🎯목표 설정
- seaborn의
mpg데이터셋을 이용하여수치형 변수에 대해 시각화 히스토그램,displot,kdeplot,rugplot,boxplot,violinplot그려보기- 스케일링에 대해 이해하기
👩🏻💻이해 과정
목차
1.importpandas, numpy, seaborn, matplotlib.pyplot
2.load_dataset
3. seaborn 시각화
1. 데이터 로드
💡 Library
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt💡 Dataset : mpg(mile per galon)
# 앤스컴 데이터셋 불러오기 df = sns.load_dataset("mpg")# 데이터셋 구조 파악 df.shape >> (398, 9)
mpg: 행 398, 열 9 로 구성된 데이터셋
2. 데이터 구조
- 데이터가 무엇으로 구성되어있는지 확인하기
- 데이터 type 확인하기
1) 데이터 형태 확인하기
💡 데이터셋 일부만 가져오기
# 상위 5개 데이터만 불러오기 df.head()
# 하위 5개 데이터만 불러오기 df.tail()
- 열 :
mpg,cylinders,displacement,horsepower,weight,acceleration,model_year,origin,name
2) 데이터 정보 확인하기
💡 데이터셋 요약
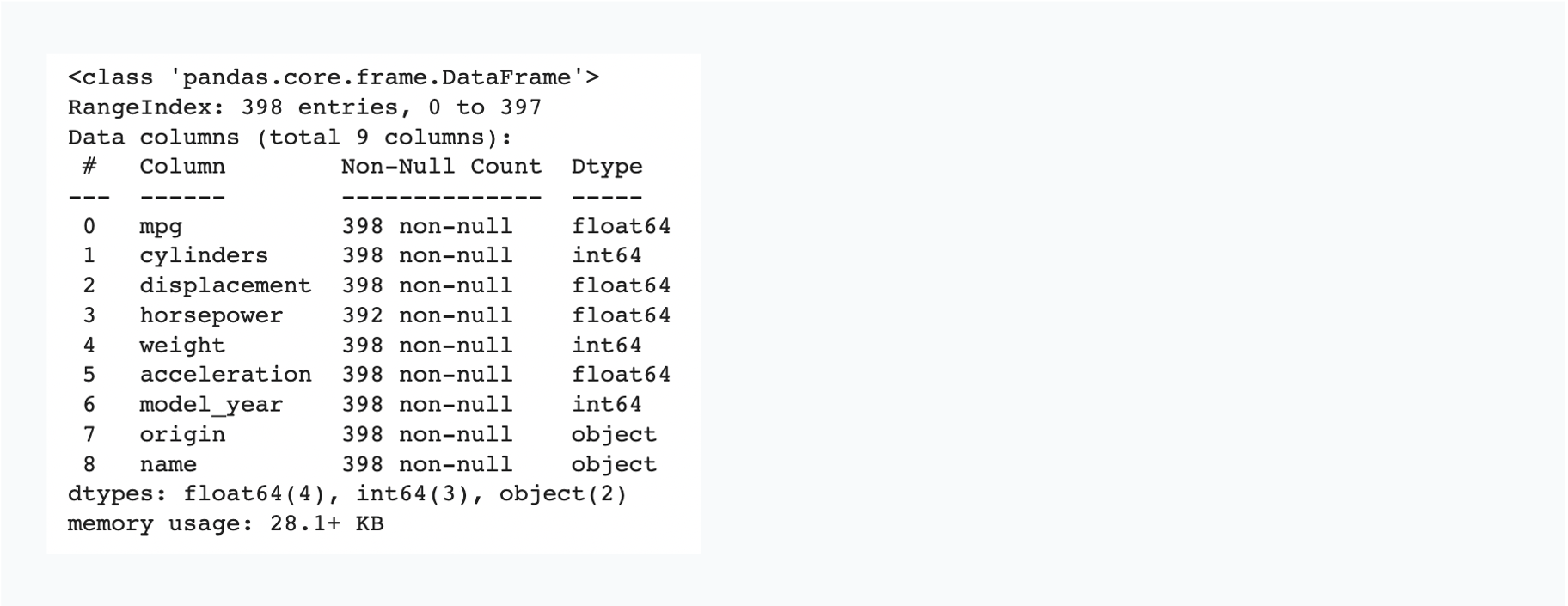
# 데이터 기본 정보 요약 df.info()
- 데이터셋은 총 398개의 데이터를 가지고 있다.
origin,name은 type이object이다.- 데이터 타입, 결측치의 유무, 메모리 사용량 등의 정보를 알 수 있다.
💡 데이터셋 결측치
# 데이터 결측치를 True, False로 확인 df.isnull()
🔥 결측치 시각화 해보기
plt.figure(figsize=(12, 8))
sns.heatmap(df.isnull(), cmap="Blues")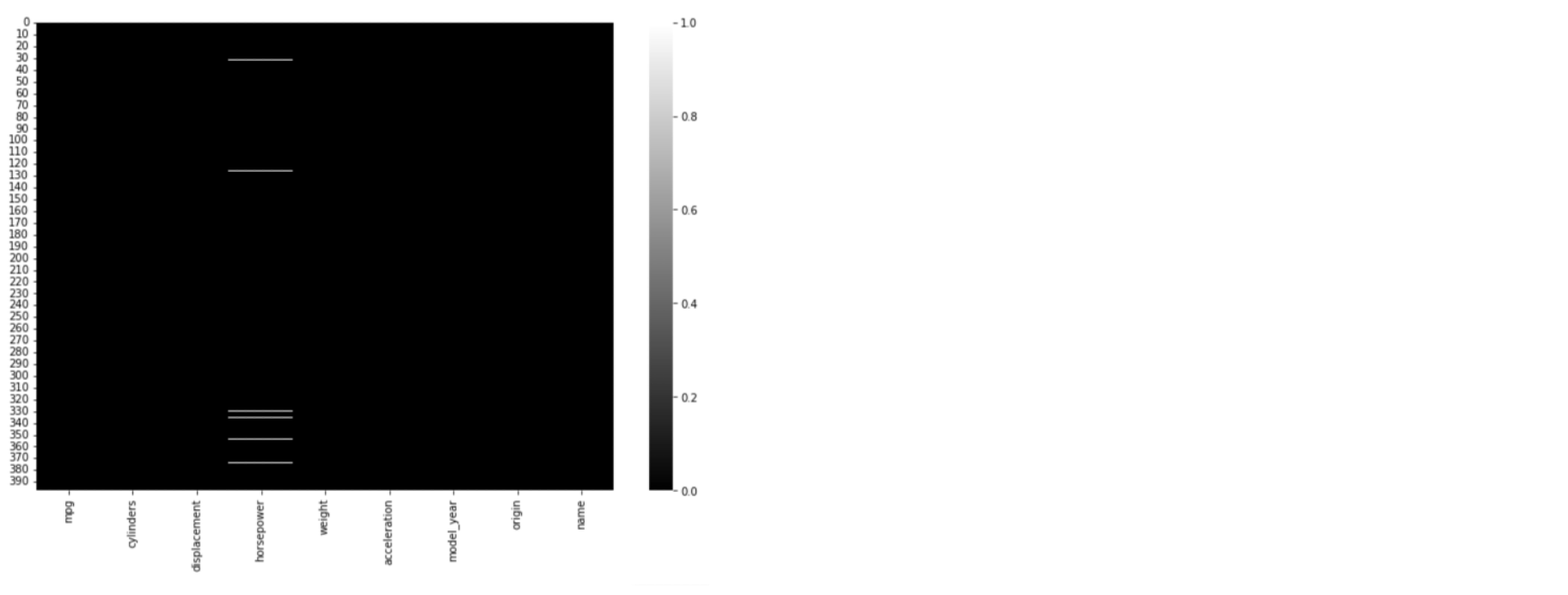
- 그래프에서
y축(왼) : 데이터 인덱스 번호/x축 : 컬럼명을 나타낸다. mpg데이터셋에서 결측치는horsepower에서 총 6개 존재한다.
