미디움에서 어떤 레퍼런스를 보다가 내용이 좋은거 같아 포스팅 해보려한다.
글을 시작하기에 앞서서 작자의 견해를 번역해 적어보려 한다.
비즈니스 로직이 백에서 프론트로 바뀌어 가고있고 점점 더 프론트엔드 엔지니어링이 중요해져 가는 중이다. 프론트엔드 엔지니어로 우리는 리액트와 같은 뷰 라이브러리를 통해 생산성을 높일 수 있다. view 라이브러리는 데이터를 관리하기 위해 Redux와 같은 상태 라이브러리에 의존한다. React와 Redux는 함께 UI 업데이트가 데이터 변화에 반응하는 반응형 프로그래밍 패러다임에 동의한다. 점점 더 많은 백엔드는 단순히 API서버 역할을 하며, 데이터를 검색하고 업데이트를 하는 데만 엔드포인트를 제공한다. 사실상, 벡엔드는 프런트엔드 엔지니어가 모든 컨트롤러 논리를 처리할 것으로 예상하면서 데이터베이스를 프런트엔드로 보내주면 된다. 마이크로 서비스와 그래프QL의 증가하는 인기는 이러한 증가 추세를 입증한다.
이제 HTML과 CSS에 대한 심미적인 이해뿐 아니라, 프런트엔드 엔지니어들도 자바스크립트를 마스터 할것으로 기대가 된다. 클라이언트의 데이터스토어가 서버에 있는 데이터베이스의 복제가 되면서 관용적인 데이터 구조에 대한 친밀한 지식은 중추적인것이 된다. 실제로 엔지니어의 경험 수준은 특정 데이터구조를 언제, 왜 사용해야 하는지 구분하는 능력에서 유추할 수 있다.
자료구조에 대한 견해
높은 수준에서는 기본적으로 세 가지 유형의 데이터 구조가 있다. 스택과 큐는 항목을 삽입하고 제거하는 방법에만 다른 배열과 같은 구조다. Linked Lists, Tree 및 Graphs는 다른 노드에 대한 참조를 유지하는 노드를 가진 구조다. 해시 테이블은 데이터를 저장하고 찾기 위해 해시 함수에 의존한다.
복잡성 측면에서 스택과 큐는 가장 간단하며 Linked Lists에서 구성할 수 있다. 트리와 그래프는 연결된 목록의 개념을 확장하기 때문에 가장 복잡하다. Hash Tables는 이러한 데이터 구조를 활용하여 안정적으로 수행되어야 한다. 효율성 측면에서 Linked Lists는 데이터의 기록과 저장에 가장 최적이며 Hash Tables는 데이터의 검색과 검색에 가장 큰 수행원이다.
작자의 견해를 보면 프론트엔드 엔지니어가 할 수 있는것들이 점점 많아지며 이를 마이크로소프트사 GraphQL의 인기로 확인을 할 수 있었다. 또한 엔지니어의 경험 수준은 데이터구조를 적재적소에 사용하는 능력으로서 구분 할 수 있다고 나온다. 이를 보면 자료구조의 중요성을 알 수 있고 알고리즘의 중요성 또한 같이 알 수 있게 된다.
자료구조에 어떠한 것들이 있는지 살펴 보고 개념을 정리한다기 보다는 미디움의 레퍼런스 기반의 내용으로 포스팅을 마무리 하겠다.
각 자료구조에 대한 알고리즘과 특징은 따로 정리하겠다.
1. Stack
JavaScript에서 가장 중요한 stack은 실행 할 때마다 함수의 범위에 넣어주는 call stack이다.
프로그래밍 방식으로는 push와 pop 두 가지 원칙적인 작업을 하는 배열일 뿐이다. 푸시는 배열의 상단에 요소를 추가하고, 팝은 동일한 위치에서 요소를 제거한다.
스택의 특징은 LIFO(Last in First Out) 프로토콜(LIFO)를 따른다.
