📄 Paper
Data-efficient Fine-tuning for LLM-based Recommendation [arxiv]
Xinyu Lin ACM SIGIR 24
📝 Key Point
-
DEALRec 제안 : LLM 기반 추천 시스템을 위한 효율적인 데이터 정제(data pruning) 방법을 제안한다.
-
핵심 기법 : Influence Score와 Effort Score를 활용해 중요한 샘플을 선택한다.
-
성능 개선 : 기존 데이터 정제 방법보다 높은 정확도를 유지하면서도 훈련 비용을 94% 이상 절감했다.
-
일반화 가능성 : 다양한 LLM 추천 모델과 데이터셋에서 일관된 성능 향상을 보였다.
Abstract
문제 제기
최근 LLM을 추천 시스템에 활용하는 연구가 활발히 이루어지고 있다. 그러나 LLM을 빠르게 확장되는 추천 데이터에 맞춰 파인튜닝하는 비용이 실용성에 큰 제한을 둔다.
제안된 해결책
이를 해결하기 위해 'few-shot fine-tuning'이라는 방법을 활용한 LLM의 빠른 적응이 유망한 접근법으로 제시된다. 본 논문에서는 LLM 기반 추천 시스템에서 효율적인 데이터 프루닝(data pruning) 작업을 제안한다. 이 작업은 LLM의 few-shot fine-tuning에 적합한 대표 샘플을 선별하는 과정이다.
기존 방법의 한계
기존의 coreset 선택 방법은 최적이 아닌 휴리스틱 메트릭을 사용하거나, 대규모 추천 데이터에서 비용이 많이 드는 최적화를 요구한다. 이러한 한계를 해결하기 위한 새로운 방법이 필요하다.
목표
데이터 프루닝 작업의 두 가지 주요 목표를 제시한다.
- 높은 정확도 : 추천 성능을 높일 수 있는 영향력 있는 샘플을 식별하는 것.
- 높은 효율성 : 데이터 프루닝 과정에서 낮은 비용을 달성하는 것.
제안된 방법
두 가지 목표를 달성하기 위해, influence score와 effort score라는 두 가지 점수를 도입한 새로운 데이터 프루닝 방법을 제안한다.
- influence score는 샘플 제거가 전체 성능에 미치는 영향을 정확히 추정하는 데 사용된다.
- effort score는 surrogate 모델과 LLM 간의 차이를 고려하여, LLM에 특화된 어려운 샘플을 우선순위로 두는 역할을 한다.
효율성 향상
데이터 프루닝 과정에서 LLM 대신 작은 크기의 대리 모델을 사용하여 영향력 점수를 계산함으로써 비용을 절감한다.
