[논문] Sequential Recommendation with Latent Relations based on Large Language Model
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
Sequential Recommendation with Latent Relations based on Large Language Model [arxiv]
Shenghao Yang ACM SIGIR 24
📝 Key Point
-
LRD (Latent Relation Discovery) 제안 : LLM을 기반으로 한 새로운 방법인 LRD는 잠재적인 아이템 관계를 효과적으로 발견하는 방법이다. 이를 통해 기존의 관계 인식 순차 추천 시스템을 향상시킬 수 있다.
-
자기 지도 학습 활용 : LRD는 자기 지도 학습 접근 방식을 사용하여, LLM이 제공하는 풍부한 지식을 바탕으로 아이템 간의 잠재적 관계를 추출한다.
-
잠재 관계와 사용자 상호작용 신호 : LRD는 사용자 상호작용 신호를 통해 관계 발견 과정을 효과적으로 안내하며, 발견된 잠재 관계는 신뢰할 수 있음을 추가 분석을 통해 확인할 수 있다.
Abstract
연구 배경
순차 추천 시스템은 사용자의 과거 행동을 기반으로 관심 아이템을 예측하는 방식이다. 기존 방법은 아이템 간 암묵적 협업 필터링 신호를 활용하며, 관계 기반 모델은 지식 그래프에서 아이템 관계를 추출하여 성능을 향상시킨다. 그러나 사전 정의된 관계에 의존하고 데이터 희소성 문제가 있어 일반화에 한계가 있다.
연구 목표
본 연구는 사전 정의된 관계 없이 LLM을 활용하여 아이템 간 잠재적 관계를 학습하는 Latent Relation Discovery (LRD) 기법을 제안한다.
제안 기법 (LRD)
LLM을 활용하여 아이템 간 자연어 기반 관계 표현을 생성하고, 이를 DVAE (Discrete state Variational AutoEncoder)로 학습한다. 자기 지도 학습을 적용하여 관계 학습과 추천을 동시에 최적화한다.
실험 결과
여러 공개 데이터셋 실험에서 LRD는 기존 관계 기반 모델과 결합하여 추천 성능을 크게 향상시켰다. 희소성 문제를 완화하고, 추천 품질을 개선하는 데 효과적이다. 추가 분석을 통해 LLM이 학습한 관계가 신뢰할 수 있음을 확인하였다.
Figure
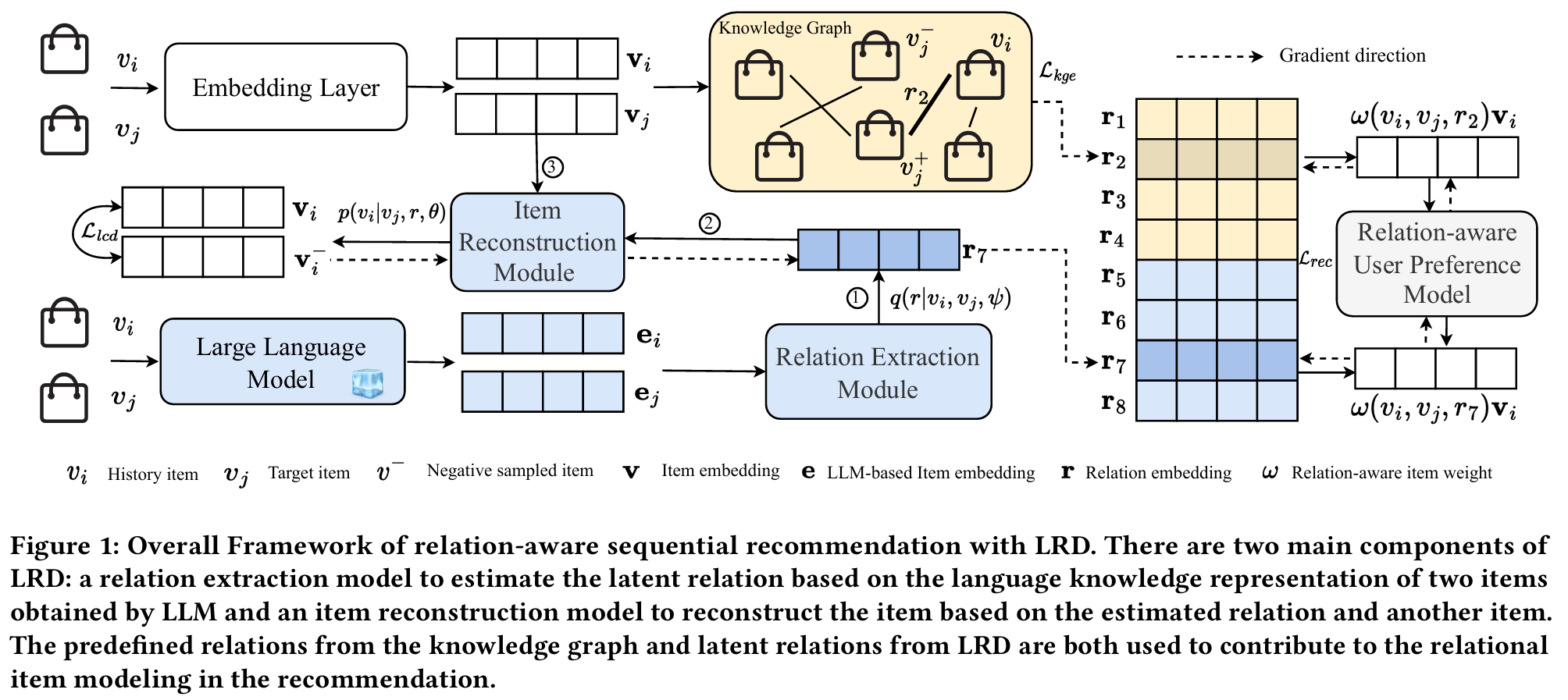
LRD 기반 관계 인식 순차 추천 프레임워크
LRD는 두 가지 주요 구성 요소로 이루어져 있다.