💡 데이터셋 기술통계
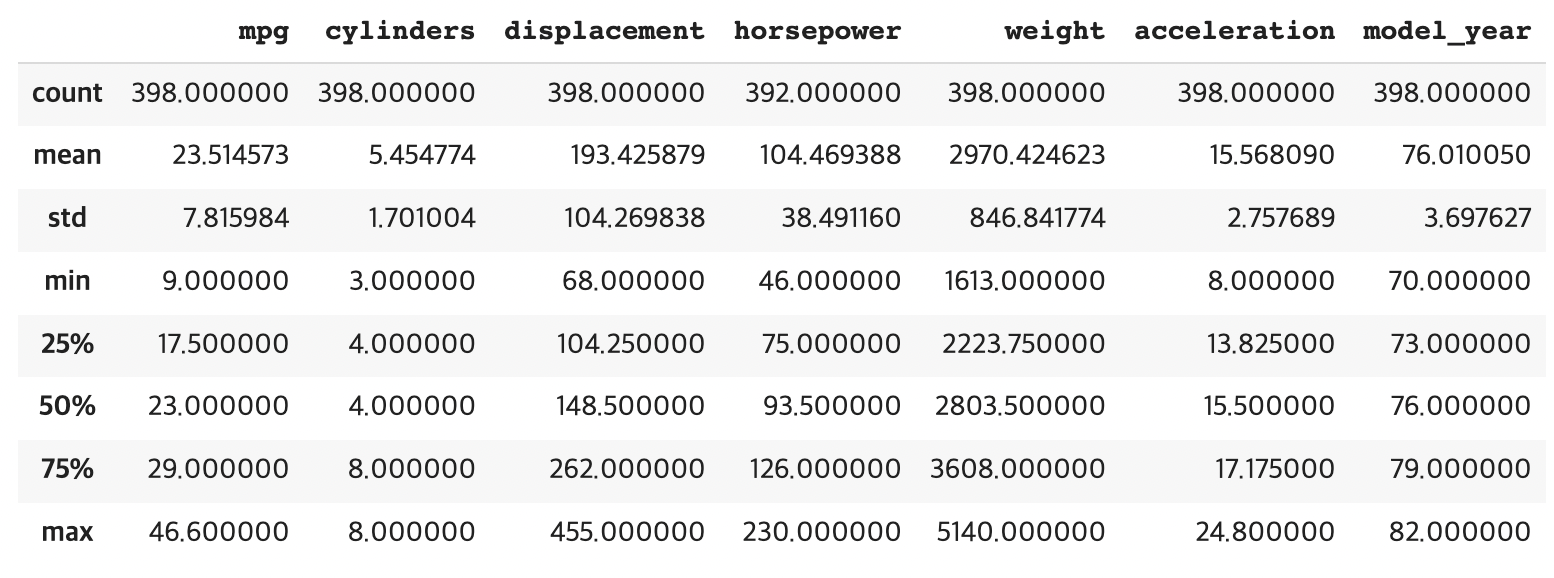
# 데이터 기술 통계값 df.describe()
💡 데이터셋 유일값# 데이터 unique 개수 df.nunique()
cylinders,model_year,origin의 유일값을 보면 전체 데이터 개수(398개)에 비해 매우 적다.
- 수치형 변수이지만 범주형 변수에 가깝다고 생각할 수 있다.

3. 데이터 시각화
- 1개 변수에 대한 그래프,
히스토그램,displot,kdeplot,rugplot,boxplot,violinplot이전 복습시간에 그려보았다. - 2개 이상의 변수에 대한 그래프
Scatterplot,regplot,residplot,lmplot,jointplot,pairplot,lineplot,heatmap를 그려 변수들 간의 상관 관계를 알아본다.
📍Scatterplot 시각화
Scatterplot: 두 개 변수 간의 관계를 나타내는 그래프 방법
# 전체 변수에 대한 관계
sns.scatterplot(data=df)
# 연비와 마력의 관계
sns.scatterplot(data=df, x="mpg", y="horsepower")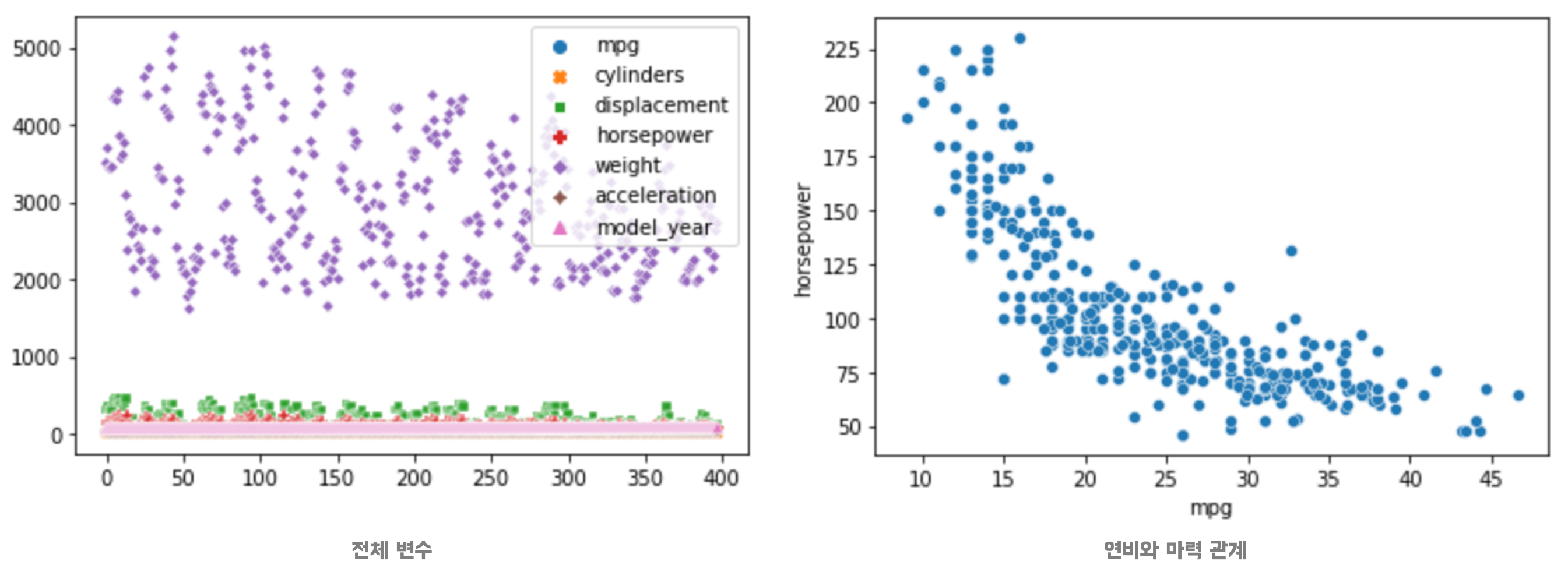
- 전체 변수에 대해
Scatterplot을 그려보니, 범위가 준구난방이라서 그래프가 어떤 의미를 담고있는지 알기 어려움 - 비교해볼 변수를 x, y로 지정하여 그리면 어떤 관계를 가지는지 알 수 있음
- 그래프 해석
- 연비와 마력은 반비례 관계를 가짐
- 특히, 연비가 10~20 사이에서 급격하게 마력이 떨어짐
📍회귀, 잔차 시각화
Regplot(회귀): scatterplot에 회귀선이 추가 된 그래프Residplot(잔차): 회귀선을 y=0인 축으로 Regplot을 옮긴 그래프- 회귀와 잔차 그래프를 그릴 때,
x,y값에 컬럼을 기입해줘야 실행 됨
# 1) regplot 으로 회귀선 그리기
sns.regplot(data=df, x="mpg", y="horsepower")
# 2) 회귀선의 잔차를 시각화 하기
sns.residplot(data=df, x="mpg", y="horsepower")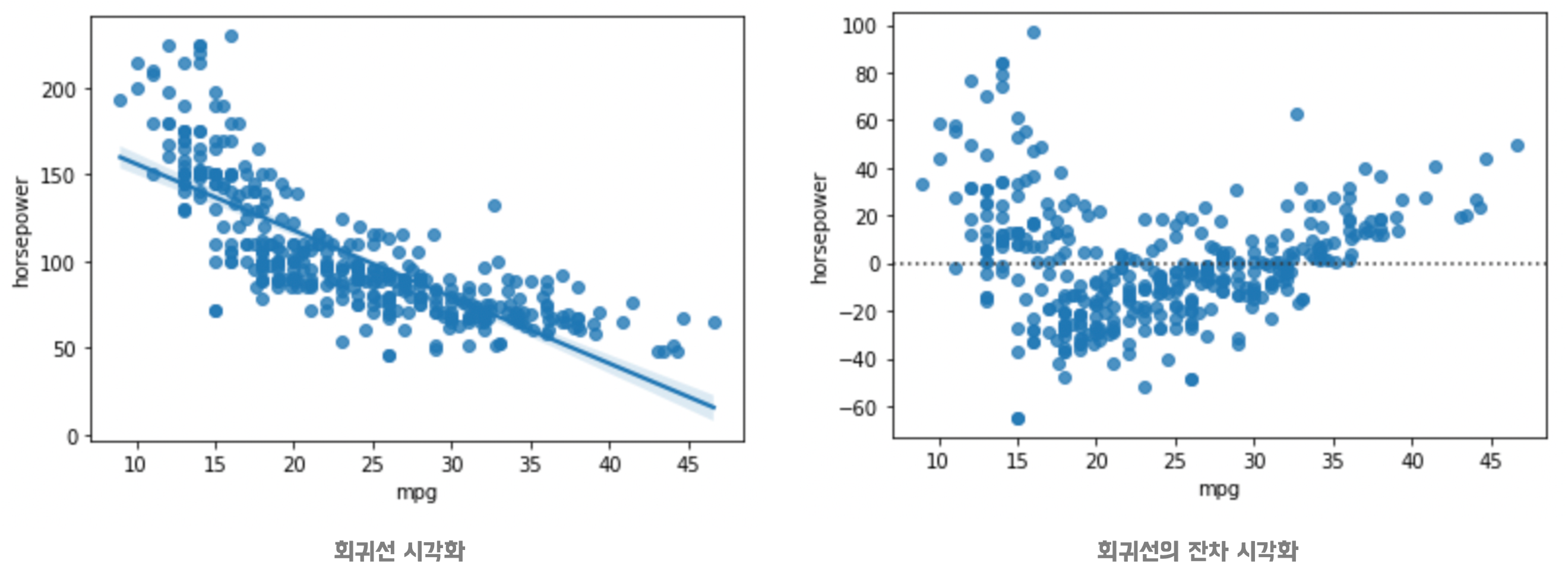
💡회귀 분석을 하는 이유?
