코드스테이츠 5주차 #5
오늘은 연결리스트와 해쉬 테이블에 대해 정리하고 psedo code를 적어보는 시간을 가져 보겠습니다.
1. linked-list
- what is linked-list?
연결리스트는 여러 값을 선형적으로 저장하는 데이터 구조입니다. 연결 리스트의 contain은 다음 노드에 대한 링크와 함께 데이터를 포함하는 자체 노드에 포함 되어 있습니다. 링크는 다른 노드 개체에 대한 방향이 없거나 다음 노드가 없는 경우 null값을 취합니다. 즉 마지막 노드의 링크는 null값을 가집니다.


실생활에서 보면 줄줄이 소세지, 기차 등이 있습니다.
linked-list property
-
link (가르키는 곳)
-
head (첫번째 노드)
-
tail (마지막 노드)
-
old (삭제 할 노드)
-
pre (이전 노드)
-
temp (임시 노드)
-
연결리스트의 Method
1. 연결리스트의 생성 crateList() 2. 첫번째 노드로 삽입 firstInsert() 3. 중간 노드에 삽입 centerInsert() 4. 마지막 노드에 삽입 lastInsert() 5. 노드를 삭제 DeleteNode() 6. 노드의 위치 탐색 SearchNode()
< 연결리스트의 psedoCode >
연결리스트의 생성 createList()
crateList()
// 노드의 데이터 값 value을 null로 지정해준다.
// 노드의 링크 값 (다음을 가르키는) link값을 null 지정해준다.첫번째 노드로 삽입 firstInsert()
firstInsert()
// 새로운 노드를 생성 해준다.
// 노드에 값을 넣어준다.
// 링크 값을 head로 정해준다. 중간 노드에 삽입 centerInsert()
centerInsert()
// 새로운 노드를 생성 해준다.
// 노드에 값을 넣어준다.
// 삽입 할 자리 이전 노드에 링크 값을 현재의 데이터 값으로 지정 해준다.
// 삽입한 링크의 값을 삽입 다음의 데이터 값으로 지정 해준다.마지막 노드에 삽입 lastInsert()
lastInsert()
// 새로운 노드를 생성 해준다.
// 노드에 값을 넣어준다.
// 마지막 노드의 링크 값을 새로운 노드의 데이터 값으로 지정해준다.노드를 삭제 DeleteNode()
DeleteNode()
// 삭제 할 노드를 지정해준다. -> 삭제 이전의 노드의 링크 값
// 삭제 할 노드가 null이면 삭제를 하지 않는다.
// 삭제 할 노드가 null값이 아니라면 삭제를 진행한다.
// 이전 노드(pre)의 링크 값을 삭제할 노드의 링크 값으로 지정한다.노드의 위치 탐색 SearchNode()
SearchNode()
// 노드가 비어있는지 확인한다. -> 노드의 값이 null
// 노드가 비어있지 않다면 탐색을 시작한다.
// 노드의 데이터 값과 찾고자 하는 데이터 값을 비교한다.
// 노드의 데이터 값이 찾고자 하는 데이터 값과 같다면 리턴한다.
// 같지 않다면 현재 노드의 링크 값을 현재 노드에 넣어 준다.
// 반복해서 비교 해준다. 2. HashTable
- what is hash?
해시 테이블은 연관배열 구조를 이용하여 키(key)에 결과 값(value)을 저장하는 자료구조이다.
- 연관배열??
연관배열은 자료구조의 하나로 키 하나 값(1:1) 하나가 연관이 되어있으며 키를 통해 연관 되는 값을 얻어 낼 수 있다.
문자열 키를 통해 연관된 값을 얻어 낼 수 있다.
특별한 알고리즘을 이용하여 저장할 데이터와 연관된 고유한 숫자를 만들어 낸 뒤 이를 인덱스로 사용한다. 특정 데이터가 저장되는 인덱스는 그 데이터만의 고유한 위치이기 때문에, 삽입 연산 시 다른 데이터의 사이에 끼어들거나, 삭제 시 다른 데이터로 채울 필요가 없으므로 연산에서 추가적인 비용이 없도록 만들어진 구조이다.
