NLP(Natural Language Processing)
Transformer (Attention is all you need)
Concept
주요 sequence 변환(transduction) 모델은 복잡한 RNN(recurrent nueral network) 또는 CNN(convolutional neural networks)에 기반한 encoder-decoder 구성을 하고 있다. 가장 좋은 성능을 가진 모델도 attention mechanism을 통해서 encoder-decoder를 연결한다. Transforemr 모델은 단순한 네트워크 구조(network architecture)로 attention mechaism에만 기반하여 recurrence와 convolutions을 완전히 제거하였다.
이는 두 개의 WMT(machine translation) tasks를 보여주면서 증명하였다. 이 모델들은 더 병력적이고 더 적은 학습시간을 보이며 우수한 성능을 보였다. WMT(machine translation)에서는 2014 English-to-German 28.4 BLEU을 보였다. 앙상블 구조를 취할 경우 2 BLEU를 보였다. WMT 2014 English-to-French에서는 새로운 싱글 모델(single-model)은 SOTA(state-of-the-art) BLEU score인 41.8 을 3.5일 동안 8 GPU로 학습한 결과로 나왔다. 이는 최고의 모델 훈련 비용보다 작으며, 대규모 및 제한된 훈련 데이터 모두 사용한 경우에도 사용하여 영어 구성 구문 분석에 성공적으로 Transformer가 task에 적용될 수 있음을 보연다.
Model
대부분의 neural sequence transduction 모델들은 encoder-decoder 구조이다. 각 스텝에서 모델은 자동 회귀(auto-regressive)하여, 이전에 생성된 심볼을 다음에 새로운 심볼을 생설할때 추가적인 입력으로 사용한다.
encoder는 입력 시퀀스 x를 연속적인 시퀀스인 z로 매핑한다.
decoder는 출력 시퀀스 y를 생성한다.
- input sequence :
- continuos of sequences :
- output sequence :
Transformer는 이러한 전반적인 구조가 stacked self-attention과 point-wise, fully connected layers로 encoder과 decoder를 이룬다.
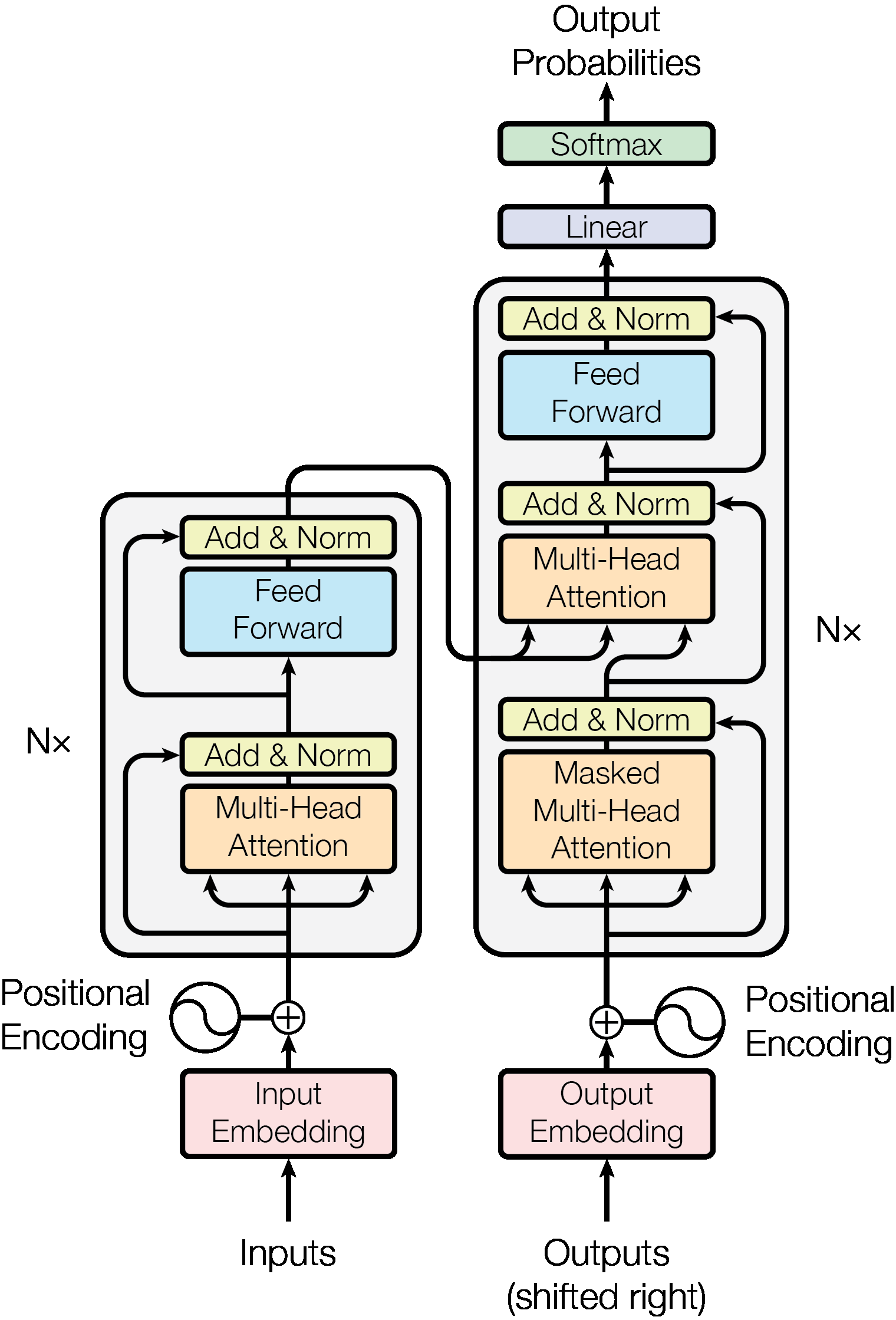
