[논문] CoLLM: Integrating Collaborative Embeddings into Large Language Models for Recommendation
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
CoLLM: Integrating Collaborative Embeddings into Large Language Models for Recommendation [arxiv]
Yang Zhang IEEE TKDE 24
📝 Key Point
-
협업 정보 모델링의 중요성 : LLMRec의 추천 성능을 향상시키기 위해 협업 정보를 효과적으로 모델링하는 것이 중요하다는 점을 강조한다.
-
CoLLM의 개발 : CoLLM은 LLMRec을 위해 협업 정보를 통합하는 새로운 접근 방식으로, 전통적인 협업 모델을 LLM에 외부화하여 유연하고 효과적인 모델링을 가능하게 한다.
-
Warm & Cold 시나리오 : CoLLM은 warm 시나리오와 cold 시나리오 모두에서 LLM의 성능을 성공적으로 향상시키며, 협업 정보의 필요성을 입증한다.
Abstract
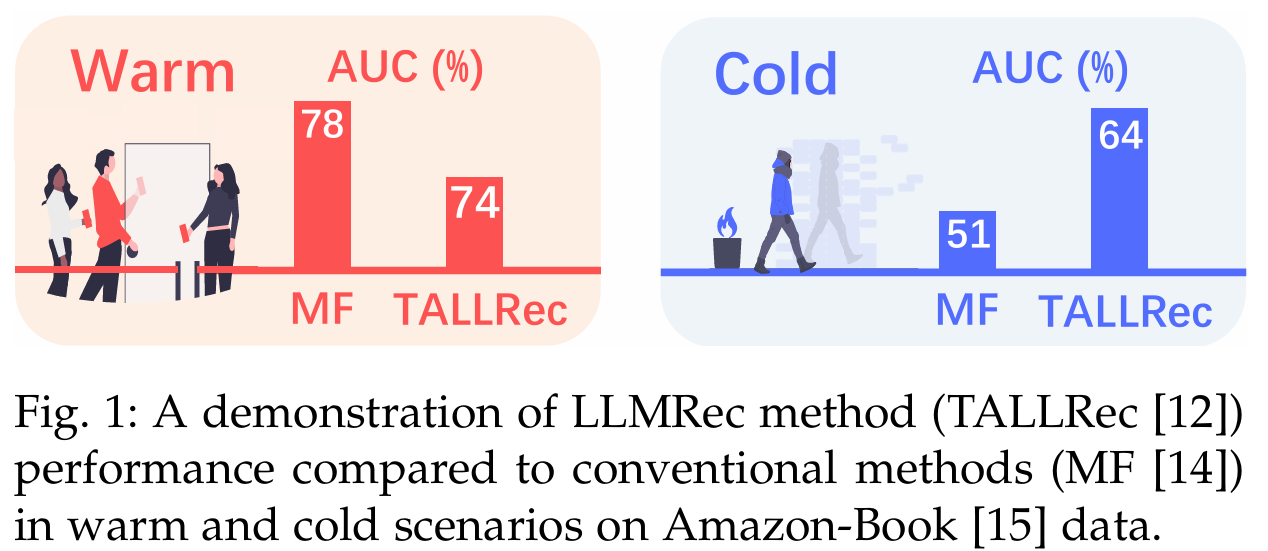
배경 : LLM을 추천 시스템에 활용하는 연구가 주목받고 있다. 기존의 LLMRec 접근법은 텍스트 의미에 중점을 둔다. 사용자-아이템 상호작용에서의 협업 정보를 간과하는 경향이 있다.
문제점 : 텍스트 중심의 접근법은 콜드 스타트 상황에서는 우수하다. 그러나 웜 스타트 상황에서는 최적의 성능을 내지 못할 수 있다.
제안 방법 : CoLLM이라는 혁신적인 LLMRec 방법론을 제안한다. CoLLM은 협업 정보를 외부의 전통적인 모델을 통해 캡처한다. 이를 LLM의 입력 토큰 임베딩 공간에 매핑하여 협업 임베딩을 생성한다.
특징 : 협업 정보의 외부 통합을 통해 LLM 자체를 수정하지 않고도 효과적으로 협업 정보를 모델링한다. 다양한 협업 정보 모델링 기법을 적용할 수 있는 유연성을 제공한다.
결과 : 광범위한 실험을 통해 CoLLM이 협업 정보를 LLM에 효과적으로 통합하여 추천 성능을 향상시킴을 입증한다.
Figure
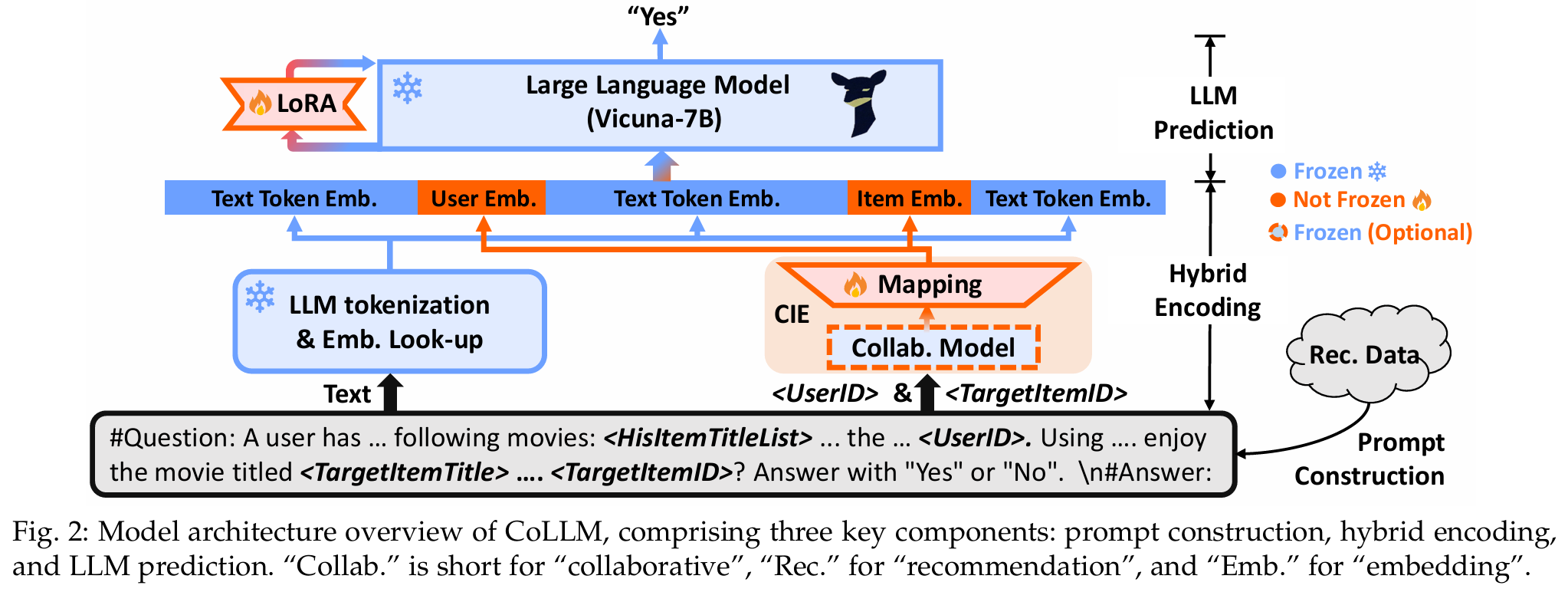
key components
- Prompt Construction
- Hybrid Encoding
- LLM Prediction
1. Introduction
LLM의 발전 : LLM인 GPT-3와 LLaMA는 빠른 발전을 이루었으며, 맥락 이해, 추론, 일반화, 세계 지식 모델링 등에서 뛰어난 성능을 보여준다. 이러한 능력은 다양한 분야에서 LLM을 탐색하고 활용하려는 열정을 불러일으켰다.
