[AI] DETR(End-to-End Object Detections with Transformers)
DETR(End-to-End Object Detections with Transformers)
Concept
"DETection TRANSformer" 또는 "DETR"이라는 새로운 프레임워크를 파이프라인에 추가하여, set-based global loss와 이분 매칭(bipartite matching)을 통해 강제적으로 분류하는 Tranformer "encoder-decoder" 아키텍처이다. 이는 새로운 Obejct Detection 기법으로, 직접적으로 set를 예측하는 문제이다.
DETR은 Detection Pipelife을 간소화하여 task를 효과적으로 만든다. 이는 hand-desigend components의 필요성(a non-maximum suppression procedure or anchor generation)을 제거하고, 명시적으로 사전지식을 인코드한다.
DETR은 학습된 객체 쿼리의 고정된 작은 세트가 주어지면, 오브젝트 간 관계와 글로벌 이미지 컨텍스트를 직접적으로 출력하기 위해서 최종 셋의 예측 값을 병렬로 추론(분석)한다.
이 모델은 개념적으로는 단순하지만 특정 라이브러리가 요구되지 않아 다른 탐지 모델들과는 다르다. DETR은 까다로운 "COCO 객체 탐지 데이터 세트"에도 잘 적용되고, 고도로 최적화된 Faster RCNN과 동등한 정확도와 런타임(run-time) 성능을 보인다. 또한, DETR은 쉽게 일반화하여 통합된 방식으로 범광학적 분할을 생성한다. Baselines을 능가하는 좋은 성능을 보여준다.기준선을 크게 능가한다는 것을 보여줍니다. 훈련 코드와 사전 훈련된 모델은 다음 사이트에서 볼 수 있다.
-
Non-Maximum Suppression: 객체 감지 모델에서 겹치는 Bounding Box를 제거하여 최종 결과를 정리하는 기술
-
Anchor Generation : Object가 있음직한 위치를 생성
Model
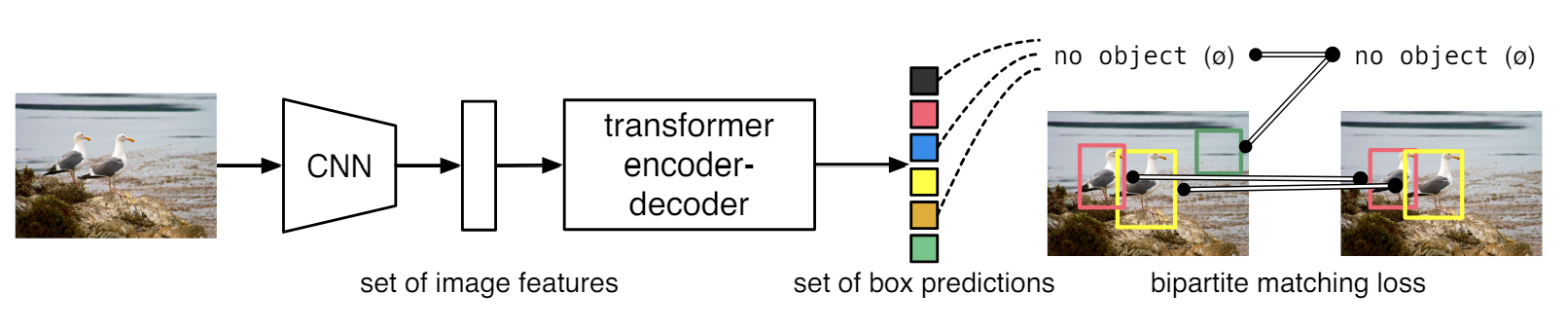
DERTR은 직접적으로 CNN과 Transformer을 결합하여 마지막 셋을 직접적으로 예측한다. 학습중에는 이분 매칭을 통해 독특하게 예측값을 ground truth 박스와 매칭한다. 매치되는 값이 없는 경우에는 “no object” (∅) class prediction으로 분류한다.
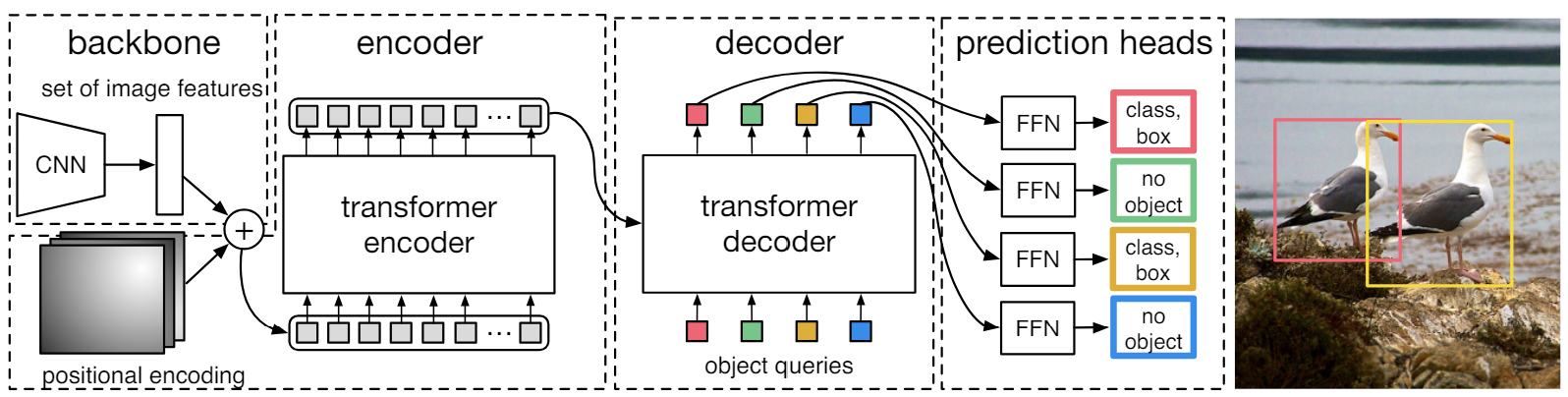
좀 더 자세히 보면, DETR은 CNN 백본(backbone)으로 2D 이미지로 학습한다. 이 후, 모델은 positional encoding을 통해서 이미지를 보강하고 Transformer encoder로 전달한다.
Transformer decoder는 고정된 작은 수의 입력의 위치 임베딩을 학습(object queries)한 후 추가적으로 encoder ouput에 집중한다. Decoer의 아웃풋 임베딩은 공유된 feed forward network (FFN)으로 각각 전달되어 Boudning box를 탐지하거나 “no object”로 클래스로 분류한다.
[1] Nicolas Carion, et al, End-to-End Object Detection with Transformers, 2020.
(https://arxiv.org/pdf/2005.12872)
