📄 Paper
On Generative Agents in Recommendation [arxiv]
An Zhang ACM SIGIR 24
📝 Key Point
-
Agent4Rec의 개발 : Agent4Rec은 추천 시스템을 시뮬레이션하기 위해 설계된 LLM 기반의 생성 에이전트로, 사용자 행동을 모사하는 데 초점을 맞춘다.
-
사용자 행동 시뮬레이션 : Agent4Rec은 실제 인간의 행동을 효과적으로 시뮬레이션할 수 있는 능력을 보여주었다. 에이전트는 추천된 아이템에 대해 사용자와 유사한 반응을 보였으며, 높은 정확도와 재현율을 유지했다.
-
필터 버블 효과 재현 : 시뮬레이션 결과, 반복적인 추천 과정에서 영화 추천이 점점 중앙 집중화되는 경향이 나타났다. 장르 다양성은 감소하고, 특정 장르의 지배력은 강화되는 결과를 보였다. 이는 실제 추천 시스템에서 관찰되는 필터 버블 현상을 잘 반영한다.
-
인과 관계 분석 : 인과 관계 분석 결과, 영화 품질과 인기가 영화 평점에 주요한 영향을 미치는 것으로 나타났다. 높은 노출을 받은 영화는 더 많은 시청과 평점 증가를 유도하며, 이는 인기 편향을 강화하는 피드백 루프를 형성한다.
Abstract
연구 배경 : 추천 시스템은 정보 전파의 핵심이지만, 오프라인 메트릭과 온라인 성능 간의 단절이 발전을 저해한다. 이를 해결하기 위해, LLM의 인간 수준의 지능을 활용한 추천 시뮬레이터를 구상한다.
제안 시스템 : Agent4Rec은 LLM 기반의 생성 에이전트를 사용하는 사용자 시뮬레이터이다. 사용자 프로필, 메모리, 행동 모듈을 추천 시스템에 맞춰 설계하며, 실제 데이터셋을 통해 에이전트의 특성을 초기화한다.
주요 기능 : 에이전트는 개인화된 추천 모델과 페이지 단위로 상호작용하고, 협업 필터링 기반 추천 알고리즘을 사용한다. 이 시스템은 에이전트의 행동을 통해 실제 자율적 인간의 행동을 시뮬레이션할 수 있는 가능성을 탐구한다.
연구 목표 : Agent4Rec의 능력과 한계를 평가하고, 추천 선호 간의 일치 및 편차를 분석한다. 또한, 필터 버블 효과를 모방하고 추천 작업의 인과 관계를 발견하는 통찰력 있는 실험을 진행한다.
Figure
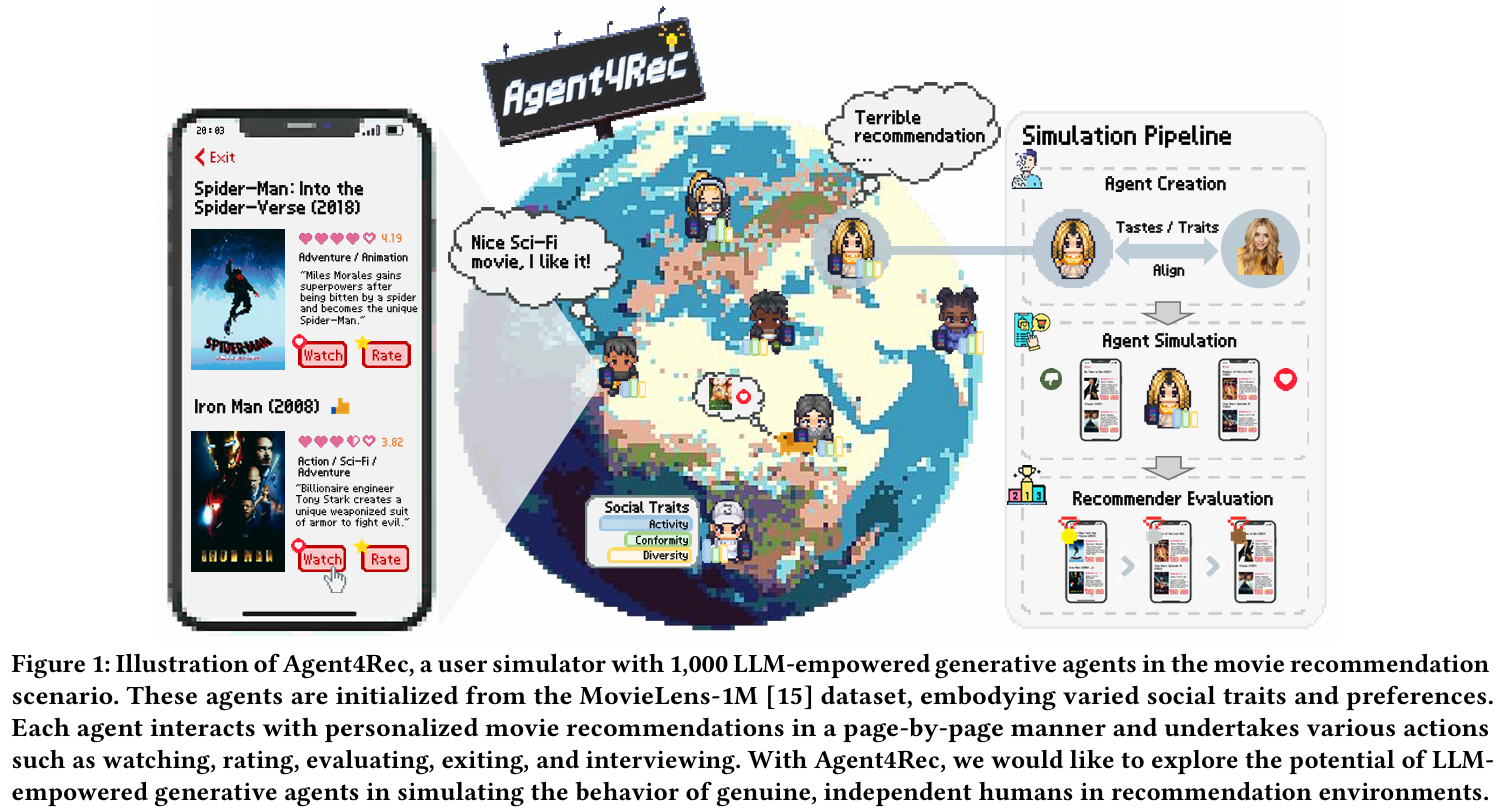
Agent4Rec은 영화 추천 시나리오에서 1,000개의 LLM 기반 생성 에이전트를 사용하는 사용자 시뮬레이터이다. 이 에이전트들은 MovieLens-1M 데이터셋을 기반으로 초기화되며, 다양한 사회적 특성과 선호를 가진다.
각 에이전트는 개인화된 영화 추천을 페이지 단위로 상호작용하며, 여러 가지 행동을 수행한다. 여기에는 영화 시청, 평가, 리뷰, 종료, 인터뷰 등이 포함된다. Agent4Rec을 통해 LLM 기반 생성 에이전트가 추천 환경에서 실제 독립적인 인간의 행동을 시뮬레이션할 수 있는 가능성을 탐구하고자 한다.