관찰이나 실험으로 얻은 샘플자료(적은 수의 자료)를 분석하고 설명하기 위해서는 그 자료를 잘 표현할 수 있는 '방정식'을 예측해야 한다.
자료를 가장 잘 설명하는 방정식이란, 원래 자료와의 오차(error)를 가장 적게 만든 식 입니다.
출처 : 회귀 분석을 하는 이유(feat.회귀선, 회귀 계수)
📍Lmplot 시각화
Lmplot: 범주값에 따라 색상을 다르게 할 수 있으며 subplot을 그릴 수 있다.
# 1) 회귀 시각화 그래프에 origin으로 색상 부여
sns.lmplot(data=df, x="mpg", y="horsepower", hue="origin")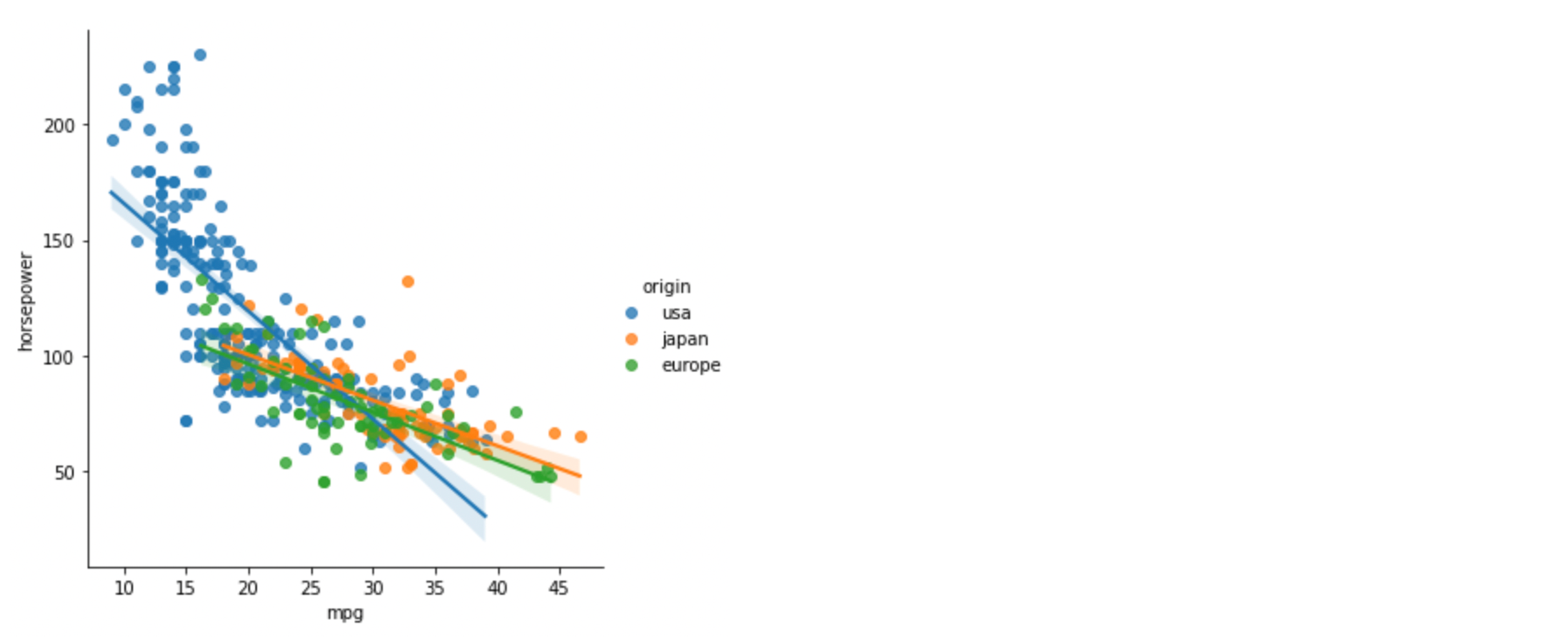
# 2) 그래프 나눠서 보기 - subplot 생성
sns.lmplot(data=df, x="mpg", y="horsepower", hue="origin", col="origin")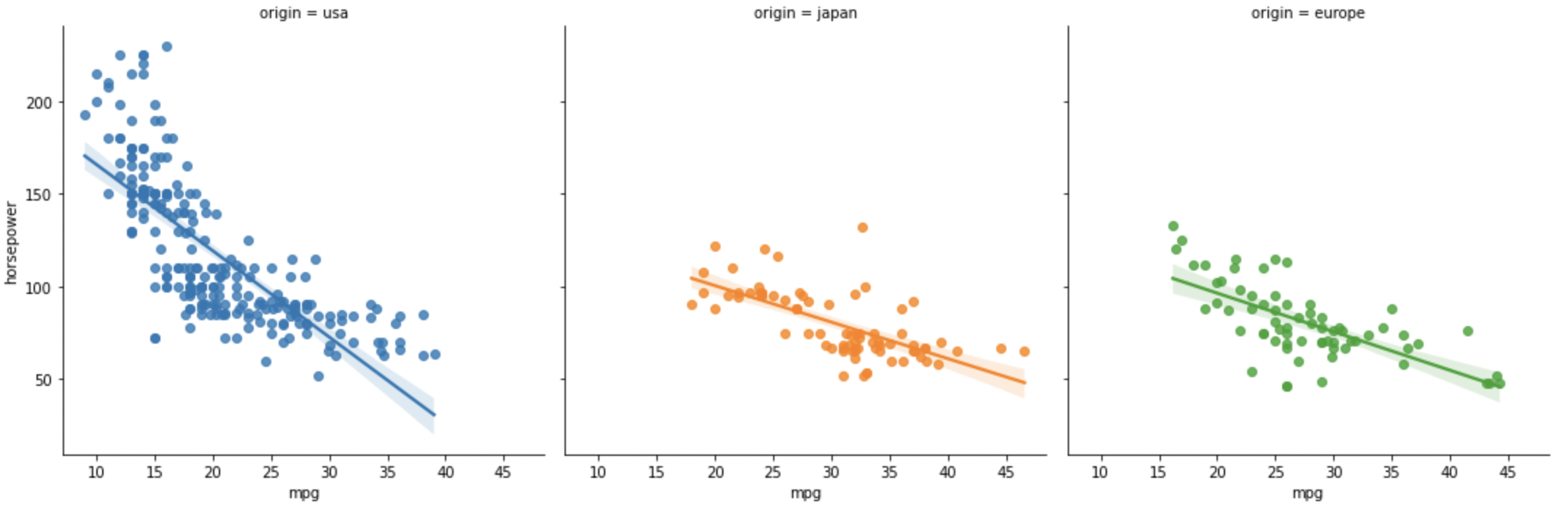
x=mpg,y=horsepower에 대한 변수를origin별로 색상을 부여하여lmplot을 그려봄
- 그래프 해석
- 연비가 10~20 사이에서 급격하게 마력이 떨어지는데
usa제품임 japan,europe에서 생산된 것은 비교적 연비와 마력 관계가 완만해 보임
- 연비가 10~20 사이에서 급격하게 마력이 떨어지는데
📍Jointplot 시각화
jointplot: 두 개의 수치형 변수 간의 관계를 연구 할 수 있다.- 차트의 중앙에서 상관 관계 그래프를 표시해주는데 스캐터 플롯(산점도), 헥스 빈 플롯, 2D 히스토그램 또는 2D 밀도(density) 플롯을 사용하는 것이 일반적이다.
