[Paper Review] VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Paper Review

Facebook AI Research (FAIR) 에서 작성한 논문으로 2022년 ICLR 에 채택되었다. Encoder 단에서 대상의 feature 를 뽑는 과정에서, constant하거나 non-informative vector 를 내놓는 collapse 문제를 피하기 위한 연구가 지속적으로 이루어졌고, collapse 가 왜 발생하는지에 대한 연구가 활발히 이루어지고 있다. 이번 논문에서는 BN, memory bank, SG, output quantization 등의 techniques를 사용한 기존의 SSL 방식과는 달리 explicit 하게 collapse 를 피하도록 설계된 loss 이외에 2개의 regularization term 을 설정하고 실험하여 collapse 문제에 대해 다루었다.
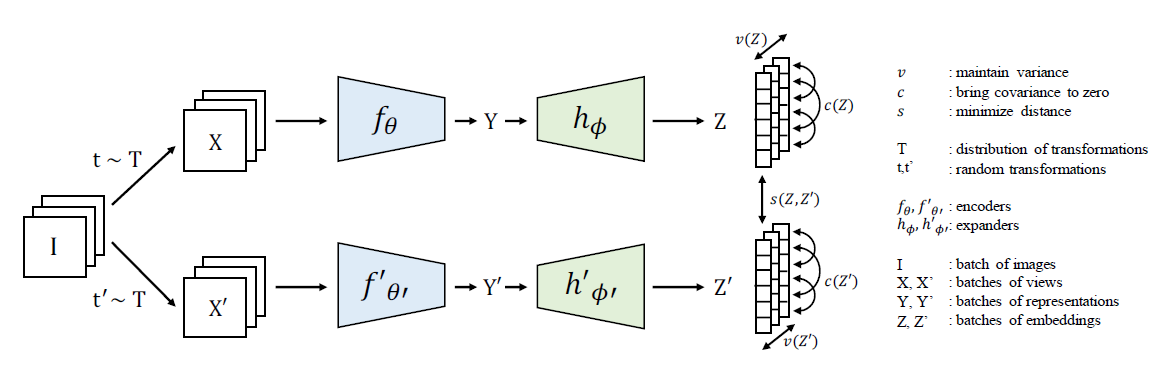
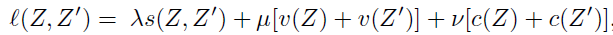
핵심 figure 는 다음과 같다. 긴 막대 하나를 하나의 sample로부터 뽑힌 feature vector 라 생각했을 때 feature vector 들 간의 variance 를 유지하는 1) variance term, 하나의 feature vector 내에서 feature 간의 correlation 을 0 으로 보내는 2) correlation term, 기존 self-supervised learning 방식과 같이 같은 image 로부터 다른 augmentation (random transformation t, t') 이 적용된 두 feature vector 간의 Euclidean distance 를 0으로 보내는 3) invariance term 으로 구성되어 있다. 이제 식을 조금 더 자세히 보도록 하자.
1) variance term
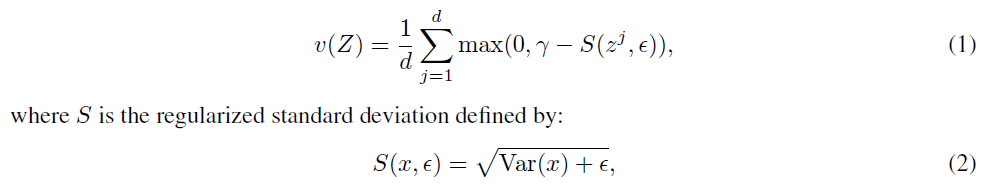
각 column 마다 전체 feature vectors의 std를 계산하고, hinge loss 를 통해 gamma 값으로 유지하도록 설계되었다. 이는 모든 vector 가 하나의 constant vector로 모이는 collapse 를 방지하는 역할을 수행한다.
