Apache Spark 를 쓰는 이유
속도
하둡
- Mapreduce 연산은 디스크 기반 I/O 중심
- 매 단계마다 파일 시스템 I/O 호출 발생 디스크(HDFS)에 기록. OS는 디스크 접근 시 페이지 캐시, 버퍼 캐시를 이용하지만 여전히 느림. 장애 발생시 중간 결과로 복구 가능
- I/O 병목이 성능의 주요 제약이 됨. 즉, OS의 디스크 접근 방식에 의존도가 크고, 전체 워크플로우의 병목 요인이 되는 구조
스파크
- 메모리 기반 인메모리 처리
- 연산의 중간 결과들을 RDD(Resilient Distributed Dataset)에 메모리에 유지 -> 훨씬 더 빠른 속도로 같은 작업 수행
- 장애 발생시 lineage(계산 재시작)
- 질의 연산을 방향성 비순환 그래프 (DAG)로 구성. DAG의 스케쥴러와 질의 최적화 모듈은, 효율적인 연산 그래프를 만들고 각각의 태스크로 분해하여 클러스터의 워커 노드 위에서 병렬 실행될 수 있도록 함
- 물리적 실행 엔진인 텅스텐은 전체 코드 생성 기법을 사용해, 실행을 위한 간결한 코드를 생성 링크
- 즉, Spark는 OS 메모리 리소스를 적극적으로 사용하는 구조라서, 메모리 용량, GC 정책, NUMA 구조 등이 성능에 큰 영향을 미침
사용 편리성
- 클라이언트 입장에서 스파크 코드가 단일 pc 혹은 분산 환경에서 실행되는지 구별하기 어려울 정도로 추상화가 잘 되어 잇음
- Dataframe, Dataset과 같은 고수준 데이터 추상화 계층 아래에 RDD라 불리는 단순한 자료구조를 구축해 단순성을 실현
- 연산의 종류로 transformation과 action의 집합과 단순한 프로그래밍 모델을 제공
모듈성
- 스파크 내의 다양한 컴포넌트(SparkSQL, Structured Streaming, MLlib 등) 사용하여 다양한 타입의 워크로드에 적용이 가능
- 특정 워크로드를 처리하기 위해 하나의 통합된 처리 엔진을 가짐
- Mapreduce 의 경우, 배치 워크로드에는 적합하나 SQL 질의, 스트리밍, 머신러닝 등 다른 워크로드와 연계해 사용하기 어려움
- 이런 워크로드를 다루기 위해 엔지니어들은 하둡과 함께, Apache Hive(SQL질의), Strom(스트리밍), Mahout(머신러닝) 등 다른 시스템과의 연동이 필요
