[논문] Representation Learning with Large Language Models for Recommendation
논문 읽기 스터디 "추천이 쪼아 LLM"
목록 보기
9/16
📄 Paper
Representation Learning with Large Language Models for Recommendation [arxiv]
Xubin Ren WWW 24
📝 Key Point
-
RLMRec 프레임워크 : RLMRec은 LLM을 활용하여 추천 시스템의 표현 성능을 향상시키는 모델 비종속적인 프레임워크이다.
-
대조적/생성적 정렬 기술 : CF 측 관계 임베딩과 LLM 측 semantic 표현을 정렬하여 노이즈를 줄이고 추천 성능을 향상시킨다.
-
협력 프로파일 생성 : RLMRec은 협력 프로파일 생성 패러다임을 도입하여, 사용자와 아이템 간의 관계를 효과적으로 모델링한다.
-
추론 기반 시스템 프롬프트 : RLMRec은 생성된 출력에서 추론 과정을 포함함으로써, 추천의 품질을 높이고 사용자 요구에 더 잘 부합하는 정보를 제공한다.
Abstract
배경 및 문제점
- 추천 시스템은 딥러닝과 그래프 신경망의 발전으로 사용자-아이템 관계를 효과적으로 포착하는 데 큰 발전을 이루었다.
- 그러나 그래프 기반 추천 시스템은 ID 기반 데이터에 의존하여 텍스트 정보를 간과한다.
- 또한, implicit feedback 데이터의 사용이 노이즈와 편향을 초래한다.
기존 연구의 한계
- LLM을 전통적인 ID 기반 추천 시스템에 통합하는 연구가 주목받고 있다.
- 그러나 확장성 문제, 텍스트 의존성의 한계, 프롬프트 입력 제약 등의 문제를 해결해야 한다.
제안된 접근법
- RLMRec이라는 모델에 구애받지 않는 프레임워크를 제안한다.
- RLMRec은 LLM을 활용한 표현 학습을 통해 기존 추천 시스템을 개선하는 것을 목표로 한다.
방법론
- 보조 텍스트 신호를 통합한다.
- LLM을 통한 사용자/아이템 프로파일링을 수행한다.
- 협업 관계 신호와 LLM의 semantic 공간을 cross-view alignment를 통해 통합한다.
- 텍스트 신호 통합에 대한 이론적 기초를 상호 정보 극대화를 통해 증명하며, 표현의 질을 향상시킨다.
평가 방법
- RLMRec를 SOTA 추천 모델과 통합하여 노이즈 데이터에 대한 효율성과 강건성을 분석한다.
Figure
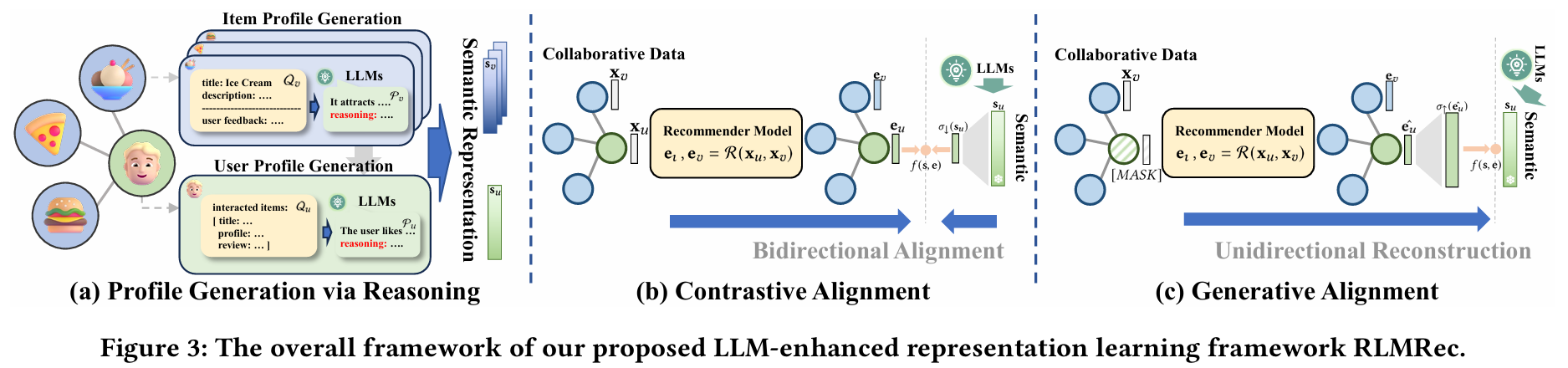
1. Introduction
배경
- 추천 시스템은 사용자 상호작용을 기반으로 개인화된 아이템 추천을 제공하기 위해 발전한다.
- 딥러닝과 그래프 신경망이 중요한 역할을 하며, NGCF와 LightGCN과 같은 그래프 기반 추천 시스템은 복잡한 사용자-아이템 관계를 효과적으로 포착한다.
문제점
- 최근 그래프 기반 추천 시스템은 학습을 위해 ID에 해당하는 정보에 크게 의존한다.
- 훈련 데이터는 사용자/아이템 인덱스와 이진 상호작용으로만 구성되며, 이는 텍스트 정보와 같은 중요한 데이터를 간과할 수 있다.
- 많은 데이터가 implicit feedback으로 구성되어 있으며, 이는 false negative나 편향(e.g. misclick, popularity bias)으로 노이즈를 유발할 수 있다.
False Negative
- False Negative는 실제로 사용자가 선호할 가능성이 있는 아이템이 추천되지 않는 경우를 의미한다. 즉, 사용자가 좋아할 만한 아이템이 추천 목록에서 누락되는 상황이다.
Popularity Bias
- Popularity Bias는 추천 시스템이 인기 있는 아이템을 선호하여 추천하는 경향을 의미한다. 즉, 사용자에게 추천되는 아이템이 대중적으로 인기가 있는 것들로 편향되는 현상이다.
기존 연구의 한계
- LLM의 출현이 추천 시스템의 가능성을 확장할 수 있지만, 기존 방법은 효율성과 정확성에서 부족하다.
- 주요 문제는 다음과 같다:
- 실용적인 추천 시스템에서의 확장성 문제 : LLM을 활용한 개인화된 사용자 행동 모델링은 많은 컴퓨팅 자원을 필요로 한다.
- 텍스트 의존성 : LLM은 환각 문제로 인해 존재하지 않는 아이템에 대한 추천을 생성할 수 있다.
