[논문] Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System [arxiv]
Sein Kim KDD 24
📝 Key Point
-
LLM과 협업 필터링(CF-RecSys)을 결합한 추천 시스템 A-LLMRec을 제안한다.
-
기존 CF-RecSys와 쉽게 통합 가능하며, 업데이트도 간단하다.
-
fine-tuning 없이 CF-RecSys의 협업 지식을 LLM이 직접 활용하도록 설계했다.
-
CF-RecSys의 협업 지식과 아이템 텍스트 정보를 결합하여 LLM의 입력으로 사용한다.
-
사용자의 행동 이력과 아이템 정보를 포함하는 텍스트 기반 프롬프트를 통해 맞춤형 추천을 수행한다.
Abstract
문제 정의 : 기존의 협업 필터링 기반 추천 시스템은 Cold 시나리오에서 성능이 저하되는 문제가 있다. 반면, LLM을 활용한 기존 접근법은 협업 지식이 부족해 Warm 시나리오에서 성능이 낮다.
연구 목표 : Cold 시나리오와 Warm 시나리오 모두에서 우수한 성능을 발휘할 수 있는 효율적인 추천 시스템인 A-LLMRec을 제안한다.
핵심 아이디어 : 사전 학습된 최신 CF-RecSys의 협업 지식을 LLM에 직접 전달하여, LLM의 새로운 능력과 CF-RecSys가 학습한 고품질 사용자 및 아이템 임베딩을 통합적으로 활용한다.
주요 장점 :
- 모델 독립성 : 다양한 CF-RecSys와 쉽게 통합 가능하다.
- 효율성 : CF-RecSys와 LLM의 추가적인 파인튜닝 없이 정렬 네트워크만 학습하여 효율적으로 성능을 극대화한다.
결과 : 실제 데이터셋 실험에서 A-LLMRec은 cold/warm, few-shot, cold user, cross-domain 시나리오에서도 우수한 성능을 보인다.
Figure
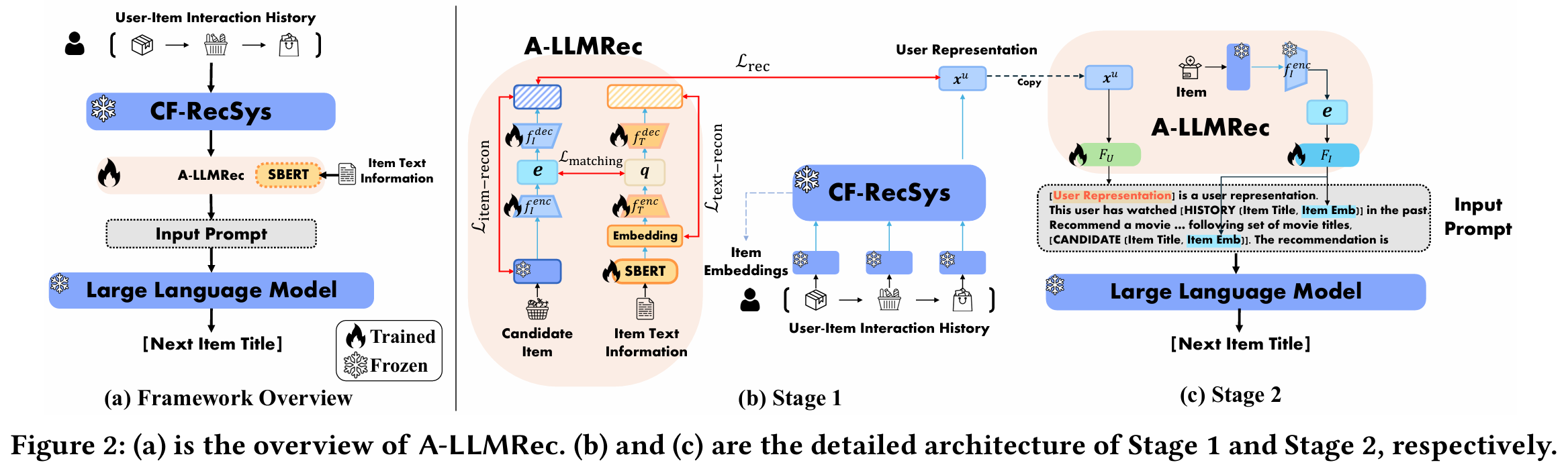
(a) Framework Overview
- 목표 : 협업 필터링 추천 시스템에서 얻은 협업 지식과 텍스트 정보를 LLM의 입력 토큰 공간에 결합한다.
- 과정 :
- 사용자-아이템 상호작용 이력을 CF-RecSys를 통해 학습한다.
- 아이템 텍스트 정보를 SBERT를 통해 학습한다.
- 상호작용 정보와 텍스트 정보를 A-LLMRec을 통해 결합하여 프롬프트를 생성한다.
- 프롬프트를 LLM에 입력하여 다음 아이템을 예측한다.
- Trained / Frozen : CF-RecSys와 LLM은 Frozen하고, A-LLMRec만 학습시킨다.
(b) Stage 1 : Alignment between Collaborative and Textual Knowledge
- 목적 : 협업 지식과 텍스트 지식을 정렬(alignment)한다.
- 구성 요소 :
- SBERT(Sentence-BERT) : 텍스트 임베딩 추출.