실험 결과
세 가지 실제 데이터셋을 통해 실험을 진행한 결과, 제안한 방법은 전체 데이터를 사용한 파인튜닝을 초과하는 성능을 보였으며, 시간 비용을 97%까지 절감하는 성과를 얻었다.
Figure
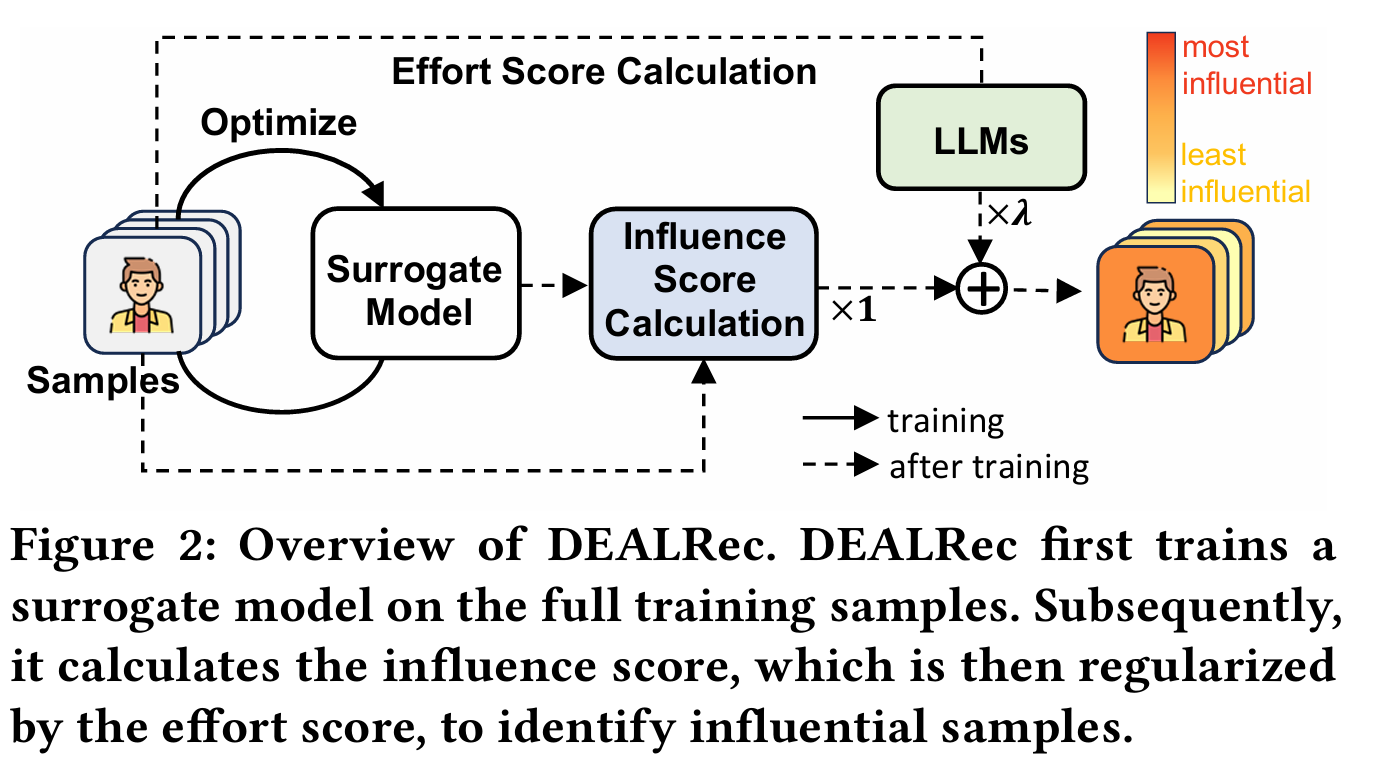
DEALRec의 구조
- 전체 학습 샘플에서 Surrogate Model을 학습시킨다.
- influence score를 계산한다.
- effort score로 influence score를 정규화하여 영향력 있는 샘플을 식별한다.
1. Introduction
LLM 기반 추천 시스템의 필요성
LLM을 활용한 추천 시스템은 다양한 작업에서 유망한 성과를 보였다. 추천 데이터는 빠르게 업데이트되기 때문에 LLM을 자주 파인튜닝해야 하며, 이는 사용자 행동과 최신 아이템 정보를 반영하는 데 필수적이다.
파인튜닝의 도전 과제
대규모 추천 데이터를 파인튜닝하는 데는 두 가지 주요 문제가 존재한다.
- 정확도 : 모든 훈련 샘플을 평가해야 하며, 이는 비용이 많이 든다.
- 효율성 : 효율적인 샘플 선택을 통해 훈련 시간과 비용을 절감해야 한다. 랜덤 샘플링된 데이터는 충분한 대표성을 가지지 못할 가능성이 높다.
DEALRec 방법 제안
이를 해결하기 위해 DEALRec이라는 데이터 프루닝 방법을 제안한다. DEALRec는 두 가지 점수를 사용하여 효율적으로 샘플을 선택한다.
- influence score : 각 샘플을 제거할 때 실험적 위험에 미치는 영향을 추정한다.
- effort score : 샘플 loss에 대한 gradient norm을 계산하여, LLM이 해당 샘플을 학습하는 데 드는 effort을 측정한다.
DEALRec의 장점
DEALRec는 influence score와 effort score를 결합하여, LLM의 파인튜닝을 위한 중요한 샘플을 효율적으로 선택한다. 기존의 방법들은 비용이 많이 들거나 실용성이 떨어지지만, DEALRec는 더 정확하고 효율적인 샘플 선택을 가능하게 한다.
실험 결과
DEALRec는 두 개의 LLM 기반 추천 모델에 적용되었으며, 세 가지 실제 데이터셋에서 우수한 효율성과 정확성을 입증하였다. DEALRec는 시간 비용을 절감하면서도 우수한 성능을 보였다.
기여
- LLM 기반 추천 시스템에서 데이터 프루닝 작업을 도입하여 실제 플랫폼에 적용 가능성을 높였다.
