단순히 공부하는 노트로 사용되니 참고용으로만 사용하시길 바랍니다.
CNN 공부를 하면서 모델을 따라서 구현해보고있다. 하지만 단순히 따라하다 보니 내것이 되는 듯한 느낌이 들지 않는다. 그래서 이 글을 통해 keras 문법과 이론은 온전히 내것으로 만들고 싶다.
학습 데이터 Shuffle
학습 데이터 Shuffle은 Model 학습을 위해 Input데이터를 섞는 방법이다.
Input데이터가 들어오면 설정한 Batch Size에 의해 나눠진다. Shuffle은 dataset을 train dataset과 test dataset으로 나눌때, 한 epoch에서 data를 섞을때 이렇게 두 가지에서 쓰인다. 여기서는 한 epoch에서 data를 섞을때를 살펴보자.
Shuffle은 왜 필요한가?
Suffle이 필요한 이유중 하나는 Overfitting을 방지하고 Model 성능을 향상시킬 수 있기 때문이다.
[1, 0, 1, 1, 0, 0, 1]이라는 Label이 있을 때 Model이 근거를 가지고 답을 유추하는게 아닌 "1 다음이니까 0?"이런식으로 가는 것을 막기 위한 것이다.
[Tensorflow] Shuffle
Tensorflow keras model에서 fit()함수에 파라미터 'shuffle'을 True로 하게되면 각 epoch마다 데이터를 Shuffle해준다. default값은 True이다.
from tensorflow.keras.models import Model
model = Model()
# Model nonshuffle
noshuffle_history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=64, epochs=30, shuffle=False)
# Model shuffle
noshuffle_history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=64, epochs=30, shuffle=True)Batch Size 변경
Batch Size는 클수록 좋다고 생각하기 쉽다. 하지만 Batch Size는 적당히 작아야한다.
data가 50000개 있다고 가정하자.
Case1] Batch Size = 50
Case2] Batch Size = 5000
이때 1번 epoch를 돌때 1번 케이스는 Gradient Descent를 1000번 계산하지만 2번 케이스는 10번만 계산하게 된다.
즉, 더 자주 Weight를 업데이트 하므로 상대적으로 작은 Batch Size를 이용하는 것이 성능 향상에 도움이된다.
물론 그렇다고해서 일방적으로 작은 Batch Size가 좋은 Model을 만드는 것은 아니다.
Callback
Callback은 Model이 학습을 진행할 때 판단하에 주어진 명령을 진행할 수 있게 해준다.
우리가 Model을 compile할 때 정한 Optimizer와 같은 파라미터는 학습중에 동적으로 변경이 불가하지만 Callback을 이용해 Model의 fit을 중간에 멈출수도, learning rate를 중간에 바꿀수도 있다.
- ReduceLROnPlateau
from tensorflow.keras.models import Model
from tensorflow.keras import ReduceLROnPlateau
# Model Compile은 했다고 가정
reduce_lr_callback = ReduceLROnPlateau(monitor='val_loss',
factor=0.2,
patience=10,
verbose=True,
mode='min')
model = Model()
model.fit(test_image, test_oh_labels, callbacks=[reduce_lr_callback])learning rate는 Model의 성능에 중요한 영향을 끼친다.
keras에서는 이런 learning rate 동적변경에 대한 Callback API ReduceLROnPlateau를 지원한다.
- EarlyStopping
Model이 학습할 때 성능이 계속해서 나빠지면 Model을 중간에 멈추는게 나을수도 있다. 왜냐하면 시간도 아껴야하고 이미 global minimum에 도달했을수도 있기 때문이다.
keras에서는 특정 조건을 만족시켰을 때 조기에 학습을 중단하게 해주는 Callback API EarlyStopping을 지원한다.
from tensorflow.keras.callbacks import EarlyStopping
# Model Compile은 했다고 가정
earlystopping_callback = EarlyStopping(monitor='val_loss',
patience=10,
)
model = Model()
model.fit(test_image, test_oh_labels, callbacks=[earlystopping_callback])Global Average Pooling
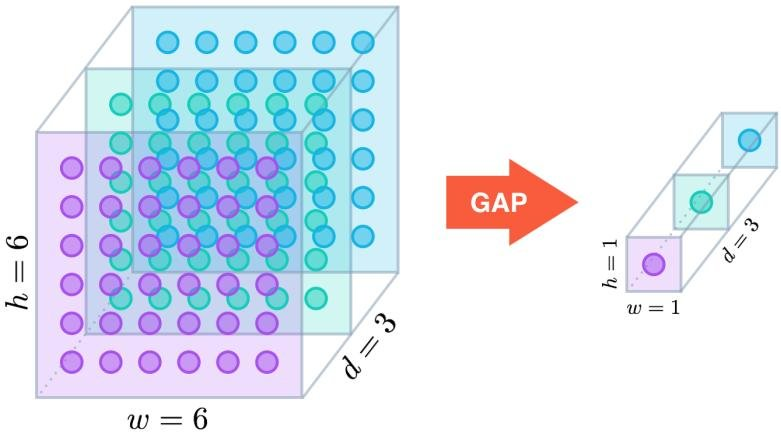
CNN에서 Input 데이터를 Convolution 연산을 거친후 이전에는 Flatten layer를 이용하여 classification Model에 넣었다.
Flatten layer를 이용하면 Input을 1차원으로 Squeeze해준다. 하지만 이 과정에서 모든 데이터를 압축해준다.
Global Average Pooling layer를 이용하면 모든 Input을 Squeeze할 필요가 없어진다.
Flatten과 Global Average Pooling중 어느것이 좋은가는 상황마다 차이가 있겠지만 일반적으로 CNN Model에서 채널이 일정수준 이상으로 많아지면 Global Average Pooling이 좋다고 한다.
CNN Model 대부분은 마지막 Classification에 들어가기 전 Input 채널이 많은 경우가 대다수이기 때문에 Flatten보다는 Global Average Pooling을 사용한다.
from tensorflow.keras.layers import GlobalAveragePooling2D, Conv2D, Activation, Input
from tensorflow.keras.layers import Dense
# GlobalAveragePooling을 적용한 간단한 Model
input_tensor = Input(shape=(32, 32, 3))
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(input_tensor)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)Global Average Pooling의 장점은 채널별로 계산을 진행하기때문에 Input데이터의 수가 준다는 장점이 있고, Overfitting을 예방해준다는 장점이 있다.
정리
- Input 데이터를 Shuffle하는 것이 Overfitting예방에 좋다.
- Batch Size는 적당히 작아야 좋다.
- Callback을 잘 활용하면 좋은 Model이 만들어질 수 있다.
- 채널이 많은 경우에는 Global Average Pooling이 Flatten보다 유리할 수도 있다.
#참고자료1
모델 학습 시 데이터를 shuffle해야 하는 이유(배치 학습)
#참고자료2
[ 인공지능 ] Loss Surface란?
#참고자료3
keras.callbacks.EarlyStopping
#참고자료4
keras.layers.ReduceLROnPlateau
#참고자료5
keras.layers.GlobalAveragePooling2D
#참고자료6
CNN완벽가이드 - 권철민