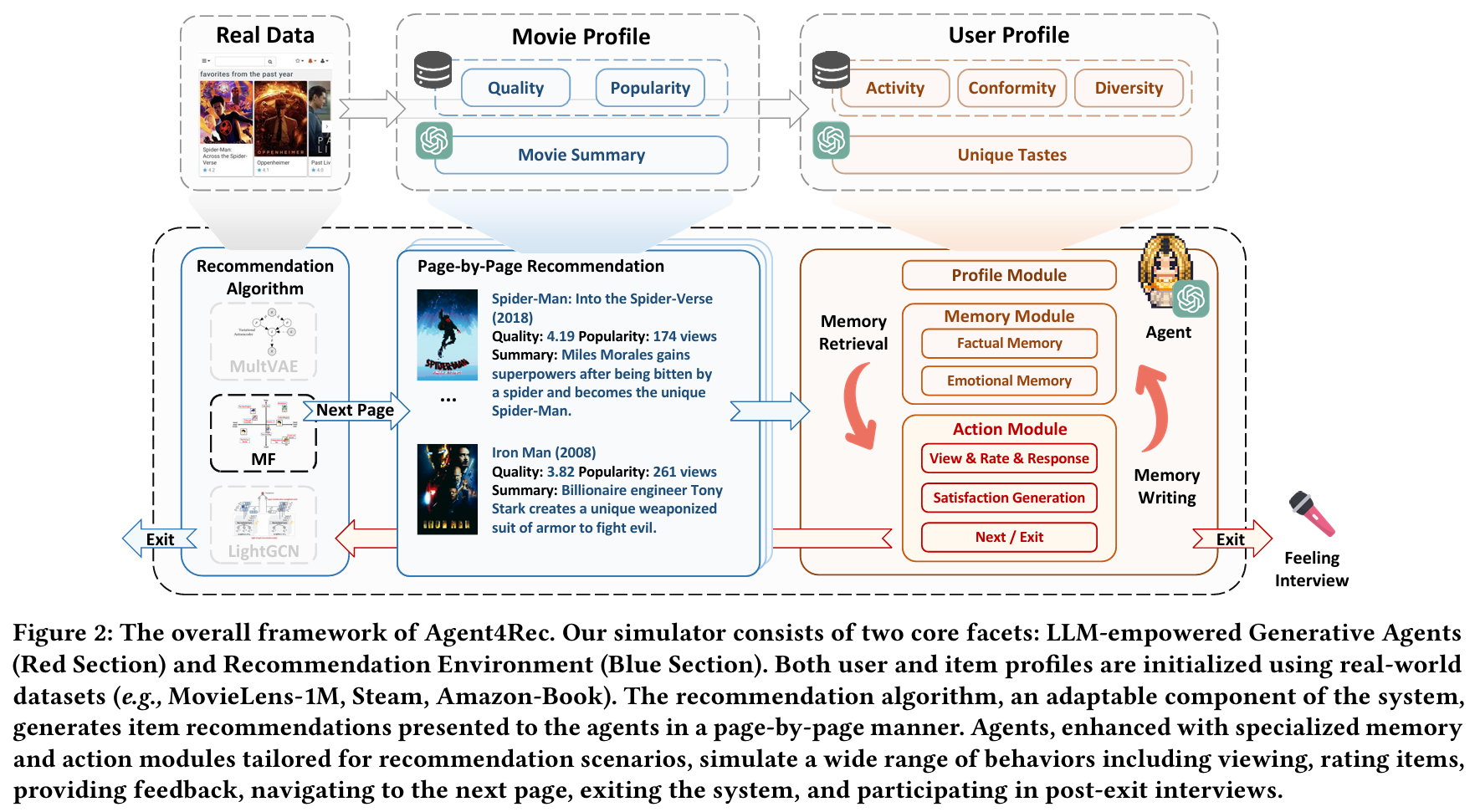
Agent4Rec의 전반적인 구조이다. 이 시뮬레이터는 두 가지 핵심 요소로 구성된다. LLM 기반 생성 에이전트(빨간색 섹션)와 추천 환경(파란색 섹션)이다. 사용자와 아이템 프로필은 실제 데이터셋(예: MovieLens-1M, Steam, Amazon-Book)을 사용하여 초기화된다.
추천 알고리즘은 시스템의 적응 가능한 구성 요소로, 에이전트에게 페이지 단위로 제시되는 아이템 추천을 생성한다. 에이전트들은 추천 시나리오에 맞춘 특화된 메모리 및 행동 모듈로 강화되어, 다양한 행동을 시뮬레이션한다. 여기에는 아이템 시청, 평가, 피드백 제공, 다음 페이지로 이동, 시스템 종료, 종료 후 인터뷰 참여 등이 포함된다.
1. Introduction
연구 배경 : 추천 시스템은 현대 정보 전파에서 중요한 역할을 하며 개인의 선호와 인지 과정을 형성한다. 그러나 기존의 감독형 추천 접근 방식은 오프라인 메트릭과 온라인 성능 간의 큰 격차로 인해 한계를 드러내며, 이는 학술 연구와 실제 추천 배포 간의 통합을 저해한다. 이러한 문제를 해결하기 위해, 사용자 의도를 충실히 포착하고 인간 인지 메커니즘을 인코딩하는 시뮬레이션 플랫폼의 필요성이 대두된다.
제안 시스템 : Agent4Rec은 LLM 기반 생성 에이전트를 사용하는 일반 사용자 시뮬레이터로, 추천 환경 내에서 1,000개의 에이전트를 시뮬레이션한다. 각 에이전트는 실제 데이터셋을 기반으로 초기화되며, 사용자 프로필, 메모리, 행동 모듈로 구성된다. 프로필 모듈은 개인화된 사회적 특성과 과거 선호를 저장하고, 메모리 모듈은 과거 시청 행동과 감정적 기억을 기록하여 정보 검색 및 감정 기반 반영을 가능하게 한다. 행동 모듈은 추천 환경과 상호작용하며 다양한 행동을 수행한다.
추천 알고리즘 : 에이전트는 사전 정의된 추천 알고리즘을 통해 페이지 단위로 아이템을 추천받으며, 주로 협업 필터링 기반 전략을 통합한다. 시뮬레이터는 개방형 인터페이스를 제공하여 연구자와 실무자가 원하는 추천 알고리즘을 쉽게 배포할 수 있도록 설계되었다.
평가 방법 : Agent4Rec의 효과성과 한계를 평가하기 위해 사용자와 추천 시스템의 관점에서 포괄적인 실험을 수행한다. 사용자의 관점에서는 에이전트의 일치 정도를 평가하고, 추천 시스템의 관점에서는 다양한 알고리즘으로 구성된 추천자들을 평가한다. 평가 지표는 추천된 아이템 수, 사용자 평점, 사용자 참여 시간, 전반적인 사용자 만족도를 포함한다.
실험 : 두 가지 실험을 통해 추천 작업의 해결되지 않은 문제를 탐구한다. 첫 번째 실험에서는 필터 버블 효과를 모방하여 중앙집중화된 추천 현상을 이해하고, 두 번째 실험에서는 데이터 수집 도구로서의 역할을 하여 인과 관계를 발견한다.