아래는 스택에 대한 코드이다. unshift와 shift를 사용하여 구성하였다.
class Stack {
constructor(...items) {
this.reverse = false;
this.stack = [...items];
}
push(...items) {
return this.reverse
? this.stack.unshift(...items)
: this.stack.push(...items);
}
pop() {
return this.reverse ? this.stack.shift() : this.stack.pop();
}
}
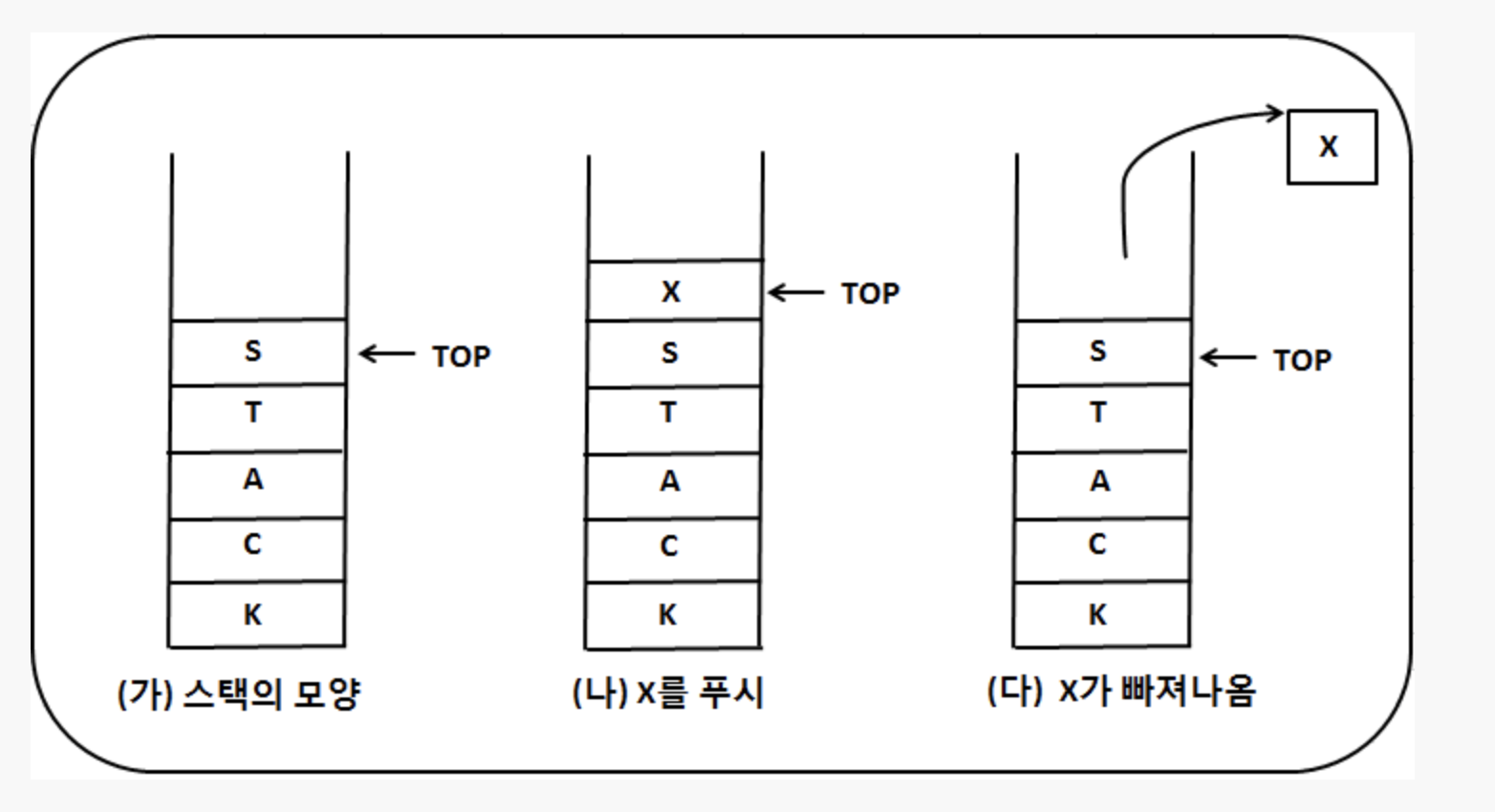
스택은 밑이 막힌 통에 값을 차례대로 저장해 놓고 그 값이 필요 할 때는 가장 위에서 부터 꺼내는 구조라 볼 수있다.