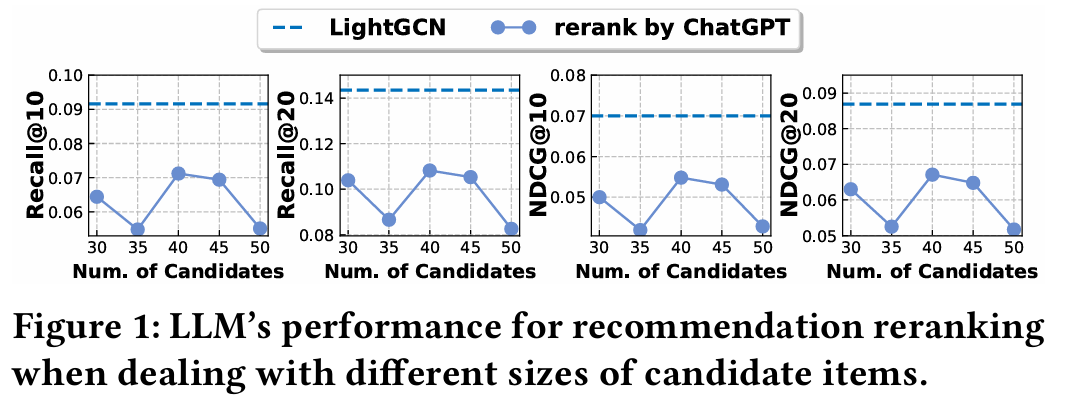
LLM의 한계 검증
- Amazon 데이터셋에서 LLM을 사용하여 추천의 re-rank 작업을 평가한다.
- LightGCN을 백본 모델로 사용하고, 각 아이템의 텍스트 정보를 사용자 정의 프롬프트와 통합하여 ChatGPT로 처리한다.
- LightGCN으로 선별한 40개의 아이템을 LLM으로 re-rank 한다.
- 추천 재정렬의 목표는 각 사용자에 대해 Top-10, 20 아이템을 식별하는 것이다.
- ChatGPT에 의해 세분화된 추천이 LightGCN이 제공한 원래 결과보다 성능이 떨어짐을 확인하였다.
- 제공된 목록 내에서 존재하지 않는 아이템(초록색 밑줄)을 추천했다.
- 올바르게 추천된 아이템(빨간색)이 LLM의 결과보다 LightGCN의 결과에 더 많다.
- 이러한 한계는 LLM의 환각 문제, 토큰 제한, 높은 계산 비용에 기인한다.

제안 방법
- LLM의 힘을 활용하여 기존 추천 시스템을 향상시키기 위한 RLMRec이라는 모델 비종속 프레임워크를 제안한다.
- RLMRec은 ID 기반 추천 시스템과 LLM 간의 연결 고리로 표현 학습을 활용하며, 사용자 행동과 선호를 이해하는 것을 목표로 한다.
- 보조 텍스트 신호를 표현 학습에 통합하는 이점을 모델링하여 이론적 기초를 마련한다.
- LLM의 semantic 공간과 협업 관계 신호의 표현 공간을 cross-view alignment 프레임워크를 통해 정렬하여 추천 성능을 향상시킨다.
기여
- LLM을 활용하고 협업 관계 모델링과의 semantic 공간을 정렬하여 기존 추천 시스템의 추천 성능을 향상시킬 가능성을 탐색하는 것을 목표로 한다.
- 이론적 발견에 기반한 RLMRec이라는 모델 비종속 표현 학습 프레임워크를 제안한다. 이 프레임워크는 대조적 또는 생성적 모델링 기술을 활용하여 학습된 표현의 질을 향상시킨다.
- 텍스트 신호를 통합하여 표현 학습을 향상시키는 효과의 이론적 기초를 확립한다. 상호 정보 극대화를 활용하여 텍스트 신호가 표현 품질을 개선할 수 있는 방법을 보여준다.
- RLMRec을 다양한 SOTA 추천 모델과 통합하고, 방법의 효과성을 검증하며, 프레임워크의 노이즈 및 불완전 데이터에 대한 강건성을 분석하여 실제 문제를 처리할 수 있는 능력을 보여준다.
3. Methodology
3.1 Theoretical Basis of RLMRec
3.1.1 Collaborative Filtering
- 추천 시나리오에서 사용자 집합 와 아이템 집합 를 설정한다.
- 관찰된 사용자-아이템 상호작용은 로 표현되며, 각 사용자와 아이템은 초기 임베딩 와 를 할당받는다.
- 목표는 추천 모델을 통해 사용자와 아이템 표현 , 를 학습하는 것이며(즉, ), 이 모델은 아래의 사후 확률 분포를 최대화한다.
- 실제 상호작용 는 노이즈(false positive, false negative)를 포함할 수 있으며, 이는 추천 정확도에 부정적인 영향을 미친다.
- false positive : 잘못 클릭하거나 인기 편향의 영향을 받은 상호작용
false negative : 사용자가 보지 못했지만 관심있는 아이템 - 이 연구에서는 추천에 유익한 히든 사전 지식(prior belief) 를 도입하여 진정한 긍정 샘플을 식별하도록 한다. 는 와 를 연결해 주는 latent space이다.