기여 :
- LLM 기반 에이전트를 활용한 추천 시뮬레이터 Agent4Rec을 개발하여 사용자 개인화된 선호와 행동 패턴을 모사한다.
- Agent4Rec의 능력과 한계를 평가하고, 오프라인 성능과 시뮬레이션 피드백을 고려한 이중 평가 방식을 제안한다.
- Agent4Rec을 데이터 수집 도구로 활용하여 필터 버블 효과를 재현하고 추천 시스템 시나리오 내의 인과 관계를 밝혀낸다.
Agent4Rec은 최첨단 기술과 추천 시스템의 도전 과제 사이의 교차점에 위치하며, 이 연구 방향에서 더 많은 연구를 촉진할 수 있는 실험 플랫폼을 제공한다.
2. Agnet4Rec
Agent4Rec은 추천 시나리오에서 사용자 시뮬레이션을 수행하며, 사용자 행동을 정확하게 반영하고 장기적인 사용자 선호를 효과적으로 예측하며 추천 알고리즘을 체계적으로 평가하는 것을 목표로 한다. 이를 위해 두 가지 핵심 요소를 고려한다 :
- 에이전트 아키텍처 설계 : 사용자 개인화된 선호와 인간의 인지적 추론을 충실히 모사하는 에이전트 아키텍처를 설계한다.
- 추천 환경 구축 : 신뢰성, 확장성, 적응성을 보장하는 추천 환경을 구축한다.
Agent4Rec은 LangChain을 수정하여 개발되었고, 모든 에이전트는 ChatGPT의 gpt-3.5-turbo 버전으로 구동된다.
Task Formulation
사용자 와 아이템 가 주어졌을 때, 은 사용자가 아이템 와 상호작용을 했고, 이후 로 평가했음을 나타낸다. 반대로, 은 사용자가 해당 아이템을 채택하지 않았음을 의미한다. 각 아이템 의 품질은 다음과 같이 표현된다:
아이템의 인기도는 로 나타내며, 아이템의 장르 집합은 로 주어진다. 시뮬레이터의 궁극적인 목표는 사용자가 보지 않은 추천 아이템 에 대한 진정한 선호 와 평가 를 충실히 추출하는 것이다.
2.1 Agent Architecture
Agent4Rec의 생성 에이전트는 LLM을 기반으로 하여 추천 시나리오에 맞춘 세 가지 전문화된 모듈(프로필 모듈, 메모리 모듈, 행동 모듈)을 통해 기능을 향상시킨다. 특히, 개인화된 진정한 인간 행동을 모사하기 위해 각 에이전트는 개인화된 사회적 특성과 선호를 반영하는 사용자 프로필 모듈을 통합한다. 또한, 인간의 인지 과정을 모델링하여 과거 상호작용과 감정을 저장, 검색 및 적용하여 일관된 행동을 생성할 수 있도록 메모리 및 행동 모듈이 장착된다.
2.1.1 Profile Module
개인화된 추천 시뮬레이션 분야에서 사용자 프로필 모듈은 에이전트의 진정한 인간 행동과의 일치를 보장하는 중요한 역할을 한다. 생성 에이전트의 후속 시뮬레이션 및 평가를 위한 신뢰할 수 있는 기반을 마련하기 위해, MovieLens-1M, Steam, Amazon-Book과 같은 벤치마크 데이터셋을 초기화에 사용한다. 각 에이전트의 프로필은 두 가지 구성 요소(사회적 특성과 고유한 취향)로 이루어진다.
-
사회적 특성 (Social Traits) : 세 가지 주요 특성(활동, 순응, 다양성)을 포함하며, 추천 시나리오에서 개인의 성격과 특성을 포착한다.
-
활동 : 사용자가 추천 아이템과 상호작용하는 빈도와 폭을 정량화한다. 에이전트의 활동 특성은 다음과 같이 정의된다:
-
순응 : 사용자의 평가가 평균 아이템 평가와 얼마나 일치하는지를 설명하며, 독립적인 관점을 가진 사용자와 대중적인 의견에 가까운 사용자를 구분한다. 사용자 의 순응 특성은 다음과 같이 정의된다:
-
다양성 : 사용자가 다양한 장르의 아이템에 얼마나 선호를 두는지를 반영한다. 사용자 의 다양성 특성은 다음과 같이 정의된다:
사용자는 일반적으로 이러한 사회적 특성에서 특정 분포를 보이며, 이를 기반으로 각 특성에 따라 세 가지 불균형 계층으로 분류한다.
-
-
고유한 취향 (Unique Tastes) : 각 사용자에 대해 시청 기록에서 무작위로 25개 아이템을 선택하여 자연어로 개인화된 선호를 인코딩한다. 평점이 3 이상인 아이템은 '좋아함'으로, 3 미만인 아이템은 '싫어함'으로 분류한다. ChatGPT를 활용하여 사용자가 보인 고유한 취향과 평가 패턴을 요약하여 프로필에 포함시킨다. 이러한 개인화된 아이템 취향은 사용자 프로필에 두 번째 구성 요소로 통합된다.
Agent4Rec에서는 개인 식별자(이름, 성별, 나이, 직업 등)를 의도적으로 숨겨서 개인정보 보호 문제를 해결하고, 널리 적용 가능성을 보장한다. 이러한 속성들은 다른 유형의 에이전트를 형성하는 데 유용할 수 있지만, 추천의 범주에서는 사용자의 아이템 선호를 지배하지 않는다. 선호는 과거 시청 기록, 평가 패턴, 사용자 상호작용에 내재된 통찰을 통해 충분히 유추할 수 있다.
2.1.2 Memory Module
인간은 다양한 기억을 보유하며, 주로 사실적 기억과 감정적 기억으로 구분된다. 이 중 감정적 기억은 개인의 역사에서 핵심적인 역할을 하며, 의사결정에 더 강한 영향을 미친다. 기존 연구들은 에이전트의 메모리 구조를 상세히 설명하였으나, 감정적 기억은 대체로 간과되었다.
Agent4Rec에서는 각 생성 에이전트 내에 전문화된 메모리 모듈을 내장하여 사실적 기억과 감정적 기억을 기록한다. 추천 작업에 맞춰 설계된 사실적 기억은 추천 시스템 내에서의 상호작용 행동을 포함하고, 감정적 기억은 이러한 상호작용에서 발생하는 심리적 감정을 포착한다.
-
사실적 기억 : 추천된 아이템 목록과 사용자 피드백을 포함한다. 피드백은 사용자가 아이템을 시청했는지, 해당 아이템에 대한 평점, 종료 행동 등을 포함한다.
-
감정적 기억 : 시스템 상호작용 중 사용자의 감정을 기록하며, 피로도 및 전반적인 만족도와 같은 요소를 포함한다. 이는 생성 에이전트가 단순히 과거의 사실적 상호작용에만 반응하는 것이 아니라, 감정도 고려하여 진정한 인간 행동을 더욱 잘 모사하도록 한다.
메모리는 자연어 설명과 벡터 표현의 두 가지 형식으로 저장된다. 자연어 설명은 인간이 이해하기 쉽게 설계되었으며, 벡터 표현은 효율적인 기억 검색과 추출을 위해 최적화된다.
에이전트가 추천 환경과 상호작용할 수 있도록 세 가지 메모리 작업을 도입한다.
