Open Domain Question Answering
- 엄청나게 많은 정보들을 포함하고 있는 대량의 문서(예: 위키피디아)들로부터 주어진 질문에 대한 답변을 찾는 문제
- 주어진 질문이 어떤 도메인에 해당되는 질문인지, 어떤 키워드인지에 대한 힌트는 전혀 주어지지 않는다.
Background
딥러닝 등장 전
- 질의 분석(question analysis), 관련 문서 검색(document retrieval), 관련 문단 검색(passage retrieval), 정답 검색(answer extraction), 정답 검증(answer verification)과 같은 복잡한 과정을 거쳐서 질의에 대한 답변을 도출
딥러닝 발전이 급격하게 이루어지면서,
- open-domain QA는 (1) 주어진 질의에 대한 답변을 포함하고 있는 문단(passage)를 찾는 context retrieval 과정 (2) retrieve 된 문단에서 실제 답변을 찾는 reading 과정 2 step으로 이루어진 프레임워크로 간소화
[문제점]
여러 연구에서 QA의 본질적인 성능을 높이기 위해서는 관련 문서를 추리는 retrieval 모델의 성능을 향상시켜야 함과, 또한 여러개의 context를 고려할 수 있는 reading 모델을 만드는 것이 필요함을 주장
-
기존 주된 연구들은 질의와 관련된 문서를 추리기 위해서 TF-IDF uni-gram/bi-gram matching이나 BM25같은 고차원의 sparse representation을 사용함. inverted index를 이용해서 빠른 검색이 가능하고, 질의에 포함되어 있는 키워드를 기반으로 탐색을 할 수 있는 장점을 가짐.
-
이와 다르게 context의 semantic한 정보를 encoding하여 dense latent vector로 표현하는 방법은 기존의 spare retrieval을 보완하는 역할을 한다. 질의와 관련있는 문서가 아예 형태적(lexical)으로 다르게 생겼어도 의미적으로 유사성을 갖는다면 dense retrieval은 이를 매칭시킬 수 있는 능력을 갖고 있기 때문임.
- Q. Who is the bad guy in lord of the king?
- The most related document : Sala Baker is an actor and stuntman from New Zealand. He is best known for portraying the villain Sauron in the Lord of the Rings…
- sparse retrieval : 질의와 관련있는 문서가 형태적으로 곂치는 부분이 적기 때문에 예시의 문서를 관련 문서로 판단할 수 없음
- dense retrieval : “bad guy”와 “villain”이 유사한 의미임을 semantic하게 판단할 수 있기 때문에, 위 예시 문서를 관련 문서로 판단할 수 있음
▶ latent vector : 차원이 줄어든 채로 데이터를 잘 설명할 수 있는 잠재 공간에서의 벡터
Data
Natural Questions
구글에 입력된 real query에 대해 long / short / others 타입의 QA
- Open-domain QA 테스트를 위해 질문만 취하고, 답변을 찾을 수 있는 문단 정보는 삭제하는 방식으로 실험 진행
- long answer type의 경우 extractive snippet이라고 판단, 제거하고 실험
- (예. 답변이 5토큰 이내인 질문에 대해서만 실험, Lee et al., 2019)
- 링크: ai.google.com/research/NaturalQuestions/
CuratedTrec
TREC QA에서 파생한 데이터지만, 데이터 소스는 실제 쿼리(MSNSearch 등)에서 비롯한다. 즉, 사용자들이 문서를 보지 않고 던진 질문이라는 점에서 real world 데이터셋에 가까움
TriviaQA
웹에서 나온 쿼리-답변 쌍에 대한 데이터 (real-world x)
SQuAD
질문자가 문단을 보고 답변 영역과 그에 대한 자연어 질문을 만들어낸 데이터셋 (real-world x)
MS MARCO
Question Answering과 Passage re-ranking 태스크가 있음
- 쿼리에 대해 10개의 후보가 주어졌을 때 가장 관련있는 문단을 골라 답변을 찾아내는 태스크
- BM25가 리턴한 top-1000개의 문단 / 혹은 전체 880만개 문단에 대해 관련도에 따라 문서를 reranking하는 태스크
- 링크: microsoft.github.io/msmarco/
▶ BM25
: ranking function 종류 중 하나로 search 쿼리에 대한 문서들의 연관성을 측정하는 함수
- IDF : Inverse Document Frequency, 문서에서 자주 등장하는 단어일수록 낮은 기중치를 주는 방법
- TF : Term Frequency, 문서 내에서 같은 단어가 여러번 등장한다면 그 단어에 높은 가중치를 주는 방법. 단, TF-IDF는 단어 등장 횟수를 이용하는 대신 BM25는 문서 전체 길이 또한 반영함.