- 아이템 및 텍스트 인코더 : CF-RecSys에서 얻은 아이템 임베딩을 텍스트 임베딩과 정렬.
- Loss 재구성 : 데이터의 원래 정보를 유지하며 과도한 평균화 방지.
- 이 과정에서 CF-RecSys와 SBERT를 함께 사용하여 고품질 임베딩을 생성한다.
(c) Stage 2 : Alignment between Joint Collaborative-Text Embedding and LLM
- 목적 : Stage 1에서 얻은 협업 텍스트 임베딩을 LLM의 토큰 공간과 정렬한다.
- 구성 요소 :
- 2-layer MLP : 사용자 표현과 공동 임베딩을 LLM의 토큰 공간으로 매핑.
- Prompt Engineering : 사용자 상호작용 이력과 아이템 정보를 포함하는 구조화된 프롬프트를 설계하여 LLM이 추천 작업을 수행하도록 지원.
1. Introduction
배경 및 문제 정의
- 추천 시스템의 발전에도 불구하고, 협업 필터링(CF) 모델은 사용자-아이템 상호작용 데이터가 희소한 Cold 시나리오에서 성능 저하를 겪고 있다.
- 최근 연구는 사용자 및 아이템의 텍스트나 이미지 같은 모달리티 정보를 활용하여 이러한 문제를 해결하려 했지만, Warm 시나리오에서는 협업 지식 부족으로 전통적인 CF 모델보다 성능이 낮아지는 한계가 있다.
모달리티 기반 접근법의 한계
- LLM은 풍부한 언어 이해 능력 덕분에 모달리티 정보를 잘 활용하지만, 협업 지식 없이 Warm 시나리오에서 효과적이지 않다.
- 텍스트 정보는 Cold 시나리오에서는 유용하지만, 데이터가 풍부한 Warm 시나리오에서는 중요성이 줄어들며, ID 기반 CF 모델이 주도적인 역할을 한다.
문제의 중요성
- 실제 추천 시스템의 상호작용이나 수익은 대부분 Warm 아이템에서 발생한다. 이는 Warm 시나리오를 간과해서는 안 된다는 것을 의미한다.
- Cold 아이템과 Warm 아이템 모두를 적절히 모델링해야 사용자 참여를 극대화할 수 있다.
제안 방법 : A-LLMRec
- 이 연구에서는 Cold 시나리오와 Warm 시나리오 모두에서 우수한 성능을 발휘하는 A-LLMRec을 제안한다.
- A-LLMRec은 사전 학습된 CF-RecSys에서 학습된 협업 지식을 LLM에 직접 전달하여, CF-RecSys의 고품질 사용자/아이템 임베딩과 LLM의 새로운 능력을 결합한다.
- 이 방법은 추가적인 CF-RecSys나 LLM의 파인튜닝 없이, 정렬 네트워크만 학습해 효율적이고 실용적이다.
2. Related Work
2.1 Collaborative Filtering
- 핵심 아이디어 : 사용자 및 아이템의 과거 상호작용 데이터를 활용해 추천을 생성하며, 유사한 사용자/아이템을 기반으로 추천을 수행한다.
- 진화 과정 :
- 행렬 분해(Matrix Factorization) : 잠재 요인을 활용하여 사용자 선호도를 효과적으로 포착하며, 확률적 행렬 분해(PMF)와 특이값 분해(SVD)로 발전하였다.
- 심층 신경망 사용 : AutoRec과 Neural Matrix Factorization(NMF)은 딥러닝을 사용해 복잡한 사용자-아이템 상호작용 패턴을 모델링하였다.
- 순차적 상호작용 : Caser와 NextItNet은 CNN을 활용해 사용자 상호작용 히스토리를 기반으로 협업 필터링을 개선하였다.
- 한계 : 사용자 및 아이템의 텍스트, 이미지 등 모달리티 정보 활용 부족으로 성능 향상이 제한적이다.
2.2 Modality-aware Recommender Systems
- 기본 개념 : 아이템의 텍스트 설명, 이미지 등 모달리티 정보를 활용하여 Cold 시나리오에서 추천 성능을 향상한다.
- 주요 모델 :
- NOVA와 DMRL은 텍스트와 아이템 임베딩을 효과적으로 통합하여 추천 성능을 개선하였다.
- MoRec은 BERT와 같은 사전 학습된 모달리티 인코더를 활용해 아이템의 텍스트 정보를 협업 필터링 모델에 통합하였다.
- RECFORMER는 Transformer 구조를 기반으로 텍스트 정보를 아이템 속성으로 변환하여 추천 작업을 수행하였다.
- 한계 : Warm 시나리오에서는 협업 지식 부족으로 성능이 저하되며, ID 기반 협업 필터링 모델에 비해 성능이 좋지 않다.
2.3 LLM-based Recommender Systems
- 기본 개념 : LLM의 풍부한 사전 학습 지식과 언어 이해 능력을 활용하여 추천 작업을 수행한다.
- 주요 연구 :
- In-context Learning : 다양한 프롬프팅 스타일(completion, instructions, few-shot prompts)을 활용하여 아이템 텍스트를 기반으로 추천 수행한다.
- TALLRec은 LoRA를 활용해 LLM을 fine-tuning하여 Cold 시나리오와 cross-domain 시나리오에서 효과적인 추천 성능을 제공한다.