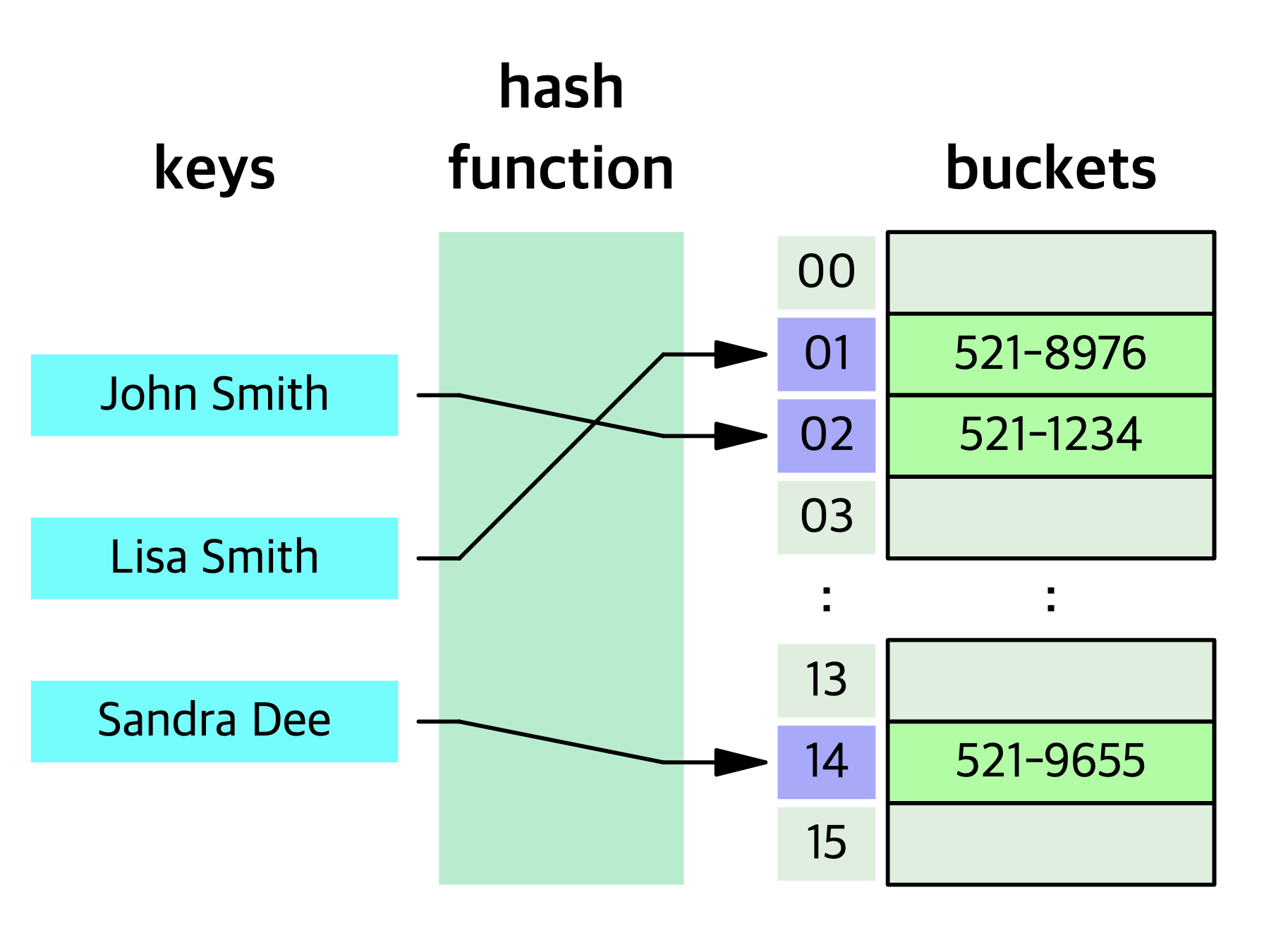
전화번호부에 있는 사람을 Hash Table에 저장할 때의 그림입니다.
keys(이름)을 hash function으로 indexing하여 bucket의 각 index에 value를 넣어줍니다.
그런데 공간을 무한정으로 생성할 수 없으니 수에 제한이 있습니다.
또, 해싱을 하면 동일한 index를 받을 수도 있고, 이때 충돌이 발생하여 중복이 생깁니다.
- hash function
특별한 알고리즘을 통해 고유한 인덱스 값을 설정하는 것이 중요합니다. 특별한 알고리즘을 hash method 또는 hash function이라고 하고 메소드에 의해 반환된 데이터의 고유 숫자 값을 hash code라고 합니다.
- 충돌
해싱을 하는 과정에서 인덱스가 겹치는 충돌이 생깁니다. 충돌이 생겼을때 해결하는 방법은 2가지가 있는데 연결리스트를 이용하여 충돌을 처리하는 Separate chaining 놀고 있는 인덱스에 할당을 해주는 Open Addressing 방법이 있습니다.