2.Queue
다른 작업을 차단하지 않는 비동기 코드의 "동기식" 실행을 허용하기 위해 프로모스는 이 이벤트 기반 아키텍처에 의존한다.
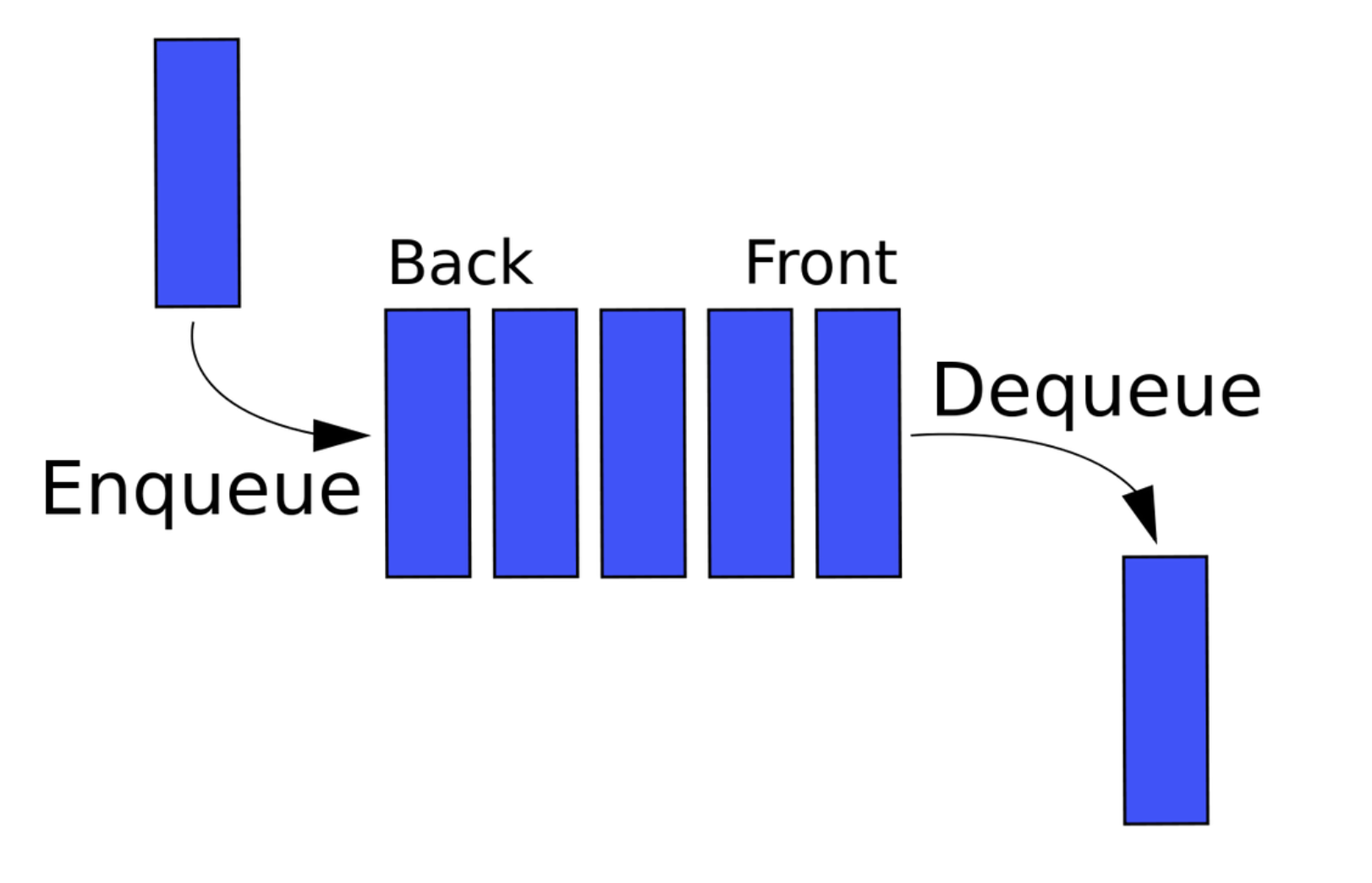
큐는 스택과 반대로 FIFO(first in first out)의 구조를 가지고 있다.