Encoder and Decoder Stacks
-
Encoder:
6개(N=6)의 동일한 layer stack으로 구성되었다. 각각의 레이어는 2개개의 sub-laeyr를 가조 있따. 하나의 sub-layer는 multi-head self-attention mechanism이고, 두번 째는 단순하고 위치 적으로 환전히 연결되 FFN(feed-forward network)이다. Residual connection은 각 두개의 sub-layer에 연결되어, 정규화(normalization)한다. 즉, 각 sub-layer는 그 자신을 활용된다. 이 residual connection을 용이하게 하기 위해서는 모델의 모든 sub-layers와 embedding layers가 출력의 demison을 512로 설정해야 한다.- the output of each sub-layer = ,
-
Decoder:
6개(N=6)의 동일한 layer stack으로 구성되었다. 추가로, 각각의 encoder layer에 두 개의 sub-layers에 decoder는 세 번째 sub-layer를 삽입하여 encoder 출력에 multi-head attention을 수행한다.encoder와 비슷하게 각 sub-layers 주변의 의 residual connections을 이용하여 layer normalization한다. self-attention은 decoder stack의 sub-layer는 (현) 위치(positions)가 후속 위치(subsequent positions) 이동하는 것을 방지하기 위해 수정한다. 이러한 마스킹(masking)은력 임베딩이 하나의 위치로 상쇄된다는 사실과 결합하여 위치 에 대한 예측이 보다 작은 위치에서 알려진 출력에만 의존할 수 있도록 보장한다.
Attention
attention 함수는 쿼리(queries)와 키-값 쌍(key-value pair)을 출력으로 매핑한다. 여기서 query, keys, values, output은 모두 모두 벡터이다. 출력은 values의 weighted sum으로 계산하고, weight는 각 value가 호환 함수(compatibility function)로 쿼릴ㄹ 상응하는 키로 계산한 것이다.
아래 그림은 (왼쪽) Scaled Dot-Product Attention과 (오른쪽) 여러 개의 병렬적으로 실행되는 attention lyers로 구성된 Multi-Head Attention 이다.
