[Paper Review] Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (SwAV)
Paper Review
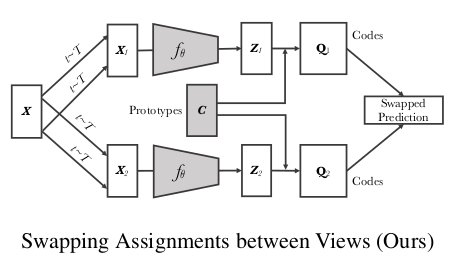
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments

SSL 분야에서 자주 인용되는 SwAV 모델의 페이퍼이다. 기존 contrastive learning 방식을 사용하되, pairwise comparison 을 계산할 필요 없어 online 으로도 사용한 알고리즘이다. Swapping Assignments between multiple Views of the same image (SwAV) 방식을 사용하여 같은 이미지로부터 생성된 representation vector 가 같은 prototype class 를 예측하도록 학습된다. memory bank 나 momentum network 대신 prototype (class) matrix 를 활용하기에 효율적이고, multi-crop 방식을 사용하여 생성된 resolution 이미지는 standard crop (full resolution crop) 과 달리 prototype 에 할당하지 않음으로써 메모리와 속도 면에서 향상이 있었다. 학습에 시간이 오래걸리기는 하나, 성능 면에서 supervised learning 에 가장 근접한 unsupervised learning 방식으로 소개된다.
Introduction
Self-supervised learning 방식에서는, same image 에서 다른 augmentation 을 적용된 image 를 생성 후 그들끼리는 가깝게, 다른 image로부터 생성된 augmentated image 와는 멀리 embedding 하는 것이 가장 기본이 된다. 하지만 모든 instance 끼리 비교하는 것은 사실상 불가능하기에, random subset (batch) 안의 instance 끼리 비교하거나, clustering 을 통해 이 instance discrimination problem을 relax 해준다. (후자 방식의) 예를 들어 DeepCluster 방식에서는 instance 끼리의 contrastive learning 이 아니라 group of instances 즉 clustering 끼리의 contrastive learning 이 이루어진다. 하지만, (이 방식은 tractable 함에도 불구하고) scalable 하지 않다. 학습을 통해 형성되는 clustering assignments 는 결국 모든 dataset image 를 사용해야 하기 때문이다.
그렇기에 이 논문에서는 same image 로부터 다른 augmentation을 적용해 나온 code (clustering assignment)들끼리의 consistency는 유지해주면서, "online" 방식으로 code를 계산하는 새로운 패러다임을 제시한다. deepcluster 방식을 아직 안 읽어봐서 모르지만, 이 논문에서는 code (prototype) matrix 를 encoder와 분리하여 만들고, error propagation 이 따로 이루어진다.
또한 기존 contrastive method 는 이미지 하나 당 한 쌍의 transformation 끼리 비교했던 것과 달리, SwAV 는 multi-crop 방식으로 생성된 small-sized 이미지들도 loss 계산 과정 안에 넣어 성능을 개선한다.
그 결과 scalable online clustering loss 는 momentum encoder나 large memory bank 없이 ImageNet 에서 +2% 의 성능을 달성하였고, multi-crop 방식은 다른 SSL 방식들 보다 2%-4% 향상되었으며, self-supervised on ImageNet with a standard ResNet model 로 4.2% 향상, supervised ImageNet pretraining를 거진 여러 downstream task 에 성능 향상을 보였다.
Related Work
보통 이 파트는 건너 뛰는데 다른 contrastive learning 방식과 비교했을 때 SwAV 이 가지는 경쟁력, 차별점을 봐야할 필요가 있어보여 작성한다.
Instance and contrastive learning
기존 unsupervised learning 에서는 각 이미지를 class 에 할당하고, 이 class 뒤에 linear classifier 를 붙여 학습을 진행했다. 하지만 이 과정은 빠르게 become intractable 했기에, 이전에 계산된 representation을 저장하는 memory bank 를 classifier 대신 사용하여 문제를 개선하였다. 보통 noise contrastive estimation, 다시 말해 InfoNCE 방식을 사용하였고, MoCo 에서는 reprsentation 을 momentum encoder 에 저장하였다. SimSiam 에서는 momentum encoder 없이 batch size 가 크다면 학습이 이루어짐도 밝혀졌다. 이렇게 모든 instance 끼리 pairwise하게 similarity 를 계산하던 기존 연구와는 달리, SwAV 에서는 image feature 를 학습 가능한 (trainable) prototype vector 에 mapping 하여 이를 학습에 활용하는 방식을 취한다.