LLM 기반 추천 시스템 : 추천 시스템은 웹에서 개인화된 정보 필터링의 핵심 엔진으로, LLM의 발전으로부터 상당한 이익을 얻을 것으로 기대된다. LLM의 세계 지식과 맥락 이해 능력은 콜드 아이템 및 사용자 모델링을 향상시킬 수 있다. 이러한 기대는 LLM을 추천자로 활용하는 새로운 방향(LLMRec)을 제시한다.
기존 연구의 한계 : LLM을 추천자로 활용하기 위해 기존 연구들은 In-Context Learning에 의존하였다. 그러나 많은 연구 결과는 원래의 LLM이 정확한 추천을 제공하는 데 어려움을 겪고 있음을 나타낸다. 이는 특정 추천 작업에 대한 훈련 부족 때문이다. 이러한 문제를 해결하기 위해 LLM을 관련 추천 데이터로 추가적인 fine-tuning을 실시하는 노력이 증가하고 있다. 그럼에도 불구하고 이러한 방법들은 잘 훈련된 전통적인 추천 모델을 초월하지 못할 수 있으며, 특히 웜 사용자/아이템에 대한 성능이 저조할 수 있다.
In-Context Learning
In-Context Learning은 LLM이 특정 작업을 수행하기 위해 사전 훈련된 지식을 활용하는 방법이다. 이 접근법은 모델이 새로운 작업이나 질문에 대한 응답을 제공하기 위해 추가적인 훈련 없이 주어진 입력 맥락(context)만으로 학습하듯이 행동하는 것을 의미한다.
협업 정보의 중요성 : 기존 LLMRec 방법의 주요 한계는 사용자-아이템 상호작용에서의 협업 정보를 충분히 모델링하지 못한다는 점이다. 이 방법들은 사용자와 아이템을 텍스트 토큰으로 표현하며, 주로 텍스트 의미에 의존하여 협업 정보를 포착하는 데 한계가 있다. 협업 정보는 추천 성능에 유익하지만, 이러한 정보를 무시하면 성능 저하가 발생할 수 있다.
연구 문제 제안 : 따라서, 우리는 협업 정보를 LLM에 효율적으로 통합하여 콜드 및 웜 사용자/아이템 모두에 대해 성능을 최적화할 수 있는 방법을 제시하는 새로운 연구 문제를 제안한다.
문제 해결 접근법 : 협업 정보를 LLM에서 명시적으로 모델링하는 방법을 제안한다. 고전적인 협업 필터링 경험을 바탕으로, 사용자와 아이템을 나타내는 추가 토큰과 임베딩을 LLM에 도입하는 것이 간단한 해결책이 될 수 있다. 이는 latent factor 모델(e.g. Matrix Factorization)에서 사용자/아이템 임베딩이 수행하는 역할과 유사하다. 하지만 직접적으로 토큰 임베딩을 추가하면 대규모 추천에서 확장성이 감소하고 토큰화 중복성이 증가하여 정보 압축률이 낮아질 수 있다. 이는 협업 정보가 일반적으로 저랭크(low-rank) 특성을 가지므로 예측 작업을 더욱 어렵게 만들 수 있다.
low-rank
- rank : 랭크(rank)는 행렬의 선형 독립적인 행 또는 열의 최대 수를 나타내며, 해당 행렬이 정보를 얼마나 잘 표현하는지를 나타낸다. 랭크가 낮다는 것은 특정 행렬의 랭크가 전체 크기에 비해 상대적으로 낮은 경우를 의미한다.
- low-rank의 특징 : Low-rank 행렬은 데이터에서 중요한 패턴이나 구조를 포착하면서도 불필요한 노이즈를 줄일 수 있는 특성을 가진다. 이는 데이터 압축이나 차원 축소에 유용하게 사용된다.
- 추천 시스템 : 추천 시스템과 같은 분야에서는 사용자-아이템 상호작용 데이터를 low-rank 행렬로 모델링하여 사용자와 아이템 간의 잠재적인 관계를 파악하는 데 활용한다. 예를 들어, 행렬 분해 기법(e.g. Matrix Factorization)은 이러한 low-rank 특성을 이용하여 추천을 개선하는 방법이다.
CoLLM 제안 : 이러한 한계를 극복하기 위해 CoLLM을 제안한다. CoLLM은 협업 정보를 별도의 모달리티로 취급하며, 잘 훈련된 전통적인 협업 모델에서 MLP를 사용해 직접 매핑하여 LLM에 도입한다. CoLLM은 두 단계의 튜닝 과정을 사용한다. 첫째, 추천 작업을 학습하기 위해 언어 정보만을 사용하여 LLM을 fine-tuning한다. 둘째, 매핑 모듈을 튜닝하여 매핑된 협업 정보가 LLM의 추천에서 이해 가능하고 유용하도록 만든다.
