📄 Paper
Large Language Models as Zero-Shot Conversational Recommenders [arxiv]
Zhankui He ACM CIKM 23
📝 Key Point
-
zero-shot 대화 추천 시스템 : LLMs을 zero-shot CRS로 활용하여 기존의 fine-tuning된 CRS 모델을 초월하는 성과를 보였다.
-
repetition shortcut 문제 : 기존 CRS 평가에서 반복 아이템을 강조하는 평가 방식의 문제를 지적하고, 신뢰성 있는 모델 설계를 위한 기준 마련의 필요성을 제기했다.
-
새로운 데이터셋 : Reddit-Movie라는 새로 구축한 데이터셋이 CRS 연구에 다양성과 현실성을 제공하였다.
-
LLM의 Content/Context 지식 : LLM이 fine-tuning 없이도 우수한 Content/Context 지식을 바탕으로 CRS 작업에 효과적임을 입증하였다.
Abstract
LLM을 사용한 zero-shot 대화 추천 작업을 제안한다.
- 데이터
- 인기 있는 토론 웹사이트에서 추천 관련 대화 데이터를 수집하였다.
- 이는 현재까지 가장 큰 공개 실제 대화 추천 데이터셋이다.
- 평가
- 새로운 데이터셋과 기존 두 개의 대화 추천 데이터셋에서 실험을 수행하였다.
- LLM이 fine-tuning 없이도 기존 fine-tuning된 대화 추천 모델보다 뛰어난 성능을 보였다.
- 분석
- LLM의 대화 추천 성능을 설명하기 위한 다양한 probing 작업을 제안한다.
- LLM의 행동과 데이터셋의 특성을 분석하여 모델의 효과성 및 한계에 대한 포괄적인 이해를 제공한다.
- 향후 대화 추천 시스템 설계 방향을 제안한다.
Figure
-
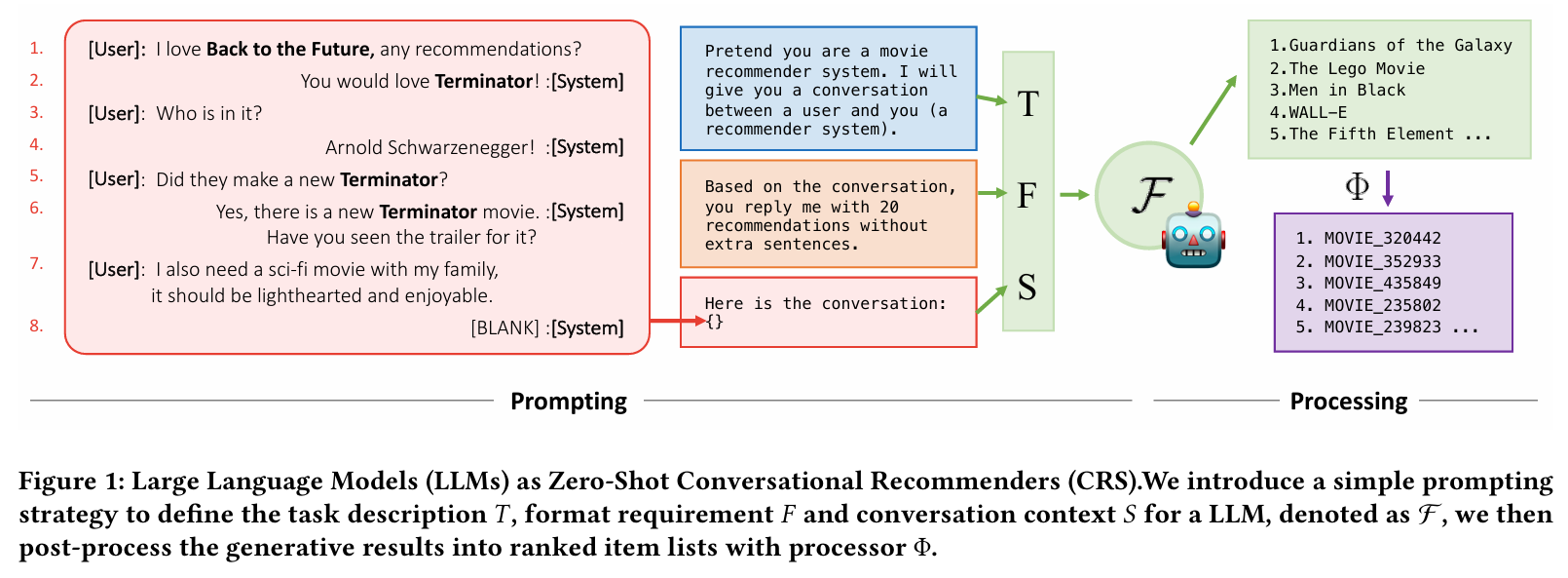
LLM을 zero-shot 대화 추천 시스템으로 활용하는 방법을 제시한다.
-
프롬프트 전략
- : 작업 설명 , : 형식 요구사항 , : 대화 맥락 , : LLM , : processor
- 작업 설명, 형식 요구사항, 대화 맥락을 조합하여 LLM에 입력하고, 생성된 추천 결과를 후처리하여 순위가 매겨진 아이템 리스트로 변환한다.
1. Introduction
-
대화 추천 시스템(CRS)의 목적
- CRS는 사용자 선호를 파악하고 개인화된 추천을 제공하기 위해 대화형 상호작용을 활용한다.
- CRS는 사용자 행동을 이해하고 인간 같은 응답을 제공할 수 있는 장점이 있다.
-
구성 요소
- CRS는 자연어 응답을 생성하는 생성기와 아이템 순위를 매기는 추천기로 구성된다.
-
대형 언어 모델의 발전
- 최근 LLM의 발전이 주목받고 있으며, CRS에서의 활용 가능성이 탐구되고 있다.
- 현재 연구는 주로 전통적인 추천 설정에서 LLM의 성능을 평가하고 있다.
-
연구 기여
- 데이터 : Reddit-Movie라는 대규모 대화 추천 데이터셋을 구축하였으며, 이는 634,000개 이상의 대화를 포함한다.
- 평가 : LLM의 추천 성능을 재평가하여 기존 평가의 문제점을 지적하였다.
- 분석 : LLM의 성능 원인을 탐구하고, 프로빙 작업을 통해 한계를 분석하였다.
-
주요 발견
- 반복 아이템 제거 후 CRS 능력을 재평가해야 한다.
- LLM은 기존 모델보다 향상된 성능을 보인다.
- LLM은 주로 Content/Context 지식을 활용하여 추천을 한다.
- CRS 데이터셋은 LLM에 더 적합하다.
- LLM은 인기 편향 및 지리적 민감성과 같은 한계가 있다.
2. LLMS AS ZERO-SHOT CRS
2.1 Task Formation
-
대화 표현
- 사용자 집합 , 아이템 집합 , 어휘 가 주어질 때, 대화는 로 표현된다.
- 번째 대화 턴에서, 발화자 가 발화 를 생성하며, 이는 어휘 의 단어 시퀀스이다.
- 발화 는 언급된 아이템 집합 를 포함하며, 아이템이 언급되지 않을 경우 빈 집합이 될 수 있다.
-
대화자 역할
- 일반적으로 대화 에는 두 사용자가 있으며, 각각 탐색자와 추천자의 역할을 수행한다.
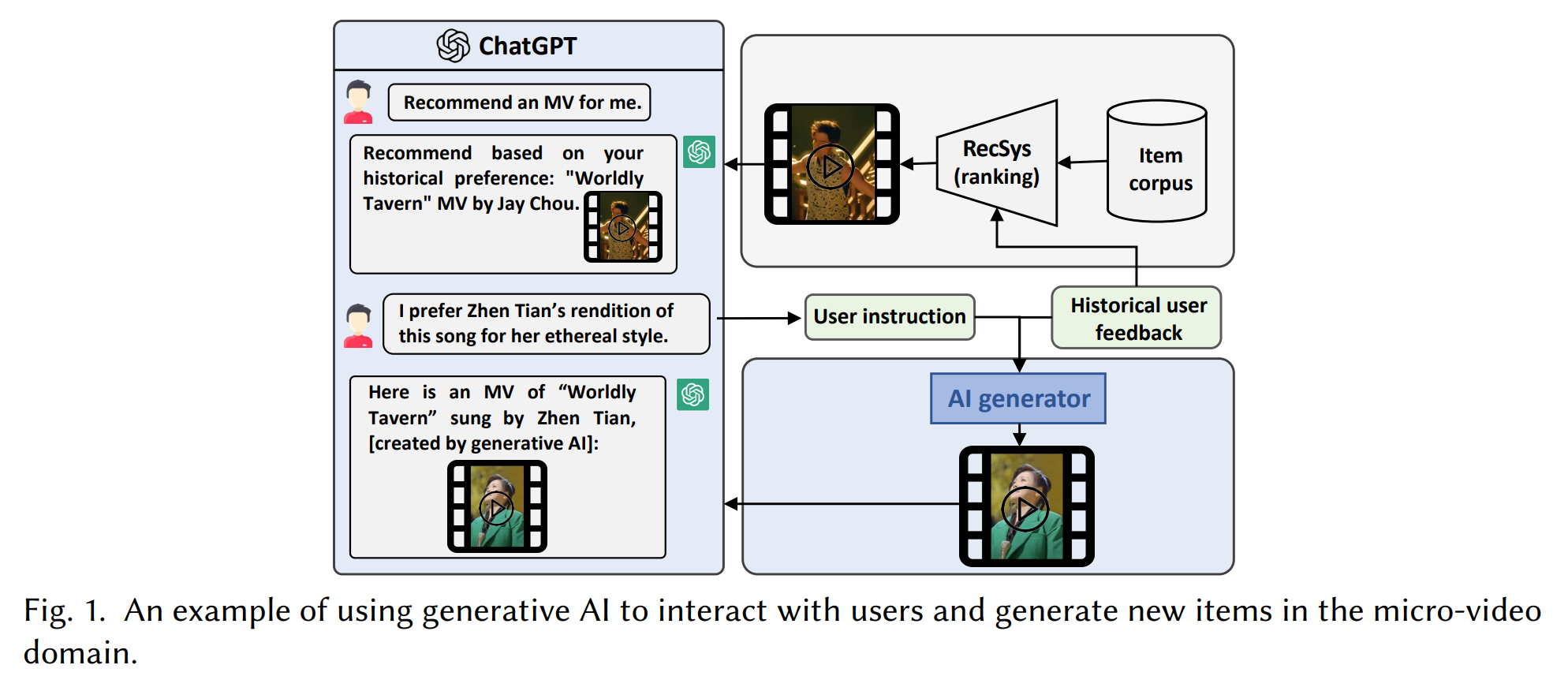
- ex) Figure 1의 두 번째 대화 턴에서 , 는 [System], 는 "You would love Terminator!"이며, 는 영화 Terminator를 포함하는 집합이다.
-
추천 목표
- CRS의 추천자 구성 요소는 다음 목표를 최적화하도록 설계된다.