Clustering for deep representation learning
DeepCluster 에서 k-means assignments 를 pseudo-label 로 사용하여 학습했을 때 large uncurated dataset 에 대해서도 확장 가능하고 downstream task 에도 사용 가능함을 보였다. 하지만 이 방식은 formulation is not principled 되었었고 추후 연구 (Asano et al.) 에서 psuedo-label problem 과 optimal transport problem 연결 짓는 방법 (how to cast ~) 을 제시하였다. 이 연구에서도 비슷한 formulation 을 사용하였지만 Asano 의 연구처럼 Sinkhorn-Knopp algorithm output 을 hard label 에 approximating 하지 않고, soft label 로 사용하여 prototype vector 를 학습하였다. 또한 Asano 의 연구와는 달리 online assignment 방식을 사용하여 어떠한 큰 데이터셋에서도 사용할 수 있는 방식으로 발전시켰다.
Method
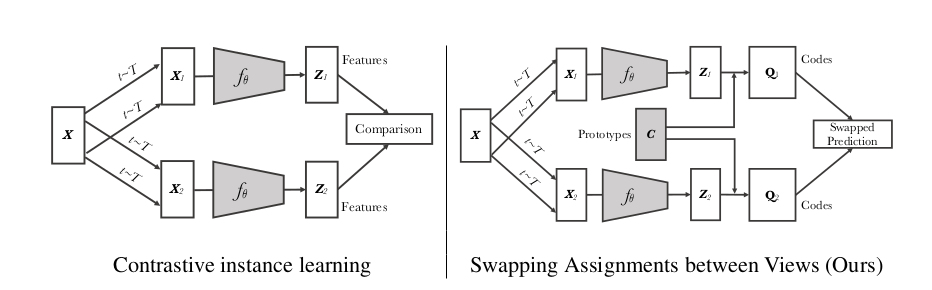
가장 간단하게 (이해는 안되겠지만) 설명하자면 한 image 에 다른 augmentation 을 적용하여 encoder 를 통과시킨 representation 을 각각 z 와 z' 이라고 해보자. z 를 trainable 한 prototype matrix C 를 통해 각각의 code q, q' 를 생성한다. 이 때 다른 augmentation 을 적용했더라도 한 image 에서 나온 code 이기 때문에, z 로 q' 을 예측할 수 있어야 하고 z' 로 q 를 예측할 수 있어야 한다는 아이디어로부터, 다음과 같은 loss 를 사용하게 된다.
이제 기본 theme 을 알았으니 그 내부를 까서 code 는 어떻게 생성되는 것인지, prototype matrix C 는 무엇인지, intro 에 소개된 multi-crop method 는 무엇인지 그리고 왜 사용하는지에 대해 소개하도록 하겠다.
Online clustering
각 image 는 transformation t sampled from the set 을 적용하여 를 생성한다. 이들은 non-linear mapping (encoder) 를 거쳐 로 표현되고, 각 feature 는 normalize 되어 unit sphere 상에 projection 된다. 이 뒤는 논문의 설명이다.
We then compute a code from this feature by mapping to a set of K trainable prototypes vectors, { , ..., }. We denote by C the matrix whose columns are the , ... , .
z 를 c (prototype vector) 를 활용해서 q로 만든다는 뜻이다. 부연설명을 하자면, q 는 z 와 c 를 이어주는 graph 형태이다. C 라는 k 개의 대표 prototype vector 를 가지고 있는 matrix 와, z 하나하나를 비교했을 때, (ex) 는 이 K 개 중 몇 번째 prototype vector 와 제일 가까운지를 계산하여 어떤 prototype vector 에 "할당" 하면 될지를 "안내" 해주는 일종의 path 혹은 label 이라고 생각하면 편하다. 극단적으로 이 (0.06 0.08 0) 이고, 2개의 class vector 각각 (0.06, 0.08, 0) (0.08, 0.06, 0) 을 가진 matrix C 가 있을 때 (이렇게 되면 matrix C 는 [[0.06 0.08 0]; [0.08 0.06 0]] ) 은 (1, 0) 이 되는 것이다.
