[논문] Alleviating the Long-Tail Problem in Conversational Recommender Systems
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
Alleviating the Long-Tail Problem in Conversational Recommender Systems [arxiv]
Zhipeng Zhao ACM RecSys 23
📝 Key Point
-
LOT-CRS 프레임워크 제안 : 대화형 추천 시스템(CRS)을 위한 long-tail 추천 향상을 목표로 하는 새로운 프레임워크를 제안한다.
-
균형 잡힌 데이터셋 시뮬레이션 : 공개적으로 수집된 아이템 속성을 활용하여 데이터 부족 문제를 해결하기 위해 균형 잡힌 CRS 데이터셋을 생성한다.
-
사전 학습 과제 설계 : PLM(Pre-trained Language Models)을 기반으로 하여, 대화 맥락 이해를 향상시키기 위해 두 가지 사전 학습 과제(Domain-Adaptive Masked Prediction & Contrastive Contexts Alignment)를 설계했다.
-
검색 보강 학습 및 라벨 스무딩 : 시뮬레이션된 데이터셋을 활용하여 long-tail 아이템 추천 성능을 개선하기 위해 검색 보강 학습과 라벨 스무딩 전략을 적용했다.
Abstract
연구 목적 : 대화형 추천 시스템(CRS)의 long-tail 문제를 완화하고 추천 성능을 향상시킨다.
문제점 : 기존 CRS 데이터셋은 long-tail 항목이 거의 언급되지 않아 추천 항목의 다양성이 줄어들고, 사용자가 쉽게 지루해진다.
제안 방법 : LOT-CRS라는 새로운 프레임워크를 통해 균형 잡힌 CRS 데이터셋을 시뮬레이션하고 활용했다.
pre-training : long-tail 아이템에 대해 시뮬레이션된 대화 이해를 향상시키기 위해 두 개의 사전 학습을 설계했다.
fine-tuning : 레이블 스무딩 전략을 적용한 검색 보강 미세 조정을 통해 long-tail 아이템의 추천 성능을 개선했다.
실험 결과 : 두 개의 공개 CRS 데이터셋을 통해 제안된 방법의 효과성과 확장성을 입증하였으며, 특히 long-tail 추천 성능이 향상되었다.
Figure
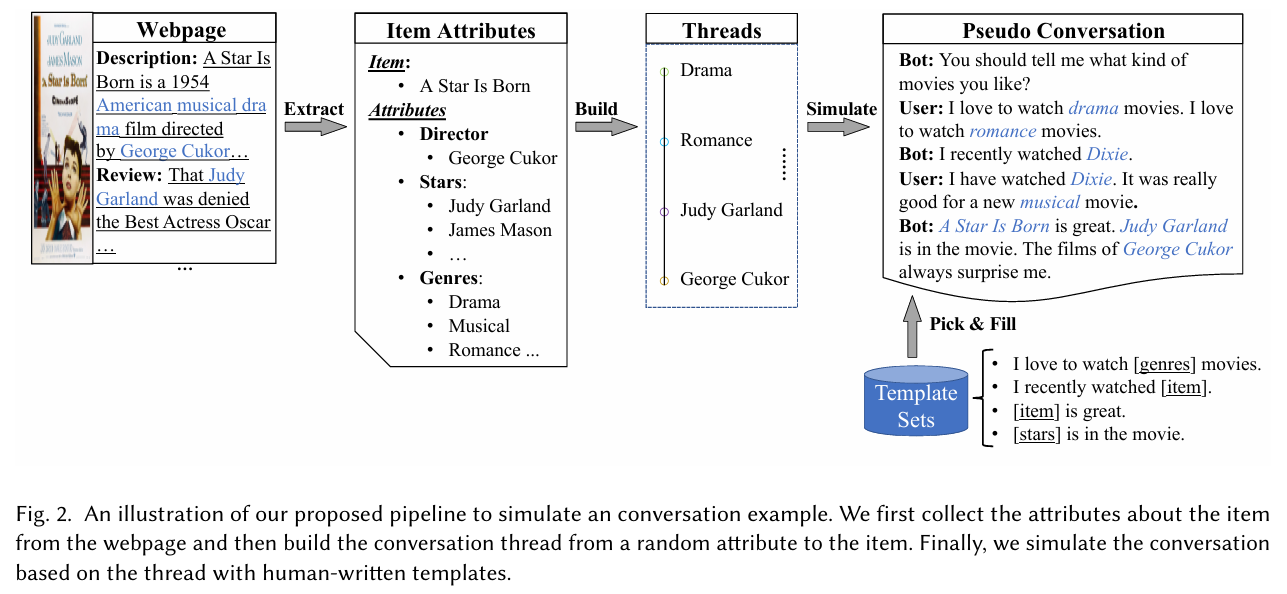
데이터 시뮬레이션 파이프라인
1. 웹사이트에서 아이템에 대한 특성을 수집한다.
2. 임의 속성에서 아이템에 대한 대화 스레드를 만든다.
3. 사람이 작성한 템플릿을 사용하여 스레드를 기반으로 대화를 시뮬레이션한다.