- LLM 기반 추천을 위한 효율적이고 정확한 데이터 프루닝 방법을 제안했다.
- 세 가지 실제 데이터셋에서 DEALRec의 우수성을 실험적으로 입증하였다.
2. Task Formulation
LLM 기반 추천 모델
LLM을 추천 시스템에 활용하려면, LLM을 직접 추천 모델로 사용하는 것이 일반적이다. 하지만 LLM은 추천 데이터를 기반으로 학습되지 않았기 때문에, 아이템 지식을 학습하고 사용자 행동을 이해하기 위해 fine-tuning이 필수적이다. 훈련 샘플은 사용자 시퀀스로 표현되며, 이는 사용자의 역사적 상호작용 순서와 다음 상호작용 아이템을 포함한다. 이를 기반으로 LLM의 학습 파라미터를 최적화하기 위해 음의 로그 우도 함수를 최소화하는 방식으로 fine-tuning을 진행한다.
하지만 LLM을 fine-tuning하는 데는 많은 자원과 시간이 소모되며, 추천 데이터는 지속적으로 갱신되므로 LLM 기반 추천 시스템의 실제 적용에 어려움이 있다. 따라서 LLM 기반 추천 시스템의 효율성을 높이는 것이 중요하다.
효율적인 LLM 기반 추천을 위한 데이터 절단
효율적인 LLM 기반 추천을 달성하기 위해, 무작위로 샘플을 선택하여 몇 가지 샷으로 fine-tuning을 하는 방식이 유망하다. 그러나 무작위 샘플은 최신 사용자 행동이나 아이템 정보를 충분히 반영하지 못할 가능성이 높다. 따라서 LLM의 몇 가지 샷 fine-tuning을 위한 대표 샘플을 선택하는 데이터 절단 작업이 필요하다.
이 작업의 목표는 전체 훈련 샘플 중에서 효율적으로 샘플을 선택하여 LLM이 테스트 세트에서 좋은 성능을 낼 수 있도록 하는 것이다. 선택된 샘플의 크기는 주어진 선택 비율에 의해 제어된다.
Coreset Selection
데이터 절단 작업과 관련된 연구로, coreset 선택 방법이 있다. coreset 선택 방법은 크게 두 가지로 나눠진다.
- 휴리스틱 방법 : 경험적 최소화 전략을 기반으로 샘플을 선택하는 방법이다. 예를 들어, 예측 엔트로피가 큰 샘플을 선택하거나 샘플 표현을 기반으로 클러스터링을 할 수 있다. 그러나 이러한 방법은 샘플이 실험적 위험에 미치는 영향을 명시적으로 고려하지 않아, 선택된 샘플로 훈련한 모델의 성능이 최적이 아닐 수 있다.
- 최적화 기반 방법 : 이 방법은 이층 최적화 기법을 사용하여 훈련할 최적의 샘플 집합을 선택하는 방식이다. 그러나 이 방법은 대규모 데이터셋에 적용하기 어렵고, 최적화 문제를 풀기 위한 계산이 복잡하여 LLM 기반 추천 모델에 적합하지 않다.
이전의 coreset 선택 방법들은 보통 원본 훈련 샘플에서 모델을 훈련해야 하는데, 이는 LLM 기반 추천 모델에서 데이터가 계속해서 유입되고 자원 비용이 크기 때문에 현실적으로 불가능하다.
데이터 절단 목표
- 높은 정확도 : 선택된 샘플로 훈련한 모델이 낮은 실험적 위험을 가지는 것을 목표로 한다.
- 높은 효율성 : 데이터 절단 과정에서 비용을 최소화하고, LLM의 무거운 fine-tuning을 피하는 것을 목표로 한다.
3. DEALRec
DEALRec는 효율적인 LLM 기반 추천 시스템을 위한 데이터 절단 방법이다. 이 방법은 두 가지 주요 요소를 포함한다.
1. Influence Score : 경험적 위험에 대한 영향을 추정하기 위한 점수
2. Effort Score : LLM과 대체 모델 간의 학습 능력 차이를 보완하기 위한 정규화 요소
3.1 Influence Score
- 파라미터 변화에 대한 영향 : 샘플을 upweight할 때의 파라미터 변화는 influence function를 사용해 추정된다. 이때 계산은 비용이 많이 드는 방식이지만, 체인 룰과 이차 최적화 기법을 활용해 효율적으로 근사된다.
