[논문] Large Language Models for Next Point-of-Interest Recommendation
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
Large Language Models for Next Point-of-Interest Recommendation [arxiv]
Peibo Li SIGIR 24
📝 Key Point
-
LLM을 활용하여 다음 관심 지점(Next Point-of-Interest, POI)을 예측하는 새로운 추천 시스템 LLM4POI를 제안한다.
-
LLM을 통해 위치 기반 소셜 네트워크 데이터의 풍부한 맥락 정보를 활용한다.
-
LLM을 사용하여 데이터를 질문-응답 형식으로 변환하고, "Trajectory Prompting"과 "Key-Query Pair Similarity"를 도입하여 사용자 행동 패턴을 분석한다.
-
LLM4POI가 기존 시스템보다 추천 정확도가 높고, 콜드 스타트와 짧은 경로 문제를 완화한다.
Abstract
문제 정의 :
- Next Point-of-Interest (POI) Recommendation Task : 사용자의 이전 방문 데이터를 바탕으로 다음 방문할 POI를 예측한다.
- 도전 과제 : LBSN(Location-Based Social Network) 데이터의 풍부한 맥락 정보를 효과적으로 활용하는 방법이 부족하다.
- 기존 방법은 데이터의 수치화에 의존하여 맥락 정보의 의미를 충분히 반영하지 못한다.
해결 방법 :
- LLM을 활용한 프레임워크를 제안한다.
- 이질적인 LBSN 데이터를 원본 형식 그대로 유지하면서 맥락 정보를 보존한다.
- 상식적 지식을 통합하여 데이터의 의미를 이해하고 활용한다.
실험 결과 :
- 세 개의 실제 LBSN 데이터셋(Foursquare-NYC, Foursquare-TKY, Gowalla-CA)에서 실험했다.
- 제안된 프레임워크가 모든 데이터셋에서 기존 SOTA 모델들보다 우수한 성능을 보인다.
결론 :
- 제안된 프레임워크는 맥락 정보를 효과적으로 활용하여 성능을 크게 개선한다.
- 일반적인 문제인 cold-start와 짧은 궤적 문제(short trajectory problem)를 완화한다.
Figure
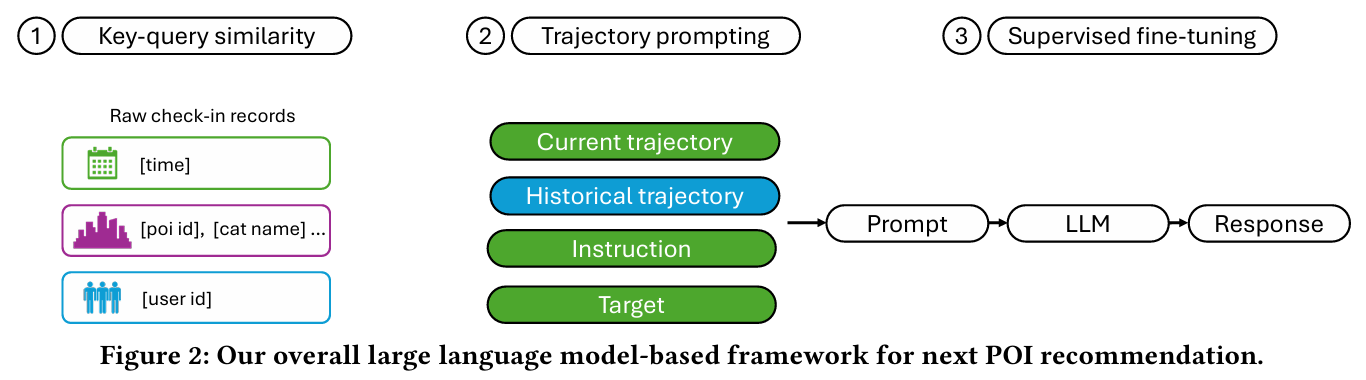
- 키-쿼리 유사성 (Key-Query Similarity) :
- 사용자 행동 패턴을 분석하기 위해 궤적 간의 유사성을 계산한다.
- 높은 유사성을 가진 궤적을 선택하여 역사적 궤적 블록으로 사용하는 방식으로 설계한다.
- 궤적 프롬프팅 (Trajectory Prompting) :
- 사용자의 체크인 데이터를 자연어 질문-응답 형식으로 변환하여 LLM에 입력 가능하도록 재구성한다.
- 현재 궤적, 역사적 궤적, 지침, 목표를 나타내는 여러 블록으로 구성된 프롬프트를 형성한다.
- 지도학습 기반 파인튜닝 (Supervised Fine-Tuning) :
- 대규모 언어 모델을 fine-tuning하여 POI를 예측한다.
- 프롬프트를 통해 입력 데이터를 처리하고 적절한 POI 추천을 생성한다.
1. Introduction
문제 정의
-
Location-Based Social Networks (LBSNs) :
- 모바일 및 위치 기술의 발전으로 인해 LBSN은 풍부한 위치 기반 정보를 제공하며 성장했다.
- Next Point-of-Interest (POI) Recommendation Task : 사용자의 역사적 궤적 데이터를 기반으로 다음 POI 방문을 예측한다.
-
기존 모델의 한계 :
- 짧은 궤적 문제(short trajectory problem)와 cold-start 문제를 일부 해결했지만, 풍부한 맥락 정보를 충분히 활용하지 못한다.
- 데이터의 통계적 접근에만 의존하여 사용자 행동 모델링의 잠재력을 제한한다.
