Javascript 알고리즘 및 자료구조(Colt Steele 강의 등 참고)
1.[JS 알고리즘] Big O표기법
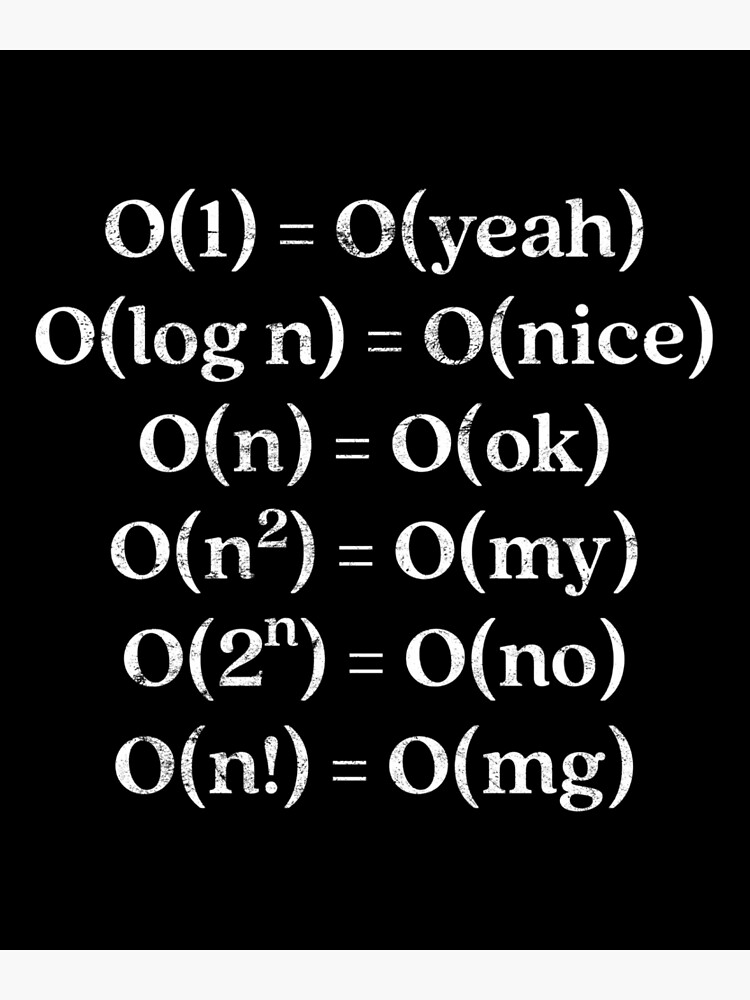
자료구조와 알고리즘 시각화 사이트 https://visualgo.net/ko Big O Notation(https://cs.slides.com/colt_steele/big-o-notation같은 기능을 구현하는데도 여러 가지 접근 방법이 있다.무엇
2.[JS 알고리즘] 배열 및 객체의 성능 분석

이번 섹션 목표Understand how objects and arrays work, through the l
3.[JS 알고리즘] 문제 해결 방식
알고리즘이란 무엇인가?특정 작업을 수행하기 위한 프로세스 또는 일련의 단계를 의미한다.(A process or
4.[JS 알고리즘] 재귀(Recursion)

What is recursion?재귀란 자기자신(함수)을 호출하는 과정이다. A process (a function in our case) that calls itself왜 알아야 하는가?어디에나 있기 때문이다.JSON.parse / JSON.stringify브라우저
5.[JS 알고리즘] 검색 알고리즘(선형 검색, 이진 검색, Naive String Search)

검색 방법주어진 배열에서 값을 검색하는 가장 간단한 방법은 배열의 모든 요소를 살펴보고 원하는 값인지 확인하는 것이다.자바스크립트에는 배열에 대한 다양한 검색 메서드를 갖고 있다.indexOfincludesfindfindIndex이러한 함수들은 어떻게 작동할까?모두 뒤
6.[JS 알고리즘] 정렬 알고리즘