- 번째 대화 턴에서, 추천자 는 대화 맥락 을 입력으로 받아, 의 실제 아이템과 가장 잘 일치하는 순위가 매겨진 아이템 목록 를 생성한다.
2.2 Framework
-
프롬프트 설정
- LLM을 zero-shot 대화 recommender로 활용하는 것이 목표이다.
- fine-tuning 없이 작업 설명 템플릿 , 형식 요구사항 , 대화 맥락 를 사용하여 LLM을 프롬프트한다.
-
모델
-
zero-shot 프롬프트 능력을 가진 여러 인기 LLM을 두 그룹으로 나누어 고려한다.
-
사전 훈련된 모델
- GPT-3.5-turbo / GPT-4 : 복잡한 작업을 해결하는 능력이 있지만 소스가 비공개이다.
-
오픈 소스 모델
- BAIZE / Vicuna : LLAMA-13B 기반으로 fine-tuning된 대표적인 오픈 소스 LLM이다.
-
-
processing
- LLM의 모델 가중치나 출력 로짓을 평가하지 않으며, 후처리기 (e.g. fuzzy matching)를 적용하여 자연어로 된 추천 목록을 순위가 매겨진 아이템 ID 목록 로 변환한다.
- 아이템 ID 대신 아이템 제목을 생성하는 방식은 생성적 검색(generative retrieval) 패러다임으로 불린다.
3. DATASET
필요성
- 대화 추천 모델의 평가를 위해서는 다양한 상호작용과 실제 대화를 포함하는 대규모 데이터셋이 필요하다.
- 기존의 크라우드 소싱 데이터셋은 현실적인 대화 역동성을 충분히 반영하지 못한다.
크라우드 소싱 (crowd-sourced)
특정 작업이나 프로젝트를 수행하기 위해 대중의 지식, 기술, 자원 등을 활용하는 방법
- 참여자 : 다양한 사람들이 특정 작업을 수행하기 위해 고용되거나 자발적으로 참여한다.
- 제한된 현실성 : 크라우드 작업자는 특정한 선호나 관심이 없을 수 있어, 그들의 응답이 실제 사용자 대화와 다를 수 있다.
- 예시 데이터셋 : 논문에서는 ReDIAL과 INSPIRED와 같은 기존의 크라우드 소싱 데이터셋을 언급하며, 이러한 데이터셋이 크라우드 소싱의 한 예로 제시된다.
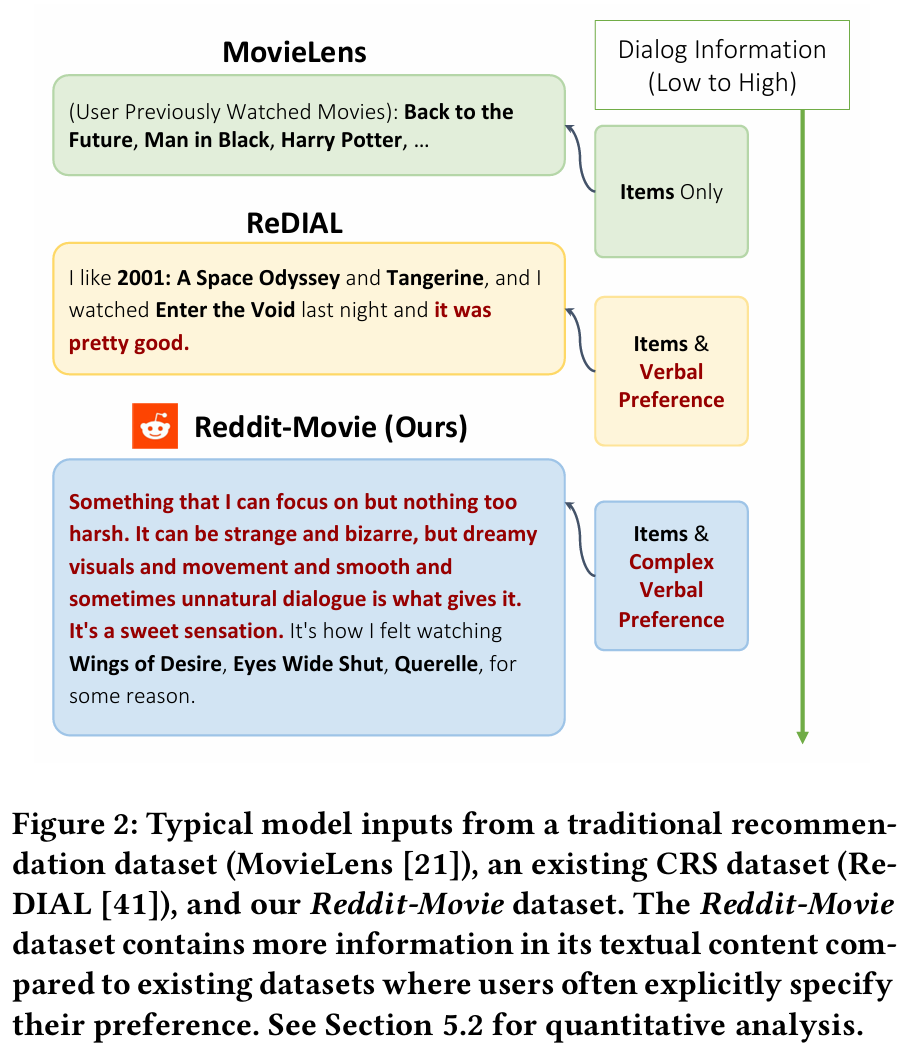
Reddit-Movie 데이터셋
- Reddit-Movie는 현재까지 가장 큰 대화 영화 추천 데이터셋으로, 자연 발생적인 영화 추천 대화를 포함한다.
- 본 연구에서는 ReDIAL과 INSPIRED 데이터셋과 함께 Reddit 데이터셋을 사용하여 모델 평가를 수행한다.
데이터셋 구축
- 2012년 1월부터 2022년 12월까지의 Reddit 게시물에서 영화 추천 관련 게시물을 추출하여 데이터셋을 구축하였다.
- 최신 9,000개의 대화를 테스트 세트로 사용하고, 나머지 76,000개의 대화는 훈련 및 검증에 활용한다.
논의
- Reddit-Movie 데이터셋은 634,392개의 대화를 포함하며, 51,203개의 영화를 다룬다.
- ReDIAL과 INSPIRED에 비해 multi-turn 대화가 적지만, 더 복잡하고 상세한 사용자 선호를 포함하여 다양하고 풍부한 논의를 제공한다.
4. EVALUATION
4.1 Evaluation Setup
-
반복 아이템 vs. 새로운 아이템
- 대화에서 추천된 실제 아이템을 식별하는 것은 도전적인 주제이다. 일반적인 평가 설정에서는 모든 아이템이 실제 추천 아이템으로 간주된다.
- 본 연구에서는 아이템을 반복 아이템과 새로운 아이템으로 구분한다. 반복 아이템은 이전 대화 턴에 등장한 아이템이고, 새로운 아이템은 이전 턴에서 언급되지 않은 아이템이다.
-
평가 프로토콜
- ReDIAL, INSPIRED, Reddit 데이터셋에서 여러 대표적인 CRS 모델과 LLM의 추천 능력을 평가한다. 기준 모델은 Recall@K를 사용하여 예측 성능을 보고한다.
-
비교 모델
- ReDIAL : ReDIAL 데이터셋과 함께 출시된 모델로, 오토인코더 기반의 추천 시스템이다.
- KBRD : DBPedia를 활용하여 아이템이나 엔티티의 의미적 지식을 강화하는 모델이다.
- KGSF : 두 개의 지식 그래프를 통합하여 단어와 엔티티의 표현을 향상시키는 모델이다. 상호 정보 최대화(Mutual Information Maximization) 방법을 사용하여 두 지식 그래프의 의미 공간을 정렬한다.
- UniCRS : 사전 학습된 언어 모델인 DialoGPT를 사용하여 추천 및 대화 생성 작업을 수행하는 모델이다. 프롬프트 튜닝을 통해 대화의 맥락을 이해하고, 추천 품질을 개선한다.
4.2 Repeated Items Can Be Shortcuts
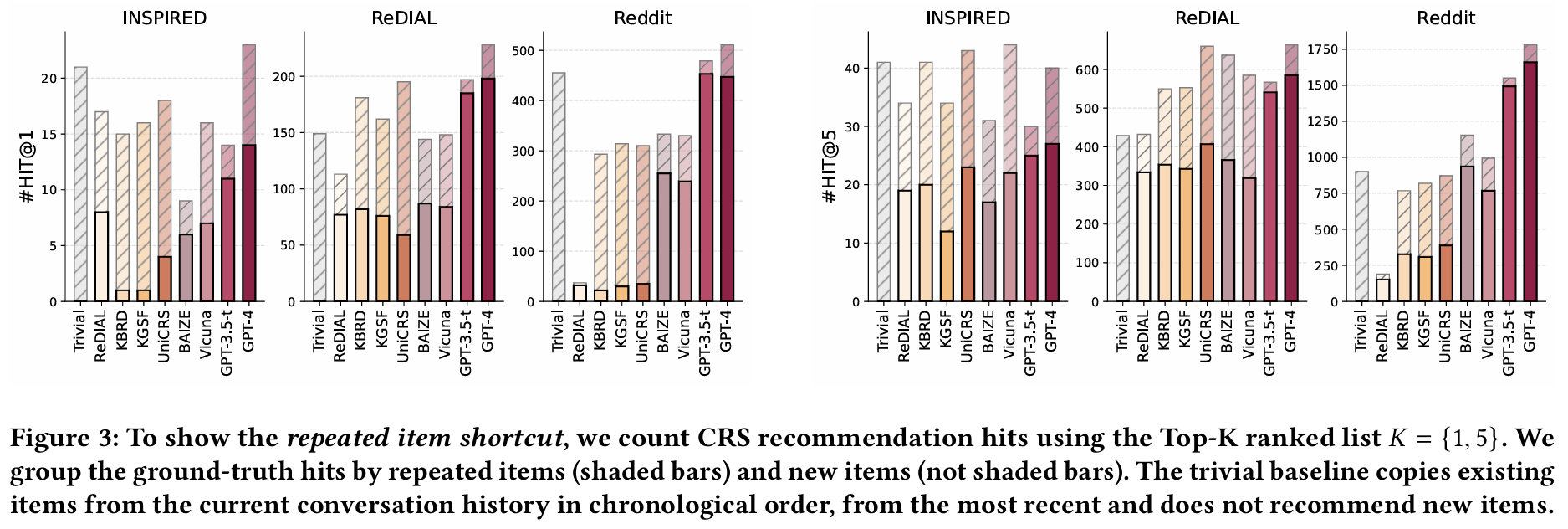
- 현재 대화 추천 시스템에 대한 평가는 반복 아이템과 새로운 아이템을 구분하지 않는다. 이로 인해 반복 아이템을 언급하는 시스템이 유리하게 평가된다. 예를 들어, 대화 이력에서 본 아이템을 항상 복사하는 단순 기준 모델이 대부분의 이전 모델보다 더 나은 성능을 보인다.