도전 과제
-
맥락 정보 추출
- 문제 : LBSN 데이터는 시간, POI 카테고리, 지리 좌표 등 풍부한 정보를 포함하고 있지만, 기존 방법들은 이 정보를 원시 데이터에서 효과적으로 추출하는 데 한계를 보인다.
- 중요성 : 이 정보는 통계적 분석을 넘어, 데이터에 존재하지 않는 행동 패턴까지 도출 가능하며 사용자 행동을 더 정밀하게 모델링할 수 있다.
-
상식 지식과의 연결
- 문제 : 맥락 정보와 실세계 행동 간의 상호 연결을 어떻게 효과적으로 구현할 것인가?
- 상식적 지식 : 추가 데이터 없이 맥락 정보를 이해하고, 데이터에서 존재하지 않는 행동 패턴을 유추할 수 있게 한다.
기존 방법의 한계
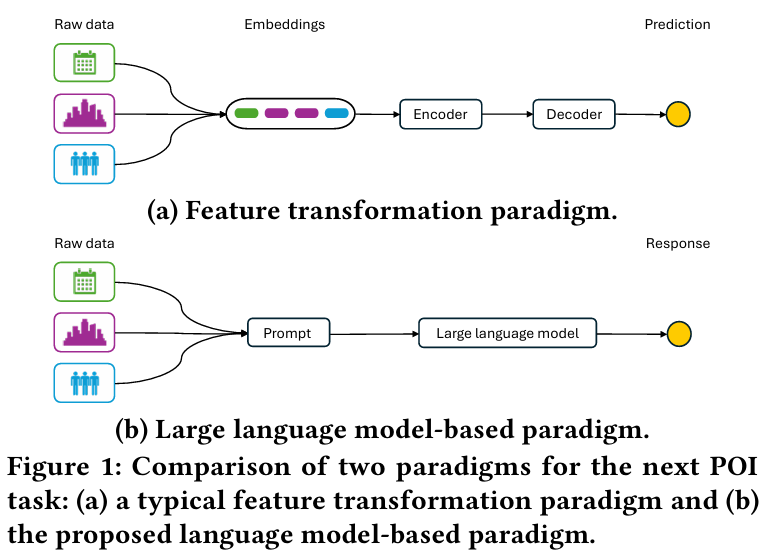
- 수치 기반 변환의 제약 :이질적 LBSN 데이터를 숫자로 변환할 필요성 때문에 데이터의 고유한 의미가 손실된다.
- 통계적 접근 및 설계 의존 :통계와 인간 설계만으로 맥락 정보를 이해하며, 의미론적 개념을 제대로 활용하지 못한다.
제안된 해결 방법
- LLM4POI 프레임워크 :
- LLM을 활용하여 다음 POI 추천 문제를 해결한다.
- 원시 데이터를 텍스트 형식 그대로 유지하며 맥락 정보를 보존한다.
- 상식적 지식을 통합하여 데이터의 의미를 파악하고 사용자 행동 패턴을 모델링한다.
- 맥락 정보 보존
- 상식적 지식 통합
주요 기여
- 풍부한 맥락 정보와 상식적 지식을 결합하여 데이터의 고유 의미를 유지하며 모델링한다.
- 짧은 궤적 문제(short trajectory problem)와 cold-start 문제를 완화한다.
- 실험을 통해 기존 SOTA 모델을 초월하는 성능을 입증되었다.
2. Related Work
2.1 Next POI Recommendation
Sequence-based Models
- 초기에 POI 추천은 순차적 추천 문제로 간주되어 기존 순차적 추천 기법이 적용되었다.
- Cheng et al. [4] : 국소 지역 제약을 적용한 FMPC 도입.
- He et al. [14] : 소프트맥스 함수와 결합된 개인화 마르코프 체인을 도입.
- HST-LSTM (Kong & Wu [17]) : 시공간 요소를 LSTM 게이트에 추가.
- LSTPM [22] : 세 가지 LSTM 모듈과 지오-확장 LSTM을 통해 짧은 선호 모델링 수행.
- STAN [19] : 다층 attention 아키텍처로 사용자, 위치, 시간 및 공간적 효과 학습.
- CFPRec [33] : 과거 및 현재 선호도를 인코더를 통해 다중 참조 추출.
Graph-based Models
- 시퀀스 기반 모델의 한계를 해결하기 위해 그래프 기반 방법론이 등장했다.
- STP-UDGAT [18] : GAT를 활용해 전역적 관점에서 데이터 학습.
- DRGN [26] : 거리 및 전이 기반 관계 그래프를 통해 POI의 특성 분석.
- STHGCN [30] : 하이퍼그래프를 구축하여 사용자 궤적 및 관계를 포착.
- 기존 모델의 한계 :
- 맥락 정보와 상식 지식을 결합하는 데 제한적이다.
2.2 LLMs for Time-series Data
- LLM은 시계열 데이터에 효과적인 것으로 입증되었다.
- SHIFT [28] : 인간 이동성을 언어 번역 문제로 간주하며 LLM 활용.
- AuxMobLCast [28] : 시계열 데이터를 위한 프롬프트 설계 연구.
- LLM4TS [2] : 두 단계 fine-tuning 접근법(기본 정렬 후 다운스트림 특화 학습)을 채택.
- 제안 방법 : 위 연구에 영감을 받아 LBSN 데이터의 특성을 반영한 trajectory prompting 설계를 통해 POI 추천을 질문-응답 문제로 변환한다.
2.3 LLMs for Recommender Systems
- 다양한 추천 시스템에서 LLM이 도입되고 있다.
- Zhang & Wang [34] : 뉴스 데이터를 위한 프롬프트 템플릿 설계 및 앙상블 학습.
