https://github.com/mlfoundations/open_clip
모델 불러오기
주의!
OpenCLIP은 기존 CLIP과 다른 라이브러리를 사용한다.
( pip install open_clip_torch )
import torch
import open_clip
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32')
state_dict = torch.load('path_to_pretrained_weight', map_location=device)
model.load_state_dict(state_dict['CLIP'])
model.to(device)
tokenizer = open_clip.get_tokenizer('ViT-B-32')state_dict: 모델의 가중치 및 파라미터를 담고 있는 dict타입 데이터. 학습된 모델을 저장하거나 로드할 때 사용된다. 여기서는 미리 저장된 가중치를 불러왔다.
tokenizer: 텍스트를 모델 입력에 맞게 토큰화하여 벡터로 변환하는 도구. 각 모델에 맞는 토크나이저를 사용해야한다.
preprocess: 이미지 데이터를 전처리하는 함수로 마찬가지로 모델이 요구하는 방식의 전처리기를 사용해야한다.
데이터 준비
커스텀 데이터셋 정의
from PIL import Image
from datasets import load_dataset
from torch.utils.data import Dataset
ds = load_dataset("tomytjandra/h-and-m-fashion-caption")
class HMFashionDataset(Dataset):
def __init__(self, dataset_split, preprocess):
self.dataset = dataset_split
self.preprocess = preprocess
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
item = self.dataset[idx]
# 이미지 데이터 가져오기
image = item['image']
if isinstance(image, Image.Image):
image = image.convert('RGB')
else:
image = Image.open(image).convert('RGB')
image = self.preprocess(image)
caption = item['text']
return image, caption # 텍스트를 문자열로 반환load_dataset: datasets 라이브러리의 함수로, 다양한 공개 데이터를 쉽게 불러올 수 있다. 여기서는 H&M 패션 이미지 - 캡션 데이터를 활용하였다.
Dataset 클래스: PyTorch에서 사용자 정의 데이터셋을 만들기 위해 상속하는 클래스로, len과 getitem 메서드를 통해 데이터셋을 정의하게 된다.
데이터 로더 설정
import torch
from torch.utils.data import DataLoader
import datasets
import random
prompts = [
'a photo of a {}',
'a fashion photo of a {}',
]
def collate_fn(batch):
images, captions = zip(*batch)
images = torch.stack(images)
prompted_captions = []
for caption in captions:
prompt = random.choice(prompts)
prompted_captions.append(prompt.format(caption))
texts = tokenizer(prompted_captions)
return images, texts
print(ds)
if isinstance(ds, datasets.DatasetDict):
if 'train' in ds:
# ds['train']을 훈련용과 테스트용으로 분할
split_ds = ds['train'].train_test_split(test_size=0.2, seed=42)
else:
raise KeyError("The dataset does not contain a 'train' split.")
else:
# ds 자체가 Dataset인 경우
split_ds = ds.train_test_split(test_size=0.2, seed=42)
# 데이터셋 스플릿
train_dataset = HMFashionDataset(split_ds['train'], preprocess)
test_dataset = HMFashionDataset(split_ds['test'], preprocess)
train_dataloader = DataLoader(
train_dataset,
batch_size=512,
shuffle=True,
num_workers=0,
collate_fn=collate_fn
)
test_dataloader = DataLoader(
test_dataset,
batch_size=512,
shuffle=False,
num_workers=0,
collate_fn=collate_fn
)prompts: 텍스트 입력을 생성하기 위해 사용되는 미리 정의된 프롬프트로, 주로 ‘a photo of {}’를 사용하지만 데이터셋의 특징에 따라서 다르게 설정할 수도 있다.
collate_fn: 데이터로더의 각 배치에서 호출되어 데이터를 배치에 맞게 정리하는 함수로 앞서 정의한 프롬프트를 적용하거나, torch.stack를 사용하여 텐서들을 하나의 배치로 결합할 수 있다.