- 새로운 아이템 추천에만 집중할 경우, 모델의 HIT@1 성능이 평균 60% 이상 감소한다. 반복 아이템의 비율이 높은 경우(예: INSPIRED의 15% 이상)를 고려할 때, 반복 아이템을 제거하고 CRS 모델을 재평가하는 것이 추천 능력을 더 잘 이해하는 데 유리하다.
4.3 LLMs Performance
-
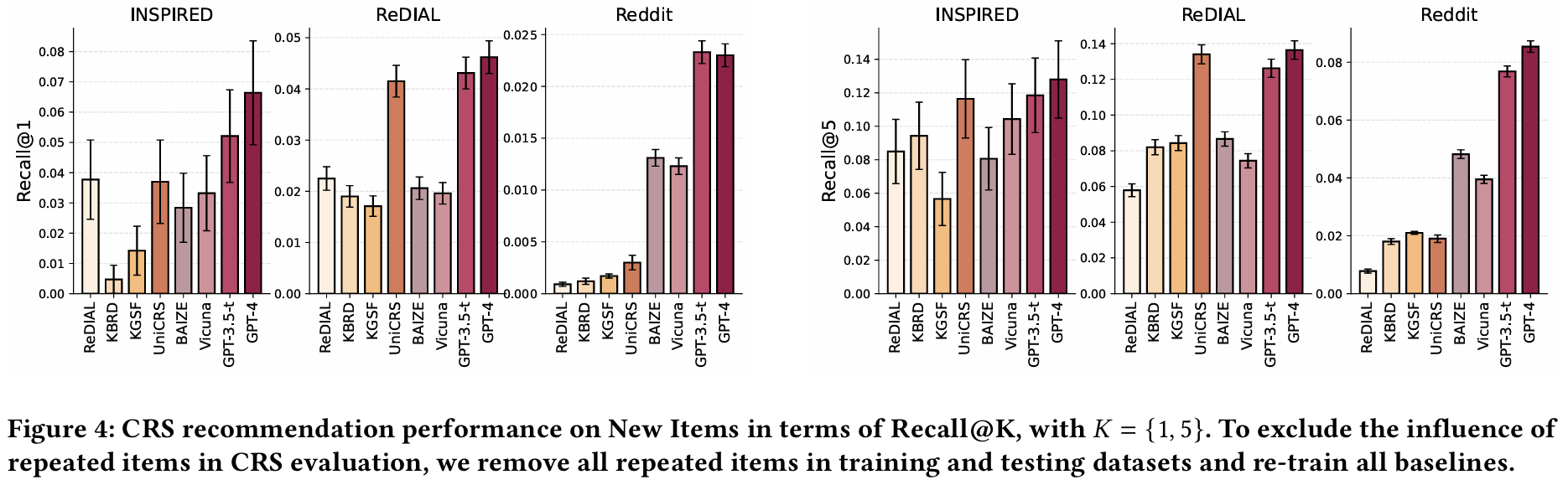
발견 1 : LLM은 zero-shot 설정에서 fine-tuning된 CRS 모델보다 우수한 성능을 보인다. 새로운 아이템 추천을 위해 기존 CRS 모델을 재훈련한 결과, LLM이 모든 데이터셋에서 가장 좋은 성능을 보인다.
-
발견 2 : GPT 기반 모델이 다른 오픈 소스 LLM보다 뛰어난 성능을 나타낸다. GPT-4가 GPT-3.5-t보다 일반적으로 더 좋은 성능을 보이며, 이는 더 큰 파라미터 크기가 영화 이름과 사용자 선호 간의 상관관계를 더 잘 유지할 수 있게 해주기 때문이다.
-
발견 3 : LLM은 허용된 아이템 세트 외의 아이템을 생성할 수 있으며, 이러한 아이템을 제거하면 추천 성능이 향상된다. GPT 기반 모델의 약 95%의 추천은 IMDB에서 일치하는 것으로 확인되고, 환각된 추천이 거의 없었다.
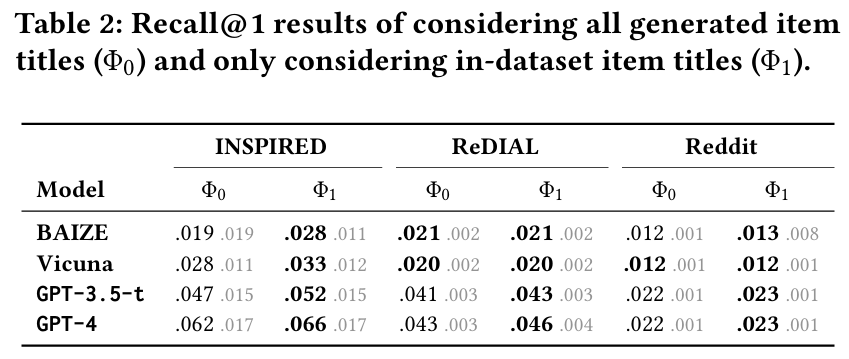 : 생성된 모든 아이템 제목
: 생성된 모든 아이템 제목
: 데이터셋에 있는 아이템 제목만 선별 (환각 추천 아이템 제외)

5. DETAILED ANALYSIS
5.1 Knowledge in LLMs
-
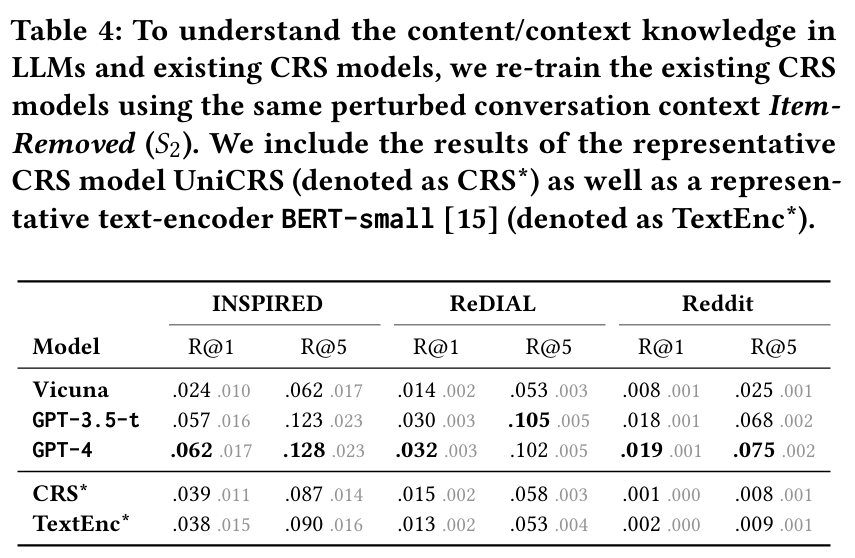
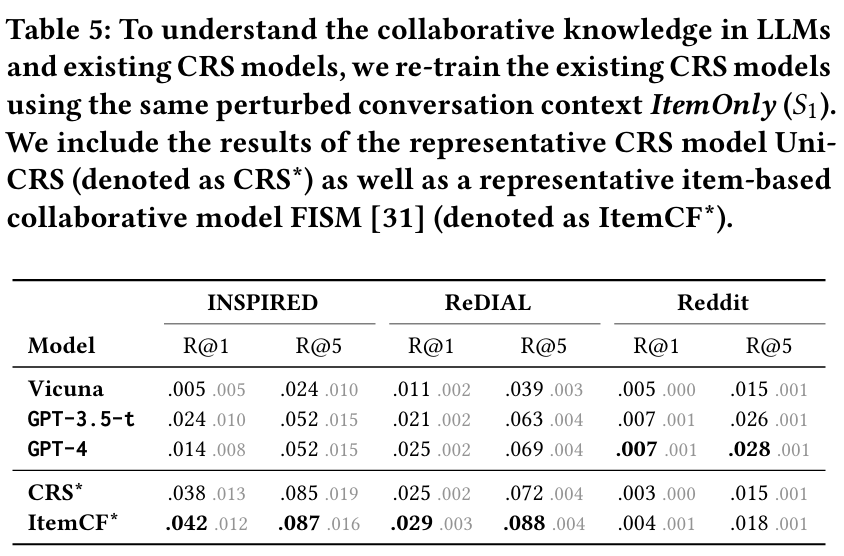
실험 설정 : LLM이 CRS에서 사용할 수 있는 두 가지 지식 유형을 정의하고 실험을 통해 이들의 효과를 분석한다.
- Collaborative 지식 : 사용자가 선호하는 아이템 간의 유사성을 기반으로 추천하는 능력이다. "A를 좋아하는 사용자는 B도 좋아할 가능성이 높다"는 원칙에 따라 추천한다.
- Content/Context 지식 : 추천된 아이템의 콘텐츠나 대화 맥락 정보를 기반으로 추천하는 능력이다. 이는 대화에서 언급된 장르, 감독 이름, 그리고 대화의 다른 내용들을 포함한다.
-
발견 4 : LLM은 주로 Content/Context 지식을 활용하여 추천하며, 반복 아이템만 사용하는 경우 성능이 평균 60% 이상 감소한다. 반면, 아이템을 제거하거나 랜덤 샘플링으로 대체할 경우 성능 감소는 10% 미만이다. 이는 LLM이 대화의 내용과 맥락 정보를 더 중요하게 사용하고 있음을 나타낸다.
