[AI] NLP_BERT(Bidirectional Encoder Representations from Transformers)
NLP
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Concept
새로운 language representation model로 Transforermer로터부의 양방향 인코더 표현이라는 의미로 BERT라고 불린다. 최근 의 언어 표현 모델과 달리 (Peters et al., 2018a; Radford et al., 2018), BERT는 모든 레이어에서 왼쪽과 오른쪽 컨텍스트를 모두 고려하여 라벨이 지정되지 않은 텍스트로부터 깊은 양방향 표현을 사전 훈련하기 위해 설계되었다. 사전 훈련된 BERT 모델은 추가적인 출력 레이어 하나만으로도 넓은 범위의 작업에 대한 최첨단 모델을 만들기 위해 파인 튜닝할 수 있다. 질문 응답, 언어 추론 등의 다양한 task를 수행하고, 특별한 작업별마다 아키텍처를 수정할 필요가 없다.
Language Representation Model
- 언어 표현 모델
- 주어진 언어의 문장이나 텍스트를 이해하고 표현하는 모델
- 텍스트의 의미를 파악하고, 그 의미를 일련의 숫자로 변환하여 컴퓨터가 처리할 수 있는 형태로 표현
- 다양한 자연어 처리 작업(task)에 활용
- 텍스트 분류, 기계 번역, 질문 응답, 대화형 시스템 등
- BERT & GPT가 대표적
Model
BERT
BERT는 pre-training과 finte-tuning 으로 나뉜다. pre-training에는 모델이 라벨이 지정되지 않은 데이터에 대해 다양한 사전 훈련 작업을 수행한다. finte-tuning에서는 BERT 모델이 먼저 사전 훈련된 매개변수(pre-trained paprameter)로 초기화되고, 모든 매개변수가 downstream task의 라벨이 지정된 데이터를 사용하여 파인 튜닝한다. 각 downstream task 마다 별도의 파인 튜닝된 모델이 있으며, 사전 훈련된 매개변수를 동일하게 초기화하더라도 동일하다. 아래 그림은 질문 응답 예제이며, BERT의 독특한 특징 중 하나는 다양한 작업에서의 통합 아키텍처이다. 사전 훈련된 아키텍처와 최종 하향 아키텍처(downstream architecture)는 차이가 있다.
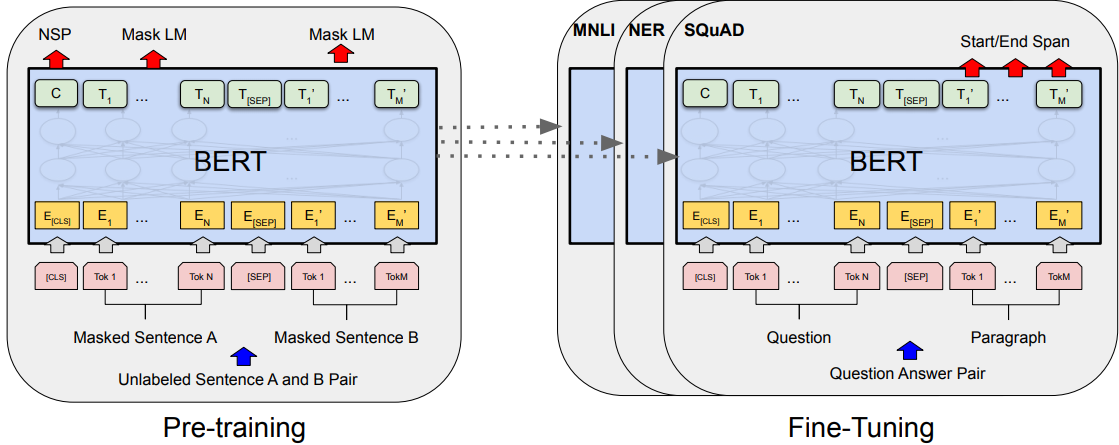
출력 레이어를 제외하고는, pre-training과 fine-tuning에서 동일한 아키텍처를 사용한다. 다양한 downstream task 수행을 위해 모델을 초기화하고 동일한 pre-trained model parameters를 사용한다. Fine-tuning에는 모든 매개변수가 파인 튜닝한다. [CLS]는 모든 입력 예제 앞에 추가된 특별한 기호이며, [SEP]는 특별한 구분자 토큰이다 (예: 질문/답변 구분).
-
Parameters
- the number of layers = L (i.e., Transformer blocks),
the hidden size = H,
the number of self-attention heads = A
- the number of layers = L (i.e., Transformer blocks),
-
Model & Parameters
- (L=12, H=768, A=12, Total Parameters=110M)
- (L=24, H=1024, A=16, Total Parameters=340M)
We primarily report results on two model sizes:
BERTBASE (L=12, H=768, A=12, Total Parameters=110M)
and BERTLARGE (L=24, H=1024,
A=16, Total Parameters=340M).
-
Input/Ouputput representation
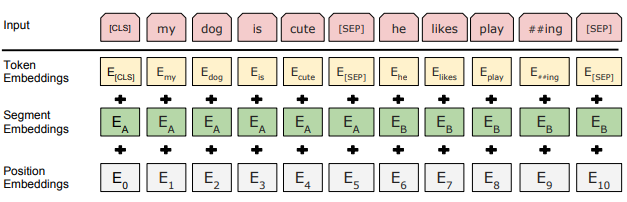
BERT의 입력 표현(input representation)을 위해 임베딩의 합을 구한다. 입력 임베딩은 토큰 임베딩, 세그멘테이션 임베딩 및 위치의 합이다.
Pre-training BERT
BERT 모델은 라벨이 지정되지 않은 대량의 텍스트 데이터에 대해 먼저 사전 훈련한다. 이 사전 훈련 단계에서, BERT는 두 가지 주요 작업을 수행한다.
- Task #1: Masked LM
입력 텍스트에서 일부 단어를 마스킹하여 가린 후 단어를 예측한다. 모델이 문맥을 이해하고 단어 간의 상관 관계를 학습한다. - Task #2: Next Sentence Prediction (NSP)
두 문장 쌍이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 연속인지 아닌지를 예측한다. 모델은 문장 간의 관계를 이해하고 문맥을 파악하는 능력을 향상시킬 수 있다.
Fine-tuning BERT
사전 훈련된 BERT 모델은 특정한 자연어 처리 작업에 대해 파인 튜닝할 수 있다. 사전 훈련된 BERT 모델의 가중치는 고정하고, 목표 작업에 맞는 추가적인 출력 레이어를 추가하여 모델을 새로운 데이터에 맞춘다. 파인 튜닝은 라벨이 지정된 작은 데이터셋에 대해 수행되며, 모델이 특정 작업을 수행하도록 가중치를 미세 조정한다. 이 과정을 통해 BERT 모델은 특정한 작업에 대해 뛰어난 성능을 보이도록 최적화한다.
Results(Experiment)
GLUE(General Language Understanding Evaluation)
BERT 모델의 성는은 11가지 자연어 처리 task를 수행한 결과를 보여준다.
- GLUE 점수는 80.5로 향상(7.7 점의 절대적인 개선),
MultiNLI 정확도를 86.7%로 향상(4.6%의 절대적인 개선),
SQuAD v1.1 질문 응답 테스트 F1 점수를 93.2로 향상(1.5 점의 절대적인 개선),
SQuAD v2.0 테스트 F1 점수를 83.1로 향상(5.1 점의 절대적인 개선).
Refenrence
[1] Jacob Devlin, et al, Pre-training of Deep Bidirectional Transformers for Language Understanding, 2020.
[2] https://github.com/google-research/bert