-
관계 추출 모델 (Relation Extraction Model)
- LLM을 활용하여 아이템의 언어 기반 지식 표현을 생성한다.
- 이를 바탕으로 두 아이템 간 잠재적 관계을 추정한다.
-
아이템 재구성 모델 (Item Reconstruction Model)
- 추정된 관계와 다른 아이템을 기반으로 대상 아이템을 재구성한다.
이 과정에서 지식 그래프의 사전 정의된 관계와 LRD에서 추론한 잠재 관계를 함께 활용하여 추천 성능을 향상시킨다.
1. Introduction
연구 배경
순차 추천 시스템은 사용자의 과거 행동을 기반으로 다음에 선호할 아이템을 예측하는 기술이다. 초기에는 마르코프 체인을 활용했으며, 이후 RNN, CNN, Transformer 등의 딥러닝 모델이 도입되면서 성능이 향상되었다. 그러나 대부분의 기존 모델은 아이템 간 암묵적 유사성을 계산하는 협업 필터링 방식에 의존하며, 명시적인 관계를 고려하지 않는다. 최근 관계 기반 순차 추천 모델이 등장했으나 한계가 있다.
기존 접근법의 문제점
기존 관계 기반 추천 모델은 지식 그래프를 활용하지만 두 가지 희소성 문제를 가진다.
- 관계 희소성 : 대부분의 관계는 수동으로 정의되며, 실제로 존재하는 다양한 관계를 충분히 반영하지 못한다.
- 아이템 희소성 : 협업 필터링 기반 관계는 충분한 사용자 데이터가 필요하지만, 데이터가 부족한 경우 일반화가 어렵다.
이를 해결하기 위해 아이템 간 잠재적 관계를 자동으로 발견하는 방법을 연구한다.
연구 목표 및 제안 기법
본 연구에서는 LLM을 활용한 Latent Relation Discovery (LRD) 기법을 제안한다.
- LLM이 아이템 간 언어 기반 관계 표현을 학습하도록 하고, 자기 지도 학습을 적용하여 잠재 관계를 학습한다.
- 기존 관계 기반 추천 모델과 결합하여 추천 성능을 향상시킨다.
LRD의 특징 및 장점
- 수동 정의 없이 관계를 자동으로 발견하여 다양한 사용자 선호를 반영한다.
- 추천 최적화 과정에서 관계 학습을 함께 수행하여 유용한 관계를 효과적으로 발견한다.
- 아이템 간 관계 분석을 통해 추천 모델의 해석 가능성을 높인다.
실험 및 성능 검증
공개 데이터셋 실험 결과, LRD는 기존 관계 기반 추천 모델보다 성능이 우수했다.
- LLM을 활용한 잠재 관계 학습으로 사용자 시퀀스 표현이 더 풍부해졌다.
- 추가 실험을 통해 LRD가 합리적인 관계를 효과적으로 학습할 수 있음을 확인했다.
연구 기여
- LLM을 활용하여 잠재적 관계를 자동으로 학습하는 순차 추천 기법을 최초로 제안했다.
- 자기 지도 학습 기반의 LRD 프레임워크를 설계하여 기존 관계 기반 추천 모델과 쉽게 결합할 수 있도록 했다.
- 여러 데이터셋 실험을 통해 기존 모델 대비 추천 성능 향상을 검증했다.
2. Problem Statement
기호 정의
- 사용자 집합() 및 아이템 집합() 을 정의한다.
- 사용자 의 시간순 상호작용 기록은 로 표현된다.
- 특정 아이템 에 대해, 관계 를 가진 또 다른 관련 아이템 가 존재할 수 있으며, 이는 삼중항(triplet) 로 나타낸다.
- 관계 집합() 은 사전 정의된 관계 집합 과 잠재적 관계 집합 으로 나뉜다.
- 지식 그래프() 는 사전 정의된 관계를 포함한 아이템 관계 삼중항 집합 을 저장한다.
- Vertex 집합은 모든 관계를 가진 아이템 쌍으로 구성된다.
- Edge 집합은 사전 정의된 관계들로 구성된다.
순차 추천 문제 정의
- 목표 : 사용자 의 과거 상호작용 기록 를 고려하여, 다음 상호작용 시 추천할 아이템을 순위별로 제공하는 것이다.
- 관계 기반 순차 추천 : 기존 방법은 아이템 간 관계 중 만을 활용하지만, 제안하는 LRD(Latent Relation Discovery) 는 잠재적 관계 집합 을 추가적으로 활용 하여 추천 성능을 개선한다.
3 Method
3.1 Framework Overview
연구에서 제안하는 관계 인식 순차 추천 프레임워크의 핵심 구성 요소는 잠재 관계 발견 모듈이다. 이 모듈은 Discrete-state Variational Autoencoder (DVAE)에서 영감을 얻은 자기 지도 학습 방식으로 설계되었다.
잠재 관계 발견 모델은 두 개의 하위 모듈로 구성된다.
1. 관계 추출 모듈 : LLM을 활용하여 아이템의 언어 지식 표현을 얻고, 이를 바탕으로 두 아이템 간의 잠재 관계를 예측한다.