- 한계 : 기존 모델은 추천 작업을 단순히 instruction 텍스트로 변환해 fine-tuning을 수행하나, 협업 지식을 명시적으로 포착하지 못해 Warm 시나리오에서는 성능이 제한적이다.
3. Problem Formulation
데이터 구성 요소
- 사용자와 아이템 : 데이터셋은 사용자 집합, 아이템 집합, 아이템 텍스트 정보(제목 및 설명), 그리고 사용자-아이템 상호작용 시퀀스로 구성된다.
- 아이템 상호작용 시퀀스 : 각 사용자에 대해 과거의 아이템 상호작용 이력으로 구성된 순서 데이터를 포함한다.
- 텍스트 정보 : 각 아이템은 텍스트 제목과 설명 정보를 가지고 있다.
문제 정의
- 목표 : 사용자의 과거 상호작용 기록을 기반으로 다음으로 추천할 아이템을 예측하는 것이다.
- 주어진 정보 : 사용자 상호작용 이력, 아이템의 텍스트 정보, 아이템의 벡터 임베딩
추천 시스템의 활용
- 순차적 추천 (Sequential Recommendation) : 사용자 상호작용 시퀀스를 분석하여 다음으로 상호작용할 가능성이 높은 아이템을 추천한다.
- 비순차적 추천 (Non-Sequential Recommendation) : 순차 데이터가 없는 경우에도 CF-RecSys 백본 모델을 교체하여 적용 가능하다.
A-LLMRec의 확장성
- 모델 구조는 유연하며, CF-RecSys의 백본을 교체하거나 다양한 도메인에 적용 가능하다.
- Cold 시나리오와 Warm 시나리오 모두에 적합한 방식으로 설계되었다.
4. Proposed Method: A-LLMRec
A-LLMRec은 최신 협업 필터링 추천 시스템(CF-RecSys)과 대형 언어 모델(LLM)을 결합하여 Cold 시나리오와 Warm 시나리오 모두에서 뛰어난 성능을 발휘할 수 있는 추천 시스템이다. 이를 위해 모달리티 차이를 줄이고 CF-RecSys의 협업 지식을 LLM의 토큰 공간과 정렬(alignment)하는 작업을 수행한다. 이 접근법은 크게 두 가지 단계로 구성된다.
4.1 Alignment between Collaborative and Textual Knowledge (Stage-1)
목표 : CF-RecSys로부터 얻어진 아이템 임베딩을 해당 텍스트 정보와 정렬하여 협업 지식과 텍스트 정보를 동시에 활용할 수 있도록 한다.
구성 요소 :
- Sentence-BERT(SBERT) : 텍스트 정보를 임베딩하여 효율적으로 아이템의 텍스트 특징을 추출한다.
- 아이템 인코더 : CF-RecSys에서 얻은 아이템 임베딩을 잠재 공간으로 변환한다.
- 텍스트 인코더 : SBERT에서 추출된 텍스트 임베딩을 잠재 공간으로 변환한다.
정렬 과정 :
- 잠재 공간에서 아이템 임베딩과 텍스트 임베딩을 정렬하여 협업 정보와 텍스트 정보를 결합한다.
- 원활한 정렬을 위해 두 인코더를 훈련시키고, 추가적으로 원래 데이터의 정보를 보존하기 위해 디코더를 활용한다.
- Cold 아이템이나 새로운 아이템의 경우, 텍스트 인코더를 통해 협업-텍스트 임베딩을 생성하여 활용한다.
4.1.1 Avoiding Over-smoothed Representation
문제점 :
- 단순히 협업 임베딩과 텍스트 임베딩의 정렬 손실()을 최적화하면 과도한 평균화(over-smoothing)가 발생할 수 있다. 즉, 인코더의 출력이 지나치게 비슷해져 가 되는 문제가 생긴다.
해결 방법 :
- 인코더마다 디코더를 추가하여 원래 데이터 정보를 보존한다.
- 재구성 손실(, )을 도입하여 인코더가 의미 있는 원래 정보를 유지하도록 학습시킨다.
4.1.2 Recommendation Loss
목적 : 협업 지식을 모델에 명시적으로 전달하고 추천 작업을 학습 목표로 포함시킨다.
정의 : 추천 작업에서 사용자-아이템 상호작용 이력과 정렬 임베딩을 활용하여 다음 아이템을 예측한다.
4.1.3 Final Loss of Stage-1
목표 : 정렬 Loss, 재구성 Loss, 추천 Loss를 통합하여 Stage-1의 최종 학습 목표를 정의한다.
4.1.4 Joint Collaborative-Text Embedding
정의 : 로 학습된 아이템 임베딩을 협업-텍스트 임베딩으로 정의하며, 협업 지식과 텍스트 정보를 포함한다.
Cold 아이템 처리 : 상호작용이 없는 아이템의 경우 텍스트 인코더를 사용하여 협업-텍스트 임베딩을 생성한다.
4.2 Alignment between Joint Collaborative-Text Embedding and LLM (Stage-2)
Stage-2의 목적은 Stage-1에서 생성된 Joint Collaborative-Text Embedding을 LLM의 토큰 공간과 정렬하고, 이를 통해 LLM이 추천 작업을 수행할 수 있도록 구성하는 것이다. 이 단계는 크게 두 가지 핵심 작업인 Embedding Projection과 Prompt Design으로 나뉜다.
