[Paper Review] Understanding and Controlling Memory in Recurrent Neural Networks
Paper Review
Understanding and Controlling Memory in Recurrent Neural Networks
-
2019, curriculum learning, memory, slow/flexible point
- difference from our setting is that
they are using pre-defined task transition timing and generating each batch data for every time step (??) → I'm scared, wondering if this is what I should have done too.
- difference from our setting is that
-
Task definition (look at figureA below)
- whole time step: 140,000. In every time step, new data is generated and trained.
- Input:
- MNIST (orCIFAR-10) appears at a specific time t_s, and noise images at remaining time steps.
- stimulus (t_s) and response (t_a) are chosen randomly for each trial, ensuring that t_a occurs at least 4 time steps after t_s. (t_a > t_s + 4)
- total length of the input time steps for each trial is capped at 20 Tmax = 20, meaning the network can process inputs and must formulate a response within a maximum of 20 time steps.
- Output:
- network should output a "null" label at all times except during t_a
therefore, only response at t_a is included in loss calculation!
→ this is implemented by introducing new variable z in code…. (I've been struggling with this for an hour)
- t_a output label is dependent on stimulus on t_s

-
Model
- GRU and LSTM for RNN
- like on above B, when using CIFAR-10, CNN weights are used together
-
Training Protocol - Two different Curriculum Learning

- VoCu: - https://dl.acm.org/doi/abs/10.1145/1553374.1553380 Bengio Curriculum Learning 2009 - gradually increase the number of categories 3→4→…→10 (or more) - DeCu: - https://doi.org/10.1142/S0218488598000094 sepp hochreiter 1998 VarnishGrad RNN - gradually increase the number of T_max 6→8→…→20
-
Extrapolation ability for each diff training protocol


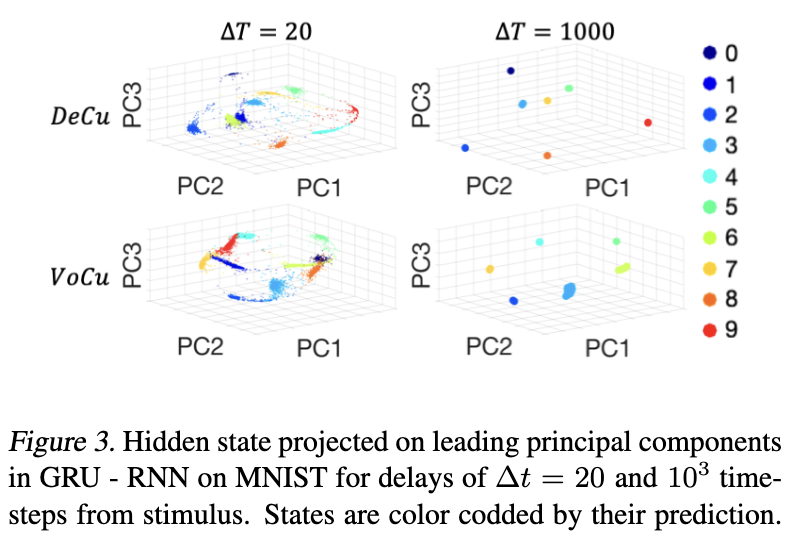
- retrieval accuracy: DeCu was better than VoCu. - VoCu rapidly formed each clouds. but showed unstable and higher variability - DeCu relatively slow, but showed good convergence toward each fixed points


- not well described but red dot (faster, low acc) = VoCu, blue dot (slower, high acc) = DeCu
- speed and accuracy has negative correlation.
- (right) code for finding slow points : just found local minima of “speed”-
Formation of Slow Points - WHY protocols differ
- in VoCu
- 8:2 means : in training step 8000, new class introduced. (MaxClasses[0:8000] = 3)
- jumps are observed.
- in DeCu
- 20 : 8 means : in t step 20000, delay time increased to 8. (T_MAX_VEC[20000:30000] = 8)
- relatively gradual changes are observed.

- (C) - In VoCu, with Backtracking procedure, they found that “the new class is assigned to an existing slow point”. → related to shared attractors (?) - (D) history affect performance? - in (c), class 8 -orange- originated from class 5 -green-. - class 5 performance was impaired more than other existing classes following the introduction of class 8. (look at thick green and orange colored line)


- Improving Long Term Memory
- slow → good
- new regularization with hidden state speed

- slow points can move → costly
- therefore they used center of mass of each class instead of slow points for each class.