장점 : 이 접근법은 기존 LLM과 유사한 확장성을 유지하면서도 다양한 협업 정보 모델링 메커니즘을 구현할 수 있는 유연성을 제공한다. 전통적인 모델의 지식을 LLM과 정렬함으로써 협업 정보를 효과적으로 통합할 수 있다.
주요 기여 :
- 협업 정보 모델링의 중요성을 강조하여 LLMRec이 웜 및 콜드 사용자/아이템 모두에서 잘 작동하게 한다.
- 외부 전통 모델의 능력을 활용하여 협업 정보를 LLM에 효과적으로 통합하는 CoLLM을 소개한다.
- 두 개의 실제 데이터셋에 대한 광범위한 실험을 수행하여 제안의 효과성을 입증한다.
3. Preliminaries
문제 정의
- 데이터셋 : 역사적 상호작용 데이터셋을 나타내며, 각 데이터 포인트는 로 구성된다.
- : 사용자, : 아이템, : 상호작용 레이블로, 로 표시된다.
- 텍스트 정보 : 아이템에 대한 추가 텍스트 정보가 제공되며, 주로 아이템 제목의 형태로 존재한다.
- 목표 : 상호작용 데이터와 텍스트 정보를 활용하여 LLM을 추천 용도로 fine-tuning하는 것이다. LLM이 텍스트 정보 외에 협업 정보를 효과적으로 활용할 수 있도록 하여, 웜 및 콜드 추천 시나리오에서 우수한 성능을 달성하는 것이 목표이다.
LLM
- 처리 과정
- 토큰화 및 임베딩 조회 : 입력 텍스트를 의미 있는 어휘 토큰으로 변환하고, 이를 벡터 공간에 임베딩한다.
- 맥락 모델링 및 출력 생성 (LLM 예측) : 주로 디코더 전용 트랜스포머 아키텍처를 기반으로 한 신경망을 사용하여 토큰 임베딩을 처리하고, 일관되고 맥락적으로 관련된 출력을 생성한다.
- 사용 모델 : 추천을 위해 Vicuna-7B 모델을 사용한다.
전통적인 협업 추천 모델
- 주요 접근법 : latent factor 모델(e.g. MF, LightGCN)을 통해 협업 정보를 인코딩한다. 이 방법들은 일반적으로 사용자와 아이템을 잠재 요인, 즉 임베딩으로 표현한다.
- 수식 : 각 샘플 에 대해 다음과 같이 표현된다.
- 여기서 는 사용자의 표현을 나타내며, 은 차원이다. 는 이 표현을 얻기 위한 과정을 나타내고, 는 모델 매개변수를 의미한다.
- 예측 과정 : 사용자 및 아이템 표현은 상호작용 모듈에 입력되어 예측을 생성하며, 실제 상호작용 레이블에 대한 예측 오류를 최소화함으로써 상호작용 데이터 내의 협업 정보를 인코딩하도록 학습한다.
4. Methodology
접근 방식
- 기존 모델 활용 : LLM을 직접 수정하는 대신, 전통적인 모델을 사용하여 협업 정보를 추출하고, 이 결과를 LLM이 이해하고 활용할 수 있는 형식으로 변환한다.
- 협업 정보 통합 : 최근 multi-modal LLM의 발전에 영감을 받아 협업 정보를 통합하는 방법을 제안한다. 이는 CoLLM 방법론의 기초가 된다.
4.1 Model Architecture
구성 요소
- Prompt Construction : 추천 데이터를 언어 프롬프트로 변환하는 단계.
- Hybrid Encoding : 생성된 프롬프트를 인코딩하고 LLM에 입력하여 추천을 생성하는 단계.
- LLM Prediction : 최종적으로 추천을 생성하는 단계.
혁신적인 접근
- 프롬프트 구성 : 텍스트 설명 외에 사용자 및 아이템 ID 필드를 추가하여 협업 정보를 나타낸다.
- 프롬프트 인코딩 : LLM의 토큰화 및 텍스트 정보 인코딩 외에, 전통적인 협업 모델을 사용하여 사용자/아이템 표현을 생성하고 이를 LLM의 토큰 임베딩 공간으로 매핑한다.
- 텍스트 정보와 협업 정보를 토큰 임베딩 공간 내에서 함께 표현한 후, LLM은 두 가지 유형의 정보를 활용하여 추천을 수행할 수 있다.
4.1.1 Prompt Construction
-
고정 프롬프트 템플릿 : 프롬프트 생성을 위해 고정된 템플릿을 활용한다. 이는 TALLRec과 유사한 접근 방식이다.
-
아이템 설명 : 아이템은 제목을 사용하여 설명한다.
-
사용자 설명 : 사용자는 과거 상호작용에서의 아이템 제목을 통해 설명된다.
-
협업 정보 통합 : 협업 정보를 통합하기 위해 의미를 가지지 않은 사용자 및 아이템 ID 관련 필드를 도입한다. 이 필드는 프롬프트 내에서 협업 정보를 위한 자리 표시자 역할을 한다.

user and item ID-related fields
- ⟨HisItemTitleList⟩ : 사용자가 상호작용한 아이템 제목의 목록으로, 상호작용 타임스탬프에 따라 정렬되어 사용자의 선호를 설명한다.
- ⟨TargetItemTitle⟩ : 예측할 대상 아이템의 제목을 나타낸다.
- ⟨UserID⟩, ⟨TargetItemID⟩ : 각각 사용자 및 아이템 ID를 나타내며, 협업 정보를 주입하는 데 사용된다.
-
의미적 일관성 유지 : 사용자 및 아이템 ID를 통합하면서 의미적 일관성을 유지하기 위해, 이들을 프롬프트 내에서 사용자/아이템의 특성(feature)으로 간주한다.
-
샘플 기반 프롬프트 구성 : 각 추천 샘플에 대해, 네 개의 필드를 샘플의 해당 값으로 채워 샘플 특정 프롬프트를 구성한다.
4.1.2 Hybrid Encoding
-
목적 : 입력 프롬프트를 LLM 처리를 위한 잠재 벡터(임베딩)로 변환하는 데 사용된다. 텍스트 및 협업 정보를 효과적으로 통합하여 LLM이 추천을 수행할 수 있도록 한다.
-
접근 방식 : 하이브리드 인코딩 방식을 채택한다.
-
텍스트 콘텐츠 처리 : 모든 텍스트 콘텐츠에 대해 LLM의 내장된 토큰화 및 임베딩 메커니즘을 활용하여 텍스트를 토큰으로 변환하고, 이후 토큰 임베딩으로 변환한다.
