
이번 시간에는 서포트 백터 머신에대해서 간단한 개요를 배워 보도록 하겠습니다
SVM(Support Vector Machine)
SVM은 패턴인식, 자료분성을 위한 지도학습 모델분류와 회귀분석을 위해 사용됩니다.
SVM알고리즘은 두 카테고리 중 한 곳에 속한 집합이 주어졌을 때, 주어진 데이터집합을 바탕으로 새로운 데이터가 어느 카테고리에 속하는지 비확률적 이진 선형분류모델을 만듭니다.
만들어진 분류 모델은 데이터가 사상된 공간에서 경계로 표현되는데 그 중 가장 큰 폭을 가진 경계를 찾습니다.
즉, 데이터들과 거리가 가장 먼 초평면(Hyperplane)을 선택하여 분리하는 알고리즘 입니다.
데이터를 분리하기 위해 margin을 이용하여 진선을 그려 줍니다.
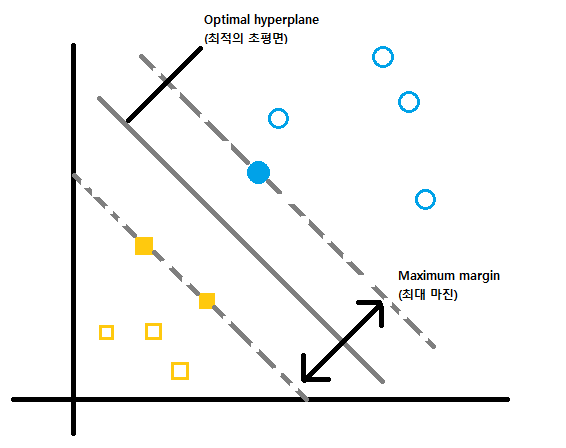
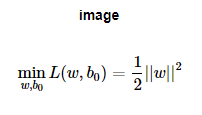
다음과 같이 데이터가 있을경우 SVM 알고리즘으로 분류를 한 예시입니다.
Support Vector는 데이터를 의미하며, Margin은 초평면과 가장 가까이 있는 데이터와의 거리를 의미합니다.
Margin을 최대로 만드는 직선을 계산하여 데이터를 분류하는 방법이 SVM 입니다.
SVM 데이터 생성
input
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
import numpy as np
learn_data=np.array([[0,0],[1,0],[0,1],[1,1]])
#learn_label=np.array([0,0,0,1]) # and
#learn_label=np.array([0,1,1,1]) # or
learn_label=np.array([0,1,1,0]) # xor
svm=LinearSVC() # 선형 svm 모형
svm.fit(learn_data, learn_label)
X_test=np.array([[0,0],[1,0],[0,1],[1,1]])
pred=svm.predict(X_test)
print(pred)
#print(accuracy_score([0,0,0,1], pred)) #and
#print(accuracy_score([0,1,1,1], pred)) #or
print(accuracy_score([0,1,1,0], pred)) #xoroutput
[1 1 1 1]
0.5
xor 데이터를 생성 후 SVM으로 학습 시켜줍니다.
데이터 시각화
input
import mglearn
mglearn.discrete_scatter(learn_data[:,0], learn_data[:,1], learn_label)output

데이터 시각화2
input
mglearn.discrete_scatter(learn_data[:,0], learn_data[:,1], learn_label)output

데이터 시각화3
input
mglearn.discrete_scatter(learn_data[:,0], learn_data[:,1], learn_label)output

최적화
input
from sklearn.svm import SVC
learn_data=np.array([[0,0],[1,0],[0,1],[1,1]])
learn_label=np.array([0,1,1,0]) # xor
svm=SVC() # 비선형 svm 모형 (linear 선형, rbf 비선형)
svm.fit(learn_data, learn_label)
X_test=np.array([[0,0],[1,0],[0,1],[1,1]])
pred=svm.predict(X_test)
print(pred)
print(accuracy_score([0,1,1,0], pred)) #xoroutput
[0 1 1 0]
1.0
시각화를 통해 데이터를 and, xor, or 중 분류 방법을 설정하고 학습시켜줍니다.
이번 시간은 간단하게 SVM이 어떤식으로 작동하는지 알아 보았습니다.좀 더 감을 잡아보기 위해
다음 시간에 더 배워보도록 하겠습니다.
😁 power through to the end 😁

AI (ML/DL) 학습