VICRegL: Self-Supervised Learning of Local Visual Features
2021년 facebook AI (FAIR) 에서 연구했던 VICReg 의 후속 연구로 VICRegL 가 얼마전 Neurips2022 에 accept 되었다. VICReg 는 contrastive learning loss 와 non-contrastive loss 을 동시에 계산해 weighted sum 하여 모델의 collapse 를 방지하고자 하였다. 본 연구에서는 VICReg의 loss 를 사용하되, 중간 단계에서 local property 를 활용하고자 feature map 을 활용해 local criterion 을 추가하여, local view 가 중요한 segmentation task 에서 state-of-the-art 성능을 기록하고, coefficient 에 따른 trade-off 를 관찰하였다.
Introduction
최근 self-supervised learning 방식은 image augmentation 을 통해 생성된 different view 의 image 를, joint embedding architecture 와 loss function 로 global feature 를 학습한다. semantic segmentation 과 같은, spatial information 이 중요한 역할을 하는 task 에서는, local image structure 도 focus 한다.
small parts of image 를 묘사하는 local feature 를 배우기 위한 방법으로는 다음과 같이 세 개로 나눌 수 있다.
- pixel level, which forces consistency between pixels at similar location
- feature map level, which forces consistency between groups of pixels
- image region level, which forces consistency between large regions that overlap in different views
핵심은, forces consistency, 비슷하게 생각할 것은 비슷하게 처리하도록 명령하고, 다르게 생각할 것은 다르게 처리하도록 명령하는 것이다. VICRegL 는 feature map level 에서, pixel space 상 가까이 있는 대상들뿐만 아니라, 멀리 떨어져 있는 object 간 고려할 수 있는 아키텍쳐를 제안한다.
Method
Background
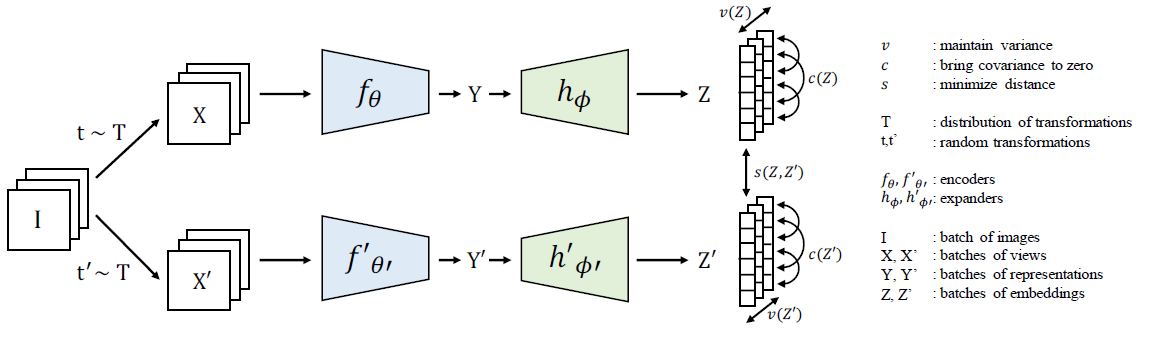
VICReg 는 variance term, invariance term, covariance term 을 활용한 self-supervised learning 이다. variance term 은 embedding vector 간의 variance 를 특정 standard deviation 아래로 떨어지지 않도록 hinge loss 를 사용한다. invariance term 은 l2 loss 를 이용해 Siamese architecture 의 두 branch 로부터 나온 feature 간의 거리를 계산한다. covariance term 은 embedding vectoro 의 covariance matrix 의 off-diagnoal term 을 0으로 보냄으로써, different dimension 을 decorrelate 하는 역할을 수행한다.