- 중앙 그래프 선택
kind= "scatter" | "reg" | "resid" | "kde" | "hex" 등 타입명 입력
(i) 전체 변수에 대한 상관관계
# 1) 전체 변수의 상관관계
sns.jointplot(data=df)
- 전체 데이터에 대한
jointplot을 그리면 변수간의 상관관계를 한눈에 알아보기 힘듦 - 변수가 많고 범위가 넓은 경우 따로 그래프를 그리는 것이 이해하기 쉬움
(ii) mpg, horsepower에 대한 상관관계
# 2) 연비와 마력의 상관관계
sns.jointplot(data=df, x="mpg", y="horsepower")
# 3) 연비와 마력의 상관관계 - kde(밀도함수)로 보기
sns.jointplot(data=df, x="mpg", y="horsepower", kind="kde")
#) 연비와 마력의 상관관계 - hex(헥스빈)으로 밀집도 보기
sns.jointplot(data=df, x="mpg", y="horsepower", kind="hex")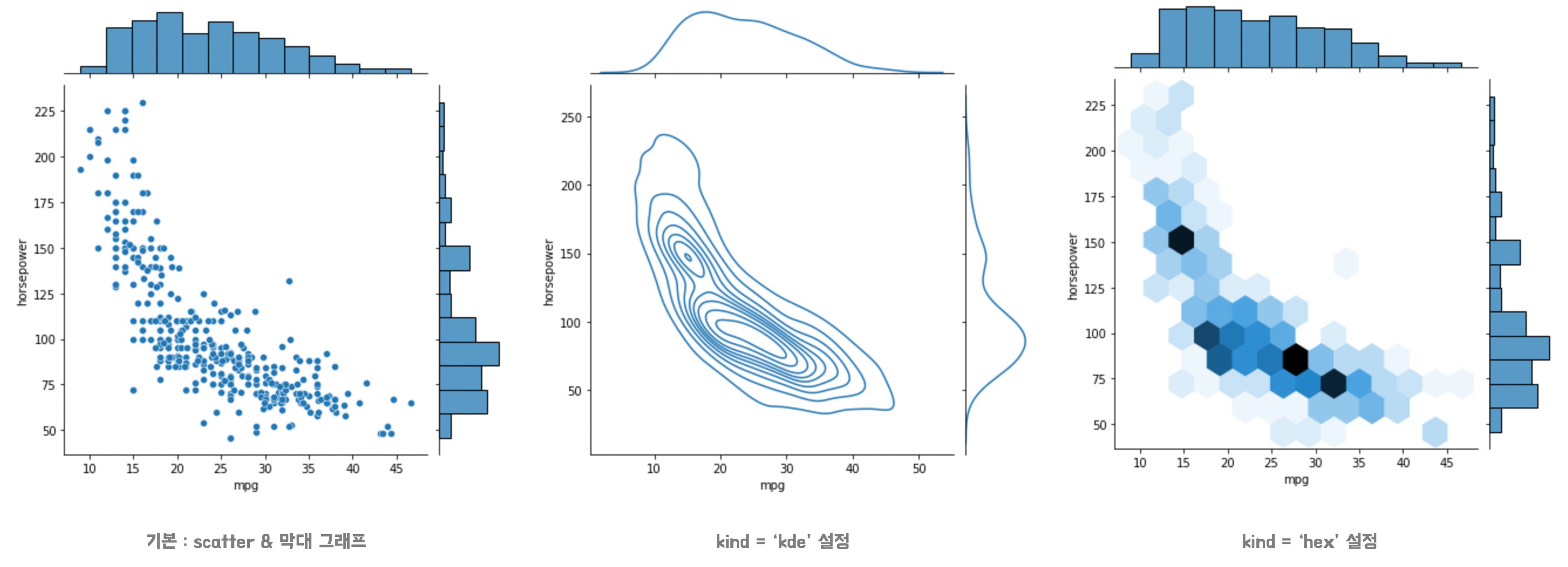
jointplot을 그리면 변수간의 상관관계를 한눈에 볼 수 있음kind를 설정하여 어디에 밀집되어있는지, 등 원하는 분석이 가능함
📍Pairplot 시각화
pairplot: 각 column 별 데이터에 대한 상관관계나 분류적 특성 확인 가능- 대각선 방향으로는 하나의 열의 히스토그램을 나타냄
- 대각선 기준 위 아래는 축이 전환된 것일 뿐, 보여주는 결과는 같음
hue를 추가하여 기존 pairplot에 hue에 지정한 것을 기준으로 나누어 그릴 수 있음
(i) hue="origin" 을 기준으로 한 pairplot
# origin에 대한 pairplot
sns.pairplot(data=df, hue="origin")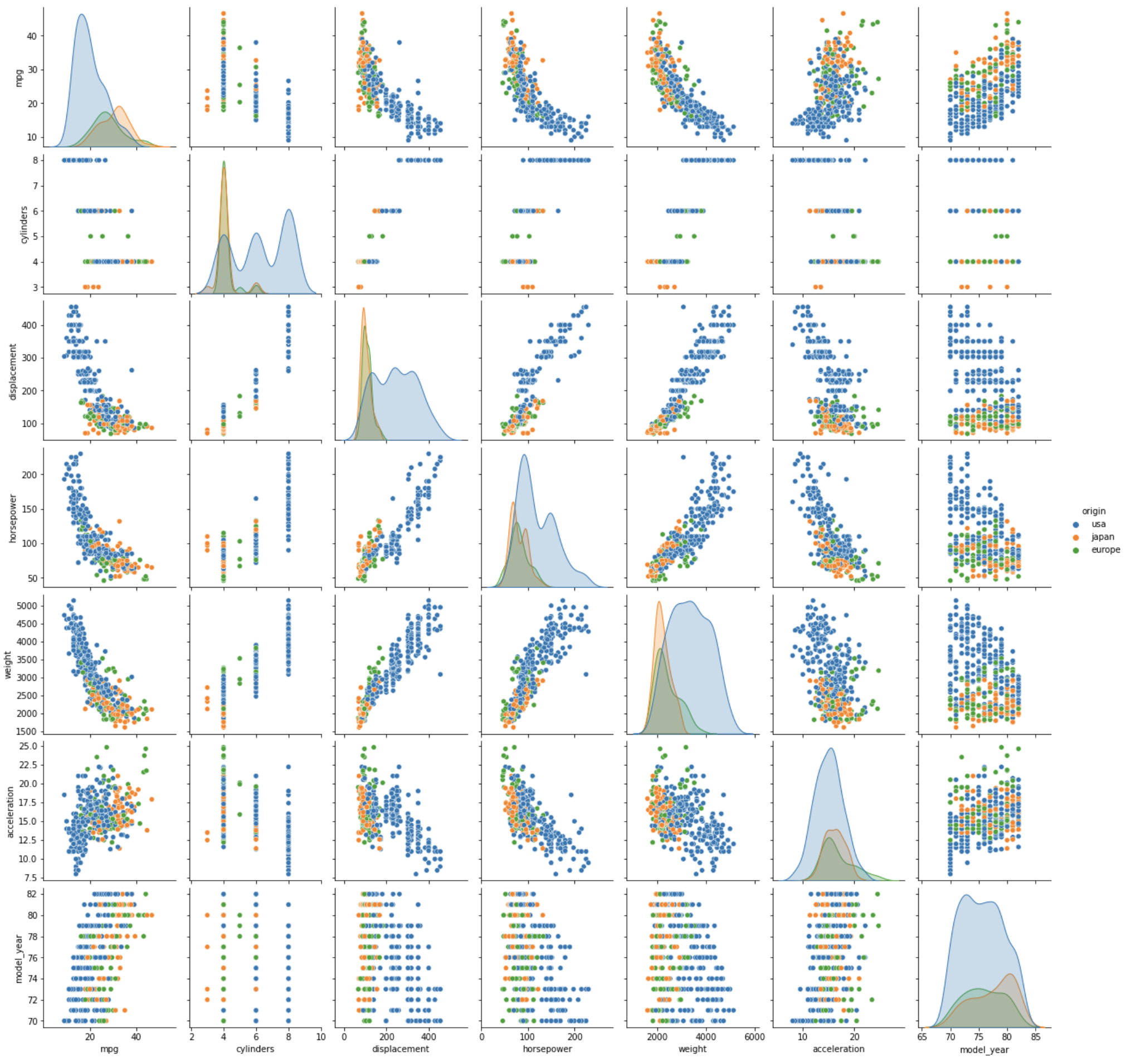
(ii) 일부 데이터로 그린 pairplot