4.2.1 Embedding Projection
목적 :
- 사용자 표현(User Representations)과 공동 임베딩(Joint Collaborative-Text Embedding)을 LLM의 토큰 공간으로 매핑하여 LLM이 이를 입력으로 처리할 수 있도록 한다.
방법 :
- 두 개의 2-layer MLP를 사용한다.
- 사용자 표현 를 LLM 토큰 공간으로 매핑 :
- 공동 임베딩 를 LLM 토큰 공간으로 매핑 :
- LLM 토큰 공간에서의 사용자 및 아이템 표현으로 매핑된 임베딩은 이후 LLM 입력 프롬프트에 통합된다.
4.2.2 Prompt Design for Integrating Collaborative Knowledge
목적 :
- 추천 작업에 필요한 협업 지식과 텍스트 정보를 LLM이 활용할 수 있도록 적절한 텍스트 프롬프트를 설계한다.
구성 방식 :
- 사용자 정보 포함 : 프롬프트 시작 부분에 사용자 표현 를 배치하여 개인화된 추천을 수행할 수 있는 기초 정보를 제공한다.
- 후보 아이템 정보 포함 : 후보 아이템 제목과 함께 매핑된 임베딩 를 추가하여, LLM이 사용자의 선호도를 기반으로 아이템을 추천하도록 유도한다.
- 구조화된 입력 프롬프트 설계 : 사용자 히스토리, 후보 아이템, 그리고 추천 작업에 대한 지시를 포함한 텍스트 프롬프트를 생성한다.
프롬프트 예시 :

5. Experiments
5.1 Experimental Setup
Datasets
- Movies and TV : 약 30만 명의 사용자와 6만 개의 아이템으로 구성된 대규모 데이터셋이다.
- Video Games : 중간 규모 데이터셋으로, 6만 명의 사용자와 3만 3천 개의 아이템으로 구성된다.
- Beauty : 작고 Cold한 데이터셋으로, 9천 명의 사용자와 6천 개의 아이템으로 구성된다.
- Toys : 아이템의 수가 사용자 수보다 많은 데이터셋으로, 약 3만 명의 사용자와 6만 개의 아이템을 포함한다.
Baselines
- Collaborative Filtering Models : NCF, NextItNet, GRU4Rec, SASRec
- Modality-aware Models : MoRec, CTRL, RECFORMER
- LLM-based Models : LLM-Only, TALLRec, MLP-LLM
Evaluation Settings