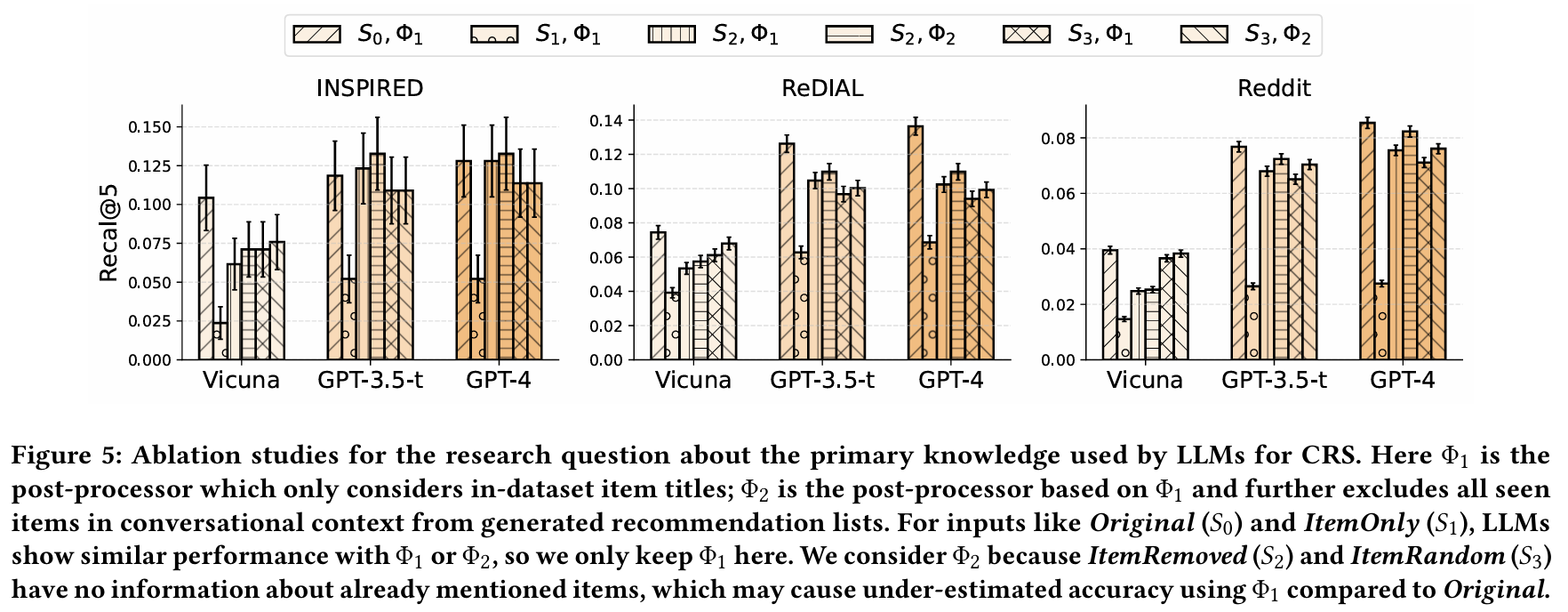
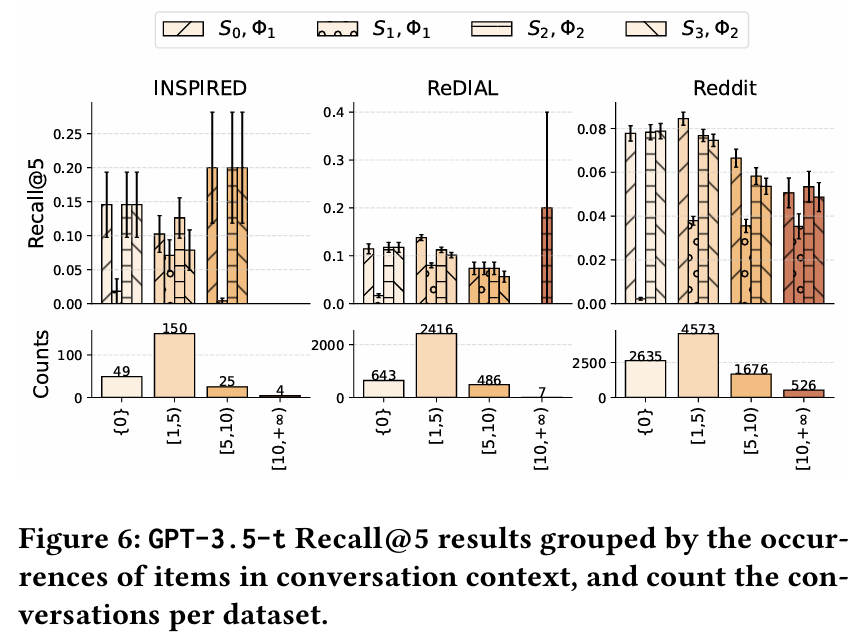
-
발견 5 : GPT 기반 LLM이 기존의 대화 추천 모델보다 더 나은 Content/Context 지식을 보여준다. 모든 데이터셋에서 GPT 기반 LLM이 사용자 선호를 이해하고 정확한 아이템 제목을 생성하는 데 뛰어난 성능을 보인다. 이로 인해 ItemRemoved 설정에서도 기존 CRS 모델보다 더 정확한 추천을 제공한다.
-
발견 6 : LLM의 Collaborative 지식은 기존 CRS 모델에 비해 약하다. ItemOnly 설정에서 LLM은 ReDIAL 및 INSPIRED 데이터셋에서 30% 이상 성능이 떨어진다. 이는 LLM이 일반적인 데이터셋에서 훈련되었기 때문에 특정 데이터셋의 상호작용 패턴과 일치하지 않을 수 있음을 시사한다. 그러나 Reddit 데이터셋에서는 LLM이 기준 모델을 초과하는 성능을 나타내며, 이는 데이터셋의 특성과 관련이 깊다.
5.2 Information from CRS Data
-
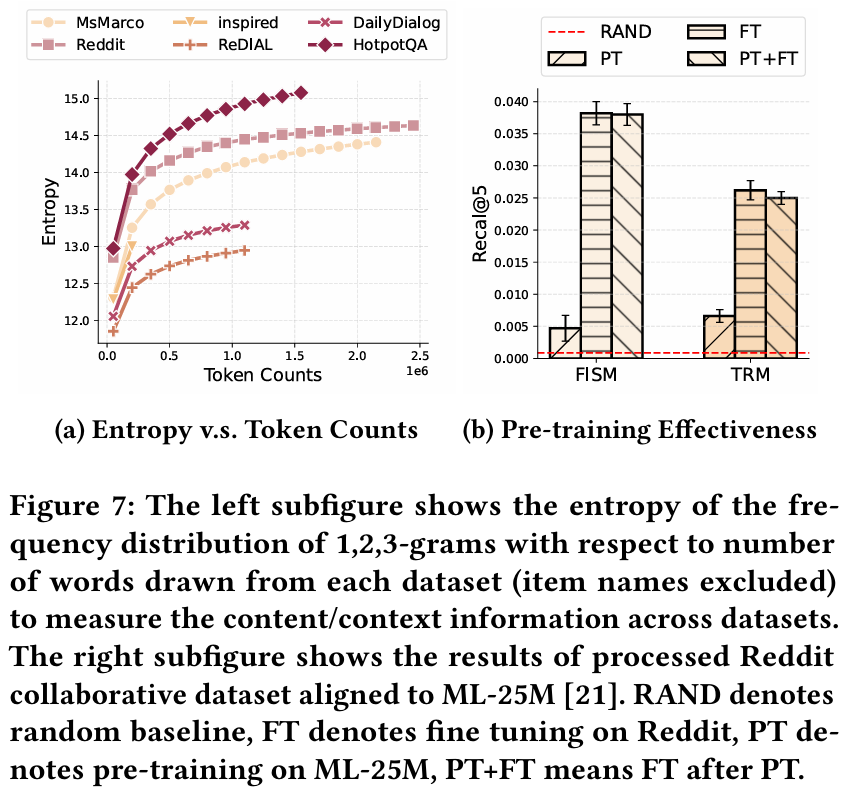
발견 7 : Reddit 데이터셋은 다른 두 CRS 데이터셋보다 더 많은 Content/Context 정보를 포함하고 있다. 이는 LLM이 Reddit 데이터셋에서 더 높은 성능을 보이는 이유로 작용한다.
-
발견 8 : 현재 모델로는 Collaborative 정보만으로 만족스러운 추천을 제공하기 어렵다는 점이 드러난다. ItemOnly 설정에서의 성능이 Original 설정과 비교하여 큰 차이를 보이며, 이는 Collaborative 정보의 한계점을 나타낸다. 기존 모델들이 Collaborative 정보만으로는 추천의 품질을 보장할 수 없음을 보여준다.
-
발견 9 : Collaborative 정보는 데이터셋이나 플랫폼에 따라 달라질 수 있으며, 동일한 아이템이더라도 특정 데이터셋에서의 성능 차이가 존재한다. 이는 LLM이 특정 데이터셋에서 Collaborative 정보를 잘 활용하지 못할 수 있음을 시사한다.
5.3 Limitations of LLMs as Zero-shot CRS
-
발견 10 : LLM 추천은 인기 아이템에 편향되는 경향이 있다. 예를 들어, ReDIAL 데이터셋에서 "Avengers: Infinity War"와 같은 인기 영화는 실제 데이터셋에서의 비율보다 LLM 추천에서 더 자주 등장한다. 이는 LLM이 훈련 과정에서 학습한 데이터의 편향을 반영할 수 있다.
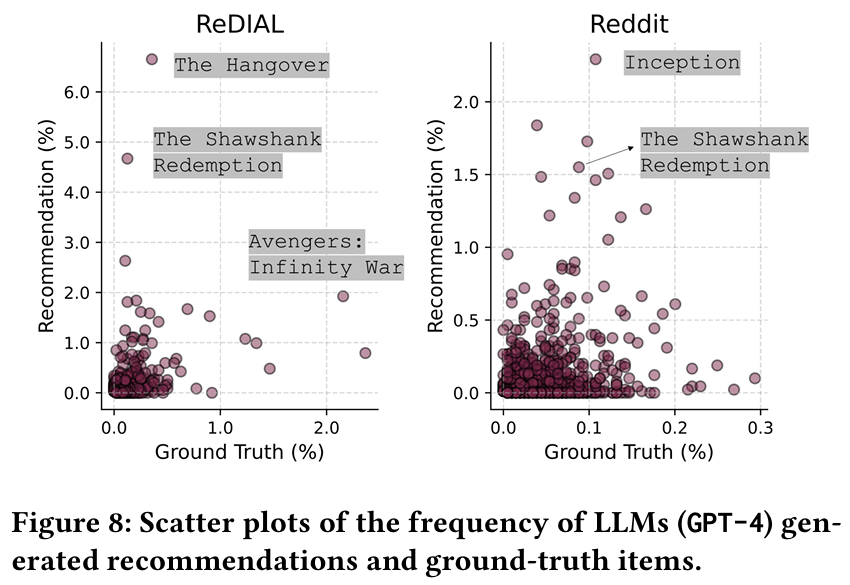
-
발견 11 : LLM의 추천 성능은 지역에 따라 민감하게 변한다. 영어권 영화에 대한 추천 성능이 더 높으며, 이는 훈련 데이터의 편향 때문일 수 있다. LLM이 특정 문화나 지역에 대한 추천에서 효과적이지 않을 수 있으며, 이는 다양한 문화와 지역에 대한 분석과 평가의 필요성을 강조한다.
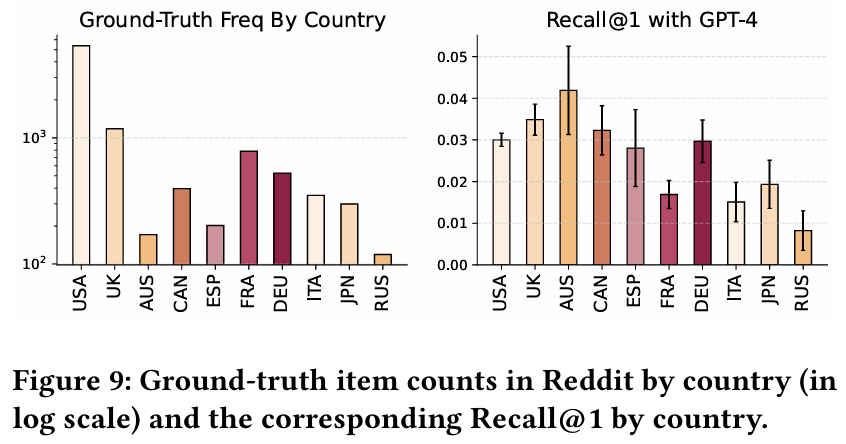
7. CONCLUSION AND DISCUSSION
-
연구 목적 : LLM을 zero-shot 대화 추천 시스템(CRS)으로 연구하고, 이전 CRS 평가에서의 repetition shortcut 문제를 다루었다.