# sample(100) 설정하여 시각화 소요 시간 단축
sns.pairplot(data=df.sample(100), hue="origin") # 전체에서 무작위로 100개 데이터 선택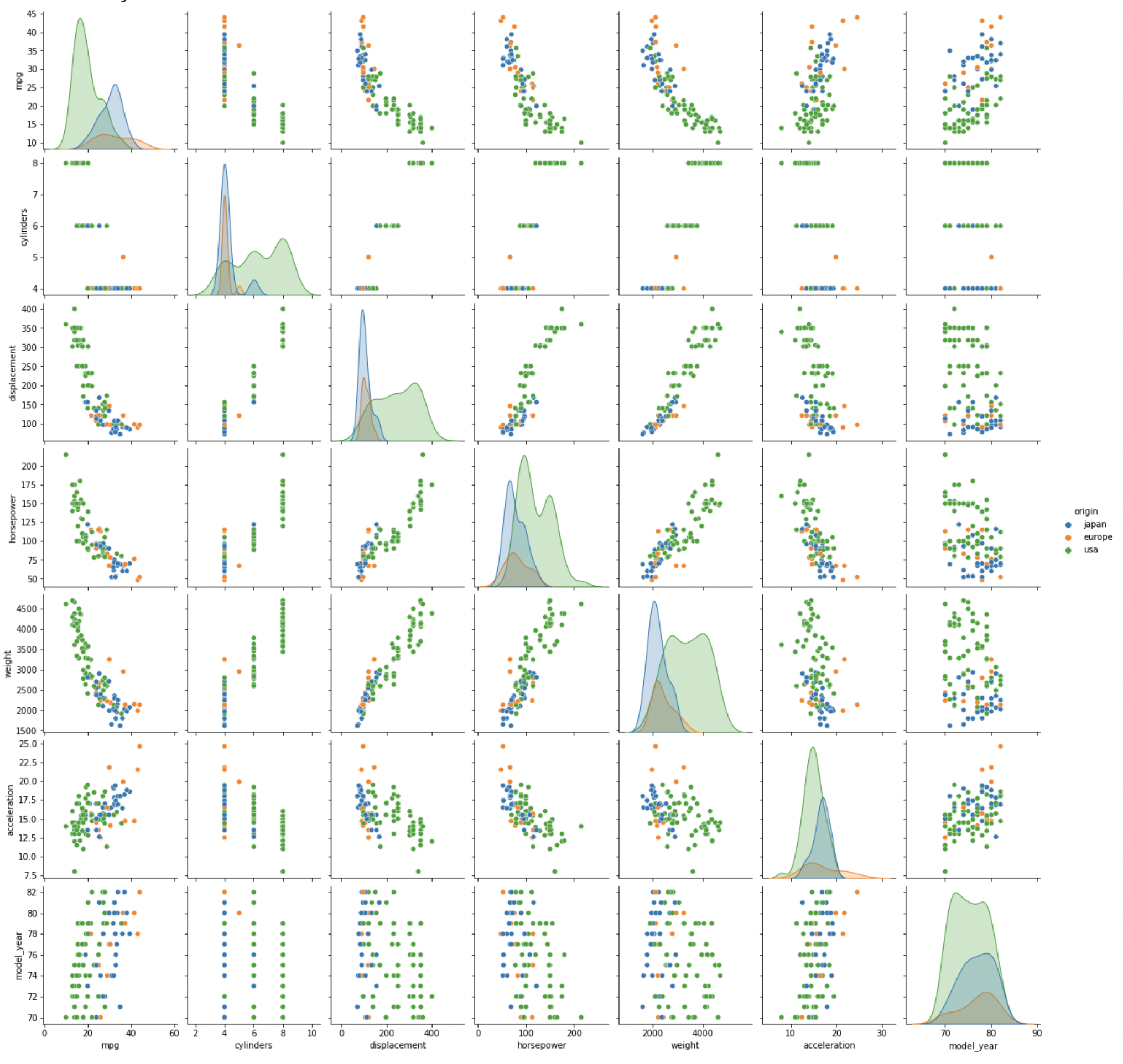
pairplot을 그릴 땐, 여러 그래프를 한 번에 처리하기 때문에 대량의 데이터를 사용하면 시간이 오래 걸림sample()로, 데이터를 무작위로 선정하기- 전체적인 상관관계를 빠르게 확인하고싶을 때 사용하면 좋은 기능
📍Lineplot 시각화
lineplot: 지정한 변수 간의 선형 관계를 알 수 있음hue별 구분이 가능함
(i) 전체 변수에 대한 선형 그래프
sns.lineplot(data=df)(ii) model_year와 mpg에 대한 선형 그래프
sns.lineplot(data=df, x="model_year", y="mpg")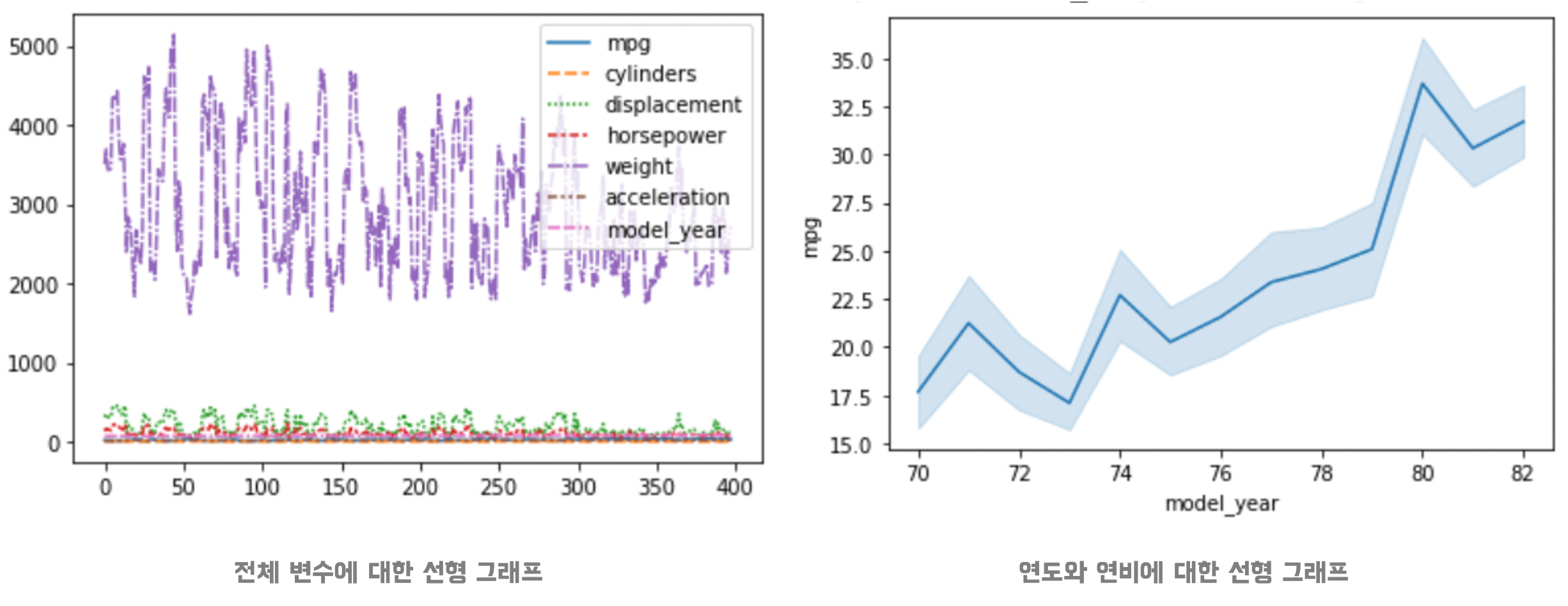
- 전체 변수에 대해 선형 그래프를 그리게 되면, 알아보기 쉽지않음 (
x: 데이터 인덱스,y: 수치형 변수에 대한 값) - 변수를 지정하여 그림을 그리면 한 눈에 알아보기 쉬움
- 그래프 해석
- 최근에 출시된 모델이 연비가 크다.
- 80년도에 연비가 약 32 이상인 데이터 때문에 급격히 상승한 구간이 발견 됨
hue를 추가하면 더 의미있는 분석이 될 것으로 생각 됨
(iii) origin 을 기준으로 구분 된 그래프
sns.lineplot(data=df, x="model_year", y="mpg", hue="origin")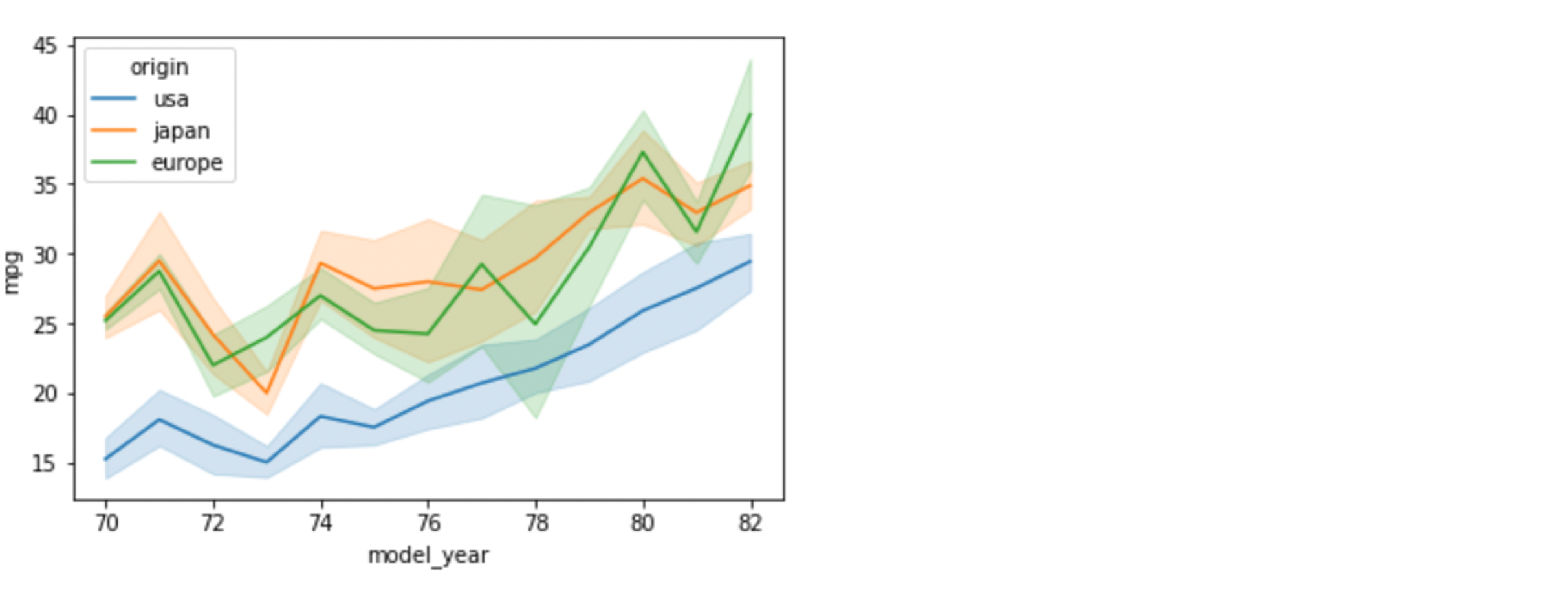
- 그래프 해석
- 나라별로 출시년도가 82년도에 가까워지면서 연비 상승
- 72 ~ 74 년도 사이에 연비 개선이 이루어지지 않음이 발견 됨
📍Relplot 시각화
Relplotscatterplot과lineplot를 그릴 수 있다.- 범주형 변수 에 따라 서브플롯을 그릴 수 있다.
