[Paper Review] Exploring Visual Prompts for Whole Slide Image Classification with Multiple Instance Learning
Paper Review
Exploring Visual Prompts for Whole Slide Image Classification with Multiple Instance Learning
훈련소에 다녀왔다. 3주 다녀왔는데 잘 안 읽히고 바보가 된 기분이다. 그래도 해야지. 이번 논문은 WSI analysis 에서 자주 쓰이는 Multiple Instance Learning 분야의 나온지 얼마 안된 따끈따끈한 논문이다. 병리 쪽에서는 natural image (ex ImageNet) 로 pretrain 된 모델을 backbone 으로 사용하는 경우가 많은데, 이러한 pretrained model 을 promopt learning 방식으로 비교적 적은 cost 로 fine-tuning 해서 MIL 성능을 높였다는 연구이다.
Introduction
- WSI 분석에 Multiple Instance Learning (MIL) 많이 씀
- frozen feature extractor pretrain 해서 사용하지만, overlook domain shift issue
- fine-tuning feature extractor 는 large-scale dataset 에서 학습된 모델을 손상할 수 있음.
- NLP에서 영감받은 prompt learning 을 병리에 적용하여 improve performance, achieve domain transformation
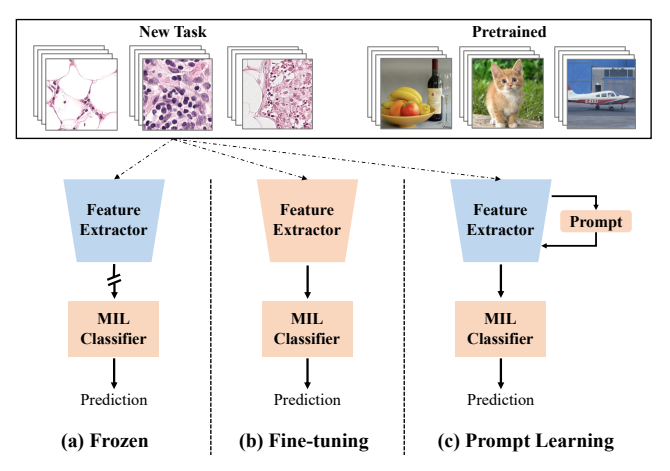
how?
1) introduce visual promopts into WSI classification
2) end-to-end promopt training, involves representative patch selection
3) extensive validation experiment with Camelyon16, TCGA-NSCLC
Method
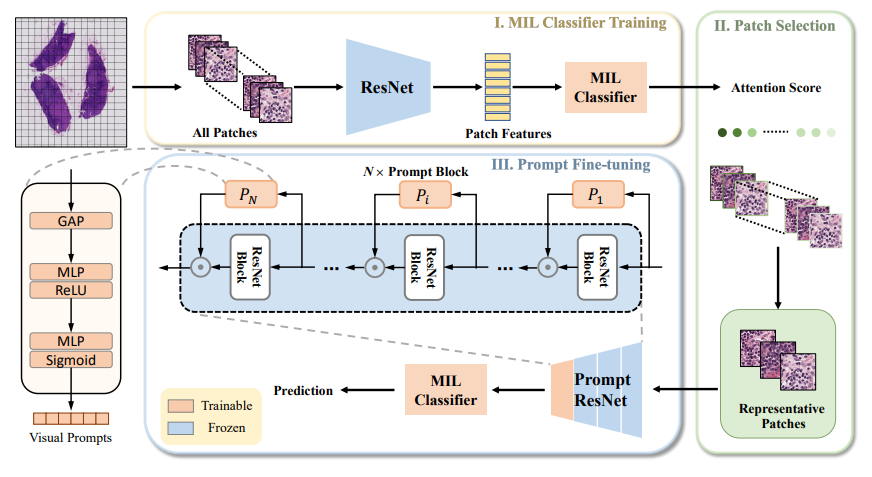
아래 그림처럼 세 step 으로 나누어 설명하고 있다.
1) MIL classifier training
2) representative patch selection
3) promopt fine-tuning
Attention-based MIL Classifier with Frozen Feature Extractor
attention-based MIL (ABMIL) 방식에서는 다음 세 식으로 요약할 수 있다.
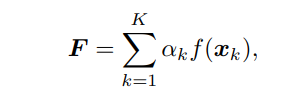
F는 attention-weighted average of all patch features in WSI,
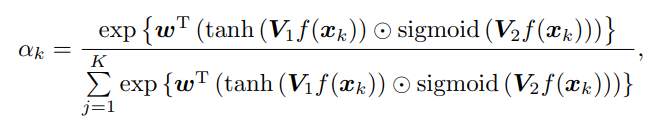
w, V1, V2 는 learnable parameters in MIL classifier. (gated attention 이군요)
이를 다시 MIL classifier h 에 넣어서 최종 prediction of WSI label 을 만들고 CE loss 를 구한다.
