When Does Contrastive Visual Representation Learning Work?

self-supervised representation learning 이 어떤 조건 하에 잘 작동하는지에 대한 insight 를 제공하는 논문이다. 크게 ImageNet, iNat21, Places365, GLC20 dataset 을 사용하여, 1) Dataset size, 2) Domain, 3) Quality, 4) Task granularity 를 달리한 실험을 진행하였다. 대부분의 실험이 SimCLR과 ResNet-50 으로 진행되었다.
Introduction
Under what conditions do self-supervised contrastive representation learning methods produce good visual representations?
- What is the impact of data quantity?
- What is the impact of the pretraining domain?
- What is the impact of data quality?
- What is the impact of task granularity?
Methods
Datasets:
ImageNet (1.3M images, 1k classes), iNat21 (2.7M images, 10k classes), Places365 (1.8M images, 365 classes), GLC20 (1M images, 16 classes)
Fixed-size subsets: uniformly random 하게 선택하여 1M, 500k, 250k, 125k, 50k images 등을 구성함.
Training details: ResNet-50 backbone 을 사용한 SimCLR 로 self-supervised learning 을 진행함.
Experiments
Data Quantity (datasize)
SSL 에서 good representation 을 배우기 위해 필요한 데이터의 양은 얼마인가?
다음 두가지 조건을 바꾸어 실험을 진행하였다.
1) # of unlabeled images used for pretraining
2) # of labeled images used to subsequently train a classifier
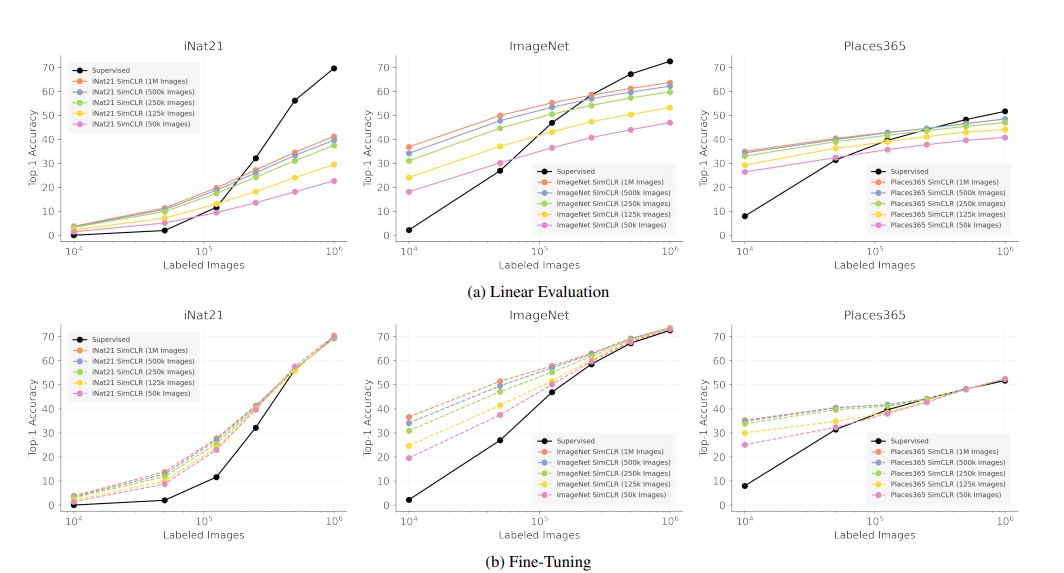
black line 은 supervised training 을 from scratch training 한 결과를 나타낸다. linear evaluation 는 fine tuning 과 달리 모든 parameter 를 freeze 해놓고 마지막에 linear layer 만 추가하여 이 parameter만 학습되도록 한 세팅이다.
There is little benefit beyond 500k pretraining images
저자는 500k (blue) 와 1M (orange) pretraining image curve 를 비교했을 때 1-2% 밖에 차이 나지 않음에 주목한다. 250k (green) 와 50k (pink) 를 비교했을 때 10% 이상의 차이를 보이는 구간도 존재하는 것으로 보아, pretraining 시에 image 개수를 500k 이상으로 늘려도 큰 효과를 보기 어렵다고 해석한다.
SSL pretraining can be a good initializer when there is limited supervision
bottom row 를 봤을 때, labeled image 가 10k, 50k인 경우 supervised learning 보다 SSL 로 pretraining 후 fine-tuning 하는 것이 significantly better 했다. 또한 labeled image 가 커짐에 따라 supervised learning 의 결과와 비슷해지는 양상을 보였다. 저자는 이를 보고 SSL 이 good initializer 라 해석하는데, 이전 연구 중 supervised learning 초기에 distort augmentation 이 들어간 image 를 사용하면 후반에 가도 일반 learning setting 의 결과를 따라잡지 못하는 결과와 함께 놓고 봤을 때 흥미롭다 해석한다.