-
사용자 및 아이템 ID 처리 : "⟨UserID⟩" 및 "⟨TargetItemID⟩" 필드에 대해서는 전통적인 협업 추천 모델로 구성된 CIE(Collaborative Information Encoding) 모듈을 사용하여 협업 정보를 추출한다.
-
프롬프트 토큰화 : 샘플 에 해당하는 프롬프트를 LLM 토크나이저를 사용하여 토큰화한다. 토큰화 결과는 다음과 같이 표현된다.
여기서 는 텍스트 토큰을 의미하며, 는 "⟨UserID⟩"/"⟨TargetItemID⟩" 필드에 배치된 사용자/아이템 ID를 나타낸다.
-
임베딩 시퀀스 : 프롬프트를 임베딩 시퀀스로 인코딩한다.
- : LLM에서 에 대한 토큰 임베딩.
- : 사용자 및 아이템 에 대한 협업 정보 임베딩.
-
CIE 모듈
-
구성 요소 : CIE 모듈은 전통적인 협업 모델()과 매핑 레이어()로 구성된다.
-
기능 : 사용자 와 아이템 를 제공받아 협업 정보를 인코딩한 사용자 및 아이템 ID 표현( 및 )을 생성한다. 이후 매핑 레이어는 이러한 표현을 LLM의 토큰 임베딩 공간으로 매핑하여 최종 잠재 협업 임베딩( 및 )을 생성한다.
-
협업 정보 추출 과정 : 협업 정보 추출 과정은 다음과 같이 표현된다.
여기서 는 사용자 표현을 나타내며, 은 차원이다.
-
협업 모델 구현 : CIE 모듈은 전통적인 협업 추천 모델로 구현될 수 있다.
-
매핑 레이어 구현 : 매핑 레이어는 MLP로 구현되며, 입력 크기는 사용자/아이템의 차원 과 같고, 출력 크기는 LLM 임베딩 크기 와 같다. (보통 )
-
4.1.3 LLM Prediction
-
입력 프롬프트 임베딩 : 입력된 프롬프트가 임베딩 시퀀스 로 변환된 후, LLM은 이를 사용하여 예측을 생성할 수 있다.
-
LLM의 한계 : LLM은 특정 추천 작업에 대한 훈련이 부족하기 때문에, LLM에만 의존하지 않고 추가적인 모듈을 도입한다.
-
LoRA 모듈 도입 : 추천 예측을 수행하기 위해 LoRA(Low-Rank Adaptation) 모듈을 추가한다. 이 모듈은 LLM의 원래 가중치에 랭크 분해 가중치 행렬(rank-decomposition weight matrices) 쌍을 추가하는 방식으로 구현된다.
-
목적: 새로운 작업(추천)을 학습하기 위해 몇 개의 매개변수만을 도입하면서도 효과적으로 학습할 수 있도록 한다.
-
예측 수식 : 예측은 다음과 같이 수식화된다.
- 여기서 는 레이블이 1일 확률, 즉 LLM이 "Yes"라고 대답할 가능성을 나타낸다.
- 는 사전 훈련된 LLM의 고정 모델 매개변수를 나타내고, 는 추천 작업을 위한 학습 가능한 LoRA 매개변수를 의미한다.
-
Plug-in 접근법 : LoRA를 사용함으로써, 추천 작업을 학습하기 위해 LoRA 가중치만 업데이트하면 되므로 파라미터 효율적인 학습이 가능하다.
LoRA (Low-Rank Adaptation)
LoRA는 LLM과 같은 복잡한 모델을 효율적으로 튜닝하기 위한 기법이다.
- 저랭크 튜닝 : LoRA는 모델의 기존 가중치에 저랭크의 행렬을 추가하여 새로운 작업(e.g. 추천, 특정 응용 분야 등)을 학습할 수 있도록 한다. 이렇게 하면 전체 모델을 수정하지 않고도 특정 작업에 맞게 튜닝할 수 있다.
- 파라미터 효율성 : LoRA는 기존의 대형 모델에 비해 상대적으로 적은 수의 추가 매개변수를 사용하여 학습할 수 있다. 이는 훈련 시간과 자원 소비를 줄이는 데 기여한다.
- 플러그인 방식 : LoRA는 기존 모델에 플러그인 형태로 추가되어, 기존의 모델 구조를 유지하면서도 새로운 기능을 학습할 수 있게 한다.
- 적용 범위 : LoRA는 다양한 자연어 처리 작업에 적용될 수 있으며, 특히 한정된 데이터로도 효과적으로 학습할 수 있는 장점이 있다.
4.2 Tuning Method
-
매개변수 훈련 : 모델 매개변수를 훈련하기 위해 LLM(임베딩 레이어 포함)을 고정하고, plug-in LoRA 모듈과 CIE 모듈의 튜닝에 집중한다.
- CIE 모듈 : 협업 정보를 추출하고 LLM이 추천에 사용할 수 있도록 변환하는 역할.
- LoRA 모듈 : LLM이 추천 작업을 학습하도록 지원.
-
문제점과 제안 방법 : 협업 정보에 대한 의존성이 크기 때문에 두 모듈을 동시에 훈련하면 콜드 시나리오에서 LLM 추천 성능이 저하될 수 있다. 두 단계 튜닝 접근법을 통해 각 구성 요소를 개별적으로 튜닝한다.
Step 1 : LoRA 모듈 튜닝
-
목적 : LLM의 콜드 스타트 추천 기능을 부여하기 위해 LoRA 모듈을 독립적으로 튜닝한다.
-
프로세스 : 협업 정보 관련 부분을 제외하고 텍스트 전용 세그먼트만 사용하여 예측을 생성하고 예측 오류를 최소화한다.
-
수식 표현 :
- 여기서 는 텍스트 전용 프롬프트에 대한 임베딩 시퀀스, 은 이진 교차 엔트로피(BCE) 손실을 나타낸다.
Step 2 : CIE 모듈 튜닝
-
목적 : CIE 모듈이 협업 정보를 효과적으로 추출하고 매핑하도록 학습한다.
-
프로세스 : 협업 정보가 포함된 프롬프트를 사용하여 예측을 생성하고 CIE 모델을 튜닝하여 예측 오류를 최소화한다.
-
수식 표현 :
- 여기서 는 전체 프롬프트에 대한 임베딩 시퀀스, 는 CIE 모듈의 모델 매개변수이다.
-
매개변수 튜닝 방식
-
: 매핑 레이어 만 튜닝하며, 잘 훈련된 협업 모델 를 사용.