Swapped prediction problem
아직 명확히 납득가지는 않았겠지만, 다음 소개된 loss 를 함께 이해해보도록 하자.
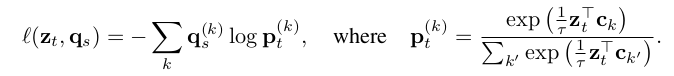
어디서 굉장히 많이 본 loss 이지 않는가? cross entropy 식 안에 들어간 q 와 p 의 첨자를 자세히 보면 각각 s 와 t 이다. 즉 다른 augmentation 이 적용된 loss 인 것이다. infoNCE loss 안을 들여다 보면, (우선 temperature가 쓰였고), z_t 와 다른 모든 prototype vector 들간의 거리에 비해, 상대적인 해당 prototype k vector c_k 사이의 거리를 뜻한다. 즉 q 는 실제로 z_s 가 어느 prototype vector 와 가장 가까운지를 특별한 알고리즘을 적용해서 "답지 label"를 만들어낸 것이고, p 는 z 와 c_k 사이의 상대적인 거리를 구해버린 것이다. 이렇게 해서 두 확률이 다르면 loss 가 커지게 되는 것이다.
요약하자면, z_s 를 주어진 C prototype matrix 를 통해 어느 prototype vector 와 가까운지를 설명하는 답지 q_s 를 생성하고, z_t 와 C prototype vector 와의 상대적인 거리를 구한 p_t 를 생성하여, q_s 와 p_t 사이의 cross entropy loss 를 구하고, 그 반대인 p_s, q_t 사이에서도 CE loss 를 구하여 더해주면 우리가 원하는 최종 loss 를 구할 수 있는 것이다. 저 위의 식을 모든 N개의 image 에 대해 풀어 쓰면 다음과 같은 식으로 표현할 수 있다.
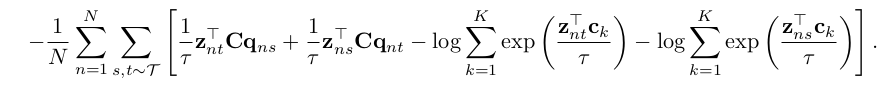
Computing codes online - Sinkhorn Algorithm
그렇다면 답지라고 설명했던 code q 를 구하기 위해 z와 c 를 이용한다 설명했는데, 구체적으로 어떤 알고리즘을 사용하는지에 대해 설명하도록 하겠다.
그 전에 문제 정의를 다시 해야 한다. 빵을 생산하는 베이커리 A, B가 있고, 이를 받아야 하는 학교 X, Y, Z 가 있다. A 는 300개, B 는 700개의 빵을 생산하고, 학교 X, Y, Z 는 각각 400개, 500개, 100개를 수급해야 한다. 이때, 베이커리와 학교 사이의 이동 거리를 cost value C graph 형태로 표현을 했을 때, 총 이동거리를 최소화 하면서도 학교에게 알맞은 빵을 공급하는 루트 P (transportation plan) 를 구하는 문제를 transportation polytope problem 이라 부른다.
그 아래부터는 필기 설명으로 대체하겠다..

결국 요약하자면, 많이 생산하는 빵집은 (일단 cost matrix 를 빼고 생각했을 때) path 가 많이 뚫려 있어야 하고, 많이 소비하는 학교도 path 가 많이 뚫려 있어야 한다는 아이디어에 착안하여, rc^T 와 P 사이의 KL divergence 를 일정 parameter 이하로 보내자는 constraint 가 하나 추가되었다. 결국 이는 P 의 관점에서 봤을 때 P 의 entropy 를 maximize 하는 식이고, 이는 optimization 관점에서 봤을 때 non-convex problem 이기 때문에, convex problem 으로 바꿔주기 위해 duality 를 이용하여 새로운 convex problem 을 만든 식이 이제 3번 아래 있는 네모박스 식이다. 결국 이를 라그랑주 식을 이용해서 풀면, 어떤 두 상수 m, n 의 function 인 u 와 v vector 와 exp(-lambda c) 의 곱으로 P 가 결정되게 된다. 이 때, u 와 v 는 diagonal 에 P 는 doubly stochastic (다 normalized 되었다는 뜻) 이기 때문에 sinkhorn theorem 을 적용했을 때, normalize iteration을 수행하면 converge 한다. 그렇기에 맨 마지막에 설명되어 있는 알고리즘으로 귀결되는 것이다.. . . . .