SSL representation can approach fully supervised performance for some dataset, but only by using lots of labeld images
ImageNet 과 Places365 의 결과 그래프를 봤을 때, labeled image 가 100k 일 때에도 pretraining을 1M image 로 진행한 실험 결과 성능 (orange) 는 supervised learning 의 성능 (black) 과 큰 차이가 나지 않는다 해석한다.
iNat21 is a valuable SSL benchmark
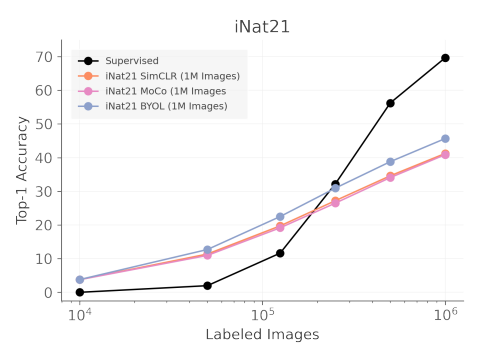
iNat21 의 경우 SSL pretraining 결과들과 supervised learning 결과 (black) 사이에 large gap 이 존재한다. 이를 보고 SimCLR 이외에 MoCo, BYOL 로 실험을 진행하지만 여전히 큰 차이를 보였다. (species point 를 보면 됨) 저자는 이를 보고 iNat21 dataset 이 SSL의 challenge, 즉 아직 해결되지 않은 과제로써 향후 SSL 연구로 주목할만한 benchmark 라 언급한다.
Data Domain
what kind of images should be use for pretraining? 어떤 데이터셋을 사용해야 하는가?
다음과 같은 세가지 실험을 진행한다.
1) in-domain and cross-domain linear evaluation results
2) pretraining on pooled datasets 세팅의 결과
3) differently fused representation 으로 실험한 output
Pretraining domain matters

in-domain 에서 실험했을 때 성능이 가장 좋았고, cross-domain 실험 세팅 중에선 ImageNet 의 성능이 가장 좋았고 GLC20 의 성능이 가장 좋지 않았다. 특히 ImageNet 의 cross-domain 성능이 잘 나온 것을 보고 이는 "semantic similarity" 때문이라 해석한다. 이에 대한 다른 근거로 2가지 추가실험을 제시한다.
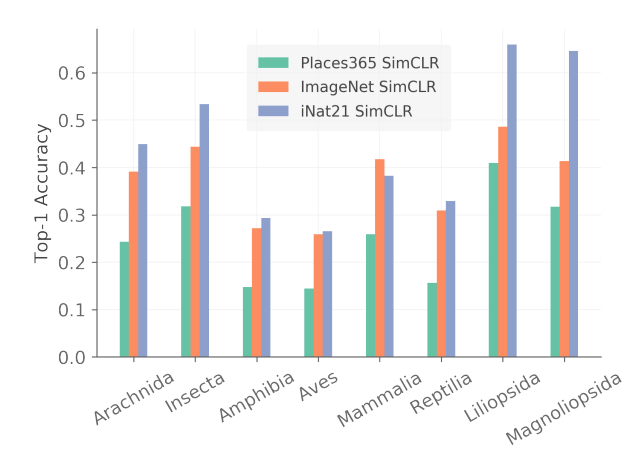
animal 과 plant 의 사진으로 이루어진 iNat21 dataset 에서 taxonomic class 를 나누어 accuracy 를 측정했을 때, animal과 plant 의 사진 또한 포함되어 있는 ImageNet pretrained 모델의 성능이 특정 class 에선 높았고 다른 여러 class 에선 iNat21 pretrained 모델의 결과와 비슷한 성능을 보였다. 그에 비해 scene 정보가 많은 Place365 의 결과는 그렇지 못했다.
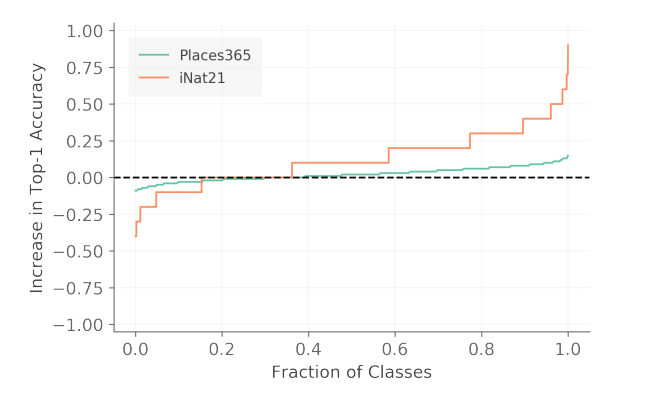

또한, Places365 와 iNat21 의 in-domain accuracy 를 class 별로 break down 해서 봤을 때 (당연히 평균은 0) iNat21의 경우 약 40%의 class 는 accuracy 전반을 hurt 하고 60%의 class 는 accuracy 향상에 도움을 주었다. 이 때 60% 의 대부분은 plants 였다는 사실에 주목한다. label 이 주어지지 않았음에도 불구하고 high level 의 semantic information 에 따라 다른 결과를 내었다는 것으로 해석하여, SSL 이 representation 을 만들어내는 과정에서도 semantic similarity 가 들어간다 라고 설명한다.