- 매핑 함수 튜닝에만 집중하므로 더 빠를 수 있다.
-
: 협업 모델 와 매핑 레이어 를 모두 튜닝.
- 협업 정보를 LLM에 더 매끄럽게 통합할 수 있어 성능 향상 가능성이 있다.
-
- 위 두 단계는 한 번만 수행된다.
- Step 2에서는 LoRA를 튜닝하지 않고 CIE 모듈만 튜닝한다. 첫 번째 단계 후 LLM은 이미 추천 작업을 수행할 수 있는 능력을 갖추고 있으며, 협업 정보는 매핑된 상태에서 LLM이 추천을 수행할 수 있도록 활용되기 때문이다.
4.3 Discussion
Relation to Soft Prompt Tuning
-
비교 : LoRA 모듈 없이 우리의 방법은 추천 시스템에서 소프트 프롬프트 튜닝의 변형으로 볼 수 있으며, 협업 임베딩이 소프트 프롬프트 역할을 한다.
-
차별점 :
- low-rank 특성 : LLM이 사용하는 소프트 프롬프트는 전통적인 협업 모델의 low-rank 표현에서 파생되어 low-rank 특성을 유지한다.
- 추가적인 지침 제공 : 협업 모델이 소프트 프롬프트 학습에 대한 가치 있는 제약 조건과 사전 조건을 제공하여 협업 정보를 보다 효과적으로 캡처하고 개인화된 정보를 인코딩하는 데 추가적인 지침을 제공한다.
Hard Prompt
- 고정된 텍스트 : 하드 프롬프트는 특정 태스크를 수행하기 위해 사용자가 명시적으로 작성한 고정된 텍스트이다.
- 수동 설정 : 하드 프롬프트는 사용자가 직접 설정해야 하며, 태스크에 따라 다양한 형식으로 작성할 수 있다.
- 일반화의 한계 : 하드 프롬프트는 특정 태스크에 맞게 작성되기 때문에 다른 태스크로의 일반화가 어려울 수 있다.
Soft Prompt
- 학습 가능한 벡터 : 소프트 프롬프트는 고정된 텍스트 대신 학습 가능한 파라미터로 구성된 벡터이다. 이 벡터는 모델이 특정 태스크에 대해 최적화된 방식으로 반응하도록 유도한다.
- 자동 튜닝 : 소프트 프롬프트는 데이터에 기반하여 모델이 자동으로 튜닝될 수 있습니다. 이는 사용자가 수동으로 프롬프트를 설계할 필요 없이, 모델이 학습 과정에서 최적의 프롬프트를 찾아내는 것을 의미한다.
- 전이 학습 가능 : 소프트 프롬프트는 다양한 태스크에서 사용할 수 있으며, 특정 작업에 대한 성능을 개선하는 데 더 유연하다. 이는 모델의 일반화 능력을 향상시키는 데 기여한다.
비교
- 하드 프롬프트는 고정된 텍스트로 수동 설정되며, 특정 태스크에 맞춰 작성되어 일반화에 한계가 습니다.
- 소프트 프롬프트는 학습 가능한 벡터로 자동 조정되며, 다양한 태스크에 대해 유연하고 일반화 능력이 뛰어나다.
Inference Efficiency
-
문제 인식 : LLMRec, 특히 CoLLM의 상대적으로 높은 계산 비용은 실제 응용에 장애가 될 수 있다.
-
가속화 기술 : LLM을 위한 다양한 가속화 기술이 등장하고 있으며, 캐싱 및 재사용과 같은 방법들이 유망한 결과를 보여준다. CoLLM도 이러한 기술을 활용하여 추론 효율성을 향상시킬 수 있다.
-
미래 연구 방향 : 협업 정보를 통합하여 추천 품질을 향상시키는 것이 목표인 만큼, 가속화 방법의 탐색은 향후 연구에 위임된다.
-
CoLLM의 경량성 : 기존 LLMRec 방법들(e.g. TALLRec)와 비교할 때, CoLLM은 CIE 모듈만 도입한다. CIE 모듈은 LLM에 비해 훨씬 작으며, LLM의 업데이트 없이 훈련이 이루어진다. 따라서 CoLLM은 훈련 및 추론 과정에서 과도한 추가 오버헤드를 발생시키지 않는다.
5. Experiments
RQ1 : Can our proposed CoLLM effectively augment LLMs with collaborative information to improve recommendation, in comparison to existing methods?
CoLLM이 협업 정보를 통해 LLM의 추천 성능을 개선할 수 있는가?
RQ2 : What impact do our design choices have on the performance/efficiency of the proposed method? How does the method perform on other datasets and LLM backbones?
설계 선택이 제안된 방법의 성능 및 효율성에 미치는 영향은 무엇인가?
5.1 Experimental Settings
데이터셋
-
ML-1M : 영화 추천 데이터셋으로, 2000-2003년 동안 수집된 사용자 영화 평가로 구성된다. 평점 3 이상을 "긍정"(y = 1)으로, 나머지는 "부정"(y = 0)으로 변환한다. 최근 20개월의 상호작용을 기준으로 훈련(10개월), 검증(5개월), 테스트(5개월) 세트로 분할한다.
-
Amazon-Book : 아마존의 도서 추천 데이터셋으로, 1996-2018년 사이의 사용자 리뷰를 포함한다. 리뷰 점수 4 이상을 "긍정"으로 변환한다. 2017년의 상호작용을 기준으로 훈련(11개월)과 검증 및 테스트(각각 2개월) 세트로 분할한다.
5.1.1 Evaluation Metrics
- AUC : ROC 곡선 아래 면적으로, 전체 예측 정확도를 정량화한다.
- UAUC : User-based Area Under the Curve, 각 사용자에 대해 AUC를 계산한 후 평균하여 사용자 단위의 순위 품질을 제공한다.
5.1.2 Compared Methods
-
전통적인 협업 방법 : MF, LightGCN
-
언어 모델과 협업 모델 결합 방법 : SASRec, DIN, CTRL(DIN)
-
LLMRec 방법 : ICL, Prompt4NR, TALLRec
-
MF : Matrix Factorization, 잠재 요인 기반 협업 필터링 방법 중 하나이다.
-
LightGCN : 사용자 관심 모델링을 향상시키기 위해 간소화된 그래프 컨볼루션 신경망을 활용하는 대표적인 그래프 기반 협업 필터링 방법이다.