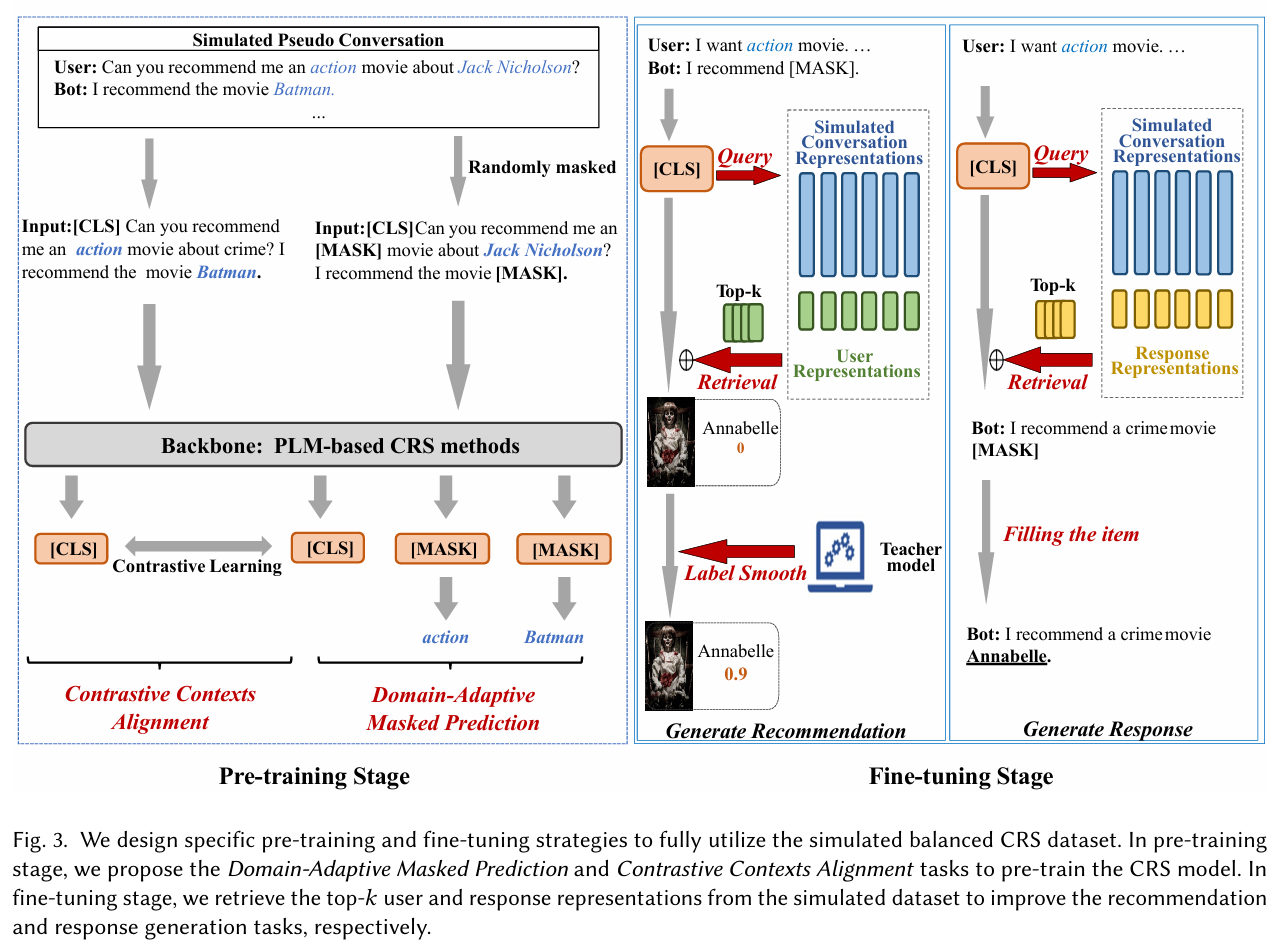
Pre-training Stage : Domain-Adaptive Masked Prediction & Contrastive Contexts Alignment
Fine-tuning Stage : 시뮬레이션된 데이터셋에서 top-𝑘 사용자와 response 표현을 검색하여 추천과 응답 생성 성능을 향상시킨다.
Contrastive Contexts Alignment
서로 다른 문맥(context) 간의 대조적 정렬(alignment)을 통해 모델의 성능을 향상시키는 방법
대조적 학습 : 두 개의 서로 다른 문맥이나 샘플을 비교하여 이들 간의 유사성과 차이를 학습한다. 이를 통해 모델은 특정 문맥에서 중요한 특징을 더 잘 이해하게 된다.
문맥 정렬 : 서로 다른 문맥에서 얻은 표현을 정렬하여, 유사한 의미를 가지는 표현들이 가까이 위치하도록 한다. 이를 통해 모델은 다양한 상황에서도 일관된 성능을 발휘할 수 있게 된다.
성능 향상 : 대조적 문맥 정렬을 통해 모델은 다양한 상황에서의 일반화 능력을 향상시키고, 특히 희귀한 데이터나 long-tail 문제를 다루는 데 유리하다.
1. Introduction
문제점 : 대부분의 기존 CRS는 데이터에 의존적이며, 고품질 CRS 데이터셋의 가용성에 성능이 크게 좌우된다. 하지만 기존 CRS 데이터셋에서 long-tail 현상이 두드러지며, 많은 아이템이 대화에서 거의 언급되지 않거나 전혀 언급되지 않는다. 이로 인해 학습된 CRS는 자주 등장하는 아이템에 치우친 추천을 하게 되어, 추천 아이템의 다양성이 줄어든다.
기존 접근법 : 기존 연구는 resampling, 인스턴스 가중치 조정, 정규화 방법 등을 사용했으나, CRS의 long-tail 문제를 해결하기에는 두 가지 해결 과제가 있다. 첫째, 대화 맥락을 이해하는 데 필요한 증거를 충분히 포착하기 어렵고, 둘째, 사용자 선호를 정확하게 추론하는 데 필요한 학습 신호가 부족하다.
제안 방법 : 본 논문에서는 CRS의 long-tail 추천 문제를 해결하기 위한 새로운 프레임워크 LOT-CRS를 제안한다. 이 프레임워크는 공공 아이템 속성을 활용하여 균형 잡힌 CRS 데이터셋을 시뮬레이션하고, 이를 통해 데이터 부족 문제를 해결한다.
전략 : 시뮬레이션된 데이터를 기반으로 두 가지 사전 학습 과제(도메인 적응형 마스크 예측, 대조적 문맥 정렬)를 설계하고, 검색 보강 학습 전략을 채택하여 대화 맥락을 풍부하게 한다. 또한, 시뮬레이션된 대화로 학습된 CRS 모델을 사용하여 long-tail 아이템을 추천하는 데 도움을 준다.