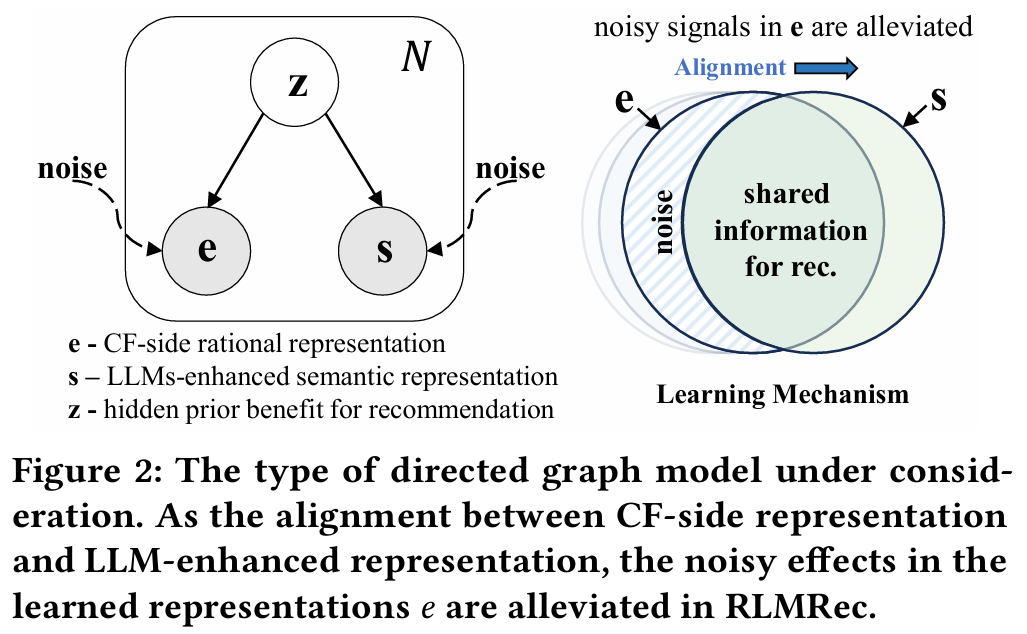
사후 확률 (Posterior Probability)
- 사후 확률 : 주어진 데이터나 증거를 기반으로 특정 사건의 확률
- 가능도(Likelihood) : 특정 사건이 주어졌을 때 관측된 데이터를 기반으로 하는 확률
이 수식은 베이즈 정리를 기반으로 한 사후 확률 분포를 설명한다.- : 주어진 상호작용 데이터 에 대한 사용자와 아이템의 표현 의 사후 확률이다. 즉, 사용자가 특정 아이템과 상호작용한 데이터를 바탕으로 해당 사용자와 아이템의 표현이 얼마나 가능성이 높은지를 나타낸다.
- : 주어진 표현 에 대한 사용자-아이템 상호작용 데이터 의 가능도이다. 이는 특정 표현이 주어졌을 때, 이 표현이 실제로 관찰된 상호작용 데이터 를 생성할 확률을 의미한다.
- : 표현 의 사전 확률이다. 이는 모델이 학습하기 전에 표현이 어떤 분포를 가질 것인지에 대한 사전 정보이다. 즉, 특정 표현이 얼마나 일반적인지를 나타낸다.
이 관계는 "사후 확률은 가능도와 사전 확률의 곱에 비례한다"는 의미이다. 즉, 관찰된 데이터 를 기반으로 하여 표현 의 가능성을 업데이트한다. 이 과정은 모델이 주어진 데이터에 맞게 사용자 및 아이템의 표현을 튜닝하도록 한다. 사후 확률 를 최대화하는 것은 모델이 데이터에 잘 적합하고 최적의 표현 를 찾는 과정이다.
3.1.2 Text-enhanced User Preference Learning
- 관련 없는 신호의 영향을 완화하기 위해 보조 정보 신호를 통합하는 것이 필요하다.
- 사용자 및 아이템 프로필을 텍스트 정보로 도입하여 사용자 선호를 효과적으로 포착하는 표현 를 생성한다.
- 협업 표현 와 텍스트 표현 는 추천에 유익한 정보를 포함하고, 조건부 확률을 최대화하여 최적의 값을 학습하는 것이 목표이다:
- 조건부 확률을 최대화함으로써 추천 모델로부터 학습된 표현이 사전 지식 에서 생성된 순수한 정보와 semantic 표현 와의 공유 정보를 포함하도록 보장한다.
Theorem 1
- 히든 사전 지식 가 주어진 상태에서, 사후 확률 를 최대화하는 것은 CF 측 관계 표현 와 LLM 측 semantic 표현 간의 상호 정보 를 최대화하는 것과 동등하다.
- "라는 latent 변수를 통해 최적화하는 것은 결국 와 간의 정보량을 최대화하는 것과 같다."는 점을 수학적으로 보여주기 위한 것이다.
Proof
- 사용자와 아이템의 프로필이 고정되어 있어 학습 과정 동안 확률 는 일정하다.
- : 주어진 에 대해 와 의 결합 확률.
- : 를 로 나누어 정규화. 이때 는 고정된 값이므로, 이 식은 에 대한 조건부 확률을 강조한다.
- 비례 관계는 두 식이 동일한 정보량을 나타내지만, 한 쪽이 다른 쪽의 상수 배에 해당함을 의미한다. 즉, 이 두 식은 같은 정보를 가지고 있다.
- 에 대해 적분해서 의 영향력을 제거한다. 이 과정에서 를 적분하는 것은 의 모든 가능한 값에 대해 평균을 구하는 것이다. 의 모든 가능한 값에 대해 를 누적하여 와 의 관계를 명확히 한다.
- 정보 이론
Theorem 2
- 상호 정보를 보존하기 위해 밀도 비율(density ratio)을 도입함으로써 를 사용하여, 의 최대화는 다음과 같은 하한을 최대화하는 것으로 재구성될 수 있다:
- 밀도 비율(density ratio) : 두 확률 분포의 비율
- : 라는 조건이 주어졌을 때 가 얼마나 더 잘 나타나는지를 보여주는 지표
- 는 상호 정보의 핵심 구성 요소 ( )
- 모델 점수 함수 를 상호 정보를 나타내는 로 설정
- softmax 형태의 목적함수를 정당화하는 이론적 증명이다.
Proof
- 상호 정보의 성질을 바탕으로, 이다.
- ,
- 조건부 확률 는 이미 가 주어진 상황에서 가 발생할 확률이라서 일반 확률 보다 높아지는 것이 자연스럽다. 조건부 확률은 추가적인 정보를 주기 때문에 그 사건에 대한 불확실성을 줄여준다. 는 에 대한 유익한 정보를 담고 있기 때문에 조건부 확률이 더 높다.
- negative sample의 영향력을 고려하여 기대값을 추가한다. 는 번째 샘플을 고려할 때의 부정 샘플을 나타낸다. ()
- 큰 샘플 수에서 합이 기대값과 비슷하므로 기대값을 합으로 근사한다. positive sample을 제외한 이 negative sample의 개수이다.
- 를 이용하여 softmax 형태로 나타낸다. 분자는 정답 후보의 score를 나타내고, 분모는 모든 후보의 score 합을 나타낸다.
Challenges
- 이 접근법은 두 가지 도전 과제를 제시한다.
- 사용자와 아이템의 상호작용 선호를 포착하는 효과적인 설명을 얻는 방법.
- 와 간의 상호 정보를 최대화하기 위해 밀도 비율 를 효과적으로 모델링하는 방법.
3.2 User/Item Profiling Paradigm
프로파일의 필요성
- 사용자와 아이템에 대한 텍스트 설명(프로파일)의 중요성을 강조한다.