-
메모리 검색 (Memory Retrieval) : 이전 연구의 통찰을 바탕으로, 이 작업은 에이전트가 메모리 모듈에서 가장 관련성 높은 정보를 추출하도록 돕는다.
-
메모리 기록 (Memory Writing) : 에이전트가 시뮬레이션한 상호작용 및 감정을 메모리 스트림에 기록할 수 있게 한다.
-
메모리 반영 (Memory Reflection) : 추천에서 감정이 사용자 행동에 미치는 영향을 인식하고, 감정 기반 자기 반영 메커니즘을 통합한다. 이는 기존 에이전트 메모리 설계(예: 자기 요약, 자기 검증, 자기 수정)와는 대조적이다. 에이전트의 행동이 미리 정의된 횟수를 초과하면 반영 과정이 시작된다. LLM의 능력을 활용하여 에이전트는 추천에 대한 만족도와 피로도를 introspect(내성적으로 성찰)하며, 자신의 인지 상태에 대한 더 깊은 이해를 제공한다.
2.1.3 Action Module
에이전트에 사용자 프로필과 메모리 모듈을 장착함으로써, 에이전트는 현재 관찰에 기반하여 인간과 유사한 다양한 행동을 보일 수 있다. Agent4Rec에서는 추천 도메인에 특화된 행동 모듈을 설계하였으며, 이는 두 가지 주요 범주의 행동을 포함한다:
-
취향 기반 행동 (Taste-driven Actions) : 아이템을 시청하고 평가하며, 시청 후 감정을 생성하는 행동이다. Agent4Rec에서는 추천 알고리즘에 의해 생성된 추천 아이템이 페이지 단위로 에이전트에게 제시된다. 에이전트는 각 페이지의 아이템을 자신의 선호와 일치하는지 평가하며, 관심 있는 아이템은 시청하고 나머지는 건너뛸 수 있다. 시청한 각 아이템에 대해 평점과 감정을 제공한다.
-
감정 기반 행동 (Emotion-driven Actions) : 추천 시스템을 종료하고 평가하며, 종료 후 인터뷰를 진행하는 행동이다. 추천 환경에서의 감정은 에이전트의 경험에 큰 영향을 미치며, 이는 시뮬레이션에서 종종 간과된다. 에이전트는 이전 추천 아이템에 대한 만족도와 현재의 피로도가 다음 추천 페이지를 탐색할지 또는 추천 시스템을 종료할지를 결정하는 데 영향을 미친다. 이러한 다면적인 의사결정을 보다 잘 시뮬레이션하기 위해, 우리는 Chain-of-Thought를 통해 에이전트의 감정적 추론 능력을 강화한다. 에이전트는 먼저 현재 추천 페이지를 인식하고 감정적 기억에서 이전 추천에 대한 만족도를 검색한다. 이후 에이전트는 현재 추천 페이지에 대한 만족도와 피로도를 자율적으로 표현한다. 이러한 통찰을 바탕으로, 개인화된 활동 특성과 결합하여 시스템을 종료할지 결정한다.
종료 후, 각 에이전트와 인터뷰를 실시하여 추천 시스템에 대한 평점과 전반적인 인상을 포착하고, 시스템 내 탐색 중 자신의 행동에 대한 명확한 설명을 제공한다. 이러한 인터뷰 스타일의 피드백은 전통적인 메트릭에서 얻은 통찰을 보강하며, 보다 풍부하고 인간이 이해할 수 있는 평가를 가능하게 한다.
Chain-of-Thought (CoT)
Chain-of-Thought는 인공지능 모델이 문제를 해결하거나 질문에 답할 때, 각 단계의 사고 과정을 명시적으로 설명하도록 하는 방법론이다. 이 접근법은 모델이 단순한 최종 답변을 제공하는 것이 아니라, 문제 해결 과정에서의 논리적 추론을 단계적으로 나열하게 함으로써 더 나은 이해와 투명성을 제공하는 데 목적이 있다.
Chain-of-Thought의 장점
- 논리적 추론 강화 : 모델이 문제를 해결하는 과정을 명시적으로 설명함으로써, 더 복잡한 문제를 해결할 수 있는 능력을 향상시킬 수 있다.
- 투명성 : 사용자는 모델이 어떻게 결론에 도달했는지를 이해할 수 있어, 결과에 대한 신뢰성을 높일 수 있다.
- 오류 분석 : 각 단계에서의 사고 과정을 명시함으로써, 모델의 오류를 더 쉽게 식별하고 개선할 수 있다.
2.2 Recommendation Environment
Agent4Rec는 에이전트와 추천 환경 간의 상호작용을 시뮬레이션하며, 실제 시나리오와 유사한 환경 구축의 세 가지 주요 측면을 논의한다: 아이템 프로필 생성, 페이지 단위 추천 시나리오, 추천 알고리즘 설계.
1. Item Profile Generation (아이템 프로필 생성)
- 아이템 특성 : 아이템의 품질, 인기도, 장르 및 요약을 포함하는 프로필을 생성한다.
- 품질 : 과거 평점에 기반하여 결정된다.
- 인기도 : 리뷰 수에 따라 판단된다.
- 장르 및 요약 : LLM을 통해 생성된다.
- 목표 : 아이템의 고유성을 프로필에 담는 것을 넘어 실제 사용자 추천 장면을 시뮬레이션한다. LLM의 환각 가능성을 테스트하기 위해, 아이템을 18개 장르 중 하나로 분류하고 요약을 생성하는 few-shot learning 접근법을 활용한다.
- 신뢰성 유지 : LLM이 잘못 분류한 아이템은 제거하여 환각의 위험을 줄이고, 시뮬레이션의 신뢰성을 높인다.
Few-shot prompting
Few-shot prompting은 LLM이 새로운 작업을 수행할 때 몇 가지 예시를 제공하여 모델이 작업의 맥락과 요구 사항을 더 잘 이해하도록 돕는 기술이다. 이 방법은 모델이 더 정확하고 구조화된 출력을 생성하게 하는 데 매우 효과적이다.
- 작업 구성 요소
- 작업 (Instructions) : 모델이 수행해야 할 작업에 대한 설명
- 예시 (Examples) : 모델이 참고할 수 있는 예시들
- 입력 데이터 (Input data) : 분석할 데이터로, 선택적으로 활용됨
2. Page-by-Page Recommendation Scenario (페이지 단위 추천 시나리오)
- 작동 방식 : 실제 추천 플랫폼(e.g. Netflix, YouTube, Douban)의 운영을 모방하여 페이지 단위로 기능한다.
- 사용자 경험 : 각 페이지에서 추천된 아이템 목록을 제시하고, 사용자의 상호작용, 선호도, 피드백에 따라 후속 페이지의 추천이 조정된다.
- 목표 : 더 정교한 사용자 경험 제공을 위해 추천을 맞춤화한다.
3. Recommendation Algorithm Designs (추천 알고리즘 설계)
- 독립 모듈 : 추천 알고리즘은 독립적인 모듈로 구성되며, 확장성에 중점을 둔다.
- 협업 필터링 전략 : 무작위, 가장 인기 있는 아이템, Matrix Factorization (MF), LightGCN, MultVAE와 같은 사전 구현된 전략을 포함한다.