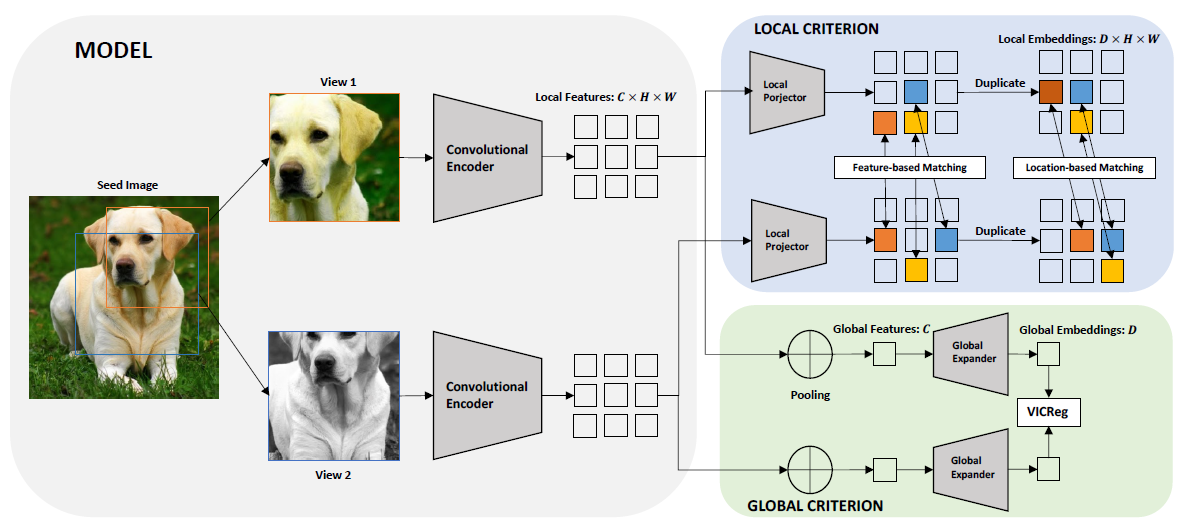
VICRegL: feature vectors matching
위 그려진 VICReg 의 구조를 보면, y 가 그대로 global expander 를 통과해 특정 dimension (D) 로 mapping 된다. VICRegL 은 VICReg 의 global expander와 loss 를 그대로 사용하되, local feature 를 학습하기 위한 새로운 경로를 도입한다. seed image x 가 convolutional encoder 를 통과한 feature map (C x H x W) 을 y, x'의 feature map (C x H x W) 의 feature map 을 y' 이라 하자. 이 때, 는 C dimension 을 가진, 즉 H x W grid 상 한 점이라고 하자. 이 논문의 핵심은 이 와 를 적절히 match 시켜 VICreg 의 criterion 을 적용하는 것이다. 그 전에, y 와 y' 을 local projector 를 통해 (D x H x W) dimension 을 가진 z 와 z' 를 만들고, y 와 y' 의 정보 & z 와 z'의 정보로 어떤 와 을 매치해서 계산할지 결정 짓는 것이다. 앞서 언급했듯이 matching 과정은, feature map 상 실제 거리를 고려한 location-based matching 과, 멀리 떨어져 있어도 같은 object 인 small part 도 고려하기 위한 feature-based matching 로 구성된다.
Location-based matching
image I 에 대해 두 view x, x' 의 similar location 으로부터 나온 feature 를 match 시켜 VICReg criterion 을 적용한다. 먼저 absolute position in I 에 따라, each feature vector at position p 는, its spatial nearest neighbor 과 match 된다 (1:1 match). 그리고 계산된 H x W pairs 중 only top- 개의 pairs 만 keep 된다.
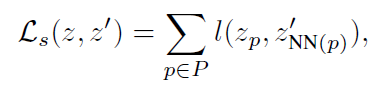
이때, P 는 H x W 상의 점 하나를 의미하고, 는 p에 따라 결정되는 spatially closest coordinate p' 를 의미한다. (위 식에는 top-에 대한 정보는 생략되어 있다.)
Feature-based matching
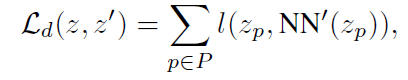
Feature-based matching 을 위해, embedding space 에서의 l2-distance 정보를 이용한다. feature vector 에 대해, feature map z' 에서, l2 distance 가 가장 작은 feature vector NN'() 와 matching 하여 VICReg criterion 을 적용한다. 이를 통해, same location 에서 pooled 된 feature 가 아니더라도, long-range interaction 을 capture 할 수 있다.
General idea of top- filtering 은 1) location-based filtering 에서 너무 멀리 떨어져 있는 feature vector 간의 mismatch 막기 위함이 있고, 무엇보다도 2) training 의 초기 단계에서, feature-based matching 과정에서 다른 texture 나 다른 object 간의 mismatch 를 막기 위함이다. (나중에 gamma 를 바꿔가며 실험함.) 또한, location-based matching 의 경우, two view 가 겹치지 않을 수 있는데, 이는 확률이 낮고 관련 실험도 진행했을 때, 성능에 큰 영향을 주지 않았음도 언급하였다.
