코드스테이츠 5주차 #5
자료구조의 방법 중 Stack과 Queue에 대해 포스팅 해보려 합니다.
< 오늘 배운 것들 >😆
-
Stack
-
Queue
1. Stack
What is stack?
스택 자료구조는 접시에 음식을 쌓아 올리듯 데이터를 차곡차고 쌓아 올린 형태로 자료를 구성합니다.
일상에서 쌓아 올리는 방식을 추상화하여 자료구조로 정의한 것이 스택입니다. 스택은 같은 구조와 같은 크기의 데이터를 정해진 방향으로만 쌓을 수 있고 ,top으로 정한 한 곳으로만 접근하도록 제한 되어 있습니다.
따라서 top을 통해 들어온 데이터가 일정한 방향, 즉 아래에서 위로 차곡차곡 쌓이게 됩니다. 여기서 top는 가장 마지막에 삽입이 된 위치 즉 스택에서의 가장 상단에 위치하게 됩니다.
스택의 특징으로는 가장 마지막에 삽입된 데이터가 가장 먼저 삭제 된다는 구조적인 특징을 가집니다. 이러한 스택 동작 구조를 후입선출 LIFO(last in First out) 이라고 합니다.
-
push
-
pop
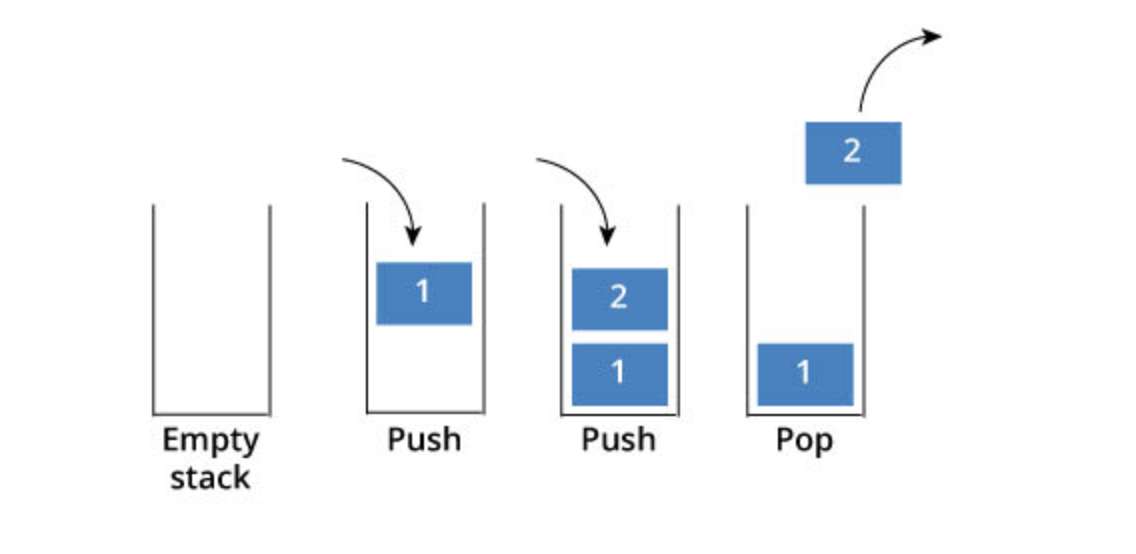
스택을 만들기 전에 앞서 스택에 대한 데이터와 연산의 특징을 추상화하여 알고리즘을 작성해 보겠습니다.
-
스택의 추상 자료형
1.공백 스택을 생성하는 연산 createStack() 2.스택이 공백인지 확인 하는 연산 imEmpty() 3.스택의 가장 위(top)에 원소(item)을 삽입 하는 연산 push() 4.스택의 가장 위(top)에 원소(item)을 삭제 하는 연산 pop() 5.스택의 가장 위(top)에 원소(item)을 반환하는 연산 peek()
< psedoCode >
스택의 공백 확인 imEmpty( )
1) stack의 크기 확인
2) 만약 0이라면 return true
3) 만약 0이 아니라면 return false
imEmpty(S)
if(S === 0){
return 0
}
else{
return false
}push( ) 스택의 원소 삽입
1) Stack의 크기 확인
2) top이 스택의 크기 보다 크다면 overflow
3) top이 스택보다 작다면 top의 값을 증가
4) 스택에 top 삽입
push(S,x)
top = top + 1
if(top > stack_Size) then overflow; // top 이 스택의 크기보다 크면 오버플로우
else {
S(top) // top의 크기를 하나 늘려 준 후 top을 삽입 해준다.
}pop( ) 스택의 원소 삭제
1) 스택의 크기 확인
2) top이 스택크기 보다 작다면
return underflow3) 스택의 top 값을 삭제
pop(item)4) top의 값을 감소
pop(S)
if(top === 0) then underflow; // top이 0인 경우 언더플로우
else {
return S(top);
top = top -1 ; // 원소를 삭제 해준 후 top의 위치를 감소 시켜준다.
}Peek() 스택의 원소 반환
1) stack이 비어 있는지 확인
2) 만약 stack이 비어 있다면
return undefined3) 만약 stack이 비어 있지 않다면
return top(item)Peek()
if(!isEmpty()){
return top(item);
}
else{
return undefined
}
2. Queue
- What is Queue?