- Harte et al. [13] : 항목 임베딩 기반 추천, 프롬프트 완료 및 기존 모델 향상 기법 제안.
- Wang et al. [25] : POI 추천에 LLM의 컨텍스트 학습 적용.
- 제안 방법 : LLM의 fine-tuning과 궤적 유사성을 결합해 POI 추천 성능을 극대화한다.
3. Problem Definition
문제 정의
이 논문은 다음 POI(관심 지점) 추천 작업을 위해 LLM을 fine-tuning하는 문제를 해결하는 데 초점을 맞추고 있다.
데이터셋 구조
데이터셋 는 사용자 체크인 기록으로 구성된다. 각 기록은 다음 정보를 포함하는 튜플 형태로 표현된다
- : 사용자
- : POI(Point-of-Interest)
- : POI의 카테고리
- : 체크인 타임스탬프
- : POI의 지리적 좌표
궤적 형성
특정 시간 간격 기준으로 사용자의 체크인 기록을 분할하여 궤적을 형성한다. 사용자의 궤적 는 다음과 같은 체크인 기록의 집합으로 구성된다.
목표
새로운 궤적 에서 사용자의 다음 체크인 POI 을 예측해야 한다. 사용자가 시점에 즉시 방문할 POI를 예측한다는 목표로 정의된다.
4. Methodology
전체 프레임워크
- Key-Query Similarity : 키와 쿼리 간 유사성을 계산해 관련 궤적 데이터를 선택한다.
- Trajectory Prompting : 사용자의 체크인 데이터를 LLM이 이해할 수 있는 질문-응답 형식으로 변환한다.
- Supervised Fine-Tuning : 프롬프트를 활용하여 LLM을 지도 학습 기반으로 파인튜닝한다.
4.1 Trajectory Prompting
아이디어 :
- LBSN 데이터를 자연어 문장으로 변환하여 이질적인 데이터를 의미 있는 문장으로 통합한다.
- 프롬프트는 다음과 같은 블록들로 구성된다.
- Current Trajectory Block : 현재 사용자 궤적 데이터(마지막 항목 제외).
- Historical Trajectory Block : 현재 사용자와 유사한 행동 패턴을 보이는 사용자의 데이터.
- Instruction Block : 모델에게 초점을 맞추어야 할 지점과 POI ID 범위를 안내한다.
- Target Block : 예측해야 할 체크인 레코드(지도 학습 평가용).
프롬프트와 Check-in 기록
- Check-in 기록은 다음과 같은 형식으로 변환한다.
- "At [time], user [user id] visited POI id [poi id] which is a/an [poi category name] with category id [category id]."
- 지리적 좌표(geo-coordinates)는 제외하여 토큰 수를 줄이고 효율성을 높인다.

특징 및 이점
- 현재 궤적 블록은 짧은 궤적 문제(short trajectory problem)를 해결하고, 역사적 궤적 블록은 다른 사용자 데이터를 활용하여 cold-start 문제를 해결한다.
- 명령 블록을 통해 모델이 특정 범위 내에서 예측하도록 유도한다.
- 입력 중 목표 블록은 예측 단계에서 제외하여 평가에 사용된다.
주요 설계 특징
- 데이터의 원래 형식을 유지하면서 문장으로 통합해 LLM에 입력한다.
- 블록 구조는 수정 및 확장이 용이하도록 설계된다.
4.2 Key-Query Pair Similarity
목적
- 사용자 행동 패턴을 포착하고, 사용자별로 혹은 다른 사용자의 궤적 데이터를 활용해 맥락적 정보를 반영한다.
- Key-Query Similarity Computation Framework를 사용하여 궤적 데이터를 자연어 형식에서 효과적으로 처리한다.
주요 개념
-
Key와 Query의 정의
- Key : 현재 궤적 블록에 포함된 궤적으로, 마지막 항목을 제외한 데이터를 활용한다.
- Query : Key 궤적의 시작 시간보다 더 이른 궤적으로, 전체 궤적 데이터를 포한다.
-
Key와 Query 간 유사성 계산
- 각 Key와 Query 쌍의 유사성을 계산하여 관련성이 높은 Query를 선택한다.
- 높은 유사성을 가진 Query를 선택하여 역사적 궤적 블록에 사용한다.
처리 과정
- Key와 Query Prompt 생성
- Key Prompt : 현재 궤적 데이터(마지막 항목 제외)를 사용해 생성한다.
- Query Prompt : 과거의 전체 궤적 데이터를 기반으로 생성한다.
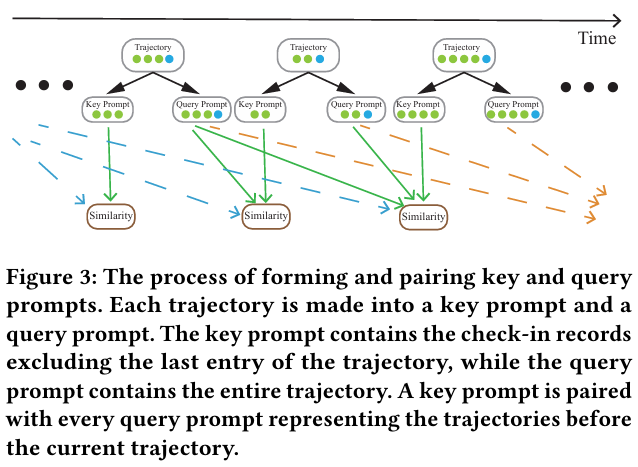
- LLM 기반 임베딩 생성
- Key Prompt와 Query Prompt를 각각 LLM(e.g. LLAMA2 Encoder)에 입력하여 마지막 hidden layer의 임베딩을 생성한다.