2. 아이템 재구성 모듈 : 예측된 잠재 관계와 하나의 아이템 표현을 이용하여 다른 아이템을 재구성한다.
이 모듈을 관계 인식 순차 추천 모델에 통합하여, 사용자 선호도를 보다 정교하게 모델링할 수 있도록 한다. 또한 추천 작업의 목표를 이용하여 더 유용한 관계를 발견하도록 유도한다.
DVAE (Discrete-state Variational Autoencoder)
논문 "Discrete-State Variational Autoencoders for Joint Discovery and Factorization of Relations" 에서 제안된 Discrete-state Variational Autoencoder (DVAE) 는 이산적인(discrete) 관계 표현을 학습하는 확률 생성 모델이다.
DVAE는 연속적인 잠재 공간을 가지는 일반적인 VAE와 달리, 이산적인 잠재 변수를 사용 한다. 이를 통해, 복잡한 관계 데이터를 명확한 상태(state)로 분해(factorization) 하고, 각 관계를 효과적으로 학습 할 수 있다.
DVAE는 특히 관계 추론(Relation Inference) 과 지식 그래프(Knowledge Graph, KG) 학습 에 적용될 수 있으며, 다음과 같은 특징을 가진다.
- 이산적인 관계 표현 학습 : 연속적인 잠재 변수를 사용하지 않고, 관계를 이산적인 잠재 변수로 모델링한다.
- 관계 발견(Joint Discovery) 및 분해(Factorization) : DVAE는 새로운 관계를 자동으로 발견하고, 기존 관계를 더 작은 구성 요소로 분해하여 학습할 수 있다.
VAE 프레임워크 기반 : 확률 모델의 구조는 Variational Autoencoder (VAE) 를 따르며, 잠재 변수 를 통해 데이터 를 생성하는 방식이다.
3.2 Latent Relation Discovery (LRD)
3.2.1 Optimization Objective
잠재 관계는 수동으로 구축된 관계 데이터셋에 포함되지 않은 관계이므로, 지도 학습이 아닌 자기 지도 학습 방식을 사용한다. DVAE 기반 접근법을 따르며, 모든 관계가 균등한 분포를 따른다고 가정한다. 이를 바탕으로 pseudo-likelihood 최적화 목표를 설정한다.
이를 변분 후 조건부 확률을 적용하여 최적화 함수로 변환한다.
- 관계 추출 모델 를 통해 두 아이템 간 관계를 예측한다.
- 아이템 재구성 모델 를 통해 예측된 관계와 다른 아이템을 이용하여 원본 아이템을 재구성한다.
- 엔트로피 항()을 추가하여 관계 예측의 균형을 조정한다.
Pseudo-Likelihood
Pseudo-Likelihood 는 완전한 우도(likelihood)를 직접 계산하기 어려운 경우, 개별 변수의 조건부 확률을 곱하여 근사하는 방법이다.
즉, 전체 확률을 직접 계산하는 대신, 각 변수의 조건부 확률들의 곱으로 근사한다.
확률 모델에서 우도를 직접 계산하기 어려운 경우, Pseudo-Likelihood를 사용해 계산량을 줄이고 학습이 가능하도록 만든다.
- 장점 :
- 계산이 효율적이고 대규모 확률 모델에서도 사용 가능
- Markov Random Field(MRF), Conditional Random Field(CRF) 같은 그래픽 모델에서 학습 가능
- 정규화 상수를 계산할 필요 없음
- 한계 :
- 변수 간의 강한 상관관계를 잘 반영하지 못할 수 있음
- 샘플링 기반 방법(MCMC)보다 정확도가 낮을 수도 있음
- 독립 가정이 강해 일부 데이터 구조에서는 성능이 떨어질 수 있음
- 응용 분야:
- Markov Random Field (MRF), Conditional Random Field (CRF)
- NLP (개체명 인식, POS 태깅)
- Energy-Based Models (EBMs)
변분 (Variational)
변분은 함수 자체를 최적화하는 방법으로, 함수 공간에서 최적의 해를 찾는 과정이다.
- 일반 최적화는 수치를 찾지만, 변분은 함수를 최적화하는 과정
- 물리학, 머신러닝 등 다양한 분야에서 활용됨
- 주요 활용 예시
- 변분 미적분 : 최소 작용 원리 등 최적 경로 찾기
- 변분 추론 (VI) : 복잡한 확률 분포를 단순한 분포로 근사
- 변분 오토인코더 (VAE) : 잠재 변수 분포를 학습해 이미지 생성 등 활용
3.2.2 Relation Extraction
관계 추출 모델의 목표는 주어진 두 아이템 간의 잠재 관계를 예측하는 것이다.
- 기존 연구에서 속성 기반 관계는 수집이 비교적 용이하지만, 현실 세계에서는 복잡하고 다양한 관계가 존재하여 수동 정의가 어렵다.
- LLM이 언어적 지식을 통해 인간처럼 관계를 설명할 수 있다는 점에 착안하여, 아이템의 언어 지식 표현을 기반으로 관계를 추출하는 방식을 도입한다.
- LLM을 사용하여 아이템 텍스트의 토큰 시퀀스를 입력하고, 풀링(e.g. CLS-pooling, mean-pooling)을 적용하여 언어 지식 표현(language knowledge representation)을 얻는다.
이를 바탕으로, 관계 추출 모델은 경량 선형 분류기(softmax 기반)를 사용하여 관계를 예측한다.
Pooling
Pooling은 주로 컨볼루션 신경망(CNN)에서 사용되는 기법으로, 입력 데이터를 다운샘플링하여 중요한 특징만 추출하고 계산량을 줄이는 역할을 한다. 보통 이미지나 시퀀스 데이터를 처리할 때, 데이터의 크기를 줄이면서도 중요한 정보를 유지하려고 사용된다.