결과 : 제안된 접근법은 long-tail 추천 성능을 효과적으로 향상시켜 기존 PLM 기반 CRS의 성능을 극대화할 수 있음을 보여준다. 이는 대화형 추천 시스템에서 long-tail 문제를 완화하기 위한 첫 번째 시도이다.
4. Approach
4.1 PLM 기반 CRS 방법
최근 Transformer 아키텍처를 기반으로 한 PLM(Pre-trained Language Models)과 대형 언어 모델(LLM)이 텍스트 및 대화 이해 작업에서 우수성을 보여주었다. 기존 CRS 방법들은 PLM을 사용하여 대화 맥락을 모델링한다. 본 연구에서는 long-tail 추천을 개선하기 위해 BERT, BART, UniCRS와 같은 PLM을 사용하고, 시뮬레이션된 CRS 데이터셋으로 사전 학습을 수행하여 대화 맥락 이해를 향상시킨다.
4.2 균형 잡힌 CRS 데이터셋 시뮬레이션
기존 데이터셋은 long-tail 아이템을 충분히 고려하지 않아, 이를 해결하기 위해 균형 잡힌 CRS 데이터셋을 시뮬레이션한다. 아이템 속성(예: 설명, 리뷰)을 수집하고, 대화 스레드를 구축하여 추천 아이템을 포함한 대화를 생성한다.
4.3 균형 잡힌 시뮬레이션 데이터셋에서의 사전 학습
시뮬레이션된 데이터셋은 long-tail 아이템에 대한 중요한 증거를 포함한다. 두 가지 사전 학습 과제를 설계한다: Domain-Adaptive Masked Prediction(DMP)과 Contrastive Contexts Alignment(CCA). DMP는 아이템 및 속성 예측을 통해 PLM을 CRS에 적응시키고, CCA는 대화 맥락과 타겟 아이템 간의 관련성을 강화한다.
4.4 검색 보강 fine-tuning
시뮬레이션된 대화를 사용하여 PLM 모델을 사전 학습한 후, 실제 CRS 데이터셋으로 fine-tuning 한다. 실제 데이터셋은 제한적이거나 희소할 수 있으므로, 검색 보강 학습 아이디어를 적용하여 시뮬레이션된 대화로부터 유용한 맥락을 검색하고 이를 활용한다.
4.4.1 추천을 위한 fine-tuning
-
검색 강화 사용자 표현 : 시뮬레이션된 데이터에서 유사한 대화를 검색하여 사용자 표현을 보강한다. 이를 통해 사용자의 선호를 더 효과적으로 반영할 수 있다.
-
long-tail 아이템을 위한 라벨 스무딩(Label Smoothness) : teacher 모델을 사용하여 soft label들을 생성하고, 이를 기반으로 정규화를 진행하여 long-tail 아이템에 대한 확률을 높인다. 이를 통해 노출 편향 문제를 완화한다.
라벨 스무딩 (Label smoothness)
모델의 예측 확률 분포를 부드럽게 만드는 방법.
모델의 예측을 더 부드럽고 일반화된 형태로 만드는 데 기여하여, 특정 클래스에 대한 편향을 줄이고, 다양한 아이템을 효과적으로 추천할 수 있도록 한다.
- 일반화 능력 향상 : 모델이 특정 클래스(ex. frequent items)에 과도하게 적합되는 것을 방지하고, 다양한 클래스(ex. long-tail items)에 대한 예측을 더 균형 있게 만들기 위해 사용된다.
- 노출 편향 완화 : 특정 아이템이 자주 추천되는 경향이 있는 경우, 라벨 스무딩은 모델이 덜 자주 등장하는 아이템에 대해서도 더 높은 확률을 할당하도록 유도합니다.
- Soft Labels 사용 : teacher 모델을 통해 생성된 soft label들을 사용하여, 모델이 각 클래스에 대해 단일 확률 대신 여러 클래스에 대한 확률 분포를 학습하게 합니다. 이를 통해 모델이 더 다양한 예측을 할 수 있도록 돕습니다.
4.4.2 응답 생성을 위한 fine-tuning
-
검색 강화 프롬프트 : 대화 기록을 인코딩하여 관련 응답을 검색하고, 이를 통해 더 유용한 응답을 생성한다.
-
응답 템플릿 생성 및 채우기 : PLM을 사용하여 응답 템플릿을 생성하며, 이 템플릿 내의 아이템 토큰을 추천된 아이템으로 채운다. 이를 통해 자연스럽고 정보가 풍부한 응답을 제공한다.
5. Experiment
5.1 실험 설정
-
데이터셋 : ReDial과 INSPIRED 두 개의 영어 CRS 데이터셋을 사용하여 접근법의 효과를 검증하였다. ReDial은 영화 추천을 다루며, Amazon Mechanical Turk를 통해 구축되었다. INSPIRED 역시 영화 추천 데이터셋이지만, 규모가 더 작다.
-
기준 모델 : 여러 경쟁력 있는 방법(기존 CRS 모델 및 PLM)을 기준으로 선택하여 추천과 대화 두 가지 하위 작업에서 평가하였다. 주요 모델로는 HRED 기반의 ReDial, KG(Knowledge Graph)를 활용한 KBRD와 KGSF, PLM 기반의 GPT-2, DialoGPT, BERT, BART, UniCRS가 포함된다.
Baseline 모델
- ReDial : HRED 기반의 대화 모듈과 auto-encoder 기반의 추천 모듈을 통합한 모델이다.
- KBRD : 외부 지식 그래프(KG)를 활용하여 대화 이력의 entity를 강화하고, self-attention 기반 추천 모듈과 Transformer 기반 대화 모듈을 사용한다.
- KGSF : 두 개의 KG를 통합하여 단어와 entity의 표현을 강화하고, 상호 정보 최대화(Mutual Information Maximization) 방법을 사용하여 두 KG의 의미 공간을 정렬한다.
- GPT-2 : auto-regressive PLM으로, 대화 맥락을 입력으로 사용하여 생성된 텍스트를 응답으로, 마지막 토큰의 표현을 추천으로 활용한다.