DataLoader: 데이터셋을 반복 가능한(iterable) 형태로 만들어주는 파이토치 유틸리티
num_workers: 병렬 데이터 로딩을 위한 프로세스 수를 설정하는 옵션
모델 학습
하이퍼 파라미터 설정
import torch
import torch.nn.functional as F
from torch.amp import GradScaler
from tqdm import tqdm
# 손실 함수 정의 (CLIP의 대조적 손실 함수)
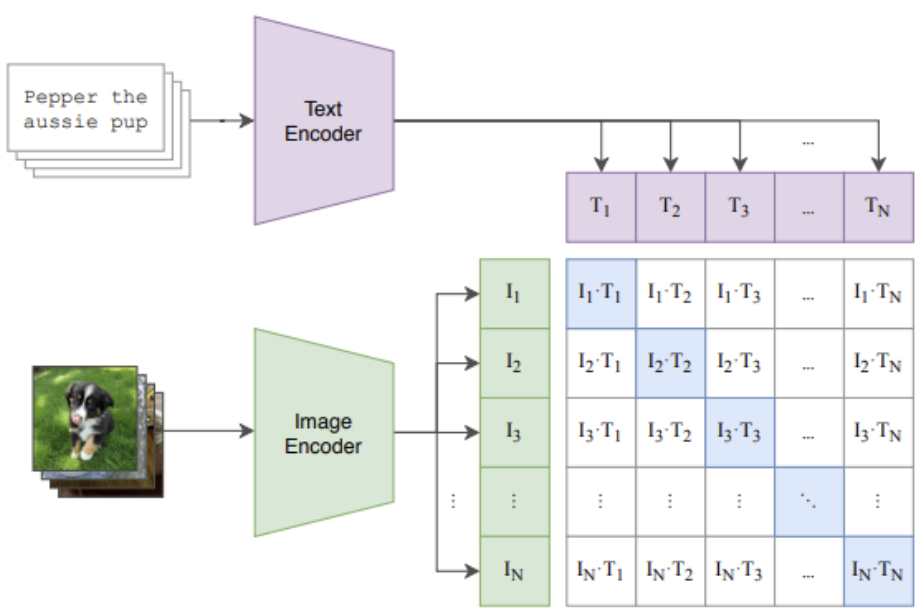
def clip_loss(logits_per_image, logits_per_text):
batch_size = logits_per_image.size(0)
labels = torch.arange(batch_size, dtype=torch.long, device=logits_per_image.device)
loss_i = F.cross_entropy(logits_per_image, labels)
loss_t = F.cross_entropy(logits_per_text, labels)
return (loss_i + loss_t) / 2
# visual encoder 파라미터만 학습 가능하도록 설정
for param in model.parameters():
param.requires_grad = False # 모든 파라미터를 고정
for param in model.image_encoder.parameters(): # visual encoder 파라미터만 학습 가능
param.requires_grad = True
# 학습 가능한 파라미터만 필터링하여 전달
optimizer = torch.optim.AdamW(
filter(lambda p: p.requires_grad, model.parameters()),
lr=5e-6,
betas=(0.9, 0.98),
eps=1e-6,
weight_decay=0.2
)
# 스케일러 정의
scaler = GradScaler()
# 에포크 수 및 total_steps 계산
epochs = 10
total_steps = epochs * len(train_dataloader)
# 스케줄러 정의
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=total_steps)torch.arange: 일정 범위의 정수 배열을 생성하는 함수로, 라벨 생성에 사용된다.
AdamW: AdamW는 학습률을 조정하며 가중치 감쇠를 적용하는 Adam의 변형 옵티마이저를 말한다. 대안으로 SGD, Adam, RMSprop 등이 있으며, 모델의 특성과 학습 속도에 따라 다른 옵티마이저를 사용할 수 있다.
optimizer 정리글
lr, betas, eps, weight_decay: AdamW 옵티마이저의 하이퍼파라미터. lr은 학습률, betas는 모멘텀, eps는 수치적 안정성을 위한 작은 값, weight_decay는 과적합 방지를 위한 L2 정규화를 나타낸다.
GradScaler: Mixed Precision 학습에서 손실 스케일링 적용
Auto Mixed Precision
scheduler: 학습률을 점진적으로 감소시키는 역할
학습
from tqdm import tqdm
model.train()
for epoch in range(epochs):
progress_bar = tqdm(train_dataloader, desc=f"Epoch {epoch+1}/{epochs}")
for batch in progress_bar:
images, texts = batch
images = images.to(device)
texts = texts.to(device)
optimizer.zero_grad()
with torch.autocast(device_type='cuda', dtype=torch.float16):
# 이미지와 텍스트 임베딩 추출
image_features = model.encode_image(images)
text_features = model.encode_text(texts)
# 임베딩 정규화
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# 유사도 계산
logit_scale = model.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# 손실 함수 계산
loss = clip_loss(logits_per_image, logits_per_text)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step() # 각 배치마다 호출
progress_bar.set_postfix(loss=loss.item())임베딩 정규화: 정규화는 벡터의 크기가 1이 되도록 벡터를 스케일링하여 임베딩 간에 비교할 때 크기가 아닌 방향만을 고려하게 하는 역할을 한다.
logit_scale: 모델에 포함된 logit_scale 파라미터를 지수 함수로 변환하여 이미지와 텍스트 임베딩 사이의 유사도 분포를 조절하여 학습의 안정성을 높이고 성능을 향상 시키는 역할을 한다.
tqdm: 진행 상황 표시바를 보여주는 라이브러리로, 반복문이 실행될 때 진행률을 아래처럼 확인할 수 잇게 해준다.