ci: 신뢰구간을 의미함 (defalt : 포함되어 있음)
(i) scatterplot 서브플롯 그리기
# kind의 defalt : scatterplot
sns.relplot(data=df, x="model_year", y="mpg", hue="origin", col="origin")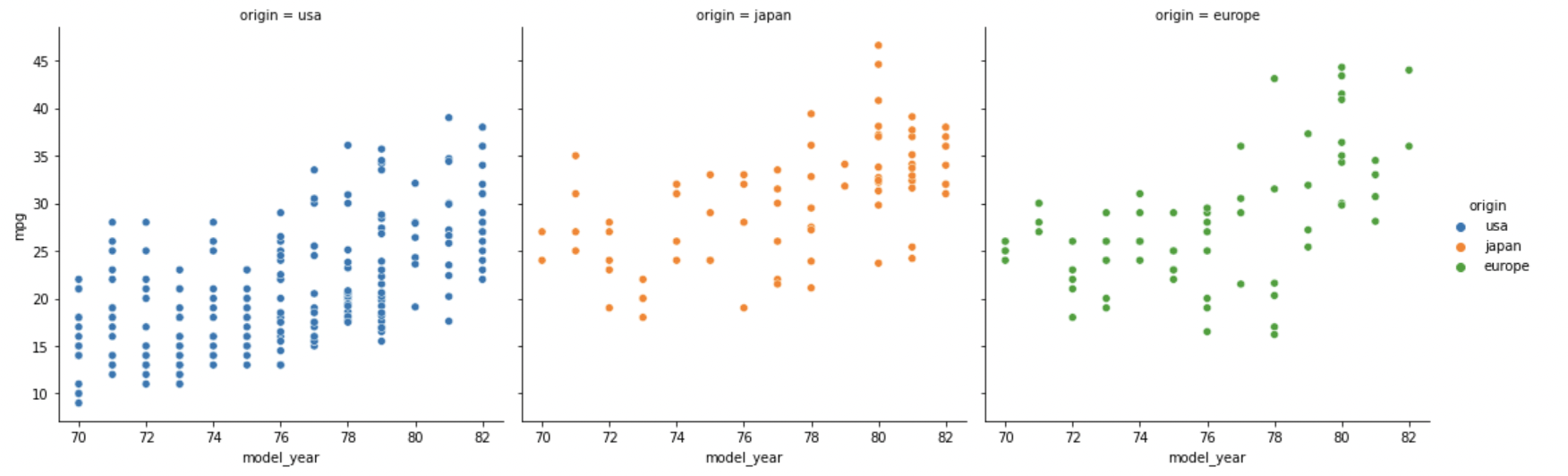
(ii) lineplot 서브플롯 그리기
# 신뢰구간 포함
sns.relplot(data=df, x="model_year", y="mpg",
hue="origin", col="origin", kind='line')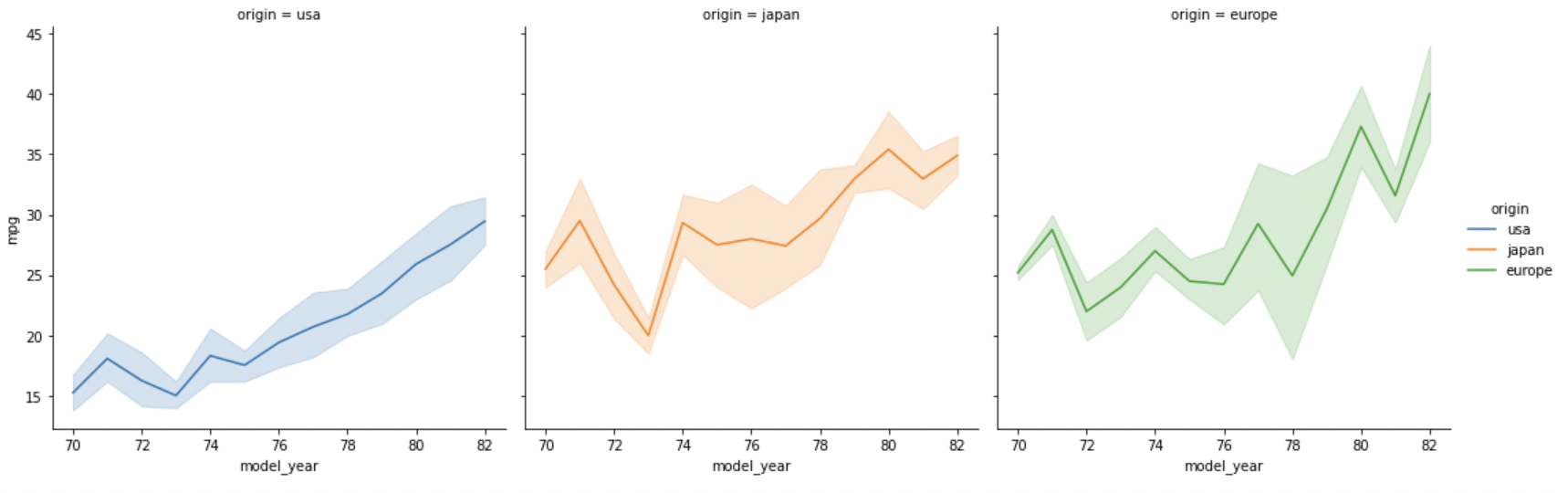
# 신뢰구간 포함 X
sns.relplot(data=df, x="model_year", y="mpg",
hue="origin", col="origin", kind='line', ci=None)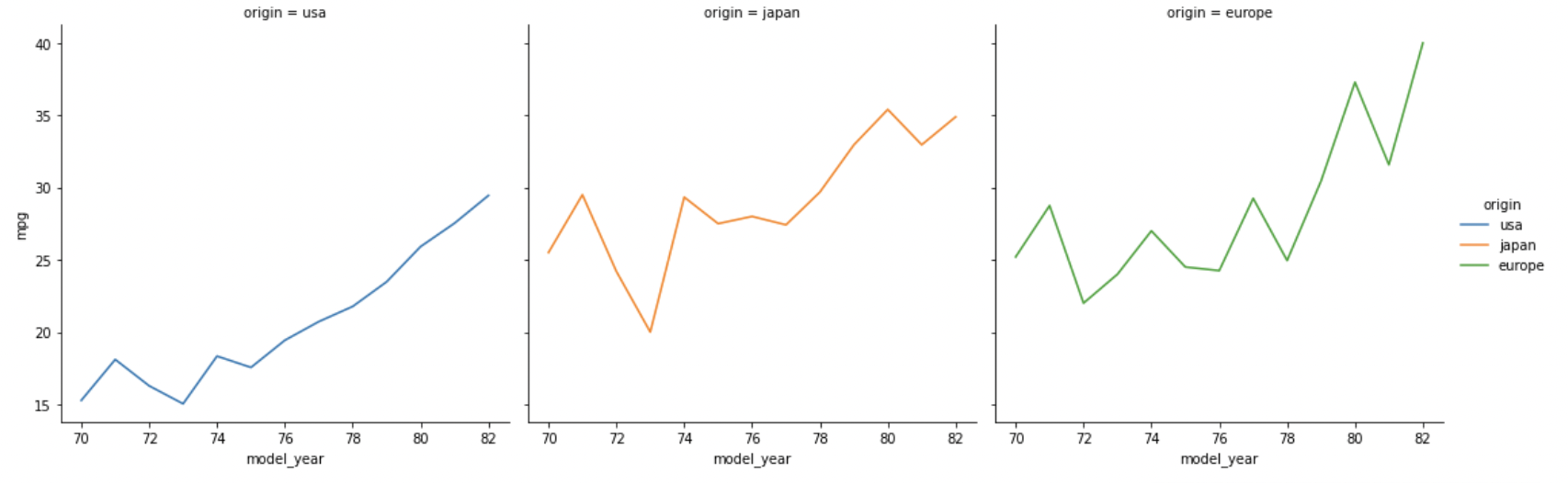
💡 replot를 사용하는 이유?
Relplot을 그리면 추정 회귀선과 신뢰구간을 함께 볼 수 있다.
- 신뢰 구간은 bootstrapping을 사용하여 계산되며, 대규모 데이터셋에 대해 시간이 많이 소요될 수 있으므로
ci=None을 이용해 비활성화시킬 수 있다.ci="sd"로 설정하면 신뢰구간을 표준 편차로 표시할 수 있다.
replot()의 장점
return값이 FacetGrid (여러개의 AxesSubplot를 포함)- scatterplot(), lineplot()의
return값은 AxesSubplot (1장의 그림에 모든 것을 담음)
📍Heatmap 시각화
heatmap: 열을 뜻하는 히트(heat)와 지도를 뜻하는 맵(map)을 결합시킨 단어- 색상으로 표현할 수 있는 다양한 정보를 일정한 이미지 위에 열분포 형태로 출력
- 목적 :
heatmap을 통해상관계수를 시각화 해보자!
💡 상관계수
- 확률론과 통계학에서 두 변수 간에 어떤 선형적 관계를 갖고 있는 지를 분석하는 방법
- 두 변수는 서로 독립적인 관계이거나 상관된 관계일 수 있으며 이때 두 변수간의 관계의 강도를 상관관계(Correlation, Correlation coefficient)라 한다.
- 옵션을 따로 쓰지 않으면, 피어슨 상관 계수로 구함
💡 피어슨 상관계수
- r 값은 X와 Y가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 완전히 동일하면 -1 을 가진다.