- DialoGPT : 대규모 대화 코퍼스에서 사전 학습된 auto-regressive 모델로, 생성된 텍스트를 응답으로, 마지막 토큰 표현을 추천으로 사용한다.
- BERT : masked 언어 모델 작업을 통해 사전 학습된 모델로, 추천을 위해 [CLS] 토큰의 표현을 활용한다.
- BART : denoising auto-encoding 작업으로 사전 학습된 Seq2Seq 모델로, 생성된 텍스트를 응답으로, 마지막 토큰 표현을 추천으로 사용한다.
- UniCRS : 추천과 대화 작업을 모두 수행하는 통합 모델로, 고정된 PLM에서 지식 강화 프롬프트 학습을 사용한다.
HRED (Hierarchical Recurrent Encoder-Decoder)
: HRED는 대화 시스템에서 문맥을 효과적으로 처리하고, 사용자와의 상호작용에서 더 자연스럽고 일관된 응답을 생성하는 데 도움을 준다. 이러한 특성 덕분에 HRED는 대화형 추천 시스템(CRS) 및 기타 대화형 AI 애플리케이션에 널리 사용되고 있다.
- 계층적 구조 : HRED는 대화의 문맥을 이해하기 위해 두 개의 수준(문맥과 응답)으로 나누어 인코딩한다. 이는 대화의 전체적인 흐름과 각 발화의 의미를 동시에 고려할 수 있게 한다.
- 인코더-디코더 아키텍처 : HRED는 인코더-디코더 구조를 기반으로 하여, 입력된 대화의 문맥(이전 발화들)을 인코딩하고, 이를 바탕으로 적절한 응답을 생성한다.
- 순환 신경망(RNN) 활용 : HRED는 RNN을 사용하여 시퀀스 데이터를 처리하며, 대화의 시간적 특성을 잘 반영할 수 있다.
- 평가 지표 : 추천과 대화 작업을 평가하기 위해 Recall@𝑘, Coverage@𝑘, Tail-Coverage@𝑘, Distinct-𝑛 등 다양한 지표를 사용하였다. Fluency와 Informativeness 측면에서 수작업 평가도 시행하였다.
평가 지표
Recall@k
- 추천 시스템이 상위 k개의 추천 목록에서 실제로 사용자가 선호하는 아이템을 얼마나 잘 추천하는지를 평가하는 지표
- 목적 : 추천의 정확성을 측정하며, k의 값에 따라 다양한 수준의 추천 성능을 평가할 수 있다.
Coverage@k
- 전체 추천 목록에서 얼마나 많은 다양한 아이템이 포함되었는지를 측정하는 지표
- 공식 : , 여기서 는 대화 C에 대한 상위 k개의 추천 아이템 목록을 나타낸다.
- 목적 : 추천 결과의 다양성을 평가하여, 추천 시스템이 다양한 아이템을 추천하는지를 확인한다.
Tail-Coverage@k
- 전체 추천 목록에서 long-tail 아이템(빈도가 낮은 아이템)이 얼마나 많이 추천되었는지를 측정하는 지표
- 공식 : , 여기서 는 long-tail 아이템으로 구성된 상위 k개의 추천 목록이다.
- 목적 : long-tail 아이템의 추천 성과를 평가하여, 추천 시스템의 균형 잡힌 추천 능력을 확인한다.
Distinct-n
- 생성된 응답을 n-그램 기반으로 계산하여 단어 수준에서 다양성을 측정하는 지표
- 목적 : 추천 시스템이 생성하는 응답의 다양성을 평가하여, 반복적인 응답을 피하고 다양한 답변을 생성하는 능력을 확인한다.
Fluency / Informativeness
- 수작업 평가를 통해 생성된 응답의 유창성과 정보량을 0에서 2까지의 점수로 평가하는 지표
- 목적 : 추천 시스템이 생성하는 응답의 질을 주관적으로 평가하여, 실제 사용자 경험을 반영한다.
5.2 추천 성능 평가
-
자동 평가 : 다양한 방법의 추천 정확도 및 long-tail 메트릭을 평가하였다. KG 기반 CRS 방법이 PLM 기반 방법과 경쟁력 있는 성능을 보였으며, 특히 UniCRS가 대부분의 지표에서 최상의 성능을 기록하였다. 제안된 접근법은 BERT, BART, UniCRS의 성능을 향상시켰다.