Final loss function
최종 loss term 은 location-based & feature-based loss function 을 combination 한 것과, global view 에 VICReg criterion 을 적용한 loss function 을 한 번 더 alpha 라는 coefficient 로 combination 한 형태를 띈다.
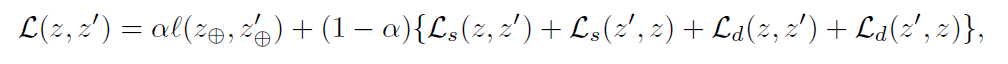
VICRegL with the ConvNeXt backbone
이번 논문에서 ResNet-50 backbone 을 사용한 experimental result 도 보고 했지만, 다른 backbone 을 활용해서도 실험했고 성능이 향상되었음을 확인하였다. 2022년 제안된 ConvNeXt architecture 를 활용하여 state-of-the-art 성능을 확인하였고, 이는 self-supervised learning 에서 ConvNeXt 를 사용한 첫 시도라고 언급하고 있다.
또한 Swav 논문에서 제안되어 사용되고 있는 multi-crop strategy 도 사용하였다. 간단히 언급하면, 기존 contrastive loss 는 두 개의 different view 들로부터 계산하지만, multi-crop strategy 는 N 개의 different view 들로부터 loss 를 계산한다. 구체적으로, 2개의 large crop 과 N-2 개의 small crop 을 사용하고, large image 만을 pivot 삼아 large-small (또는 large-large) view 간의 비교를 통해 computational efficient 와 performance importance 두 측면의 trade-off 를 최소화 하는 방식이다. 말로만 하면 이해가 안될테니 식으로 보면 다음과 같다. (=20, =4)
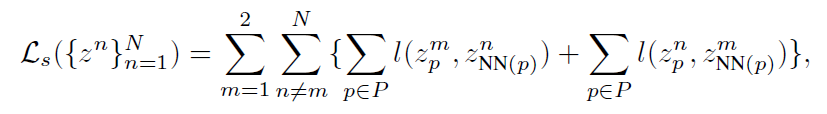
m 은 large crop image, n 은 small crop image 를 의미한다. 원래 N 개의 different view 를 사용하면, 번의 비교를 거쳐야 하지만, 다음과 같은 방식을 사용하면 번의 computation 만 거치면 된다. location-based matching loss 이외에도 feature-based matching loss 와 기존 global loss 에도 비슷하게 적용된다.
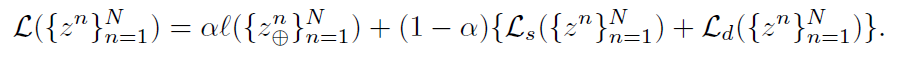
Implementation details
- best ResNet-50, ConvNeXts
- pretrained on the 100-class unlabeled ImageNet dataset
- most hyperparameter unchanged, Bardes et al., 2022
- VICReg criterion coefficient ratio 25:25:1
- global expander is 3-layers fully-connected network (2048-8192-8192-8192)
- local projector, due to memory limitation, small (2048-512-512-512)
- GPU: Nvidia Tesla V100-32Gb GPU, R50:32(2048), Cs:8(384), Cb:16(572)
Experimental Results
다양한 조건을 바꿔가며 실험하였다. main observation 으로, VICRegL 은 strongly improves on segmentation results over VICReg 와 동시에, preserving classification performance 였다.