-
SASRec : 사용자 관심을 모델링하기 위해 순차적 패턴을 인코딩하는 self-attention 네트워크를 사용하는 대표적인 순차 추천 방법이다. 이는 순차 정보를 고려하는 협업 방법으로 볼 수 있다.
-
DIN : 특정 아이템에 대한 사용자 관심을 학습하기 위해 가장 관련성 높은 사용자 행동을 활성화하는 attention 메커니즘을 사용하는 대표적인 협업 클릭률(CTR) 모델이다.
-
CTRL(DIN) : 지식 증류를 통해 언어 모델과 협업 모델을 결합하는 SOTA 방법으로, 협업 모델로 DIN을 활용한다.
-
ICL : In-Context Learning, LLM의 In-Context 학습 능력을 기반으로 하는 LLMRec 방법으로, 프롬프트를 사용하여 원래 LLM에 직접 추천을 요청한다.
-
Prompt4NR : 고정 프롬프트와 소프트 프롬프트를 모두 사용하여 전통적인 언어 모델(e.g. BERT)을 추천 목적으로 활용하는 SOTA 방법이다. 이 방법을 Vicuna-7B에 확장하여 공정한 비교를 위해 LLM을 LoRA로 튜닝하여 계산 비용을 관리한다.
-
TALLRec : 지시 튜닝을 통해 LLM과 추천을 정렬하는 최첨단 LLMRec 방법으로, Vicuna-7B에서 구현된다.
5.1.3 ImplementationDetails
- 프레임워크 : 모든 방법을 PyTorch 2.0으로 구현한다.
- 손실 함수 : Binary Cross-Entropy (BCE)를 사용한다.
- 최적화 알고리즘 : 대형 언어 모델에는 AdamW, 기타 모델에는 Adam을 사용한다.
- 하이퍼파라미터 튜닝 :
- 학습률 : [1e-2, 1e-3, 1e-4] 범위
- 임베딩 크기 : [64, 128, 256] 범위
- 가중치 감소 : LLM 기반 방법에 대해 1e-3, 다른 모델에 대해 [1e-2, 1e-3, ..., 1e-7] 범위로 튜닝한다.
- SASRec : 최대 상호작용 시퀀스 길이를 훈련 데이터의 평균 사용자 상호작용 수에 따라 설정한다.
- TALLRec : 모든 방법에 대해 최대 시퀀스 길이를 10으로 설정한다.
- DIN 및 CTRL(DIN) : 드롭아웃 비율과 숨겨진 레이어 크기를 추가로 튜닝한다.
5.2 Performance Comparison (RQ1)
5.2.1 Overall Performance
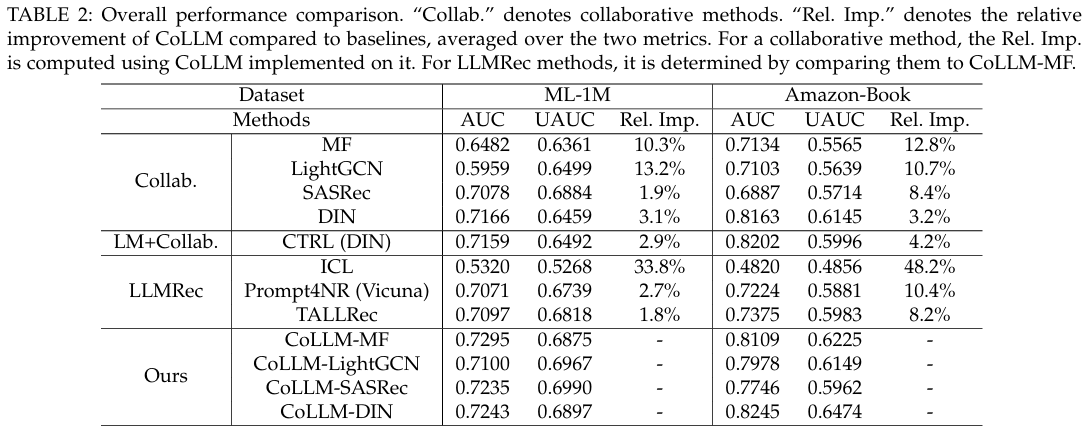
- CoLLM의 성능 : CoLLM은 두 데이터셋에서 모든 비교 방법 중 최고의 성능을 보이며, 이는 협업 정보를 통합한 접근 방식의 우수성을 입증한다.
- LLMRec 방법과의 비교 : LLMRec의 최상의 기준선인 TALLRec은 대체로 MF, LightGCN, SASRec보다 우수하지만 DIN에는 미치지 못한다. 그러나 CoLLM을 통해 LLMRec에 협업 정보를 도입한 결과, LLM의 성능이 일관되게 향상되었다(단, 아마존 북의 SASRec에 대한 UAUC 제외). 이는 협업 정보의 필요성을 강조한다.
- LLMRec 방법의 성능 : ICL 방법은 일관되게 가장 낮은 성능을 보이며, 이는 LLM의 추천에 대한 내재적 한계를 보여준다. Prompt4NR는 LLM을 fine-tuning하면서 적응 가능한 프롬프트를 포함하지만, 여전히 CoLLM의 성능에는 미치지 못하며 TALLRec보다도 뒤처진다. 이는 CoLLM의 성능 향상이 협업 정보 모델링에 기인함을 시사한다.
- CTRL 접근법 : LM과 협업 모델을 통합하는 CTRL은 한 지표를 향상시키면 다른 지표에는 부정적인 영향을 미친다. 이는 LM의 강점과 협업 정보를 효과적으로 활용하는 데 한계가 있음을 나타낸다. CoLLM은 이러한 한계를 극복하여 성능을 지속적으로 개선한다.
- CIE 모듈의 효과 : CoLLM의 CIE 모듈은 다양한 협업 모델과 함께 구현되었을 때, 일관되게 성능 향상을 보여주며, CoLLM의 성능은 해당 협업 모델의 성능과 긍정적인 상관관계를 가진다.
Ensemble

- MF와 TALLRec 모델을 앙상블하여 CoLLM-MF 접근 방식과 비교하고, CoLLM-MF와 MF의 추가 앙상블 효과를 조사했다.
- MF와 TALLRec의 앙상블은 CoLLM-MF에 비해 성능이 저조했지만, CoLLM-MF에 앙상블 평균을 적용하면 약간의 성능 향상이 있었다.