- 역할 : 노이즈 영향을 완화하고 사용자와 아이템 간의 상호작용 선호를 의미적으로 이해할 수 있도록 한다.
이상적인 프로파일 특성
- 사용자 프로파일 : 사용자가 선호하는 아이템 유형을 효과적으로 요약하고 개인의 취향을 포괄적으로 표현해야 한다.
- 아이템 프로파일 : 아이템이 끌어당길 가능성이 있는 사용자 유형을 명확히 설명하고, 해당 사용자들의 선호와 관심사에 맞는 특성을 제공해야 한다.
원본 데이터의 문제점
- 누락된 속성 : 특정 아이템이나 사용자의 일부 속성이 누락될 수 있음.
- 노이즈가 많은 텍스트 : 텍스트에 사용자 선호와 무관한 노이즈가 포함될 수 있음.
LLM을 활용한 제안 방법
- LLM의 발전으로 텍스트 노이즈 제거 및 요약이 가능해졌다.
- 협력적 정보를 기반으로 한 프로파일 생성 패러다임을 제안한다.
- 아이템 속성에 대한 텍스트 설명 비율이 사용자 속성보다 높다는 점을 고려하여 item-to-user 관점을 취한다.
3.2.1 추론을 통한 프로파일 생성 (Profile Generation via Reasoning)
- 최근 연구에서는 LLM에 과정 추론을 통합하여 출력 품질을 향상시키는 효과를 입증했다.
- 시스템 프롬프트 설계 : 입력과 출력의 내용과 원하는 출력 형식을 명확하게 지정하여 사용자와 아이템의 프로파일을 생성하는 기능을 분명히 정의한다.
- : 프로파일, : 시스템 프롬프트, : 프로파일 생성 프롬프트
3.2.2 아이템 프롬프트 구성 (Item Prompt Construction)
- 프롬프트 구성:
- : 제목, : 원본 설명, : 데이터셋 특정 속성, : 사용자 리뷰 집합
- 각 아이템에 특정한 함수 를 사용하여 다양한 텍스트 특성을 하나의 문자열로 결합한다.
- 원본 설명 가 누락된 경우, 리뷰의 하위 집합 을 무작위로 샘플링하고 이를 속성 과 결합하여 입력으로 사용한다.

- 사용자가 선호할 만한 책의 유형을 요약하도록 지시하여 추천 목적으로 유용한 정보를 제공한다. 언어 모델의 출력은 JSON 형식을 준수해야 한다.
- Input Prompt : 입력 정보는 데이터셋의 책 제목과 원본 설명으로 구성된다.
- Generated Item Profile : 생성된 프로파일에 대한 언어 모델의 추론을 제공하는 것이 중요하며, 이는 고품질 요약을 보장하고 잠재적인 환각을 방지한다.
- 예시 : 책 설명에서 독자가 정신 건강 및 여성의 경험에 관심이 있을 가능성이 있음을 언어 모델이 정확하게 포착하였다.
3.2.3 사용자 프롬프트 구성 (User Prompt Construction)
- 이미 생성된 아이템 프로파일을 기반으로 사용자 프로파일을 생성한다.
- 프롬프트 구성:
- : 텍스트 속성, : 사용자 가 상호작용한 아이템 집합, : 사용자 가 제공한 리뷰
- 사용자 가 상호작용한 아이템들이 일 때, 그 중에서 아이템의 하위 집합 를 균등하게 샘플링한다.
- 의 각 아이템 에 대해, 텍스트 속성을 로 연결한다.
- 함수 는 텍스트 내용을 일관된 문자열로 구성하는 역할을 한다.
- 각 텍스트 속성 에는 사용자의 리뷰가 포함되어 있어 그들의 진정한 의견을 진솔하게 반영한다.

- item-to-user 생성 패러다임을 채택하여, 아이템의 상호작용 선호를 설명하는 이전에 생성된 프로파일을 활용할 수 있게 한다.
- 이를 위해 아이템에 대한 사용자 피드백 정보뿐만 아니라 아이템 자체의 프로파일도 포함한다.
- 두 정보 출처를 종합적으로 활용함으로써, LLM은 사용자 선호를 더 높은 정확도로 포착할 수 있다.
- 예시 : 책 설명과 사용자 리뷰 텍스트를 활용하여 언어 모델이 초자연적 요소를 결합한 청소년 소설에 대한 사용자의 선호를 도출한다.
3.3 Density Ratio Modeling for Mutual Information Maximization
상호 정보 최대화를 위한 밀도 비율 모델링
- 밀도 비율 를 모델링하여 상호 정보 를 최대화하는 과정을 설명한다.
semantic 표현 인코딩
- 프로파일 생성 : 사용자/아이템 프로파일 를 기반으로 semantic 표현 를 인코딩한다.
- : 텍스트 임베딩 모델로, 텍스트를 고정 길이 벡터로 변환한다.
밀도 비율 해석
- 정의 : 밀도 비율 는 와 의 유사성을 포착하는 양의 실수 값 점수 측정 함수이다.
- 효과 : 밀도 비율의 정확한 모델링은 CF측 표현과 LLM-enhanced 표현 간의 정렬을 개선하고 표현 학습에서 노이즈 영향을 완화시킨다.
모델링 접근 방식 제안
- 대조적 모델링 : 서로 다른 view를 양방향으로 효과적으로 정렬하는 방법이다.
- 생성적 모델링 : 부분적으로 마스킹된 입력을 재구성하며 학습한다. CF측 표현을 사용하여 semantic 표현을 재구성함으로써 두 형태의 정보를 효과적으로 정렬할 수 있다.
3.3.1 Contrastive Alignment
- : 유사성을 확률적으로 표현, : 코사인 유사성, : semantic 표현 를 의 피처 공간으로 매핑하는 다층 퍼셉트론
- 긍정 샘플 쌍 와 를 서로 끌어당겨 표현을 정렬한다.
- 구체적인 구현에서는 긍정 샘플 쌍을 batch 내에서 서로 가깝게 만드는 것을 목표로 하며, 나머지 샘플은 negative로 간주된다.
3.3.2 Generative Alignment
- MAE(masked autoencoder)에 대한 연구에서 영감을 받아, MAE 내에서 밀도 비율을 위한 추가 모델링 접근 방식을 제안한다.
- : 표현을 semantic 피처 공간으로 매핑하는 다층 퍼셉트론 모델, : 마스킹이 적용된 번째 샘플의 초기 임베딩
- 생성 과정은 단일 방향 재구성 접근 방식을 따르며, 마스킹된 샘플에 대해 semantic 표현을 재구성하는 데 집중한다.