- 사용자 시퀀스를 Training, Validation, Test 세트로 분리한다.
- 가장 최근에 상호작용한 아이템은 테스트 세트에 포함한다.
- 그 이전 아이템은 검증 세트에 포함한다.
- 나머지 시퀀스는 학습 세트로 사용한다.
- Hit@1 평가 지표를 사용한다.
Implementation Details
- SASRec을 사전학습된 CF-RecSys로 사용하고, OPT-6.7B를 백본 LLM으로 사용한다.
- 모델을 효율적으로 학습시키기 위해 하이퍼파라미터를 튜닝한다.
5.2 Performance Comparison
5.2.1 Overall Performance
결과 :
- A-LLMRec은 Movies and TV, Video Games, Beauty, 그리고 Toys 데이터를 사용한 실험에서 다른 모든 추천 모델들보다 Hit@1 메트릭 기준으로 우수한 성능을 기록했다.
- A-LLMRec은 특히 LLM 기반 모델과 비교할 때, 협업 지식을 효과적으로 활용하여 높은 정확도를 보인다.

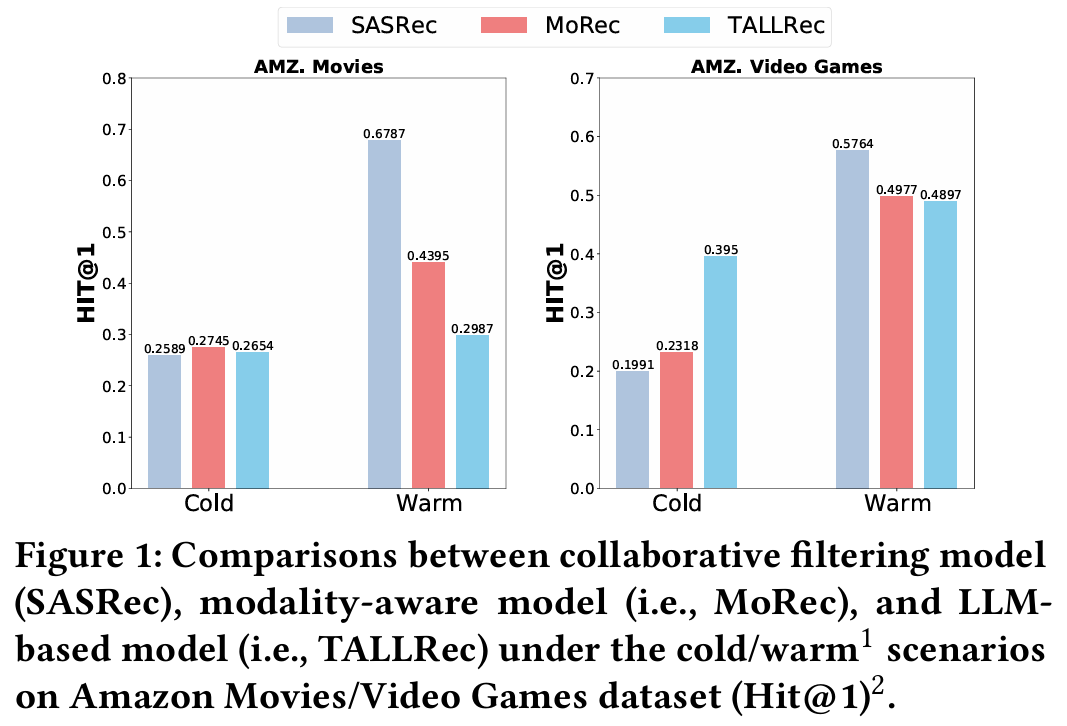
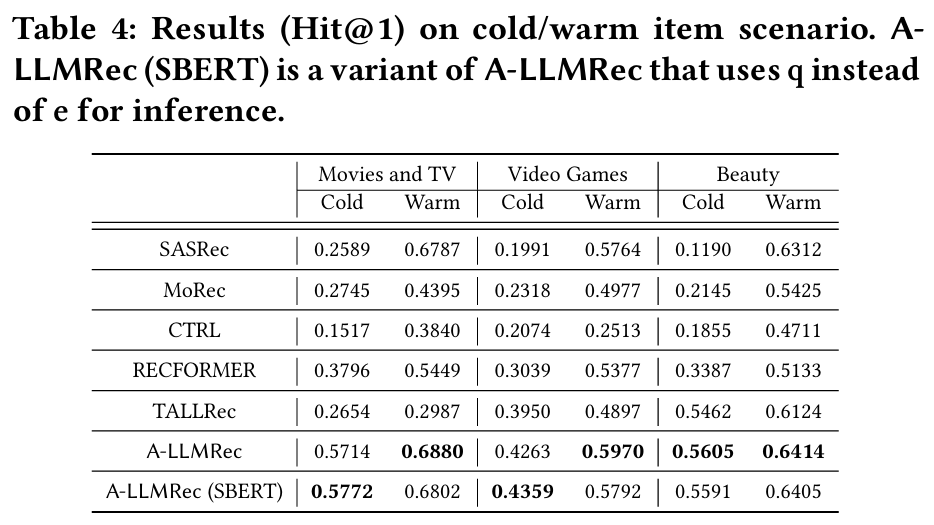
5.2.2 Cold/Warm Item Scenario
목적 : Cold 아이템(상호작용 데이터가 적은 아이템)과 Warm 아이템(상호작용 데이터가 풍부한 아이템)을 각각 평가하여 모델의 성능을 분석한다.
결과 :
- Cold 시나리오 : A-LLMRec이 다른 모델들보다 뛰어난 정확도를 기록하며 Cold 아이템 추천에서 우수한 성능을 입증한다.
- Warm 시나리오 : A-LLMRec은 전통적인 협업 필터링 모델(CF-RecSys)보다도 성능이 우수하여 모든 시나리오에서 높은 추천 품질을 유지한다.
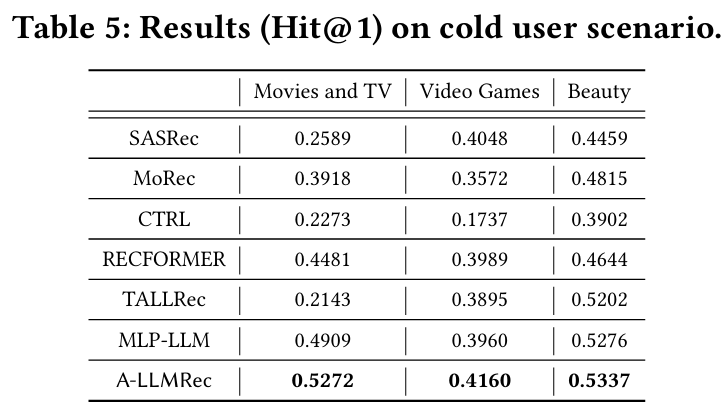
5.2.3 Cold User Scenario
목적 : Cold 사용자를 대상으로 모델의 추천 성능을 평가한다.
결과 : A-LLMRec은 협업 지식과 텍스트 정보를 효과적으로 결합하여 다른 모델 대비 높은 정확도를 유지한다.
5.2.4 Few-shot Training Scenario
목적 : 제한된 학습 데이터를 사용하여 A-LLMRec의 성능을 평가하고 적응력을 분석한다.
결과 : A-LLMRec은 Few-shot 환경에서도 다른 모델들보다 안정적으로 높은 성능을 발휘한다.