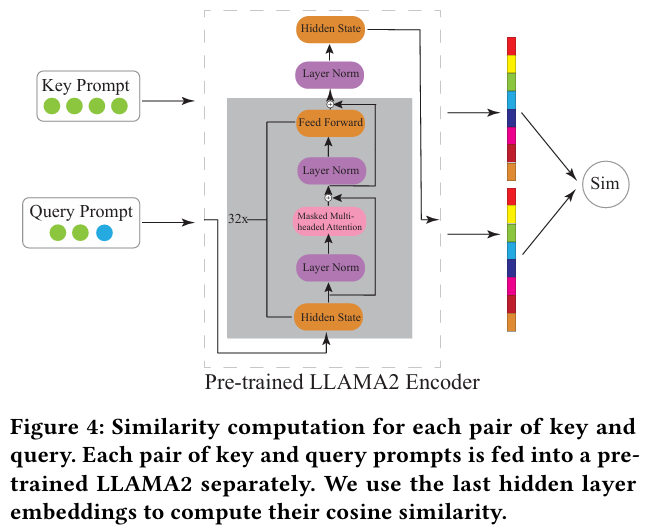
-
코사인 유사도 계산
- Key와 Query 간의 코사인 유사도 를 계산한다.
- Key와 Query 간의 코사인 유사도 를 계산한다.
-
상위 Query 선택
- 유사도 기준으로 상위 개의 Query를 선택한다.
핵심 장점
- 높은 유사성을 가진 Query를 활용해 현재 궤적과 연관된 정보를 역사적 궤적 블록에 통합한다.
- 짧은 궤적 문제와 cold-start 문제를 효과적으로 완화한다.
4.3 Supervised Fine-tuning
Supervised Fine-tuning은 LLM을 효율적으로 파인튜닝하기 위한 과정으로, Parameter-Efficient Fine-Tuning (PEFT) 기술을 사용해 비용을 절감하면서 높은 성능을 유지하는 것을 목표로 한다.
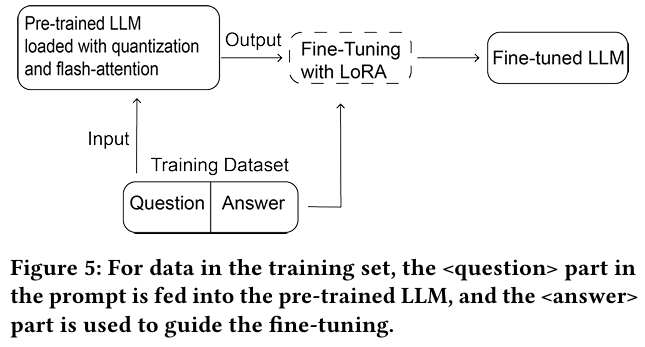
Low-Rank Adaptation (LoRA)
- 목적 : LLM의 dense layers을 고정하고, rank가 낮은 행렬을 활용해 가중치를 업데이트하여 효율적인 학습을 진행한다.
- 작동 방식 :
- 사전 학습된 가중치 행렬 에 대해, 를 저차 분해 로 대체한다.
- , 이며, . 즉, 매우 작은 차원 을 사용한다.
- 학습 중에는 과 만 gradient 업데이트를 받으며 나머지 가중치는 고정된다.
- 예시 : Attention 레이어(4096 elements)에서는, rank를 16으로 설정하면 학습 가능한 매개변수가 0.78%로 감소한다.
- 장점 : MLP 레이어는 고정되고, Attention 레이어만 파인튜닝하므로 계산 비용을 크게 절감한다.
Quantization
- 목적 : GPU 메모리 사용량을 줄이고 계산 효율성을 증가시킨다.
- 기술 :
- 고비트 데이터를 저비트 데이터로 변환한다.
- 4-bit NormalFloat(NF4)을 사용한다.
- 평균 0, 범위 [-1, 1] 내의 정규 분포에 최적화한다.
- 텐서를 rescale하고 양자화 상수를 적용한다.
- 이중 양자화(double quantization)를 적용한다.
- 저장 시 NF4, forward 및 backward pass에서는 16-bit BrainFloating(BF)을 사용한다.
- gradient는 LoRA 파라미터에 대해서만 계산된다.
Flash Attention
- 문제 : 긴 문맥 길이가 필요한 경우, 기존 Transformer의 4096 토큰 길이는 부족하다.
- 해결책 : FlashAttention-2 기술을 도입한다.
- Transformer가 긴 문맥 길이를 처리하도록 지원한다.
- 긴 궤적 및 역사적 궤적 블록 처리를 위한 적합한 솔루션을 제공한다.
5. Experiment
5.1 Experimental Setup
5.1.1 Datasets
- 데이터셋 : Foursquare-NYC, Foursquare-TKY, Gowala-CA.
- Foursquare-NYC와 Foursquare-TKY : 뉴욕과 도쿄 지역 데이터를 포함하며, 11개월 동안 수집된 기록이다.
- Gowala-CA : 캘리포니아 및 네바다 지역 데이터를 포함, 더 넓은 지역과 기간을 다룬다.
- 전처리 과정 :
- 방문 기록이 10개 미만인 POI 제거.
- 방문 기록이 10개 미만인 사용자 제외.
- 24시간 간격으로 체크인 기록을 궤적으로 나누고, 1개만 포함된 궤적은 제거.
- 80%는 학습 데이터, 10%는 검증 데이터, 나머지 10%는 테스트 데이터로 분류.