- 열린 인터페이스 : 외부 추천 알고리즘을 쉽게 통합할 수 있는 인터페이스를 제공하여, 연구자와 실무자가 다양한 알고리즘을 활용할 수 있도록 한다.
- 목표 : Agent4Rec을 포괄적인 평가와 가치 있는 사용자 피드백 수집을 위한 다목적 플랫폼으로 만들기 위해 설계되었다.
3. Agent Alignment Evaluation
RQ1 : LLM 기반 생성 에이전트가 추천 시스템에서 실제 독립적인 인간의 행동을 얼마나 잘 시뮬레이션할 수 있는가?
이 섹션에서는 생성 에이전트의 능력과 한계를 다양한 관점에서 분석한다. 여기에는 사용자 행동의 일치(사용자 취향, 평점 분포 및 사회적 특성 등)와 추천 환경의 평가(추천 전략 평가, 페이지 단위 추천 개선 및 인터뷰 사례 연구 등)가 포함된다.
Motivation
- 생성 에이전트는 추천된 아이템에 적절히 응답하기 위해 자신의 선호를 명확히 이해해야 한다.
- 독립적이고 개인화된 에이전트가 MovieLens-1M의 실제 사용자로부터 초기화되었을 때, 장기적인 선호 일관성을 유지해야 한다고 가정한다.
- 이는 에이전트가 실제 사용자가 선호하는 아이템을 구별할 수 있어야 함을 의미한다.
Setting
- 생성 에이전트가 사용자 프로필에 인코딩된 선호와 얼마나 잘 일치하는지를 검증하기 위해, 에이전트에게 해당 사용자와 상호작용한 아이템과 하지 않은 아이템을 구별하도록 한다.
- 세 가지 실제 데이터셋(즉, Movielens-1M, Steam, Amazon-Book)을 사용하여 실험을 수행한다.
- 1,000개의 에이전트가 각각 20개의 아이템을 무작위로 할당받으며, 이 중 사용자가 상호작용한 아이템과 하지 않은 아이템의 비율을 1:𝑚(𝑚 ∈ {1, 2, 3, 9})로 설정한다.
- 에이전트의 응답(즉, 𝑦ˆ𝑢𝑖)은 추천된 아이템에 대한 이진 판별로 간주된다.
Results

- 생성 에이전트는 사용자 선호와 일치하는 아이템을 일관되게 식별한다. 특히, 방해 아이템의 수에 관계없이 에이전트는 약 65%의 높은 정확도와 75%의 재현율을 유지한다. 이러한 높은 충실도는 개인화된 프로필이 사용자의 진정한 관심사를 충실히 반영하기 때문이다.
- 에이전트는 선호 아이템의 수를 상대적으로 일관되게 유지하는 경향이 있으며, 이는 LLM의 고유한 환각에서 기인할 수 있다. 정확도와 재현율은 만족스러운 결과를 보이나, 정밀도와 F1 점수는 사용자 선호 아이템의 비율이 감소함에 따라 급격히 감소한다. 이는 LLM의 고유한 환각으로 인해 에이전트가 일정 수의 아이템을 지속적으로 선택하는 경향이 있음을 보여준다.
3.1 Rating Distribution Alignment (평점 분포 일치)
-
Motivation
- 각 에이전트의 미시적 사용자 행동 일치를 보장하는 것 외에도, 생성 에이전트가 실제 사용자 행동 패턴을 거시적으로 반영해야 한다. 특히, 평점 분포에서 MovieLens-1M 데이터 분포와의 일치를 목표로 한다.
-
Results
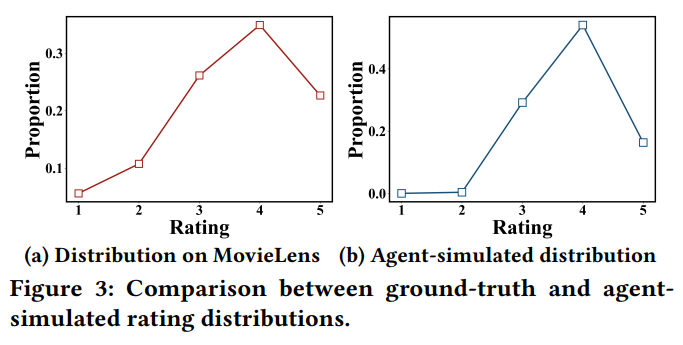
- (a)는 Movielens-1M 데이터셋의 실제 평점 분포를 보여주고, (b)는 에이전트가 생성한 평점 분포를 보여준다.
- 두 분포 간의 강한 일치를 나타내며, 4점 평점이 전체 분포에서 우세하고, 낮은 평점(1-2)은 소수에 불과하다.
- 에이전트는 1-2 평점을 매우 적게 주며, 이는 실제 인간 행동과 다르다. 이는 LLM의 영화에 대한 폭넓은 사전 지식으로 인해 발생하며, 에이전트가 저품질 영화를 피하는 경향이 있다.
3.2 Social Traits Alignment (사회적 특성 일치)
-
Motivation
- 실제 추천 시나리오에서 사용자 행동 패턴은 개인적 선호뿐만 아니라 활동성, 동조성, 다양성과 같은 사회적 속성의 영향을 받는다. 따라서 Agent4Rec의 사용자 프로필에는 이러한 사회적 특성이 포함된다. 활동성, 동조성, 다양성과 같은 사회적 특성은 MovieLens 데이터셋의 통계 정보를 기반으로 높음(high), 중간(medium), 낮음(low)의 세 가지 수준으로 분류한다.
-
Results
- 다양한 측면에서 사용자 프로필 모듈의 설계 중요성을 검증한다.