2) covariance term

feature vector 의 covariance matrix 를 구하고, 이 vector 의 diagonal part 를 제외한 부분만 loss 에 포함시켜, 하나의 sample 에 대해서 서로 다른 dimension 끼리의 correlation을 0으로 보내주는 역할을 수행한다. 마치 Barlow Twins의 decorrelation loss와 비슷하다.
3) invariance term
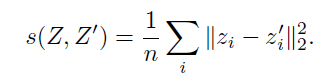
Z (original), Z' (random transformed) 사이의 Euclidean distance 로 표현된 loss 이다. representation space 상에서 positive sample 간의 distance를 줄임으로써 의미있는 representation 이 수행될 수 있도록 하는 term이다. 만약 위 두개의 term 없이 이 invariance term 만 존재했더라면, 그리고 memory bank 및 stop gradient 등의 technique 이 사용되지 않았다면, representation vector 가 저 square term 의 최소를 만족하는 하나의 constant term으로 collapse 할 것이라는 시나리오를 쉽게 생각해 볼 수 있다.
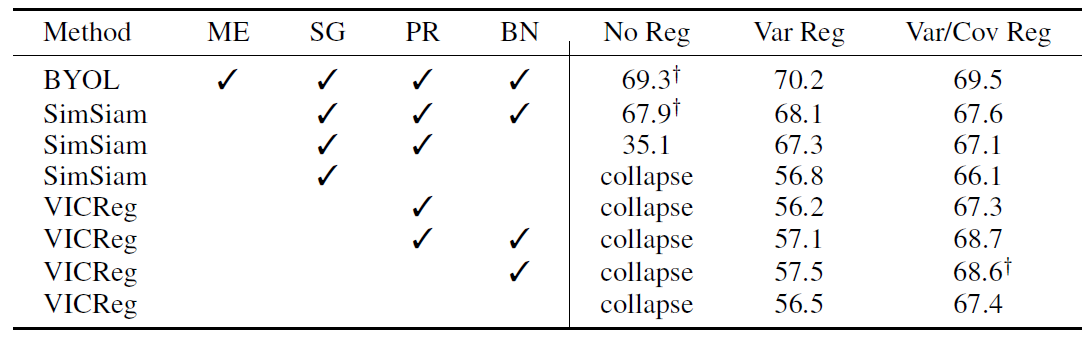
실제 실험 결과 테이블로 이 논문의 가장 핵심이 되는 실험 결과 자료이다. accuracy 옆에 mark 가 있는 실험 set은 original paper 실험 set 을 의미한다. BYOL은 moving average, stop gradient, predictor (sg와 다른 곳), batch normalization 이 사용되었고, SimSiam 에서는 moving average를 사용하지 않고도 좋은 성능을 보여주었다. 4번째 row 를 보면, SimSiam에서 predictor 없이 stop gradient 만 사용되면 collapse 가 발생한 것을 확인할 수 있다. 이전 블로그에서 리뷰했던 How SimSiam works? 논문에서 decorrelation 성분과 de-centering 성분이 중요하다 언급이 되었었는데, 그 역할을 해주는 variance term과 correlation term 을 넣어주었을 때 collapse 문제가 해결됨과 동시에 성능향상이 있었다. 이는 언급했던 논문의 결과와 굉장히 consistent 한 결과이며 재미있는 부분이라 생각해 볼 수 있다. 또 VICReg 실험 결과에서도, 딱히 stop gradient와 predictor, moving average와 같은 technique을 사용하지 않아도 explicit 한 variance regularization term과 covariance regularization term을 넣어주었을 때 collapse를 피하면서도 성능이 괜찮게 나온 것을 확인할 수 있다. 이것만으로 이전 SSL technique의 역할과 variance/covariance term 간의 인과관계를 설명할 수는 없겠지만 굉장히 강력한 supporting idea가 될 것이다.
재밌구만