확장성
- 저장과 연산을 모두 포함하는 하둡과 달리, 스파크는 병렬 연산 초점
- 수 많은 데이터 소스(Hadoop, Cassandra, Hbase, 몽고DB, AWS S3 등) 로부터 데이터를 읽어 들일 수 있음
- 여러 파일 포맷 (txt,csv,parquet, roc, hdfs)과 호환 가능
- 이외의 많은 서드파티 패키지 목록 사용 가능
Apache Spark가 빠른 이유(처리 방식)
✅ 디스크 I/O vs 메모리 I/O
항목 디스크 (HDD/SSD) 메모리 (RAM) 역할 영구적인 데이터 저장 일시적인 데이터 저장 휘발성 여부 비휘발성 (전원 꺼져도 데이터 유지) 휘발성 (전원 꺼지면 데이터 소실) 속도 느림 (특히 HDD는 기계식 I/O), SSD는 그보다 빠름 매우 빠름 (CPU와 직접 연결) 저장 방식 HDD: 자기 디스크, SSD: 플래시 메모리 전기적 신호 가격 상대적으로 저렴함 용량 대비 고가 용량 수백 GB ~ 수 TB (대용량 가능) 수 GB ~ 수십 GB (제한적) 접근 방식 순차 접근에 최적, 랜덤 접근은 SSD가 유리 랜덤 접근 최적 사용 예시 파일 저장, DB, OS, 앱 설치 등 실행 중인 프로그램, 캐시, 세션, 버퍼 등 캐싱 활용 자주 접근되는 데이터를 메모리에 올려 속도 개선 디스크보다 빠르기 때문에 캐시로 주로 사용됨 장점 영구 저장 가능, 대용량 저장 빠른 속도, 실시간 처리 적합 단점 느린 속도, I/O 병목 가능성 휘발성, 저장 한계, 비용
Spark 데이터 구조
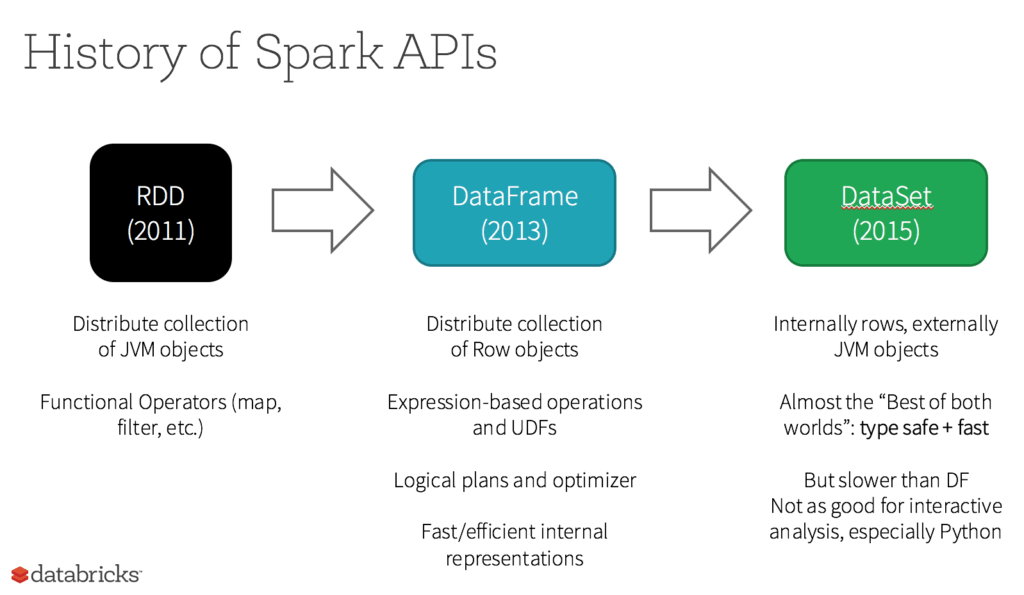
스파크의 데이터 구조는 크게 RDD -> Dataframe -> Dataset 으로 나눌 수 있다.
Spark Cluster 작동 방식
Spark Cluster 란?
스파크 클러스터는 여러 대의 컴퓨터(노드)를 묶어 대규모 데이터를 병렬로 처리할 수 있도록 구성된 시스템. 이 클러스터는 하나의 마스터(Master) 노드와 여러 개의 워커(Worker) 노드로 구성
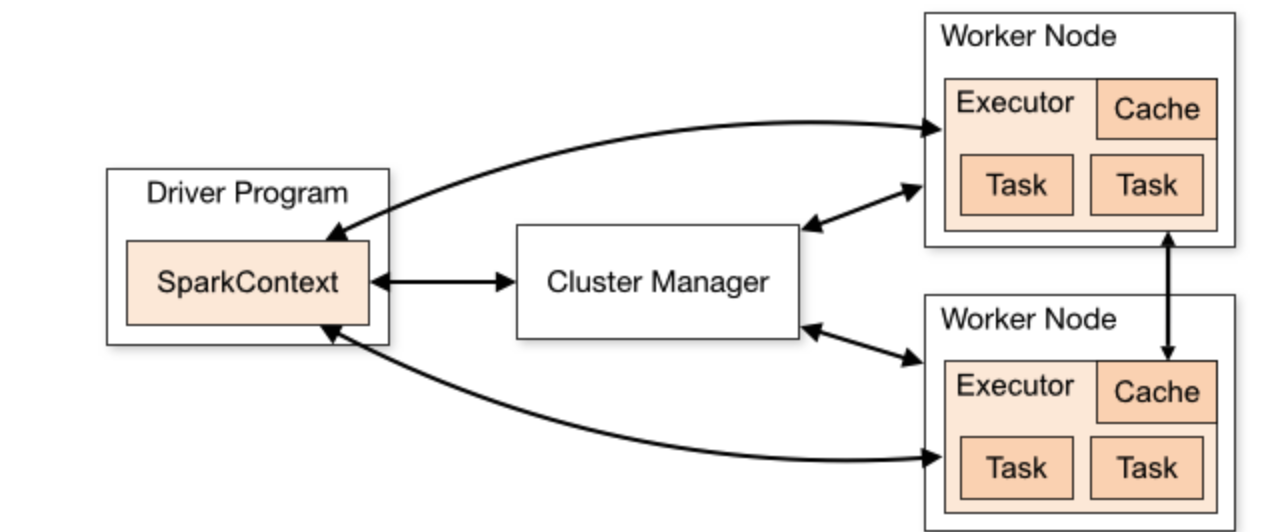
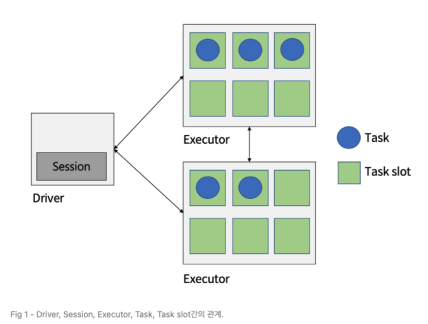