- 서로 다른 계층에 분류된 에이전트의 행동 차이
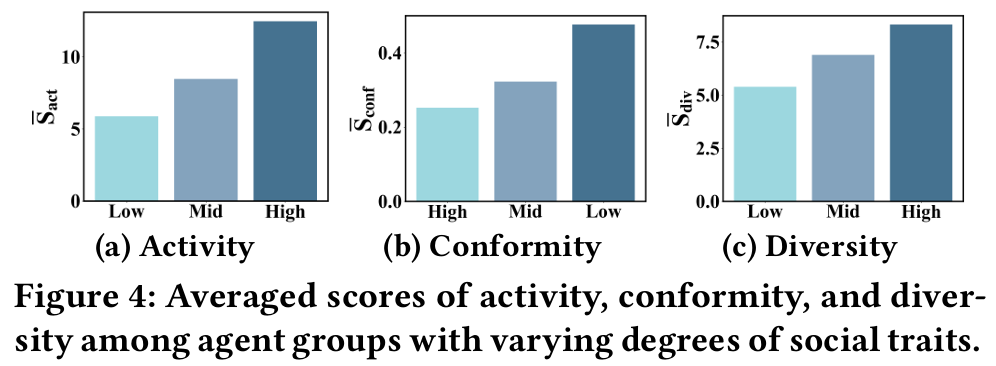
- 사회적 특성이 있는 에이전트와 없는 에이전트 간의 차이
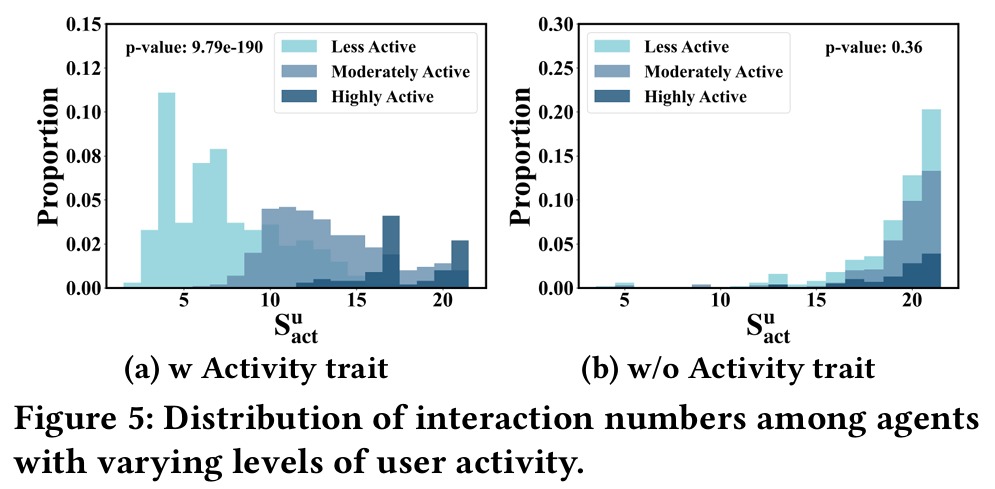
- 에이전트의 특성 분포가 실제 사용자와 일치 여부
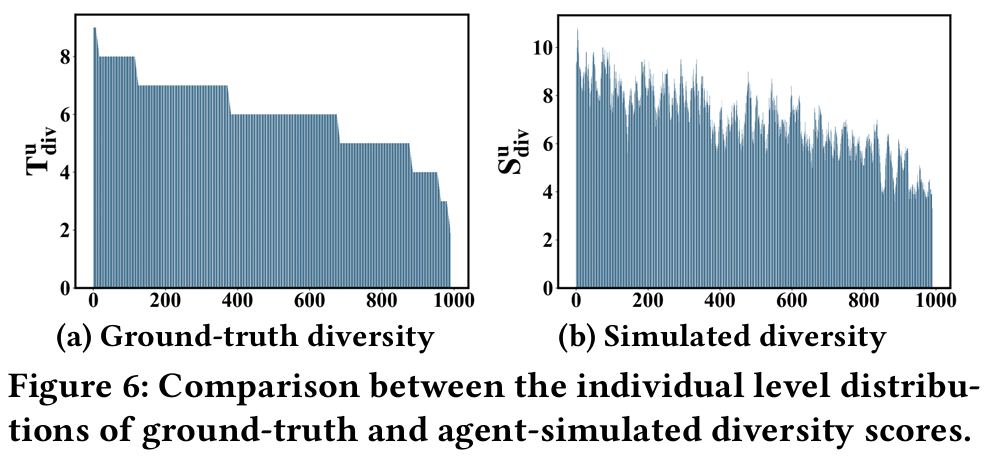
- 실험 결과는 사회적 특성이 사용자 프로필 구성에서 중요한 역할을 하며, 에이전트 행동에 크게 영향을 미친다는 것을 보여준다.
- 다양성 특성은 영화 카테고리의 강한 중복으로 인해 차이가 미미할 수 있으며, 이는 추가 연구가 필요함을 시사한다.
- 다양한 측면에서 사용자 프로필 모듈의 설계 중요성을 검증한다.
3.3 Recommendation Strategy Evaluation (추천 전략 평가)
-
Motivation
- 인간 사용자들은 다양한 추천 알고리즘에 대해 서로 다른 만족도를 보인다. 생성 에이전트가 실제 인간 행동을 정확히 시뮬레이션할 수 있다면, 이들이 보여주는 만족도 경향도 유사할 것이다.
-
Setting
- 협업 필터링 기반 추천 전략(무작위, 인기, MF, LightGCN, MultVAE)을 사용하여 MovieLens에서 만족도 경향을 평가한다.
- 에이전트는 각 추천 페이지에서 4개의 영화를 보고 개인 선호에 따라 행동하며, 최대 5페이지를 탐색한 후 추천 시스템에 대한 만족도를 1에서 10까지 평가한다.
-
Results
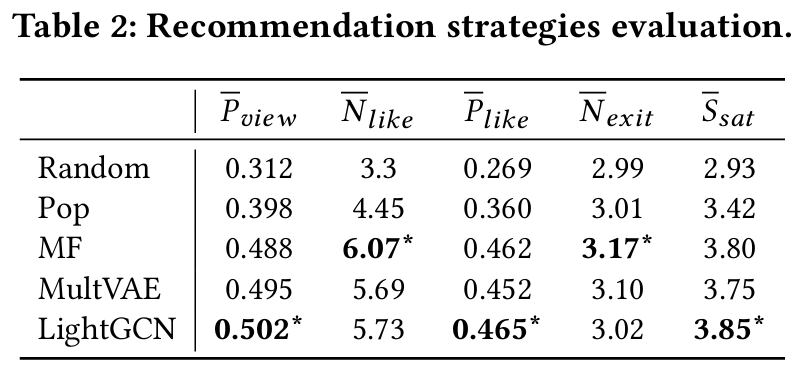
-
: Average Viewing Ratio
: Average Number of Likes
: Average Ratio of Likes
: Average Number of Exit Pages
: Average User Satisfaction Score -
에이전트는 알고리즘 기반 추천에 대해 무작위 및 인기 기반 추천보다 높은 만족도를 보인다.
-
LightGCN이 MF 및 MultVAE보다 다양한 평가 기준에서 우수한 성과를 보이며, 이는 LLM 기반 에이전트의 세밀한 평가 능력을 강조한다.
-
이러한 결과는 에이전트 기반 추천 시뮬레이터가 A/B 테스트에 대한 비용 효율적인 대안을 제공할 가능성을 제시한다.
-
3.4 Page-by-Page Recommendation Enhancement (페이지 단위 추천 개선)
-
Motivation
- 추천 플랫폼은 사용자 행동을 실시간으로 수집하여 추천 시스템을 반복적으로 개선한다. 페이지 단위 추천 설정을 통해 이러한 피드백 기반 추천 개선을 모사하고자 한다.
-
Setting
- 추천 시뮬레이션 후 각 에이전트의 조회 및 미조회 영화를 긍정적인 신호로 활용하여 추천 알고리즘을 재훈련한다. 재훈련된 추천 시스템의 성능을 표준 오프라인 메트릭(Recall@20, NDCG@20)과 만족도 평가로 평가한다.