- 특징 추출 : 데이터에서 중요한 특징을 강조한다.
- 계산 효율성 : 데이터 크기를 줄여 계산량 감소시킨다.
- 과적합 방지 : 데이터의 세부적인 부분을 무시하고, 일반화된 특성만을 사용한다.
NLP에서 쓰이는 Pooling 기법은 문자, 단어, 또는 문서 수준에서 중요한 정보를 추출하기 위해 사용된다. NLP에서는 주로 단어 임베딩이나 문장의 임베딩을 처리할 때 Pooling 기법을 적용한다. 이 기법은 단어 수준의 임베딩을 하나의 고차원 벡터로 요약하는 데 유용하다.
3.2.3 Relational Item Reconstruction
관계 추출 모델을 통해 두 아이템 간의 잠재 관계를 추정한 후, 이를 기반으로 아이템 재구성 모델을 통해 아이템을 재구성한다.
- 아이템 재구성 과정에서는 DistMult를 사용하여 관계 임베딩을 적용한다.
- 모든 아이템을 고려하는 계산 복잡도를 줄이기 위해 네거티브 샘플링(negative sampling) 기법을 사용하여 최적화한다.
DisMult
DisMult는 지식 그래프 및 추천 시스템에서 관계 추론을 위한 모델로, 주어진 triple (head, relation, tail)에 대해 관계를 예측하는 방법이다. head 엔티티와 tail 엔티티의 벡터를 내적하여 관계를 예측한다. DisMult는 보통 관계형 데이터를 다룰 때 주로 사용되며, 특히 지식 그래프에서의 링크 예측(Link Prediction) 작업에 활용된다.
- 임베딩 기반 : DisMult는 각 엔티티와 관계를 벡터로 표현하고, 이를 통해 관계를 모델링한다.
- 내적 사용 : 모델은 관계 벡터와 엔티티 벡터 간의 내적을 계산하여 트리플의 가능성을 예측한다.
- 대칭성 가정 : DisMult는 모든 관계가 대칭적이라고 가정하고, 이를 통해 모델을 단순화한다.
3.3 LRD-based Sequential Recommendation
3.3.1 Relation-aware Sequential Recommendation
사용자의 과거 인터랙션 정보를 기반으로 선호도를 모델링하며, 아이템 간의 관계를 명시적으로 고려하여 더욱 정교한 추천이 가능하도록 한다.
- 사용자 u의 선호도 점수는 로 정의된다.
- 여기서 는 사용자의 과거 기록과 타겟 아이템 간의 관계를 고려한 사용자 이력 표현이다.
- 는 여러 관계 유형에 따른 사용자 시퀀스 표현을 집계(aggregation)하여 생성하며, 평균 풀링(mean-pooling), 최대 풀링(max-pooling), 어텐션 풀링(attention-pooling) 등의 방법을 사용할 수 있다.
- 관계의 강도를 고려하여 가중치를 적용하는 방식으로 아이템 표현을 구성한다.
3.3.2 Joint Learning
관계 인식 순차 추천 모델을 최적화하기 위해 BPR(Bayesian Personalized Ranking) pairwise loss를 사용한다.
- 잠재 관계 발견(LRD)과 추천 모델을 동시에 학습(joint optimization)한다.
- 이를 통해 추천 작업이 잠재 관계 발견을 돕도록 하고, 발견된 관계가 추천 성능 향상에 기여하도록 한다.
- 이를 위해 LRD의 최적화 목표를 추천 모델의 최적화 목표에 통합하여 함께 학습한다.
BPR pairwise loss
BPR (Bayesian Personalized Ranking) Pairwise Loss는 추천 시스템에서 사용자에게 아이템을 추천할 때 순위(rank)를 예측하기 위한 손실 함수이다. 주로 implicit feedback(사용자의 클릭, 구매 등) 데이터를 다룰 때 사용된다. BPR은 pairwise ranking 방식을 사용하여 두 아이템 간의 상대적 순위를 학습한다.
- Pairwise Ranking : BPR은 사용자와 관련된 두 아이템을 비교하며, 사용자가 특정 아이템을 선호하는지 여부를 학습한다.
- Loss Function : 손실 함수는 두 아이템을 비교하여, 사용자가 한 아이템을 선호하고 다른 아이템을 선호하지 않는 방식으로 학습한다.
- 임베딩 기반 : BPR은 사용자와 아이템을 임베딩 공간에 매핑하고, 해당 공간에서의 상대적인 거리를 학습한다.
- 순위 학습 : BPR은 아이템의 절대적인 점수가 아닌 상대적인 순위에 집중하여 학습한다.
4. Experiments
- RQ1 : LRD 강화된 관계 인식 순차 추천 모델의 효과는 무엇인가?
- RQ2 : LRD 강화된 관계 인식 순차 추천 모델의 각 구성 요소가 추천 성능에 기여하는가?
- RQ3 : LRD가 아이템 간 신뢰할 수 있는 중요한 관계를 발견하는가?