https://amsword.medium.com/a-simple-introduction-on-sinkhorn-distances-d01a4ef4f085 설명은 이 글을 참고하였다..
이제 다시 우리의 문제로 돌아와서, 다음 식과 마주하게 된다.
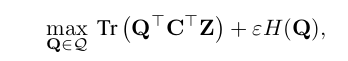
Q 는 z와 c를 이어주는 code matrix 이고, 는 두 matrix entry 사이의 거리를 표현해주는, 즉 위 문제에서의 cost matrix 가 되어준다. 위 optimization 식의 결과와 consistent 하게, 여기서도 optimal Q 를 다음과 같이 정리한다.
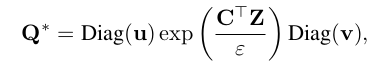
이 때 논문에서 본인들은 soft code 를 사용한다 표현하였다. 원래 Q matrix 자체는 discrete 하게 z_1 은 c_3 로 이어지고 z_2 는 c_4 로 이어지는 entry 가 0, 1 인 graph 형태로 표현하려 했으나, 실제로 결과를 내본 결과 z_1 은 c_3 에 0.5 c_2 에 0.2 ... 이런식으로 continuous solution Q 를 사용했을 때 성능이 더 잘 나왔다고 한다. 이는 discrete solution 으로 바꾸는 과정에서 rounding 이 사용되었고 이는 aggressive optimization 이기 때문이라 설명한다.
또한 하나의 포인트가 더 있는데, Q 의 entropy 를 penalty term 으로 놓았기 때문에, Q matrix 가 하나의 prototype vector 로 쏠리게 할당을 하게 된다면 (어쩌면 이는 collapse) penalty 를 부여하게 된다. 즉 각 representation z 를 모든 prototype vector 에 골고루 할당하도록 하는 하나의 constraint 로 작동한다고 설명한다.
Multi-crop: Augmenting views with smaller images
하나의 image 를 여러 view 로 보는 것이 성능 개선이 도움이 되는 것이 알려져 있지만, augmentation 을 늘릴수록 compute / memory requirement 가 quadratic 하게 늘어나게 된다. 이 문제를 타개하기 위해, two standard resolution crop 은 모든 다른 augmentation 과 계산을 수행하고, 다른 multi-crop sample V additional low resolution crop 들에 대해서는 서로서로 계산하지 않고 오직 two standard resolution crop 들과만 loss 계산을 수행한다. 다음과 같은 식으로 표현할 수 있다.
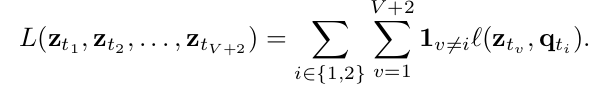
code 를 계산하는 부분은 오직 2 standard resolution 에 대해서만 수행된 것을 확인할 수 있다. 아래 섹션에서 성능차이를 보여주며, multi-crop 은 여러 self-supervised method 에서 성능 향상에 도움을 주었고 promising augmentation strategy 라 설명하고 있다.
Main Results
SwAV 를 통해 feature 를 학습하고, 이를 multiple dataset 에 transfer learning 하여 성능을 찍었다. SimCLR 에서 사용된 LARS, cosine learning rate, MLP projection head 를 구현하였고 성능 향상을 이뤄냈다.