- 학습 데이터에 등장하지 않는 사용자와 POI는 검증 및 테스트 세트에서 제거.
5.1.2 Baselines
- FPMC : 마르코프 체인과 행렬 분해를 결합하여 위치 전이를 예측.
- LSTM : 순차적 데이터의 단기 및 장기 의존성을 포착.
- PRME : 사용자-POI 선호도를 학습하는 개인화 순위 모델.
- STGCN : 시공간 간격을 효과적으로 모델링.
- PLSPL : 짧은 선호도는 Attention 메커니즘으로, 긴 선호도는 병렬 LSTM 구조로 학습.
- STAN : 사용자 궤적 내 공간-시간 상관 관계를 학습.
- GETNext : Transformer와 GCN을 결합하여 전역 궤적 흐름 지도 및 효과적인 POI 임베딩 생성.
- STHGCN : 하이퍼그래프를 구성하여 사용자 관계를 포착하고, 차가운 시작 문제를 해결.
5.1.3 Our Models
- 모델 변형 :
- LLM4POI* : 현재 궤적 블록만 포함, 역사적 궤적 제외. Llama-2-7b-longlora-32k 사용.
- LLM4POI** : 역사적 궤적 블록을 포함하되 Key-Query 유사성 미적용. LLAMA2-7b 사용.
- LLM4POI : 현재 사용자와 다른 사용자 궤적을 포함한 Key-Query 유사성 적용. LLAMA2-7b 사용.
5.1.4 Evaluation Metrics
- Accuracy@1 평가 :
- 상위 1개 추천 항목이 테스트 데이터에서 올바른 예측 항목인지 확인한다.
- 더 높은 값은 더 나은 성능을 의미한다.
- 상위 1개 추천 항목이 테스트 데이터에서 올바른 예측 항목인지 확인한다.
5.1.5 Implementation Details
- 설정 :
- 학습률 :
- GPU 당 batch 크기 : 1
- 토큰 길이 : 32,768
- Epoch : 3
- Nvidia A100 GPU 사용
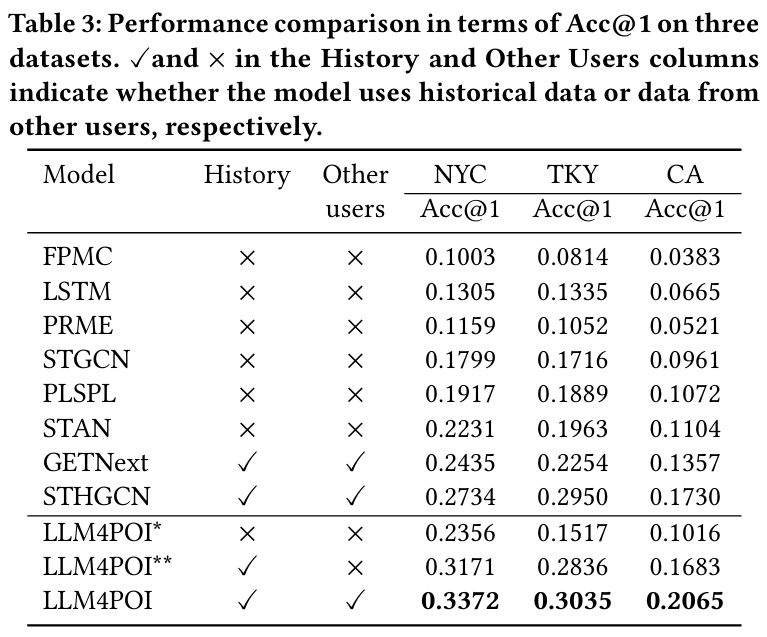
5.2 Main Results
Accuracy@1 성능 비교
- LLM4POI는 세 데이터셋 모두에서 가장 높은 Accuracy@1 점수를 기록했다.
- NYC: 0.3372 (23.3% 향상, STHGCN 대비)
- TKY: 0.3035 (2.8% 향상, STHGCN 대비)
- CA: 0.2065 (19.3% 향상, STHGCN 대비)
모델별 성능 패턴
- LLM4POI : 역사적 데이터와 다른 사용자 데이터를 모두 사용하며 최고의 성능을 보인다.
- LLM4POI* : 역사적 데이터를 사용하지 않으며 성능이 상대적으로 낮다.
- LLM4POI** : 다른 사용자 데이터를 제외하고도 높은 성능을 유지한다.
역사적 데이터와 다른 사용자 데이터의 중요성
- 역사적 데이터를 사용하는 모델(e.g. GETNext, STHGCN)이 데이터를 사용하지 않는 모델보다 더 나은 성능을 보인다.
- 다른 사용자 데이터를 추가로 사용하는 경우(e.g. GETNext, LLM4POI), 성능이 더욱 향상된다.
지역별 데이터 특성
- NYC 데이터셋 : 사용자와 POI 개수가 적고 POI 카테고리가 많아 학습이 쉬운 데이터 특성을 보여 더 높은 성능을 보인다.
- CA 데이터셋 : 넓은 지역과 상대적으로 적은 데이터로 인해 모델 성능이 낮다.