- CoLLM의 협업 정보와 LLM 통합 메커니즘은 단순한 앙상블 기법을 초월하여 LLM의 기능을 효과적으로 활용함을 보여준다. CoLLM-MF 접근 방식이 더 우수한 성능을 나타낸다.
5.2.2 Performance in Warm and Cold Scenarios
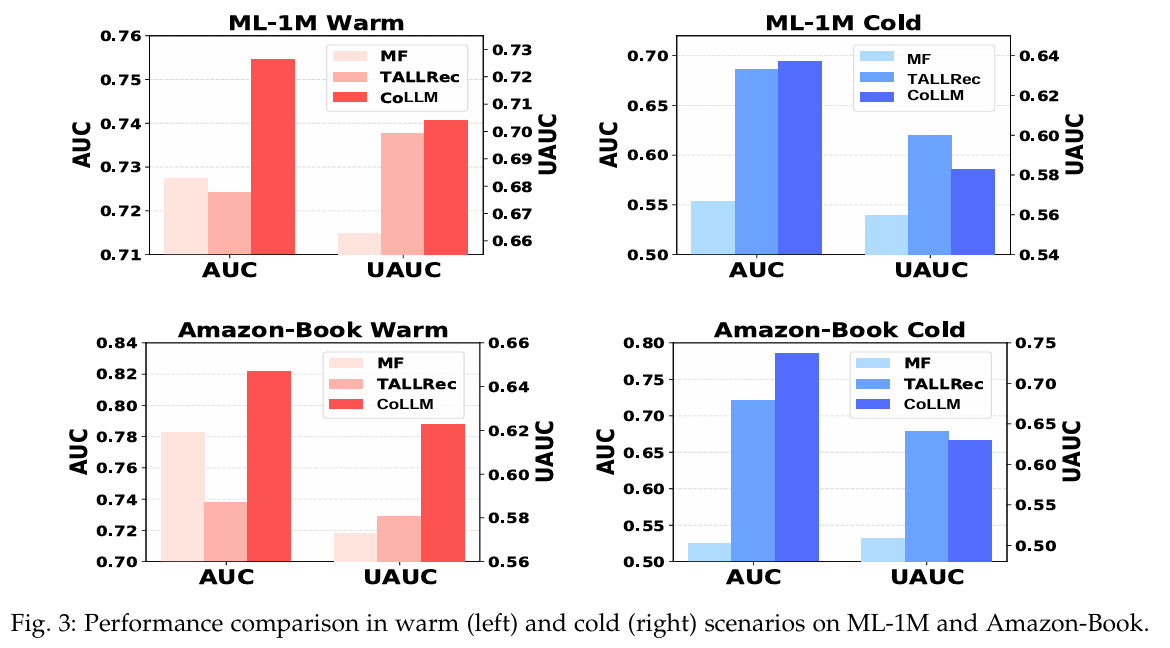
-
Warm 시나리오 : TALLRec는 MF에 비해 낮은 AUC 점수를 보이며, MF는 CoLLM에 비해 낮다. UAUC 측면에서는 MF가 TALLRec에 미치지 못하고, TALLRec는 CoLLM에 뒤처진다. 이는 기존 LLMRec 방법이 Warm 시나리오에서 단점이 있음을 시사하며, 협업 정보를 도입하면 성능이 개선될 수 있음을 보여준다.
-
Cold 시나리오 : TALLRec와 CoLLM은 모두 MF보다 우수한 성능을 보이며, CoLLM은 TALLRec와 유사한 성능을 유지한다. 이는 CoLLM이 Cold 시나리오에서도 LLMRec의 강점을 효과적으로 활용하고 있음을 나타낸다.
종합적으로, CoLLM은 Warm 시나리오에서 TALLRec에 비해 상당한 성능 개선을 보이며, Cold 시나리오에서도 능력을 유지하고 있다. 이는 협업 정보를 성공적으로 통합하여 LLMRec가 두 시나리오 모두에서 효과적으로 작동하도록 하는 CoLLM의 목표를 강조한다.
5.3 In-depth Analysis (RQ2)
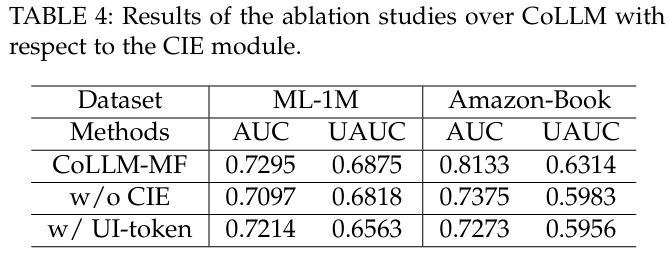
5.3.1 The Effect of CIE Module
- CIE 모듈의 중요성 : CoLLM의 성능에 대한 CIE 모듈의 영향을 평가하기 위해, CoLLM-MF와 두 가지 변형을 비교한다.
- "w/o CIE" : CIE 모듈을 생략한 변형 (TALLRec와 동일).
- "w/ UI-token" : CIE 모듈을 생략하고 사용자와 아이템을 직접 나타내는 토큰 및 임베딩을 사용하는 변형.
- 비교 결과 : "w/o CIE" 변형은 CoLLM보다 낮은 성능을 보이며, "w/ UI-token" 변형도 CoLLM보다 성능이 낮고, 오히려 CIE 없이 모델링한 경우보다 더 나쁜 성능을 기록한다. 이는 LLM에서 직접 토큰을 도입하는 것이 협업 정보를 효과적으로 포착하지 못함을 시사한다. CIE 모듈은 협업 정보를 저차원 상태로 유지하여 중복성을 줄이고 성능을 향상시킨다.
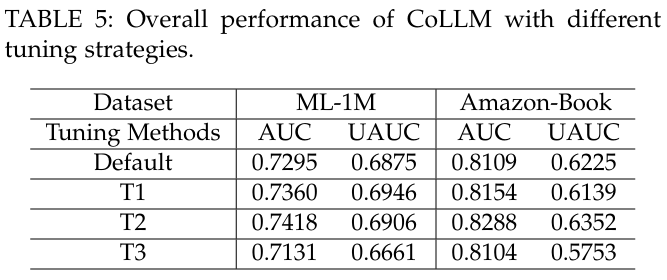
5.3.2 The Influence of Tuning Choices
-
튜닝 전략 : CoLLM의 성능에 대한 훈련 선택의 영향을 분석한다. 기본적으로 두 단계 튜닝 전략을 사용하며, 첫 번째 단계에서 LoRA 모듈을 학습하고, 두 번째 단계에서 CIE 모듈의 매핑 레이어를 튜닝한다.