1) Separate chaining
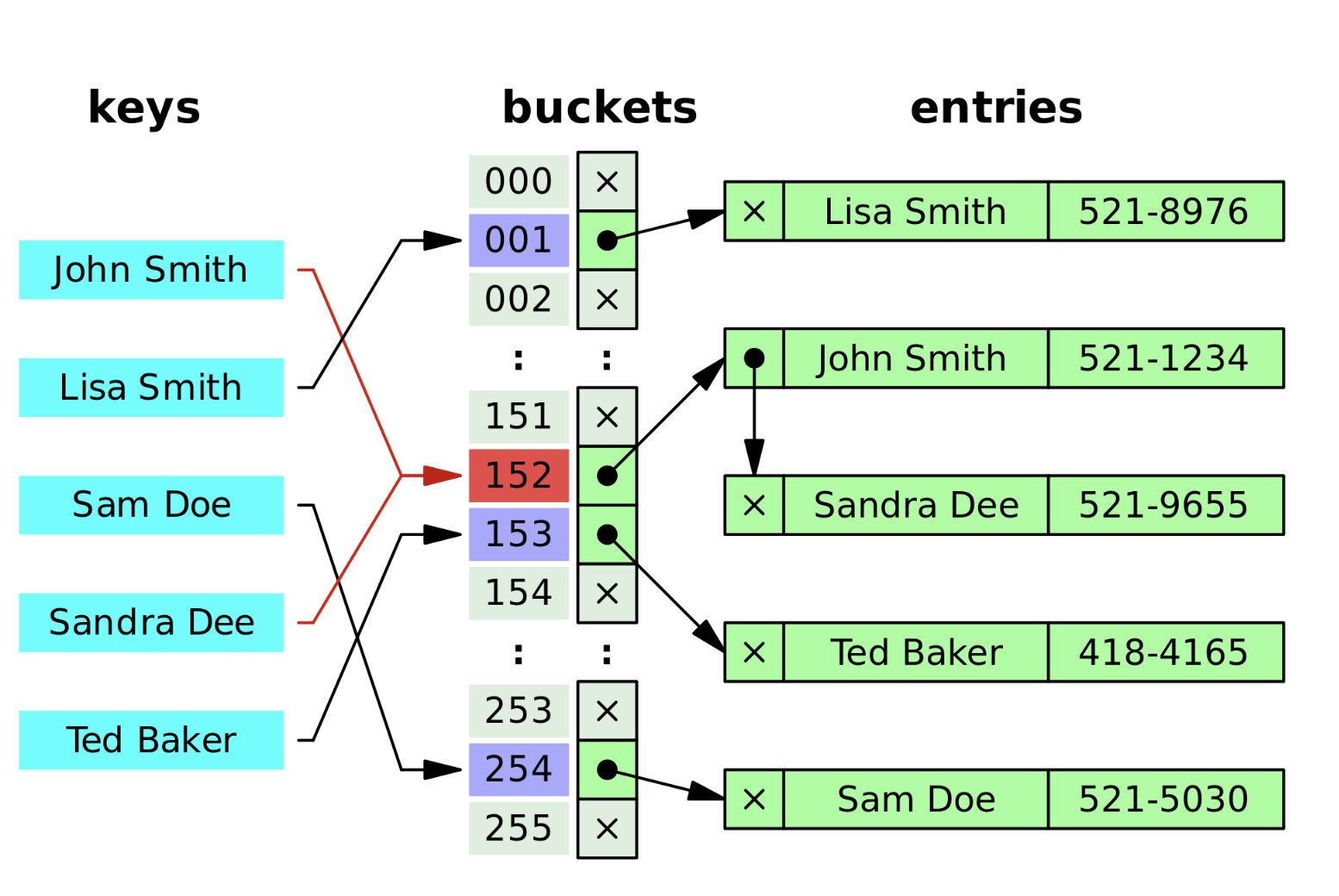
위의 그림은 Separate chaining을 사용하여 충돌을 해결한 그림입니다.
동일한 인덱스를 받아 충돌이 생겼을때 해당 index가 가르키고 있는 linked-list에 노드를 추가하여 값을 추가 해줍니다.
이렇게 하면 데이터를 추가할때 동일한 인덱스를 받아 충돌이 생겼을때 데이터 삽입에 문제가 없습니다.
데이터를 추출시에는 key에 대한 index로 linked-list를 검색해 데이터를 추출합니다.
하지만 여기에 단점이 있습니다. 동일한 인덱스를 받아 충돌을 체이닝으로 계속 해결을 하게 되면 버킷의 할당된 테이블이 놀고 있는 현상이 일어납니다. 이러한 부분 때문에 자원소모가 커지게 됩니다.