5.3 Analysis
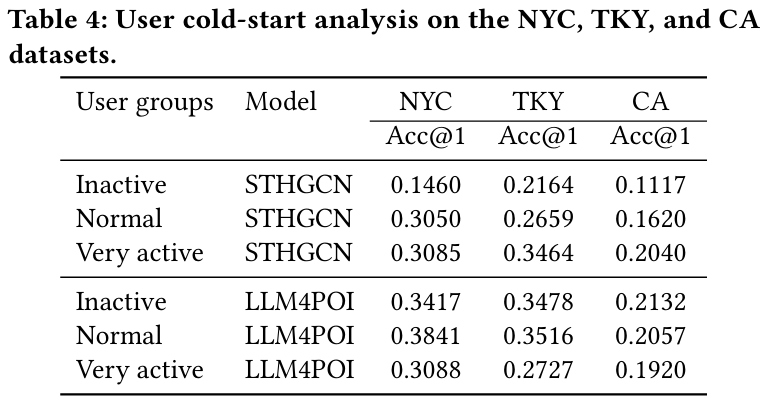
5.3.1 User Cold-start Analysis
- 문제 : cold-start 문제를 해결하기 위해 역사적 궤적 블록과 Key-Query 궤적 유사성을 활용한다.
- 사용자 그룹 정의 :
- Inactive (비활성) : 궤적 개수가 하위 30%에 속하는 사용자.
- Normal (보통) : 궤적 개수가 중간에 해당하는 사용자.
- Very Active (매우 활성) : 상위 30%의 궤적 개수를 가진 사용자.
- 결과 :
- LLM4POI는 STHGCN 대비 비활성 사용자에 대해 NYC 데이터셋에서 두 배 이상의 성능 향상을 보인다.
- 도쿄와 캘리포니아에서도 약 50% 이상의 성능 향상을 보인다.
- 주요 발견 :
- 우리의 모델은 비활성 사용자에서 더 높은 성능을 기록한다.
- 반면 STHGCN은 매우 활성 사용자에서 더 나은 성능을 보인다.
- 도쿄와 캘리포니아의 사용자가 많아 협업 정보 활용에 제약이 발생한다.
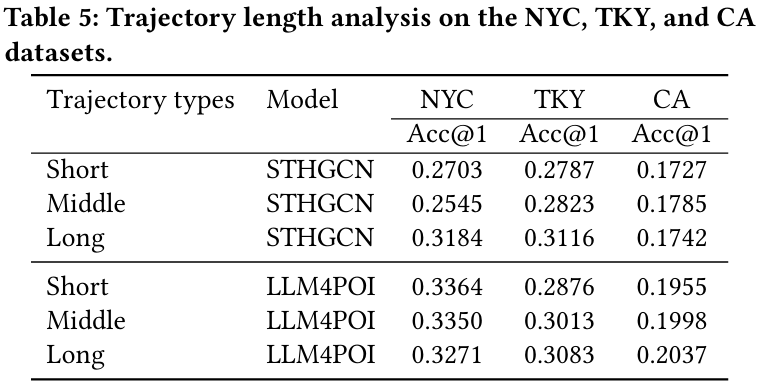
5.3.2 Trajectory Length Analysis
- 문제 : 궤적 길이의 다양성이 POI 추천에 중요한 영향을 미친다.
- 짧은 궤적 : 공간-시간 정보가 제한되어 도전 과제가 된다.
- 긴 궤적 : 정보는 풍부하지만 패턴 추출의 어려움 존재한다.
- 궤적 길이 정의 :
- 상위 30% : 긴 궤적
- 하위 30% : 짧은 궤적
- 나머지 : 중간 궤적
- 결과 :
- NYC 데이터셋에서 짧은 궤적에 대해 Accuracy@1 24.4% 개선했다.
- 중간 궤적에서는 31.6% 개선했다.
- TKY 및 CA에서는 긴 궤적에서 더 나은 성능을 보인다.
- 결론 : 모델은 궤적 길이에 따라 균형 잡힌 성능을 유지하며 역사적 데이터를 효과적으로 통합한다.
5.3.3 Number of Historical Data Variants
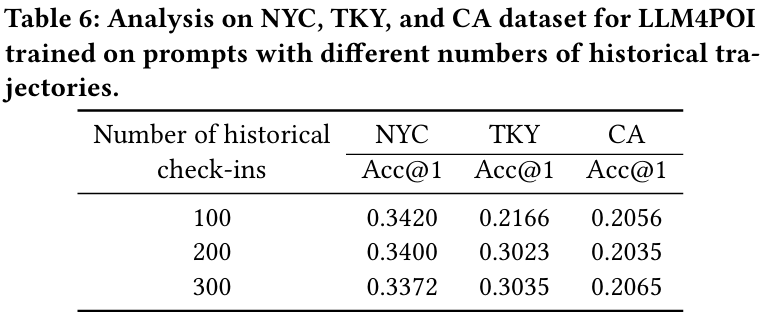
- 문제 : 프롬프트의 토큰 제한으로 인해 선택된 최고 유사 궤적만 사용할 수 있다.
- 결과 :
- NYC : 100개의 역사적 체크인 기록에서 최고 성능.
- TKY : 300개의 역사적 체크인 기록에서 최고 성능.
- CA : 다양한 기록 개수에도 성능 차이가 거의 없음.
- 결론 :
- 더 많은 데이터를 사용할수록 성능이 반드시 개선되지 않는다.
- 적은 데이터를 사용해 토큰 크기를 줄이면서도 경쟁력 있는 성능 유지가 가능하다.
5.3.4 Generalization to Unseen Data Analysis
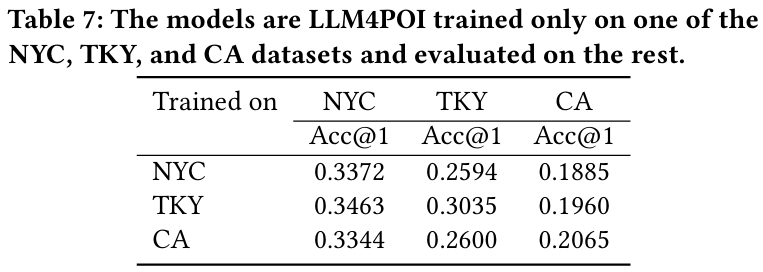
- 문제 : LLM4POI 모델은 순수한 언어 모델링 기반으로 POI ID를 예측하며, 데이터셋 간 전이 학습 없이도 성능을 평가할 수 있다.