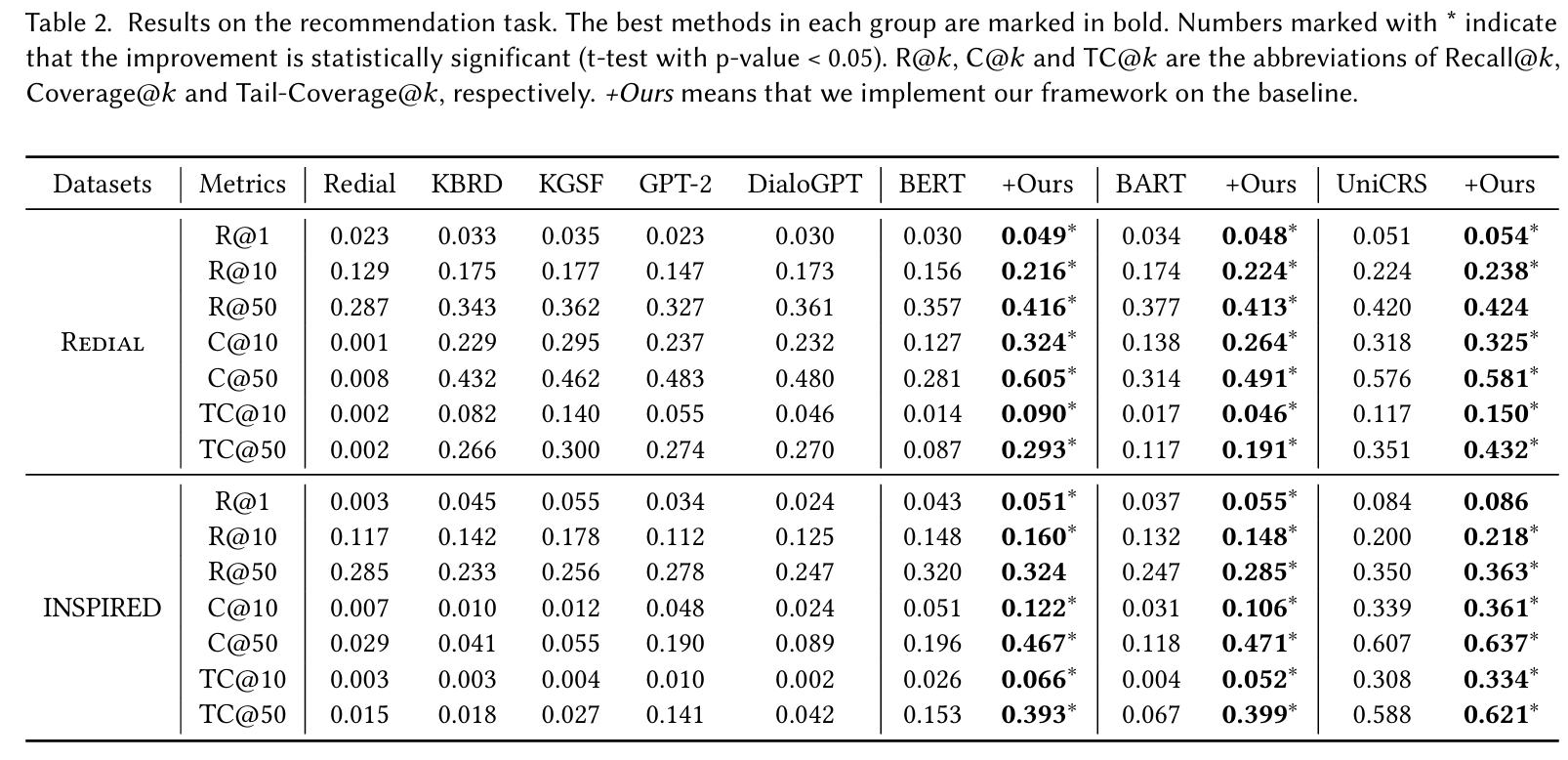
-
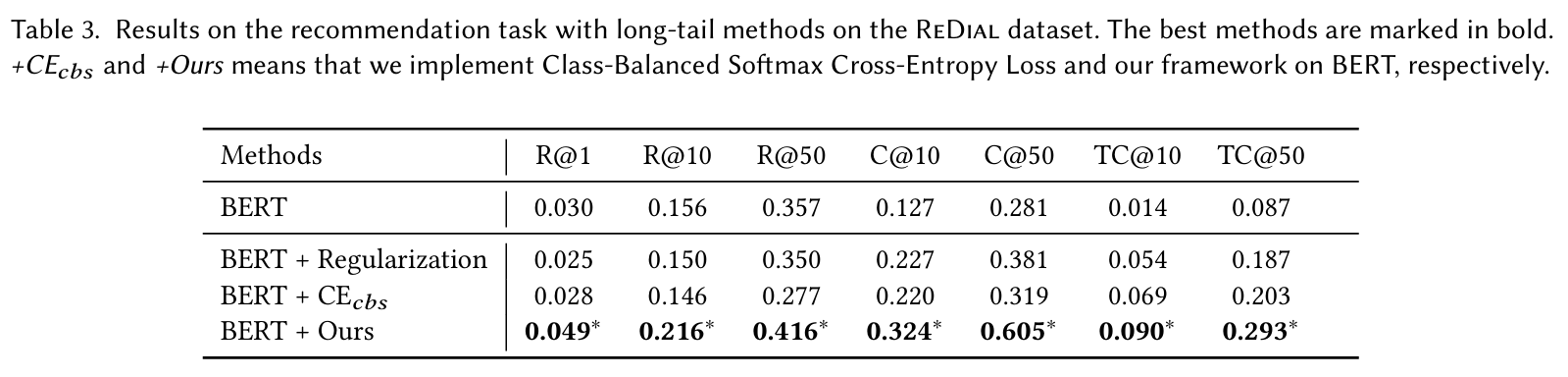
Long-tail 방법과의 성능 비교 : Class-Balanced Softmax Cross-Entropy Loss 및 Regularization 방법과 비교하여, 제안된 접근법이 보다 효과적으로 long-tail 문제를 해결함을 보였다. Regularization 방법으로는 Balanced Group Softmax를 사용했다.
Class-Balanced Softmax Cross-Entropy Loss
- 목적 : 데이터셋에서 클래스 불균형 문제를 해결하기 위해 설계된 손실 함수이다. 일반적인 Softmax Cross-Entropy Loss은 다수 클래스에 대해 모델이 과도하게 학습하는 경향이 있어, 소수 클래스의 성능이 저하될 수 있다.
- 작동 원리
- 클래스 불균형을 해결하기 위해, 각 클래스에 가중치를 부여하여 손실 계산 시 소수 클래스의 중요성을 높인다.
- 가중치는 각 클래스의 샘플 수에 기반하여 조정되며, 일반적으로는 로 계산된다. 여기서 은 전체 샘플 수, 는 클래스 수, 는 클래스 의 샘플 수이다.
- 이 가중치를 사용하여 손실 함수를 계산함으로써, 소수 클래스에 대한 손실이 더 크게 반영되어 모델이 균형 잡힌 학습을 할 수 있도록 한다.
Regularization
- 목적 : 모델이 학습 데이터에 과적합(overfitting)되는 것을 방지하기 위해 사용된다. Regularization은 모델의 복잡성을 줄이고, 일반화 성능을 향상시키는 역할을 한다.