1. 클러스터 관리자(Cluster Manager)
전체 애플리케이션의 컴퓨팅 자원 즉, 리소스 관리(CPU, 메모리 등)하고, 스파크 애플리케이션이 요청하는 자원을 할당
- 종류 : Standalone, Apache Mesos, Hadoop Yarn, Kubernetes
- 예시
- 드라이버가 요청한 실행기 프로세스 시작
- 실행 중인 프로세스를 중지하거나 재시작
- 실행자 프로세스가 사용할 수 있는 최대 CPU 코어 갯수 제한
- 노드 관리 : 클러스터에 참여하는 워커 노드들을 관리하고 상태를 모니터링
2. 드라이버 노드(Dirver Node)
전체 애플리케이션의 실행을 조율하고 관리 전체 데이터를 수집하거나 매우 큰 객체를 저장하려고 하면 OOM 발생. 따라서 드라이버 노드에서는 주로 집계된 결과나 메타데이터를 처리하는 것이 일반적
- 1개의 스파크 애플리케이션에는 1개의 드라이버 존재
- 드라이버 프로세스가 어디에 있는지에 따라, 스파크에는 크게 두 가지 모드가 존재
- 클러스터 모드 : 드라이버가 클러스터 내의 특정 노드에 존재
- 클라이언트 모드 : 드라이버가 클러스터 외부에 존재
- 예시
- 클러스터 매니저에 메모리 및 CPU 리소스를 요청
- 애플리케이션 로직을 스테이지와 태스크로 분할
- 여러 실행자에 태스크를 전달
- 태스크 실행 결과 수집
클러스터 모드 vs 클라이언트 모드 (Driver 위치 차이)
🎯 언제 어떤 모드를 쓰나?
- 클러스터 모드 : 대규모 프로덕션 배치 처리, 자동화 스케줄링 (Airflow 등)
- 클라이언트 모드 : 분석가가 로컬에서 테스트, 디버깅할 때 유리
- 애플리케이션 관리자 : 사용자가 작성한 스파크 애플리케이션의 메인 함수가 실행되는 곳
- SparkContext : 스파크 애플리케이션의 진입점(Entry Point) 역할을 하며, 클러스터 관리자와 통신하여 자원을 요청하고 작업 조율
- DAG Scheduler : 사용자의 코드를 논리적인 DAG로 변환
- 메모리 및 상태 관리 : 애플리케이션의 상태와 필요한 정보를 관리
3. 실행기(Executor)
스파크 드라이버가 요청한 태스크들을 받아서 실행하고 그 결과를 드라이버로 반환.