4.1 실험 설정
4.1.1 데이터셋
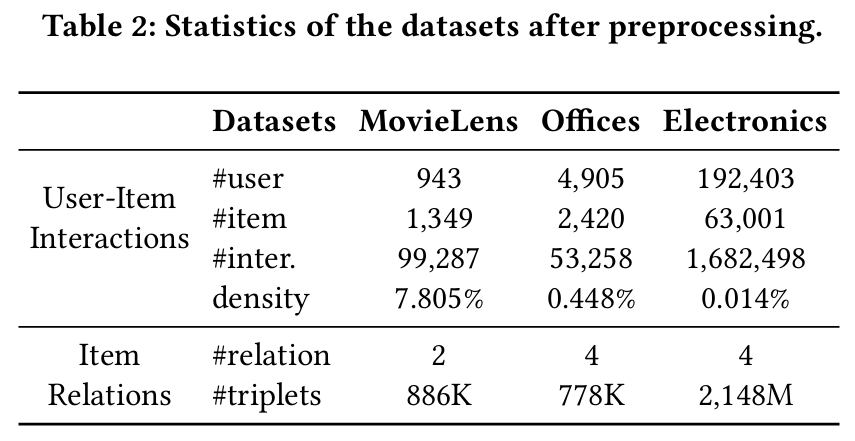
모델의 잠재적 관계 발견 능력을 평가하기 위해 세 가지 공개 데이터셋을 사용한다.
- MovieLens : 영화 추천을 위한 데이터셋으로, 사전 정의된 관계(출시 연도, 장르)와 IMDB에서 추가로 크롤링한 영화 정보로 잠재적 관계를 발견한다.
- Amazon Office 제품 및 전자제품 : 아마존 전자상거래 데이터셋의 두 하위집합으로, 사전 정의된 관계(카테고리, 브랜드)와 아이템 제목, 카테고리, 브랜드를 통해 잠재적 관계를 발견한다.
4.1.2 비교 모델
여러 가지 순차 추천 모델이 비교 모델로 사용된다.
- Caser : convolutional 필터를 사용하여 사용자 시퀀스의 순차적 패턴을 포착하는 모델이다.
- GRU4Rec : Gated Recurrent Units(GRU)를 활용하여 사용자 상호작용 시퀀스의 패턴을 학습하고 사용자 표현을 모델링하는 방식이다.
- SASRec : self-attention 메커니즘을 도입하여 과거 항목의 표현을 통합하고 사용자 표현을 학습한다.
- TiSASRec : SASRec을 기반으로 하며, 과거 상호작용 간의 시간 간격을 추가로 고려하는 방식이다.
- RCF : 두 단계로 이루어진 attention 네트워크를 활용하여 아이템 간 관계를 사용자 시퀀스 표현 모델링에 통합한다.
- KDA : 푸리에 변환 기반의 시간적 진화 모듈을 도입하여 아이템 관계의 동적 변화를 효과적으로 포착하는 모델이다.
제안된 LRD 방법은 RCF와 KDA 모델을 향상시켜 RCFLRD와 KDALRD를 비교 모델로 사용한다.
4.1.3 평가 지표
추천 모델 성능을 평가하기 위해 HR@K와 nDCG@K 지표를 사용하며, K는 5와 10으로 설정된다. 데이터셋은 leave-one-out 방식으로 구성하고, 다섯 번의 랜덤 실행을 통해 평균 지표를 평가한다.
leave-one-out
Leave-One-Out은 교차 검증의 한 종류로, 주로 모델의 성능을 평가할 때 사용된다. 이 방법은 주어진 데이터셋에서 각 샘플을 하나씩 제외하고, 나머지 데이터로 모델을 학습하여 그 샘플에 대한 예측을 평가하는 방식이다. 특히 데이터가 적거나 성능을 정확하게 평가하고 싶을 때 유용하게 사용된다.
- 각 샘플을 한 번씩 테스트 데이터로 사용 : 각 샘플이 한 번은 모델의 테스트에 사용되므로, 모델이 모든 샘플에 대해 평가된다.
- 완전한 검증 : 모든 데이터가 훈련과 테스트에 사용되므로 모델에 대한 신뢰성을 높일 수 있다.
- 과적합 방지 : 모델이 훈련 데이터에 너무 적합되는 것을 방지하는 데 도움이 된다.
- 소규모 데이터셋에 유용 : 데이터셋이 작을 때, 가능한 모든 데이터를 테스트에 활용할 수 있어 효과적이다.
- 시간 소모 : 데이터셋의 크기가 커지면, 모든 샘플을 하나씩 제외하고 학습 및 예측을 반복해야 하므로 계산 비용이 많이 든다.
4.1.4 구현 세부사항
LRD와 비교 모델은 ReChorus 라이브러리로 구현되며, 아이템의 언어 지식 표현을 얻기 위해 GPT-3을 사용한다. 여러가지 하이퍼파라미터를 튜닝하였고, 관계 추출 모델의 정규화 계수는 0.1로 설정된다.