- 주요 유형
- L1 Regularization (Lasso) : 모델의 가중치에 대한 절대값 합을 손실 함수에 추가한다. 이로 인해 일부 가중치가 0으로 수렴하여, 변수 선택 효과를 가져온다.
- L2 Regularization (Ridge) : 모델의 가중치에 대한 제곱합을 손실 함수에 추가한다. 이는 모든 가중치가 작아지도록 유도하여, 모델의 복잡성을 줄인다.
- Dropout : 학습 과정에서 일정 비율의 뉴런을 무작위로 비활성화하여, 네트워크가 특정 뉴런에 의존하지 않도록 한다. 이로 인해 더 강건한 모델이 학습된다.
이 두 가지 방법은 각각 클래스 불균형 문제와 과적합 문제를 해결하는 데 효과적이며, 특히 long-tail 데이터셋에서 모델의 성능을 향상시키는 데 중요한 역할을 한다.
Balanced Group Softmax
그룹화 : 클래스 간의 불균형을 완화하기 위해 그룹별로 소프트맥스 함수를 조정하여 각 클래스의 기여도를 균형 있게 만든다.
가중치 조정 : 각 클래스의 중요도에 따라 가중치를 조정하여 학습 과정에서 덜 나타나는 클래스를 더 잘 학습하도록 유도한다.
-
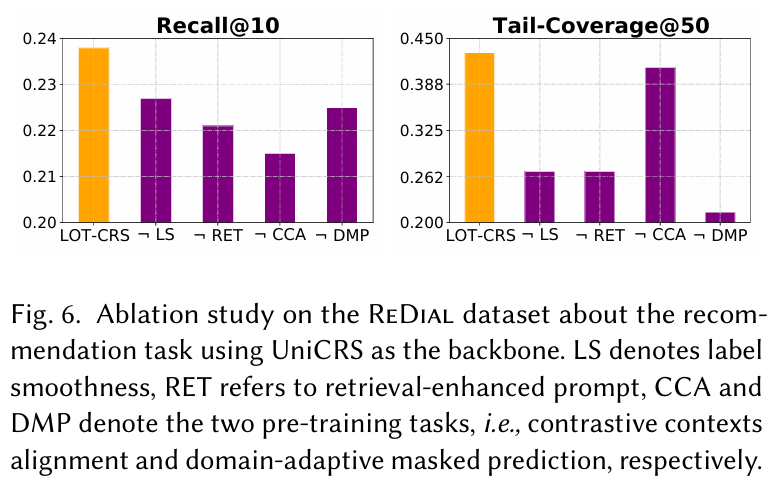
Ablation Study : UniCRS를 기준으로 여러 구성 요소의 효과를 검증하였다. DMP와 CCA, label smoothness, retrieval-augmented 전략을 제거할 경우 성능 저하가 발생함을 확인하였다.
-
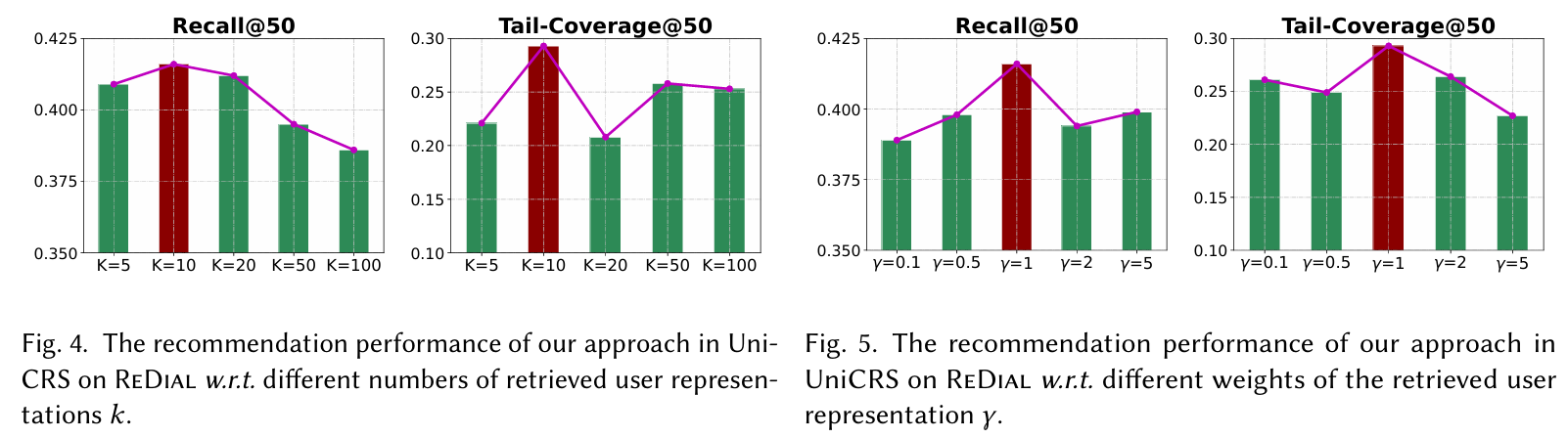
하이퍼파라미터 분석 : 사용자 표현을 검색하는 수와 그 가중치를 조정하여 성능에 미치는 영향을 평가하였다. 적절한 값 설정이 필요함을 강조하였다.