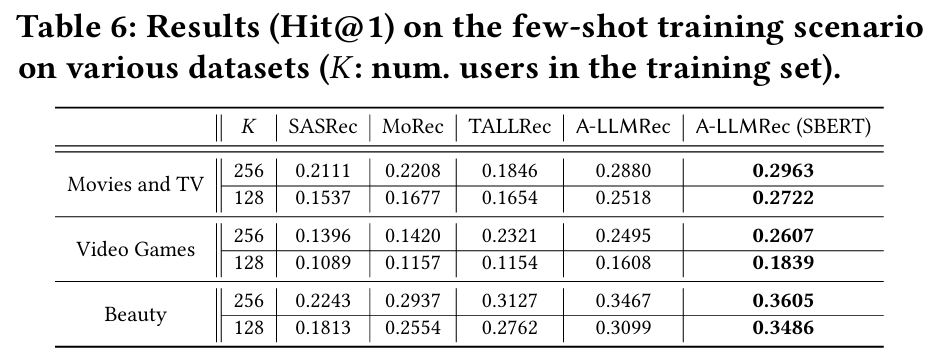
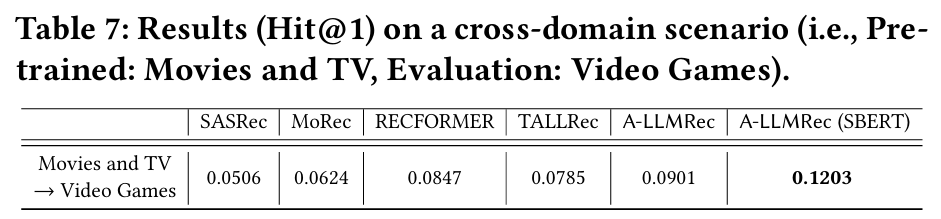
5.2.5 Cross-domain Scenario
목적 : 도메인 간 데이터셋을 사용하여 모델의 일반화 능력을 테스트한다.
결과 : A-LLMRec은 도메인 전환 상황에서도 우수한 성능을 유지하여 강력한 확장성을 입증한다.
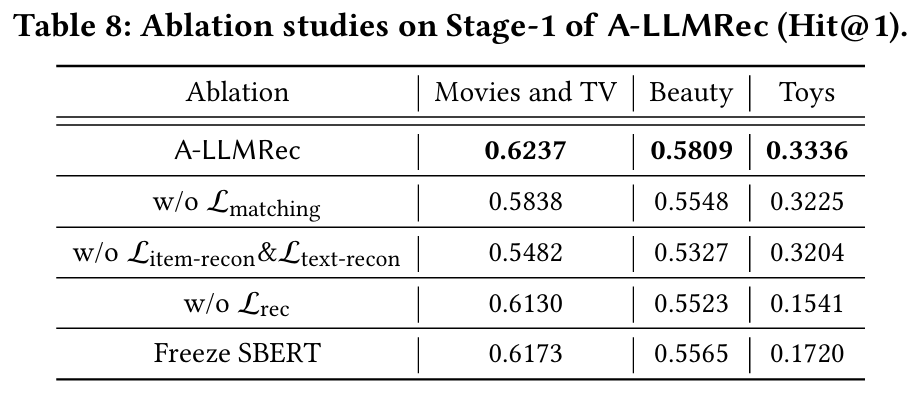
5.3 Ablation Studies
5.3.1 Stage-1 구성 요소의 영향
실험 목적 : Stage-1에서 각 구성 요소(손실 함수)가 모델 성능에 미치는 영향을 분석한다.
실험 방법 : 각 손실 함수를 제거했을 때의 성능 변화를 관찰한다.
결과 및 분석
- 제거 : 모든 데이터셋에서 성능이 크게 감소한다. 이는 아이템과 텍스트 정보 간의 정렬이 효과적이며, LLM이 협업-텍스트 임베딩을 통해 아이템 텍스트 정보를 이해하고 추천 능력을 향상시킬 수 있음을 의미한다.
- 및 제거 : 성능이 저하된다. 이는 Section 4.1.1에서 논의된 바와 같이 표현이 과도하게 평활화될 위험 때문이다.
- 제거 : 성능이 저하된다. Lrec는 추천 작업에 대한 정보를 모델에 제공하면서 협업 지식을 명시적으로 통합하기 위해 도입되었으므로, 제거 시 아이템과 사용자 간의 협업 지식이 감소하여 추천 성능이 저하된다.
- SBERT 고정 : 모든 데이터셋에서 성능이 저하된다. 이는 SBERT를 fine-tuning하면 텍스트 임베딩이 추천 작업에 더 잘 적응할 수 있음을 의미한다.
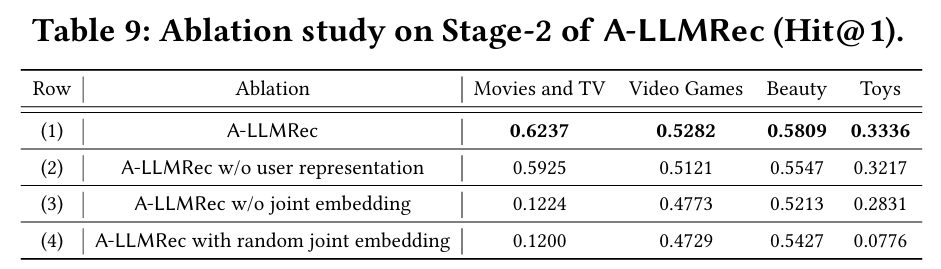
5.3.2 Stage-2 정렬 방법의 영향
실험 목적 : Stage-2에서 사용자 표현 및 아이템 임베딩을 LLM 프롬프트에 주입하는 것이 얼마나 효과적인지 검증한다.
실험 방법 : 사용자 표현 또는 joint embedding을 프롬프트에서 제거하거나, joint embedding을 랜덤 임베딩으로 대체했을 때의 성능 변화를 관찰한다.
결과 및 분석
- 사용자 표현 또는 joint embedding 제거 : 모든 데이터셋에서 성능이 감소한다. 특히 joint embedding을 제거했을 때 성능 감소가 더 큰데, 이는 joint embedding이 협업 지식을 전달하는 데 중요한 역할을 한다는 것을 의미한다. Joint embedding은 아이템에 대한 텍스트 정보도 캡처하므로, 이를 제거하면 성능에 더욱 부정적인 영향을 미친다.