- 결정계수(coefficient of determination)는 r^2로 계산하며 이것은 X로부터 Y를 예측할 수 있는 정도를 의미한ㄷ.
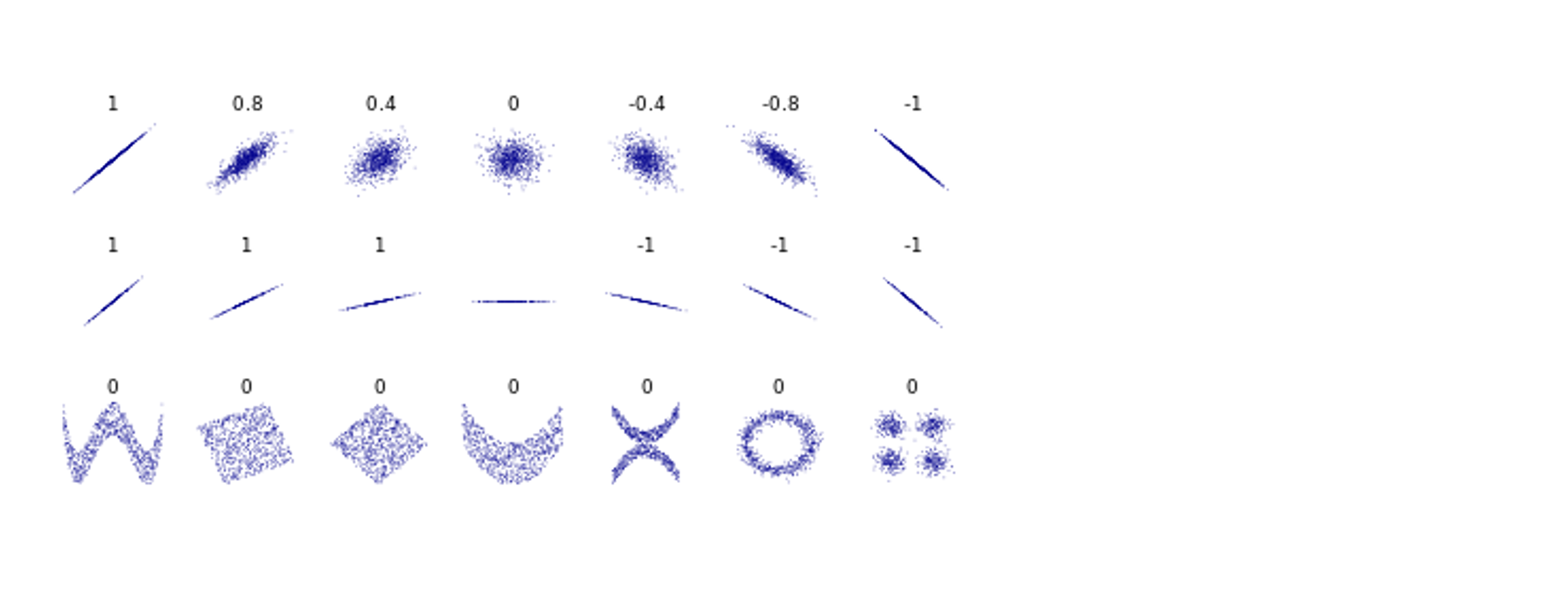
r이 -1.0과 -0.7 사이이면, 강한 음적 선형관계, r이 -0.7과 -0.3 사이이면, 뚜렷한 음적 선형관계, r이 -0.3과 -0.1 사이이면, 약한 음적 선형관계, r이 -0.1과 +0.1 사이이면, 거의 무시될 수 있는 선형관계, r이 +0.1과 +0.3 사이이면, 약한 양적 선형관계, r이 +0.3과 +0.7 사이이면, 뚜렷한 양적 선형관계, r이 +0.7과 +1.0 사이이면, 강한 양적 선형관계
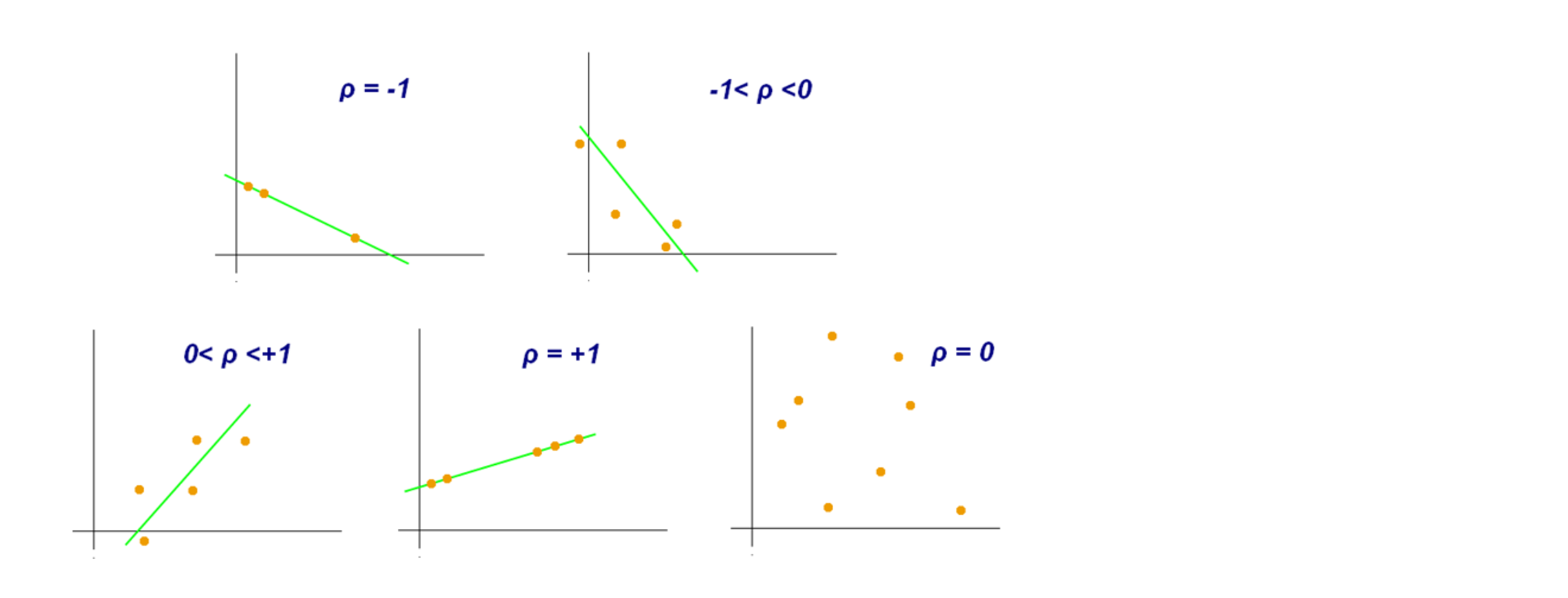
- 서로 다른 상관계수 값을 갖는 산포도 다이어그램의 예
(i) 상관계수 구하기
# 옵션을 따로 쓰지 않으면, 피어슨 상관계수로 구해짐
corr = df.corr()
# np.triu 함수를 이용해 matrix를 상삼각행렬로 만들기
mask = np.triu(np.ones_like(corr))(ii) heatmap 그리기
# heatmap으로 상관계수 시각화
sns.heatmap(corr, cmap="coolwarm")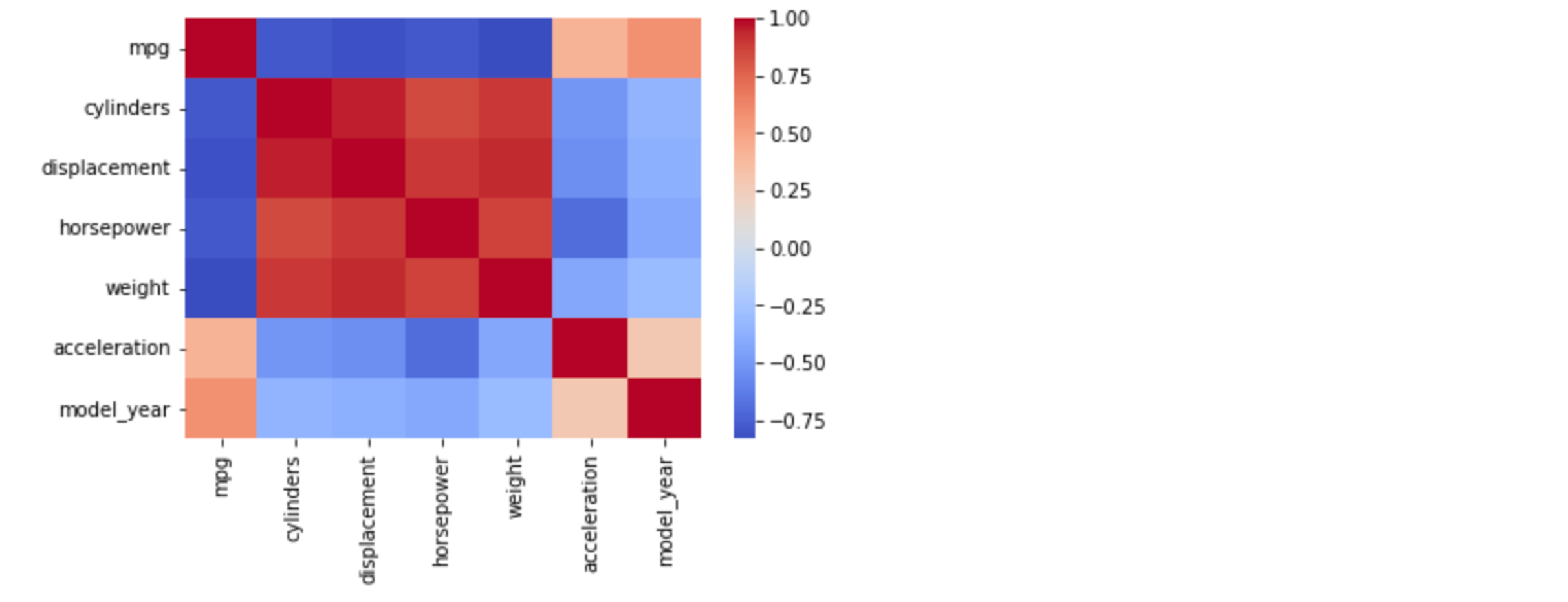
# 대각선을 기준으로 윗부분 제거 + 각 셀에 숫자 입력
sns.heatmap(corr, cmap="coolwarm", annot=True, mask=mask)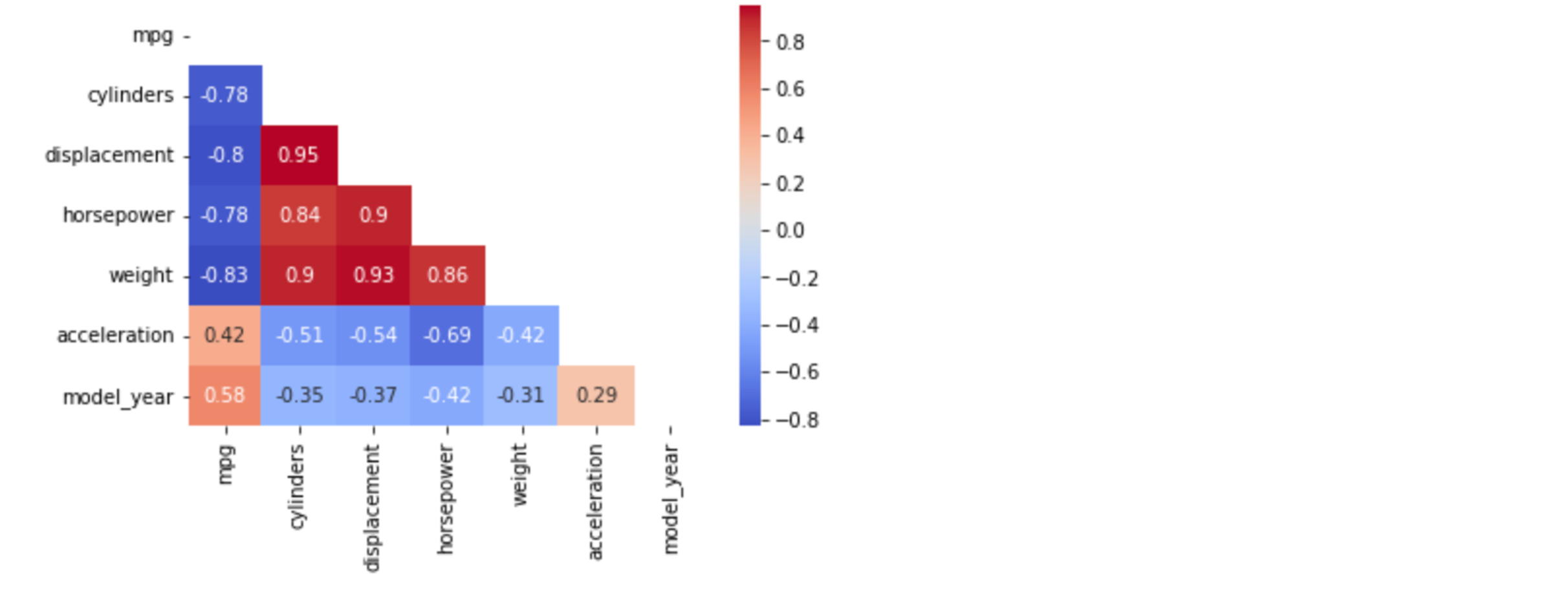
- seaborn을 이용해 히트맵을 그려보았다.
- heatmap의 paramets
mask: bool array or DataFrame, optional If passed, data will not be shown in cells wheremaskis True.annot=True: annotate each cell with numeric value