Adding cross-domain pretraining data, general representation 에는 그닥
dataset 을 섞었을 때 성능이 어떤지 실험한다. (pretraining on pooled dataset)
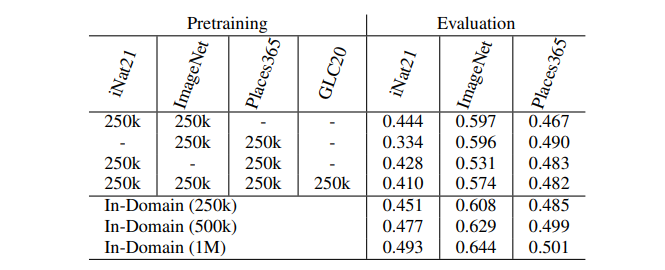
모든 실험에서, adding pretraining data from different domain 은 성능을 저하했다. 이에 대한 원인으로 "diversity-difficulty trade-off" 라 설명하는데, diverse (different domain) image 가 들어오면, contrastive learning 과정에서 너무 쉬운 문제로 인식하여 성능이 떨어진다 설명한다. (SimSiam 에서도 비슷한 설명 나왔음)
Self-supervised "representation" can be largely redundant
어떤 dataset 에 pretrain 되느냐에 따라 성능이 다른 것을 보고, representation 의 차이가 어떤지 궁금하여 representation 끼리 fusion 하여 성능을 측정해 보았다. 구체적으로 저자는 concatenate features from different pretrained networks 하고 linear evaluation 을 통해 성능을 측정한다.

1) two self-supervised representation 을 섞어도 성능 변화는 미미했다.
ImageNet SimCLR alone 0.647 --> combined 0.641 / iNat21 SimCLR alone 0.506 --> combined 0.520
이를 통해 저자는 two self-supervised representation 은 largely "redundant" 함을 암시한다고 설명한다.
2) supervised and self-supervised representation 을 섞었을 때 차이가 꽤 있었다.
ImageNet SimCLR alone 0.506 --> ImageNet SimCLR + iNat21 Sup 0.553 / iNat SimCLR alone 0.647 --> iNat21 SimCLR + ImageNet Sup 0.605
이 때, iNat sup 을 추가했을 때 ImageNet 분류 성능이 저하되었던 것에 반하여 ImageNet sup 을 추가했을 때 iNat 분류 성능이 향상되었다. 이 또한 dataset semantics 가 SSL 에서 중요하다라는 가정과 consistent 하다 설명한다. (ImageNet의 feature 는 iNat 에게 도움, iNat 의 feature 는 ImageNet에게 도움 안됨 -> 쉬운 문제라서)
Data Quality
여러 image corruption 방식을 적용하여 실험을 진행한다.
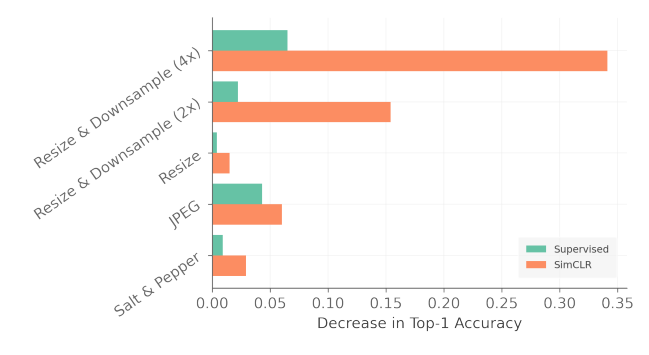
이 때 Resize & Downsample 은 downsample 후 upsample 을 적용하여 size 는 그대로 유지하되 resolution 을 망가뜨리는 corruption 이다. salt & pepper 방식은 이미지 픽셀 단위에서 일정 확률(0.01)로 black or white 한 pixel 로 바꿔버리는 corruption 방식이다. JPEG 는 손실 압축 알고리즘을 적용하여 사람의 눈에 민감도가 적은 high frequency 정보를 제하는 방식의 corruption 이다. Resize 는 resolution을 유지하되 크기만 줄이는 방식이다. pretraining 을 corrupted image 로 진행한 뒤 기존 clean image 를 사용하여 linear evaluation 을 진행하였다.