4.2 성능 비교 (RQ1)
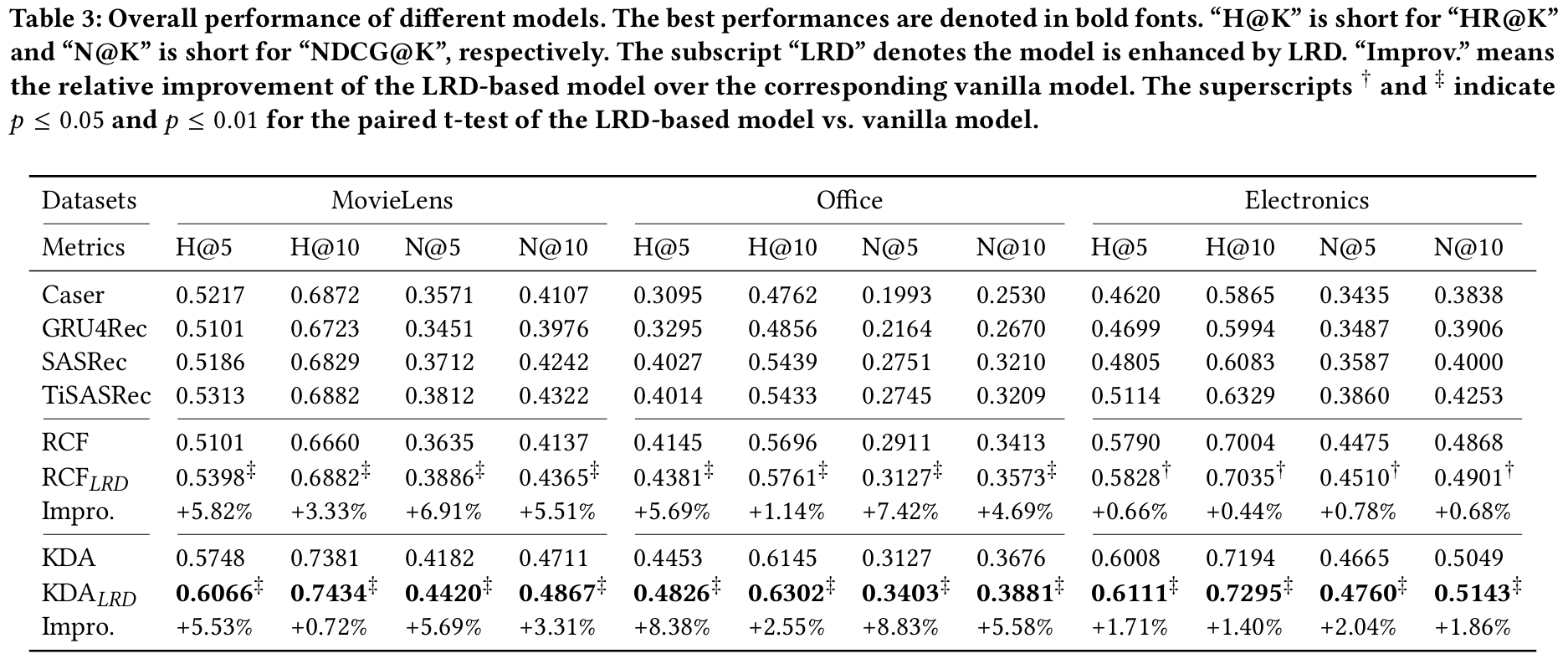
실험 결과 :
- 전통적인 순차 추천 모델은 MovieLens와 같은 밀집된 데이터셋에서는 성능 차이가 크지 않지만, 아마존과 같은 희소한 데이터셋에서는 성능이 저조하다.
- 아이템 관계를 포함한 RCF와 KDA 모델은 전통적인 모델보다 우수한 성능을 보인다.
- LRD를 강화한 RCFLRD와 KDALRD는 사전 정의된 관계가 적은 데이터셋에서 더 높은 성능을 발휘하며, 잠재적 관계를 발견하여 성능을 크게 향상시킨다.
4.3 구성 요소 분석 (RQ2)
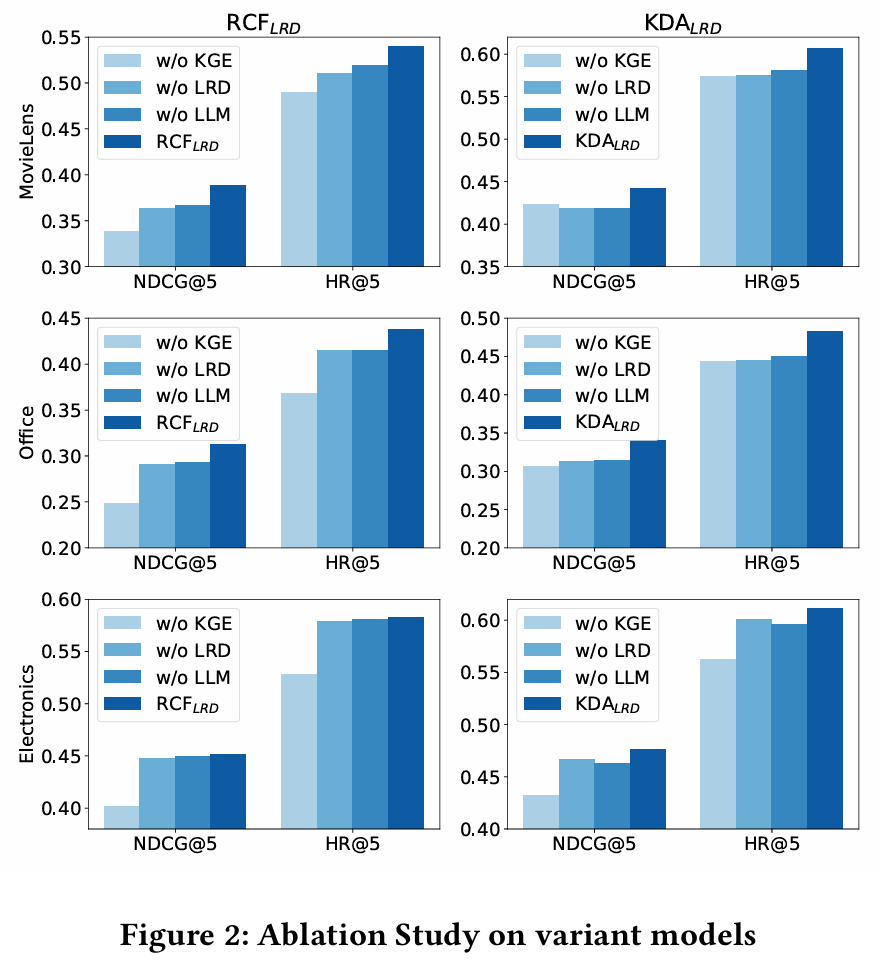
LRD 기반 모델의 각 구성 요소가 추천 성능에 미치는 영향 분석 :
- w/o LLM : LLM을 제외하면 성능이 크게 떨어진다. 이는 LLM의 풍부한 언어 지식이 잠재적 관계를 발견하는 데 중요한 역할을 함을 의미한다.
