSim: A Configurable Simulation Platform for Recommender Systems (2019)
RecSim은 추천 시스템에서 강화학습을 사용하기 위한 시뮬레이션 환경을 구성할 수 있는 플랫폼이다. RecSim은 사용자와의 순차적 상호작용을 자연스럽게 지원하며, 사용자 행동 및 아이템 구조의 특정 측면을 반영하는 새로운 환경을 생성할 수 있다.
(Google 연구)
3. CORE
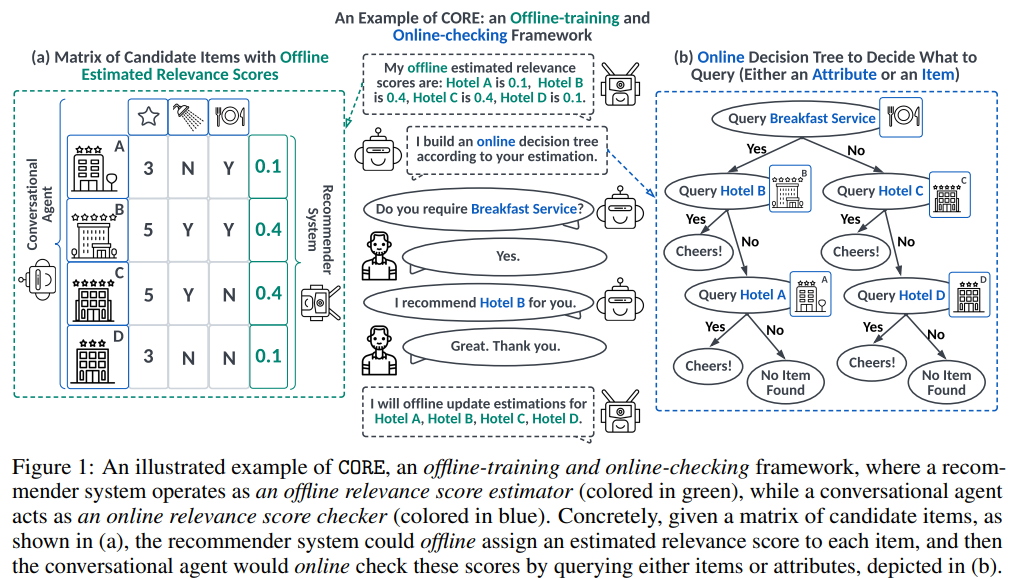
Lending Interaction Wings to Recommender Systems with Conversational Agents (2023)
CORE는 대화형 에이전트(챗봇)를 추천 시스템에 통합하기 위한 오프라인 훈련 및 온라인 확인 시스템이다. 