- JVM 프로세스
- 각 프로세스는 드라이버가 요청한 태스크들을 여러 태스크 슬롯(스레드)에서 병렬로 실행
4. 스파크세션(Spark Session)
스파크 코어 기능들과 상호 작용할 수 있는 진입점 제공. 그 API로 프로그래밍을 할 수 있게 해주는 객체
- spark-shell 에서는 기본적으로 제공
- 스파크 애플리케이션에서는 사용자가 SparkSession 객체를 생성해 사용해야함
5. 잡(Job)
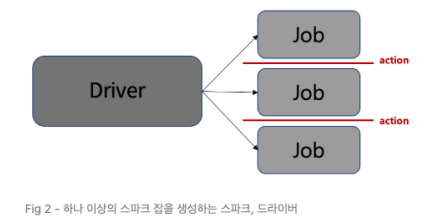
스파크 액션(save(), collect()) 에 대한 응답으로 생성되는 여러 태스크로 이루어진 병렬 연산
- 액션이 실제로 수행이 되어야, 액션 이전의 transformation 들이 수행이 됨
6. 스테이지(Stage)
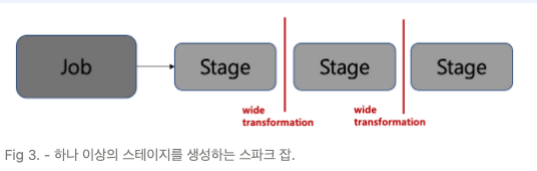
스파크 각 잡(Job)은 스테이지라 불리는 서로 의존성을 가지는 다수의 태스크 모음으로 나뉨
- 스테이지를 나누는 기준은 Wide transformation, narrow transformation 이 있음
7. 태스크(Task)
- 스파크 각 잡(Job)별 실행기로 보내지는 작업 할당의 가장 기본적인 단위
- 개별 task slot에 할당 되고, 데이터의 개별 파티션을 가지고 작업
- 한 개의 테스크가 기본적으로 한 개의 파티션을 가지고 어떠한 transformation 작업을 수행함
워커 노드(Worker Node)
- 실제 데이터 처리 : 클러스터의 각 워커 노드는 할당받은 데이터 파티션에 대해 실제 연산 수행
- Executor : 각 워커 노드는 할당받은 데이터 파티션에 대해 실제 연산을 수행
- 데이터 저장(선택사항) : 워커 노드는 처리할 데이터의 일부를 로컬 디스크나 메모리에 저장
✅ 워커 노드는 실제로 데이터를 분산 처리하는 작업자 역할.
Spark 연산 방식
Transformation
- Immutable(불변)의 원본 데이터를 수정하지 않고, 하나의 RDD나 Dataframe 을 새로운 RDD나 Datagrame으로 변형
- (input, output)타입 : (RDD, RDD), (DF, DF) 인 연산
- ex) map(), filter(), flatMap(), select(), groupby(), orderby()
- Narrow, Wide 두 종류가 존재
Narrow Transformation
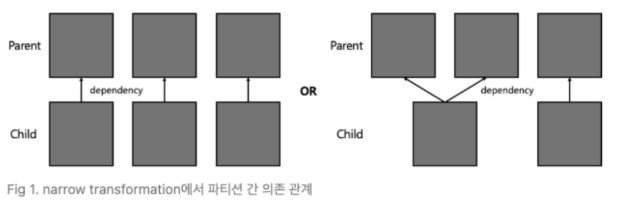
-
input(1개 파티션), output(1개 파티션)
-
파티션 간의 데이터 교환이 발생하지 않음
-
filter(), map(), coalesce()
-
이전 RDD의 단일 파티션 -> 새로운 RDD의 단일 파티션으로 연결
-
셔플(Shuffle)이 없음
-
따라서 같은 Stage 안에서 실행
rdd = sc.parallelize([1,2,3,4])
mapped = rdd.map(lamda x: x * 2) #narrow
riltered = mapped.filter(lamda x: x > 4) #narrow
# map과 filtered 는 같은 파티션에 대해 작동하므로 하나의 Stage로 묶임Wide Transformation

- 연산 시 파티션끼리 데이터 교환 발생
- groupby(), orderby(), sortByKey(), reduceByKey()
- 단, join의 경우 두 부모 RDD/Dataframe 이 어떻게 파티셔닝 되어 있냐에 따라 narrow일 수도, wide일 수도 있음
- 하나의 파티션 -> 여러 파티션으로 데이터 재분배
- 셔플 발생
- 새로운 Stage로 분리됨 (Stage 경계 발생)
Action
- Immutable(불변)인 인풋에 대해, side effect(부수 효과)를 포함하고, 아웃풋이 RDD 혹은 Dataframe이 아닌 연산
- count() -> int
- collect() -> array
- save() -> void
Lazy evaluation (추가 개념)
- 모든 transformation은 즉시 계산되지 않고 lineage라 불리는 형태로 기록
- transformation이 실제 계산되는 시점은 action이 실행되는 시점
- action이 실행될 때, 그 전까지 기록된 모든 transformation들의 지연 연산이 수행됨
장점
- 스파크가 연산 쿼리를 분석하고, 어디를 최적화할지 파악하여, 실행 계획 최적화가 가능(eager evaluation이라면, 즉시 연산이 수행되기 때문에 최적화의 여지가 없음)
- 장애에 대한 데이터 내구성 제공
- 장애 발생 시, 스파크는 기록된 lineage를 재실행 하는 것만으로 원래 상태를 재생성 할 수 있음
Executor 수, 코어 수, 메모리 최적 설정법
Spark 자원 설정은 작업의 특성 + 클러스터 스펙에 따라 다르지만, 실무에서 쓰이는 튜닝 전략은 매우 중요하다.