class Queue {
constructor(...items) {
this.reverse = false;
this.queue = [...items];
}
enqueue(...items) {
return this.reverse
? this.queue.push(...items)
: this.queue.unshift(...items);
}
dequeue() {
return this.reverse ? this.queue.shift() : this.queue.pop();
}
}3. Linked List
배열과 마찬가지로 연결리스트는 데이터 요소를 순차적으로 저장한다. 연결된 목록은 인덱스를 유지 하는 대신 다른 요소에 대한 포인터를 보유한다. 첫 번째 노드를 HEAD라고 하고 마지막 노드를 Tail이라고 한다. 단일 리스트에서 각 노드는 다음 노드에 대한 포인터를 하나만 가지고 있다. 여기서 머리 노드는 나머지 부분을 따라 내려간다. 이중 연결 리스트는 이전 노드에 대한 포인터도 보관이 된다. 그래서 꼬리에서 부터 시작해 머리를 쪽으로 "뒤로"도 갈 수 있다.
연결리스트는 포인터를 변경할 수 있기 때문에 일정 시간 삽입과 삭제가 있다. 배열에서 동일한 작업을 수행 하려면 뒤의 항목을 바꾸어 주어야 하기 때문에 선형적인 시간이 필요하다. 또한 연결리스트는 공간이 있는 한 커질 수있다. 하지만 자동으로 크기를 조정하는 동안 "동적인" 배열도 예상치 못하게 공간을 많이 잡아 먹을 수 있다.
배열과 마찬가지로 연결리스트도 스택으로 작동할 수 있다. 연결리스트는 대기열로도 작동 할수 있다. 이는 꼬리 부분에 삽입이 발생하고 머리 부분에 제거가 발생하는 이중 연결 리스트로도 될 수 있다. 많은 수의 요소의 경우, 배열에서의 삽입은 많은 선형시간이 필요하기 때문에 이러한 대기열 구현 방법은 배열을 사용 하는 것 보다 더 수행적이다.
연결리스트는 클라이언트와 서버에서 모두 유용하다. 클라이언트에서, Redux와 같은 국가 관리 도서관은 미들웨어 logic을 연결리스트방식으로 구조화 한다. 서버에서는 express와 같은 웹 프레임워크도 비슷한 방식으로 미들웨어 논리로 구성을 한다. 요청이 접수되면 응답이 발행 될 때 까지 한 미들웨어에서 다음 미들웨어로 전송이 된다.
연결리스트의 중요성을 알 수있다.
다음은 이중 연결 리스트의 구성이다.
class Node {
constructor(value, next, prev) {
this.value = value;
this.next = next;
this.prev = prev;
}
}
class LinkedList {
constructor() {
this.head = null;
this.tail = null;
}
addToHead(value) {
const node = new Node(value, null, this.head);
if (this.head) this.head.next = node;
else this.tail = node;
this.head = node;
}
addToTail(value) {
const node = new Node(value, this.tail, null);
if (this.tail) this.tail.prev = node;
else this.head = node;
this.tail = node;
}
removeHead() {
if (!this.head) return null;
const value = this.head.value;
this.head = this.head.prev;
if (this.head) this.head.next = null;
else this.tail = null;
return value;
}
removeTail() {
if (!this.tail) return null;
const value = this.tail.value;
this.tail = this.tail.next;
if (this.tail) this.tail.prev = null;
else this.head = null;
return value;
}
search(value) {
let current = this.head;
while (current) {
if (current.value === value) return value;
current = current.prev;
}
return null;
}
indexOf(value) {
const indexes = [];
let current = this.tail;
let index = 0;
while (current) {
if (current.value === value) indexes.push(index);
current = current.next;
index++;
}
return indexes;
}
}
4. Tree
트리 구조는 많은 하위노드에 대한 참조를 유지하는 것을 제외하고 연결리스트와 같다. 즉 각 노드는 하나의 상위 루트를 가질 수 있다.DOM(Document Object Model)은 트리구조로 머리와 몸체 노드로 분기하는 루트 html 노드가 있어, 익숙한 모든 html 태그로 더욱 세분화된다. React 컴포넌트를 사용한 프로토타입 상속과 구성 또한 트리 구조를 생성한다. 물론 DOM의 메모리 내 표현으로서 react의 virtual DOM도 트리구조이다.