-
주요 발견 : LLM은 모든 fine-tuning된 기존 CRS 모델을 초월하는 성과를 보였으며, LLM의 작동 메커니즘과 CRS 작업의 특성을 분석하였다.
-
데이터셋 : 두 개의 공개 데이터셋과 새롭게 생성한 영화 추천 데이터셋을 사용하여, CRS 연구에 더 다양하고 현실적인 대화를 제공하였다.
-
LLM의 잠재력 : LLM은 fine-tuning 없이도 뛰어난 성능을 보이며, CRS 작업에 효과적이다. 오픈 소스 LLM의 성과는 CRS 성능 향상을 위한 튜닝 및 Collaborative Filtering의 가능성을 제시한다.
-
CRS 재평가 필요성 : CRS 모델의 체계적인 재평가와 다양한 출처에서의 새로운 데이터셋 구축이 필요하다. LLM의 Content/Context 지식의 중요성을 강조하며, CRS 작업과 전통적인 추천 시스템 간의 상호 연결성을 탐구할 필요성을 제안한다.
Related Work
Conversational Recommendation
대화형 추천 시스템은 대화를 통해 사용자 선호도를 이해하고 개인화된 추천을 제공하는 것을 목표로 한다.
1. 전통적인 CRS
1-1. Template-based CRS
템플릿 기반 CRS는 미리 정의된 템플릿을 사용하여 사용자와의 대화를 통해 추천을 제공한다. 고정된 구조의 대화 패턴을 기반으로 작동하며, 사용자의 요구에 맞춘 추천을 제공하기 위해 템플릿을 활용한다.
- 정형화된 대화 흐름 : 템플릿을 사용하여 대화의 흐름을 정형화하고, 사용자가 특정 질문이나 요청을 할 때 일관된 방식으로 응답한다.
- 사전 정의된 질문 및 응답 : 추천 시스템은 특정 상황에 맞는 질문과 응답을 미리 정의하여 사용자의 입력에 따라 적절한 템플릿을 선택하여 대화를 진행한다.
- 제한된 유연성 : 템플릿 기반 시스템은 유연성이 떨어질 수 있으며, 사용자의 다양한 요청에 완벽하게 대응하지 못할 수 있다.
- 쉬운 구현 : 비교적 간단하게 구현할 수 있으며, 특정 도메인에 맞춰 빠르게 설정할 수 있다.
1-2. Critiquing-based CRS
비평 기반 CRS는 사용자와의 상호작용을 통해 개인화된 추천을 제공한다. 사용자가 제공하는 피드백이나 비판을 기반으로 추천 결과를 조정하고 개선하는 방식으로 작동한다.
- 사용자 피드백 : 사용자가 추천된 항목에 대해 긍정적 또는 부정적인 피드백을 제공할 수 있으며, 이 피드백은 향후 추천에 반영된다.
- 대화형 상호작용 : 사용자는 시스템과 대화를 통해 자신의 선호도를 명확히 하고, 특정 항목에 대한 선호도를 표현할 수 있다.
- 추천 조정 : 사용자의 비판이나 의견에 따라 추천 알고리즘이 조정되어 더 나은 개인화된 추천을 제공하게 된다.
- 적응성 : 시스템은 지속적으로 사용자의 피드백을 학습하여 시간이 지남에 따라 추천 품질을 향상시킨다.
2. Deep CRS
Deep CRS는 딥러닝 기술을 활용하여 사용자와의 대화를 통해 개인화된 추천을 제공한다. 자연어 처리와 심층 신경망을 활용하여 사용자와의 상호작용을 보다 효율적으로 처리하고, 복잡한 패턴을 학습하여 추천 품질을 향상시킨다.
- 딥러닝 기반 모델 : 딥러닝 아키텍처(ex. RNN, LSTM, Transformer 등)를 사용하여 대화의 맥락을 이해하고, 사용자 선호를 모델링한다.
- 자연어 처리 : 자연어 이해(NLU)와 자연어 생성(NLG) 기술을 통해 사용자와의 대화를 자연스럽고 효과적으로 진행한다.
- 상황 인식 : 사용자의 요청이나 질문을 이해하고, 그에 맞춰 적절한 추천을 제공하기 위해 대화의 맥락을 파악한다.
- 개인화된 추천 : 사용자 데이터와 대화의 내용을 바탕으로 개인화된 추천을 제공하며, 사용자 피드백을 통해 지속적으로 학습하고 개선할 수 있다.
- 다양한 작업 수행 : 질문 응답, 정보 검색, 아이템 추천 등 다양한 작업을 수행할 수 있는 능력을 갖추고 있다.
3. Additional Information을 활용한 CRS
Additional Information을 활용한 CRS는 협업 필터링(CF) 외의 다양한 정보를 활용하여 추천 성능을 향상시킨다.
3-1. Knowledge-enhanced Models
외부 지식 기반(ex. 위키피디아, 도메인 특정 데이터베이스 등)을 활용하여 추천 품질을 향상시킨다.
- 사용자의 요청사항이나 아이템에 대한 추가적인 배경 지식을 제공하여 보다 정확한 추천을 가능하게 한다.
- 예를 들어, 특정 영화에 대한 정보(장르, 감독, 출연 배우 등)를 활용하여 사용자의 관심사에 맞는 영화를 추천할 수 있다.
3-2. Review-aware Models
사용자 리뷰와 평점을 고려하여 추천을 제공한다.
- 리뷰의 감정 분석이나 키워드 추출을 통해 사용자 선호도를 파악하고, 이를 추천 알고리즘에 통합한다.
- 예를 들어, 긍정적인 리뷰가 많은 아이템이나 특정 키워드가 자주 언급되는 아이템을 우선적으로 추천할 수 있다.
3-3. Session/Sequence-based Models
사용자의 세션 정보나 이전 상호작용의 순서를 고려하여 추천을 제공한다.
- 사용자의 행동 패턴을 분석하여 다음에 어떤 아이템을 추천할지 결정한다.
- 예를 들어, 사용자가 특정 카테고리의 아이템을 연속적으로 조회하는 경우, 그와 관련된 아이템을 추천할 수 있다.
4. LLM 기반 CRS
4-1. UniCRS
Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning (2022)
UniCRS 모델은 대화형 추천 시스템을 위한 통합 모델로, 추천과 대화의 두 가지 작업을 하나의 접근 방식으로 통합하여 처리한다. 이 모델은 지식 강화 프롬프트 학습(Knowledge-Enhanced Prompt Learning)을 기반으로 하여, 사전 학습된 언어 모델(PLM)인 DialoGPT를 활용하여 두 작업을 효과적으로 수행할 수 있도록 설계되었다.
UniCRS 모델은 대화형 추천 시스템의 효율성을 높이고, 다양한 작업을 통합한다. 이 모델은 대화와 추천의 경계를 허물고 새로운 형태의 서비스 제공을 위한 기초를 마련하고 있다.
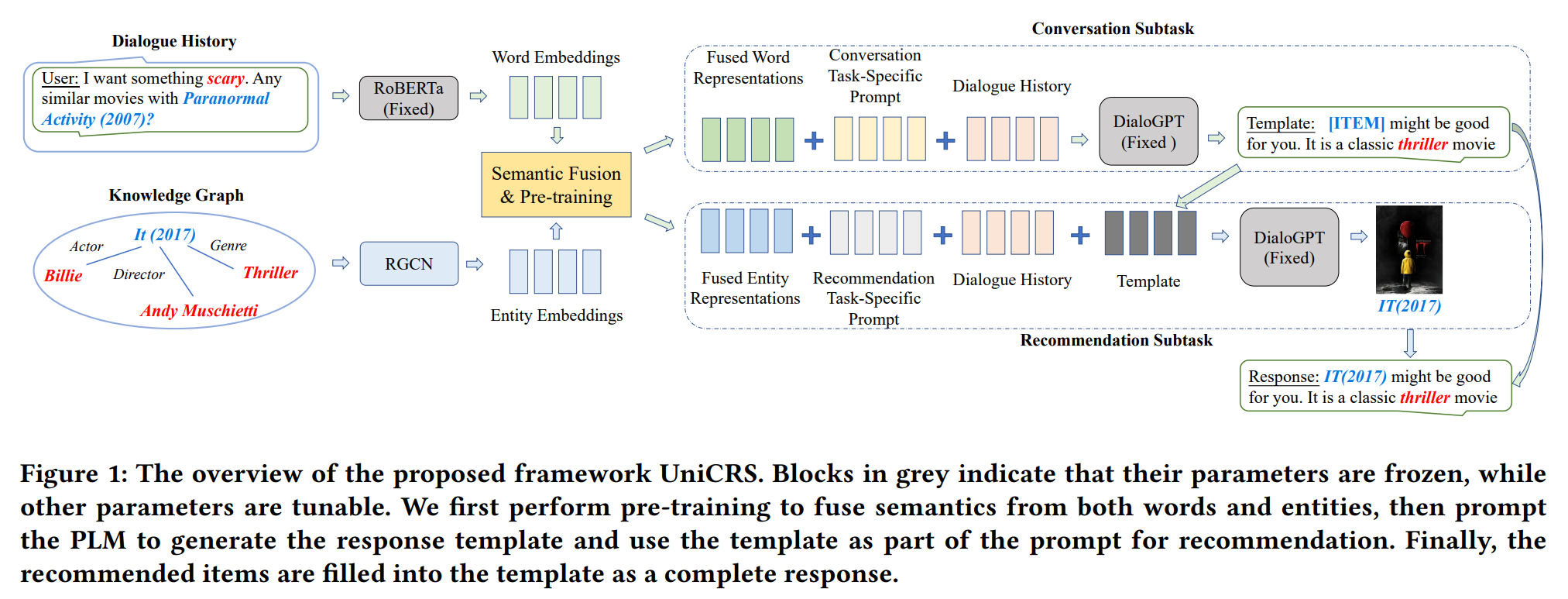
먼저, 단어와 엔티티의 의미를 융합하기 위해 사전 학습을 수행한다. 사전 학습된 언어 모델(PLM)을 사용하여 응답 템플릿을 생성하고, 이 템플릿을 추천을 위한 프롬프트의 일부로 사용한다. 마지막으로, 추천된 아이템이 템플릿에 채워져 완전한 응답이 된다.
Knowledge-Enhanced Prompt Learning
- 프롬프트 설계
- 융합된 지식 표현 : 사전 훈련된 의미 융합 모듈에서 생성된 지식 표현을 포함한다.
- 작업별 소프트 토큰 : 각 하위 작업에 맞는 소프트 토큰을 사용하여 프롬프트를 구성한다.
- 대화 맥락 : 대화의 맥락 정보를 제공하여 모델이 더 잘 적응할 수 있도록 한다.
- 응답 템플릿 : 대화 하위 작업에서 생성된 응답 템플릿을 추천 하위 작업의 중요한 부분으로 포함하여 두 하위 작업 간의 정보 상호작용을 강화한다.