Evaluating the unsupervised features on ImageNet
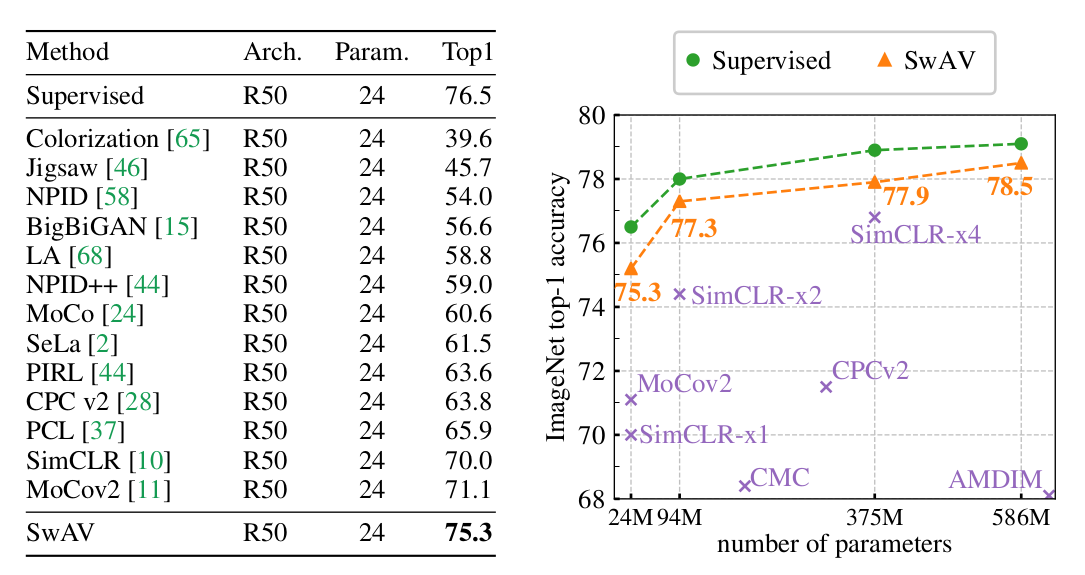
left: frozen feature 를 사용했을 때 기존 sota 를 +4.2% outperform 하고 supervised learning 과 1.2% 차이밖에 나지 않는 뛰어난 성능을 보였다. (800 epoch, 4096 large batch)
right: 또한 ResNet-50 width 에 2, 4, 5 를 곱한 variants 에서도 supervised learning 과 비슷한 경향성을 보였고 그에 준하는 성능을 보여주었다.
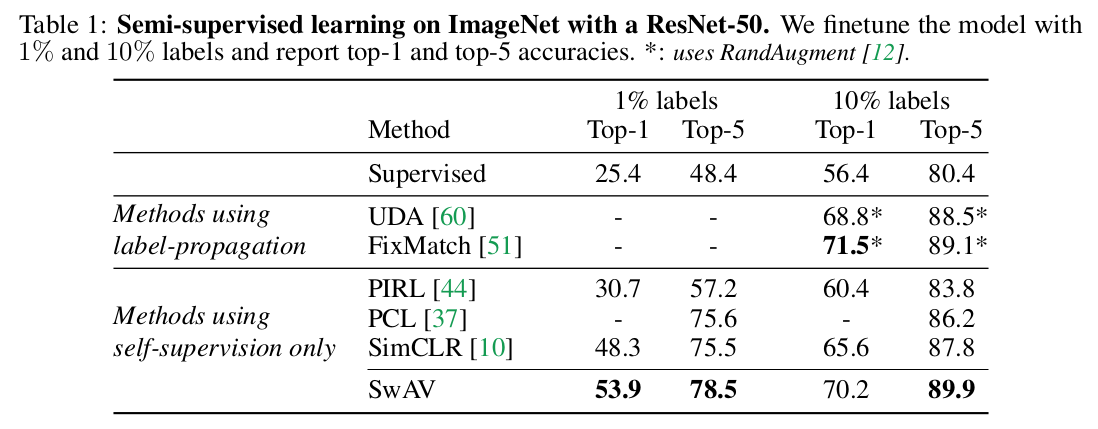
semi-supervised learning 을 타겟하고 설계된 모델이 아님에도, sota semi-supervised learning 과 다른 self-supervised learning 을 outperform 하는 성능을 보여주었다.