- 결과 :
- NYC, TKY, CA 데이터셋 중 한 데이터셋에서 fine-tune한 모델을 나머지 데이터셋에서 테스트한 결과, 경쟁력 있는 성능을 보였다.
- 예를 들어, NYC에서 학습된 모델은 TKY에서 STHGCN보다 낮은 성능을 보였지만 CA에서는 기존 SOTA 모델보다 뛰어난 성능을 보인다.
- 결론 : 모델의 일반화 능력은 'Historical Trajectory Block'과 'Key-Query Similarity'가 효율적으로 사용자 이동 기록을 포착했기 때문이다.
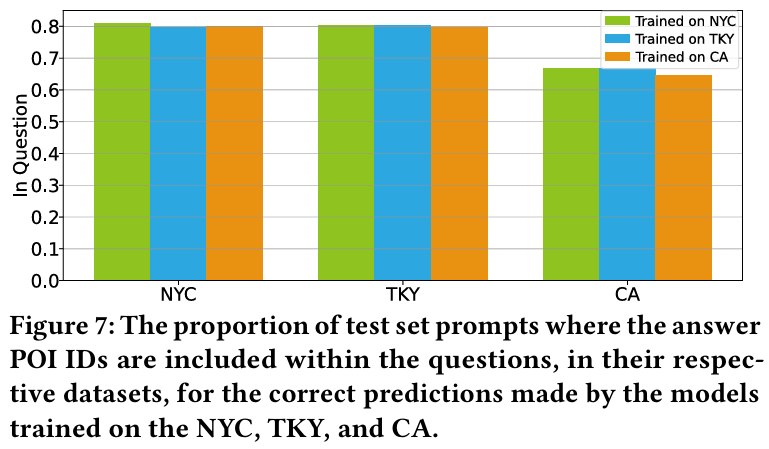
5.3.5 Contextual Information Analysis
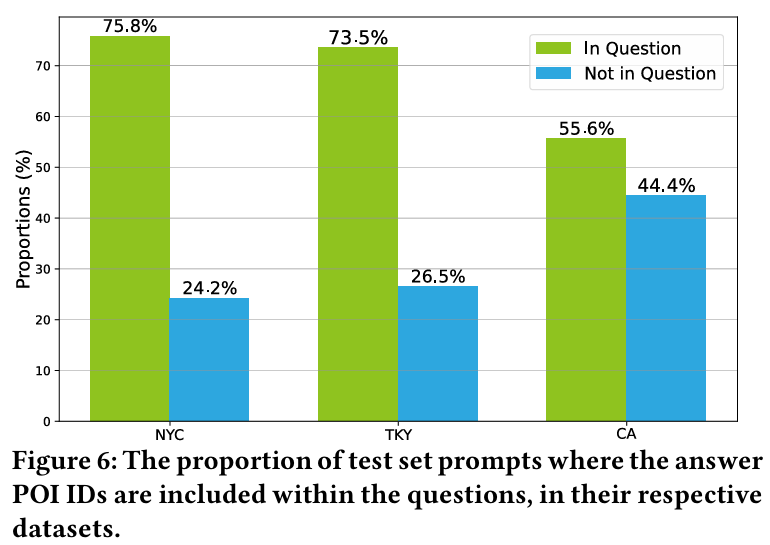
- 문제 : 문맥 정보를 활용하는 것은 LLM4POI 모델의 차별화된 특성 중 하나이다.
- 결과 :
- NYC, TKY, CA 데이터셋에서 문맥 정보를 포함한 프롬프트와 그렇지 않은 프롬프트로 모델을 테스트한 결과 : NYC에서 문맥 정보를 제거해도 성능은 약간 감소(1.8%)했지만 TKY와 CA에서는 각각 6.4%, 6.2% 감소한다.
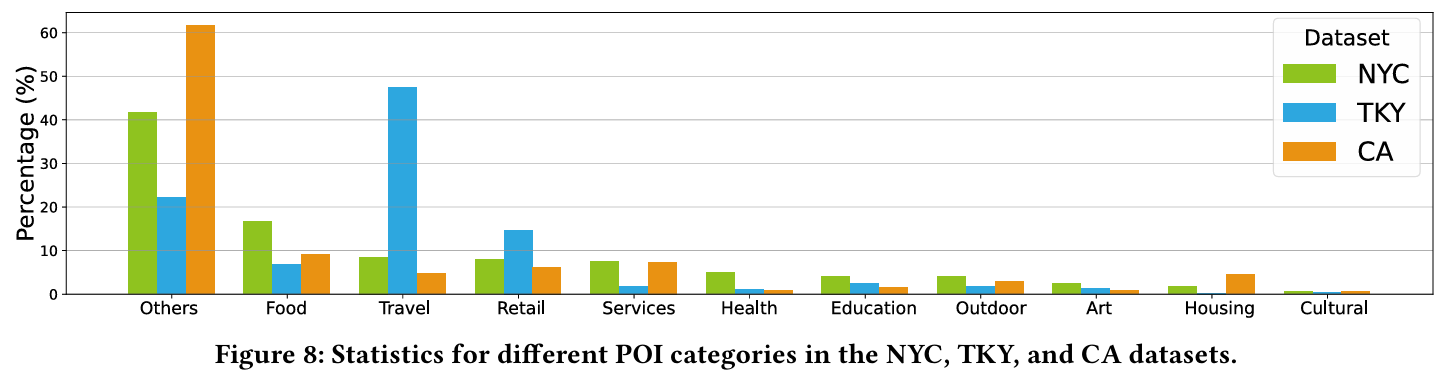
- 활동 수준에 따른 분석 결과 : NYC와 CA에서는 활동이 적은 사용자의 성능이 향상되었고, 반대로 TKY에서는 활동적인 사용자의 성능이 향상된다.