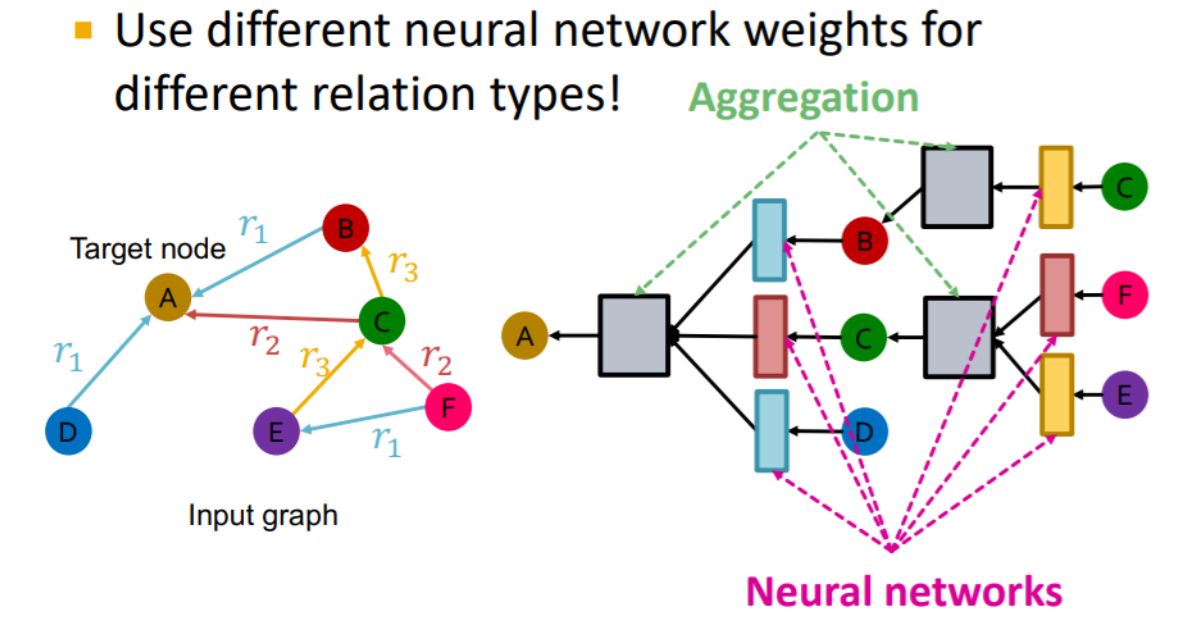
RGCN (Relational Graph Convolutional Network)
heterogeneous graph에 사용할 수 있는 GNN 모델
- RGCN은 관계에 따라 다른 가중치를 적용하여 노드의 이웃 정보를 집계하고, 노드의 표현을 업데이트한다. 즉, 각 관계 유형에 대해 별도의 합성곱 연산을 수행하며, 이를 통해 관계 정보를 더욱 세밀하게 반영한다.
- RGCN은 추천 시스템, 지식 그래프 완성, 소셜 네트워크 분석 등 다양한 분야에서 활용된다. 특히, 관계가 중요한 데이터셋에서 강력한 성능을 발휘한다.
4-2. RecLLM
Leveraging Large Language Models in Conversational Recommender Systems (2023)
RecLLM은 LLM을 활용하여 사용자와의 대화를 통해 추천을 제공하는 데 중점을 두고 있다. 이는 사용자의 요구와 선호를 더 잘 이해하고 반영할 수 있도록 한다. 또한, RecLLM은 LLM의 잠재력을 활용하여 추천 시스템의 효율성과 개인화를 향상시킨다.
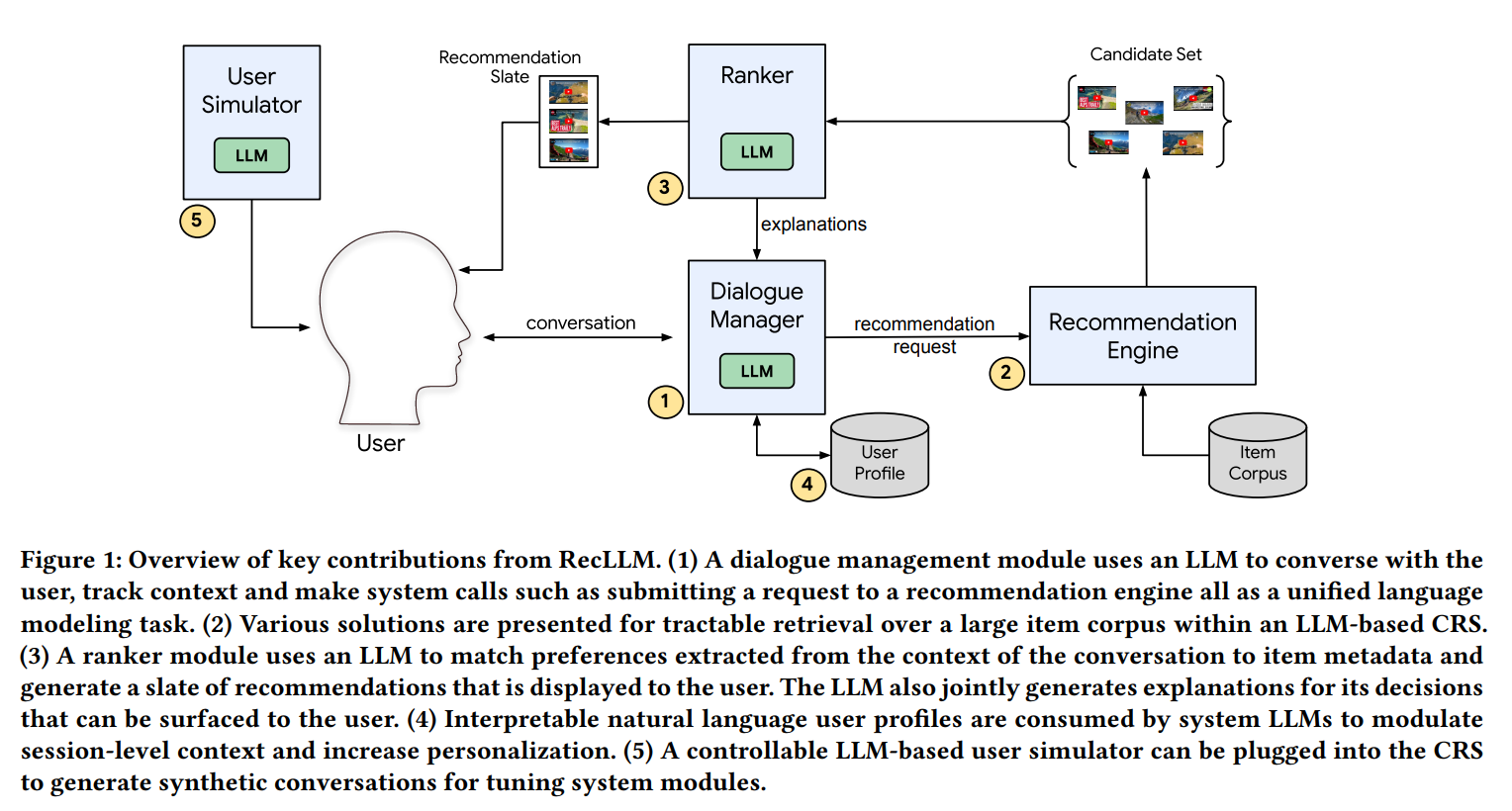
(1) Dialogue Manager : 대화 관리 모듈은 LLM을 사용하여 사용자와 대화하고, 맥락을 추적하며, 추천 엔진에 요청을 제출하는 등의 시스템 호출을 통합된 언어 모델링 작업으로 수행한다.
(2) Recommendation Engine : LLM 기반 CRS 내에서 대규모 아이템 코퍼스에 대한 효율적인 검색을 위한 다양한 솔루션이 제시된다.
(3) Ranker : 랭커 모듈은 LLM을 사용하여 대화의 맥락에서 추출된 선호도를 아이템 메타데이터와 매칭하고, 사용자에게 표시될 추천 목록을 생성한다. 또한, LLM은 사용자에게 제공되는 추천에 대한 설명을 함께 생성한다.
(4) User Profile : 해석 가능한 자연어 사용자 프로필이 시스템 LLM에 의해 사용되어 세션 수준의 맥락을 조절하고 개인화를 증가시킨다.
(5) User Simulator : LLM 기반 사용자 시뮬레이터는 CRS에 통합되어 모델을 튜닝하기 위한 합성 대화를 생성할 수 있다. 사용자 시뮬레이터는 실제 사용자와의 상호작용을 모사하여 합성 대화를 생성함으로써, 모델이 다양한 대화 상황을 학습할 수 있도록 돕는다.
4-3. iEvaLM
Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models (2023)
iEvaLM 모델은 대화형 추천 시스템의 평가 방식을 재고하는 데 중점을 둔 접근 방식이다. 이 모델은 LLM 기반 사용자 시뮬레이터를 활용하여 상호작용 평가를 수행한다.
기존 대화형 추천 시스템의 평가 방식은 인간 주석자가 생성한 정답 항목과의 일치를 과도하게 강조하는 경향이 있다. iEvaLM 모델은 이러한 평가 방식을 혁신적으로 변화시키는 접근 방식으로, 사용자와의 상호작용을 중시하여 보다 실질적인 평가를 가능하게 한다.