기존의 대화형 추천 접근 방식이 대화와 추천 부분을 강화 학습 프레임워크를 통해 결합하는 것과 달리, CORE는 unified uncertainty minimization framework(불확실성 최소화)를 통해 대화형 에이전트와 추천 시스템을 연결한다.
4. RecAgent
RecAgent: A Novel Simulation Paradigm for Recommender Systems (2023)
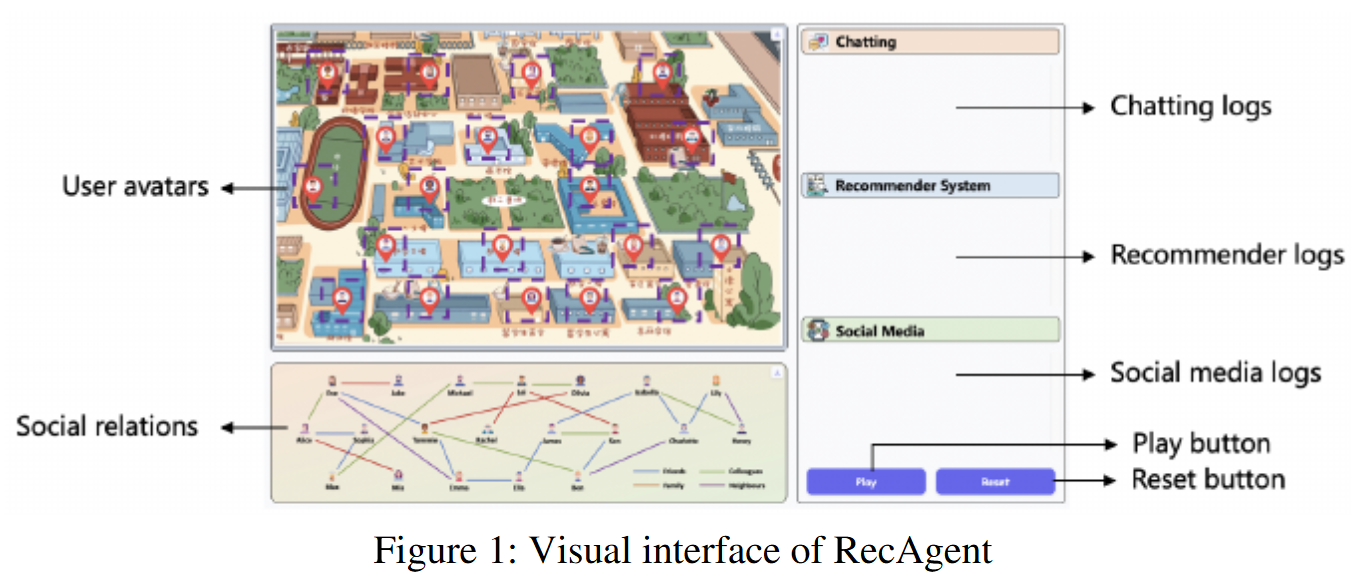
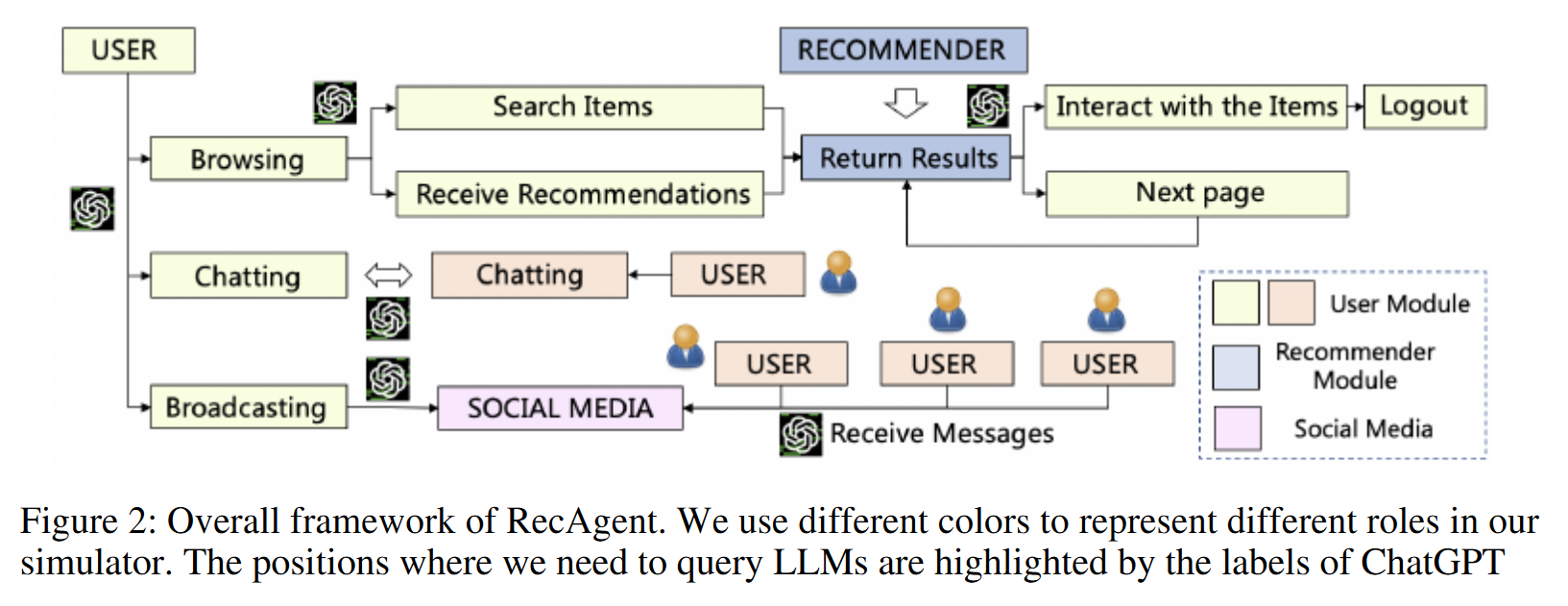
RecAgent는 LLM 기반 추천 시뮬레이터이다. 사용자 모듈의 가상 사용자는 추천 웹사이트(개인화된 콘텐츠나 제품을 추천하는 기능을 제공하는 웹 플랫폼)를 탐색하고, 다른 사용자와 소통하며, 소셜 미디어에 메시지를 전파할 수 있다. 추천 모듈은 사용자에게 검색 또는 추천 목록을 제공하며, 다양한 모델을 설계할 수 있다. 모든 사용자는 LLM을 기반으로 행동하며, 실제 세계처럼 자유롭게 진화할 수 있다.