용어 정리
- num-executors : Executor 의 총 갯수
- executor-cores : Executor 당 사용 가능한 CPU 코어수
- executor-memory : Executor당 할당되는 메모리 양
설정 전략
일반적으로 Executor는 여러 서버(노드)에 분선해서 실행되며, 하나의 서버에 하나 이상의 Executor가 올라갈 수 있음
- 하나의 서버에 여러 Executor 배치
- 서버에 자원이 많고 여러 잡(Job)을 동시에 실행시킴
- 32코어 머신 -> Executor 2개, 각 16코어씩
- 여러 서버에 Executor 하나씩 배치 후 클러스터링
- 분산 처리 효과 극대화
- 서버 간 데이터 로컬리티 고려하여 shuffle 비용 감소
shuffle 이란, 데이터가 파티션 간에 재분배되는 과정. 특히 groupby, join, reduceByKey 같은 transformation이 발생할 때, 동일 key끼리 묶기 위해 서로 다른 파티션 간의 데이터가 이동됨.
- 네트워크 I/O, 데이터가 서로 다른 서버/Executor 간에 전송되면 속도 저하
- 디스크 I/O, 중간 데이터를 디스크에 저장 후 다시 로드할 수도 있음
- 메모리 pressure, 버퍼링 중 GC 발생 가능성
즉, 한 서버에 Executor가 몰려 있으면 외부로 전송해야 하므로 Shuffle 비용 증가. 여러 서버에 분산되어 있다면, 자기 로컬 디스크/메모리에서 처리할 수 있어 비용 감소
클러스터 : 16코어, 64GB RAM 일 때
총 4개 Executor 4 코어씩
14GB 4 = 56GB 사용
Job (saveAsTextFile)
├── Stage 1 (flatMap + map)
│ ├── Task 0 on Partition 0
│ ├── Task 1 on Partition 1
│ └── ...
└── Stage 2 (reduceByKey → Shuffle 발생)
├── Task 0 (aggregates all "a" keys)
├── Task 1 (aggregates all "b" keys)
└── ...예시
예를 들어 100GB의 로그 파일을 16개의 파티션으로 나누면 → 4대 서버에서 각각 4개의 Task가 동시에 실행
1단계 : 100GB 로그 파일 -> 16개 파티션으로 나눔
2단계 : 각 파티션은 Task 1개로 매핑됨 (즉, 총 16개의 Task 생성)
3단계 : 클러스터에 4개의 서버가 있다면 -> Executor 4개에 Task 4개씩 분배
4단계 : 각 서버는 병렬로 4개 Task를 동시에 처리하며 전체 Job을 병렬 실행
-> 이 구조 덕분에 Spark는 데이터를 나누고(Task), Executor를 분산시켜 병렬 처리함으로써 대용량 데이터를 빠르게 처리할 수 있음
- Task 수 = 파티션 수
- Executor 수와 Task 수 비율은 동시 병렬 처리 수에 영향을 줌
- 각 Executor는 내부적으로 코어 수만큼 Task를 병렬 실행
Q1. 16개의 Task, 8개의 Executor -> 어떻게 분배되고 병렬성은?
- Executor 당 사용 가능한 코어 수가 2개라고 하면 각 executor는 동시에 2개의 task 실행 가능
Excutor 수 = 8개
Excutor 당 Task 슬롯 = 2개
병렬 Task 실행 수 = 16개
-> 16개의 Task 가 동시에 실행 됨 - 만약 Excutor 가 4개 고 각자 코어가 2개라면?