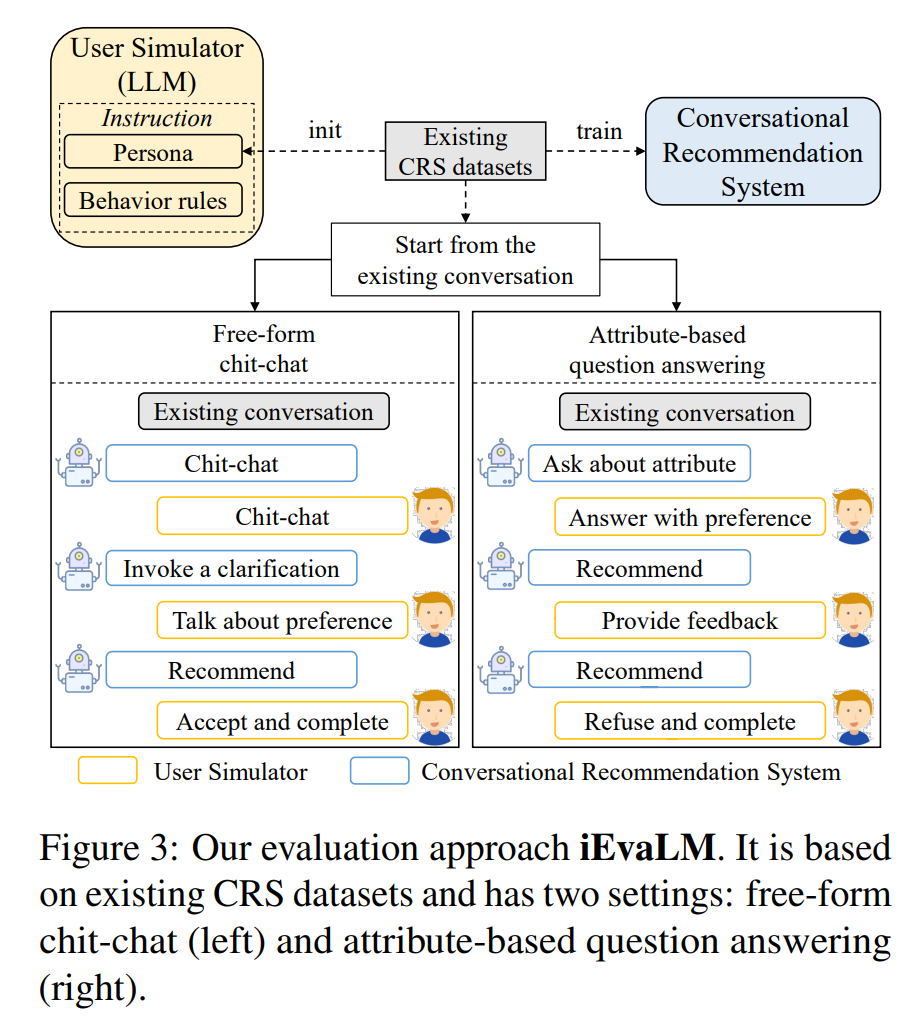
-
Free-form Chit-chat : 자유로운 대화 형식으로, 사용자가 자연스럽게 대화할 수 있는 환경을 제공한다. 이 방식은 사용자가 특정 주제에 대해 질문하거나 의견을 표현할 수 있도록 하여, 보다 인간적인 상호작용을 가능하게 한다.
- 사용자의 다양한 질문과 반응을 수용할 수 있는 유연성을 제공한다.
- 대화의 맥락을 이해하고, 적절한 응답을 생성하는 데 중점을 둔다.
-
Attribute-based Question Answering : 특정 속성이나 특성에 기반하여 질문에 답하는 방식이다. 사용자가 관심 있는 특정 속성에 대해 질문하면, 시스템이 그에 맞는 정보를 제공하는 형태이다.
- 사용자가 원하는 정보나 추천을 보다 구체적으로 요청할 수 있도록 한다.
- 이는 추천의 정확성을 높이고, 사용자의 요구를 더 잘 충족시킬 수 있도록 한다.
Large Language Models
LLM의 일반화 능력 : LLM은 처음보는 작업과 도메인에 강력한 일반화 능력을 보여준다.
LLM의 매개변수 크기 확장 : 기존 연구들은 언어 모델의 성능과 다운스트림 작업에서의 샘플 효율성은 매개변수 크기를 증가시킴으로써 개선될 수 있음을 밝혀냈다.
Instruction Tuning : 언어 모델은 instruction 튜닝을 통해 처음보는 다양한 작업에서 더욱 일반화될 수 있다.
Downstream Task : 많은 연구들이 질문 응답, 수치 추론, 코드 생성, 상식 추론 등 다양한 다운스트림 작업에 대형 언어 모델을 성공적으로 배포하고 있다.
Sample Efficiency on Downstream Tasks
Downstream task는 모델이 학습한 후, 그 모델을 사용하여 수행하는 실제 응용 작업을 의미한다. 예를 들어, LLM 모델이 학습된 후, 그 모델을 사용하여 질문 응답, 텍스트 요약, 감정 분석 등과 같은 구체적인 작업을 수행하는 것을 말한다.
Sample Efficiency on Downstream Tasks는 주어진 데이터 샘플을 얼마나 효과적으로 활용하여 모델의 성능을 향상시킬 수 있는지를 의미한다. 즉, 적은 양의 학습 데이터를 사용하더라도 높은 성능을 달성할 수 있는 능력을 나타낸다.
LLM 기반 추천
- LLM에서 사용되는 아키텍처 조정 : M6-Rec, P5
- 기존 LLM을 추천에 재사용 : GPT4Rec, ChatGPT 추천, GeneRec
1. M6-Rec
M6 Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems (2022)
Alibaba의 LLM 모델인 M6를 활용한 추천 시스템
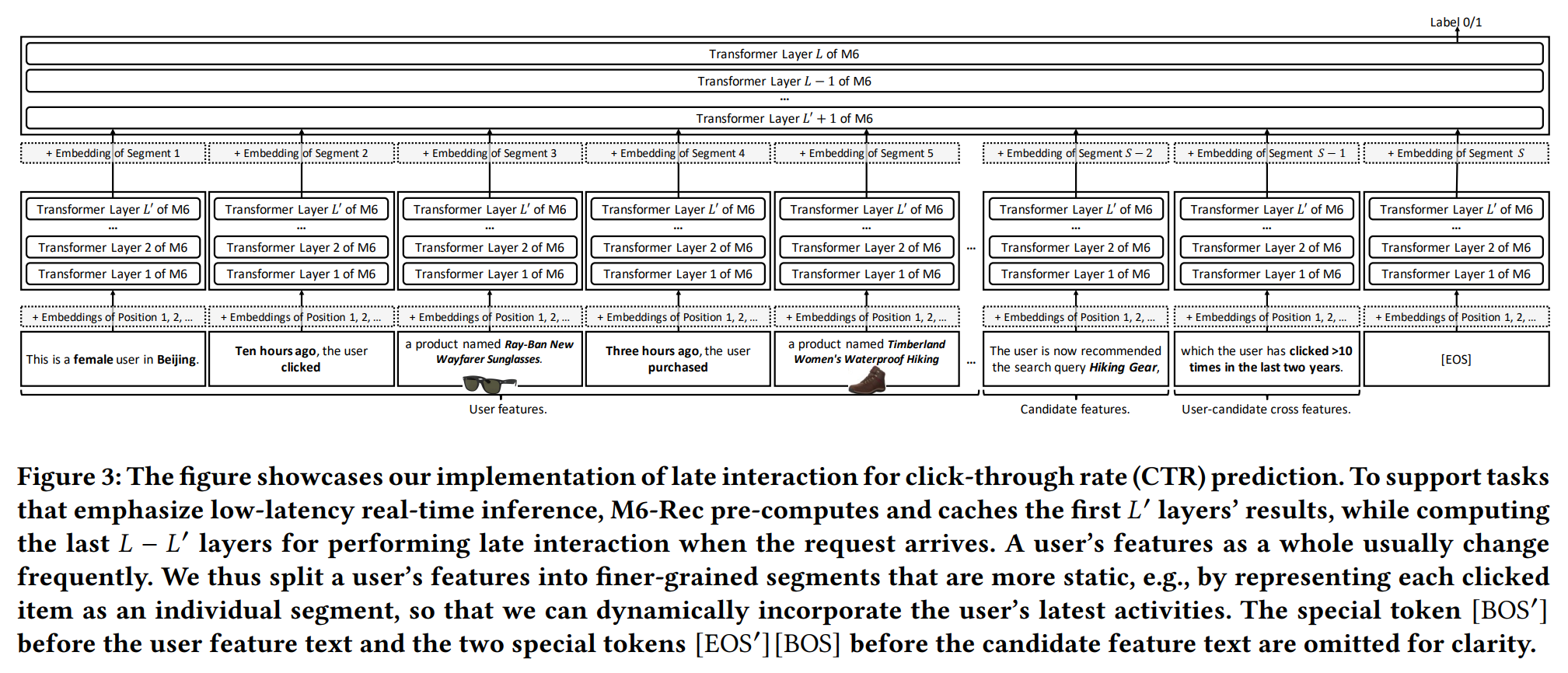
- M6 모델은 사용자 행동 데이터를 텍스트로 표현하고, 작업을 언어 이해/생성으로 변환하여 하위 작업에 활용할 수 있는 범용 모델이다.
ex) "A male user in Beijing, who clicked product X last night and product Y this noon, was recommended product Z and did not click it." - M6-Rec 모델은 검색, 순위 매기기, 제로샷 추천, 설명 생성, 개인화된 콘텐츠 생성, 대화형 추천 등의 다양한 작업에서 그 유연성을 입증했다.
2. P5
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) (2022)
P5 : Pretrain, Personalized Prompt, and Predict Paradigm
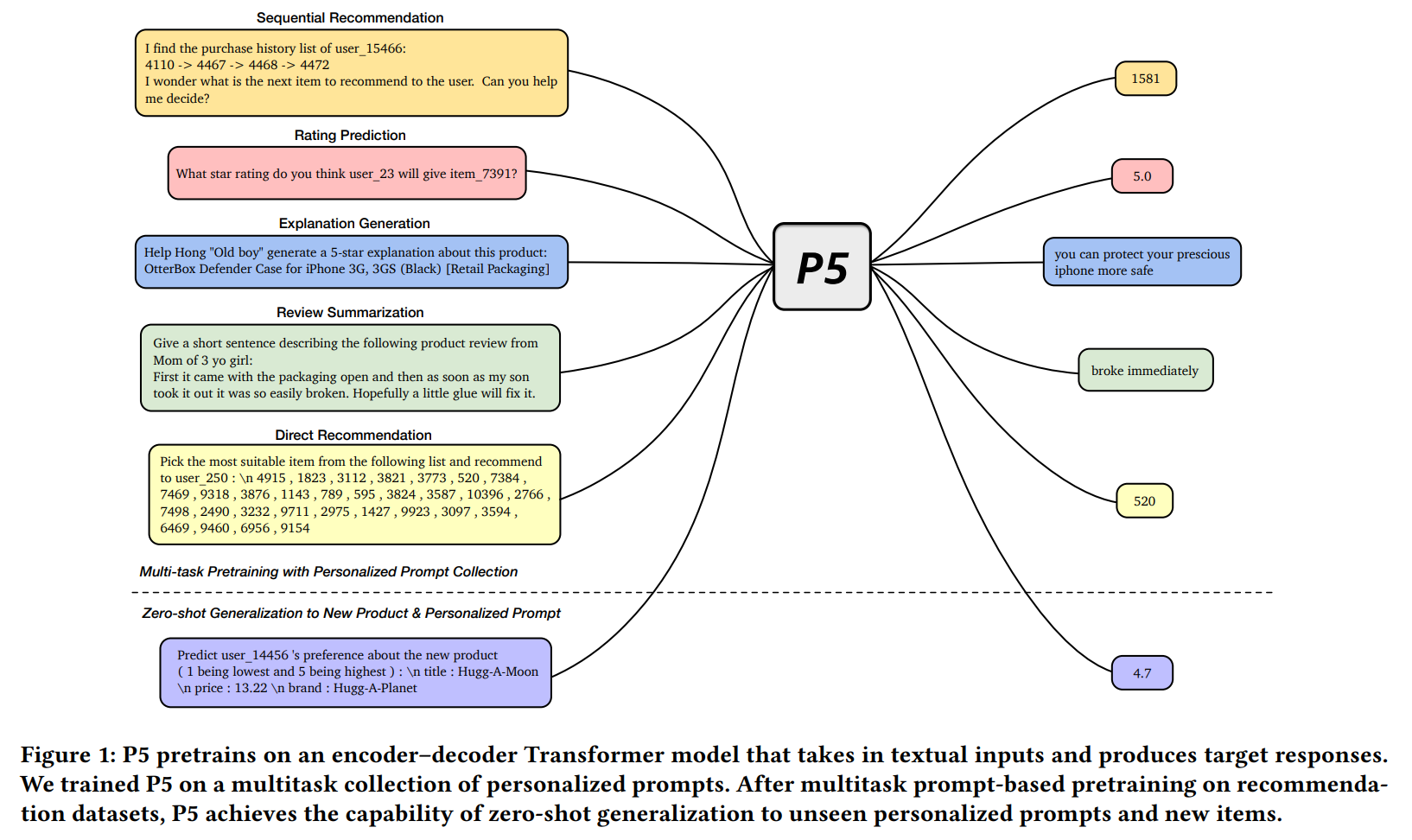
다양한 추천 작업을 통합할 수 있는 P5라는 유연한 text-to-text 패러다임을 제안한다. 기존의 추천 시스템에서는 작업별로 특화된 아키텍처와 훈련 목표가 필요했지만, P5는 모든 데이터를 자연어 시퀀스로 변환하여 공통 형식으로 처리한다.