이진 검색 트리는 각 노드마다 두개 이상의 자식노드를 가질 수 없기 때문에 특별하다. 왼쪽 자식노드는 부모 노드보다 작거나 같은 값을 가져야 하고, 오른쪽 자식노드는 왼쪽 자식노드보다 더 큰 값을 가져야 한다. 이런식으로 체계적이고 균형잡힌, 각각의 반복으로 분기점의 1/2를 무시할 수있기 때문에 시간복잡도가 log로 되면서 어떠한 값도 검색이 가능하다. 삽입 및 삭제 또한 시간복잡도 log에서 처리가 가능하고 가장 작은 값과 큰 값은 왼쪽과 오른쪽 leaf에서 찾는 것이 가능하다.
이진 트리
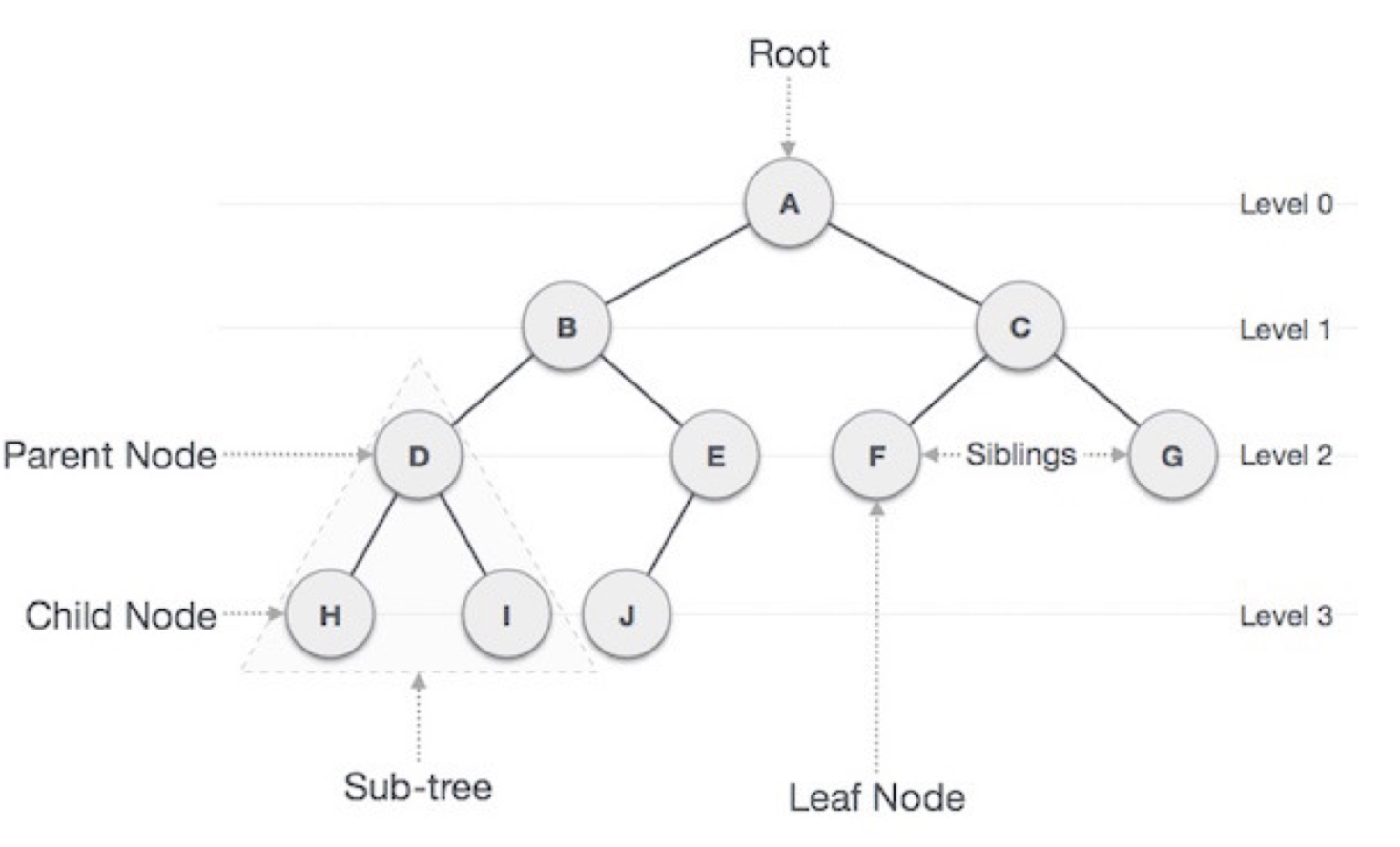
이진 탐색트리 구성
class Tree {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
insert(value) {
if (value <= this.value) {
if (!this.left) this.left = new Tree(value);
else this.left.insert(value);
} else {
if (!this.right) this.right = new Tree(value);
else this.right.insert(value);
}
}
contains(value) {
if (value === this.value) return true;
if (value < this.value) {
if (!this.left) return false;
else return this.left.contains(value);
} else {
if (!this.right) return false;
else return this.right.contains(value);
}
}
depthFirstTraverse(order, callback) {
order === "pre" && callback(this.value);
this.left && this.left.depthFirstTraverse(order, callback);
order === "in" && callback(this.value);
this.right && this.right.depthFirstTraverse(order, callback);
order === "post" && callback(this.value);
}
breadthFirstTraverse(callback) {
const queue = [this];
while (queue.length) {
const root = queue.shift();
callback(root.value);
root.left && queue.push(root.left);
root.right && queue.push(root.right);
}
}
getMinValue() {
if (this.left) return this.left.getMinValue();
return this.value;
}
getMaxValue() {
if (this.right) return this.right.getMaxValue();
return this.value;
}
}5. Graph