- Joint embedding을 랜덤 임베딩으로 대체 : 모든 데이터셋에서 성능이 저하된다. 이는 A-LLMRec가 협업 지식 없이 아이템 임베딩으로 학습될 때 성능이 떨어진다는 것을 의미하며, 추천에 협업 지식을 활용하는 것이 중요하다는 것을 시사한다.
5.4 Model Analysis
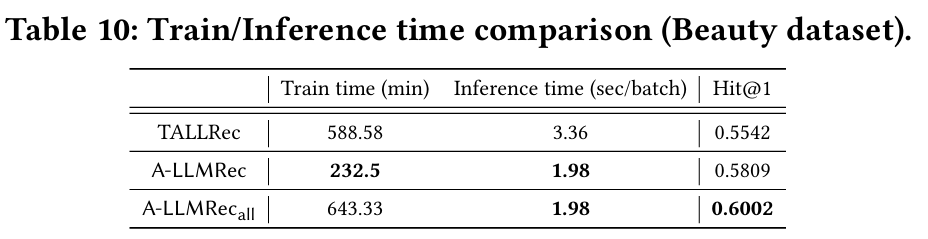
5.4.1 Train/Inference Speed
- 효율성 : A-LLMRec은 CF-RecSys나 LLM의 fine-tuning을 요구하지 않고, alignment network만 훈련하여 효율적으로 작동한다. 반면, TALLRec은 LoRA를 통해 LLM을 fine-tuning해야 한다.
- 비교 : A-LLMRec과 TALLRec의 훈련 및 추론 시간을 비교한 결과, A-LLMRec이 TALLRec보다 훨씬 빠른 훈련 및 추론 시간을 보인다. 특히 훈련 시간이 크게 개선되었으며, 이는 A-LLMRec이 LLM fine-tuning을 필요로 하지 않기 때문이다.
- 결론 : A-LLMRec의 높은 효율성은 대규모 추천 데이터셋 및 실시간 추천 서비스에서의 실용성을 보여준다.
5.4.2 Training with all items in each sequence
- 기본 설정 : Stage-1과 Stage-2의 최종 Loss를 최소화하기 위해 각 사용자 시퀀스의 마지막 아이템만 사용하여 훈련을 진행한다.
- 실험 방법 : 각 사용자 시퀀스의 모든 아이템을 활용하여 추천 성능을 개선한다.
- 실험 결과 :
- 모든 아이템을 활용할 경우 Hit@1 지표 기준으로 추천 성능이 개선된다.
- 그러나 훈련 시간이 약 3배 이상 증가했으며, 성능 향상은 상대적으로 미미하다.
- 결론 : 마지막 아이템만 사용하는 기본 접근 방식이 효율성을 고려할 때 실용적이다.
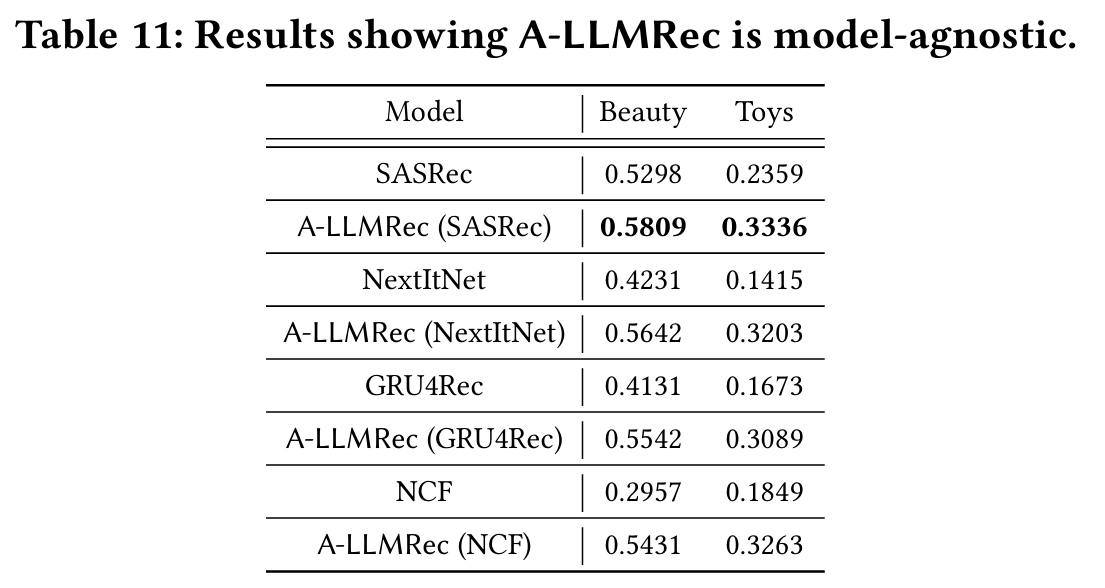
5.4.3 A-LLMRec is Model-Agnostic
- 모델 유연성 : A-LLMRec은 SASRec을 기본 CF-RecSys로 사용하되, 다른 CF-RecSys로 대체가 가능하다. NextItNet, GRU4Rec, NCF와 같은 다양한 협업 필터링 모델을 A-LLMRec에 통합하여 테스트를 진행한다.