Comparision with prior work
ResNet-50 Backbone
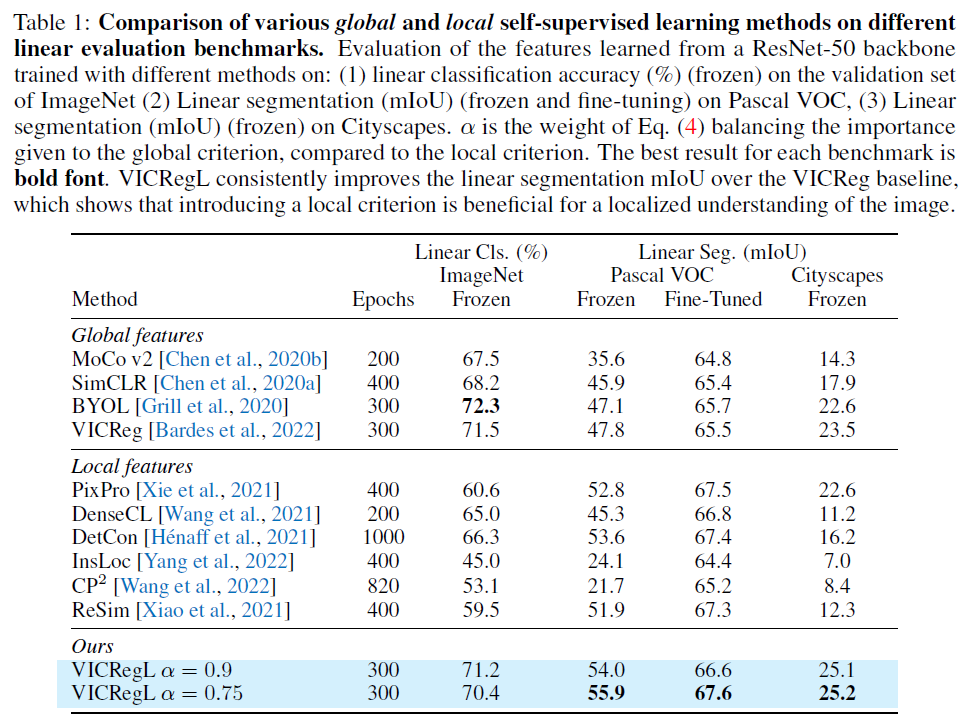
made improvement of VICRegL over VICReg on linear segmentation, cityscape 는 대부분 성능 안좋음, global feature 와 local feature 를 동시에 사용한 것에 기인한 robustness.
ConvNeXt Backbone
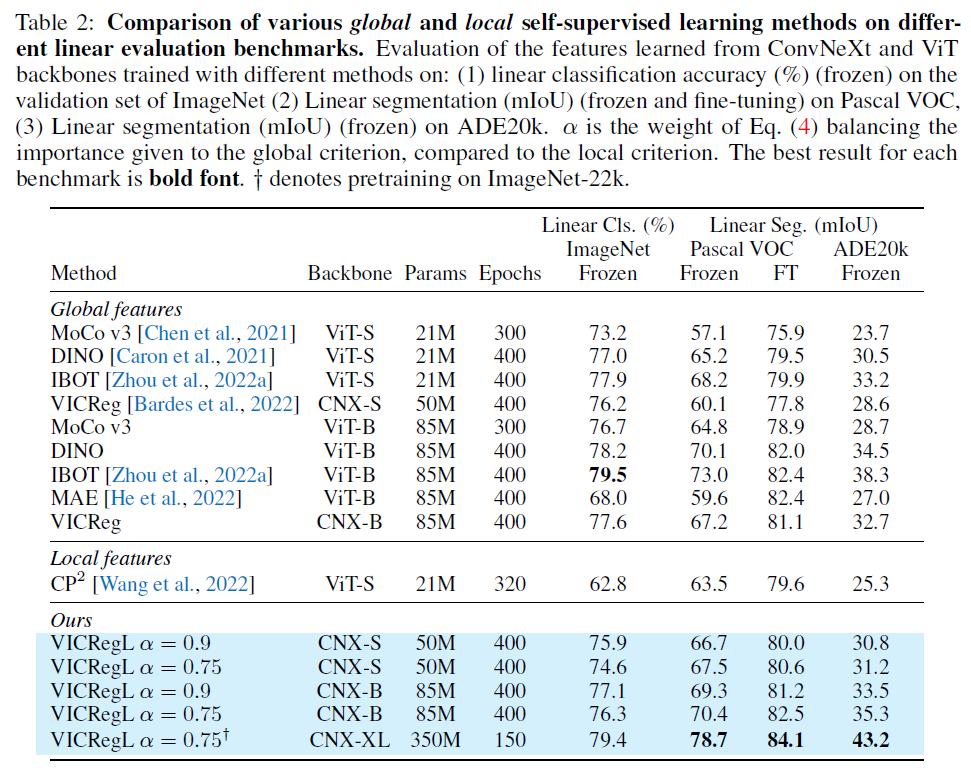
linear segmentation task 에서, CNX-XL 을 사용했을 때 state-of-the-art 달성
alpha 값에 따른 classification / segmentation performance trade-off
Ablations
CNX-S ImageNet over 100 epoch 결과로 통일. linear classification 및 linear frozen segmentation mIOU 각각 ImageNet 과 Pascal VOC 에서 측정
Trade-off between the local and global criterion

alpha<1 을 적용했을 때, segmentation performance is greatly increased
existence of a sweet spot, where the model performs both tasks
Study of the importance between feature-based and location-based local criteria
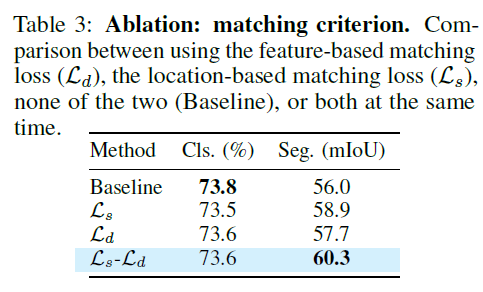
두 component 가 함께 할 때 classification performance 방어와 segmentation performance improvement 면에서 의미가 있음.