5.3 대화 성능 평가
-
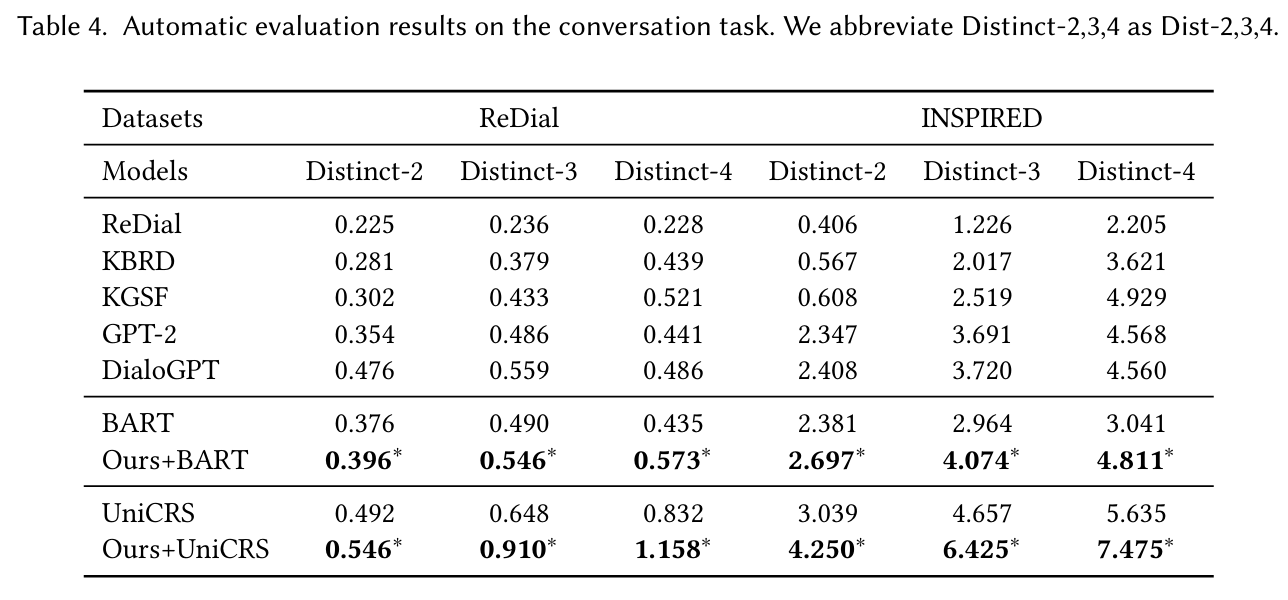
자동 평가 : PLM 기반 방법이 다른 CRS 방법보다 일관되게 우수한 성능을 보였다. 특히 DialoGPT가 가장 높은 성능을 기록하였으며, UniCRS도 다른 기준 모델보다 우수한 성능을 발휘하였다. 제안된 접근법은 BERT, UniCRS의 성능을 향상시켰다.
-
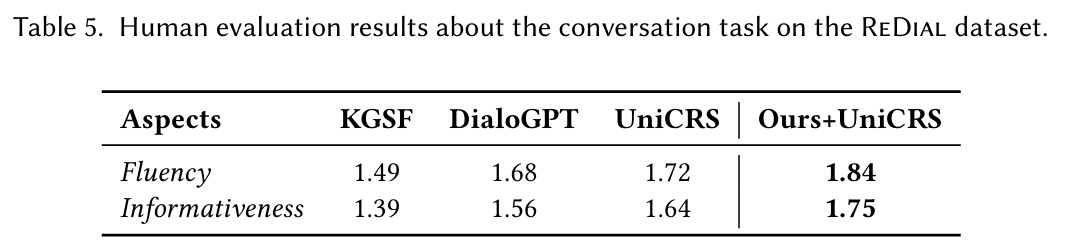
인간 평가 : KGSF, DialoGPT, UniCRS와 비교하여 제안된 접근법이 가장 높은 성능을 보였다. 시뮬레이션된 균형 잡힌 CRS 데이터셋을 통해 대화 역사 이해와 정보 생성 능력이 향상되었다.
-
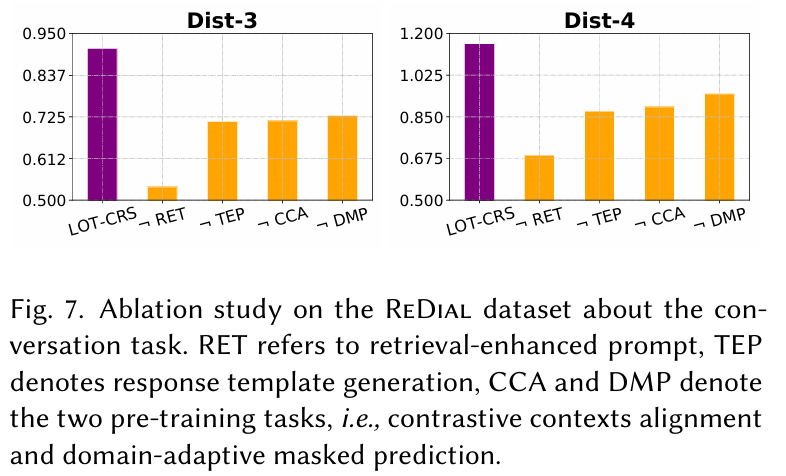
Ablation Study : 대화 작업에 대한 여러 구성 요소의 효과를 검증하였다. retrieval-augmented 전략이 다른 전략보다 더 중요한 것으로 나타났으며, 성능 저하가 더 크게 발생하였다.