정렬 알고리즘이란, 컬렉션(예를 들어 배열)의 항목을 재정렬하여 항목이 일종의 순서로 정렬되도록 하는 과정을 의미한다.정렬 알고리즘 시각화 영상(참고)https://www.youtube.com/watch?v=kPRA0W1kECg왜 정렬 알고리즘을 알아야 할까?
7.[JS 알고리즘] 버블 정렬(Bubble sort)

버블 정렬은 느려서 효율적이기 않기 때문에 잘 쓰이지 않는다. 하지만 어떻게 작동하는지 알면 왜 다른 알고리즘들이 이것보다 더 나은지 이해하는 데에 도움이 된다.각 요소를 루프로 돌면서, 다음 요소가 비교하는 값보다 큰 지를 확인하고 그렇다면 자리를 바꾸는 과정(swa
8.[JS 알고리즘] 선택 정렬(Selection sort)

버블 정렬과 유사하지만, 큰 값이 아닌 작은 값부터 찾아서 정렬해나간다.루프를 돌면서 가장 작은 값을 찾고, 찾게된 최소값을 해당 루프 시작점에 둔다.https://visualgo.net/en/sortingBest Case : $O(n^2)$선택 정렬은 효율
9.[JS 알고리즘] 삽입 정렬(Insertion sort)

삽입 정렬은 루프를 돌면서 정렬한 요소를 왼쪽에 쌓아가면, 각 요소를 보면서 이미 정렬되어 있는 절반에서 어디로 가야 하는지 찾고 그곳에 삽입한다. 배열에서 두 번째 요소(그 다음 루프에서는 세 번째...루프 끝까지)를 선택하여 루프를 시작한다. \- 이제
10.[JS 알고리즘] 병합 정렬(Merge sort)

이전에 살펴본 버블 정렬, 선택 정렬, 삽입 정렬 은 확장성이 좋지 않다. 예를 들어, 이러한 알고리즘으로 10만 개 정도 요소가 있는 배열을 정렬하려면 시간이 많이 걸린다.큰 배열을 더 빨리 정렬하기 위해서는 합병 정렬, 퀵 정렬, 지수 정렬 등의 알고리즘을 사용할
11.[JS 알고리즘] 퀵 정렬(Quick Sort)

퀵 정렬은 기본적으로 재귀를 사용해서 데이터를 쪼개고, 배열이 0개나 1개의 요소를 가지면 각자 정렬된 배열이 된다는 점을 이용해서 정렬을 했던 병합 정렬과 같은 가정에서 출발한다.그렇지만 병합정렬과는 약간 다르다. 피봇 포인트라고 부르는 기준점을 선택하여 작업을 한다
12.[JS 알고리즘] 기수 정렬(Radix sort)

비교 정렬들의 평균적인 시간 복잡도 한계는 n log n이다. 더 빠른 정렬 알고리즘은 없을까?더 빠른 정렬 알고리즘이라고 간주되는 알고리증 중 기수 정렬이 있다.그러나 기수 정렬은 숫자에 대해서만 정렬할 수 있다. 또한, 그 대상들을 직접 비교하지는 않는다는 것이 특
13.[JS 자료구조] 단일 연결 리스트(Singly linked list) [JS]

단일 연결 리스트는 head , tail , length 프로퍼티들을 포함한 자료구조다.단일 연결 리스트는 node 들로 구성되어 있으며, 각각의 node 는 value 와 다른 노드나 null을 향한 pointer 를 갖고 있다.마치 다음 열차와 연결되어 있는 기차와
14.[JS 자료구조] 이중 연결 리스트(Doubly linked list) [JS]