BM25는 문서 A와 B의 검색어 빈도수가 같을 때 문서의 길이가 길수록 낮은 score를 가진다. 또한 다른 문서에 잘 등장하지 않는 단어 a를 포함한 문서는 a의 빈도수가 높지 않아도 높은 score를 가진다.
WebQuestions
Google Suggest API에서 샘플링된 질문을 포함한 QA 데이터셋
- 답변은 대규모 지식그래프인 Freebase에 대해 annotation되어 있음.
- 개체에 대한 string representation만 사용해 open-domain QA로 테스팅
- 링크: github.com/brmson/dataset-factoid-webquestions
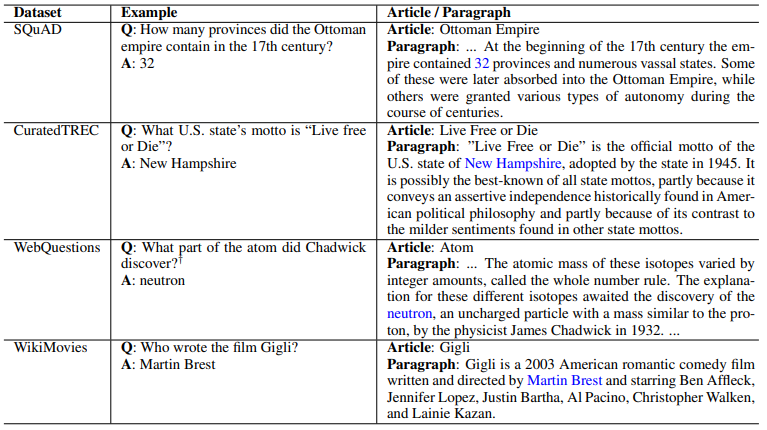
<데이터셋 예시: SQuAD, CuratedTREC, WebQuestions, WikiMovies>
METHODS
전통적인 접근 방법
Open Domain QA를 풀기 위해 전통적으로는 Retriever-Reader 프레임워크에서 2 step 추론 방법을 사용함
1) Retriever - 질문과 관련된 문서를 찾음
- space vector를 활용하는 TF-IDF, BM25 등의 기법 사용
2) Reader - 주어진 문서에 대해 구체적인 답변을 찾아냄
- 뉴럴넷 기반의 모델 사용
[대표적인 연구] DrQA (FAIR, 2017)
논문 : https://arxiv.org/pdf/1704.00051.pdf
Dense Retriever 학습
최근에는 전통적인 IR 방식의 한계를 극복하기 위해 Retriever를 학습하는 방법들이 제안되었다. 이러한 dense 벡터 공간을 학습하고, 서치를 진행하는 것은 어려운 작업인데, 모델의 search space 때문이다. (일반적인 Open domain QA의 대상문서는 백만 ~ 수십억개의 문서를 아우름)
[대표적인 연구]
1) Passage Re-ranking with BERT (2019)
논문 : https://arxiv.org/pdf/1901.04085.pdf
2) Latent Retrieval for Weakly Supervised Open Domain QA (2019)
- 논문 : https://arxiv.org/pdf/1906.00300.pdf
- IR 시스템 없이 retriever와 reader를 QA쌍으로부터 동시에 학습하는 방법을 제안
3) REALM (2020)
- 논문 : https://arxiv.org/pdf/2002.08909.pdf
- 사전학습 과정에서 질문에 대한 다변을 찾을 수 있는 문서를 찾아오는 것을 학습
4) Dense Passage Retrieval for Open-Domain QA (2020)
- 논문 : https://arxiv.org/pdf/2004.04906.pdf
- 논문 리뷰 : https://junseong.oopy.io/paper-reveiw/dpr
- Retrieval을 dense representation만 사용해서 찾아올 수 있다
Retriever-free 방식
Open domain QA에서 새로운 추세로 떠오른 방법은 대규모 사전학습 모델에 기반해 내제된 Knowledge Based를 활용하는 것이다. 이 방법은 추론 시 직접적으로 text data에 접근하지 않는다. GPT-3와 같이 뛰어난 성능의 pretrained model은 zero-shot 셋팅에서 사용자 질문에 바로 답변을 리턴한다.
대표적인 연구 : GPT-3 (Open AI, 2020)
참고 사이트