- 경험적 위험에 대한 영향 : 샘플 제거가 경험적 위험에 미치는 영향을 추정하는 방법이다. 이를 통해 각 샘플의 influence score를 계산할 수 있다.
- 효율적인 influence score 계산 : Hessian-Vector Products (HVP)를 사용하여 계산을 효율적으로 만든다. 이를 통해 모든 샘플에 대한 influence score를 한 번의 계산으로 추정할 수 있다.
3.2 Gap Regularization
- Surrogate Model (대체 모델) : 계산 비용을 줄이기 위해 작은 크기의 전통적인 추천 모델을 사용한다. 그러나 LLM은 사전 훈련을 통해 풍부한 지식을 얻기 때문에 대체 모델과는 학습 능력에서 차이가 있다.
- Effort Score : LLM이 특정 사용자 시퀀스를 학습하는 데 드는 effort를 측정한다. 큰 점수는 LLM이 학습하기 어려운 샘플을 나타낸다. 이 점수는 LLM의 학습 능력 차이를 보완한다.
- 전체 점수 : influence score와 effort score를 결합하여 최종 점수를 계산한다. 이를 통해 LLM 기반 추천 시스템의 효율적인 fine-tuning을 할 수 있다.
3.3 Few-shot Fine-tuning
- 데이터 선택 : 최종 점수를 기반으로 데이터를 선택하여 LLM을 적은 양의 데이터로 fine-tuning 한다.
- 문제 : 높은 점수를 가진 샘플을 선택하면 유사한 샘플들이 중복되므로 전체적인 성능 향상에 한계가 있다.
- 해결 방법 : 계층화 샘플링(stratified sampling)을 사용하여 다양한 영역에서 균등하게 샘플을 선택하고, 데이터 커버리지를 향상시킨다.
DEALRec는 influence score와 effort score를 결합하여 LLM 기반 추천 모델의 fine-tuning을 효율적으로 개선하는 방법을 제시한다.
4. Experiment
RQ1 : DEALRec이 기존의 coreset 선택 기법 및 전체 데이터 학습 모델과 비교하여 얼마나 우수한가?
RQ2 : DEALRec의 주요 구성 요소(영향 점수, 간극 정규화, 층화 샘플링)의 효과는 어떠하며, 다른 대체 모델에도 일반화될 수 있는가?
RQ3 : 샘플링 비율에 따른 DEALRec의 성능 변화는 어떠하며, 전반적인 성능을 얼마나 향상시키는가?
4.1 실험 설정
1) 데이터셋
- Games(Amazon 리뷰 데이터셋, 비디오 게임 추천)
- MicroLens-50K(마이크로 비디오 추천)
- Book(Amazon 리뷰 데이터셋, 도서 추천)
- 사용자-아이템 상호작용 데이터를 시간순으로 정렬 후 8:1:1 비율로 훈련, 검증, 테스트 데이터셋으로 분할
- 두 가지 미세 조정 방식 적용
- Few-shot fine-tuning(1024개 샘플, 다양한 데이터 선택 기법 적용)
- Full fine-tuning(전체 데이터 활용)
2) 비교 기법(베이스라인)
- 무작위 샘플링(Random): 무작위 데이터 선택
- 난이도 기반 방법(GraNd, EL2N): 그래디언트 크기 및 예측 오류를 기준으로 어려운 샘플 선택
- 다양성 기반 방법(TF-DCon, RecRanker): 사용자 시퀀스를 다양하게 구성
- CCS: 높은 데이터 커버리지와 중요도를 고려한 샘플 선택
- LLM 기반 추천 모델: BIGRec(LLaMA-7B 활용), TIGER(아이템 특성 학습 후 토큰 변환)
3) 평가 지표
- Recall@K, NDCG@K 사용 (K=10, 20, 50)
4) 실험 환경
- BIGRec은 LLaMA-7B, TIGER는 Transformer 기반
- 4개의 NVIDIA RTX A5000 GPU 사용
- LoRA 기법으로 BIGRec을 미세 조정, TIGER는 전체 파라미터 미세 조정
- DEALRec의 대체 모델로 SASRec 사용
4.2 전체 성능 분석(RQ1)
- BIGRec이 TIGER보다 일반적으로 우수한 성능을 보이며, 이는 LLaMA-7B의 강력한 일반화 성능과 아이템 제목 활용 때문일 가능성이 높다.