- 결과 :
- SASRec을 백본으로 사용할 때 가장 높은 성능을 보여준다.
- A-LLMRec을 기존의 어떤 CF-RecSys에 적용하더라도 성능이 향상된다.
- A-LLMRec은 텍스트 정보와 협업 지식을 결합하여 다양한 CF-RecSys의 성능 격차를 줄인다.
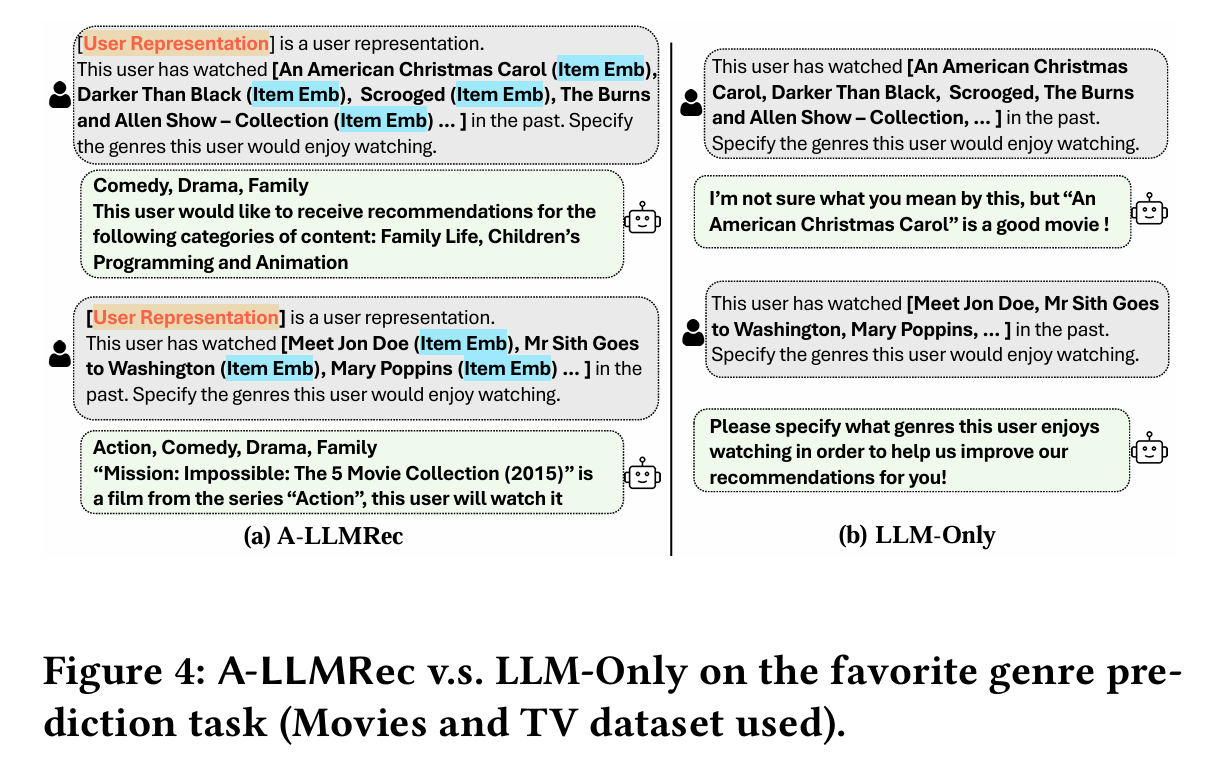
5.4.4 Beyond Recommendation: Language Generation Task
- 실험 설정 : 사용자의 과거 시청 데이터와 아이템 정보를 기반으로 사용자가 선호하는 영화 장르를 예측하는 언어 생성 태스크를 수행한다.
- 결과 :
- A-LLMRec은 LLM-Only 모델보다 정확한 답변을 생성한다.
- CF-RecSys의 아이템 임베딩을 LLM의 토큰 공간과 잘 정렬하여 협업 지식을 활용할 수 있도록 지원한다.
- TALLRec은 LLM을 fine-tuning하는 과정에서 자연어 생성 태스크의 성능이 감소하는 문제를 겪는다.
6. Conclusion
A-LLMRec의 제안 :
- 새로운 LLM 기반 추천 시스템, A-LLMRec를 제안한다.
- A-LLMRec은 사전 학습된 CF-RecSys의 협업 지식을 LLM이 활용할 수 있도록 설계되었다.
주요 성과 :
- 기존 CF-RecSys, 모달리티 기반 추천 시스템, 그리고 LLM 기반 추천 시스템들보다 우수한 성능을 발휘한다.
- 다양한 시나리오(Cold/Warm Items, Cold User, Few-shot, Cross-domain)에서 효과적이다.
특장점 :
- 모델 독립성(Model-agnostic) : 기존 CF-RecSys 및 LLM의 fine-tuning이 필요 없다.
- 효율성(Efficiency) : fine-tuning 없이 간단한 구조로 높은 성능을 발휘한다.
잠재성 :
- CF-RecSys에서 얻은 협업 지식을 바탕으로 자연어 생성 작업의 가능성을 확인한다.
향후 작업 :
- Chain-of-thought prompt engineering을 활용하여 LLM의 능력을 추가적으로 강화할 계획이다.