이중 연결 리스트는 앞에서 살펴본 단일 연결 리스트에서 이전의 노드를 가리키는 포인터를 하나 더하는 것 뿐이다. 그러니까 각각의 노드에 포인터 가 두 개씩 있게 된다.이중 연결 리스트는 이처럼 반대 방향 포인터도 갖게 되어 성능상 유연함을 갖게 됐지만, 더 많은 메모리
15.[JS 자료구조] 스택(Stack)과 큐(Queue)

스택은 LIFO(Last In Fisrt Out, 후입선출) 자료구조이다. 스택에서는 마지막으로 추가된 요소가 제일 먼저 제거된다.배열에서 push 메서드와 pop 메서드를 사용하여 스택 자료구조를 만들 수 있다.또는 별도의 클래스로 자신만의 스택 자료구조를 만들 수도
16.[JS 자료구조] 이진탐색트리(Binary Search Tree)

트리는 parent , child 관계를 지닌 노드들로 구성된 자료구조다.노드들로 구성됐다는 점에서 연결리스트와 비슷하다.하지만 리스트는 일렬로 쭉 이어지는 선형(linear) 구조인 반면에,트리는 여러 갈래로 뻗을 수 있는 비선형(nonlinear) 구조이다.어떻게
17.[JS 자료구조] 트리 순회(Tree traversal) - BFS(너비우선탐색), DFS(깊이우선탐색)

트리 순회(Tree traversal) 트리의 모든 노드를 순회하는 2가지 방법(이진검색트리뿐만 아니라 트리 전반에 대한 방법) Breadth-frist Search(BFS, 너비우선탐색) Depth-first Seacrh(DFS, 깊이우선탐색) 본 포
18.[JS 자료구조] 이진 힙(Binary Heap)과 우선순위 큐(Priority Queue)

일단 힙(Heap)이라는 단어가 매우 생소하므로, 이에 대하여 익숙해질 필요가 있다. Heap의 사전적 의미는 무엇인가 차곡차곡 쌓여있는 더미를 의미한다. 건초 더미, 모래 더미, 산 더미처럼 말이다. 이를 통해, 자료 구조에서 힙(Heap)은 모래 더미처럼 삼각형으로
19.[JS 자료구조] 해시 테이블(Hash Table)

목표해시 알고리즘에 대한 정의좋은 해시 알고리즘을 만드는 방법해시 테이블에서 충돌이 발생하는 경우 이해개별 체이닝(separte chaining)과 선형 조사법(linear probing)을 이용한 충돌 해결해시 테이블이란해시 테이블은 key-value 쌍을 저장하는
20.[JS 자료구조] 그래프(Graph)
이전에 살펴본 트리는 그래프의 일종이다. 그래프는 트리를 포괄하는 개념이다.그래프를 코딩하는 방법은 여러 가지가 있으나, 인접 리스트(Adjacency List) 를 사용하여 그래프를 만들어본다.그래프는 유한한(가변적인) 꼭지점(노드)들의 집합으로 구성된 데이터 구조다
21.[JS 자료구조] 그래프 순회(Graph Traversal) - DFS(깊이우선탐색), BFS(너비우선탐색)

그래프에서 순회하는 코드를 짤 때, 루트가 있는 트리와는 달리 시작점을 정해줘야 한다.그래프의 한 노드에서 다른 노드로 갈 때 유일한 하나의 길만이 있다는 보장은 없다. 이미 방문한 노드를 다시 방문해야 할 수도 있다.그래프 순회 사용 예시P2P 네트워킹웹 크롤러최단
22.[JS 알고리즘] 다익스트라(Dijkstra) 알고리즘

이번에 만드는 다익스트라 알고리즘은 ‘그래프’와 ‘우선순위 큐(이진 힙 버전)’ 개념을 이해하고 있어야 한다.다익스트라 알고리즘은 그래프의 두 개의 정점 간에 최단 경로를 찾는 알고리즘이다. “A 포인트에서 B포인트까지 가는 가장 빠른 방법은?”다익스트라 알고리즘는 가