- 그래프 해석
- 히트맵 위에 표기된 상관계수 값을 보면, 빨간색으로 되어 있는(+1 값에 가까운) 부분은 양적 선형 관계에 가깝다는 것을 의미 함
- 예를 들어,
displavement와cylinders는 선형 관계가 강하다는 뜻임
- 🔥 확인해 보기
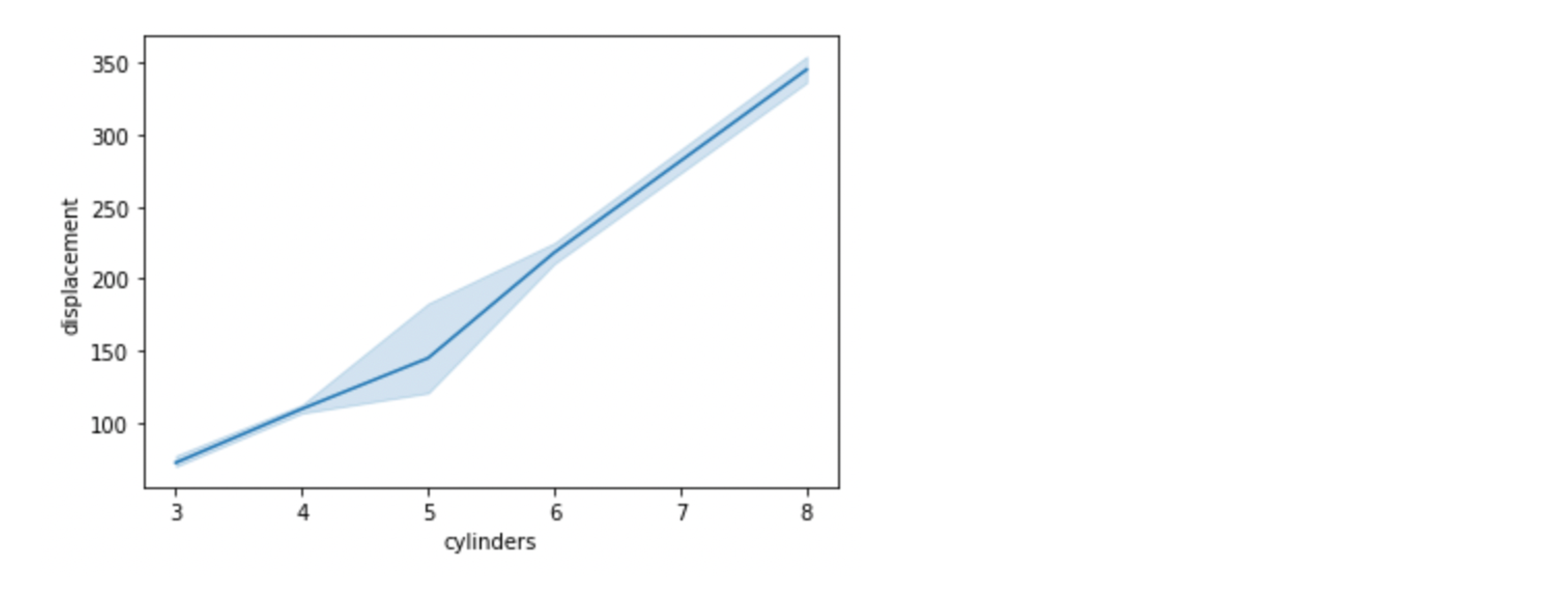
# 위 히트맵에서 알아낸 'cylinders'와 'displacement'의 선형관계를 그래프로 그려보기 sns.lineplot(data=df, x="cylinders", y="displacement")
- 상관계수를 계산하여 heatmap을 그려보면 변수 간의 선형성을 파악할 수 있다.
- 위 그래프에서 cylinders가 5 부분에서 신뢰구간이 커짐
- 이유? 이상치때문에 신뢰구간이 급격히 커진 것으로 생각 됨
🤔느낀점
2개 이상의 변수에 대한 그래프를 그려보았다. 그릴 수 있는 그래프는 거의 다 그려본 것 같다. 이렇게 배운 것을 데이터셋이 주어졌을 때 무엇을 전달하기 위해 어떤 그래프를 그릴 것인지 선택하기 위해선 여러 실습이 중요하겠다고 생각했다.
Kaggle에 올라온 데이터를 이용해서 배운 것들을 적용시켜봐야겠다.
📄참고문헌
참고 1. 산점도
참고 2. 회귀 분석의 필요성
참고 3. 파이썬 seaborn : 시각화 유형 : 상관관계 - 조인트 플롯
참고 4. 상관 분석
참고 5. Seaborn - 관계 그래프 : pairplot
참고 6. Seaborn으로 시각화하기 - [relplot(), scatter(), lineplot()]
참고 7. 히트맵(heatmap)
참고 8. [Python] 히트맵 그리기 (Heatmap by python matplotlib, seaborn, pandas