- 구체적으로, 마스킹 작업은 초기 임베딩을 지정된 마스크 토큰(i.e. [MASK])으로 교체하고, 무작위로 선택된 사용자/아이템을 마스킹한 후 재구성한다. 이를 통해 semantic 피처 공간 내에서 재구성 능력을 탐색할 수 있다.
정렬 효과
- 대조적 정렬와 생성적 정렬 방법을 통해 LLM의 지식을 사용자 선호 이해 영역과 효과적으로 정렬한다.
- 이는 ID 기반 협력 관계 신호와 텍스트 기반 행동 의미를 결합함으로써 달성된다.
모델 이름
- RLMRec-Con
- RLMRec-Gen
3.4 Model-agnostic Learning
모델 비종속적 접근
- 지금까지 CF측 관계 표현 와 LLM측 semantic 표현 의 최적화에 집중해왔다.
- 사용자와 아이템에 대한 표현 학습을 수행할 수 있는 모든 모델은 앞서 설명한 최적화 과정을 거칠 수 있다.
최적화 함수
- : 추천 시스템 의 최적화 목표
- 최적화 함수 을 최소화하는 것은 앞서 언급한 상호 정보를 최대화하는 것과 일치한다.
4. Evaluation
Research Question
- RQ1 : RLMRec이 다양한 실험 환경에서 기존의 SOTA 추천 시스템을 개선하는가?
- RQ2 : LLM-enhanced semantic 표현이 추천 성능 향상에 기여하는가?
- RQ3 : RLMRec이 cross-view semantic alignment을 통해 노이즈 데이터 문제를 효과적으로 해결하는가?
- RQ4 : 추천 시스템 성능 향상을 위한 사전 훈련 프레임워크로서의 모델의 잠재력은 무엇인가?
- RQ5 : RLMRec의 훈련 효율성은 어떤가?
4.1 Experimental Settings
4.1.1 Datasets
- Amazon-book : Amazon에서 판매되는 책에 대한 사용자 평가 및 리뷰
- Yelp : 다양한 사업체에 대한 광범위한 텍스트 카테고리 정보를 제공하는 사용자-사업체 데이터셋
- Steam : Steam 플랫폼에서 제공되는 게임에 대한 사용자 피드백
- Amazon-book과 Yelp 데이터에서는 평가 점수가 3 미만인 상호작용을 필터링한다. Steam 데이터셋은 평가 점수가 없어 필터링을 적용하지 않는다.
- 이후 k-core 필터링을 수행하고 각 데이터셋을 3:1:1 비율로 훈련, 검증, 테스트 세트로 나눈다.
k-core filtering
- k-core는 그래프에서 각 노드의 차수가 최소 k 이상인 서브그래프를 의미한다.
- k-core에 포함된 모든 노드가 최소한 k개의 이웃 노드를 가지도록 노드와 엣지를 필터링한다.
- 그래프의 밀집한 구조를 강조하고, 노드 간의 강한 연결을 보존하는 데 유용하다.
- 추천 시스템이나 소셜 네트워크 분석 등에서 데이터의 품질을 높이고, 노이즈를 줄이는 데 기여할 수 있다.
필터링 과정
- 초기 그래프에서 차수가 k 미만인 노드를 제거한다.
- 노드를 제거할 때마다 그 노드와 연결된 엣지도 함께 제거되므로, 이로 인해 다른 노드의 차수도 변경될 수 있다.
- 이러한 과정을 반복하여 더 이상 차수가 k 미만인 노드가 없을 때까지 진행한다.
4.1.2 Evaluation Protocols and Metrics
- 포괄적인 평가와 편향 완화를 위해 모든 항목에 대해 all-rank 프로토콜을 채택한다.
- Recall@N과 NDCG@N을 사용하여 모델의 성능을 측정한다.
4.1.3 Base Models
- GCCF : GNN에서 비선형 연산의 역할을 재평가하여 그래프 기반 추천 설계를 단순화한 모델