Scaled Dot-Product Attention
입력은 queries, keys의 차원 , values of 의 차원 이다. 이 attention function은 Query와 모든 key를 dot products 하고 각각 로 나눈다. 이는 softmax function을 적용하여 values의 weights를 얻는다.
동시에 쿼리 셋은 매트릭스 로 묶이고, key와 values도 함께 매트릭스 와 로 묶여, 아래 식을 계산한다.
가장 많이 사용되는 functions은 additive attention과 dot-product (multiplicative) attention이다. Dot-product attention은 스케일링 팩터 를 제외하고 이 알고리즘과 동일하다.
Additive attention는 단일 은닉층을 가진 FNN을 사용해 호환성 함수(compatibility function)를 계산한다. Dot-product attention은 고도로 최적화된 행렬 곱셈 코드를 사용하여 구현할 수 있기 때문에 이론적 복잡성은 비슷하지만 실제로는 훨씬 빠르고 공간 효율적이다.
작은 값의 {d_k}에 대해서는 두 메커니즘이 유사하지만, 더 큰 값의 {d_k}에 대해서는 스케일링하지 않아도 additive attention이 dot-product attention보다 뛰어나다. 큰 값 {d_k}는 dot-product의 크기가 크게 증가하여 softmax function을 극도로 작은 기울기를 갖게 한다. 이러한 문제를 해결하기 위해서 dot-product를 로 스케일링한다.
Multi-Head Attention
단일 주의 함수를 -dimensional keys, values, queries-로 수행하는 대신에, 배 만큼 서로 다른 학습된 선형 투영을 사용하여 쿼리, 키 및 값을 각각 {d_k}, {d_k} 및 {d_v} 차원으로 linear projections하는 것이 유용하다. linear projections의 각 버전의 queries, keys, values에서 주의 함수를 병렬로 수행하여 차원으로 값을 출력한다. 이들은 연결되고 다시 한 번 투영되어 최종 값을 생성한다. Multi-head attention은 모델이 서로 다른 위치에 있는 서로 다른 표현 하위 공간(respresentation subspaces)의 정보에 공동으로 주의를 기울이게 한다. 단일 어텐션 헤드로 평균을 내는 것이 이를 막는다.
Where the projections are parameter matrices , , and .
이 논문에서는 attention layer와 head를 각각 8개를 병렬로 놓았다. 그리고 로 설정하였다. 각각의 감소된 차원으로 인해, 컴퓨팅 소요비용은 single-haed attenion의 모든 차원을 사용한 것과 비슷하다.
- parallel attention layers, or heads
Results
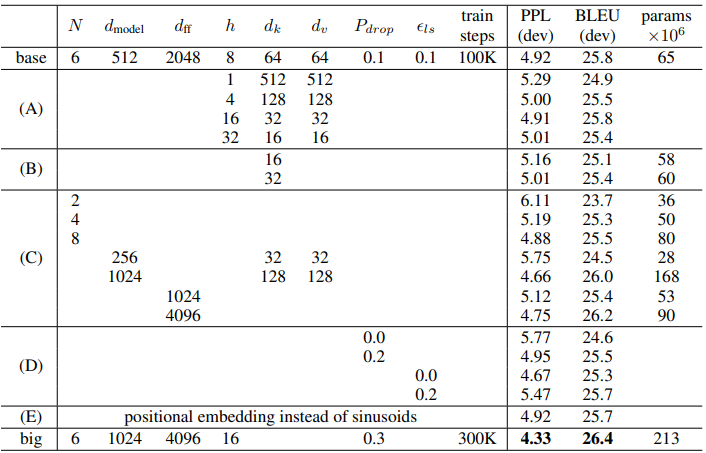
일러한 메카니즘을 적용한 실험결과는 여러 인수들을 적용하여 아래 표와 같이 확인할 수 있다. 평가 지표는 PPl(Perplexity), BLEU, Pramas 이다.
- , , #d_{ff}$ 등을 인수로 적용하여 실험을 하였다.
Reference
[1] Ashish Vaswani, Attention Is All You Need (https://arxiv.org/abs/1706.03762)