큐는 삽입과 삭제의 위치와 방법이 제한된 순서리스트라는 점은 같지만 리스트의 한쪽 끝에서는 삽입 작업만 이루어지고 반대쪽 끝에서는 삭제 작업만 이루어진다는 점이 스택과는 다릅니다.
큐는 삽입된 순서대로 먼저 삽입된 데이터가 삭제되는 선입선출 (FIFO:first in first out) 구조로 운영이 됩니다.
큐는 한쪽 끝은 front(머리)로 정해 삭제 연산만 수행하고, 다른 쪽 끝을 rear(꼬리)로 정하여 삽입 연산만 수행하는 제한 조건을 가진 자료구조 입닌다.
큐에서 front는 가장 먼저 큐에 삽입된 첫번째 원소이고 ,rear는 큐에 가장 늦게 삽입된 마지막 원소입니다. 가장 먼저 삽입되어 가장 앞에 있는 front 원소가 가장 먼저 삭제 되므로 큐는 FIFO구조가 됩니다.
큐의 rear에서 이루어지는 삽입 연산을 EnQueue라고 하고, front에서 이루어지는 삭제 연산을 Dequeue라고 합니다.
-
EnQueue: 삽입
-
Dequeue: 삭제
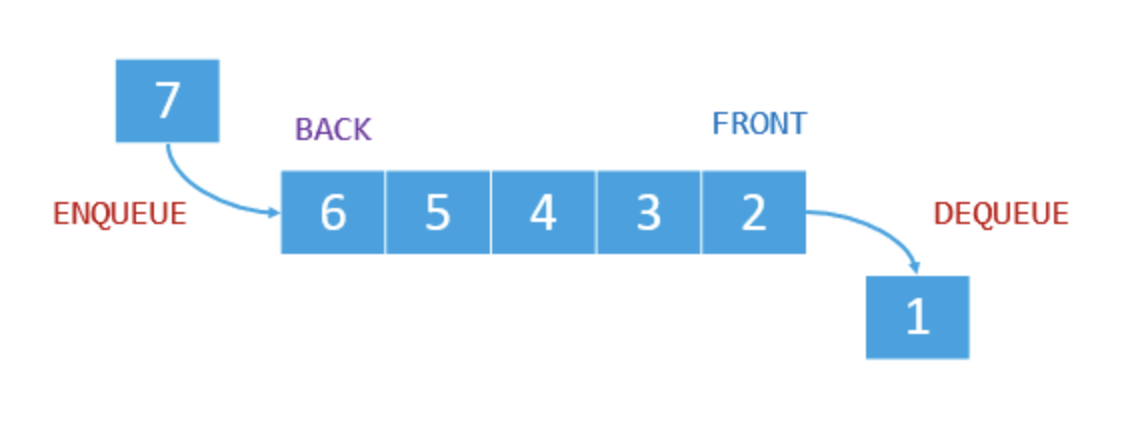
큐를 만들기 전에 앞서 큐에 대한 데이터와 연산의 특징을 추상화하여 알고리즘을 작성해 보겠습니다.
큐의 추상 자료형
1.공백 큐를 생성하는 연산 createQueue()
2.큐가 공백인지 확인 하는 연산 isEmpty()
3.큐의 rear에 원소를 삽입하는 연산 enQueue()
4.큐의 front에 있는 원소를 삭제하는 연산 deQueue()
5.큐의 front에 있는 원소를 반환하는 연산 peek()createQueue() 공백 큐 생성
1) 큐 생성
2) front값과 rear값이 같으면 공백이다.
createQueue()
Q[n] // 배열
front = -1 ;
rear = -1 ; // front값과 rear의 값이 같다.
isEmpty() 큐 공백 상태 확인
1) front 값과 rear의 값이 같다면 true
2) front 값과 rear의 값이 같다면 false
isEmpty()
if(front = rear) then return true; // 만약 front와 rear가 같으면 true
else return false; // front와 rear가 같지 않다면 falseenQueue() 큐의 원소 삽입
1) front 값과 rear의 값이 같다면 true
2) front 값과 rear의 값이 같다면 false
enQueue()
rear = rear + 1 // rear의 값을 증가한다.
Q[rear] = item // 큐에 원소를 삽입 해준다.
}deQueue() 큐의 원소 삭제
1) 큐가 공백인지 아닌지 확인
2) 큐가 공백 상태라면 삭제 x
3) 큐가 공백 상태가 아니라면 front의 값 증가
return Q[front]deQueue()
//만약 공백 상태이면 삭제 연산 중단
if(isEmpty){
}
else {
front = front + 1; // front의 값을 증가한다.
return Q[front]; // 큐의 front자리의 원소를 삭제하여 반환한다.
}peek() 큐의 front의 있는 원소 반환
1) 큐가 빈 큐인지 확인
2) 만약 큐가 빈큐가 아니라면
return Q[front+1]peek()
if(isEmpty){
}
else{
return Q[front+1] // front는 삭제 되어있는 자리이기 때문에 front +1 자리의 원소를 반환 해준다.
}Reference
https://dev.to/rinsama77/data-structure-stack-and-queue-4ecd