- w/o KGE : 지식 그래프 임베딩 작업을 제외하면 성능이 감소하며, 이는 사전 정의된 관계를 모델링하는 것이 중요함을 시사한다.
4.4 잠재적 관계 분석 (RQ3)
LRD가 발견한 잠재적 아이템 관계의 신뢰성을 평가하기 위한 추가 실험 :
- 관계 임베딩 : 잠재적 관계와 사전 정의된 관계 간에 명확한 차이가 있다. LRD는 관계 추출 모델을 통해 사전 정의된 관계와 잠재적 관계를 구별할 수 있다.
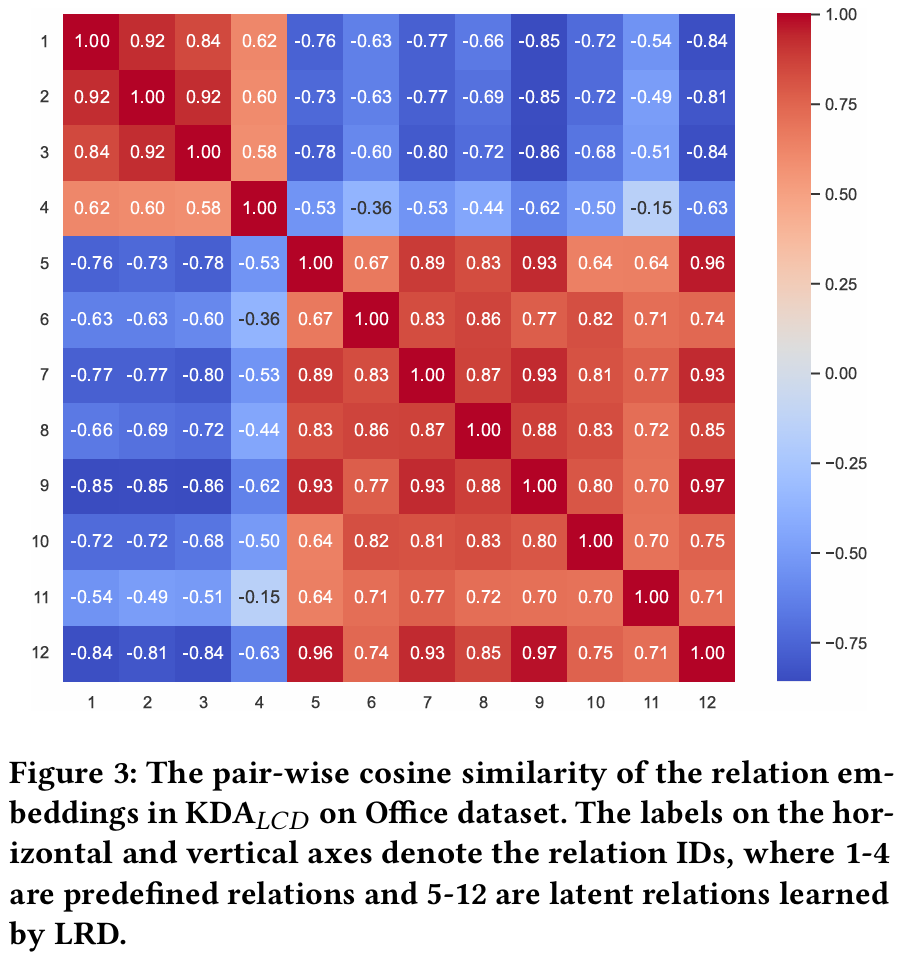
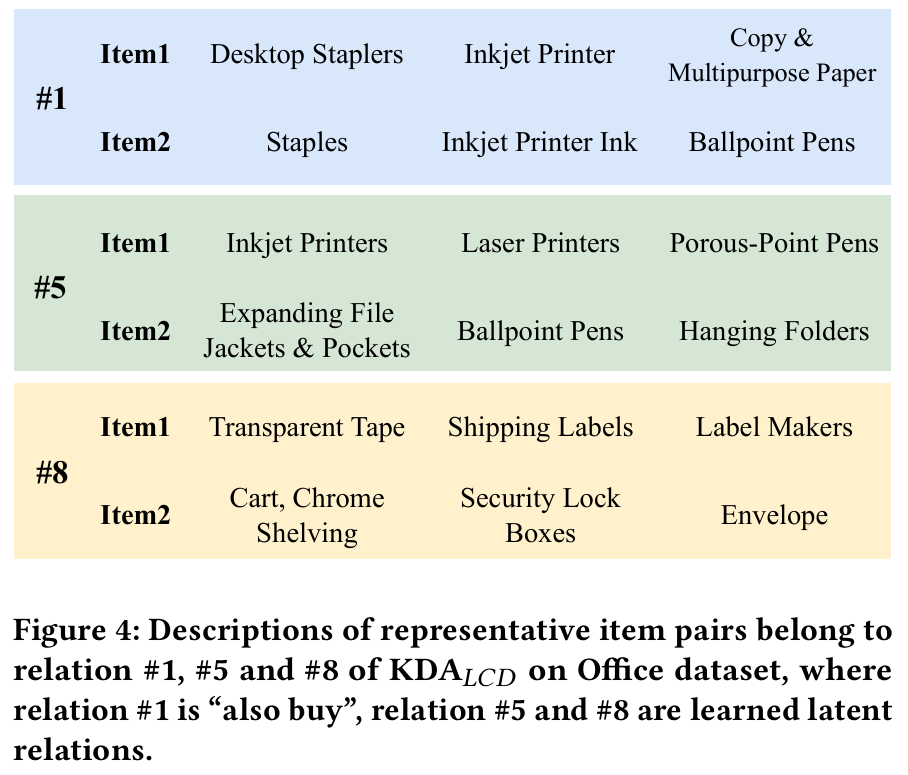
- 잠재적 관계 아이템 : 모델은 복잡한 다단계 관계를 학습하여 사전 정의된 관계를 넘어서는 더 정교한 사용자 선호를 포착한다.