- 결론 : 이러한 차이는 국가 간 POI 카테고리 분포의 차이와 연관이 있다.
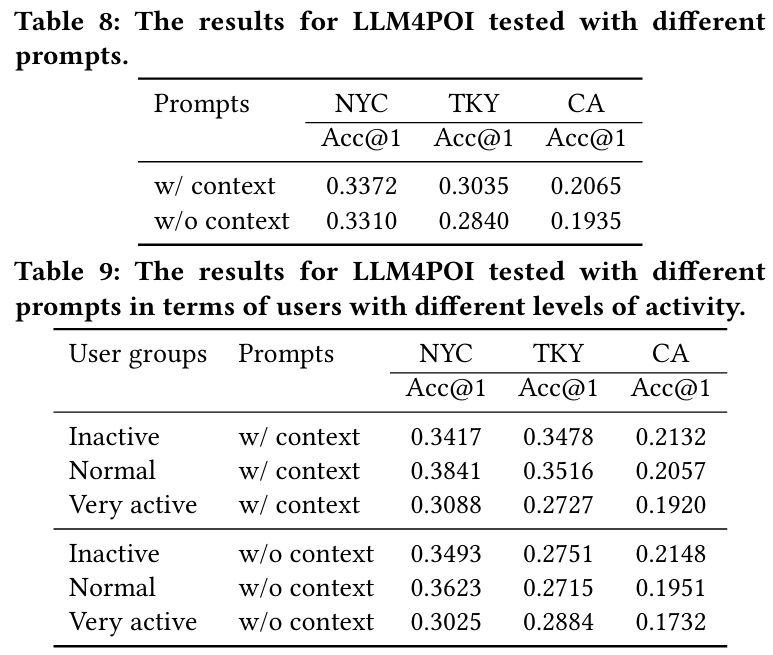
5.3.6 Effect of Different Components
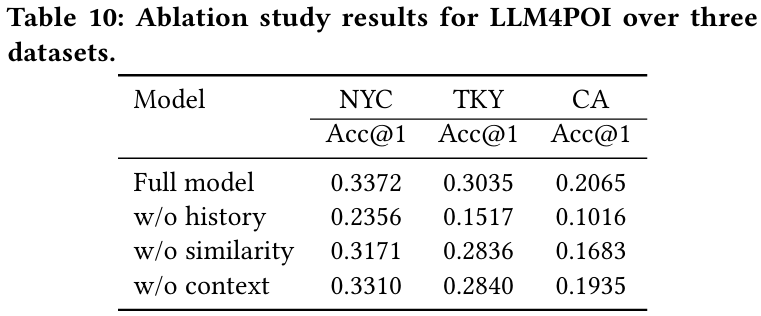
- 결과 : 모델 성능은 다음 3가지 주요 구성 요소의 결합 효과로 이루어진다.
- Historical Trajectory Block : 이 구성 요소를 제거하면 TKY와 CA 데이터셋에서 정확도가 50%까지 급격히 감소한다.
- Key-Query Similarity : 이 요소 제거 시 NYC에서 정확도 6% 감소한다.
- Contextual Information : 문맥 정보 제거는 모든 데이터셋에서 성능 저하를 초래한다.
- 결론 : 각 구성 요소는 LLM4POI 모델 성능에 중요한 기여를 하며, 특히 'Historical Trajectory Block'이 가장 중요한 역할을 한다.
6. Conclusion and Future Work
주요 연구 제안
- LLM4POI라는 프레임워크를 개발하여 대규모 언어 모델을 활용한 다음 관심 지점(Point-of-Interest, POI) 추천 과제를 수행했다.
- 처음으로 상식 기반의 대규모 언어 모델을 이 과제에 도입했다.
- Trajectory Prompting을 통해 과제를 질문 답변 형태로 변환했다.
- Key-Query Similarity를 소개하여 콜드 스타트 문제를 완화했다.
연구 결과 및 분석
- 실험 결과 : 세 가지 실제 데이터셋에서 기존 모델을 큰 차이로 능가했다.
- 분석 결과 :
- 콜드 스타트 문제와 다양한 길이의 사용자 이동 경로를 효과적으로 처리했다.
- 모델에서 맥락 정보의 중요성과 효과를 입증했다.
- 잠재성 : 대규모 언어 모델의 일반화 능력을 활용하여 새로운 데이터에서도 탁월한 성과를 보인다.
제약 및 향후 연구 방향
- 대규모 언어 모델의 특성상 학습 및 추론 시간 효율성 문제가 존재한다.
- 프롬프트 디자인이 모델의 컨텍스트 길이 및 사전 학습 코퍼스에 제한을 받는다.
향후 계획
- 현재의 제한점을 해결하는 연구를 진행한다.
- Chain-of-thought reasoning을 통해 성능 향상 및 예측에 대한 설명을 제공한다.
- 단일 아이템 추천에 국한되지 않은 추천 시나리오로 모델로 확장한다.