8개의 task는 즉시 실행되고, 나머지 8개는 대기 후 실행됨
Q2. 파티션 수가 너무 많거나 너무 적으면?
🔻 너무 적은 경우 (ex: 100GB 파일 → 파티션 4개)
- 병렬성 저하 -> CPU 코어가 많아도 할 일이 없음
- Executor 자원 활용 못함 -> 4개의 Task만 생성되니 Excutor가 놀고 있음
- 16코어인데 Task가 4개면 병렬로 4개밖에 못 돌림
🔺 너무 많은 경우 (ex: 100GB → 파티션 500개)
- Task 수 증가 -> 스케줄링 오버헤드 -> Stage 마다 Task 수가 너무 많아 관리 부담 증가
- 작은 파일 다수 생성 -> saveAsTextFile 하면 작은 파일 수백 개 생성
- Shuffle 병목 증가 -> Shuffle 시 파티션이 많으면 네트워크 비용 증가
collect()
모든 데이터를 드라이버 노드로 수집해서 리스트 형태로 반환하는 액션 함수
rdd = sc.parallelize([1, 2, 3, 4]) data = rdd.collect() print(data) #[1, 2, 3, 4]
foreach(print)
RDD의 각 요소에 대해 주어진 함수를 실행하지만, 결과는 반환하지 않음
rdd = sc.parallelize([1, 2, 3, 4]) rdd.foreach(print) # 각 워커에서 개별 출력됨
파이썬 딕셔너리 vs 스파크 Pair RDD
차이
- 데이터 저장 방식(Local vs Distributed)
- 파이썬 딕셔너리 : 단일 프로세스(단일 컴퓨터의 메모리) 내에서 데이터를 저장하고 관리. 모든 키-값 쌍이 하나의 메모리 공간에 존재
- 스파크 RDD (Spark RDD) : 스파크 RDD의 (key, value) 쌍은 여러 대의 컴퓨터(클러스터의 노드)에 분산되어 저장. 특히 키-값 쌍이 어느 노드에 저장될지는 스파크의 파티셔닝(partitioning) 전략에 따라 결정
- 연산 방식(Local vs Distributed/Parallel)
- 파이썬 딕셔너리 : 딕셔너리에 대한 연산(추가, 삭제, 검색, 업데이트)은 단일 CPU 코어에서 순차적으로 이루어짐
- 스파크 RDD의 (key,value) 쌍 (Pair RDD) : Pair RDD에 대한 연산(reduceByKey, join 등)은 스파크 클러스터의 여러 워커 노드에서 동시에 병렬로 수행. 스파크는 동일한 키를 가진 데이터를 같은 워커 노드로 모아서 처리하는 셔플(Shuffle) 과정을 통해 효율적인 분산 처리 가능
- 목적 및 활용
- 파이썬 딕셔너리 : 주로 작은 규모의 데이터셋 저장, 특정 키를 통해 빠르게 값 찾아냄.
- 스파크 RDD의 (key,value) 쌍 (Pair RDD) : 주로 대규모 분산 데이터셋에서 데이터를 효율적으로 그룹화, 집계, 조인, 정렬하는 등의 복잡한 분석 및 변환 작업을 수행하는 데 사용. 분산 환경의 특성을 최대한 활용하기 위한 패턴
파이썬 딕셔너리
my_dict = {"apple": 10, "banana": 20, "cherry": 30}
print(my_dict["banana"])
# 20스파크 Pair RDD
# 스파크 RDD는 클러스터에 분산되어 있음
# 워커 노드 1 : ('apple',10)
# 워커 노드 2 : ('banana',20)
# 워커 노드 3 : ('cherry',15)
data =[("apple", 10), ("banana", 20), ("cherry", 15), ("apple", 5)]
rdd = sc.parallelize(data) # 이 데이터를 RDD로 분산
# "apple" 키를 기준으로 값을 환산하는 reduceByKey 연산
# 스파크는 'apple' 키를 가진 데이터들을 한 워커 노드로 모아서 (셔플) 합산
result_rdd = rdd.reduceBykey(lambda x, y: x + y)
print(result_rdd.collect())
# 결과: [('apple', 15), ('banana', 20), ('cherry', 15)]