-
추가 튜닝 전략:
- T1 : 기본 두 단계 튜닝과 동일하나, 전체 CIE 모델을 튜닝.
- T2 : 기본 두 단계 튜닝을 따르지만, CIE 모델을 처음부터 튜닝.
- T3 : 한 단계 튜닝 접근법으로 LoRA 모듈과 CIE의 매핑 레이어를 동시에 튜닝.
-
비교 결과 : 두 단계 업데이트 프레임워크 내에서 T1과 T2는 성능 향상을 가져오지만, 추가적인 계산 비용과 느린 수렴 속도를 초래한다. T3는 상대적으로 낮은 성능을 보이며, 특히 Cold 시나리오에서 성능 저하가 두드러진다. 이는 첫 번째 단계에서 텍스트 전용 데이터를 사용하여 추천 작업을 학습하는 것이 중요함을 강조한다.
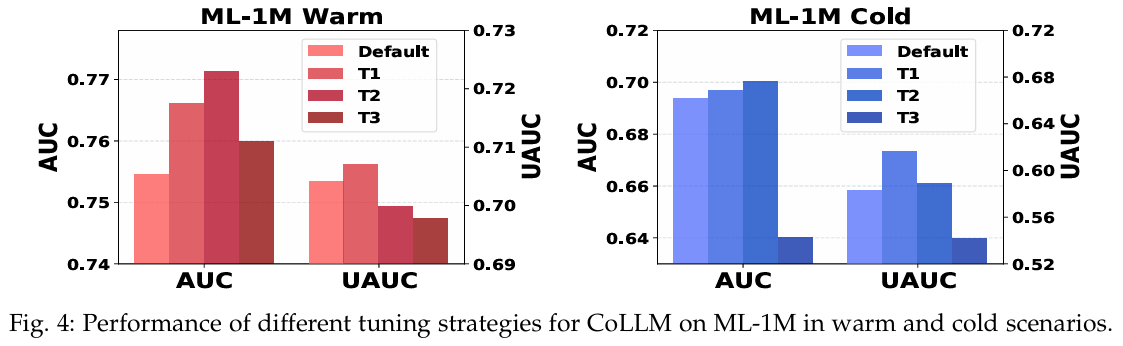
5.3.3 Efficiency
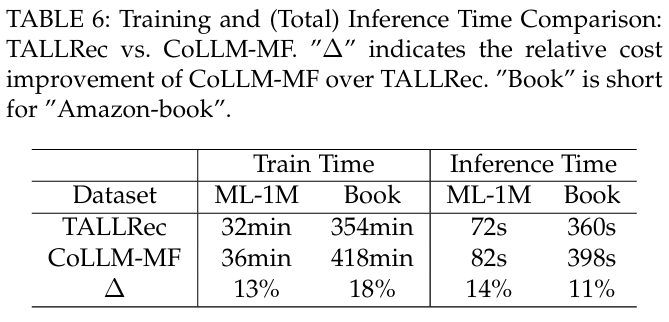
-
효율성 문제 : LLMRec의 효율성 문제를 조사한다. CIE 모듈의 훈련에서 추가 비용이 발생하지만, 협업 모듈의 사전 훈련 덕분에 CoLLM은 TALLRec에 비해 훈련 시간의 증가가 약 15.5%에 불과하다.
-
추론 비용 : CIE 모듈의 비용은 LLM에 비해 미미할 것으로 예상되며, 추가 토큰이 필요하지만 전체 프롬프트의 일부에 불과하다. CoLLM은 평균적으로 총 추론 비용이 12.5% 증가한다.
5.3.4 Method Generalization
-
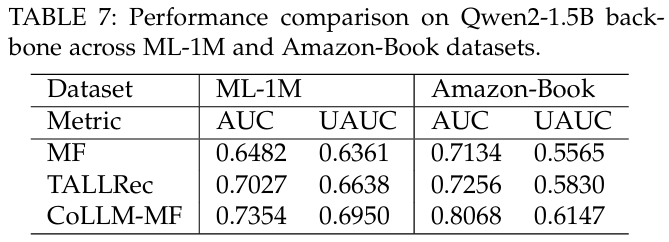
다른 LLM 백본 : Qwen2-1.5B 백본을 사용하여 CoLLM-MF와 TALLRec의 성능을 비교한 결과, CoLLM이 항상 TALLRec와 MF를 초과하는 성능을 보인다. 이는 다양한 LLM 백본에서의 일반적인 적용 가능성을 보여준다.
-
다른 데이터셋 : 아마존 데이터셋의 비디오 게임 및 CDs & Vinyl 데이터셋을 포함하여 CoLLM-MF의 성능을 MF 및 TALLRec와 비교한 결과, 협업 정보를 통합함으로써 LLMRec를 효과적으로 향상시킬 수 있음을 나타낸다. 비디오 게임 데이터셋에서 AUC 값은 MF: 0.6161, TALLRec: 0.7356, CoLLM-MF: 0.7440이며, CDs & Vinyl 데이터셋에서는 MF: 0.6957, TALLRec: 0.6607, CoLLM-MF: 0.7237로 나타났다. 이는 다양한 데이터셋에서 제안된 방법의 일관된 우수성을 나타낸다.
6. Conclusion
-
협업 정보 모델링의 중요성 : 본 연구에서는 LLMRec의 추천 성능 향상을 위해 협업 정보 모델링의 중요성을 강조하며, 특히 warm 시나리오에서 그 효과를 부각시킨다.
-
CoLLM 소개 : CoLLM은 LLMRec을 위한 협업 정보를 통합하는 새로운 접근 방식으로, 전통적인 협업 모델을 LLM에 외부화하여 효과적인 협업 정보 모델링을 보장하고, 모델링 메커니즘을 튜닝하는 유연성을 제공한다.
-
실험 결과 : 광범위한 실험 결과는 CoLLM의 효과성과 적응성을 입증하며, LLM이 Warm 시나리오와 Cold 시나리오 모두에서 우수한 성능을 발휘할 수 있도록 한다.
-
미래 연구 방향 :
- 현재 실험은 Vicuna-7B에서만 진행되었으며, 향후 다른 LLM을 탐색할 계획이다.
- 실제 세계에서의 협업 정보의 변화하는 특성을 고려하여 CoLLM의 점진적 학습 능력을 조사할 예정이다.