-
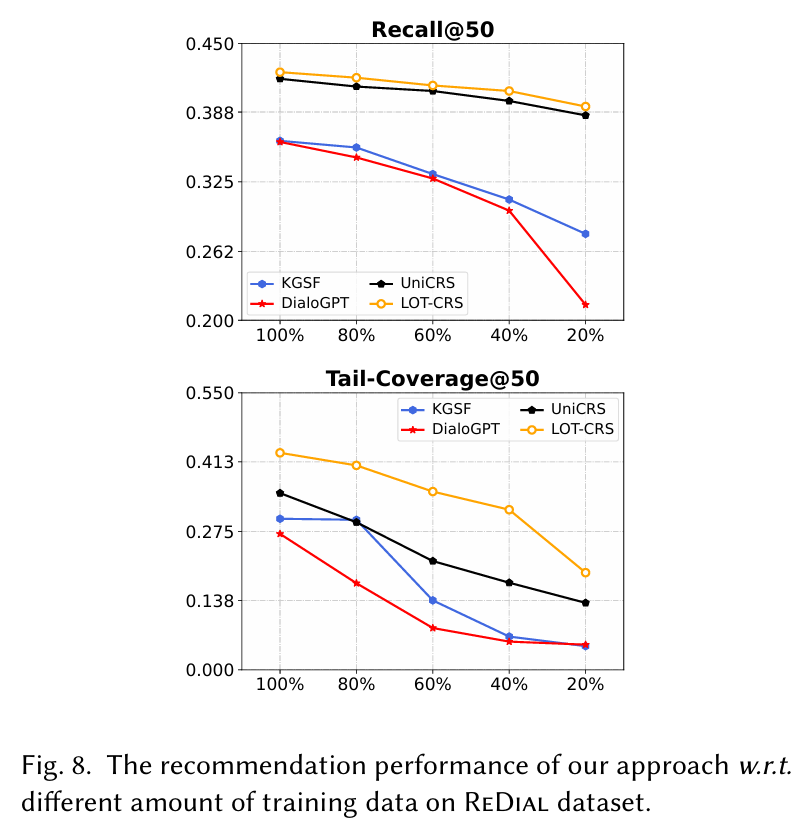
데이터 부족 시나리오 : 학습 데이터의 비율을 조정하여 제안된 접근법이 데이터 부족 문제를 얼마나 잘 해결하는지 평가하였다. 제안된 방법이 모든 경우에서 우수한 성능을 나타냈다. 이는 LOT-CRS가 제한된 레이블이 지정된 데이터를 더 잘 활용하고 특히 롱테일 권장 사항에 대해 콜드 스타트 문제를 완화할 수 있음을 나타낸다.
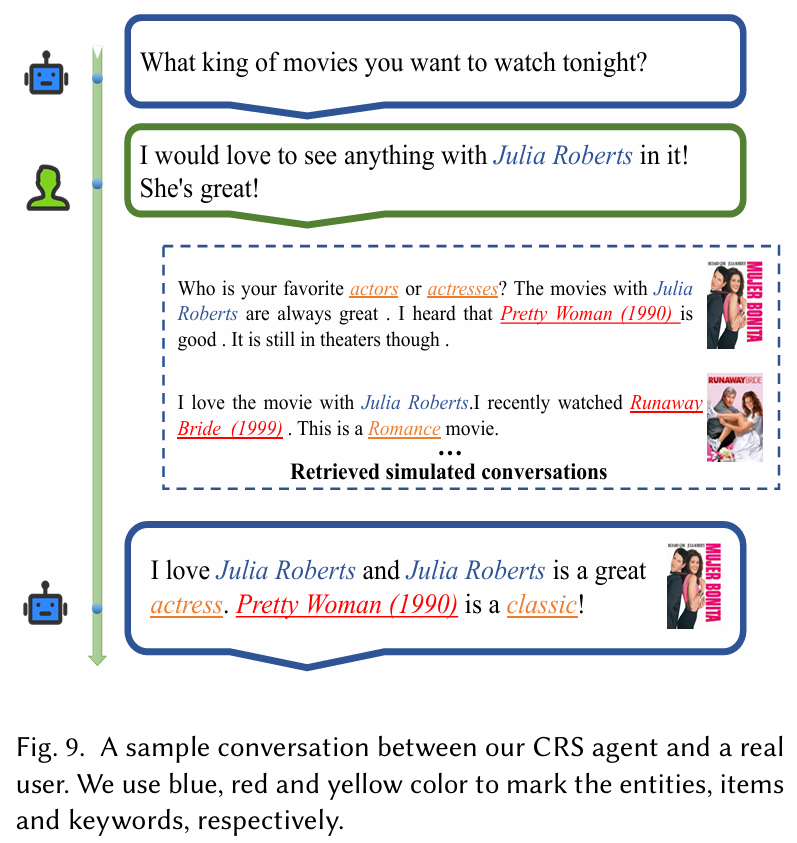
5.4 정성적 분석
사용자와 CRS 간의 대화 예시는 제안된 접근법의 효과를 보여준다. 사용자 요청에 대해 적절한 영화를 추천하는 과정에서, 시뮬레이션된 데이터셋을 활용하여 관련된 대화를 검색하고, 이를 통해 적합한 추천을 수행하였다. 이러한 실험 결과는 제안된 접근법이 대화형 추천 시스템에서 long-tail 문제를 완화하는 데 효과적임을 나타낸다.
6. Conclusion
본 논문에서는 대화형 추천 시스템(CRS)의 long-tail 추천을 향상시키기 위한 새로운 프레임워크인 LOT-CRS를 제안하였다.
LOT-CRS
- 균형 잡힌 CRS 데이터셋 시뮬레이션 : 데이터 부족 문제를 해결하기 위해, 공개적으로 수집된 아이템 속성을 활용하여 다양한 아이템이 고르게 포함된 CRS 데이터셋을 인위적으로 생성하는 과정이다. 이를 통해 long-tail 아이템 추천의 기반이 되는 데이터셋을 마련한다.
-
PLM 기반의 두 가지 사전 학습 과제 : 시뮬레이션된 데이터를 사용하여 두 가지 사전 학습 과제를 설계했다. 첫 번째는 도메인 적응형 마스크 예측(Domain-Adaptive Masked Prediction)으로, 대화 맥락을 이해하는 데 필요한 정보를 주입하는 역할을 한다. 두 번째는 대조적 문맥 정렬(Contrastive Context Alignment)로, 대화 맥락과 추천 아이템 간의 관련성을 강화한다.
-
검색 보강 학습 및 라벨 스무딩 전략 : 시뮬레이션된 데이터셋을 활용하여 long-tail 아이템의 추천 성능을 개선하는 방법이다. 검색 보강 학습은 유사한 대화를 검색하여 추천의 품질을 높이고, 라벨 스무딩은 모델의 예측을 부드럽게 하여 다양한 아이템을 추천할 수 있도록 한다.
이러한 접근법은 다양한 PLM 기반 CRS의 long-tail 추천 향상에 적용 가능하며, 광범위한 실험을 통해 여러 PLM 기반 CRS 방법의 성능을 높일 수 있음을 보여주었다.