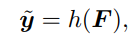
minimize the prediction error 하는 방식으로 MIL classifier 를 학습함.
Representative Patch Selection
- 배경: Camelyon16 관심있는 암 영역이 WSI 전체에서 10% 이하임.
- 내용: select top-K patches with highest attention score (K=200)
- 효과: reduce vast quantities of patches --> enable end-to-end training
Prompt Fine-tuning

이쪽 부분이 잘 이해가 안가서, reference 하는 논문을 (꽤나 자세히) 읽어보고 왔다. 논문의 제목은 Exploring Visual Promopts for Adapting Large-Scale Models.
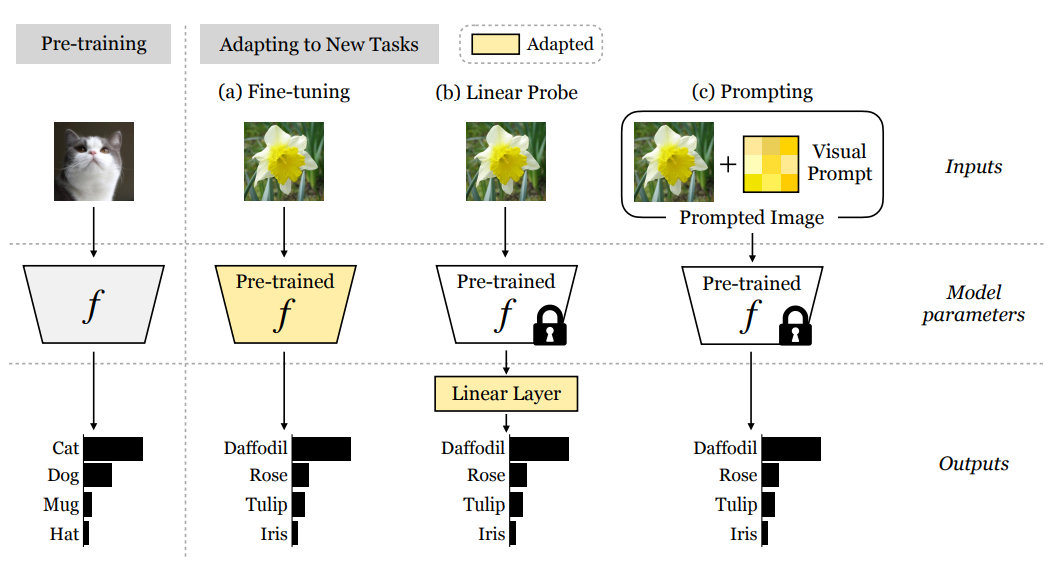
visual promopt 라는 random noise 같이 생긴 액자를 주목해서 보자. 핵심은 "image perturbation" 이다. 기존 backbone model 은 frozen 된 상태로, learnable parameter 로 만들어진 image perturbation 을 통해 task 자체를 reprogramming (like adversarial attack) 하고, frozen model 을 새로 programming 된 task 에 adapt 하도록 하는 것이다. 이 방식을 사용하면, 식으로 보면 조금 더 이해가 편하다.

task-specific visual promopt parameterized by 를 배우는 것이 목적이다. 이 논문에는 promopt design (액자식으로 하느냐-padding, random location, fixed location), output transformation (hard-coded mapping?) 과 같은 세부적인 내용도 담고 있으니 참고하도록 하자.

다시 보면 위 등장했던 그림이 더 이해가 될 것이다. 이번 논문에서는 저 로 parameterize 된 visual prompt 를 여기서 어떻게 표현했는지 보자.
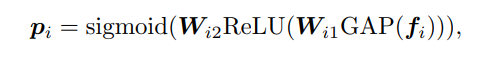
중간 단계의 feature map 를 ResNet block 에 통과시키 라는 D dimension 을 가진 prompt vetor 를 얻고, 이 prompt vector 를 next block에서 다시 과 channel-wise multiplication 을 거치게 된다.
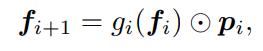
이렇게 표현함으로써, training process 에서 (feature extractor 는 frozen 된 채로) prompt block 에 해당하는 parameter 만으로, lightweight MIL classifier 가 end-to-end 방식으로 update 되는 것이다.