-
Results
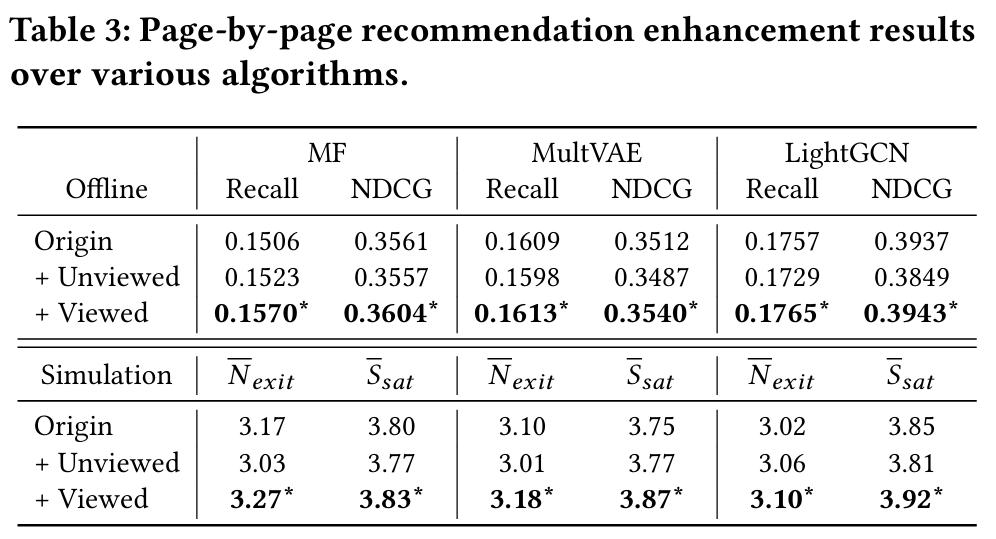
- 에이전트가 조회한 영화를 활용하여 모든 추천 알고리즘이 오프라인 평가 메트릭과 만족도 평가에서 개선됨을 보여준다.
- 그러나 미조회 영화를 추가하면 전반적인 사용자 경험이 저하되는 경향이 있다. 이는 에이전트의 영화 선택이 사용자 선호의 일관된 지표가 될 수 있음을 나타낸다.
3.5 Case Study of Feeling Interview (감정 인터뷰 사례 연구)
-
Motivation
- LLM 기반 에이전트 시뮬레이션의 독특한 강점은 인간이 이해할 수 있는 설명을 제공할 수 있다는 점이다. 에이전트로부터 설명을 이끌어내면 시뮬레이션의 신뢰성을 평가하고 추천 시스템을 개선하는 데 도움이 된다.
-
Results

- 그림 7은 MovieLens에서의 사후 인터뷰 사례를 보여준다. 에이전트는 개인적인 취향, 사회적 특성, 감정 기억에 따라 추천 영화를 평가한다.
- 에이전트는 추천 시스템이 자신의 선호에 맞는 영화를 제안했음을 인식하지만, 만족도를 낮추는 요소도 존재한다고 언급한다. 예를 들어, 다양한 관심사를 가지고 있음에도 불구하고 시스템이 인기 영화를 추천하는 경향이 있다.
4. Insights and Exploration
RQ2 : Agent4Rec이 추천 분야의 해결되지 않은 문제에 대한 통찰을 제공할 수 있는가?
4.1 Filter Bubble Effect (필터 버블 효과)
-
Motivation
- 필터 버블 효과는 추천 시스템에서 널리 퍼진 문제로, 알고리즘 기반 추천자가 사용자 피드백 루프를 기반으로 사용자가 선호할 영화를 예측함으로써 발생한다. 이로 인해 점점 동질적인 추천 콘텐츠가 생성된다. 우리의 주요 목표는 Agent4Rec이 필터 버블 현상을 재현할 수 있는 능력을 평가하는 것이다.
-
Setting
- 공정성을 위해 MovieLens의 영화 풀을 네 개의 동일한 부분으로 나누고, MF 기반 추천자가 네 번의 완전한 시뮬레이션 라운드를 거치도록 한다. 각 라운드에서 추천된 영화는 최대 5페이지에 걸쳐 있으며, 각 시뮬레이션 라운드 후에 MF 기반 추천자가 재훈련된다. 필터 버블 효과는 개별 사용자 수준에서 콘텐츠 다양성을 기반으로 평가한다.
- 두 가지 메트릭이 사용된다.
: 추천 영화 중 가장 많이 추천된 장르의 평균 비율.
: 각 시뮬레이션에서 추천된 장르의 평균 개수.
-
Results
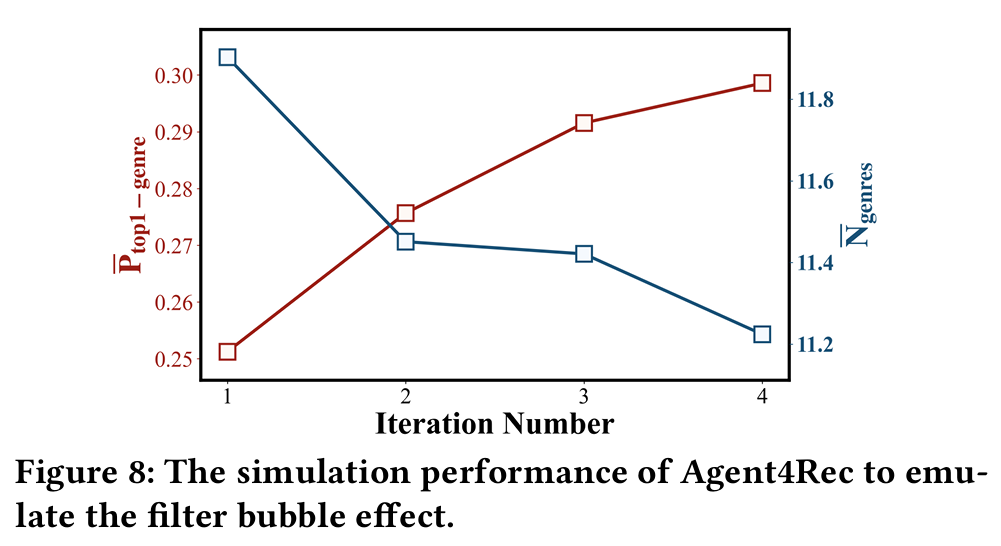
- 위 그래프는 반복 횟수가 증가함에 따라 영화 추천이 더 중앙 집중화되는 경향을 보여준다. 구체적으로, 장르 다양성()은 감소하고, 주 장르의 지배력()은 강화된다. 이 결과는 Agent4Rec이 실제 추천 시스템에서 일반적으로 관찰되는 필터 버블 효과를 반영할 수 있음을 입증한다.
Filter Bubble Effect (필터 버블 효과)
필터 버블 효과는 개인화된 추천 시스템이나 알고리즘이 사용자의 과거 행동, 선호, 검색 기록 등을 기반으로 정보를 제공할 때 발생하는 현상이다. 이 과정에서 사용자는 자신이 선호하는 정보나 콘텐츠만 지속적으로 접하게 되어, 다양한 의견이나 관점을 접할 기회를 잃게 된다.
즉, 사용자가 특정한 정보에만 노출되면서 그 정보의 범위가 좁아지고, 결과적으로 정보의 다양성이 감소하게 된다. 이로 인해 사용자는 자신의 기존 신념이나 의견을 강화하게 되고, 새로운 아이디어나 관점을 수용하기 어려워질 수 있다. 필터 버블 효과는 사회적, 정치적, 문화적 문제와 관련하여 심각한 영향을 미칠 수 있다.
4.2 Discovering Causal Relationships (인과 관계 발견)
-
Motivation
- 인과 발견은 관찰 데이터를 통해 인과 구조(인과 그래프)를 추론하는 것을 목표로 한다. 이 기법은 특정 분야의 기초 메커니즘을 이해하는 데 중요하다. Agent4Rec이 추천 시스템에서 인과 관계를 밝혀내는 데 기여할 수 있는가를 평가한다.