Transferring unsupervised features to downstream tasks
ImageNet 을 label 없이 ResNet-50을 기반으로 학습한 SwAV 의 generalization 성능을 보기 위해, 몇몇 downstream vision task 에 transfer 하여 성능을 비교했다.
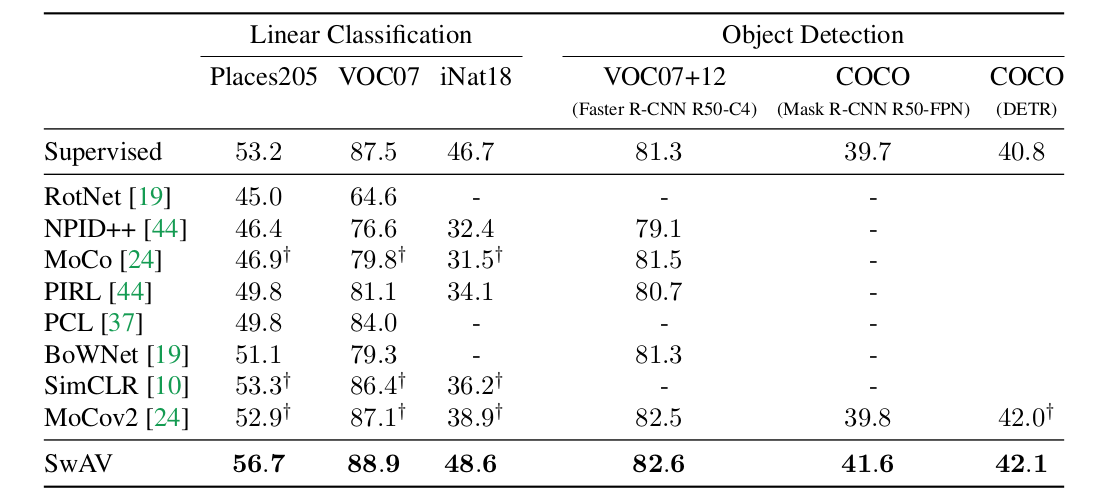
왼쪽 supervised learning - linear classification 결과를 outperform 했다. 흠 왜지
appendix - places205 28 epoch, iNat18 84 epoch - 이미지 몇개 썼는지는 나와있지 않음.
Our SwAV ResNet-50 model surpasses supervised ImageNet pretraining on all the considered transfer tasks and datasets.
Training with small batches
SwAV 를 (이전엔 large batch 4096) small batch 256 images on 4 GPU setting 에서 실험하고, MoCov2 와 SimCLR 과 비교하였다.
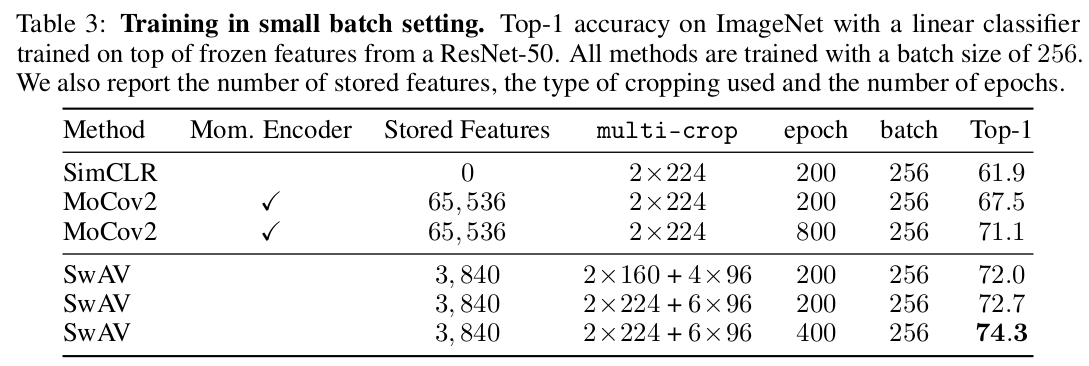
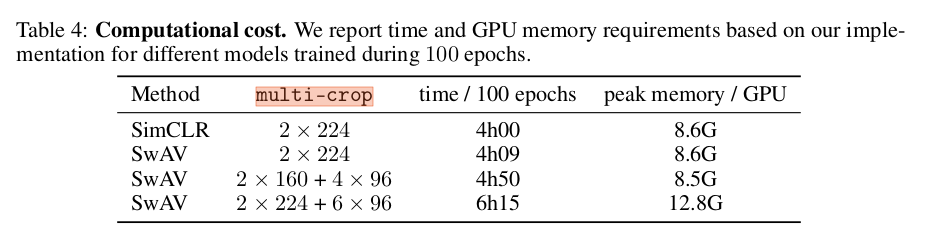
다른 방식과 비교했을 때 sota 성능을 보여주었다. SwAV 는 3840개의 feature 가 들어가는 queue 를 사용했고, MoCov2 는 momentum encoder network 를 돌리면서도 65536 개의 feature가 들어가는 queue 를 사용하였다. 