- LightGCN : 그래프 메시지 전달에서 중복 뉴럴 모듈을 간소화하여 경량화한 추천 모델
- SGL : 대조 학습을 위한 다양한 관점 생성하기 위해 노드/엣지 드롭아웃을 사용하여 데이터를 증강한 모델
- SimGCL : 증강 없는 view 생성 기법을 도입하여 추천 성능을 향상시킨 모델
- DCCF : 분리된 대조 학습(disentangled contrastive learning)을 사용하여 추천을 위한 의도 기반 관계를 캡처하는 모델
- AutoCF : 추천을 위한 데이터 증강 프로세스를 자동화하는 self-supervised masked autoencoder 모델
4.1.4 Implementation Details
- 사용자/아이템 프로파일 생성 : ChatGPT (gpt-3.5-turbo)
- semantic 표현 생성 : text-embedding-ada002 (OpenAI)
- dimension of representations (i.e. , ) : 32
- batch : 4096, learning rate : 1e-3, optimizer : Adam
- hyperparameters : grid search
- early stopping : validation set 성능 기반
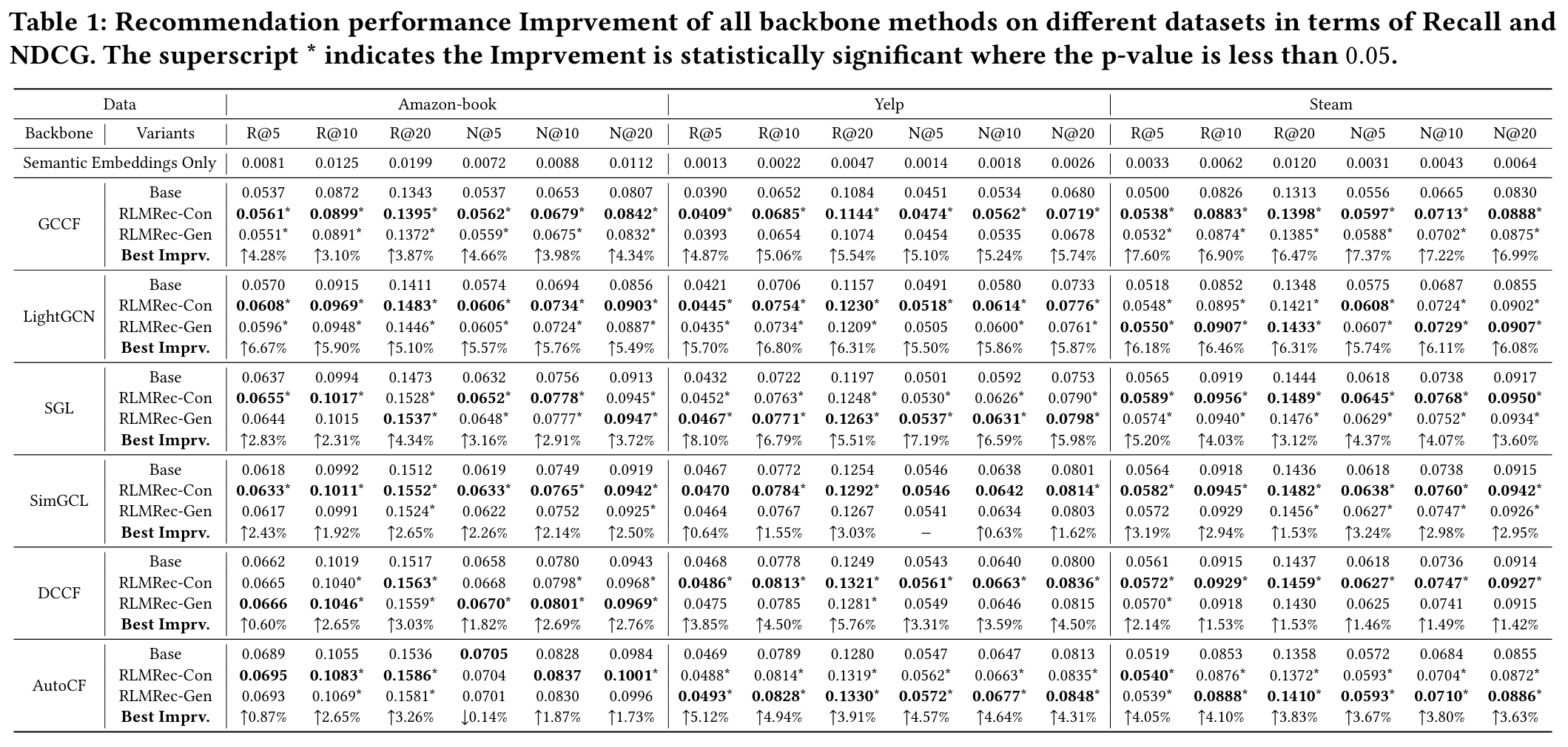
4.2 Performance Comparison (RQ1)
모델 비종속적 성능 향상
- 목적 : RLMRec을 여섯 가지 SOTA 협업 필터링 모델에 통합하여 성능을 향상시키는 것을 입증한다.
- 방법 : 5회의 무작위 초기화를 사용하여 평균 결과를 확인한다.
- 성능 향상 : 전반적으로, RLMRec을 백본 추천 시스템과 통합하면 원래 버전보다 성능이 향상되는 것이 일관되게 관찰된다.
- 요인 1 : RLMRec은 LLM에 의해 강화된 정확한 사용자/아이템 프로파일링을 가능하게 하여 사용자 상호작용 행동에서 풍부한 semantic 정보를 향상시킨다.
- 요인 2 : cross-view 상호 정보 최대화는 CF측 관계 임베딩과 LLM측 semantic 표현의 협력적 향상을 촉진하여 추천 기능에서 관련 없는 노이즈를 효과적으로 필터링한다.
- 대조적/생성적 모델링 : 대조적/생성적 모델링 접근 방식은 일반적으로 성능을 향상시킨다.
- 그러나 대조적 접근 방식은 GCCF 및 SimGCL과 같은 다양한 백본과 결합할 때 우수한 성능을 보인다.
- 반면, mask 재구성을 포함하는 AutoCF에 적용할 경우, RLMRec-Gen은 더 큰 향상을 보인다. mask 작업이 정규화 형태로 작용하여 생성적 접근 방식을 사용하는 방법과 함께 사용할 때 더 나은 결과를 낳는다고 추측한다.
LLM-enhanced 접근 방식에 대한 우수성
- 목적 : RLMRec의 효과를 최근 LLM-enhanced 사용자 행동 모델링 접근 방식인 KAR와 비교 평가한다.
- KAR와 비교 :
- KAR는 CTR 작업을 위한 사용자 선호 학습을 강화하기 위해 텍스트 사용자/아이템 설명을 생성하는 것을 목표로 한다.
- KAR는 텍스트 지식을 사용자 행동 표현과 효과적으로 정렬하지 못할 수 있으며, 사용자 행동이나 LLM 지식 기반에서 발생하는 관련 없는 노이즈에 더 취약할 수 있다.
- RLMRec은 사용자 행동 표현과 텍스트 지식을 효과적으로 정렬한다.

4.3 Ablation Study (RQ2)
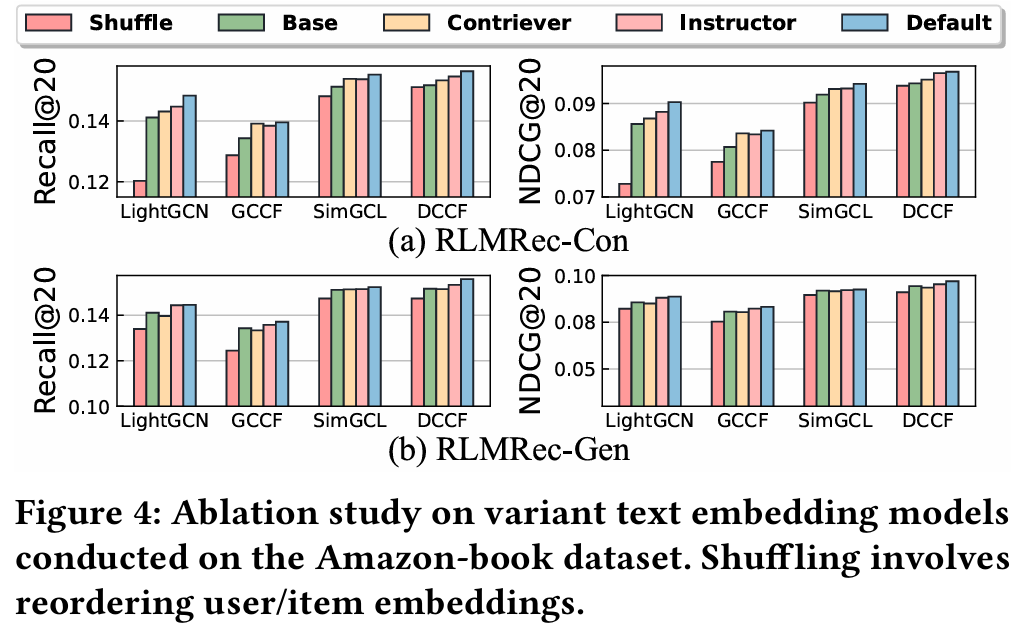
- 목적 : semantic 표현 통합이 성능에 미치는 영향을 조사한다.