저자는 extreme cropping 을 사용하는 SSL 방식 특성 상 resolution 에 robust 할 것이라 예상했지만, 실제 결과를 봤을 때 SSL 방식은 resolution 을 망가뜨리는 방식에 크게 반응하여 성능 저하가 일어났다. 오히려 high-frequency noise 에 robust 한 결과를 보였고, 이는 texture information이 저하되어 설명력이 크게 감소했다 라고 설명한다. (자세한 원인이 분석되지는 않음)
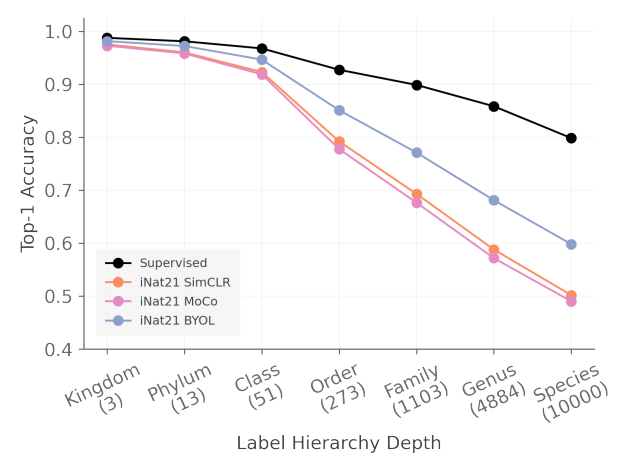
Task Granularity
SSL 은 downstream task 에도 많이 사용된다. 여러 dataset 의 label 의 hierarchy 를 사용하여 fine-grained classification 의 성능을 측정한다. finest label 로 training 시키고, (retrain 없이) label set 만 바꿔 실험을 진행하였다.
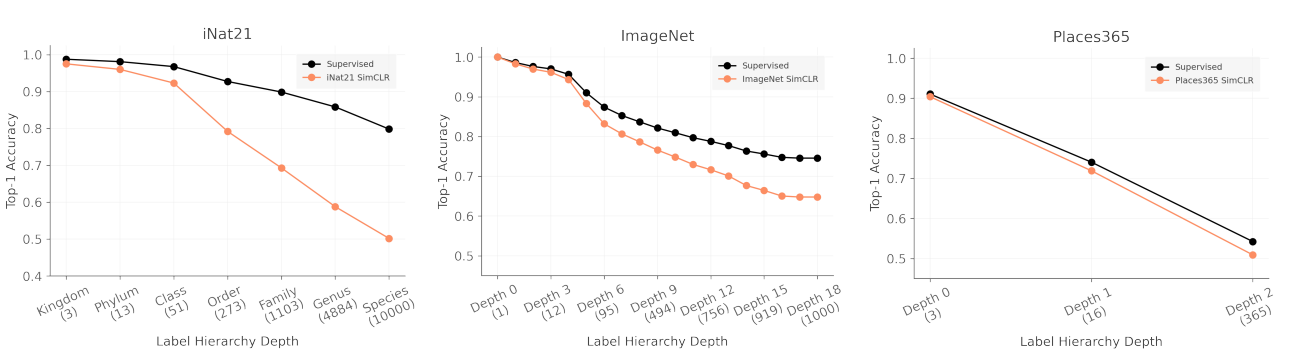
iNat21 결과 Supervised 모델과 달리 SimCLR 모델에서 rapid degradation 이 관측되었다. 다른 dataset 에서도 전반적으로 더 빠른 degradation 이 일어났다. 그럼에도 데이터양 (data quantity) 을 달리하여 진행했던 실험 결과와 비슷하게, iNat21 은 SSL 방식이 잘 잡지 못하였다. 이에 대한 원인으로, SSL 의 augmentation 등의 방식이 ImageNet에 fitting 되었을 가능성을 언급한다. 예를 들어 SSL 에서 사용된 color jitter augmentation 이 ImageNet 에서는 잘 작동하였지만 iNat21의 fine-grained classes 를 구분하는 핵심 feature 를 손상시켰을 수 있는 것이다.
Conclusion
- 500k 는 있어야.. 100k 는 supervised learning 과 차이가 너무 큼.
- 다른 dataset 사용했을 때 성능 차이 큼. 단순히 SSL representation concat 했을 때 성능 변화 미미함.
- image resolution 이 contrastive learning 에서 critical 함.
- SSL pretraining 은 fine-grained classification 성능 면에서 벽을 느낌.
수학적인 내용이 많을 줄 알았는데 생각보다 실험 위주여서 조금 아쉽.. 하지만 representation fusion 은 써먹을만 할지도? (단순 feature concat 이 도움이 많이 되는구만)