또한 running time 을 기준으로 한 epoch 당 걸리는 시간은 MoCov2나 SimCLR 이 더 빨랐지만 good downstream performance 를 얻기까지의 epoch 수는 SwAV 이 더 적었다. (ex MoCov2 800 epoch 71.1, SwAV 200 epoch 72.0) 마지막으로, SwAV 는 large batch + momentum encoder 와도 사용할 수 있는데, 이는 future work 로 남겨두었다고 한다.
Ablation study
Clustering based self-supervised learning
improving prior clustering-based approaches
과거 clustering-based model 을 재구현하고 현존 contrastive method SimCLR 과 비교하였다.
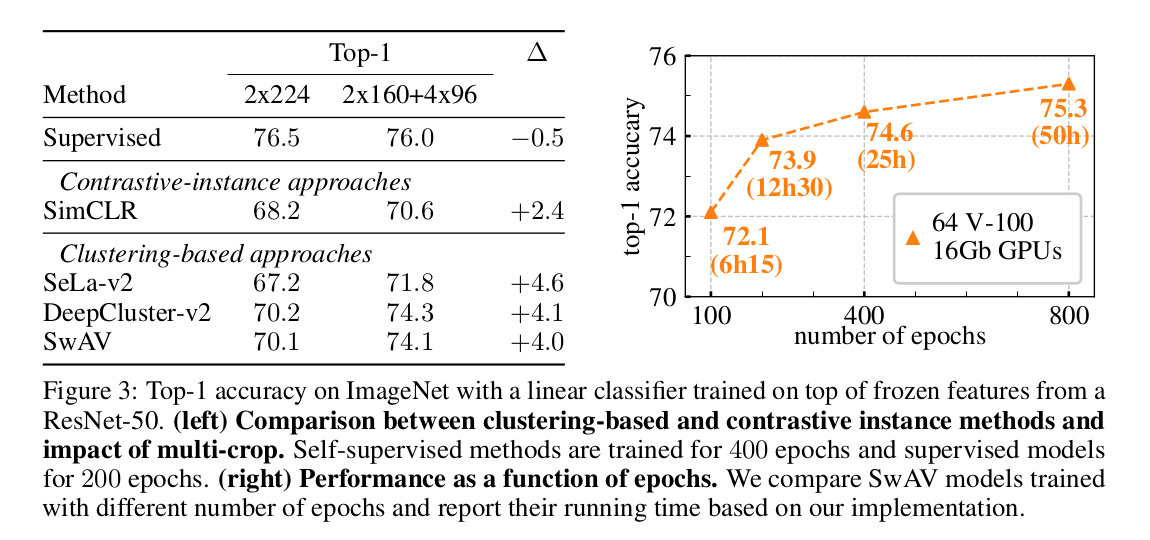
DeepCluster-v2 는 기존 deepcluster 의 two consecutive (ex epoch 1, 2 에서의) cluster assignments 끼리 correspondence 가 없어, epoch 이 새로 시작될 때마다 cluster assignment 와 final classification layer 이 irrelevant 하게 되어 다시 처음부터 학습되어야 한다는 큰 단점이 있었다. 이를 보완하고자, k-means clustering centroid의 explicit comparison 을 추가함으로써 stability 와 performance 를 향상하였다.