-
Setting
- MovieLens에서 영화 평점에 영향을 미치는 요인을 이해하기 위해 각 영화에 대해 에이전트가 시뮬레이션한 평점 외에 네 가지 주요 변수를 수집한다.
- 주요 변수 : 영화 품질, 인기(영화 프로필에서 수집), 노출 비율, 그리고 영화가 시청된 횟수(시뮬레이터에서 수집).
- 이 시뮬레이션된 데이터 내에서 잠재적 인과 관계를 탐구하기 위해 DirectLiNGAM 알고리즘을 사용한다. 이 알고리즘은 가중치가 있는 유향 비순환 그래프(Directed Acyclic Graph, DAG)를 발견한다.
-
Results
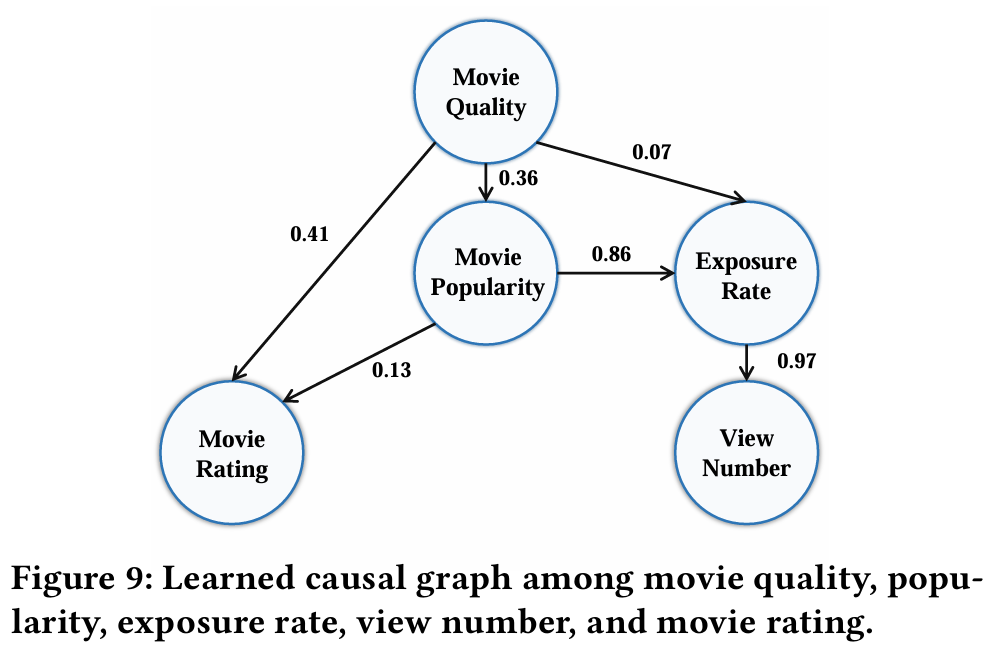
- Movie Rating : 영화 품질과 영화 인기는 영화 평점의 원인이다. 영화 품질이 에이전트 평점에 가장 크게 기여하지만, 영화의 인기 또한 평점에 약간의 영향을 미친다. 이는 실제 상황에서 인간이 인기 있는 영화에 대해 높은 평점을 주는 경향과 일치한다.
- Exposure Rate : 인기 편향을 증폭하는 피드백 루프가 관찰된다. 매우 인기 있는 영화는 더 많은 노출을 받아 에이전트에 의해 더 많이 시청된다. 이러한 인기 아이템이 새로운 훈련 데이터셋에 포함되면, 추천 시스템은 후속 반복에서 이들을 더 많이 노출하는 경향이 있으며, 이는 인기 편향으로 알려져 있다.
DirectLiNGAM 알고리즘
DirectLiNGAM 알고리즘은 인과 관계를 추론하기 위한 방법 중 하나로, 관찰된 데이터를 기반으로 인과 그래프를 구축하는 데 사용된다.
- 선형 시스템 : DirectLiNGAM은 선형 인과 관계를 가정하며, 변수 간의 관계가 선형적으로 나타날 수 있다고 전제한다.
- 비순환 그래프 : 이 알고리즘은 가중치가 있는 유향 비순환 그래프(Directed Acyclic Graph, DAG)를 생성하여 변수 간의 인과 관계를 시각적으로 표현한다.
- 적용 가능성 : DirectLiNGAM은 주로 사회 과학, 생물학, 경제학 등 다양한 분야에서 인과 관계를 분석하는 데 활용된다.
- 효율성 : 이 알고리즘은 데이터의 인과 구조를 발견하는 데 상대적으로 빠르고 효율적으로 작동하며, 다양한 변수 간의 인과 관계를 명확히 이해하는 데 도움을 줍니다.
6. Limitations and Future Work
1. Datasource Constraints (데이터 소스 제약)
- Agent4Rec은 오프라인 데이터셋만을 사용하여 구현되며, 두 가지 주요 요인에 의해 제약을 받는다.
- LLM의 사전 지식 필요성 : LLM은 추천된 아이템에 대한 사전 지식이 필요하기 때문에, ID만 있거나 상세한 아이템 설명이 부족한 대부분의 오프라인 데이터셋은 이 작업에 적합하지 않다.
- 온라인 데이터 : 온라인 데이터는 시뮬레이터와 자연스럽게 일치하여 효과성을 평가하는 데 편향 없는 관점을 제공하지만, 이러한 데이터를 획득하는 것은 상당한 도전 과제이다.
2. Limited Action Space (제한된 행동 공간)
- 현재 Agent4Rec의 행동 공간은 제한적이며, 사용자 결정에 영향을 미치는 중요한 요소(e.g. 소셜 네트워크, 광고, 입소문 마케팅 등)를 생략하고 있다.
- 간소화의 장단점 : 이러한 단순화는 간단한 시나리오에서 LLM 기반 에이전트의 신뢰할 수 있는 평가를 촉진하지만, 실제 사용자 의사 결정 과정에서의 격차를 초래한다.
- 미래 방향 : 향후 작업의 주요 방향은 사용자 행동의 다면적 특성을 더 잘 포착하기 위해 영향력 있는 요인의 범위를 넓혀, 시뮬레이션이 추천 시나리오를 보다 보편적으로 대표할 수 있도록 하는 것이다.
3. Hallucination in LLM (LLM의 환각)
- 시뮬레이션에서 간헐적인 환각 현상이 관찰되었다. 예를 들어, LLM이 부정적인 평점을 주는 인간 사용자를 정확하게 시뮬레이션하지 못하거나, 존재하지 않는 아이템을 만들어내고 이를 평가하거나, 요구된 출력 형식을 준수하지 않는 경우가 있다.
- 결과적 영향 : 이러한 불일치는 부정확한 시뮬레이션 결과로 이어질 수 있다.
- 미래 목표 : 이러한 관찰을 고려하여, 추천 시나리오에서 사용자 행동을 시뮬레이션하기 위해 특별히 LLM을 미세 조정하여 시뮬레이터의 안정성과 정확성을 향상시키는 것이 향후 목표이다.