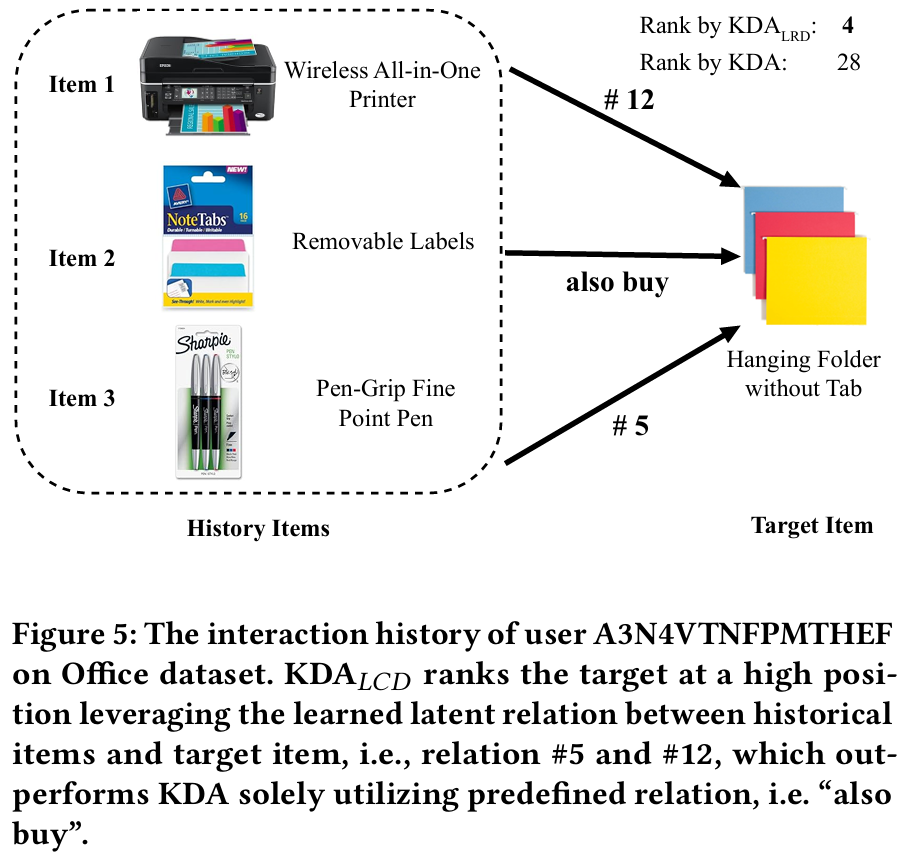
- 사례 연구 : KDA 모델은 사전 정의된 관계만을 기반으로 추천하나, LRD 기반 모델은 잠재적 관계를 발견하여 더 나은 성능을 보인다.
4.5 하이퍼파라미터 민감도 분석
LRD의 두 중요한 하이퍼파라미터에 대해 민감도 분석 수행 :
- num_latent : 잠재적 관계의 수에 따라 성능이 달라지며, 각 데이터셋에 대해 최적의 값이 다르다.
- λ : 잠재적 관계 발견 작업의 계수는 일정 값까지 성능 향상을 보이고, 이후 최적 값을 찾을 수 있다.
6. Conclusion
본 논문에서는 LLM을 기반으로 잠재 아이템 관계를 발견하는 새로운 방법인 LRD(Latent Relation Discovery)를 제안한다. LRD는 자기 지도 학습 접근 방식을 활용하여 LLM의 풍부한 지식을 통해 잠재 아이템 관계를 효과적으로 추출한다. 이 방법은 기존의 관계 인식 순차 추천 시스템과 함께 공동 최적화되어, 다음과 같은 두 가지 주요 기여를 한다.
- 잠재 관계의 제공 : LRD가 발견한 잠재 관계는 더 정교한 아이템 연관을 제공하며, 이를 통해 복잡한 사용자 선호를 충분히 모델링할 수 있다.
- 사용자 상호작용 신호의 활용 : 사용자 상호작용에서 얻은 감독 신호는 관계 발견 과정을 효과적으로 안내하며, 잠재 관계의 정확도를 높인다.
여러 공개 데이터셋에 대한 실험 결과, LRD는 기존의 관계 인식 순차 추천 방법들의 성능을 크게 향상시킨다. 추가 분석을 통해 LRD가 발견한 잠재 관계가 신뢰할 수 있음을 확인할 수 있었다. 그러나 현재 구현에서는 LLM이 세밀하게 선택되지 않았다는 점에서, 향후 작업으로 더 발전된 LLM을 사용하는 것이 성능 향상에 중요한 영향을 미칠 가능성이 높다.