Study of the number of matches
multicrop 을 사용하면, large view와 small view 가 만들어지고 그에 따른 feature map 크기도 (7x7), (3x3) 으로 달라진다. 이에 따라 top- 의 gamma1, gamma2 를 나누었고 이 값들을 달리하여 실험을 진행하였음.
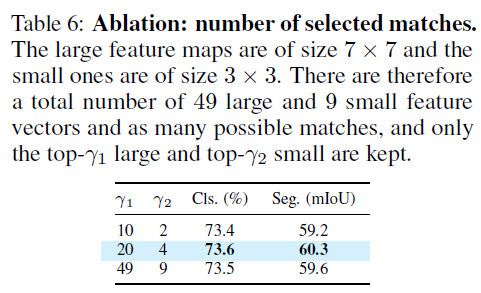
최소한으로 줄이거나 최대로 늘렸을 때도 성능이 괜찮았지만, between 값을 했을 때 가장 좋음.
Study of VICReg components for the local criterion, Multi-crop strategy
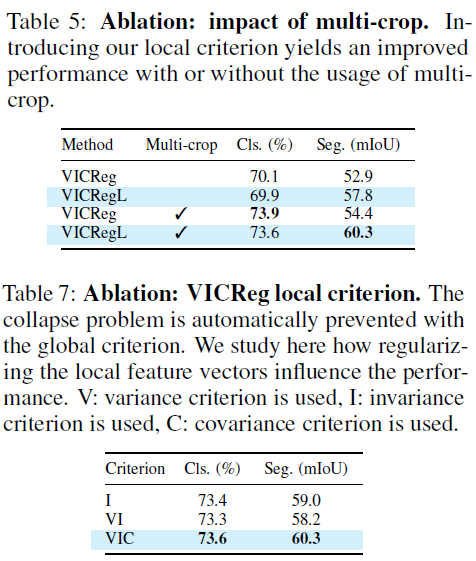
SimCLR + local feature network
local feature network 에서 사용하던 VICReg criterion 대신 SimCLR loss 를 적용함.
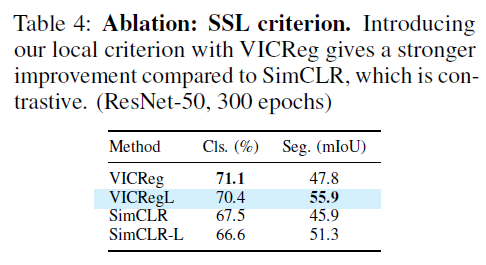
SimCLR 보다 SimCLR-L 에서 additional benefit 이 확인되었고, VICReg와 VICRegL 사이의 additional benefit 의 폭이, SimCLR의 그것보다 더 컸음.
Visualization

왼쪽 column 의 빨강파랑은 feature-based matching, 오른쪽 colum 의 빨강 파랑은 location-based matching 을 의미한다. 실험 상 20개의 best match 를 골랐지만 여기는 visualziation 을 위해 몇개를 생략하였다. 또한, 노란 선은 matching 된 pair 를 의미하고, grid 로 나누었지만 실제 receptive field 는 훨씬 크다.
비오는 날엔 카페에서 논문 리뷰... 집중 잘된다 히히