comparing clustering with contrastive instance learning
SimCLR 과의 fair comparison 을 위해 SwAP 에서 사용했던 same data augmentation, epoch 수, batch size 등을 맞추어 실험을 진행하였고, 향상된 기존 clustering-based model 과 SwAV 이 SimCLR 을 성능 면에서 능가하였다. 이는 learning potential of clusteirng-based methods over instance classification 을 보여준다 설명한다.
advantage of SwAV compared to DeepCluster-v2
성능 면에서 DeepCluster-v2 가 SwAV 을 능가하지만, 결정적으로 DeepCluster-v2 는 online algorithm 이 아니라서 large dataset 에 대해서는 작동할 수 없다. 또한 DeepCluster-v2 는 본 논문에서 제안한 swapping 방식의 special case 라 볼 수 있는데, swapping 이 batch 내에서 instance 끼리 이루어지는 것이 아니라 across epoch 에서 일어나는 것이라 해석할 수 있다.
Applying the multi-crop strategy to different methods
figure 3 의 left 를 보면, multi-crop strategy 가 가진 성능개선 효과에 대해 알 수 있다.
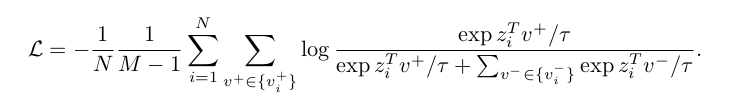
다음 loss function 은 SimCLR 에서 multi-crop strategy 를 어떻게 적용했는지를 보여준다. M 은 number of crops per instance 이고, 2x160+4x96 crops 이 있으면 M=6이 되는 것이다.
Unsupervised pretraining on a large uncurated dataset
online algorithm 을 사용함으로써 얻을 수 있는 scalability 를 증명하기 위해, instagram 으로부터 1 billion random public non-EU image (uncurated dataset) 으로 SwAV 를 pretrain 하고, ImageNet 에서 frozen feature linear classifier / finetuned feature linear classifier 성능을 비교하였다.
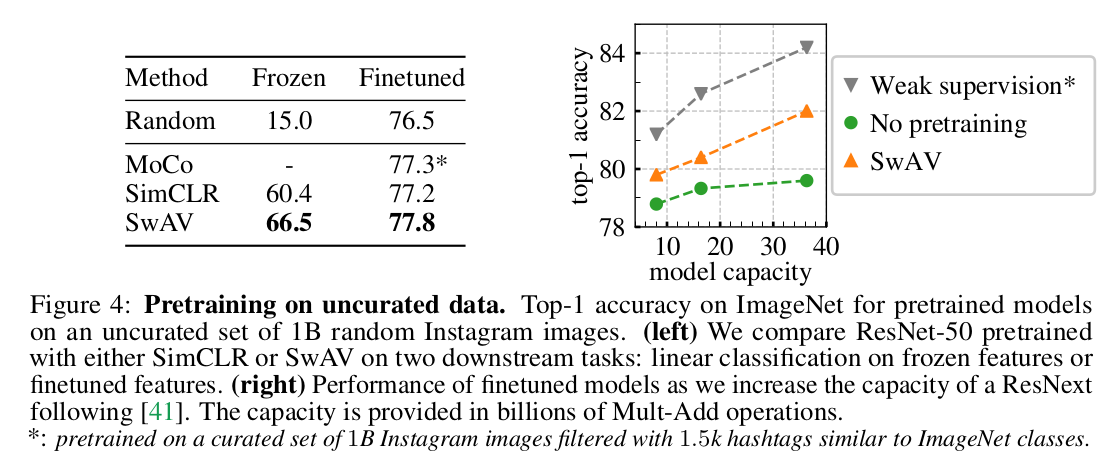
결과 SwAV에서 random initialized / SimCLR pretrained 보다 좋은 성능을 보였고, fined-tuned 에서도 역시 좋은 성능을 보여주었다. 또한 기존 ResNet-50 보다 capacity 를 늘린 ResNext 를 이용하여 동일 실험을 진행하였고 supervised models trained from scratch on ImageNet 과 비교했을 때 더 좋은 성능을 보여주었다.

설명을 되게 깔끔하게 잘해주셨네요.
잘보고 갑니다!