Experiments
Datasets
- Camelyon16: 256x256, 20x magnification, with average of 11556 patch per WSI, 399 WSI
- TCGA-NSCLC: 256x256, 20x magnification, with average 3089 patch per WSI, 1053 WSI
Implementation Details
promopt block 개수는 2-6개, top 200 patches 는 default
Comparison Results
sota MIL 인 DTFD, ABMIL 에 적용하여 실험함.
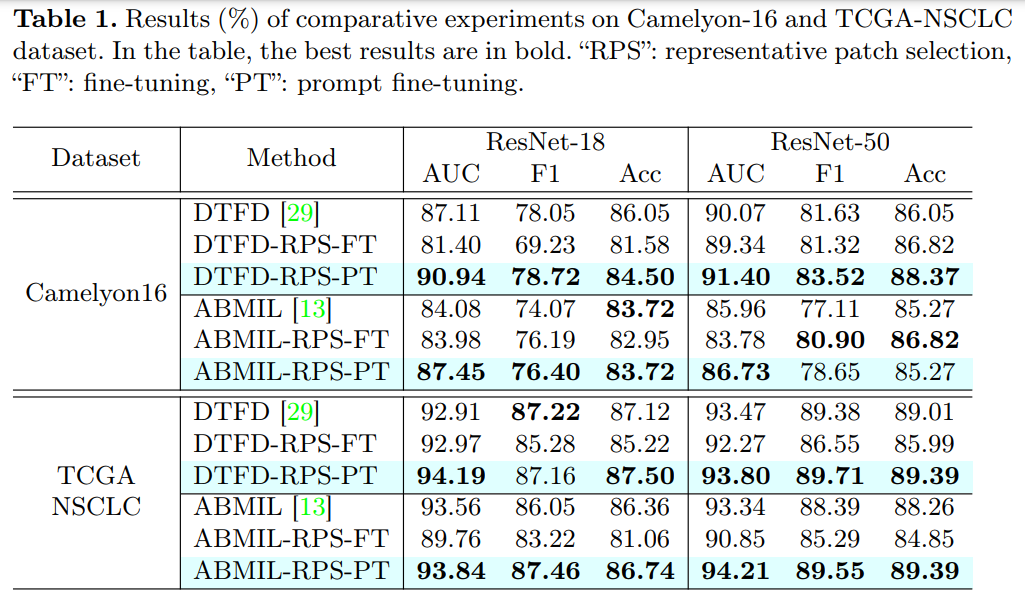
대부분의 실험에서 prompt fine-tuning 했을 때 성능이 더 향상되었다. 이 때 주목해야 할 점은 fine-tuning 은 cost 가 훨씬 많이 든다. 이는 demonstrate the advantage of visual prompt 라고 설명한다.
Ablation study
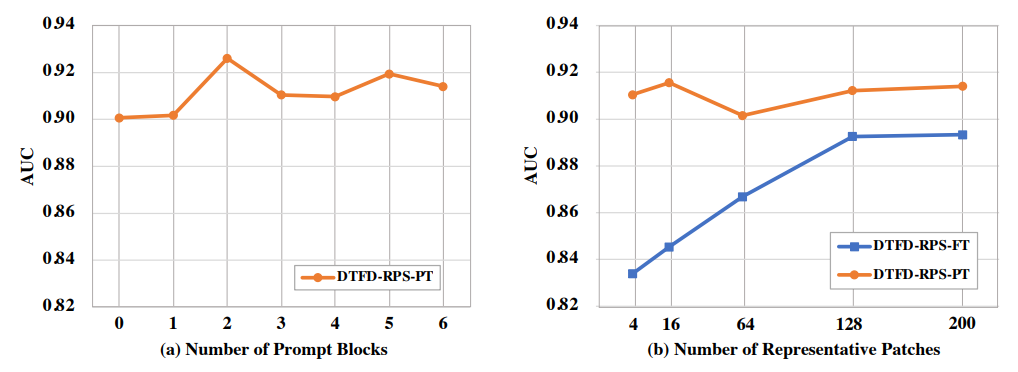
Camelyon16 데이터에서, promopt block 개수, representative patch 개수를 달리하여 실험하였다. (a)를 보면, one prompt block 초과일 때 1%의 성능 향상을 보였다. (b) 에서는 K value 에 따라서, FT 방식에 비해 50% 이하의 GPU resource 를 사용하고도 (이는 본문에 나온 내용임) efficiency, effectiveness 향상이 있었다고 설명한다. - 몇개를 선택하는게 낫다 라는 statement 는 없음.
Conclusion
novel promopt learning method to learn domain-specific knowledge transformation from ImageNet pre-trained model to pathological images
돌려봐야겠다 그리고 sota 라고 언급한 DTFD-MIL 도...