- 방법 : semantic 표현을 무작위로 섞어 CF 측 관계 표현과 LLM의 지식을 불일치시킨다. 기본 인코딩 모델인 text-embedding-ada-002와 추가로 Contriever, Instructor를 사용한다.
- 결과 :
- 무작위로 섞인 표현이 CF와 semantic 정보 간의 불일치를 초래하여 성능이 감소한다. 이는 LLM의 semantic 지식과 사용자 간의 협력 관계 간의 정확한 정렬이 추천 성능 향상에 중요함을 나타낸다.
- Contriever와 Instructor 모델을 사용할 때도 RLMRec은 기본 성능을 향상시킨다. 이는 RLMRec이 텍스트 semantic 표현을 선호 표현으로 변환할 수 있는 적절한 텍스트 인코더를 효과적으로 활용할 수 있음을 시사한다.
Contriever
- Contriever는 정보 검색 및 질문 응답 시스템에서 효과적으로 사용되는 텍스트 임베딩 모델로, 주어진 문서나 텍스트에서 관련 정보를 추출하는 데 초점을 맞춘다.
- 특징 : contrastive learning 기법을 사용하여, 문서와 쿼리 간의 유사성을 극대화하고, 관련 없는 정보는 최소화하는 방식으로 학습된다. 이는 사용자 쿼리와 관련된 문서를 더 잘 찾는 데 도움을 준다.
Instructor
- Instructor는 주로 텍스트 생성 및 요약 작업을 위한 텍스트 임베딩 모델로, 사용자의 요청에 따라 적절한 응답을 생성하는 데 초점을 맞춘다.
- 특징 : 사용자 피드백이나 특정 지침을 기반으로 학습되며, 더욱 정교하고 사용자 친화적인 텍스트 출력을 생성하는 데 도움을 준다. 이 과정에서 LLM을 활용하여 보다 자연스럽고 일관성 있는 결과를 제공한다.
4.4 In-depth Analysis of RLMRec (RQ3 – RQ5)
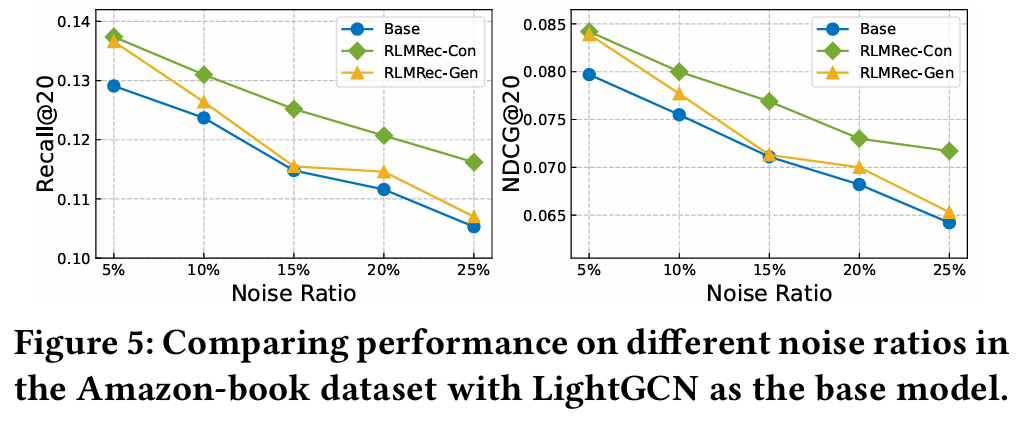
4.4.1 Performance w.r.t. Noisy Data (RQ3)
- 목적 : RLMRec의 데이터 노이즈에 대한 강건성을 평가한다.
- 방법 : 원래 훈련 데이터에 존재하지 않는 상호작용을 추가하여 노이즈 수준을 5%에서 25%까지 조정한다.
- 결과 :
- RLMRec-Con과 RLMRec-Gen 모두 모든 노이즈 수준에서 LightGCN 모델보다 우수하다. 이는 의미 정보를 통합하고 상호 정보를 활용하여 관련 없는 데이터를 필터링함으로써 추천을 개선하고 노이즈에 대한 강건성을 높이는 장점을 강조한다.
- RLMRec-Con은 RLMRec-Gen에 비해 데이터 노이즈에 더 잘 견디는 것으로 나타난다. 이는 생성적 방법에 노드 마스킹을 통해 도입되는 고유 노이즈로 인한 것일 수 있다. 반면 대조적 방법은 노이즈가 적게 발생하여 동일한 노이즈 비율에서 우수한 성능을 발휘한다.
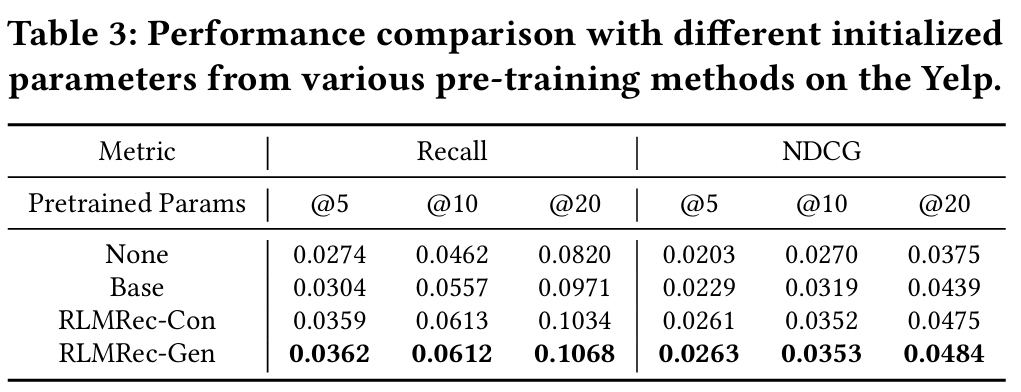
4.4.2 Performance in Pre-training Scenarios (RQ4)
- 목적 : Pre-training 기술로서의 RLMRec의 잠재력을 탐구한다.