- 난이도 기반 방법(GraNd, EL2N)이 다양성 기반 방법(TF-DCon, RecRanker)보다 성능이 높다.
- 무작위 샘플링이 일부 coreset 선택 방법보다 성능이 높으며, 이는 데이터 분포를 균일하게 유지하기 때문일 가능성이 높다.
- DEALRec이 모든 비교 기법보다 우수한 성능을 보이며, 영향 점수와 간극 정규화를 통해 LLM 적응을 효과적으로 수행한 것으로 판단된다.
- DEALRec은 전체 데이터를 학습한 모델보다도 성능이 높으며, 학습 비용을 평균 97.11% 절감할 수 있다.
4.3 심층 분석
1) 구성 요소별 효과 분석(RQ2)
- 영향 점수 또는 간극 정규화를 제거하면 성능이 저하됨
- 탐욕적 샘플 선택(가장 높은 점수 샘플만 선택)은 성능이 떨어짐
2) 대체 모델에서의 일반화 성능(RQ2)
- DEALRec은 다른 추천 모델(BERT4Rec, SASRec, DCRec)에서도 우수한 성능을 보이며, 일반화 가능성이 높다.
- SASRec이 학습 시간이 가장 짧고 안정적인 성능을 보이며, 실무 적용에 적합할 가능성이 높다.
3) 샘플링 비율에 따른 성능 변화(RQ3)
- 샘플링 비율(𝑟)이 1%까지 증가할 때 성능이 급격히 향상되며, 이후 추가 샘플 증가에 따른 성능 향상은 미미하다.
- 1% 샘플링이 전체 데이터 학습과 유사한 성능을 내면서도 94% 이상의 학습 비용 절감 효과를 보인다.
4) 사용자 그룹별 성능 분석(RQ3)
- 난이도가 높은 사용자 그룹에서 전반적으로 성능이 감소하지만, DEALRec이 무작위 샘플링보다 일관되게 우수한 성능을 보인다.
5) 정규화 강도(𝜆)에 따른 성능 변화
- 𝜆가 증가함에 따라 성능이 향상되지만, 너무 높은 𝜆는 오히려 성능 저하를 초래할 가능성이 있다.
- 영향 점수와 LLM 학습 능력 간의 균형을 맞추는 것이 중요하다.
6. Conclusion
본 연구에서는 LLM 기반 추천 시스템의 효율적인 데이터 정제를 위한 작업을 제안하였으며, 이는 LLM의 few-shot fine-tuning을 위한 대표적인 샘플을 식별하는 것을 목표로 한다. 이를 위해 데이터 정제 작업에서 두 가지 주요 목표를 설정하였다.
- 높은 정확도 : 실험적 위험(empirical risk)이 낮아질 가능성이 높은 샘플을 선택하는 것을 목표로 한다.
- 높은 효율성 : 데이터 정제 과정에서 비용을 절감하는 것을 목표로 한다.
이러한 목표를 달성하기 위해 DEALRec이라는 새로운 데이터 정제 방법을 제안하였다.
- Influence Score : 샘플 제거가 실험적 위험에 미치는 영향을 추정하며, 영향 함수에서 확장된 형태로 대칭 속성을 활용하여 가속화하였다.
- 대체 모델(Surrogate Model) 활용 : 소형 대체 모델을 사용하여 영향 점수를 효율적으로 계산하고, LLM과의 격차를 줄이기 위해 Effort Score를 도입하였다.
실험 결과, DEALRec이 높은 효율성과 높은 정확도를 동시에 달성할 가능성이 높음을 검증하였다.
본 연구는 LLM 미세 조정을 위한 데이터 정제 작업을 제안함으로써 새로운 연구 방향을 개척하였으며, 향후 연구에 대한 여러 가능성을 남겼다.
- DEALRec을 다양한 LLM 기반 추천 모델과 교차 도메인 데이터셋에 적용하여 제한된 자원으로도 미세 조정 성능을 향상시킬 가능성이 높다.
- LLM의 제한적인 컨텍스트 윈도우 길이를 고려할 때, 사용자 상호작용 데이터에서 정보량이 높은 항목을 선택하여 미세 조정 성능을 개선할 가능성이 높다.
- LLM 기반 추천 모델의 추론 효율성을 향상시키는 것이 실제 적용을 위해 중요한 문제로 남아 있을 가능성이 높다.