만약 트리가 하나 이상의 부모를 가질 수 있다면, 그래프가 된다. 노드를 그래프에서 함께 연결하는 엣지는 방향이 있거나 없을 수 있고 가중치를 가지거나 가지지 않을 수 있다. 방향과 가중치가 있는 엣지는 벡터와 유사하다.
소셜 네트워크와 인터넷 자체도 그래프이다.
6.Hash Table
해시 테이블은 키와 값을 쌍으로 묶는 사전 같은 구조다. 각 페어의 메모리 내 위치는 해시함수에 의해 결정되는데, 해시함수는 키를 받아들이고 페어가 삽입되어 검색되어야 할 주소를 반환한다. 두 개 이상의 키가 동일한 주소로 변환될 경우 충돌이 발생할 수 있다. 견고성을 위해, 게이터와 세터는 모든 데이터를 복구할 수 있고 데이터를 덮어쓰지 않도록 이러한 이벤트를 예상해야 한다. 일반적으로 링크된 목록은 가장 간단한 해결책을 제공한다. 매우 큰 테이블을 갖는 것도 도움이 된다.
class Node {
constructor(key, value) {
this.key = key;
this.value = value;
this.next = null;
}
}
class Table {
constructor(size) {
this.cells = new Array(size);
}
hash(key) {
let total = 0;
for (let i = 0; i < key.length; i++) total += key.charCodeAt(i);
return total % this.cells.length;
}
insert(key, value) {
const hash = this.hash(key);
if (!this.cells[hash]) {
this.cells[hash] = new Node(key, value);
} else if (this.cells[hash].key === key) {
this.cells[hash].value = value;
} else {
let node = this.cells[hash];
while (node.next) {
if (node.next.key === key) {
node.next.value = value;
return;
}
node = node.next;
}
node.next = new Node(key, value);
}
}
get(key) {
const hash = this.hash(key);
if (!this.cells[hash]) return null;
else {
let node = this.cells[hash];
while (node) {
if (node.key === key) return node.value;
node = node.next;
}
return null;
}
}
getAll() {
const table = [];
for (let i = 0; i < this.cells.length; i++) {
const cell = [];
let node = this.cells[i];
while (node) {
cell.push(node.value);
node = node.next;
}
table.push(cell);
}
return table;
}
}Reference
https://medium.com/siliconwat/data-structures-in-javascript-1b9aed0ea17c