P5는 개인화된 프롬프트를 통해 적응적으로 예측을 수행할 수 있어, zero-shot 또는 few-shot 방식으로 예측할 수 있으며, 광범위한 fine-tuning의 필요성을 크게 줄인다.
3. GPT4Rec
GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation (2023)
GPT4Rec은 사용자의 히스토리에 있는 아이템 제목을 바탕으로 가상의 "검색 쿼리"를 생성한 후, 이 쿼리를 검색하여 추천 아이템을 찾는 방식으로 설계되었다. 이 프레임워크는 사용자와 아이템의 임베딩을 언어 공간에서 학습하여, 다양성과 세분성(granularity) 관점에서 사용자 관심사를 잘 포착할 수 있도록 한다. 특히, Beam Search를 활용한 다중 쿼리 생성 기법을 통해 추천의 정확성과 다양성을 높이고, 콜드 스타트 아이템 추천을 위한 해석 가능한 user interests representation을 제공한다.
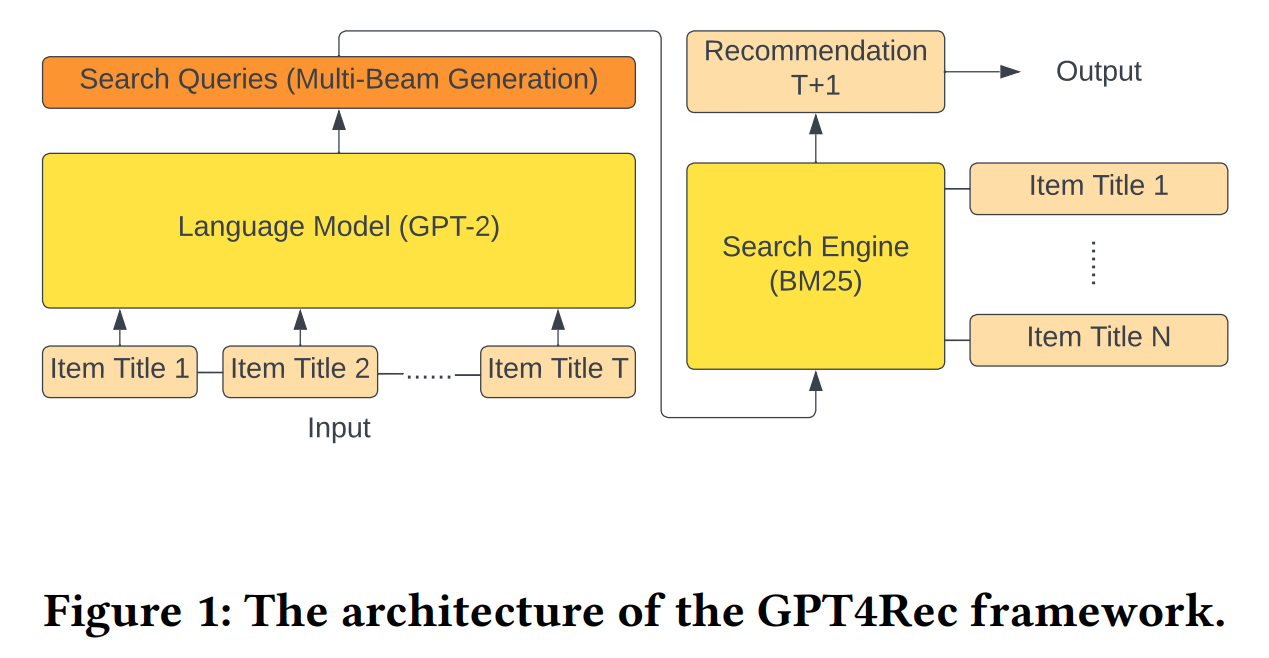
Beam Search
Beam Search는 최적의 해를 찾기 위해 사용되는 탐색 알고리즘이다. 주로 자연어 처리 분야에서 시퀀스 생성 문제를 해결하는 데 사용된다. 이 알고리즘은 최적의 한가지 경로만 탐색하거나 가능한 모든 경로를 탐색하는 대신, 각 단계에서 가장 유망한 몇 개의 경로만을 유지하여 다양성과 효율성을 높인다.
BM25
BM25는 정보 검색에서 문서의 관련성을 평가하는 데 사용되는 알고리즘이다. BM25는 TF-IDF 계열의 검색 알고리즘 중 하나로, 주어진 쿼리에 대해 문서와의 연관성을 점수화하여 랭킹을 매긴다. BM25는 전통적인 TF-IDF 방법을 개선하여 문서 길이와 평균 문서 길이를 고려하여 더 정확한 관련성 점수를 제공한다.
4. ChatGPT 추천
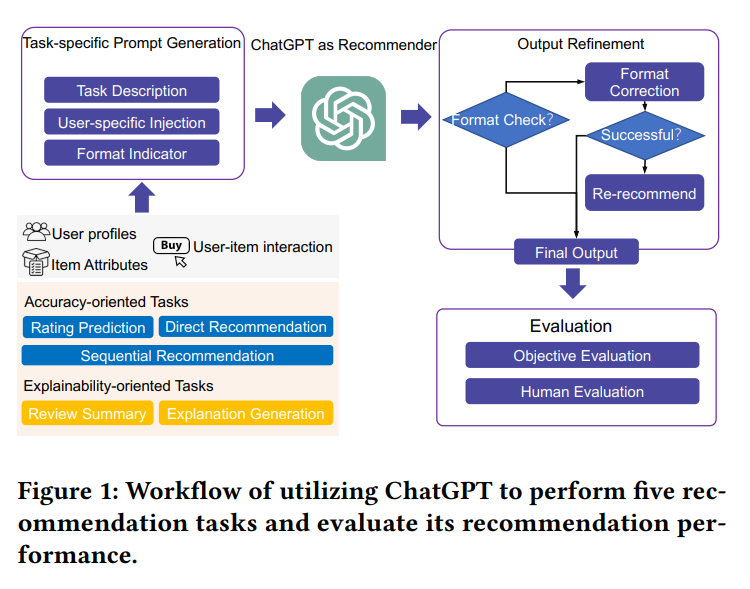
Is ChatGPT a Good Recommender? A Preliminary Study (2023)
ChatGPT를 추천 모델로 활용하여 추천 분야에서의 가능성을 탐구한다. ChatGPT의 지식을 추천 시나리오에 적용하여 높은 일반화 능력을 기대한다.
연구에서는 다섯 가지 추천 시나리오(평점 예측, 순차 추천, 직접 추천, 설명 생성, 리뷰 요약)에 대해 ChatGPT의 성능을 평가하기 위해 다양한 프롬프트를 설계했다. ChatGPT를 fine-tuning 없이 프롬프트만을 사용하여 추천 작업을 자연어 작업으로 변환했다. 또한, few-shot 프롬프팅을 통해 사용자 잠재 관심 정보를 주입하여 ChatGPT가 사용자 요구와 관심을 더 잘 이해하도록 했다.
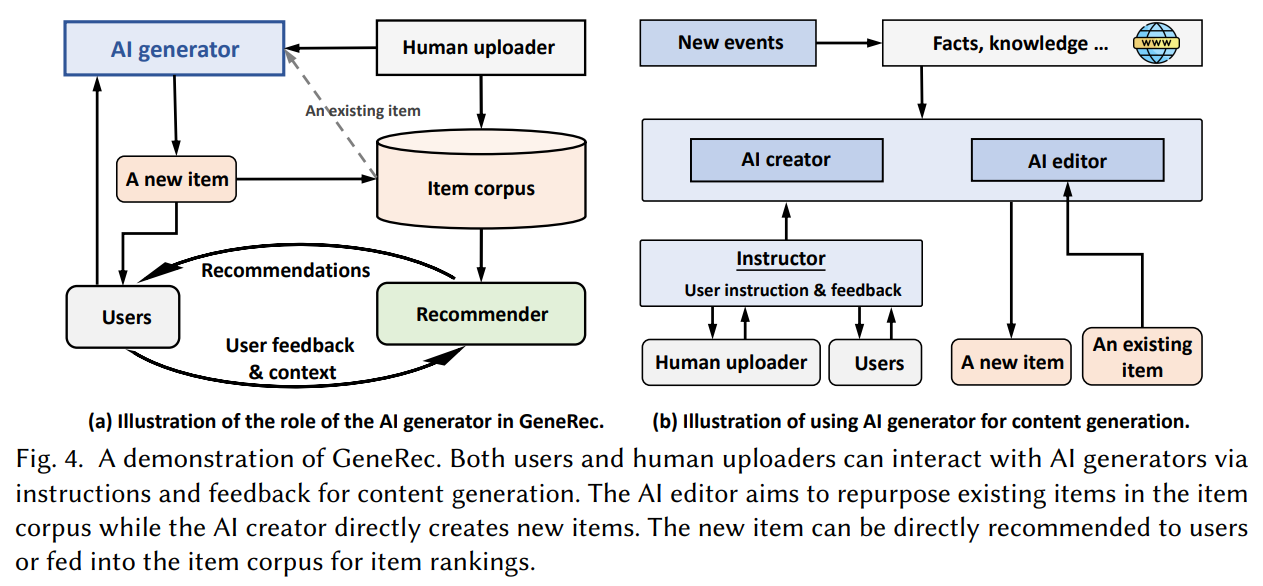
5. GeneRec
Generative Recommendation: Towards Next-generation Recommender Paradigm (2023)
GeneRec은 생성 AI를 활용하여 개인화된 콘텐츠를 생성하고, 사용자 지침을 통합하여 콘텐츠 생성을 안내한다. 이를 위해 사용자의 지침과 피드백을 처리하여 생성 지침을 출력하는 Instructor를 사용한다. 그 후, AI editor와 AI creator를 통해 기존 아이템을 재구성하고 새로운 아이템을 생성한다.