- 방법 : Yelp 데이터셋을 사용하여 2012년부터 2017년까지의 데이터를 사전 훈련에 활용한다.
- 결과 :
- Pre-training을 수행한 경우가 수행하지 않은 경우보다 우수한 결과를 얻는다. 이는 Pre-training 데이터셋이 사용자/아이템 선호 예측에 도움이 되는 귀중한 협력 정보를 포함하고 있음을 시사한다.
- RLMRec-Con과 RLMRec-Gen 모두 기본 모델만으로 Pre-training하는 것보다 더 나은 사전 성과를 보이며, RLMRec-Gen이 가장 좋은 결과를 달성했다. 이는 Pre-training 시나리오에서 semantic 정보 통합과 생성적 방법의 효과를 강조하며, mask 작업의 규제 기능이 overfitting을 방지하는 데 기여할 수 있음을 나타낸다.
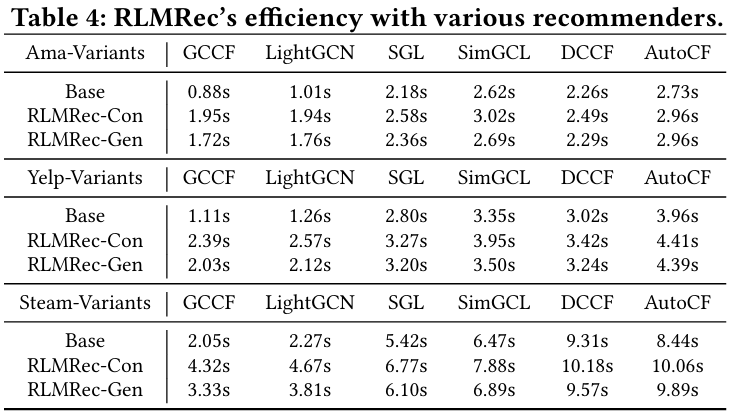
4.4.3 Analysis of Training Efficiency (RQ5)
- 목적 : RLMRec 사용의 시간 복잡성을 분석한다.
- 결과 :
- MLP에 대한 시간 복잡성은 RLMRec-Con과 RLMRec-Gen 모두 이다.
- RLMRec-Con의 경우, 손실 계산이 추가적인 복잡성 를 도입한다. RLMRec-Gen의 경우, 시간 복잡성은 이며, 마스킹 작업은 를 차지하고, 여기서 은 마스킹된 노드의 수를 나타낸다.
- RLMRec-Gen의 시간 비용이 RLMRec-Con보다 낮으며, 이는 batch 크기와 마스킹된 노드 수의 차이에서 기인한다. 주로 RLMRec-Con의 N 값이 배치 크기로 결정되며, 이는 RLMRec-Gen의 마스킹된 노드 수 M보다 더 큰 경향이 있기 때문이다.
4.5 Case Study
- 목적 : LLM-enhanced semantics를 활용하여 직접적인 메시지 전달로 포착할 수 없는 사용자 관계를 탐구한다.
- 결과 : RLMRec을 사용하여 학습된 표현이 ID 기반 추천 기술을 넘어서는 글로벌 협력 관계를 포착한다.
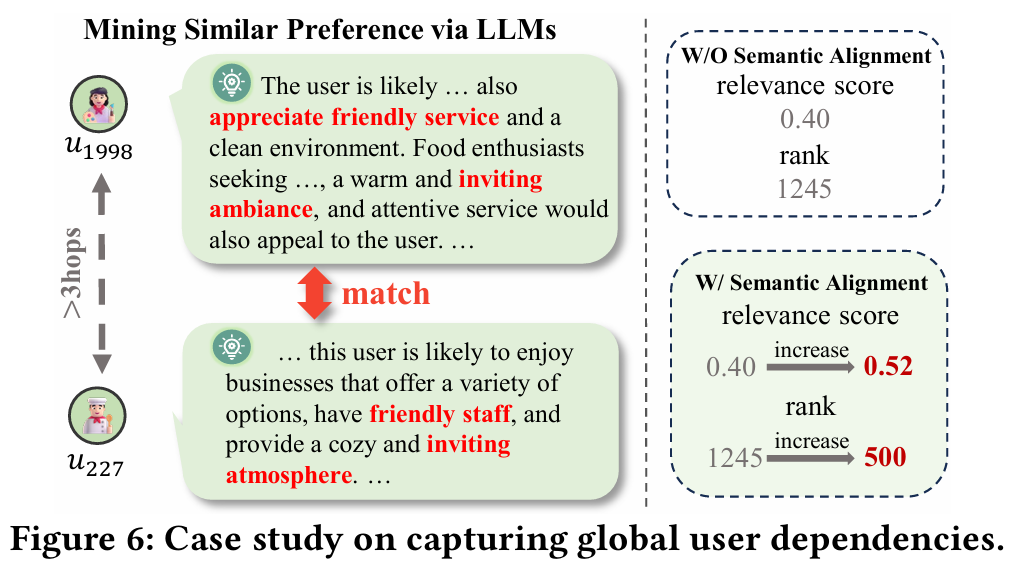
- 사용자 과 간의 거리가 3hop을 초과하여 공통점이 적다.
- 모델이 이들의 관계를 포착하는 능력을 평가하기 위해 사용자 표현의 유사성을 조사한다.
- 과 간의 공유 관심사 같은 LLM에서 파생된 의미 정보(e.g. 친절한 서비스)를 통합함으로써 관련 점수와 순위가 증가하는 것이 관찰된다.
- 이는 RLMRec에서 학습된 표현이 기존 추천 시스템으로 알 수 없었던 잠재적인 공통점을 포착한다는 것을 시사한다.
5 Conclusion
- RLMRec은 LLM을 활용하여 추천 시스템의 표현 성능을 개선하는 모델 비종속 프레임워크이다.
- 협력 프로파일 생성 패러다임과 추론 기반 시스템 프롬프트를 도입하며, 생성된 출력에서 추론 과정의 포함을 강조한다.
- 대조적/생성적 정렬 기술을 활용하여 LLM 측 semantic 표현과 CF 측 관계 임베딩을 정렬하여 노이즈를 줄인다.
- 향후 연구는 추천 시스템에서 LLM 기반 추론 결과를 개선하여 더 통찰력 있는 설명을 제공하는 데 집중할 예정이다.