이러한 문제 즉 놀고 있는 버킷의 테이블을 먼저 소모 하도록 만든 기법이 Open addressing 입니다. Open addressing의 방법 중 하나인 linear probing에 대해 알아 보겠습니다.
2) Linear Probing (선형 탐사)
선형 탐사 방법은 버킷의 자리를 먼저 다 쓰는 방식 입니다.
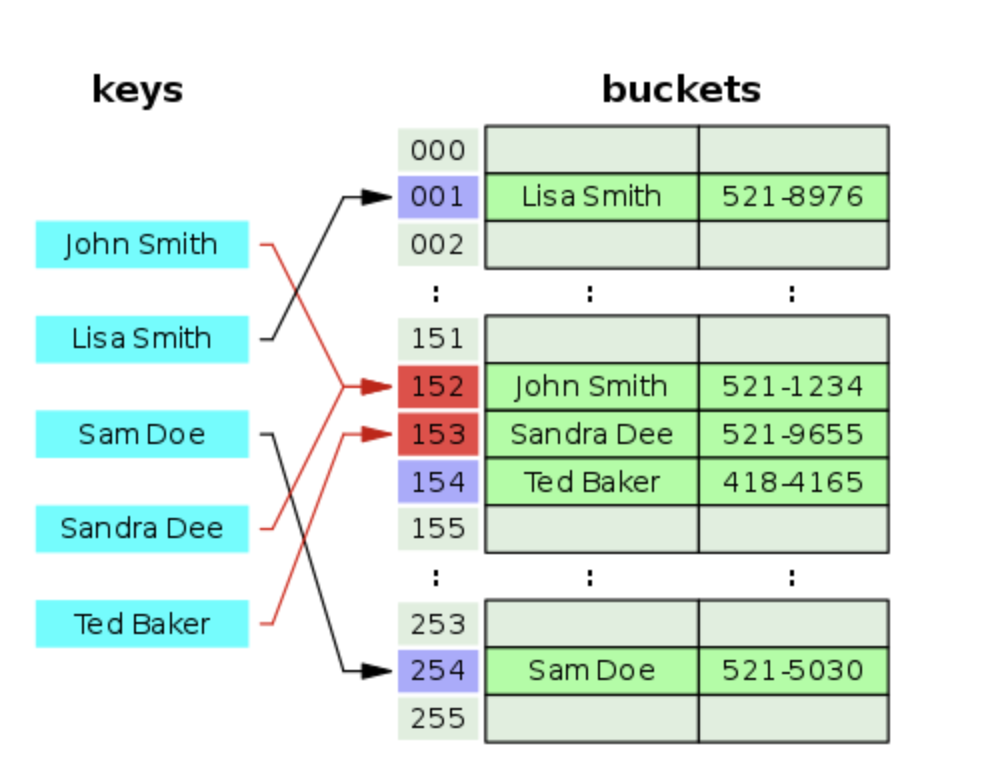
위의 그림을 보면 충돌이 생겼을때 다음 인덱스로 할당을 해주는 것을 볼 수가 있습니다. 계속해서 linear probing방식으로 충돌을 해소하다보면 테이블이 다 차게 되는 경우가 생깁니다.
테이블이 다 차게 되면 더 이상 요소를 넣어 줄 수 없기 때문에 테이블의 크기를 늘려줘야 할 것 같습니다.
이때 테이블의 크기를 늘려주는 Resizing을 통해 테이블의 크기를 늘려 줍니다. 보통은 80%만큼 채워진다면 2배로 테이블의 크기를 늘려주고, 25%로 줄었다면 절반으로 줄여 줍니다.
Hash table property
1. limit: 한 슬롯(버킷) 안에 들어갈 수 있는 데이터의 최대 개수
2. storage: 데이터들이 저장되는 테이블 Hash Table Method
1. insert() 주어진 인덱스로 테이블에 데이터 추가
2. retrive() 주어진 인덱스로 데이터 값을 찾는다
3. remove() 주어진 키 값에 해당하는 인덱스에 들어 있는 값을 제거 - insert()
insert()
// 해시함수로 인덱스를 가져온다. -> 주어진 key값을 index로 해시한다.
// 인덱스에 맞추어 버킷에 저장한다. -> index를 key로 사용해 테이블 안에 데이터를 넣는다.- retrive()
retrieve() // 해시함수로 구한 인덱스로 값을 찾는다.
// 주어진 key값을 index로 해쉬한다.
// 테이블에서 index에 들어 있는 데이터를 찾은 후 리턴한다.
- remove()
remove()
// 해시함수로 구한 인덱스에 맞춰 버킷을 돌면서 제거한다.