5. RecMind
RecMind: Large Language Model Powered Agent For Recommendation (2023)
RecMind는 외부 지식을 활용하고 도구를 신중하게 계획하여 zero-shot 개인화 추천을 제공할 수 있는 LLM 기반 자율 추천 에이전트이다. Self-Inspiring 알고리즘은 계획 능력을 향상시키기 위해 제안된 알고리즘으로, LLM이 각 중간 단계에서 이전에 탐색한 모든 상태를 고려하여 다음 단계를 계획한다. 이 메커니즘은 추천을 위한 계획 과정에서 과거의 정보를 이해하고 활용하는 능력을 크게 향상시킨다.
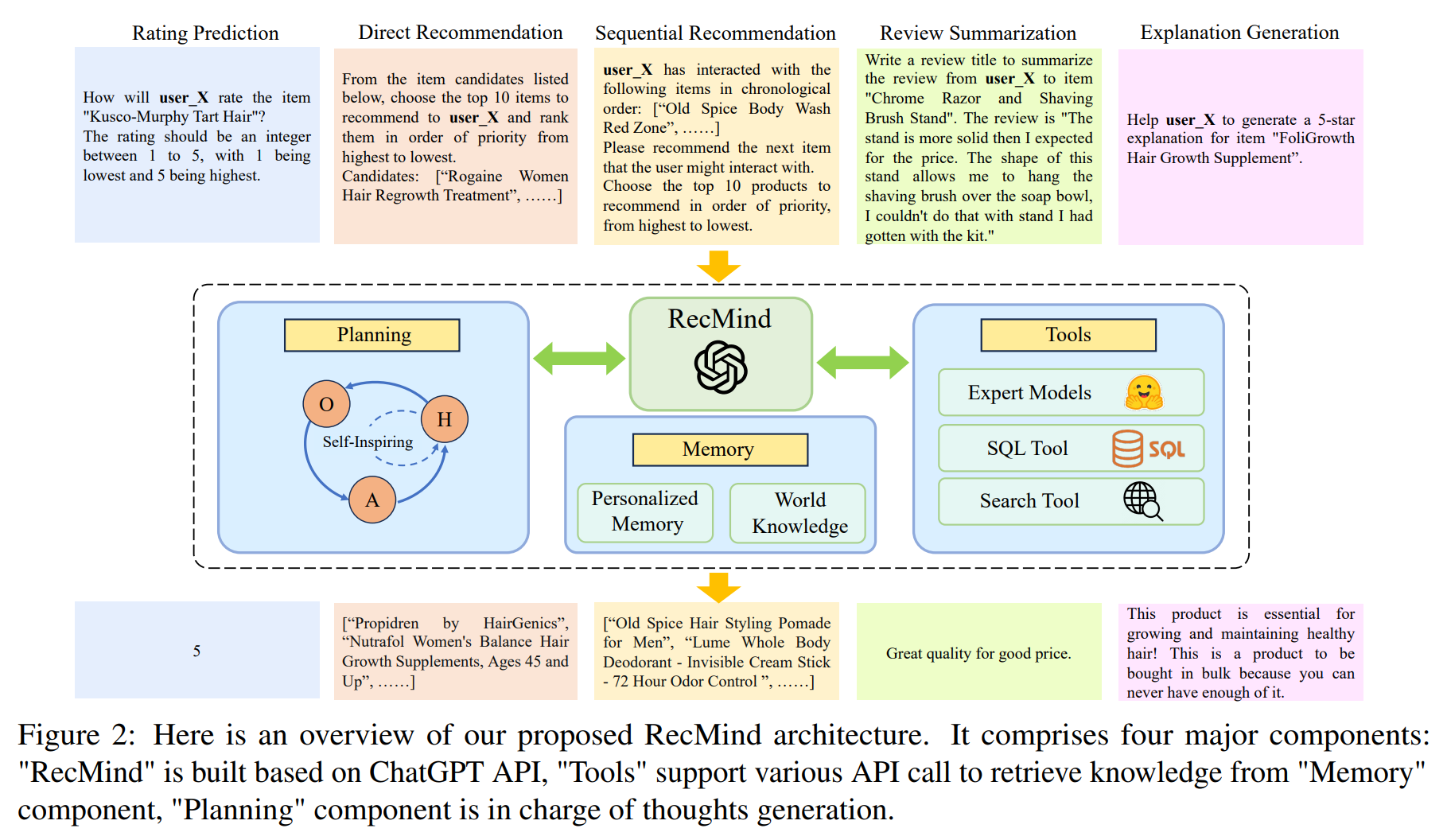
RecMind : ChatGPT API를 기반으로 구축된다.
Tools : Memory 구성 요소에서 지식을 검색하기 위한 다양한 API 호출을 지원한다.
Planning : 사고 생성 역할을 한다.
